python中nlp的库_单词袋简介以及如何在Python for NLP中对其进行编码
python中nlp的库
by Praveen Dubey
通过Praveen Dubey
单词词汇入门以及如何在Python中为NLP 编写代码的简介 (An introduction to Bag of Words and how to code it in Python for NLP)
Bag of Words (BOW) is a method to extract features from text documents. These features can be used for training machine learning algorithms. It creates a vocabulary of all the unique words occurring in all the documents in the training set.
单词袋(BOW)是一种从文本文档中提取特征的方法。 这些功能可用于训练机器学习算法。 它为训练集中的所有文档中出现的所有唯一单词创建了词汇表。
In simple terms, it’s a collection of words to represent a sentence with word count and mostly disregarding the order in which they appear.
简而言之,它是一个单词集合,代表一个带有单词计数的句子,并且大多不考虑它们出现的顺序。
BOW is an approach widely used with:
BOW是一种广泛用于以下方面的方法:
- Natural language processing自然语言处理
- Information retrieval from documents从文件中检索信息
- Document classifications文件分类
On a high level, it involves the following steps.
从高层次上讲,它涉及以下步骤。
Generated vectors can be input to your machine learning algorithm.
生成的向量可以输入到您的机器学习算法中。
Let’s start with an example to understand by taking some sentences and generating vectors for those.
让我们从一个示例开始,以理解一些句子并为其生成向量。
Consider the below two sentences.
考虑下面的两个句子。
1. "John likes to watch movies. Mary likes movies too."2. "John also likes to watch football games."These two sentences can be also represented with a collection of words.
这两个句子也可以用单词集合来表示。
1. ['John', 'likes', 'to', 'watch', 'movies.', 'Mary', 'likes', 'movies', 'too.']2. ['John', 'also', 'likes', 'to', 'watch', 'football', 'games']Further, for each sentence, remove multiple occurrences of the word and use the word count to represent this.
此外,对于每个句子,删除单词的多次出现并使用单词计数来表示。
1. {"John":1,"likes":2,"to":1,"watch":1,"movies":2,"Mary":1,"too":1}2. {"John":1,"also":1,"likes":1,"to":1,"watch":1,"football":1, "games":1}Assuming these sentences are part of a document, below is the combined word frequency for our entire document. Both sentences are taken into account.
假设这些句子是文档的一部分,以下是我们整个文档的合并词频。 两个句子都被考虑在内。
{"John":2,"likes":3,"to":2,"watch":2,"movies":2,"Mary":1,"too":1, "also":1,"football":1,"games":1}The above vocabulary from all the words in a document, with their respective word count, will be used to create the vectors for each of the sentences.
来自文档中所有单词的上述词汇以及相应的单词计数将用于为每个句子创建向量。
The length of the vector will always be equal to vocabulary size. In this case the vector length is 11.
向量的长度将始终等于词汇量。 在这种情况下,向量长度为11。
In order to represent our original sentences in a vector, each vector is initialized with all zeros — [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
为了表示向量中的原始句子,每个向量都用全零初始化- [ 0,0,0,0,0,0,0,0,0,0 ]
This is followed by iteration and comparison with each word in our vocabulary, and incrementing the vector value if the sentence has that word.
接下来是迭代和与词汇表中的每个单词进行比较,如果句子中有该单词,则将向量值增加。
John likes to watch movies. Mary likes movies too.[1, 2, 1, 1, 2, 1, 1, 0, 0, 0]John also likes to watch football games.[1, 1, 1, 1, 0, 0, 0, 1, 1, 1]For example, in sentence 1 the word likes appears in second position and appears two times. So the second element of our vector for sentence 1 will be 2: [1, 2, 1, 1, 2, 1, 1, 0, 0, 0]
例如,在句子1中,“ likes ”一词出现在第二个位置,并且出现了两次。 因此,句子1的向量的第二个元素将是2: [1、2、1、1、1、2、1、1、0、0、0]
The vector is always proportional to the size of our vocabulary.
向量始终与我们的词汇量成正比。
A big document where the generated vocabulary is huge may result in a vector with lots of 0 values. This is called a sparse vector. Sparse vectors require more memory and computational resources when modeling. The vast number of positions or dimensions can make the modeling process very challenging for traditional algorithms.
生成的词汇量很大的大文档可能会导致向量具有很多0值。 这称为稀疏向量 。 建模时,稀疏向量需要更多的内存和计算资源。 大量的位置或维度可能会使建模过程对传统算法非常具有挑战性。
编码我们的BOW算法 (Coding our BOW algorithm)
The input to our code will be multiple sentences and the output will be the vectors.
我们代码的输入将是多个句子,输出将是向量。
The input array is this:
输入数组是这样的:
["Joe waited for the train", "The train was late", "Mary and Samantha took the bus","I looked for Mary and Samantha at the bus station","Mary and Samantha arrived at the bus station early but waited until noon for the bus"]步骤1:标记句子 (Step 1: Tokenize a sentence)
We will start by removing stopwords from the sentences.
我们将从删除句子中的停用词开始。
Stopwords are words which do not contain enough significance to be used without our algorithm. We would not want these words taking up space in our database, or taking up valuable processing time. For this, we can remove them easily by storing a list of words that you consider to be stop words.
停用词是指没有我们算法无法使用的重要性不高的词。 我们不希望这些单词占用我们数据库中的空间或占用宝贵的处理时间。 为此,我们可以通过存储您认为是停用词的单词列表来轻松删除它们。
Tokenization is the act of breaking up a sequence of strings into pieces such as words, keywords, phrases, symbols and other elements called tokens. Tokens can be individual words, phrases or even whole sentences. In the process of tokenization, some characters like punctuation marks are discarded.
令牌化是将字符串序列分解为单词,关键字,短语,符号和其他称为Token的元素的行为。 令牌可以是单个单词,短语甚至整个句子。 在标记化过程中,某些字符(如标点符号)被丢弃。
def word_extraction(sentence): ignore = ['a', "the", "is"] words = re.sub("[^\w]", " ", sentence).split() cleaned_text = [w.lower() for w in words if w not in ignore] return cleaned_textFor more robust implementation of stopwords, you can use python nltk library. It has a set of predefined words per language. Here is an example:
为了更强大地实现停用词,您可以使用python nltk库。 每种语言都有一组预定义的单词。 这是一个例子:
import nltkfrom nltk.corpus import stopwords set(stopwords.words('english'))步骤2:对所有句子应用标记化 (Step 2: Apply tokenization to all sentences)
def tokenize(sentences): words = [] for sentence in sentences: w = word_extraction(sentence) words.extend(w) words = sorted(list(set(words))) return wordsThe method iterates all the sentences and adds the extracted word into an array.
该方法迭代所有句子并将提取的单词添加到数组中。
The output of this method will be:
该方法的输出将是:
['and', 'arrived', 'at', 'bus', 'but', 'early', 'for', 'i', 'joe', 'late', 'looked', 'mary', 'noon', 'samantha', 'station', 'the', 'took', 'train', 'until', 'waited', 'was']步骤3:建立词汇表并产生向量 (Step 3: Build vocabulary and generate vectors)
Use the methods defined in steps 1 and 2 to create the document vocabulary and extract the words from the sentences.
使用步骤1和2中定义的方法来创建文档词汇表并从句子中提取单词。
def generate_bow(allsentences): vocab = tokenize(allsentences) print("Word List for Document \n{0} \n".format(vocab));for sentence in allsentences: words = word_extraction(sentence) bag_vector = numpy.zeros(len(vocab)) for w in words: for i,word in enumerate(vocab): if word == w: bag_vector[i] += 1 print("{0}\n{1}\n".format(sentence,numpy.array(bag_vector)))Here is the defined input and execution of our code:
这是代码的定义输入和执行:
allsentences = ["Joe waited for the train train", "The train was late", "Mary and Samantha took the bus","I looked for Mary and Samantha at the bus station","Mary and Samantha arrived at the bus station early but waited until noon for the bus"]generate_bow(allsentences)The output vectors for each of the sentences are:
每个句子的输出向量是:
Output:Joe waited for the train train[0. 0. 0. 0. 0. 0. 1. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 1. 0.]The train was late[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 1. 0. 1. 0. 0. 1.]Mary and Samantha took the bus[1. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 1. 0. 1. 0. 0. 1. 0. 0. 0. 0.]I looked for Mary and Samantha at the bus station[1. 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 1. 1. 0. 0. 0. 0. 0. 0.]Mary and Samantha arrived at the bus station early but waited until noon for the bus[1. 1. 1. 2. 1. 1. 1. 0. 0. 0. 0. 1. 1. 1. 1. 0. 0. 0. 1. 1. 0.]As you can see, each sentence was compared with our word list generated in Step 1. Based on the comparison, the vector element value may be incremented. These vectors can be used in ML algorithms for document classification and predictions.
如您所见, 每个句子都与步骤1中生成的单词列表进行了比较。基于比较,向量元素值可能会增加 。 这些向量可以在ML算法中用于文档分类和预测。
We wrote our code and generated vectors, but now let’s understand bag of words a bit more.
我们编写了代码并生成了向量,但是现在让我们更多地了解一些单词。
洞悉字词 (Insights into bag of words)
The BOW model only considers if a known word occurs in a document or not. It does not care about meaning, context, and order in which they appear.
BOW模型仅考虑已知单词是否出现在文档中。 它不关心它们出现的含义,上下文和顺序。
This gives the insight that similar documents will have word counts similar to each other. In other words, the more similar the words in two documents, the more similar the documents can be.
这提供了这样的见解,即相似的文档将具有彼此相似的字数。 换句话说,两个文档中的单词越相似,文档可能就越相似。
BOW的局限性 (Limitations of BOW)
Semantic meaning: the basic BOW approach does not consider the meaning of the word in the document. It completely ignores the context in which it’s used. The same word can be used in multiple places based on the context or nearby words.
语义 :基本的BOW方法不考虑文档中单词的含义。 它完全忽略了使用它的上下文。 可以根据上下文或附近的单词在多个位置使用同一单词。
Vector size: For a large document, the vector size can be huge resulting in a lot of computation and time. You may need to ignore words based on relevance to your use case.
向量大小 :对于大文档,向量大小可能很大,导致大量的计算和时间。 您可能需要根据与用例的相关性来忽略单词。
This was a small introduction to the BOW method. The code showed how it works at a low level. There is much more to understand about BOW. For example, instead of splitting our sentence in a single word (1-gram), you can split in the pair of two words (bi-gram or 2-gram). At times, bi-gram representation seems to be much better than using 1-gram. These can often be represented using N-gram notation. I have listed some research papers in the resources section for more in-depth knowledge.
这是对BOW方法的简短介绍。 该代码显示了它是如何在较低级别上工作的。 有关BOW的更多知识。 例如,您可以将我们的句子拆分成两个单词对(二元语法或2-gram),而不是将我们的句子拆分成一个单词(1-克)。 有时,二元语法表示似乎比使用1-gram更好。 这些通常可以用N-gram表示法表示。 我在资源部分列出了一些研究论文,以获取更深入的知识。
You do not have to code BOW whenever you need it. It is already part of many available frameworks like CountVectorizer in sci-kit learn.
您无需在需要时对BOW进行编码。 它已经是许多可用框架的一部分,例如sci-kit learning中的CountVectorizer。
Our previous code can be replaced with:
我们之前的代码可以替换为:
from sklearn.feature_extraction.text import CountVectorizervectorizer = CountVectorizer()X = vectorizer.fit_transform(allsentences)print(X.toarray())It’s always good to understand how the libraries in frameworks work, and understand the methods behind them. The better you understand the concepts, the better use you can make of frameworks.
了解框架中的库如何工作并了解其背后的方法总是很有益的。 您越了解概念,就可以更好地利用框架。
Thanks for reading the article. The code shown is available on my GitHub.
感谢您阅读本文。 显示的代码在我的GitHub上可用 。
You can follow me on Medium, Twitter, and LinkedIn, For any questions, you can reach out to me on email (praveend806 [at] gmail [dot] com).
您可以在Medium , Twitter和LinkedIn上关注我,如有任何疑问,您可以通过电子邮件与我联系(praveend806 [at] gmail [dot] com)。
有关词汇的资源 (Resources to read more on bag of words)
Wikipedia-BOW
维基百科
Understanding Bag-of-Words Model: A Statistical Framework
了解词袋模型:统计框架
Semantics-Preserving Bag-of-Words Models and Applications
保留语义的词袋模型及其应用
翻译自: https://www.freecodecamp.org/news/an-introduction-to-bag-of-words-and-how-to-code-it-in-python-for-nlp-282e87a9da04/
python中nlp的库
相关文章:

机器学习:计算学习理论
计算学习理论介绍 关键词: 鲁棒性 关键词: 【机器学习基础】理解为什么机器可以学习1——PAC学习模型--简书 关键词:存在必要性;从机器学习角度出发 PAC学习理论:机器学习那些事 关键词:不错的大道理 如果相…

HTML超出部分滚动效果 HTML滚动 HTML下拉 附效果图
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 H5 效果图 实现代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title>Bootstrap 实例 - 滚动监听(Scrollspy)…
编写高质量代码改善C#程序的157个建议——建议148:不重复代码
建议148:不重复代码 如果发现重复的代码,则意味着我们需要整顿一下,在继续前进。 重复的代码让我们的软件行为不一致。举例来说,如果存在两处相同的加密代码。结果在某一天,我们发现加密代码有个小Bug,然后…
求职者提问的问题面试官不会_如何通过三个简单的问题就不会陷入求职困境
求职者提问的问题面试官不会by DJ Chung由DJ Chung 如何通过三个简单的问题就不会陷入求职困境 (How to get un-stuck in your job search with three simple questions) 您甚至不知道为什么会被卡住? (Do you even know why you’re stuck?) Your job search can…
不能交换到解决jenkins用户的问题
su - jenkins始终有效,今centos无效,因为/etc/password在文档/bin/bash是yum当安装到/bin/false.之后可以改变。ubuntu安装包和yum安装包的行为不一致啊。版权声明:本文博主原创文章,博客,未经同意,不得转载…

HTML引用公共组件
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 在test.html引用footer.html 效果图 代码 test.html <!DOCTYPE html> <html><head><meta charset"utf-8"><title>引用demo</title><s…
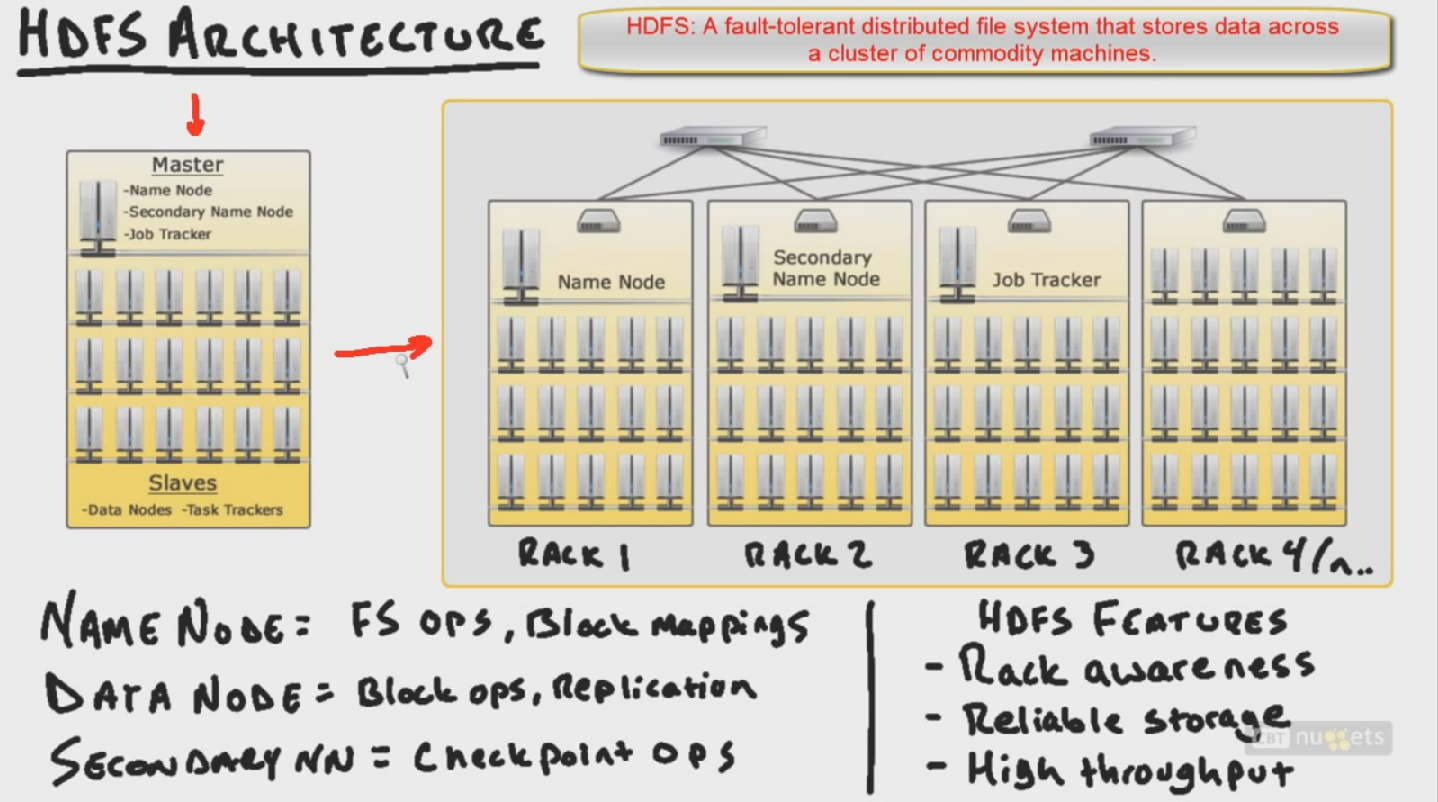
Hadoop自学笔记(二)HDFS简单介绍
1. HDFS Architecture 一种Master-Slave结构。包括Name Node, Secondary Name Node,Data Node Job Tracker, Task Tracker。JobTrackers: 控制全部的Task Trackers 。这两个Tracker将会在MapReduce课程里面具体介绍。以下具体说明HDFS的结构及其功能。 Name Node:控制全部的Dat…
如何为Linux设置Docker和Windows子系统:爱情故事。 ?
Do you sometimes feel you’re a beautiful princess turned by an evil wizard into a frog? Like you don’t belong? I do. I’m a UNIX guy scared to leave the cozy command line. My terminal is my castle. But there are times when I’m forced to use Microsoft …
再谈Spring Boot中的乱码和编码问题
编码算不上一个大问题,即使你什么都不管,也有很大的可能你不会遇到任何问题,因为大部分框架都有默认的编码配置,有很多是UTF-8,那么遇到中文乱码的机会很低,所以很多人也忽视了。 Spring系列产品大量运用在…

UDP 构建p2p打洞过程的实现原理(持续更新)
UDP 构建p2p打洞过程的实现原理(持续更新) 发表于7个月前(2015-01-19 10:55) 阅读(433) | 评论(0) 8人收藏此文章, 我要收藏赞08月22日珠海 OSC 源创会正在报名,送机械键盘和开源无码内裤 摘要 UDP 构建p2p打洞过程…
Vue父组件网络请求回数据后再给子组件传值demo示例
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 这里demo使用延迟执行模拟网络请求;父组件给子组件需要使用自定义属性 Prop ,下面是示例代码: <!DOCTYPE html> <html> <head> <me…
gulp-sass_如果您是初学者,如何使用命令行设置Gulp-sass
gulp-sassby Simeon Bello通过Simeon Bello I intern at a tech firm presently, and few days ago I got a challenge from my boss about writing an article. So I decided to write something on Gulp-sass. Setting it up can be frustrating sometimes, especially when…
MyEclipse快捷键
MyEclipse快捷键 Ctrl1 快速修复CtrlD: 删除当前行 CtrlQ 定位到最后编辑的地方 CtrlL 定位在某行 CtrlO 快速显示 OutLine CtrlT 快速显示当前类的继承结构 CtrlW 关闭当前Editer CtrlK 快速定位到下一个 CtrlE 快速显示当前Editer的下拉列表CtrlJ 正向增量查找(按下C…

关于UNION和UNION ALL的区别
今天在运行程序的时候发现个问题,就是计算和的时候两条数据一样的话自动去除重复的,可是我这个程序需要重复的数据也算进来呀,然后就找原因,最后在sql语句中找到了是union和union all的问题,简单总结一下下。 当使用到…
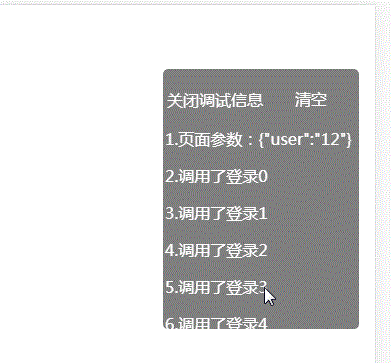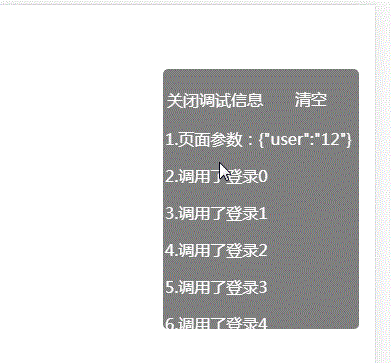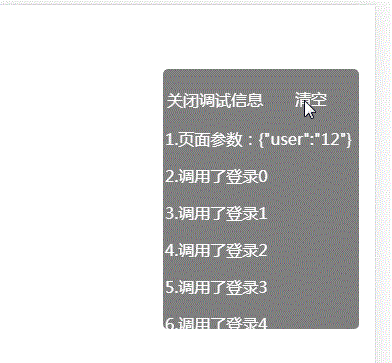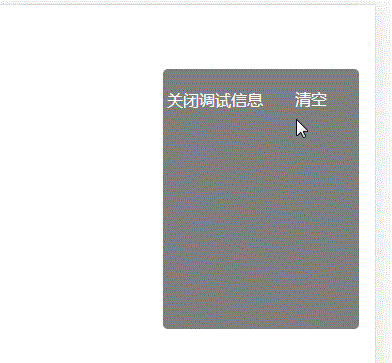
html 写一个日志控件 查看log
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 使用场景, 示例访问:https://weixin.njkeren.cn/test1.html?user12 得到的效果图 实现代码 <!DOCTYPE html> <html><head><meta charset&q…
python开源项目贡献_通过为开源项目做贡献,我如何找到理想的工作
python开源项目贡献by Utsab Saha由Utsab Saha 通过为开源项目做贡献,我如何找到理想的工作 (How I found my dream job by contributing to open source projects) One of the concerns I often hear about from my coding students is, “How am I going to land…
JSON解析与XML解析的区别
JSON与XML的区别比较 1.定义介绍 (1).XML定义扩展标记语言 (Extensible Markup Language, XML) ,用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 XML使用DTD(d…

[matlab]Monte Carlo模拟学习笔记
理论基础:大数定理,当频数足够多时,频率可以逼近概率,从而依靠概率与$\pi$的关系,求出$\pi$ 所以,rand在Monte Carlo中是必不可少的,必须保证测试数据的随机性。 用蒙特卡洛方法进行计算机模拟的…
vue 网络请求 axios vue POST请求 vue GET请求 代码示例
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 1.安装 axios 和 vue-axios 和 qs (qs是为了解决post默认使用的是x-www-from-urlencoded 请求,导致请求参数无法传递到后台) $ npm install --save axio…
bff v2ex_语音备忘录的BFF-如何通过Machine Learning简化Speech2Text
bff v2exby Rafael Belchior通过拉斐尔贝尔基奥尔(Rafael Belchior) 语音备忘录的BFF-如何通过Machine Learning简化Speech2Text (The voice memo’s BFF — how to make Speech2Text easy with Machine Learning) Do you think recording voice memos is inconvenient becaus…
pat1094. The Largest Generation (25)
1094. The Largest Generation (25) 时间限制200 ms内存限制65536 kB代码长度限制16000 B判题程序Standard作者CHEN, YueA family hierarchy is usually presented by a pedigree tree where all the nodes on the same level belong to the same generation. Your task is to …
web-view里面的网页能请求未配置的request域名吗
QQ技术交流群 173683866 526474645 欢迎加入交流讨论,打广告的一律飞机票 可以
.NET调用JAVA的WebService方法
调用WebService,最简单的办法当然是直接添加WEB引用,然后自动产生代理类,但是在调用JAVA的WebService时并没有这么简单,特别是对于SoapHeader的处理,在网上也有相关资料,但是都整理的不够清晰明了。根据网上…
适合初学者的数据结构_数据结构101:图-初学者的直观介绍
适合初学者的数据结构了解您每天使用的数据结构 (Get to know the data structures that you use every day) Welcome! Let’s Start with Some Vital Context. Let me ask you something:✅ Do you use Google Search? ✅ Do you use Google Maps? ✅ Do you use social med…
深入解析CSS样式层叠权重值
本文为转载内容,源地址:http://www.ofcss.com/2011/05/26/css-cascade-specificity.html 读到《重新认识CSS的权重》这篇,在文章最后给出了便于记忆的顺序: “important > 内联 > ID > 类 > 标签 | 伪类 | 属性选择 &…

VUE做一个公共的提示组件,显示两秒自动隐藏,显示的值父组件传递给子组件
需求:VUE做一个公共的提示组件,显示两秒自动隐藏,显示的值由父组件动态传给子组件。 效果图: 实现步骤: 1.创建一个子组件 Toptips.vue (它就是公共提示组件), optips.vue代码如下: <temp…

Linux课堂随笔---第四天
用户账户简介 在Linux系统中有三大类用户,分别是root用户,系统用户和普通用户。 在Linux系统中,root用户UID为0,root用户的权限是最高的,普通用户无法执行的操作,root用户都能完成。所以也被称为超级用户。…
初级开发人员的缺点_作为一名初级开发人员,我如何努力克服自己的挣扎
初级开发人员的缺点by Syeda Aimen Batool通过Syeda Aimen Batool 作为一名初级开发人员,我如何努力克服自己的挣扎 (How I’m working to overcome my struggles as a junior developer) I believe the other name for coding is the “struggle”. And if you ar…
lintcode-136-分割回文串
136-分割回文串 给定一个字符串s,将s分割成一些子串,使每个子串都是回文串。 返回s所有可能的回文串分割方案。 样例 给出 s "aab",返回 [ ["aa", "b"], ["a", "a", "b"] ] 标…
微信小程序把繁琐的判断用Js简单的解决
场景: 订单列表,有很多种订单状态,根据不同的订单状态要显示不同的css。 适用场景:需要根据数组下标判断不同的显示。 示例代码: this.data.order [{"_type":"1","custName":"…