如何使用日志进行程序调试_如何使用日志节省调试时间
如何使用日志进行程序调试
by Maya Gilad
通过Maya Gilad
如何使用日志节省调试时间 (How to save hours of debugging with logs)
A good logging mechanism helps us in our time of need.
一个 良好的日志记录机制可以在需要时帮助我们。
When we’re handling a production failure or trying to understand an unexpected response, logs can be our best friend or our worst enemy.
当我们处理生产故障或试图了解意外的响应时,日志可能是我们最好的朋友,也可能是我们最大的敌人。
Their importance for our ability to handle failures is enormous. When it comes to our day to day work, when we design our new production service/feature, we sometimes overlook their importance. We neglect to give them proper attention.
它们对于我们处理故障的能力至关重要。 当涉及到日常工作时,当我们设计新的生产服务/功能时,有时会忽略它们的重要性。 我们忽略给他们适当的关注。
When I started developing, I made a few logging mistakes that cost me many sleepless nights. Now, I know better, and I can share with you a few practices I’ve learned over the years.
当我开始开发时,我犯了一些记录错误,这些错误使我失去了许多不眠之夜。 现在,我知道的更多了,我可以与您分享我多年来学到的一些实践。
没有足够的磁盘空间 (Not enough disk space)
When developing on our local machine, we usually don’t mind using a file handler for logging. Our local disk is quite large and the amount of log entries being written is very small.
在本地计算机上进行开发时,我们通常不介意使用文件处理程序进行日志记录。 我们的本地磁盘很大,正在写入的日志条目数量很少。
That is not the case in our production machines. Their local disk usually has limited free disk space. In time the disk space won’t be able to store log entries of a production service. Therefore, using a file handler will eventually result in losing all new log entries.
在我们的生产机器中并非如此。 他们的本地磁盘通常具有有限的可用磁盘空间。 随着时间的推移,磁盘空间将无法存储生产服务的日志条目。 因此,使用文件处理程序最终将导致丢失所有新的日志条目。
If you want your logs to be available on the service’s local disk, don’t forget to use a rotating file handler. This can limit the max space that your logs will consume. The rotating file handler will handle overriding old log entries to make space for new ones.
如果您希望日志在服务的本地磁盘上可用, 请不要忘记使用旋转文件处理程序。 这个 可以限制您的日志将占用的最大空间。 旋转文件处理程序将处理覆盖的旧日志条目,以为新日志条目腾出空间。
Eeny,meeny,miny,moe (Eeny, meeny, miny, moe)
Our production service is usually spread across multiple machines. Searching a specific log entry will require investigating all them. When we’re in a hurry to fix our service, there’s no time to waste on trying to figure out where exactly did the error occur.
我们的生产服务通常分布在多台机器上。 搜索特定的日志条目将需要调查所有这些条目。 当我们急于修复我们的服务时,没有时间浪费在试图弄清楚错误的确切位置。
Instead of saving logs on local disk, stream them into a centralized logging system. This allows you to search all them at the same time.
与其将日志保存在本地磁盘上, 不如将它们流式传输到集中式日志系统中。 这使您可以同时搜索所有它们。
If you’re using AWS or GCP — you can use their logging agent. The agent will take care of streaming the logs into their logging search engine.
如果您使用的是AWS或GCP,则可以使用其日志记录代理。 代理将负责将日志流式传输到其日志搜索引擎中。
要登录还是不登录? 这是问题... (To log or not log? this is the question…)
There is a thin line between too few and too many logs. In my opinion, log entries should be meaningful and only serve the purpose of investigating issues on our production environment. When you’re about to add a new log entry, you should think about how you will use it in the future. Try to answer this question: What information does the log message provide the developer who will read it?
日志太少与太多之间有一条细线。 我认为,日志条目应该有意义,并且仅用于调查生产环境中的问题。 当您要添加新的日志条目时,应考虑将来如何使用它。 尝试回答以下问题: 日志消息为开发人员提供了哪些信息?
Too many times I see logs being used for user analysis. Yes, it is much easier to write “user watermelon2018 has clicked the button” to a log entry than to develop a new events infrastructure. This is not the what logs are meant for (and parsing log entries is not fun either, so extracting insights will take time).
我看到很多次日志都用于用户分析。 是的,在日志条目中写“ user lemon2018 has clicked the button”要比开发新的事件基础架构容易得多。 这不是日志的目的(解析日志条目也不是一件好事,因此提取见解将需要时间)。
大海捞针 (A needle in a haystack)
In the following screenshot we see three requests which were processed by our service.
在以下屏幕截图中,我们看到三个请求已由我们的服务处理。
How long did it take to process the second request? Is it 1ms, 4ms or 6ms?
处理第二个请求花了多长时间? 是1ms,4ms还是6ms?
2018-10-21 22:39:07,051 - simple_example - INFO - entered request 2018-10-21
22:39:07,053 - simple_example - INFO - entered request 2018-10-21
22:39:07,054 - simple_example - INFO - ended request 2018-10-21
22:39:07,056 - simple_example - INFO - entered request 2018-10-21
22:39:07,057 - simple_example - INFO - ended request 2018-10-21
22:39:07,059 - simple_example - INFO - ended requestSince we don’t have any additional information on each log entry, we cannot be sure which is the correct answer. Having the request id in each log entry could have reduced the number of possible answers to one. Moreover, having metadata inside each log entry can help us filter the logs and focus on the relevant entries.
由于我们在每个日志条目上没有任何其他信息,因此我们无法确定哪个是正确的答案。 在每个日志条目中都有请求ID可以将可能的答案数量减少到一个。 此外, 在每个日志条目中包含元数据可以帮助我们过滤日志并专注于相关条目。
Let’s add some metadata to our log entry:
让我们在日志条目中添加一些元数据:
2018-10-21 23:17:09,139 - INFO - entered request 1 - simple_example
2018-10-21 23:17:09,141 - INFO - entered request 2 - simple_example
2018-10-21 23:17:09,142 - INFO - ended request id 2 - simple_example
2018-10-21 23:17:09,143 - INFO - req 1 invalid request structure - simple_example
2018-10-21 23:17:09,144 - INFO - entered request 3 - simple_example
2018-10-21 23:17:09,145 - INFO - ended request id 1 - simple_example
2018-10-21 23:17:09,147 - INFO - ended request id 3 - simple_exampleThe metadata is placed as part of the free text section of the entry. Therefore, each developer can enforce his/her own standards and style. This will result in a complicated search.
元数据被放置为条目的自由文本部分的一部分。 因此,每个开发人员都可以执行自己的标准和样式。 这将导致复杂的搜索。
Our metadata should be defined as part of the entry’s fixed structure.
我们的元数据应定义为条目的固定结构的一部分。
2018-10-21 22:45:38,325 - simple_example - INFO - user/create - req 1 - entered request
2018-10-21 22:45:38,328 - simple_example - INFO - user/login - req 2 - entered request
2018-10-21 22:45:38,329 - simple_example - INFO - user/login - req 2 - ended request
2018-10-21 22:45:38,331 - simple_example - INFO - user/create - req 3 - entered request
2018-10-21 22:45:38,333 - simple_example - INFO - user/create - req 1 - ended request
2018-10-21 22:45:38,335 - simple_example - INFO - user/create - req 3 - ended requestEach message in the log was pushed aside by our metadata. Since we read from left to right, we should place the message as close as possible to the beginning of the line. In addition, placing the message in the beginning “breaks” the line’s structure. This helps us with identifying the message faster.
日志中的每条消息都被我们的元数据推开了。 由于我们是从左到右阅读的,因此应该将消息放置在尽可能靠近行首的位置。 此外,将消息放在开头会“破坏”行的结构。 这有助于我们更快地识别消息。
2018-10-21 23:10:02,097 - INFO - entered request [user/create] [req: 1] - simple_example
2018-10-21 23:10:02,099 - INFO - entered request [user/login] [req: 2] - simple_example
2018-10-21 23:10:02,101 - INFO - ended request [user/login] [req: 2] - simple_example
2018-10-21 23:10:02,102 - INFO - entered request [user/create] [req: 3] - simple_example
2018-10-21 23:10:02,104 - INFO - ended request [user/create [req: 1] - simple_example
2018-10-21 23:10:02,107 - INFO - ended request [user/create] [req: 3] - simple_examplePlacing the timestamp and log level prior to the message can assist us in understanding the flow of events. The rest of the metadata is mainly used for filtering. At this stage it is no longer necessary and can be placed at the end of the line.
在消息之前放置时间戳和日志级别可以帮助我们了解事件的流程。 元数据的其余部分主要用于过滤。 在此阶段,它不再是必需的,可以放在行尾。
An error which is logged under INFO will be lost between all normal log entries. Using the entire range of logging levels (ERROR, DEBUG, etc.) can reduce search time significantly. If you want to read more about log levels, you can continue reading here.
在INFO下记录的错误将在所有普通日志条目之间丢失。 使用整个范围的日志记录级别(ERROR,DEBUG等)可以大大减少搜索时间 。 如果您想了解更多有关日志级别的信息,可以继续阅读此处 。
2018-10-21 23:12:39,497 - INFO - entered request [user/create] [req: 1] - simple_example
2018-10-21 23:12:39,500 - INFO - entered request [user/login] [req: 2] - simple_example
2018-10-21 23:12:39,502 - INFO - ended request [user/login] [req: 2] - simple_example
2018-10-21 23:12:39,504 - ERROR - invalid request structure [user/login] [req: 1] - simple_example
2018-10-21 23:12:39,506 - INFO - entered request [user/create] [req: 3] - simple_example
2018-10-21 23:12:39,507 - INFO - ended request [user/create [req: 1] - simple_example
2018-10-21 23:12:39,509 - INFO - ended request [user/create] [req: 3] - simple_example日志分析 (Logs analysis)
Searching files for log entries is a long and frustrating process. It usually requires us to process very large files and sometimes even to use regular expressions.
在文件中搜索日志条目是一个漫长而令人沮丧的过程。 它通常需要我们处理非常大的文件,有时甚至需要使用正则表达式。
Nowadays, we can take advantage of fast search engines such as Elastic Search and index our log entries in it. Using ELK stack will also provide you the ability to analyze your logs and answer questions such as:
如今,我们可以利用诸如Elastic Search之类的快速搜索引擎 ,并在其中索引日志条目。 使用ELK堆栈还将使您能够分析日志并回答以下问题:
- Is the error localized to one machine? or does it occur in all the environment?错误是否局限于一台机器? 还是发生在所有环境中?
- When did the error started? What is the error’s occurrence rate?错误何时开始? 错误的发生率是多少?
Being able to perform aggregations on log entries can provide hints for possible failure’s causes that will not be noticed just by reading a few log entries.
能够对日志条目执行聚合可以为可能的失败原因提供提示,仅通过读取一些日志条目就不会注意到这些提示。
In conclusion, do not take logging for granted. On each new feature you develop, think about your future self and which log entry will help you and which will just distract you.
总之,不要将日志记录视为理所当然。 在开发的每个新功能上,请考虑一下自己的未来,哪些日志条目将对您有所帮助,哪些只会分散您的注意力。
Remember: your logs will help you solve production issues only if you let them.
请记住:只有让日志允许,您的日志才会帮助您解决生产问题。
翻译自: https://www.freecodecamp.org/news/how-to-save-hours-of-debugging-with-logs-6989cc533370/
如何使用日志进行程序调试
相关文章:

(转)线程的同步
Java线程:线程的同步-同步方法线程的同步是保证多线程安全访问竞争资源的一种手段。线程的同步是Java多线程编程的难点,往往开发者搞不清楚什么是竞争资源、什么时候需要考虑同步,怎么同步等等问题,当然,这些问题没有很…
wpf浏览器应用程序发布后获取当前应用地址
AppDomain.CurrentDomain.ApplicationIdentity.CodeBase 获取作为URL的部署清单的位置 Eg:发布前地址为E:\PROJECTWORK\LandaV8\bin\Debug\xxxxx.xbap(xxxxx.xbap为部署站点下的文件),部署后获取的地址为http://192.168.1.1/xxx…

微信小程序获取用户手机号,后端php实现 (前后端完整代码附效果图)
微信小程序开发交流qq群 173683895 承接微信小程序开发。扫码加微信。 如图: 小程序代码: 第一步,登录,获取用户的 session_key; 第二步,点击按钮调用 bindgetphonenumber 事件,通过该事件…
pytorch与keras_Keras vs PyTorch:如何通过迁移学习区分外星人与掠食者
pytorch与kerasby Patryk Miziuła通过PatrykMiziuła Keras vs PyTorch:如何通过迁移学习区分外星人与掠食者 (Keras vs PyTorch: how to distinguish Aliens vs Predators with transfer learning) This article was written by Piotr Migdał, Rafał Jakubanis…
Ubuntu 16.04安装QQ(不一定成功)
注意1:如果是刚新装的系统,可以正常安装,但是,如果你已经装了很多软件,千万不要安装,因为会把系统上一般的依赖包和你之前装的软件全部卸载掉!甚至将桌面Dock都会卸载!最终只能重装U…
for循环动态的给select标签添加option内容
微信小程序开发交流qq群 173683895 承接微信小程序开发。扫码加微信。 html <select class"form-control selectpicker" name"college" id"eq_num" data-actions-box"true" data-live-search"true" data-live-sea…
Linux下Debug模式启动Tomcat进行远程调试
J2EE开发各类资源下载清单, 史上最全IT资源,点击进入! 一. 应用场景 在实际的测试过程中,可能会遇到由于程序执行的不间断性,我们无法构造测试场景来验证某个功能的正确性,只有通过代码级的调试才能验…
guice google_与Google Guice的动手实践
guice googleby Sankalp Bhatia通过Sankalp Bhatia 与Google Guice的动手实践 (A hands-on session with Google Guice) A few months ago, I wrote an article explaining dependency injection. I had mentioned of a follow-up article with a hands-on session of Google …
IQKeyboardManager使用方法
使用方法:将IQKeyboardManager 和 IQSegmentedNextPrevious类文件加进项目中。在AppDelegate文件中写下以下一行代码: [IQKeyBoardManager installKeyboardManager]; 搞定! 也可以开启或者关闭keyboard avoiding功能: [IQKeyBoard…
JQ加AJAX 加PHP实现网页登录功能
微信小程序开发交流qq群 173683895 承接微信小程序开发。扫码加微信。 前端代码 <!DOCTYPE HTML> <html><head><link href"css/style.css" rel"stylesheet" type"text/css" media"all" /><meta http-eq…
web安全简介_Web安全:HTTP简介
web安全简介by Alex Nadalin通过亚历克斯纳达林 Web安全:HTTP简介 (Web Security: an introduction to HTTP) This is part 2 of a series on web security: part 1 was “Understanding The Browser”这是有关网络安全的系列文章的第2部分:第1部分是“…

继承实现的原理、子类中调用父类的方法、封装
一、继承实现的原来 1、继承顺序 Python的类可以继承多个类。继承多个类的时候,其属性的寻找的方法有两种,分别是深度优先和广度优先。 如下的结构,新式类和经典类的属性查找顺序都一致。顺序为D--->A--->E--->B--->C。 class E:…
hdu 5366 简单递推
记f[i]为在长度是i的格子上面至少放一个木桩的方法数。考虑第i个格子,有放和不放两种情况。 1.如果第i个格子放了一个木桩,则i - 1和i - 2格子上面不能放木桩,方案数为:f[i - 3] 1 2.如果第i个格子没有放木桩,则方案数…
git 代理 git_如何不再害怕GIT
git 代理 git了解减少不确定性的机制 (Understanding the machinery to whittle away the uncertainty) 到底什么是Git? (What is Git anyway?) “It’s a version control system.”“这是一个版本控制系统。” 我为什么需要它? (Why do I need it?)…

Python 基础 - Day 2 Assignment - ShoppingCart 购物车程序
作业要求 1、启动程序后,输入用户名密码后,如果是第一次登录,让用户输入工资,然后打印商品列表 2、允许用户根据商品编号购买商品 3、用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒 4…
hdu 1878 欧拉回路
欧拉回路 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submission(s): 10548 Accepted Submission(s): 3849 Problem Description欧拉回路是指不令笔离开纸面,可画过图中每条边仅一次,且可以回到起点…
bootstrap 时间日期日历控件(datetimepicker)附效果图
开发交流QQ群: 173683895 173683895 526474645 人满的请加其它群 效果图 代码 <!DOCTYPE html> <html><head><meta charset"UTF-8"><link href"https://cdn.bootcss.com/bootstrap/3.3.7/css/bootstrap.min.css" rel&q…
如何在您HTML中嵌入视频和音频
by Abhishek Jakhar通过阿比舍克贾卡(Abhishek Jakhar) 如何在您HTML中嵌入视频和音频 (How to embed video and audio in your HTML) HTML allows us to create standards-based video and audio players that don’t require the use of any plugins. Adding video and audi…

html 省份,城市 选择器附效果图
开发交流QQ群: 173683895 173683895 526474645 人满的请加其它群 效果图: 源码: <!DOCTYPE html> <html><head><meta charset"UTF-8"><link href"https://cdn.bootcss.com/bootstrap/3.3.7/css/boots…
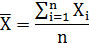
机器学习:协方差矩阵
一、统计学的基本概念 统计学里最基本的概念就是样本的均值、方差、标准差。首先,我们给定一个含有n个样本的集合,下面给出这些概念的公式描述: 均值: 标准差: 方差: 均值描述的是样本集合的中间点…
TemplatedParent 与 TemplateBinding
http://blog.csdn.net/idebian/article/details/8761388转载于:https://www.cnblogs.com/changbaishan/p/4716414.html
避免成为垃圾邮件_如何避免犯垃圾
避免成为垃圾邮件by Yoel Zeldes由Yoel Zeldes 如何避免犯垃圾 (How to avoid committing junk) In the development process, every developer writes stuff they don’t intend to commit and push to the remote server, things like debug prints. It happens to all of u…
[bzoj2333] [SCOI2011]棘手的操作 (可并堆)
//以后为了凑字数还是把题面搬上来吧2333 发布时间果然各种应景。。。 Time Limit: 10 Sec Memory Limit: 128 MB Description 有N个节点,标号从1到N,这N个节点一开始相互不连通。第i个节点的初始权值为a[i],接下来有如下一些操作࿱…
vue.js created函数注意事项
因为created钩子函数是页面一加载完就会调用的函数,所以如果你想在这个组件拿值或者是赋值,很可能this里面能拿到数据,但是如果你用this.赋值的话,控制台或者debugger都会发现this里面有你所想要的数据,但是赋值后就是…
JS删除城市的后缀
开发交流QQ群: 173683895 173683895 526474645 人满的请加其它群 代码 const deleteStr str >{if (str.indexOf("市") ! -1 || str.indexOf("州") ! -1){str str.substring(0, str.length - 1)console.log(删除城市的最后一个字,str)return s…
gatsby_将您的GraphCMS数据导入Gatsby
gatsbyLets set up Gatsby to pull data from GraphCMS.让我们设置Gatsby来从GraphCMS中提取数据。 This will be a walk-through of setting up some basic data on the headless CMS, GraphCMS and then querying that data in Gatsby.这将是在无头CMS,GraphCMS上…
Java学习笔记07--日期操作类
一、Date类 在java.util包中定义了Date类,Date类本身使用非常简单,直接输出其实例化对象即可。 public class T { public static void main(String[] args) { Date date new Date(); System.out.println("当前日期:"date); //当前…
javascript数组集锦
设计数组的函数方法 toString, toLocaleString, valueOf, concat, splice, slice indexOf,lastIndexOf, push, pop, shift, unshift, sort, reverse map, reduce, reduceRight, filter, every, some, forEach 创建数组 数组字面量创建:var arr [val1, val2, val3];…
JS实现HTML标签转义及反转义
开发交流QQ群: 173683895 173683895 526474645 人满的请加其它群 编码反编码 function html_encode(str) { var s ""; if (str.length 0) return ""; s str.replace(/&/g, "&"); s s.replace(/</g, "<")…
喜欢把代码写一行的人_我最喜欢的代码行
喜欢把代码写一行的人Every developer has their favourite patterns, functions or bits of code. This is mine and I use it every day.每个开发人员都有自己喜欢的模式,功能或代码位。 这是我的,我每天都用。 它是什么? (What is it?) …