pytorch与keras_Keras vs PyTorch:如何通过迁移学习区分外星人与掠食者
pytorch与keras
by Patryk Miziuła
通过PatrykMiziuła
Keras vs PyTorch:如何通过迁移学习区分外星人与掠食者 (Keras vs PyTorch: how to distinguish Aliens vs Predators with transfer learning)
This article was written by Piotr Migdał, Rafał Jakubanis and myself. In the previous post, they gave you an overview of the differences between Keras and PyTorch, aiming to help you pick the framework that’s better suited to your needs.
本文由PiotrMigdał , RafałJakubanis和我本人撰写。 在上一篇文章中,他们为您概述了Keras和PyTorch之间的区别 ,旨在帮助您选择更适合您需求的框架。
Now, it’s time for a trial by combat.
现在,该进行战斗审判了。
We’re going to pit Keras and PyTorch against each other, showing their strengths and weaknesses in action. We present a real problem, a matter of life-and-death: distinguishing Aliens from Predators!
我们将让Keras和PyTorch相互对立,展示他们在行动上的优点和缺点。 我们提出了一个真正的问题,一个生死攸关的问题:将外星人与捕食者区分开!
We’ll perform image classification, one of the computer vision tasks deep learning shines at. As training from scratch is unfeasible in most cases (as it is very data hungry), we’ll perform transfer learning using ResNet-50 pre-trained on ImageNet. We’ll get as practical as possible, to show both the conceptual differences and conventions.
我们将执行图像分类,这是深度学习所展现的计算机视觉任务之一。 由于在大多数情况下从头开始进行培训是不可行的(因为它非常耗费数据),因此我们将使用在ImageNet上经过预先培训的ResNet-50进行迁移学习。 我们将尽可能实用,以显示概念上的差异和约定。
At the same time we’ll keep the code fairly minimal, to make it clear and easy to read and reuse. See notebooks on GitHub, Kaggle kernels or Neptune versions with fancy charts.
同时,我们将代码保持在最小限度,以使其清晰易读和重用。 在GitHub , Kaggle内核或Neptune版本 上查看带有花式图表的 笔记本 。
等一下,什么是转学? 为什么选择ResNet-50? (Wait, what’s transfer learning? And why ResNet-50?)
In practice, very few people train an entire Convolutional Network from scratch (with random initialization), because it is relatively rare to have a dataset of sufficient size. Instead, it is common to pretrain a ConvNet on a very large dataset (e.g. ImageNet, which contains 1.2 million images with 1000 categories), and then use the ConvNet either as an initialization or a fixed feature extractor for the task of interest. — Andrej Karpathy, Transfer Learning — CS231n Convolutional Neural Networks for Visual Recognition
实际上,很少有人从头开始训练整个卷积网络(使用随机初始化),因为拥有足够大小的数据集相对很少。 取而代之的是,通常在非常大的数据集(例如ImageNet,其中包含120万个具有1000个类别的图像)上对ConvNet进行预训练,然后将ConvNet用作初始化或固定特征提取器以完成感兴趣的任务。 — 安德烈·卡帕蒂 ( Andrej Karpathy), 转移学习— CS231n用于视觉识别的卷积神经网络
Transfer learning is a process of making tiny adjustments to a network trained on a given task to perform another, similar task.
转移学习是对在给定任务上训练的网络进行微小调整以执行另一个相似任务的过程。
In our case we’re working with the ResNet-50 model trained to classify images from the ImageNet dataset. It is enough to learn a lot of textures and patterns that may be useful in other visual tasks, even as alien as this Alien vs. Predator case. That way, we’ll use much less computing power to achieve much better results.
在我们的案例中,我们正在使用ResNet-50模型,该模型经过训练可对ImageNet数据集中的图像进行分类。 学习很多在其他视觉任务中可能有用的纹理和图案就足够了,即使像“外星人与捕食者”案例一样陌生。 这样,我们将使用更少的计算能力来获得更好的结果。
In our case we’re going to do it the simplest possible way:
在我们的案例中,我们将以最简单的方式进行操作:
- keep the pre-trained convolutional layers (so-called feature extractor), with their weights frozen, and保持预训练的卷积层(所谓的特征提取器),使其权重保持不变,并且
- remove the original dense layers, and replace them with brand-new dense layers we will use for training.删除原始的密集层,然后将其替换为我们将用于训练的全新密集层。
So, which network should we choose as the feature extractor?
那么,我们应该选择哪个网络作为特征提取器?
ResNet-50 is a popular model for ImageNet image classification (AlexNet, VGG, GoogLeNet, Inception, Xception are other popular models). It is a 50-layer deep neural network architecture based on residual connections, which are connections that add modifications with each layer, rather than completely changing the signal.
ResNet-50是ImageNet图像分类的流行模型(AlexNet,VGG,GoogLeNet,Inception,Xception是其他流行模型)。 它是一个基于残差连接的50层深度神经网络架构, 残差连接是对每一层进行修改而不是完全改变信号的连接。
ResNet was the state-of-the-art on ImageNet in 2015. Since then, newer architectures with higher scores on ImageNet have been invented. However, they are not necessarily better at generalizing to other datasets (see the Do Better ImageNet Models Transfer Better? arXiv paper).
ResNet是2015年ImageNet上的最先进技术。从那时起,就发明了ImageNet上得分更高的更新架构 。 但是,它们不一定能更好地推广到其他数据集(请参见“更好的ImageNet模型是否更好地传输?” arXiv文件)。
Ok, it’s time to dive into the code.
好的,是时候深入研究代码了。
让比赛开始! (Let the match begin!)
We’ll set up our Alien vs. Predator challenge in seven steps:
我们将通过七个步骤设置“外星人与捕食者”挑战:
0. Prepare the dataset1. Import dependencies2. Create data generators3. Create the network4. Train the model5. Save and load the model6. Make predictions on sample test images
0.准备数据集1。 导入依赖项2。 创建数据生成器3。 创建网络4。 训练模型5。 保存并加载模型6。 对样本测试图像进行预测
We’re supplementing this blog post with Python code in Jupyter Notebooks (Keras-ResNet50.ipynb, PyTorch-ResNet50.ipynb). This environment is more convenient for prototyping than bare scripts, as we can execute it cell by cell and peak into the output.
我们在Jupyter Notebooks( Keras-ResNet50.ipynb , PyTorch-ResNet50.ipynb )中用Python代码补充了此博客文章。 与裸脚本相比,此环境对原型制作更方便,因为我们可以逐个执行它并到达输出峰。
All right, let’s go!
好吧,走吧!
0.准备数据集 (0. Prepare the dataset)
We created a dataset by performing a Google Search with the words “alien” and “predator”. We saved JPG thumbnails (around 250×250 pixels) and manually filtered the results. Here are some examples:
我们通过使用单词“ alien”和“ predator”执行Google搜索来创建数据集。 我们保存了JPG缩略图(约250×250像素),并手动过滤了结果。 这里有些例子:
We split our data into two parts:
我们将数据分为两部分:
- Training data (347 samples per class) — used for training the network.训练数据(每班347个样本)—用于训练网络。
- Validation data (100 samples per class) — not used during the training, but needed in order to check the performance of the model on previously unseen data.验证数据(每堂课100个样本)—在训练期间未使用,但需要使用该数据来检查以前看不见的数据的模型性能。
Keras requires the datasets to be organized in folders in the following way:
Keras要求以下列方式将数据集组织在文件夹中:
If you want to see the process of organizing data into directories, check out the data_prep.ipynb file. You can download the dataset from Kaggle.
如果要查看将数据组织到目录中的过程,请检出data_prep.ipynb文件。 您可以从Kaggle下载数据集。
1.导入依赖 (1. Import dependencies)
First, the technicalities. We’re assuming that you have Python 3.5+, Keras 2.2.2 (with TensorFlow 1.10.1 backend) and PyTorch 0.4.1. Check out the requirements.txt file in the repo.
首先,技术性。 我们假设您拥有Python 3.5 +,Keras 2.2.2(具有TensorFlow 1.10.1后端)和PyTorch 0.4.1。 在仓库中检出requirements.txt文件。
So, first, we need to import the required modules. We’ll separate the code in Keras, PyTorch and common (one required in both).
因此,首先,我们需要导入所需的模块。 我们将用Keras,PyTorch和common(两者都需要)分开代码。
We can check the frameworks’ versions by typing keras.__version__ and torch.__version__, respectively.
我们可以分别通过输入keras.__version__和torch.__version__来检查框架的版本。
2.创建数据生成器 (2. Create data generators)
Normally, the images can’t all be loaded at once, as doing so would be too much for the memory to handle. At the same time, we want to benefit from the GPU’s performance boost by processing a few images at once. So we load images in batches (e.g. 32 images at once) using data generators. Each pass through the whole dataset is called an epoch.
通常,图像不能一次全部加载,因为这样做对于内存来说太过分了。 同时,我们希望通过一次处理一些图像来受益于GPU的性能提升。 因此,我们使用数据生成器批量加载图像(例如一次加载32张图像)。 遍历整个数据集的每个过程称为一个时期 。
We also use data generators for preprocessing: we resize and normalize images to make them as ResNet-50 likes them (224 x 224 px, with scaled color channels). And last but not least, we use data generators to randomly perturb images on the fly:
我们还使用数据生成器进行预处理:我们对图像进行大小调整和归一化,以使其按照ResNet-50的喜好进行处理(224 x 224像素,具有缩放的颜色通道)。 最后但并非最不重要的一点是,我们使用数据生成器动态地随机扰动图像:
Performing such changes is called data augmentation. We’ll use it to show a neural network which kinds of transformations don’t matter. Or, to put it another way, we’ll train on a potentially infinite dataset by generating new images based on the original dataset.
执行此类更改称为数据增强 。 我们将使用它来显示神经网络,哪些转换无关紧要。 或者,换句话说,我们将通过基于原始数据集生成新图像来训练潜在的无限数据集。
Almost all visual tasks benefit, to varying degrees, from data augmentation for training. For more info about data augmentation, see as applied to plankton photos or how to use it in Keras. In our case, we randomly shear, zoom and horizontally flip our aliens and predators.
几乎所有的视觉任务都在不同程度上受益于训练的数据扩充。 有关数据增强的更多信息,请参阅应用于浮游生物照片或如何在Keras中使用它 。 在我们的案例中,我们随机剪切,缩放和水平翻转外星人和掠食者。
Here we create generators that:
在这里,我们创建生成器:
- load data from folders,从文件夹加载数据,
- normalize data (both train and validation), and标准化数据(训练和验证),以及
- augment data (train only).扩充数据(仅训练)。
In Keras, you get built-in augmentations and preprocess_input method normalizing images put to ResNet-50, but you have no control over their order. In PyTorch, you have to normalize images manually, but you can arrange augmentations in any way you like.
在Keras中,您可以使用内置的增强功能和preprocess_input方法来规范化ResNet-50上的图像,但无法控制它们的顺序。 在PyTorch中,您必须手动对图像进行规范化,但是您可以按照自己喜欢的任何方式安排增强。
There are also other nuances: for example, Keras by default fills the rest of the augmented image with the border pixels (as you can see in the picture above) whereas PyTorch leaves it black. Whenever one framework deals with your task much better than the other, take a closer look to see if they perform preprocessing identically; we bet they don’t.
还有其他细微差别:例如,默认情况下,Keras用边框像素填充其余的增强图像(如上图所示),而PyTorch将其保留为黑色。 每当一个框架比另一个框架更好地处理您的任务时,请仔细检查一下它们是否执行相同的预处理。 我们打赌他们不会。
3.创建网络 (3. Create the network)
The next step is to import a pre-trained ResNet-50 model, which is a breeze in both cases. We’ll freeze all the ResNet-50’s convolutional layers, and only train the last two fully connected (dense) layers. As our classification task has only 2 classes (compared to 1000 classes of ImageNet), we need to adjust the last layer.
下一步是导入经过预训练的ResNet-50模型,这两种情况都很容易。 我们将冻结所有ResNet-50的卷积层,只训练最后两个完全连接的(密集)层。 由于我们的分类任务只有2个类别(与ImageNet的1000个类别相比),我们需要调整最后一层。
Here we:
在这里,我们:
- load pre-trained network, cut off its head and freeze its weights,加载预先训练的网络,切断其头部并冻结其重量,
- add custom dense layers (we pick 128 neurons for the hidden layer), and添加自定义密集层(我们为隐藏层选择128个神经元),然后
- set the optimizer and loss function.设置优化器和损失函数。
We load the ResNet-50 from both Keras and PyTorch without any effort. They also offer many other well-known pre-trained architectures: see Keras’ model zoo and PyTorch’s model zoo. So, what are the differences?
我们毫不费力地从Keras和PyTorch加载ResNet-50。 他们还提供了许多其他知名预先训练的架构:看Keras'模型动物园和PyTorch模型动物园 。 那么,有什么区别呢?
In Keras we may import only the feature-extracting layers, without loading extraneous data (include_top=False). We then create a model in a functional way, using the base model’s inputs and outputs. Then we use model.compile(...) to bake into it the loss function, optimizer and other metrics.
在Keras中,我们可以仅导入要素提取图层,而不加载无关数据( include_top=False )。 然后,我们使用基本模型的输入和输出以实用的方式创建模型。 然后,我们使用model.compile(...)将损失函数,优化器和其他指标纳入其中。
In PyTorch, the model is a Python object. In the case of models.resnet50, dense layers are stored in model.fc attribute. We’ll overwrite them. The loss function and optimizers are separate objects. For the optimizer, we need to explicitly pass a list of parameters we want it to update.
在PyTorch中,模型是Python对象。 对于models.resnet50 ,密集层存储在model.fc属性中。 我们将覆盖它们。 损失函数和优化器是单独的对象。 对于优化器,我们需要显式传递要更新的参数列表。
In PyTorch, we should explicitly specify what we want to load to the GPU using .to(device) method. We have to write it each time we intend to put an object on the GPU, if available. Well…
在PyTorch中,我们应该使用.to(device)方法明确指定要加载到GPU的内容。 每次我们打算在GPU上放置对象(如果有)时,都必须编写它。 好…
Layer freezing works in a similar way. However, in The Batch Normalization layer of Keras is broken (as of the current version; thx Przemysław Pobrotyn for bringing this issue), you’ll see that some layers get modified anyway, even with trainable=False.
图层冻结的工作方式与此类似。 但是,在Keras 的Batch Normalization层已损坏 (从当前版本开始;请使用PrzemysławPobrotyn带来此问题),您会发现无论如何都修改了某些层,即使使用trainable=False 。
Keras and PyTorch deal with log-loss in a different way.
Keras和PyTorch以不同的方式处理对数损失。
In Keras, a network predicts probabilities (has a built-in softmax function), and its built-in cost functions assume they work with probabilities.
在Keras中,网络可预测概率(具有内置的softmax函数 ),而其内置的成本函数则假定它们与概率一起工作。
In PyTorch we have more freedom, but the preferred way is to return logits. This is done for numerical reasons, performing softmax then log-loss means doing unnecessary log(exp(x)) operations. So, instead of using softmax, we use LogSoftmax (and NLLLoss) or combine them into one nn.CrossEntropyLoss loss function.
在PyTorch中,我们拥有更大的自由度,但首选方式是返回logit。 出于数字原因执行此操作,先执行softmax,然后执行log-loss意味着执行不必要的log(exp(x))操作。 因此,我们不使用softmax,而是使用LogSoftmax (和NLLLoss )或将它们组合为一个nn.CrossEntropyLoss损失函数。
4.训练模型 (4. Train the model)
OK, ResNet is loaded, so let’s get ready to space rumble!
好的,ResNet已加载,所以让我们准备好隆隆声!
Now, we’ll proceed to the most important step — model training. We need to pass data, calculate the loss function and modify network weights accordingly. While we already had some differences between Keras and PyTorch in data augmentation, the length of code was similar. For training… the difference is massive. Let’s see how it works!
现在,我们将继续执行最重要的步骤-模型训练。 我们需要传递数据,计算损失函数并相应地修改网络权重。 尽管我们在数据扩充方面已经在Keras和PyTorch之间存在一些差异,但是代码的长度却是相似的。 对于培训……差异很大。 让我们看看它是如何工作的!
Here we:
在这里,我们:
- train the model, and训练模型,以及
- measure the loss function (log-loss) and accuracy for both training and validation sets.测量训练集和验证集的损失函数(对数损失)和准确性。
In Keras, the model.fit_generator performs the training… and that’s it! Training in Keras is just that convenient. And as you can find in the notebook, Keras also gives us a progress bar and a timing function for free. But if you want to do anything nonstandard, then the pain begins…
在model.fit_generator , model.fit_generator进行训练……就是这样! 在Keras进行培训就是那么方便。 正如您在笔记本中可以找到的那样,Keras还免费提供了进度条和计时功能。 但是,如果您想做任何非标准的事情,那么痛苦就开始了……
PyTorch is on the other pole. Everything is explicit here. You need more lines to construct the basic training, but you can freely change and customize all you want.
PyTorch在另一极。 一切在这里都是明确的。 您需要更多的代码来构建基础培训,但是您可以自由地更改和定制所有所需的内容。
Let’s shift gears and dissect the PyTorch training code. We have nested loops, iterating over:
让我们换档并剖析PyTorch培训代码。 我们有嵌套循环,遍历:
- epochs,时代,
- training and validation phases, and培训和验证阶段,以及
- batches.批次。
The epoch loop does nothing but repeat the code inside. The training and validation phases are done for three reasons:
epoch循环除了重复内部代码外什么都不做。 进行培训和验证阶段的原因有以下三个:
Some special layers, like batch normalization (present in ResNet-50) and dropout (absent in ResNet-50), work differently during training and validation. We set their behavior by
model.train()andmodel.eval(), respectively.一些特殊的层,如批处理规范化 (在ResNet-50中存在)和退出 (在ResNet-50中不存在),在训练和验证期间的工作方式有所不同。 我们分别通过
model.train()和model.eval()设置它们的行为。- We use different images for training and for validation, of course.当然,我们使用不同的图像进行训练和验证。
The most important and least surprising thing: we train the network during training only. The magic commands
optimizer.zero_grad(),loss.backward()andoptimizer.step()(in this order) do the job. If you know what backpropagation is, you appreciate their elegance.最重要和最令人惊讶的事情是:我们仅在训练期间训练网络。 魔术命令
optimizer.zero_grad(),loss.backward()和optimizer.step()(按此顺序)可以完成任务。 如果您知道什么是反向传播 ,则可以欣赏它们的优雅。
We then take care of computing the epoch losses and prints ourselves.
然后,我们负责计算历时损失并自行打印。
5.保存并加载模型 (5. Save and load the model)
保存 (Saving)
Once our network is trained, often with high computational and time costs, it’s good to keep it for later. Broadly, there are two types of savings:
一旦对我们的网络进行了培训(通常需要很高的计算和时间成本),最好将其保留下来。 广义上讲,有两种节省方式:
- saving the whole model architecture and trained weights (and the optimizer state) to a file, and将整个模型架构和经过训练的权重(以及优化器状态)保存到文件中,以及
- saving the trained weights to a file (keeping the model architecture in the code).将训练后的权重保存到文件中(在代码中保留模型架构)。
It’s up to you which way you choose.
选择哪种方式取决于您。
Here we:
在这里,我们:
- save the model.保存模型。
One line of code is enough in both frameworks. In Keras you can either save everything to a HDF5 file or save the weights to HDF5 and the architecture to a readable JSON file. By the way: you can then load the model and run it in the browser.
在两个框架中,一行代码就足够了。 在Keras中,您可以将所有内容保存到HDF5文件中,也可以将权重保存到HDF5中,并将体系结构保存到可读的JSON文件中。 顺便说一句: 然后可以加载模型并在浏览器中运行它 。
Currently, PyTorch creators recommend saving the weights only. They discourage saving the whole model because the API is still evolving.
目前,PyTorch创作者建议仅保存权重 。 他们不鼓励保存整个模型,因为API仍在不断发展。
载入中 (Loading)
Loading models is as simple as saving. You should just remember which saving method you chose and the file paths.
加载模型就像保存一样简单。 您应该只记住选择的保存方法和文件路径。
Here we:
在这里,我们:
- load the model.加载模型。
In Keras we can load a model from a JSON file, instead of creating it in Python (at least when we don’t use custom layers). This kind of serialization makes it convenient for transferring models.
在Keras中,我们可以从JSON文件加载模型,而不是在Python中创建模型(至少在我们不使用自定义图层时)。 这种序列化使您可以方便地传输模型。
PyTorch can use any Python code. So pretty much we have to re-create a model in Python.
PyTorch可以使用任何Python代码。 因此,我们几乎不得不在Python中重新创建模型。
Loading model weights is similar in both frameworks.
在两个框架中,加载模型权重都是相似的。
6.对样本测试图像进行预测 (6. Make predictions on sample test images)
All right, it’s finally time to make some predictions! To fairly check the quality of our solution, we’ll ask the model to predict the type of monsters from images not used for training. We can use the validation set, or any other image.
好的,现在是时候做些预测了! 为了公平地检查我们的解决方案的质量,我们将要求模型从不用于训练的图像中预测怪物的类型。 我们可以使用验证集或任何其他图像。
Here we:
在这里,我们:
- load and preprocess test images,加载并预处理测试图像,
- predict image categories, and预测图像类别,以及
- show images and predictions.显示图像和预测。
Prediction, like training, works in batches (here we use a batch of 3; though we could surely also use a batch of 1).
预测和训练一样,是按批次进行的(这里我们使用3的批次;尽管我们当然也可以使用1的批次)。
In both Keras and PyTorch we need to load and preprocess the data. A rookie mistake is to forget about the preprocessing step (including color scaling). It is likely to work, but will result in worse predictions (since it effectively sees the same shapes but with different colors and contrasts).
在Keras和PyTorch中,我们都需要加载和预处理数据。 一个菜鸟的错误是忘记了预处理步骤(包括颜色缩放)。 它可能会起作用,但会导致较差的预测(因为它实际上可以看到相同的形状,但是具有不同的颜色和对比度)。
In PyTorch there are two more steps, as we need to:
在PyTorch中,还有两个步骤,我们需要:
- convert logits to probabilities, and将logit转换为概率,以及
- transfer data to the CPU and convert to NumPy (fortunately, the error messages are fairly clear when we forget this step).将数据传输到CPU并转换为NumPy(幸运的是,当我们忘记此步骤时,错误消息非常清楚)。
And this is what we get:
这就是我们得到的:
It works!
有用!
And how about other images? If you can’t come up with anything (or anyone) else, try using photos of your co-workers. ?
那其他图像呢? 如果您无法提出其他建议(或其他任何建议),请尝试使用同事的照片。 ?
结论 (Conclusion)
As you can see, Keras and PyTorch differ significantly in terms of how standard deep learning models are defined, modified, trained, evaluated, and exported. For some parts it’s purely about different API conventions, while for others fundamental differences between levels of abstraction are involved.
如您所见,Keras和PyTorch在定义,修改,训练,评估和导出标准深度学习模型方面有很大不同。 对于某些部分,它纯粹是关于不同的API约定,而对于其他部分,则涉及抽象级别之间的根本差异。
Keras operates on a much higher level of abstraction. It is much more plug&play, and typically more succinct, but at the cost of flexibility.
Keras在更高的抽象水平上运行。 它具有更多的即插即用功能,并且通常更为简洁,但以灵活性为代价。
PyTorch provides more explicit and detailed code. In most cases it means debuggable and flexible code, with only small overhead. Yet, training is way-more verbose in PyTorch. It hurts, but at times provides a lot of flexibility.
PyTorch提供了更明确和详细的代码。 在大多数情况下,这意味着可调试且灵活的代码,而开销却很小。 但是,培训在PyTorch中更为冗长。 很痛,但有时会提供很大的灵活性。
Transfer learning is a big topic. Try tweaking your parameters (e.g. dense layers, optimizer, learning rate, augmentation) or choose a different network architecture.
转移学习是一个大话题。 尝试调整您的参数(例如,密集层,优化器,学习率,扩充)或选择其他网络架构。
Have you tried transfer learning for image recognition? Consider the list below for some inspiration:
您是否尝试过转移学习进行图像识别? 考虑以下列表以获取一些启发:
Chihuahua vs. muffin, sheepdog vs. mop, shrew vs. kiwi (already serves as an interesting benchmark for computer vision)
吉娃娃与松饼,牧羊犬与拖把,泼妇与猕猴桃 (已经成为计算机视觉的有趣基准 )
- Original images vs. photoshopped ones原始图像与Photoshop图像
- Artichoke vs. broccoli vs. cauliflower朝鲜蓟vs.西兰花vs.菜花
- Zerg vs. Protoss vs. Orc vs. Elf虫族,神族,兽人,精灵
- Meme or not meme模因与否
Is it a picture of a bird?
它是鸟的照片吗?
Is it huggable?
可以拥抱吗?
Pick Keras or PyTorch, choose a dataset, and let us know how it went in the comments section below ?
选择Keras或PyTorch,选择一个数据集,然后在下面的评论部分让我们知道它如何进行?
By the way, in November we are running a series of hands-on training where you can learn more about Keras and PyTorch. Piotr Migdał and I will lead some of the sessions so feel free to check it out.
顺便说一句,在11月,我们将进行一系列的动手培训 ,在这里您可以了解有关Keras和PyTorch的更多信息。 PiotrMigdał和我将主持一些会议,请随时查看。
翻译自: https://www.freecodecamp.org/news/keras-vs-pytorch-avp-transfer-learning-c8b852c31f02/
pytorch与keras
相关文章:

Ubuntu 16.04安装QQ(不一定成功)
注意1:如果是刚新装的系统,可以正常安装,但是,如果你已经装了很多软件,千万不要安装,因为会把系统上一般的依赖包和你之前装的软件全部卸载掉!甚至将桌面Dock都会卸载!最终只能重装U…

for循环动态的给select标签添加option内容
微信小程序开发交流qq群 173683895 承接微信小程序开发。扫码加微信。 html <select class"form-control selectpicker" name"college" id"eq_num" data-actions-box"true" data-live-search"true" data-live-sea…
Linux下Debug模式启动Tomcat进行远程调试
J2EE开发各类资源下载清单, 史上最全IT资源,点击进入! 一. 应用场景 在实际的测试过程中,可能会遇到由于程序执行的不间断性,我们无法构造测试场景来验证某个功能的正确性,只有通过代码级的调试才能验…
guice google_与Google Guice的动手实践
guice googleby Sankalp Bhatia通过Sankalp Bhatia 与Google Guice的动手实践 (A hands-on session with Google Guice) A few months ago, I wrote an article explaining dependency injection. I had mentioned of a follow-up article with a hands-on session of Google …
IQKeyboardManager使用方法
使用方法:将IQKeyboardManager 和 IQSegmentedNextPrevious类文件加进项目中。在AppDelegate文件中写下以下一行代码: [IQKeyBoardManager installKeyboardManager]; 搞定! 也可以开启或者关闭keyboard avoiding功能: [IQKeyBoard…
JQ加AJAX 加PHP实现网页登录功能
微信小程序开发交流qq群 173683895 承接微信小程序开发。扫码加微信。 前端代码 <!DOCTYPE HTML> <html><head><link href"css/style.css" rel"stylesheet" type"text/css" media"all" /><meta http-eq…
web安全简介_Web安全:HTTP简介
web安全简介by Alex Nadalin通过亚历克斯纳达林 Web安全:HTTP简介 (Web Security: an introduction to HTTP) This is part 2 of a series on web security: part 1 was “Understanding The Browser”这是有关网络安全的系列文章的第2部分:第1部分是“…

继承实现的原理、子类中调用父类的方法、封装
一、继承实现的原来 1、继承顺序 Python的类可以继承多个类。继承多个类的时候,其属性的寻找的方法有两种,分别是深度优先和广度优先。 如下的结构,新式类和经典类的属性查找顺序都一致。顺序为D--->A--->E--->B--->C。 class E:…
hdu 5366 简单递推
记f[i]为在长度是i的格子上面至少放一个木桩的方法数。考虑第i个格子,有放和不放两种情况。 1.如果第i个格子放了一个木桩,则i - 1和i - 2格子上面不能放木桩,方案数为:f[i - 3] 1 2.如果第i个格子没有放木桩,则方案数…
git 代理 git_如何不再害怕GIT
git 代理 git了解减少不确定性的机制 (Understanding the machinery to whittle away the uncertainty) 到底什么是Git? (What is Git anyway?) “It’s a version control system.”“这是一个版本控制系统。” 我为什么需要它? (Why do I need it?)…

Python 基础 - Day 2 Assignment - ShoppingCart 购物车程序
作业要求 1、启动程序后,输入用户名密码后,如果是第一次登录,让用户输入工资,然后打印商品列表 2、允许用户根据商品编号购买商品 3、用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒 4…
hdu 1878 欧拉回路
欧拉回路 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submission(s): 10548 Accepted Submission(s): 3849 Problem Description欧拉回路是指不令笔离开纸面,可画过图中每条边仅一次,且可以回到起点…
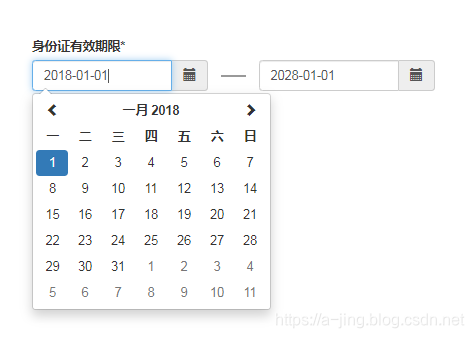
bootstrap 时间日期日历控件(datetimepicker)附效果图
开发交流QQ群: 173683895 173683895 526474645 人满的请加其它群 效果图 代码 <!DOCTYPE html> <html><head><meta charset"UTF-8"><link href"https://cdn.bootcss.com/bootstrap/3.3.7/css/bootstrap.min.css" rel&q…
如何在您HTML中嵌入视频和音频
by Abhishek Jakhar通过阿比舍克贾卡(Abhishek Jakhar) 如何在您HTML中嵌入视频和音频 (How to embed video and audio in your HTML) HTML allows us to create standards-based video and audio players that don’t require the use of any plugins. Adding video and audi…

html 省份,城市 选择器附效果图
开发交流QQ群: 173683895 173683895 526474645 人满的请加其它群 效果图: 源码: <!DOCTYPE html> <html><head><meta charset"UTF-8"><link href"https://cdn.bootcss.com/bootstrap/3.3.7/css/boots…
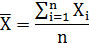
机器学习:协方差矩阵
一、统计学的基本概念 统计学里最基本的概念就是样本的均值、方差、标准差。首先,我们给定一个含有n个样本的集合,下面给出这些概念的公式描述: 均值: 标准差: 方差: 均值描述的是样本集合的中间点…
TemplatedParent 与 TemplateBinding
http://blog.csdn.net/idebian/article/details/8761388转载于:https://www.cnblogs.com/changbaishan/p/4716414.html
避免成为垃圾邮件_如何避免犯垃圾
避免成为垃圾邮件by Yoel Zeldes由Yoel Zeldes 如何避免犯垃圾 (How to avoid committing junk) In the development process, every developer writes stuff they don’t intend to commit and push to the remote server, things like debug prints. It happens to all of u…
[bzoj2333] [SCOI2011]棘手的操作 (可并堆)
//以后为了凑字数还是把题面搬上来吧2333 发布时间果然各种应景。。。 Time Limit: 10 Sec Memory Limit: 128 MB Description 有N个节点,标号从1到N,这N个节点一开始相互不连通。第i个节点的初始权值为a[i],接下来有如下一些操作࿱…
vue.js created函数注意事项
因为created钩子函数是页面一加载完就会调用的函数,所以如果你想在这个组件拿值或者是赋值,很可能this里面能拿到数据,但是如果你用this.赋值的话,控制台或者debugger都会发现this里面有你所想要的数据,但是赋值后就是…
JS删除城市的后缀
开发交流QQ群: 173683895 173683895 526474645 人满的请加其它群 代码 const deleteStr str >{if (str.indexOf("市") ! -1 || str.indexOf("州") ! -1){str str.substring(0, str.length - 1)console.log(删除城市的最后一个字,str)return s…
gatsby_将您的GraphCMS数据导入Gatsby
gatsbyLets set up Gatsby to pull data from GraphCMS.让我们设置Gatsby来从GraphCMS中提取数据。 This will be a walk-through of setting up some basic data on the headless CMS, GraphCMS and then querying that data in Gatsby.这将是在无头CMS,GraphCMS上…
Java学习笔记07--日期操作类
一、Date类 在java.util包中定义了Date类,Date类本身使用非常简单,直接输出其实例化对象即可。 public class T { public static void main(String[] args) { Date date new Date(); System.out.println("当前日期:"date); //当前…
javascript数组集锦
设计数组的函数方法 toString, toLocaleString, valueOf, concat, splice, slice indexOf,lastIndexOf, push, pop, shift, unshift, sort, reverse map, reduce, reduceRight, filter, every, some, forEach 创建数组 数组字面量创建:var arr [val1, val2, val3];…
JS实现HTML标签转义及反转义
开发交流QQ群: 173683895 173683895 526474645 人满的请加其它群 编码反编码 function html_encode(str) { var s ""; if (str.length 0) return ""; s str.replace(/&/g, "&"); s s.replace(/</g, "<")…
喜欢把代码写一行的人_我最喜欢的代码行
喜欢把代码写一行的人Every developer has their favourite patterns, functions or bits of code. This is mine and I use it every day.每个开发人员都有自己喜欢的模式,功能或代码位。 这是我的,我每天都用。 它是什么? (What is it?) …
智能家居APP开发
智能家居APP开发 APP开发技术qq交流群:347072638 前言,随着智能硬件设备的流行,智能家居開始红火,智能家居就是家用电器的智能化。包含智能锁,灯,空调,灯,音箱等等,移动设…

android小技巧(二)
一、如何控制Android LED等?(设置NotificationManager的一些参数) 代码如下: final int ID_LED19871103; NotificationManager nm(NotificationManager)getSystemService(NOTIFICATION_SERVICE); Notification notification new Notification(); notificatio…

JS 验证表单不能为空
开发交流QQ群: 173683895 173683895 526474645 人满的请加其它群 JS 验证表单不能为空的简单demo,先看效果图 实现代码 <!--index.wxml--> <form classform bindsubmitformSubmit bindresetformReset><input namename value{{name}} placeho…
周末不用过来了,好好休息吧_如何好好休息
周末不用过来了,好好休息吧When I wrote about my productive routine in a previous article, I said I’d work for 1.5 hours and take a break for 30 minutes. And I’d repeat this sequence four times a day.当我在上一篇文章中谈到生产性例程时,…