聊天软交互原理_来自不同城市的人们如何在freeCodeCamp聊天室中进行交互
聊天软交互原理
by Déborah Mesquita
由DéborahMesquita
来自不同城市的人们如何在freeCodeCamp聊天室中进行交互 (How people from different cities interact in the freeCodeCamp chatrooms)
推理统计入门以及如何使用spaCy从文本中提取信息 (A primer on Inferential statistics and how to extract information from text using spaCy)
In Data Science we usually talk a lot about Exploratory Data Analysis (Descriptive Statistics), but there is another “statistical world” that can also be very useful: the world of Inferential Statistics.
在数据科学中,我们通常谈论探索性数据分析 (描述性统计),但是还有另一个“统计世界”也可能非常有用: 推论统计 。
Inferential statistical analysis infers properties of a population, for example by testing hypotheses and deriving estimates. Descriptive statistics is solely concerned with properties of the observed data, and it does not rest on the assumption that the data come from a larger population. — Statistical Inference
推论统计分析可推断人口的属性,例如,通过检验假设并推导出估计。 描述性统计数据仅与观察到的数据的属性有关,并不基于数据来自更大的总体这一假设。 — 统计推断
In this article we’ll use the gitter-history dataset from freeCodeCamp open data to answer this question: is there a different mention pattern in the chat-rooms from different cities?
在本文中,我们将使用来自freeCodeCamp开放数据的gitter-history数据集来回答此问题: 来自不同城市的聊天室中是否存在不同的提及模式?
We’ll learn about inferential statistics and also learn how to extract information from text using the Matcher class from spaCy. First let’s extract the data, then we’ll get our hands dirty with statistics (hey, it’s fun! you’ll see).
我们将学习推论统计,还将学习如何使用spaCy的Matcher类从文本中提取信息。 首先,让我们提取数据,然后使用统计数据来处理问题(嘿,这很有趣!您会看到的)。
使用spacy.Matcher提取信息 (Extracting information with spacy.Matcher)
The way we use the Matcher is very similar to the way we use regular expressions (in fact we can use regex to create patterns). Each rule can have many patterns, and a pattern consists of a list of dicts, where each dict describes a token.
我们使用Matcher的方式与我们使用正则表达式的方式非常相似(实际上,我们可以使用正则表达式来创建模式)。 每个规则可以具有许多模式,并且一个模式由一系列字典组成,其中每个字典描述一个标记。
// this pattern matches all tokens == 'hello' (lowercase){'LOWER': 'hello'}Let’s create some examples of things we can extract from the messages.
让我们创建一些我们可以从消息中提取的内容的示例。
问候 (Greetings)
Here we have 4 patterns for the same rule ("GREETINGS"):
在这里,我们为相同的规则提供了4种模式( "GREETINGS" ):
matcher = Matcher(nlp.vocab)self.matcher.add("GREETINGS", None, [{"LOWER": "good"}, {"LOWER": "morning"}], [{"LOWER": "good"}, {"LOWER": "evening"}], [{"LOWER": "good"}, {"LOWER": "afternoon"}], [{"LOWER": "good"}, {"LOWER": "night"}])matches = matcher(text)标点符号的邮件 (Messages with punctuation)
We can use all the available token attributes as patterns. Let’s see if a message has a punctuation token.
我们可以将所有可用的令牌属性用作模式。 让我们看看消息中是否包含标点符号。
matcher = Matcher(nlp.vocab)self.matcher.add("PUNCT", None, [{"IS_PUNCT": True}])matches = matcher(text)人们的感觉如何? (What are people feeling?)
Here things get a little more interesting. We’ll match the lemma of the verb be to detect all the conjugations of the verb. The matcher also lets you use quantifiers, specified as the 'OP' key. We’ll match all the adverb tokens after the verb be (with 'OP': '*' we can match any and all of them).
在这里,事情变得更加有趣。 我们将匹配动词be的引理 ,以检测该动词的所有词缀。 匹配器还允许您使用指定为'OP'键的量词。 我们将在动词be之后匹配所有副词标记(使用'OP': '*'我们可以匹配所有它们)。
After that there is a lot of possibility for the two following words, so we’ll use the wildcard token {} to match them.
之后,后面的两个词很有可能,因此我们将使用通配符{}进行匹配。
matcher = Matcher(nlp.vocab)self.matcher.add("FEELING", None, [ {"LOWER": "i"}, {"LEMMA":"be"}, {"POS": "ADV", "OP": "*"}, {"POS": "ADJ"} ])matches = matcher(text)提及 (Mentions)
There is not a token attribute to @some_token, so let’s create one.
@some_token没有令牌属性,因此让我们创建一个。
mention_flag = lambda text: bool(re.compile(r'\@(\w+)').match(text))IS_MENTION = nlp.vocab.add_flag(mention_flag)self.matcher.add("MENTION", None, [{IS_MENTION: True}])matches = matcher(text)I built a dataset with mentions for the rest of the article.
在本文的其余部分,我用提及建立了一个数据集。
[menssage, mention, sent_at, city]You can find all the code here.
您可以在此处找到所有代码。
推论统计入门 (A primer on Inferential statistics)
Statistical inference is the process of using data analysis to deduce properties of an underlying probability distribution (Statistical inference).
统计推断是使用数据分析来推断潜在概率分布的属性的过程( 统计推断 )。
We have samples and we want to compare them. With Test Statistic we can measure the probability of they coming from the same distribution or not. Applying this to our scenario, if the probability of the mentions coming from the same distribution is below a threshold (defined by us) then we’ll be able to infer that people from different cities have different mention patterns.
我们有样本,我们想比较它们。 通过测试统计,我们可以衡量它们是否来自相同分布的可能性 。 将其应用于我们的情况, 如果来自同一分布的提及的可能性低于阈值 (由我们定义),那么我们将能够推断出来自不同城市的人们具有不同的提及模式 。
Let’s define some concepts to clarify things (all the definitions are taken from Wikipedia):
让我们定义一些概念来澄清事物(所有定义均来自Wikipedia):
Frequency distribution: a list, table or graph that displays the frequency of various outcomes in a sample
频率分布 :列表,表格或图表,显示样本中各种结果的频率
Null hypothesis: a general statement or default position that there is no relationship between two measured phenomena, or no association among groups
零假设 :一般的陈述或默认位置,即两个测得的现象之间没有关系 ,或者组之间没有关联
p-value: the probability, when the null hypothesis is true, of obtaining a result equal to or more extreme than what was actually observed. The smaller the p-value, the higher the significance because it tells the investigator that the hypothesis under consideration may not adequately explain the observation
p值 :当零假设成立时,获得等于或大于实际观察到的结果的可能性。 p值越小,意义越高,因为它告诉研究者所考虑的假设可能不足以解释观察结果。
Statistical significance: something is statistically significant if it allows us to reject the null hypothesis
统计显着性 :如果某种事物允许我们拒绝原假设,那么它在统计上是有意义的
One thing to keep in mind while dealing with statistical hypothesis tests is that it goes like this:
在处理统计假设检验时要记住的一件事是,它像这样:
- We assume something is true我们假设某事是真的
- Then we try to prove that it’s impossible that it can be true然后我们尝试证明不可能是真的
- Then when we see that indeed, this probably can’t be true for the results we got, we reject the claim然后,当我们看到确实如此时,对于我们得到的结果可能就不正确了,我们拒绝了该主张。
“Null hypothesis testing is a reductio ad absurdum argument adapted to statistics. In essence, a claim is assumed valid if its counter-claim is improbable”. — P-value
“ 零假设检验是一种适用于统计的还原性荒谬论据。 从本质上讲,如果反请求是不可能的,则认为该请求有效 。 — P值
In our case we are dealing with categorical variables (a variable that can take on one of a limited, and usually fixed number of possible values). Because of that, we’ll use the Chi-squared distribution.
在我们的案例中,我们正在处理分类变量(可以采用有限且通常为固定数量的可能值之一的变量)。 因此,我们将使用卡方分布。
In probability theory and statistics, the chi-squared distribution (also chi-square or χ2-distribution) with k degrees of freedom is the distribution of a sum of the squares of k independent standard normal random variables. It’s one of the most widely used probability distributions in inferential statistics, notably in hypothesis testing or in construction of confidence intervals. — Chi-squared distribution
在概率论和统计学中,具有k个自由度的卡方分布 (也称为卡方或χ2分布 )是k个独立标准正态随机变量的平方和的分布。 它是推论统计中使用最广泛的概率分布之一,特别是在假设检验或构造置信区间中。 — 卡方分布
“Statisticians have identified several common distributions, known as probability distributions. From these distributions it is possible to calculate the probability of getting particular scores based on the frequencies with which a particular score occurs in a distribution with these common shapes.” — Discovering Statistics Using R
统计人员确定了几种常见的分布,称为概率分布。 从这些分布中,可以根据具有这些共同形状的分布中特定分数出现的频率,计算获得特定分数的概率。” — 使用R查找统计信息
了解卡方检验的同质性 (Understanding the chi-square test for homogeneity)
We want to know if the mention distribution is the same for each city. First we assume that they indeed come from the same population, then we get all the messages from each city and sum them up. This distribution (all the messages together) should be the same for each city if we assume they come from the same population.
我们想知道每个城市的提及分布是否相同。 首先,我们假设它们确实来自同一人口,然后我们从每个城市获取所有消息并进行汇总。 如果我们假设每个城市都来自同一人口,则每个城市的分布(所有消息加在一起)应该相同。
We cannot prove that the distributions are different using statistics, but we can reject that they are the same.
我们不能使用统计数据证明分布是不同的,但是我们可以拒绝它们是相同的 。
“The reason that we need the null hypothesis is because we cannot prove the experimental hypothesis using statistics, but we can reject the null hypothesis. If our data give us confidence to reject the null hypothesis then this provides support for our experimental hypothesis. However, be aware that even if we can reject the null hypothesis, this doesn’t prove the experimental hypothesis — it merely supports it.” — Discovering Statistics Using R
“我们需要原假设的原因是因为我们无法使用统计数据证明实验假设,但是我们可以拒绝原假设。 如果我们的数据使我们有信心拒绝原假设,那么这为我们的实验假设提供了支持。 但是,请注意,即使我们可以拒绝原假设, 也不能证明实验假设-它只是支持该假设。 ” — 使用R发现统计信息
This is very important. We are not proving that the experimental (or alternative) hypothesis is true. We are saying that at a given significance level it’s likely that it’s true.
这个非常重要。 我们没有证明实验(或替代)假设是正确的。 我们说的是, 在给定的重要性水平下,这很可能是真的 。
“So, rather than talking about accepting or rejecting a hypothesis (which some textbooks tell you to do) we should be talking about ‘the chances of obtaining the data we’ve collected assuming that the null hypothesis is true’.” — Discovering Statistics Using R
“因此,与其说接受或拒绝一个假设(有些教科书告诉你这样做),不如说是'假设零假设是真实的,'获得我们收集的数据的机会'。” — 使用R查找统计信息
In essence, when we collect data to test theories we can only talk in terms of the probability of obtaining a particular set of data (Field, Andy). And to judge that we use the p-values.
本质上,当我们收集数据以检验理论时,我们只能谈论获得特定数据集(Field,Andy) 的可能性 。 并判断我们使用p值。
High p-values: your data are likely with a true null
高p值 :您的数据可能为true
Low p-values: your data are unlikely with a true null, (How to Correctly Interpret P Values)
低p值 :您的数据不太可能带有真正的null,( 如何正确解释P值 )
We’ll set our significance level to 5% (p-value threshold of 0.05).
我们将显着性水平设置为5%( p值阈值为0.05)。
Ok, now back to the test.
好的,现在返回测试。
数据 (The data)
We’ll use the dataset of all chat activity in freeCodeCamp’s Gitter chatrooms. This dataset can be found here.
我们将在freeCodeCamp的Gitter聊天室中使用所有聊天活动的数据集。 该数据集可在此处找到。
Our sample has all messages from the San Francisco, Toronto, Boston, Belgrade, London and Sao Paulo sent between 2015–08–16 and 2016–08–16 (one year of messages).
我们的样本包含2015年8月16日至2016年8月16日之间从旧金山,多伦多,波士顿,贝尔格莱德,伦敦和圣保罗发送的所有邮件(一年的邮件)。
进行卡方检验同质性的条件 (Conditions for conducting the chi-square test for homogeneity)
To use the chi-square test we need to meet some conditions:
要使用卡方检验,我们需要满足一些条件:
- For each population, the sampling method is simple random sampling对于每个人口,抽样方法都是简单的随机抽样
- All of the expected counts are 5 or greater所有预期计数均为5或更大
We’ll assume the first condition is met (1 year of data from each city). Let’s find out if the second condition is met.
我们假设满足第一个条件(每个城市的一年数据)。 让我们找出是否满足第二个条件。
探索数据 (Exploring the data)
Since we are sipping at the waters of statistics let’s use R instead of Python.
由于我们在统计领域statistics之以鼻,因此我们使用R代替Python。
I created a JSON file and we’ll load it into a dataframe using the jsonlite library. To see the contents we’ll use the tally function.
我创建了一个JSON文件,我们将使用jsonlite库将其加载到数据帧中。 要查看内容,我们将使用提示功能。
> library(jsonlite)> df <- fromJSON("experiment_sample_data.json")> library(mosaic)> mentiontable <- tally(~city+mention, data=df, margins=T)> mentiontable mentioncity NO YES Belgrade 184 45 Boston 383 121 London 278 98 SanFrancisco 156 51 SaoPaulo 153 132 Toronto 379 81Now is the time to introduce the contingency tables.
现在该介绍列联表。
Contingency tables: in statistics, a contingency table (also known as a cross tabulation or crosstab) is a type of table in a matrix format that displays the (multivariate) frequency distribution of the variables.
列联表 :列联表在统计数据中(也称为交叉表或交叉表)是以矩阵格式显示变量的(多变量)频率分布的一种表。
With chisq.test we can perform chi-squared contingency table tests and goodness-of-fit tests. Let’s calculate the expected counts for this sample.
使用chisq.test我们可以执行卡方列联表测试和拟合优度测试。 让我们计算该样本的预期计数。
Expected outcome = (sum of data in that row)×(sum of data in that column) / total data.
预期结果=(该行中数据的总和)×(该列中数据的总和)/总数据。
So the expected number of messages with mentions (mention=YES) for the city of Sao Paulo is:
因此,对于圣保罗市,带有提及(mention = YES)的消息的预期数量为:
285*407/1557 = 74,49903
285 * 407/1557 = 74,49903
The expected value of chisq.test gives the expected counts under the null hypothesis for all the cities:
该expected值chisq.test给出了零假设所有的城市下的预期计数:
> chisq.test(mentiontable)$expected mentioncity NO YES Belgrade 170.3333 58.66667 Boston 374.8821 129.11790 London 279.6739 96.32606 SanFrancisco 153.9694 53.03057 SaoPaulo 211.9869 73.01310 Toronto 342.1543 117.84571The expected counts are all greater than 5, so we can perform the test.
预期计数均大于5,因此我们可以执行测试。
执行卡方检验 (Performing the chi-square test)
We’ll assume the distributions are the same, so the total column is the best estimate of what this distribution should be:
我们假设分布是相同的,因此total列是对该分布应为最佳的估计:
> tally(~mention, data=df)mention NO YES 1150 407The chi-squared test is used to determine whether there is a significant difference between the expected frequencies and the observed frequencies.
卡方检验用于确定预期频率和观测频率之间是否存在显着差异。
For each cell, the expected frequency is subtracted from the observed frequency, the difference is squared, and the total is divided by the expected frequency. The values are then summed across all cells. This sum is the chi-square test statistic — The chi-square test
对于每个单元, 从观察到的频率中减去期望频率,对差值进行平方,然后将总数除以期望频率 。 然后将所有单元格的值相加。 该和是卡方检验统计量— 卡方检验
With the value from the chi-square test and with the value for the degrees of freedom (number_if_rows -1 × number_of_columns -1) we can calculate the probability of getting the results by chance or not.
使用卡方检验的值和自由度的值(number_if_rows -1×number_of_columns -1),我们可以计算是否偶然获得结果的概率。
> chisq.test(mentiontable) Pearson's Chi-squared testdata: mentiontableX-squared = 84.667, df = 5, p-value < 2.2e-16The p-value is lower than the alpha value (0.05), so we will reject the null hypothesis. This means that with these results for each city, it is unlikely that all the cities have the same distribution of mentions.
p值低于alpha值(0.05),因此我们将拒绝原假设 。 这意味着,根据每个城市的这些结果,不太可能所有城市都具有相同的提及分布。
We can also examine the source of differences of the test.
我们还可以检查差异的来源。
检查残差作为差异来源 (Examining residuals for the source of differences)
We have the expected values for each city, so it’s possible to see the residuals: (observed - expected) / sqrt(expected)
我们具有每个城市的期望值,因此可以看到残差:( (observed - expected) / sqrt(expected)
The standardized residual, provides a measure of deviation of the observed from expected which retains the direction of deviation (whether observed was more or less than expected is interesting for interpretations) for each cell in the table. It is scaled much like a standard normal distribution providing a scale for “large” deviations for absolute values that are over 2 or 3. — Intermediate Statistics with R
标准化残差提供了观测值与预期值之间的偏差的量度,该值保留了表中每个单元格的偏差方向(对于解释而言,观测到的值是大于还是小于预期是有意义的)。 它的缩放比例很像标准正态分布,为大于2或3的绝对值提供了“大”偏差的标度。—带R的中间统计量
mosaicplot(mentiontable, shade=T)For São Paulo and Toronto the number of messages with mention and NO mention appear to be more than 2.4 standard deviations away from the expected values. The São Paulo chat-room has more people mentioning other people than expected, and for Toronto there are less people mentioning other people than expected.
对于圣保罗和多伦多,带有提及和未提及消息的数量似乎比预期值多2.4个标准差。 圣保罗聊天室有更多的人提其他人于预期,多伦多也有少人提及其他人超过预期。
That’s interesting. A next step would be to explore the sources of these differences. Maybe it’s because of the number of people in each chat-room? Or maybe they already know each other, so they have more one on one conversations?
那很有意思。 下一步将是探索这些差异的根源。 也许是因为每个聊天室中的人数? 也许他们已经彼此认识,所以他们有更多的一对一对话?
结论 (In conclusion)
In Inferential Statistics we deduce properties of an underlying probability distribution. When you have a categorical variable you can use the chi-square test to find the probability of the distribution being the same for two or more populations (or subgroups of a population).
在推论统计中,我们推导了潜在概率分布的属性。 如果具有分类变量,则可以使用卡方检验来发现两个或多个总体(或总体的子组)的分布概率相同。
And the steps to use a statistical hypothesis test are:
使用统计假设检验的步骤是:
- First assume the null hypothesis is true首先假设原假设为真
- Then try to prove that it’s impossible that it can be true然后尝试证明不可能是真的
- Then if we see that indeed, this probably can’t be true for the results we got, we reject the null hypothesis (or otherwise we fail to reject and accept that the data supports the experimental hypothesis)然后,如果我们发现确实如此,那么对于我们得到的结果可能就不正确了,我们将拒绝原假设(否则,我们将无法拒绝并接受数据支持实验假设)
Besides that, we also saw that Spacy.Matcher is a great way to extract information from text. Here we did the experiment with mentions from each message but the code has other extracted patterns we could explore.
除此之外,我们还看到Spacy.Matcher是从文本中提取信息的好方法。 在这里,我们通过对每条消息的提及进行了实验,但是代码中还有我们可以探索的其他提取模式。
And that’s it! Thanks for reading!
就是这样! 谢谢阅读!
翻译自: https://www.freecodecamp.org/news/how-people-from-different-cities-interact-in-the-freecodecamp-chatrooms-a22378571790/
聊天软交互原理
相关文章:

使用微信的JS-SDK实现自定义分享到微信朋友圈
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 实现代码 <!DOCTYPE html> <html><head><meta name"viewport" content"widthdevice-width, initial-scale1.0, user-scalableno, minimum-scale1.0, …

[Unity3D]Unity3D连衣裙实现游戏开发系统
大家好,我是秦培。欢迎关注我的博客,我的博客地址blog.csdn.net/qinyuanpei。 不知从什么时候開始,国产RPG单机游戏開始出现换装,仙剑系列中第一部实现了换装的游戏是仙剑奇侠传四,后来原上海软星团队。眼下的烛龙科技…
python中nlp的库_单词袋简介以及如何在Python for NLP中对其进行编码
python中nlp的库by Praveen Dubey通过Praveen Dubey 单词词汇入门以及如何在Python中为NLP 编写代码的简介 (An introduction to Bag of Words and how to code it in Python for NLP) Bag of Words (BOW) is a method to extract features from text documents. These featur…
机器学习:计算学习理论
计算学习理论介绍 关键词: 鲁棒性 关键词: 【机器学习基础】理解为什么机器可以学习1——PAC学习模型--简书 关键词:存在必要性;从机器学习角度出发 PAC学习理论:机器学习那些事 关键词:不错的大道理 如果相…

HTML超出部分滚动效果 HTML滚动 HTML下拉 附效果图
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 H5 效果图 实现代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title>Bootstrap 实例 - 滚动监听(Scrollspy)…
编写高质量代码改善C#程序的157个建议——建议148:不重复代码
建议148:不重复代码 如果发现重复的代码,则意味着我们需要整顿一下,在继续前进。 重复的代码让我们的软件行为不一致。举例来说,如果存在两处相同的加密代码。结果在某一天,我们发现加密代码有个小Bug,然后…
求职者提问的问题面试官不会_如何通过三个简单的问题就不会陷入求职困境
求职者提问的问题面试官不会by DJ Chung由DJ Chung 如何通过三个简单的问题就不会陷入求职困境 (How to get un-stuck in your job search with three simple questions) 您甚至不知道为什么会被卡住? (Do you even know why you’re stuck?) Your job search can…
不能交换到解决jenkins用户的问题
su - jenkins始终有效,今centos无效,因为/etc/password在文档/bin/bash是yum当安装到/bin/false.之后可以改变。ubuntu安装包和yum安装包的行为不一致啊。版权声明:本文博主原创文章,博客,未经同意,不得转载…

HTML引用公共组件
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 在test.html引用footer.html 效果图 代码 test.html <!DOCTYPE html> <html><head><meta charset"utf-8"><title>引用demo</title><s…
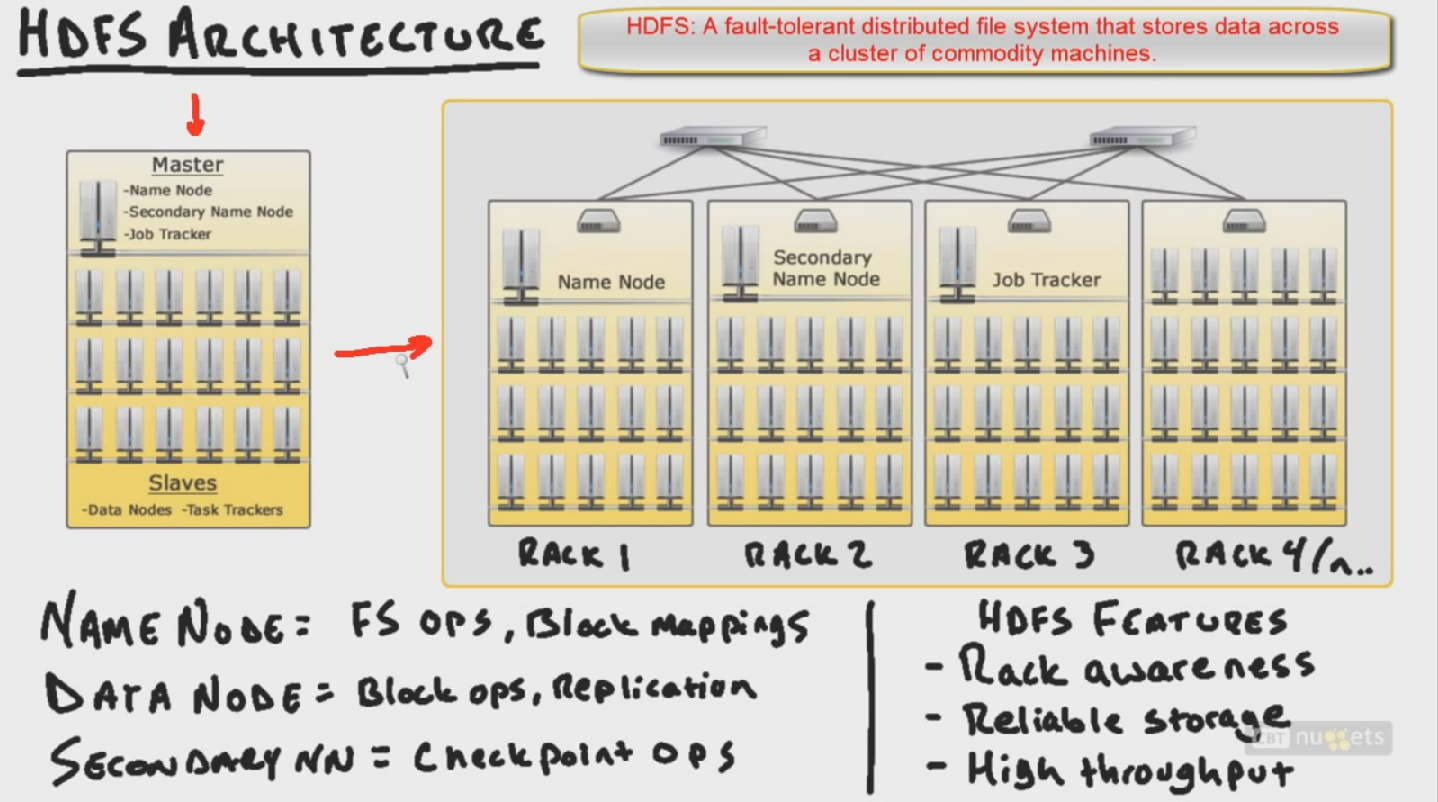
Hadoop自学笔记(二)HDFS简单介绍
1. HDFS Architecture 一种Master-Slave结构。包括Name Node, Secondary Name Node,Data Node Job Tracker, Task Tracker。JobTrackers: 控制全部的Task Trackers 。这两个Tracker将会在MapReduce课程里面具体介绍。以下具体说明HDFS的结构及其功能。 Name Node:控制全部的Dat…
如何为Linux设置Docker和Windows子系统:爱情故事。 ?
Do you sometimes feel you’re a beautiful princess turned by an evil wizard into a frog? Like you don’t belong? I do. I’m a UNIX guy scared to leave the cozy command line. My terminal is my castle. But there are times when I’m forced to use Microsoft …
再谈Spring Boot中的乱码和编码问题
编码算不上一个大问题,即使你什么都不管,也有很大的可能你不会遇到任何问题,因为大部分框架都有默认的编码配置,有很多是UTF-8,那么遇到中文乱码的机会很低,所以很多人也忽视了。 Spring系列产品大量运用在…

UDP 构建p2p打洞过程的实现原理(持续更新)
UDP 构建p2p打洞过程的实现原理(持续更新) 发表于7个月前(2015-01-19 10:55) 阅读(433) | 评论(0) 8人收藏此文章, 我要收藏赞08月22日珠海 OSC 源创会正在报名,送机械键盘和开源无码内裤 摘要 UDP 构建p2p打洞过程…
Vue父组件网络请求回数据后再给子组件传值demo示例
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 这里demo使用延迟执行模拟网络请求;父组件给子组件需要使用自定义属性 Prop ,下面是示例代码: <!DOCTYPE html> <html> <head> <me…
gulp-sass_如果您是初学者,如何使用命令行设置Gulp-sass
gulp-sassby Simeon Bello通过Simeon Bello I intern at a tech firm presently, and few days ago I got a challenge from my boss about writing an article. So I decided to write something on Gulp-sass. Setting it up can be frustrating sometimes, especially when…
MyEclipse快捷键
MyEclipse快捷键 Ctrl1 快速修复CtrlD: 删除当前行 CtrlQ 定位到最后编辑的地方 CtrlL 定位在某行 CtrlO 快速显示 OutLine CtrlT 快速显示当前类的继承结构 CtrlW 关闭当前Editer CtrlK 快速定位到下一个 CtrlE 快速显示当前Editer的下拉列表CtrlJ 正向增量查找(按下C…

关于UNION和UNION ALL的区别
今天在运行程序的时候发现个问题,就是计算和的时候两条数据一样的话自动去除重复的,可是我这个程序需要重复的数据也算进来呀,然后就找原因,最后在sql语句中找到了是union和union all的问题,简单总结一下下。 当使用到…
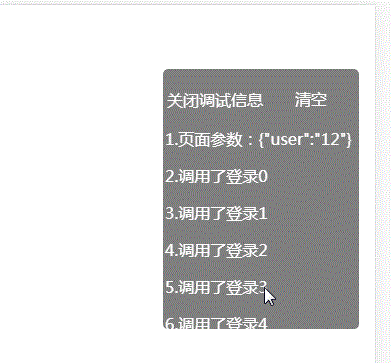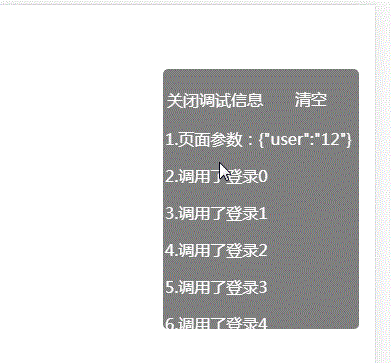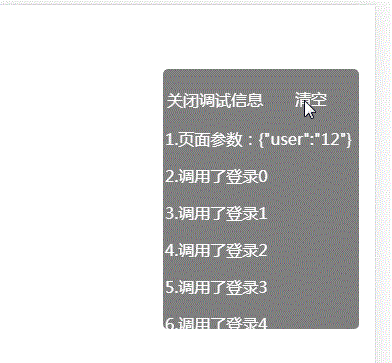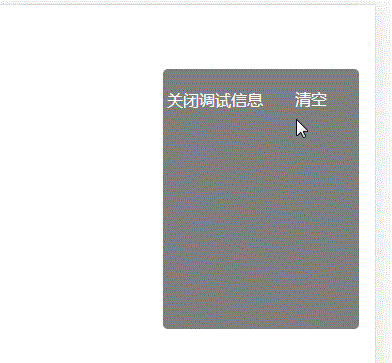
html 写一个日志控件 查看log
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 使用场景, 示例访问:https://weixin.njkeren.cn/test1.html?user12 得到的效果图 实现代码 <!DOCTYPE html> <html><head><meta charset&q…
python开源项目贡献_通过为开源项目做贡献,我如何找到理想的工作
python开源项目贡献by Utsab Saha由Utsab Saha 通过为开源项目做贡献,我如何找到理想的工作 (How I found my dream job by contributing to open source projects) One of the concerns I often hear about from my coding students is, “How am I going to land…
JSON解析与XML解析的区别
JSON与XML的区别比较 1.定义介绍 (1).XML定义扩展标记语言 (Extensible Markup Language, XML) ,用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 XML使用DTD(d…

[matlab]Monte Carlo模拟学习笔记
理论基础:大数定理,当频数足够多时,频率可以逼近概率,从而依靠概率与$\pi$的关系,求出$\pi$ 所以,rand在Monte Carlo中是必不可少的,必须保证测试数据的随机性。 用蒙特卡洛方法进行计算机模拟的…
vue 网络请求 axios vue POST请求 vue GET请求 代码示例
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 1.安装 axios 和 vue-axios 和 qs (qs是为了解决post默认使用的是x-www-from-urlencoded 请求,导致请求参数无法传递到后台) $ npm install --save axio…
bff v2ex_语音备忘录的BFF-如何通过Machine Learning简化Speech2Text
bff v2exby Rafael Belchior通过拉斐尔贝尔基奥尔(Rafael Belchior) 语音备忘录的BFF-如何通过Machine Learning简化Speech2Text (The voice memo’s BFF — how to make Speech2Text easy with Machine Learning) Do you think recording voice memos is inconvenient becaus…
pat1094. The Largest Generation (25)
1094. The Largest Generation (25) 时间限制200 ms内存限制65536 kB代码长度限制16000 B判题程序Standard作者CHEN, YueA family hierarchy is usually presented by a pedigree tree where all the nodes on the same level belong to the same generation. Your task is to …
web-view里面的网页能请求未配置的request域名吗
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 可以
.NET调用JAVA的WebService方法
调用WebService,最简单的办法当然是直接添加WEB引用,然后自动产生代理类,但是在调用JAVA的WebService时并没有这么简单,特别是对于SoapHeader的处理,在网上也有相关资料,但是都整理的不够清晰明了。根据网上…
适合初学者的数据结构_数据结构101:图-初学者的直观介绍
适合初学者的数据结构了解您每天使用的数据结构 (Get to know the data structures that you use every day) Welcome! Let’s Start with Some Vital Context. Let me ask you something:✅ Do you use Google Search? ✅ Do you use Google Maps? ✅ Do you use social med…
深入解析CSS样式层叠权重值
本文为转载内容,源地址:http://www.ofcss.com/2011/05/26/css-cascade-specificity.html 读到《重新认识CSS的权重》这篇,在文章最后给出了便于记忆的顺序: “important > 内联 > ID > 类 > 标签 | 伪类 | 属性选择 &…

VUE做一个公共的提示组件,显示两秒自动隐藏,显示的值父组件传递给子组件
需求:VUE做一个公共的提示组件,显示两秒自动隐藏,显示的值由父组件动态传给子组件。 效果图: 实现步骤: 1.创建一个子组件 Toptips.vue (它就是公共提示组件), optips.vue代码如下: <temp…

Linux课堂随笔---第四天
用户账户简介 在Linux系统中有三大类用户,分别是root用户,系统用户和普通用户。 在Linux系统中,root用户UID为0,root用户的权限是最高的,普通用户无法执行的操作,root用户都能完成。所以也被称为超级用户。…