如何爬取知乎中问题的回答以及评论的数据?
如何爬取知乎中问题的回答以及评论的数据?
我们以爬取“为什么中医没有得到外界认可?”为例来讨论一下如何爬取知乎中问题的回答以及评论的数据。
爬取网页数据通常情况下会经历以下三个步骤。
第一步:网页分析,确认自己所要数据的真正存储地址,以及这些url地址的规律。
第二步:爬取网页数据,并对这些数据进行清洗和整理变成结构化数据。
第三步:存储数据,以便于后面的分析。
下面我们分别来详细介绍。
一、网页分析
我们利用Chrome浏览器,打开所要爬取的网页:
https://www.zhihu.com/question/370697253
按F12查看元素,点击“Network”,再点击“XHR”选项。
先按左边的小圆圈清空列表,方便后面查找请求链接,再按“F5”刷新一下网页,如下图所示:
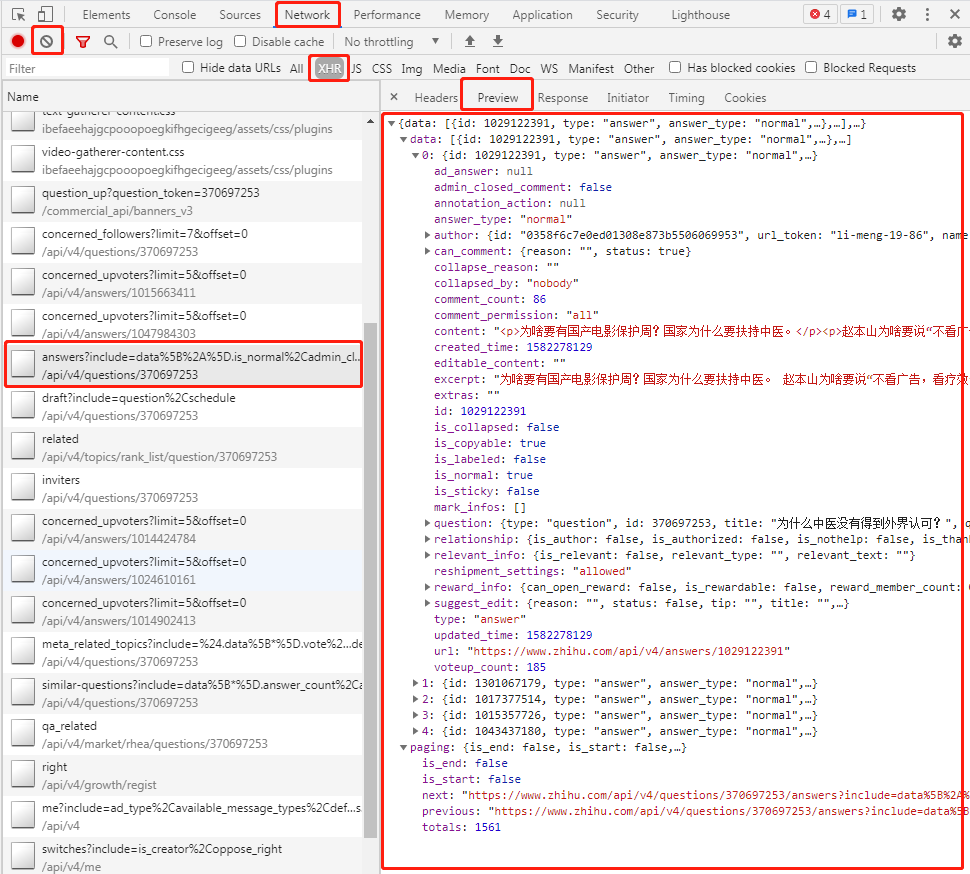
在列表中找到存储回答数据的url地址,点击后在“Preview”面板可以看到Josn格式的数据。
观察每一页数据对应的url地址。
第1页:
https://www.zhihu.com/api/v4/questions/370697253/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=0&platform=desktop&sort_by=default
第2页:
https://www.zhihu.com/api/v4/questions/370697253/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=5&platform=desktop&sort_by=default
第3页:
https://www.zhihu.com/api/v4/questions/370697253/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=10&platform=desktop&sort_by=default
我们发现,除了offset属性对应的取值不同,其余部分全部相同。而且offset属性对应的取值从0开始,每一页相差5。最后一页Json中的 paging -> is_end属性为false。
以上是问题回答的网页分析。我们再分析一下针对每个回答的评论。
跟上面的步骤相同,找到这些评论存储的真正网络地址。
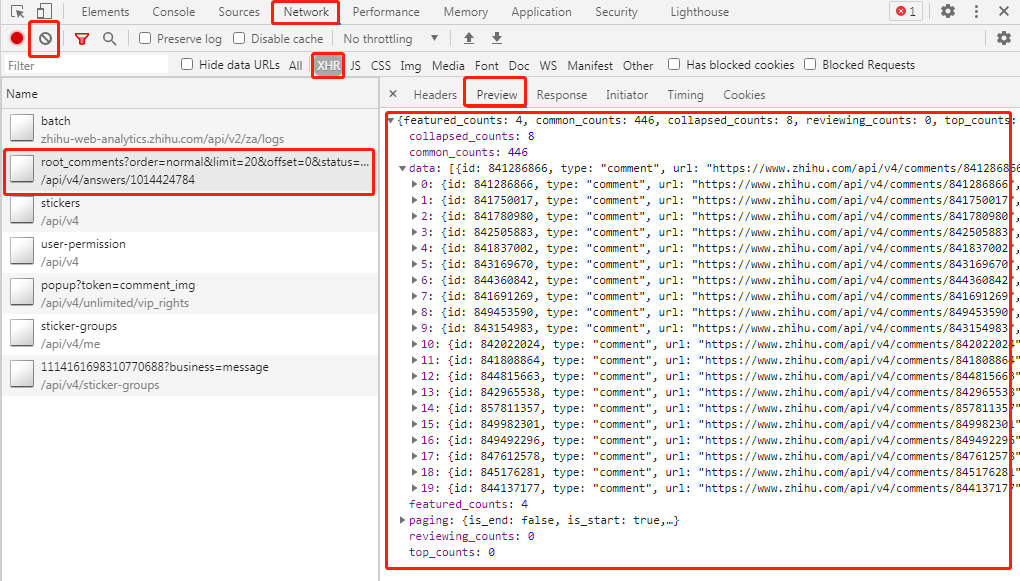
观察每一页数据对应的url地址如下:
第1页:
https://www.zhihu.com/api/v4/answers/1014424784/root_comments?order=normal&limit=20&offset=0&status=open
第2页:
https://www.zhihu.com/api/v4/answers/1014424784/root_comments?order=normal&limit=20&offset=20&status=open
第3页:
https://www.zhihu.com/api/v4/answers/1014424784/root_comments?order=normal&limit=20&offset=40&status=open
“1014424784”是该回答的id,不同的回答该id值不同。上面的url是针对同一回答的评论,这些url地址除了offset属性对应的取值不同,其余部分全部相同。而且offset属性对应的取值从0开始,每一页相差20。最后一页Json中的 paging -> is_end属性为false。
二、常用库介绍
(1)requests
requests的作用就是发送网络请求,返回响应数据。
官方文档如下:
https://docs.python-requests.org/zh_CN/latest/user/quickstart.html
(2)json
Json 是一种轻量级的数据交换格式,完全独立于任何程序语言的文本格式。一般,后台应用程序将响应数据封装成Json格式返回。
官方文档如下:
https://docs.python.org/zh-cn/3.7/library/json.html
(3)lxml
lxml 是一个HTML/XML的解析器,主要功能是解析和提取 HTML/XML 数据。
官方文档如下:
https://lxml.de/index.html
由于本图文的篇幅有限,后面会另写图文分别介绍上面这些跟爬虫相关的库。
三、完整代码
GetAnswers方法用于爬取问题的回答数据。
回答数据结构化之后的属性有:帖子的ID(answer_id)、作者名称(author)、发表时间(created_time)、帖子内容(content)。
GetComments方法用于爬取每个问题的评论数据。
评论数据结构化之后的属性有:评论的ID(answer_id_comment_id)、作者名称(author)、发表时间(created_time)、评论内容(content)。
这些数据全部存储在“知乎评论.csv”这个文件中,需要注意的是该文件用Excel打开之后出现中文乱码,解决方法可以参考前面的一篇图文如何解决Python3写入CSV出现’gbk’ codec can’t encode的错误?
import requests
import json
import time
import csv
from lxml import etreeheaders = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36',
}csvfile = open('知乎评论.csv', 'w', newline='', encoding='utf-8')
writer = csv.writer(csvfile)
writer.writerow(['id', 'created_time', 'author', 'content'])def GetAnswers():i = 0while True:url = 'https://www.zhihu.com/api/v4/questions/370697253/answers' \'?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%' \'2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%' \'2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%' \'2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%' \'2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%' \'2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%' \'2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset={0}&platform=desktop&' \'sort_by=default'.format(i)state=1while state:try:res = requests.get(url, headers=headers, timeout=(3, 7))state=0except:continueres.encoding = 'utf-8'jsonAnswer = json.loads(res.text)is_end = jsonAnswer['paging']['is_end']for data in jsonAnswer['data']:l = list()answer_id = str(data['id'])l.append(answer_id)l.append(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(data['created_time'])))l.append(data['author']['name'])l.append(''.join(etree.HTML(data['content']).xpath('//p//text()')))writer.writerow(l)print(l)if data['admin_closed_comment'] == False and data['can_comment']['status'] and data['comment_count'] > 0:GetComments(answer_id)i += 5print('打印到第{0}页'.format(int(i / 5)))if is_end:breaktime.sleep(1)def GetComments(answer_id):j = 0while True:url = 'https://www.zhihu.com/api/v4/answers/{0}/root_comments?order=normal&limit=20&offset={1}&status=open'.format(answer_id, j)state=1while state:try:res = requests.get(url, headers=headers, timeout=(3, 7))state=0except:continueres.encoding = 'utf-8'jsonComment = json.loads(res.text)is_end = jsonComment['paging']['is_end']for data in jsonComment['data']:l = list()comment_id = str(answer_id) + "_" + str(data['id'])l.append(comment_id)l.append(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(data['created_time'])))l.append(data['author']['member']['name'])l.append(''.join(etree.HTML(data['content']).xpath('//p//text()')))writer.writerow(l)print(l)for child_comments in data['child_comments']:l.clear()l.append(str(comment_id) + "_" + str(child_comments['id']))l.append(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(child_comments['created_time'])))l.append(child_comments['author']['member']['name'])l.append(''.join(etree.HTML(child_comments['content']).xpath('//p//text()')))writer.writerow(l)print(l)j += 20if is_end:breaktime.sleep(1)GetAnswers()
csvfile.close()四、总结
本篇文档是大数据与哲学社会科学实验室召开第75次学术讨论会上汇报的内容,大家如果感兴趣可以在微信后台回复“资料下载”来获取源码,以及该帖子爬取的8000多条数据。
相关文章:

Facebook如何使用Avartarnode提升HDFS可靠性
在不久前的Hadoop峰会上,Facebook的工程师Andrew Ryan分享了他们如何使用Namenode和Avatarnode提升HDFS可靠性的方法。Ryan从2009年开始,就参与到了Facebook的 Hadoop开发中。在他的帮助下,Facebook的Hadoop和HDFS数据基础设施,从…

无法远程分发安装软件原因
一、问题及原因 最近做实验在域环境通过组策略分发软件、防病毒网络版远程安装客户端软件都失败,真的原因在于:阻止对Windows注册表的远程访问引起来的。客户端是XP系统,通过Ghost版本安装的,默认是禁用Windows XP注册表的远程访…

小程序的ui应该怎么设计?
UI设计中小程序的设计是很多UI设计师在工作中会碰到的,一款好的小程序设计页面,会带来效果很好的用户体验,下面小编就为大家详细的分享一下具体小程序的ui应该怎么设计? UI设计培训分享:小程序的ui应该怎么设计? 一、导航明确&a…

什么是ThreadLocal
顾名思义它是local variable(线程局部变量)。它的功用非常简单,就是为每一个使用该变量的线程都提供一个变量值的副本,使每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。从线程的角度看࿰…
【组队学习】【25期】Datawhale组队学习内容介绍
第25期 Datawhale 组队学习活动马上就要开始啦! 本次组队学习的内容为: web开发入门教程数据挖掘实战(异常检测)集成学习(下) 大家可以根据我们的开源内容进行自学,也可以加入我们的组队学习…
为pony程序添加IACA标记(二)
在上一篇文章介绍了一种加IACA标记的方法,但使用还是很麻烦,所以我尝试修改pony编译器,直接增加了IACA支持,目前代码在iaca分支。 使用方法 因为还没发PR到上游,所以要自己克隆编译。 git clone https://github.com/or…

Python培训就业怎么样?
学习Python技术的同学越来越多,很多人都比较看好Python这项技术,觉得Python的前景是不错的,那么具体Python培训就业怎么样呢?来看看下面的详细介绍就知道了。 Python培训就业怎么样?国家大力推行互联网人工之智能技术、大数据技术等&#x…
Oracle Connect to an idle instance
意思是数据库没有启动。转载于:https://www.cnblogs.com/vigarbuaa/archive/2012/09/05/2671825.html
【青少年编程】【Scratch】10 画笔模块
10 画笔模块 有关于画笔模块,需要掌握以下两个方面的内容: 能够设置画笔的属性:颜色、粗细、亮度/饱和度/透明度能够使用画笔绘制各种图案:抬笔、落笔、擦除 1. 使用者可以设置各种画笔属性。 另外,可以将角色设置为…

4-1 ADO.NET简介
第四章ADO.NET数据库访问技术本章内容4-1 ADO.NET 简介4-2 ADO.NET-插入、删除、修改、检索数据4-3 DataGridView 控件 — 显示和操作数据4-4本章小结 本章重点介绍WINDOWS应用程序对数据访问所涉及的SYSTEM.DATA.SQLCLIENT、SYSTEM.DATA.OLEDB、SYSTEM.DATA.ORA…

Java培训出来后一般多少工资
学完Java培训出来后一般多少工资呢?这是很多人都比较关心的一个问题,小编在这里告诉大家,java技术这个岗位分为初级、中级和高级,每个等级的工资情况也是不一样,来看看下面的详细介绍。 Java培训出来后一般多少工资?Java程序员薪…

NeHe OpenGL第四十一课:体积雾气
NeHe OpenGL第四十一课:体积雾气 体积雾气 把雾坐标绑定到顶点,你可以在雾中漫游,体验一下吧。 这一课我们将介绍体积雾,为了运行这个程序,你的显卡必须支持扩展"GL_EXT_fot_coord"。 #include <wi…

如何做中文文本的情感分析?
如何做中文文本的情感分析? 这是本学期在大数据哲学与社会科学实验室做的第三次分享了。 第一次分享的是:如何利用“wordcloudjieba”制作中文词云? 第二次分享的是:如何爬取知乎中问题的回答以及评论的数据? 本次…
java游戏开发--连连看-让程序运行更稳定、更高效
之六)优化:让程序运行更稳定、更高效 改善游戏的合理性 到目前为止,我们的游戏基本上算是完成了,为了使程序更合理,我们还需要将整个程序从头再理一遍,看看有没有改进的地方。 首先,在变量的…

学java是不是必须要参加java培训班?
学java是不是必须要参加java培训班?java技术对于零基础的同学来说学习起来是比较困难的,所以对于这个问题,小编的回答是当然要参加java培训班进行系统学习,下面来看看到底有没有必要报班学习? 学java是不是必须要参加java培训班?学习Java无…
【青少年编程】黄羽恒:我要背单词
「青少年编程竞赛交流群」已成立(适合6至18周岁的青少年),公众号后台回复【Scratch】或【Python】,即可进入。如果加入了之前的社群不需要重复加入。 微信后台回复“资料下载”可获取以往学习的材料(视频、代码、文档&…

【转载】:最佳注释
原文地址:http://blog.xiqiao.info/2012/08/29/1240 转载于:https://www.cnblogs.com/TianFang/archive/2012/09/05/2672558.html
从 C++ 到 Objective-C
开始一个新的系列《从 C 到 Objective-C》。欢迎感兴趣的童鞋看看。在做完《让你的 Qt 桌面程序看上去更加 native》之后,也会把这个系列搬到这里来吧。不过这是后话了…;-P 地址:http://www.devbean.info PS:话说 wordpress 还是更好用一些……
参加UI设计培训如何高效学习
想要成为一名合格的UI设计师,扎实的基础知识是要到位的,那么如何在短时间内学会UI设计技术呢?那么就要了解高效的学习方法了,下面就为大家详细的介绍一下参加UI设计培训如何高效学习? 参加UI设计培训如何高效学习? 一、1%原则 让自己变得更…
访问级别约束0906
1 访问级别约束子类访问级别不能比父类高 儿子能去的地方老子一定能去方法、属性等暴露的返回值、参数的数据类型不能比方法、属性或者所在类的可访问级别低,因为这些方法、属性要能在高级场合出现,如果用到的类型却不能在这个场合出现就明显不合理了&am…
VSCode环境下配置ESLint 对Vue单文件的检测
本文介绍了在VSCode环境下如何配置eslint进行代码检查,并介绍了如何对.vue单文件进行支持。 ESLint 安装1.在工程根目录下,安装eslint及初始化 $ npm install eslint --save-dev $ ./node_modules/.bin/eslint -- --init //会输出几个问题,指…
【青少年编程】黄羽恒:加减乘除法小测试
「青少年编程竞赛交流群」已成立(适合6至18周岁的青少年),公众号后台回复【Scratch】或【Python】,即可进入。如果加入了之前的社群不需要重复加入。 微信后台回复“资料下载”可获取以往学习的材料(视频、代码、文档&…

Python Cookie HTTP获取cookie并处理
本期Python培训教程是教大家如何进行HTTP获取cookie并处理的方法,希望本期教程能够给大家带来帮助,请看以下详细内容介绍。 Cookie模块同样是Python标准库中的一员,它定义了一些类来解析和创建HTTP 的 cookie头部信息。 一、创建和设置Cookie…
利益驱动 需求驱动 技术驱动 谁才是真正的驱动力?
作java码工也有上段日子了,没有调查,就没有发方权。更何况自已是亲身试了一把,有人说程序员就是二代农民工,我还是比较赞同的,对于刚入道的同仁们来说确实就是个体力活。真就迁扯不到什么高深的算法,虽然在…

【青少年编程】黄羽恒:翻译小工具 -- 利用有道翻译
「青少年编程竞赛交流群」已成立(适合6至18周岁的青少年),公众号后台回复【Scratch】或【Python】,即可进入。如果加入了之前的社群不需要重复加入。 微信后台回复“资料下载”可获取以往学习的材料(视频、代码、文档&…
iframe 自动适应高和宽问题 和 其他Frame操作技巧
< DOCTYPE html PUBLIC -WCDTD XHTML TransitionalEN httpwwwworgTRxhtmlDTDxhtml-transitionaldtd> iframe 自动适应高和宽问题iframe的滚动条很难看,很多时候需要自动调整高和宽 扩展到使页面显示正常。搜索了一下,以下是解决办法:fu…

Python代码编写过程中有哪些重要技巧?
近几年,转行做Python技术岗的人越来越多,大家对于Python的关注越来越高,尤其是工作后,很多人都想知道Python代码编写过程中有哪些重要技巧?小编告诉大家,在编写Python代码过程中,除了在意代码的功能性&…
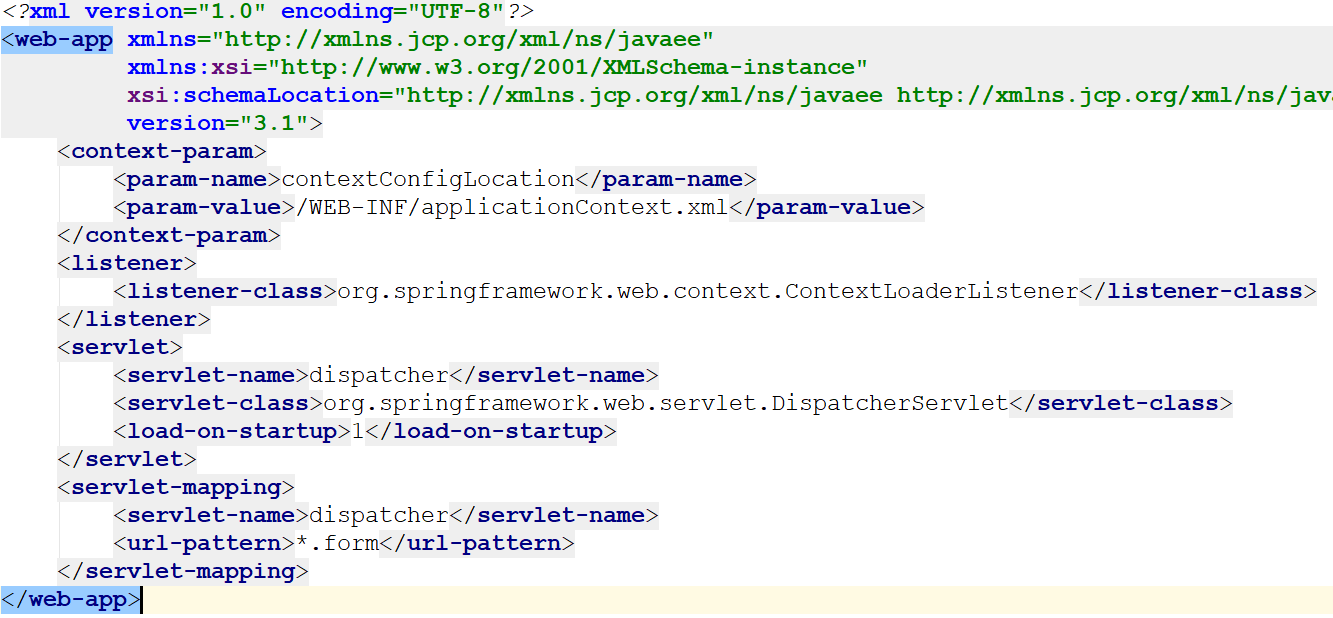
SpringMVC启动分析
以下分析基于JDK1.8 启动的第一步是执行监听器,这里web.xml中配置了一个监听器org.springframework.web.context.ContextLoaderListener 接下来,看ContextLoaderLisener 在Web应用启动的时候,所有的ServletContextListener会在filter和servle…
Edit Distance
题意是求俩字符串的编辑距离,编辑定义有三种1、插入字符 2、删除字符 3、替换字符。 int minDistance(string word1, string word2) { if (word1.size() 0) return (int)word2.size(); if (word2.size() 0) return (int)word1.size(); int result 0; int *dist …
【青少年编程】黄羽恒:翻译小工具 -- 利用百度翻译
「青少年编程竞赛交流群」已成立(适合6至18周岁的青少年),公众号后台回复【Scratch】或【Python】,即可进入。如果加入了之前的社群不需要重复加入。 微信后台回复“资料下载”可获取以往学习的材料(视频、代码、文档&…