python实战讲解之使用Python批量发送个性化邮件
前言
在现代工作环境中,我们经常需要向多个收件人发送个性化的邮件。通过使用Python编程语言,我们可以自动化这个过程,从Excel文件中读取收件人和相关数据,并发送定制的邮件。
首先,导入所需的库:
import pandas as pd
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.application import MIMEApplication
import os
from email.header import Header
然后,设置发件人邮箱和密码:
sender\_email = 'your\_email@example.com'
sender\_password = 'your\_password'
接下来,设置SMTP服务器和端口号(根据你使用的邮件服务提供商):
smtp\_server = 'smtp.example.com'
smtp\_port = 587
创建SMTP连接并登录到邮箱:
server = smtplib.SMTP(smtp\_server, smtp\_port)
server.starttls() # 开启TLS加密
server.login(sender\_email, sender\_password)
读取原始Excel文件:
df = pd.read\_excel('path\_to\_excel\_file.xlsx')
获取唯一的员工姓名列表:
employee\_names = df['员工姓名'].unique()
获取员工姓名和对应的邮箱地址,假设这些信息存储在一个字典中:
employee\_emails = {
'张三': 'zhangsan@example.com',
'李四': 'lisi@example.com',
'王五': 'wangwu@example.com',
# 添加更多员工和邮箱信息
}
遍历员工数据并发送邮件:
for employee\_name in employee\_names:
employee\_data = df[df['员工姓名'] == employee\_name] # 创建员工的数据
# 生成员工的 Excel 文件
employee\_data\_filename = f'{employee\_name}.xlsx'
employee\_data.to\_excel(employee\_data\_filename, index=False)
# 创建邮件
msg = MIMEMultipart()
msg['From'] = sender\_email
msg['To'] = employee\_emails.get(employee\_name, '') # 根据员工姓名获取邮箱
msg['Subject'] = '拆分数据通知'
body = f"尊敬的{employee\_name},您的拆分数据已经准备好,请查收附件。"
msg.attach(MIMEText(body, 'plain'))
# 添加附件
with open(employee\_data\_filename, 'rb') as file:
part = MIMEApplication(file.read(), Name=os.path.basename(employee\_data\_filename))
part.add\_header('Content-Disposition', 'attachment', filename=Header(os.path.basename(employee\_data\_filename), 'utf-8').encode())
msg.attach(part)
# 发送邮件
server.sendmail(sender\_email, employee\_emails.get(employee\_name, ''), msg.as\_string())
# 删除生成的员工数据文件
os.remove(employee\_data\_filename)
# 退出SMTP连接
server.quit()
最后,关闭与SMTP服务器的连接。
总结
通过上述Python脚本,我们可以批量发送个性化的邮件。我们首先设置发件人邮箱和密码,然后指定SMTP服务器和端口号。接下来,我们读取包含员工信息的Excel文件,并获取唯一的员工姓名列表和对应的邮箱地址。然后,我们遍历员工数据,并为每个员工创建邮件,附带相应的附件。最后,我们通过SMTP服务器发送邮件,并在发送完成后删除生成的员工数据文件。
完整代码:
import pandas as pd
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.application import MIMEApplication
import os
from email.header import Header
# 设置发件人邮箱和密码
sender\_email = 'liuchunlin202205@163.com'
sender\_password = '授权码'
# 设置SMTP服务器和端口(QQ邮箱的SMTP服务器和端口)
smtp\_server = 'smtp.163.com'
smtp\_port = 25
# 创建SMTP连接
server = smtplib.SMTP(smtp\_server, smtp\_port)
server.starttls() # 开启TLS加密
# 登录邮箱
server.login(sender\_email, sender\_password)
# 读取原始 Excel 文件
df = pd.read\_excel('C:\\Users\\liuchunlin2\\Desktop\\测试数据\\员工.xlsx')
# 获取唯一的员工姓名列表
employee\_names = df['员工姓名'].unique()
# 获取员工姓名和对应的邮箱地址,假设这些信息存储在一个字典中
employee\_emails = {
'刘备': '2823028760@qq.com',
'孙权': '2823028760@qq.com',
'曹操': '2823028760@qq.com',
# 添加更多员工和邮箱信息
}
# 遍历员工数据并发送邮件
for employee\_name in employee\_names:
# 创建员工的数据
employee\_data = df[df['员工姓名'] == employee\_name]
# 生成员工的 Excel 文件
employee\_data\_filename = f'{employee\_name}.xl
相关文章:

ModuleNotFoundError: No module named ‘qcloud_cos‘
是腾讯云提供的一个Python SDK,用于与腾讯云对象存储(COS)服务进行交互。使用pip安装qcloud_cos报以下错误。这个错误表示Python无法找到名为。
Springboot整合HBase——大数据技术之HBase2.x
Apache HBase 是以hdfs为数据存储的,一种分布式、可扩展的noSql数据库。是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase使用与BigTable(BigTable是一个稀疏的、分布式的、持久化的多维排序map)非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。

终于有人把Web 3.0和元宇宙讲明白了
分散的数据网络使个人数据(例如个人的健康数据、农民的作物数据或汽车的位置和性能数据)出售或交换成为可能,与此同时,不会失去对数据的所有权控制、放弃数据隐私或依赖第三方平台来管理数据。Web 3.0的目标是在创作者经济中取得更好的平衡。互联网第二次迭代(Web 2.0)的缺陷,加上公有区块链技术的诞生,帮助我们朝着更加去中心化的Web 3.0 迈进,元宇宙和更广泛的去中心化网络都是关于现实世界和虚拟世界的融合。此时的网络中不再是静态内容,而是动态的内容,用户现在可以与发布在网络上的内容进行交互。

python安装成功的图标_ubuntu下:安装anaconda、环境配置、软件图标的创建、成功启动anaconda图形界面...
Ubuntu安装anaconda常见的四大问题:目录1、介绍2、安装anaconda3、环境配置4、软件图标的创建5、成功启动anaconda图形界面1、介绍先介绍一下anaconda和python的关系:初学者所安装的python2/3只是python的环境,没有python的工具包&a…
万字详解数据仓库、数据湖、数据中台和湖仓一体
数字化转型浪潮卷起各种新老概念满天飞,数据湖、数据仓库、数据中台轮番在朋友圈刷屏,有人说“数据中台算个啥,数据湖才是趋势”,有人说“再见了数据湖、数据仓库,数据中台已成气候”……企业还没推开数字化大门,先被各种概念绊了一脚。那么它们 3 者究竟有啥区别?别急,先跟大家分享两个有趣的比喻。1、图书馆VS地摊如果把数据仓库比喻成“图书馆”,那么数据湖就是“地摊”。去图书馆借书(数据),书籍质量有保障,但你得等,等什么?等管理员先查到这本书属于哪个类目、在哪个架子上,你才能精准拿到自己想要的书;
什么是数据中台?
说完了数据中台诞生的历史背景,现在,我们应该对数据中台有了一定的了解,那我们现在给数据中台下个定义。自2016年,数据中台被提出以来,不同的人对数据中台有不同的理解,就像一千个读者心中有一千个哈姆雷特,因此也有许多不同的定义,以下是我从一些文章、书籍中搜集到的关于数据中台的定义:数据中台是DT时代的大背景下,为实现数据快(快速)、准(准确)、省(低成本)赋能业务发展的目标,将企业的数据统一整合起来,基于Onedata方法论借助大数据平台完成数据的统一加工处理,对外提供数据服务的一套机制。
Java中的方法重载和方法重写有什么区别?
Java中的方法重载(Overloading)和方法重写(Overriding)都是面向对象编程中的重要概念,但它们之间有一些区别。方法重载是指在同一个类中,可以定义多个具有相同名称但参数列表不同的方法。这些方法具有不同的参数类型、参数个数或参数顺序。在调用重载方法时,Java编译器会根据传递给方法的参数类型和数量来选择要调用的正确方法。方法重载主要用于解决方法的命名冲突和提高代码的可读性和可维护性。
python基础使用之变量,表达式,语句
PYTHON基础知识系列之变量、表达式、语句

python基础小知识:引用和赋值的区别
通过引用,就可以在程序范围内任何地方传递大型对象而不必在途中进行开销巨大的赋值操作。不过需要注意的是,这种赋值仅能做到顶层赋值,如果出现嵌套的情况下仍不能进行深层赋值。赋值与引用不同,复制后会产生一个新的对象,原对象修改后不会影响到新的对象。如果在原位置修改这个可变对象时,可能会影响程序其他位置对这个对象的引用

Python自动化实战之接口请求的实现
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。
Git 的基本概念、使用方式及常用命令
Git的基本概念、使用方式及常用命令
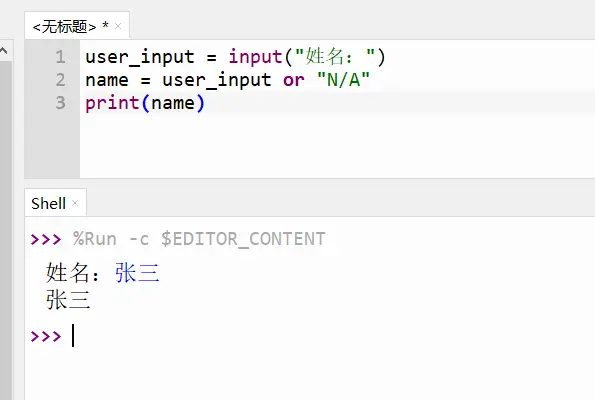
Python中如何简化if...else...语句
我们通常在Python中采用if...else..语句对结果进行判断,根据条件来返回不同的结果,如下面的例子。这段代码是一个简单的Python代码片段,让用户输入姓名并将其赋值给变量user_input。我们能不能把这几行代码进行简化,优化代码的执行效率呢?以下是对各行代码的解读。这里使用了or这个逻辑运算符,当user_input不为空时,user_input为真,name就被赋于user_input的值。采用这种方法可以轻松实现if...else语句的简化。我们可以使用一行简短的代码来实现上面的任务。
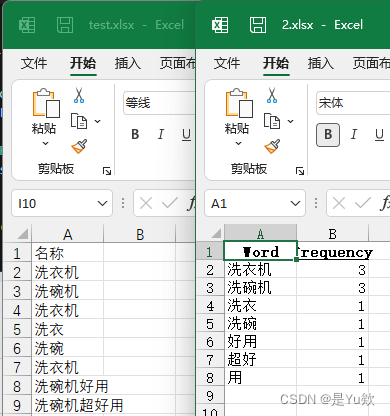
一键式Excel分词统计工具:如何轻松打包Python脚本为EXE
最近,表姐遇到了一个挑战:需要从Excel文件中统计出经过分词处理的重复字段,但由于数据隐私问题,这些Excel文件不能外传。这种情况下,直接使用Excel内置功能好像是行不通的,需要借助Python脚本来实现。为了解决这个问题,我写了一个简单的数据分析和自动化办公脚本,以方便使用。想象一下,即使电脑上没有安装Python,也能通过一个简单的EXE文件轻松完成工作,这是多么方便!因此,我决定不仅要写出这个脚本,还要学会如何将其打包成一个独立的EXE文件。这样,无需Python环境的电脑也能直接运行它
深入三目运算符:JavaScript、C++ 和 Python 比较
三目运算符是编程中常用的条件表达式,它允许我们根据条件选择不同的值。我们将通过具体的例子分别介绍 JavaScript、C++ 和 Python 中的三目运算符,以便更好地理解它们的用法和特性。JavaScript 示例// 例子: 根据条件选择不同的值var x = 10;var y = 20;"x 大于 y" : "x 不大于 y";在这个例子中,如果x大于y,则result的值为 “x 大于 y”,否则为 “x 不大于 y”。C++ 示例// 例子: 根据条件选择不同的值。

python实现网络爬虫代码_python如何实现网络爬虫
2、【find()】和【find_all()】方法可以遍历这个html文件,提取指定信息。return soup.find_all(string=re.compile( '百度' )) #结合正则表达式,实现字符串片段匹配。print(res) #打印输出[root@localhost demo]# python3 demo1.py。[root@localhost demo]# vim demo.py#web爬虫学习 -- 分析。r.raise_for_status() #如果状态码不是200,产生异常。
详细讲解Python中的aioschedule定时任务操作
aioschedule 是一个基于 asyncio 的 Python 库,用于在异步应用程序中进行任务调度。它提供了一种方便的方式来安排和执行异步任务,类似于传统的 schedule 库,但适用于异步编程。
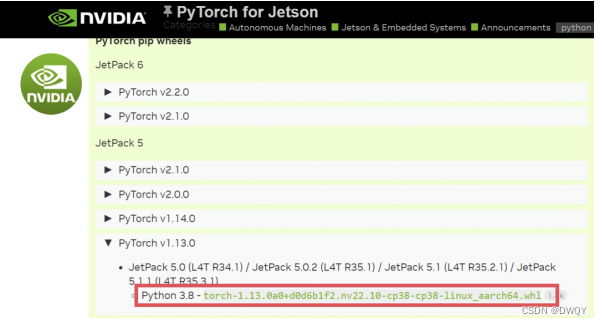
Jetson AGX Orin安装archiconda、Pytorch
Jetson AGX Orin安装archiconda、Pytorch

pandas进行数据计算时如何处理空值的问题?
我们在处理数据时经常会遇到空值的问题,比如有个学生某科弃考但是其他科有成绩的话,计算总分时便需要解决空值计算的问题
如何用pthon连接mysql和mongodb数据库【极简版】
发现宝藏 前言 1. 连接mysql 1.1 安装 PyMySQL 1.2 导入 PyMySQL 1.3 建立连接 1.4 创建游标对象 1.5 执行查询 1.6 关闭连接 1.7 完整示例 2. 连接mongodb 2.1 安装 PyMongo 2.2 导入 PyMongo 2.3 建立连接 2.4
用python实现实现手势音量控制
要实现手势音量控制,您可以使用Python中的PyAutoGUI和pynput库。PyAutoGUI可以模拟鼠标和键盘操作,而pynput可以检测用户的输入事件。,用于检测键盘事件。如果用户按下ESC键,则停止监听鼠标和键盘事件并退出程序。最后,我们创建了鼠标和键盘监听器对象,并调用它们的。,用于模拟按下音量增加和音量减少键的操作。然后,我们定义了一个鼠标手势检测函数。,用于检测鼠标左键的点击事件。在程序的主循环中,我们使用。在这个示例代码中,我们定义了两个函数。函数等待用户按下ESC键退出程序。
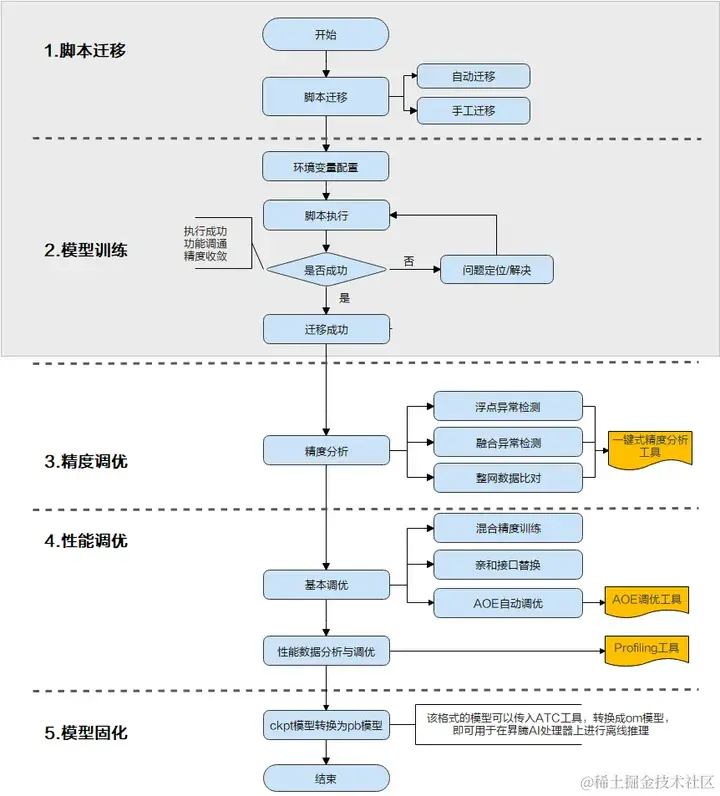
一文详解TensorFlow模型迁移及模型训练实操步骤
当前业界很多训练脚本是基于TensorFlow的Python API进行开发的,默认运行在CPU/GPU/TPU上,为了使这些脚本能够利用昇腾AI处理器的强大算力执行训练,需要对TensorFlow的训练脚本进行迁移。

websocket介绍并模拟股票数据推流
Websockt是一种网络通信协议,允许客户端和服务器双向通信。最大的特点就是允许服务器主动推送数据给客户端,比如股票数据在客户端实时更新,就能利用websocket。

Python实现PDF—>Excel的自动批量转换(附完整代码)
tkinter适用于简单的 GUI 应用,对于入门级开发者和小型项目而言是一个良好的选择。PyQt、PySide、Kivy 和 wxPython 适用于需要更丰富功能、更现代外观或跨平台移动应用的项目,但可能需要更多学习和配置。选择 GUI 库的最佳方法取决于项目的需求、开发者的经验水平以及对不同库的个人偏好。

怎么选择数据安全交换系统,能够防止内部员工泄露数据?
数据泄露可能给企业带来诸多风险:财产损失、身份盗窃、骚扰和诈骗、经济利益受损、客户信任度下降、法律风险和责任等,《2021年度数据泄漏态势分析报告》中显示,在数据泄露的主体中,内部人员导致的数据泄漏事件占比接近60%。飞驰云联文件安全交换系统,可以满足企业多场景下的文件交换需求,帮助企业终结多工具、 多系统并行使用的局面,减少因文件交换行为分散带来的数据管理不集中、难以管控的问题, 帮助企业内部构建统一、安全的企业数据流转通道。对于不能下载保存的数据,使用截屏、录屏的方式窃取并外泄数据;
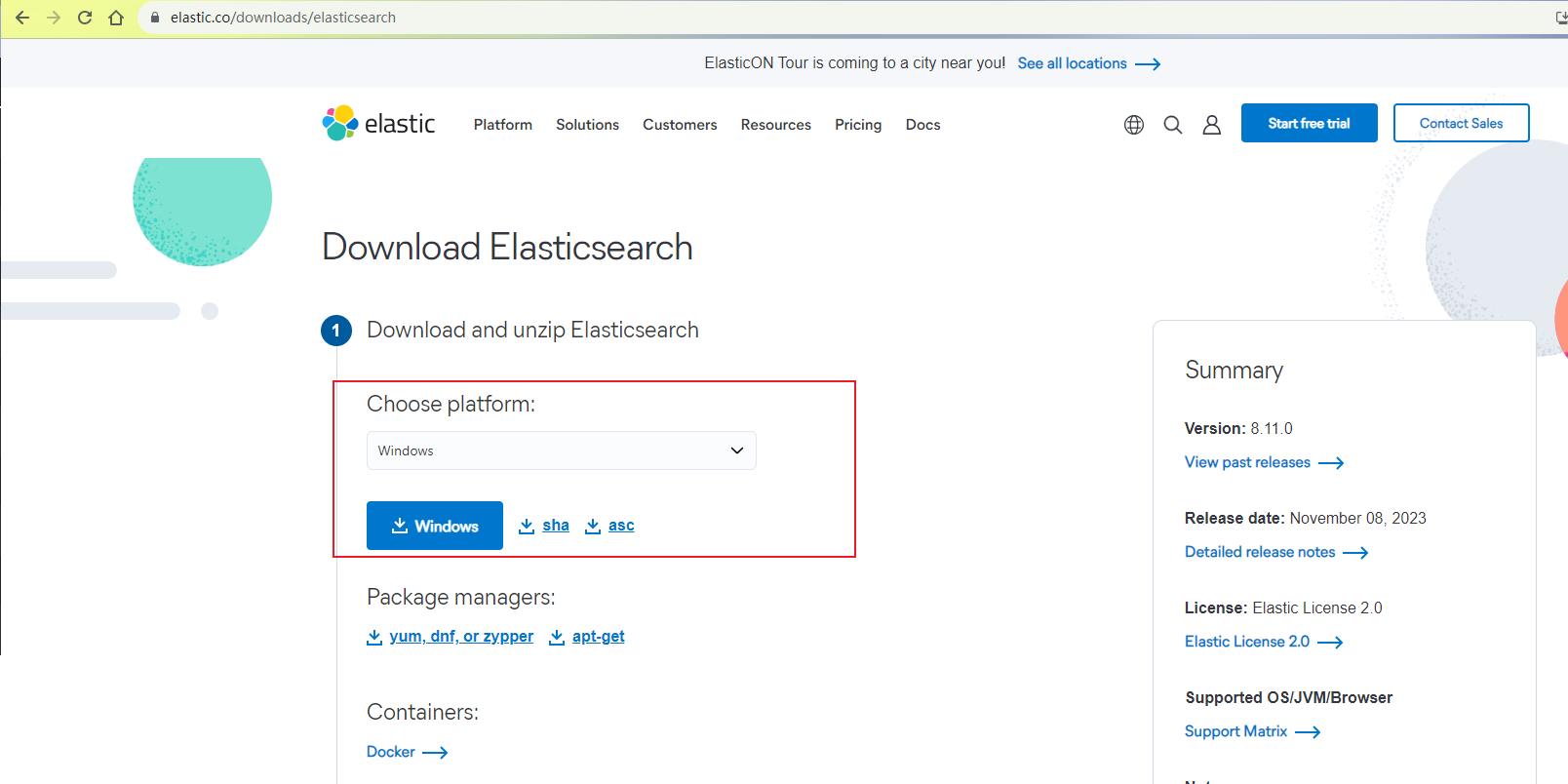
弹性搜索引擎Elasticsearch:本地部署与远程访问指南
本文主要讲解如何使用Elasticsearch分布式搜索分析引擎本地部署与远程访问。
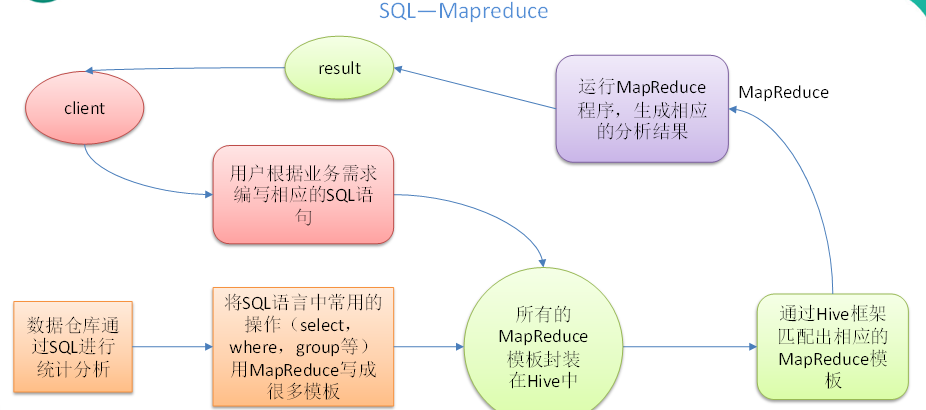
Hive(总)看完这篇,别说你不会Hive!
Hive:由Facebook开源用于解决海量结构化日志的数据统计。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。本质是:将HQL转化成MapReduce程序1)Hive处理的数据存储在HDFS2)Hive分析数据底层的实现是MapReduce3)执行程序运行在Yarn上创建一个数据库,数据库在HDFS上的默认存储路径是/opt/hive/warehouse/*.db避免要创建的数据库已经存在错误,增加if not exists判断。
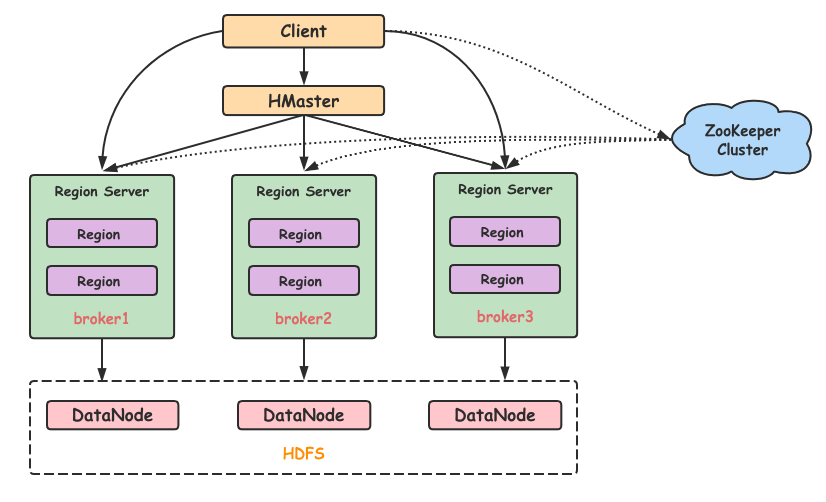
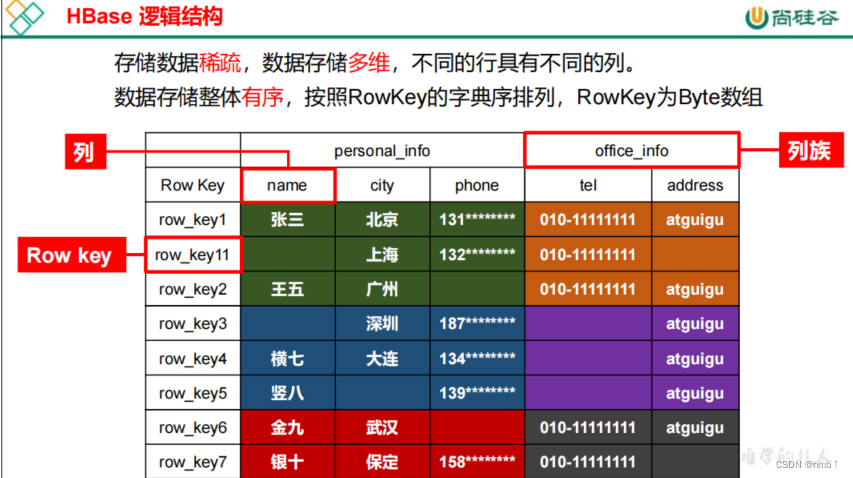
什么是HBase?终于有人讲明白了
在 HBase 表中,一条数据拥有一个全局唯一的键(RowKey)和任意数量的列(Column),一列或多列组成一个列族(Column Family),同一个列族中列的数据在物理上都存储在同一个 HFile 中,这样基于列存储的数据结构有利于数据缓存和查询。HBase Client 为用户提供了访问 HBase 的接口,可以通过元数据表来定位到目标数据的 RegionServer,另外 HBase Client 还维护了对应的 cache 来加速 Hbase 的访问,比如缓存元数据的信息。
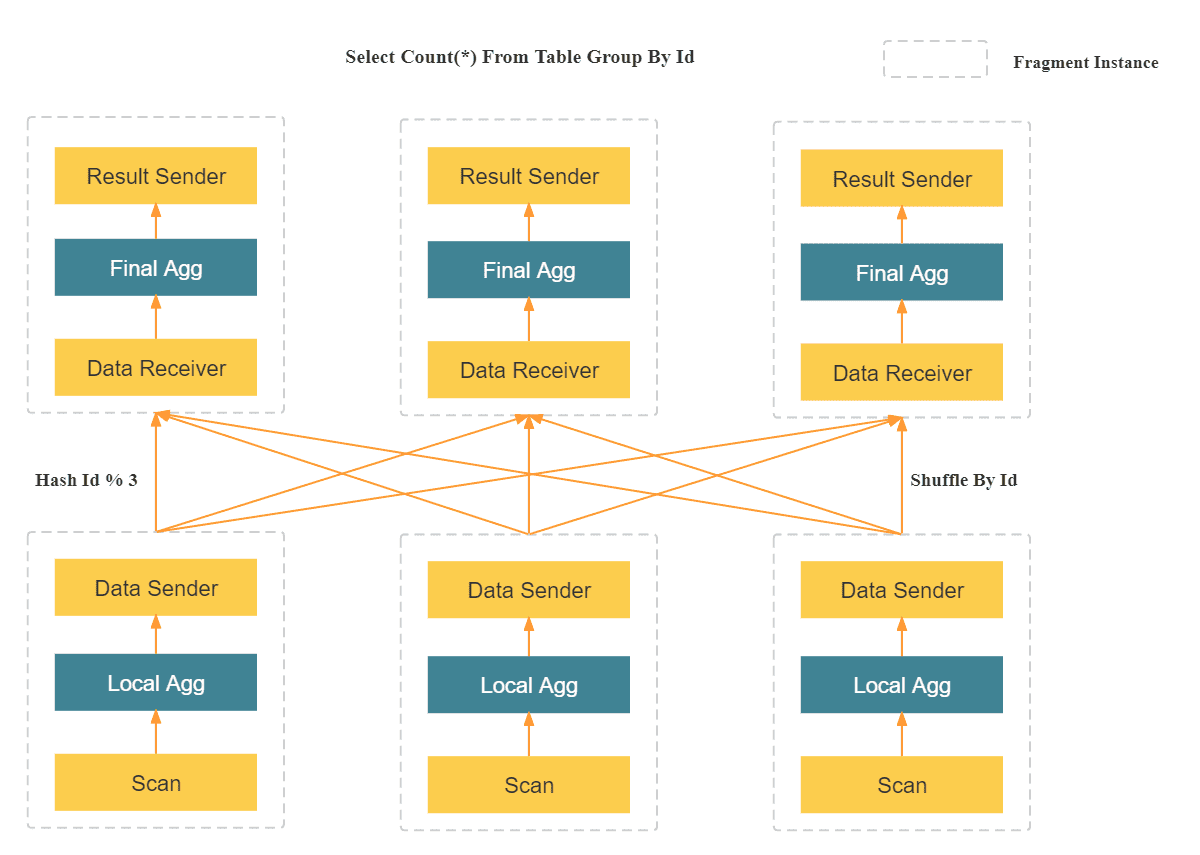
数据仓库系列:StarRocks 入门培训教程
StarRocks 是一款MPP DB, 对标ClickHouse、Vertica、Teradata、Greenplum,在查询性能上远超当代最快的开源数据库 clickhouse,目前已经被一众互联网企业在生产环境中采用。提供千亿级大数据的在线多维分析和分布式存储。新一代极速全场景 MPP (Massively Parallel Processing) 数据库是forkdoris后独立运营的商业化版本StarRocks。

Python 教程 01:Python 简介及发展历史
Python 是一门大小写敏感的、动态类型的、解释型的编程语言。

ClickHouse & StarRocks 使用经验分享
总结一下,如果是需要分析日志流数据,更加推荐 ClickHouse ,因为 ClickHouse 单机强悍,可以支撑亿级别数据量,架构简单,相比于 StarRocks 也更加稳定,相比集群,更推荐单机 ClickHouse。如果是分析业务流数据,更加推荐 StarRocks ,因为 StarRocks 对于更新场景性能更加,而且 JOIN 性能更好,而且更加推荐部署 StarRocks 集群,可以充分发挥 StarRocks 的性能。