矩阵奇异值分解特征值分解_推荐系统中的奇异值分解与矩阵分解
矩阵奇异值分解特征值分解
Recently, after watching the Recommender Systems class of Prof. Andrew Ng’s Machine Learning course, I found myself very discomforted not understanding how Matrix Factorization works.
最近,在观看了Andrew Ng教授的机器学习课程的“推荐系统” 课程后 ,我发现自己不了解矩阵因式分解的工作原理感到非常不自在。
I know sometimes the math in Machine Learning is very obscure. It’s better if we think about it as a black box, but that model was very “magical” for my standards.
我知道有时机器学习中的数学非常模糊。 如果我们将其视为黑匣子,那会更好,但是对于我的标准而言,该模型非常“神奇”。
In such situations, I usually try to search on Google for more references to better grasp the concept. This time I got even more confused. While Prof. Ng called the algorithm as (Low Factor) Matrix Factorization, I found a different nomenclature on the internet: Singular Value Decomposition.
在这种情况下,我通常会尝试在Google上搜索更多参考,以更好地理解该概念。 这次我变得更加困惑。 吴教授将算法称为(低因子)矩阵分解,但我在互联网上发现了另一种命名法:奇异值分解。
What confused me the most was that Singular Value Decomposition was very different from what Prof. Ng had taught. People kept suggesting they were both the same thing.
最让我感到困惑的是,奇异值分解与Ng教授的教导截然不同。 人们不断暗示着他们都是同一件事。
In this text, I will summarize my findings and try to clear up some of the confusion those terms can cause.
在本文中,我将总结我的发现,并尝试消除这些术语可能引起的一些混乱。
推荐系统 (Recommender Systems)
Recommender Systems (RS) are just automated ways to recommend something to someone. Such systems are broadly used by e-commerce companies, streaming services and news websites. It helps to reduce the friction of users when trying to find something they like.
推荐系统(RS)只是向某人推荐某些东西的自动化方法。 电子商务公司,流媒体服务和新闻网站广泛使用这种系统。 它有助于减少用户在尝试找到自己喜欢的东西时的摩擦。
RS are definitely not a new thing: they have been featured since at least 1990. In fact, part of the recent Machine Learning hype can be attributed to interest in RS. In 2006, Netflix made a splash when they sponsored a competition to find the best RS for their movies. As we will see soon, that event is related to the nomenclature mess that followed.
RS绝对不是什么新鲜事物:至少自1990年以来,它们就已经成为特色。 实际上,最近的机器学习炒作的一部分可以归因于对RS的兴趣。 在2006年,Netflix赞助了一场竞赛,为他们的电影寻找最佳的RS,引起了轰动。 我们将很快看到,该事件与之后的命名混乱有关。
矩阵表示 (The matrix representation)
There are a lot of ways a person can think of recommending a movie to someone. One strategy that turned out to be very good is treating movie ratings as a Users x Movies matrix like this:
一个人可以通过多种方式向他人推荐电影。 事实证明很好的一种策略是将电影分级视为“用户x电影”矩阵,如下所示:
In that matrix, the question marks represent the movies a user has not rated. The strategy then is to predict those ratings somehow and recommend to users the movies they will probably like.
在该矩阵中,问号代表用户未评分的电影。 然后,策略是以某种方式预测这些收视率,并向用户推荐他们可能会喜欢的电影。
矩阵分解 (Matrix Factorization)
A really smart realization made by the guys who entered the Netflix’s competition (notably Simon Funk) was that the users’ ratings weren’t just random guesses. Raters probably follow some logic where they weight the things they like in a movie (a specific actress or a genre) against things they don’t like (long duration or bad jokes) and then come up with a score.
参加Netflix竞赛的人(尤其是Simon Funk )做出的一个非常聪明的认识是,用户的评分不仅仅是随机的猜测。 评分者可能遵循某种逻辑,即将电影中喜欢的事物(特定的女演员或流派)与不喜欢的事物(持续时间长或坏笑话)权衡,然后得出分数。
That process can be represented by a linear formula of the following kind:
该过程可以由以下线性公式表示:
where xₘ is a column vector with the values of the features of the movie m and θᵤ is another column vector with the weights that user u gives to each feature. Each user has a different set of weights and each film has a different set of values for its features.
其中xₘ是具有电影m的特征值的列向量, θᵤ是具有用户u赋予每个特征权重的另一个列向量。 每个用户都有不同的权重设置,每个影片的功能都有不同的值设置。
It turns out that if we arbitrarily fix the number of features and ignore the missing ratings, we can find a set of weights and features values that create a new matrix with values close to the original rating matrix. This can be done with gradient descent, very much like the one used in linear regression. Instead of that now we are optimizing two sets of parameters (weights and features) at the same time.
事实证明,如果我们任意固定要素的数量而忽略缺失的等级,则可以找到一组权重和要素值,这些权重和要素值将创建一个新矩阵,其值与原始等级矩阵接近。 这可以通过梯度下降来完成,与线性回归中使用的非常相似。 取而代之的是,我们现在同时优化两组参数(权重和特征)。
Using the table I gave as an example above, the result of the optimization problem would generate the following new matrix:
使用上面作为示例给出的表,优化问题的结果将生成以下新矩阵:
Notice that the resulting matrix can’t be an exact copy of the original one in most real datasets because in real life people are not doing multiplications and summations to rate a movie. In most cases, the rating is just a gut feeling that can also be affected by all kinds of external factors. Still, our hope is that the linear formula is a good way to express the main logic that drives users ratings.
请注意,在大多数真实数据集中,所得矩阵不能完全是原始矩阵的精确副本,因为在现实生活中,人们并没有进行乘法和求和来对电影评分。 在大多数情况下,评级只是一种直觉,也可能会受到各种外部因素的影响。 尽管如此,我们希望线性公式是表达驱动用户评分的主要逻辑的好方法。
OK, now we have an approximate matrix. But how the heck does that help us to predict the missing ratings? Remember that to build the new matrix, we created a formula to fill all the values, including the ones that are missing in the original matrix. So if we want to predict the missing rating of a user on a movie, we just take all the feature values of that movie, multiply by all the weights of that user and sum everything up. So, in my example, if I want to predict User 2’s rating of Movie 1, I can do the following calculation:
好,现在我们有了一个近似矩阵。 但是,这到底如何帮助我们预测缺失的评分? 请记住,要构建新矩阵,我们创建了一个公式来填充所有值,包括原始矩阵中缺少的值。 因此,如果我们要预测电影上用户的缺失评分,我们只需获取该电影的所有特征值,然后乘以该用户的所有权重,然后将所有内容相加即可。 因此,在我的示例中,如果要预测用户2对电影1的评分,则可以执行以下计算:
To make things clearer, we can disassociate the θ’s and x’s and put them into their own matrices (say P and Q). That is effectively a Matrix Factorization, hence the name used by Prof. Ng.
为了使情况更清楚,我们可以解开θ和x的关系并将它们放入自己的矩阵中(例如P和Q )。 这实际上是矩阵分解,因此由Ng教授使用。
That Matrix Factorization is basically what Funk did. He got third place in Netflix’s competition, attracting a lot of attention (which is an interesting case of a third place being more famous than the winners). His approach has been replicated and refined since then and is still in use in many applications.
矩阵因式分解基本上就是Funk所做的。 他在Netflix的比赛中获得第三名,吸引了很多关注(这是一个有趣的例子,第三名比优胜者更著名)。 从那时起,他的方法一直在被复制和完善,并且仍在许多应用中使用。
奇异值分解 (Singular Value Decomposition)
Enter Singular Value Decomposition (SVD). SVD is a fancy way to factorizing a matrix into three other matrices (A = UΣVᵀ). The way SVD is done guarantees those 3 matrices carry some nice mathematical properties.
输入奇异值分解(SVD)。 SVD是将矩阵分解为其他三个矩阵( A =UΣVᵀ )的一种理想方法 。 SVD的完成方式可确保这3个矩阵具有良好的数学特性。
There are many applications for SVD. One of them is Principal Component Analysis (PCA), which is just reducing a dataset of dimension n to dimension k (k < n).
SVD有许多应用程序 。 其中之一是主成分分析(PCA),它只是将维度n的数据集简化为维度k ( k <n )。
I won’t give you any further detail on SVDs because I don’t know myself. The point is that it’s not the same thing as we did with Matrix Factorization. The biggest evidence is that SVD creates 3 matrices while Funk’s Matrix Factorization creates only 2.
因为我不认识我,所以我不会为您提供有关SVD的更多详细信息。 关键是, 这与我们对矩阵分解进行的处理不同。 最大的证据是,SVD创建了3个矩阵,而Funk的矩阵分解仅创建了2个矩阵。
So why SVD keeps popping up every time I search for Recommender Systems? I had to dig a little bit, but eventually, I found some hidden gems. According to Luis Argerich:
那么,为什么每次我搜索推荐系统时SVD都会不断弹出? 我不得不挖掘一点,但最终,我发现了一些隐藏的宝石。 根据路易斯·阿尔格里希 ( Luis Argerich)的说法:
The matrix factorization algorithms used for recommender systems try to find two matrices: P,Q such as P*Q matches the KNOWN values of the utility matrix.
用于推荐系统的矩阵分解算法尝试找到两个矩阵:P,Q(例如P * Q)与效用矩阵的KNOWN值匹配。
This principle appeared in the famous SVD++ “Factorization meets the neighborhood” paper that unfortunately used the name “SVD++” for an algorithm that has absolutely no relationship with the SVD.
该原理出现在著名的SVD ++“分解与邻域”中,该论文不幸地使用了名称“ SVD ++”作为与SVD毫无关系的算法。
For the record, I think Funk, not the authors of SVD++, first proposed the mentioned matrix factorization for recommender systems. In fact, SVD++, as its name suggests, is an extension of Funk’s work.
作为记录,我认为Funk(不是SVD ++的作者)首先提出了针对推荐系统的提到的矩阵分解。 实际上,顾名思义,SVD ++是Funk工作的扩展。
Xavier Amatriain gives us a bigger picture:
Xavier Amatriain为我们提供了更大的前景 :
Let’s start by pointing out that the method usually referred to as “SVD” that is used in the context of recommendations is not strictly speaking the mathematical Singular Value Decomposition of a matrix but rather an approximate way to compute the low-rank approximation of the matrix by minimizing the squared error loss. A more accurate, albeit more generic, way to call this would be Matrix Factorization. The initial version of this approach in the context of the Netflix Prize was presented by Simon Funk in his famous Try This at Home blogpost. It is important to note that the “true SVD” approach had been indeed applied to the same task years before, with not so much practical success.
让我们首先指出,在建议的上下文中使用的通常称为“ SVD”的方法并不是严格说来是矩阵的数学奇异值分解 ,而是一种近似的方法来计算矩阵的低秩近似通过最小化平方误差损失。 一种更准确(尽管更通用)的调用方式是矩阵分解。 西蒙·冯克(Simon Funk)在他著名的“在家中尝试此”博客文章中介绍了这种方法在Netflix大奖方面的最初版本。 重要的是要注意,“真正的SVD”方法实际上早在几年前就已应用于同一任务,但实际应用并没有那么多。
Wikipedia also has similar information buried in its Matrix factorization (recommender systems) article:
维基百科的“ 矩阵分解”(推荐系统)文章中也包含类似的信息:
The original algorithm proposed by Simon Funk in his blog post factorized the user-item rating matrix as the product of two lower-dimensional matrices, the first one has a row for each user, while the second has a column for each item. The row or column associated with a specific user or item is referred to as latent factors. Note that, despite its name, in FunkSVD no singular value decomposition is applied.
Simon Funk在他的博客文章中提出的原始算法将用户项目评分矩阵分解为两个低维矩阵的乘积,第一个对每个用户都有一行,第二个对每个项目都有一列。 与特定用户或项目关联的行或列称为潜在因素。 请注意,尽管有其名称,但在FunkSVD中未应用任何奇异值分解。
To summarize:
总结一下:
1. SVD is a somewhat complex mathematical technique that factorizes matrices intro three new matrices and has many applications, including PCA and RS.
1. SVD是一种比较复杂的数学技术,可以将矩阵分解为三个新矩阵,并具有许多应用,包括PCA和RS。
2. Simon Funk applied a very smart strategy in the 2006 Netflix competition, factorizing a matrix into two other ones and using gradient descent to find optimal values of features and weights. It’s not SVD, but he used that term anyway to describe his technique.
2.西蒙·冯克(Simon Funk)在2006年的Netflix竞赛中采用了一种非常聪明的策略,将一个矩阵分解为另外两个矩阵,并使用梯度下降法来找到要素和权重的最佳值。 这不是SVD ,但他仍然使用该术语来描述他的技术。
3. The more appropriate term for what Funk did is Matrix Factorization.
3.对于Funk而言,更合适的术语是矩阵分解。
4. Because of the good results and the fame that followed, people still call that technique SVD because, well, that’s how the author named it.
4.由于取得了良好的结果和名声,人们仍然称其为SVD技术,因为作者就是这样命名的。
I hope this helps to clarify things a bit.
我希望这有助于澄清一些事情。
翻译自: https://www.freecodecamp.org/news/singular-value-decomposition-vs-matrix-factorization-in-recommender-systems-b1e99bc73599/
矩阵奇异值分解特征值分解
相关文章:
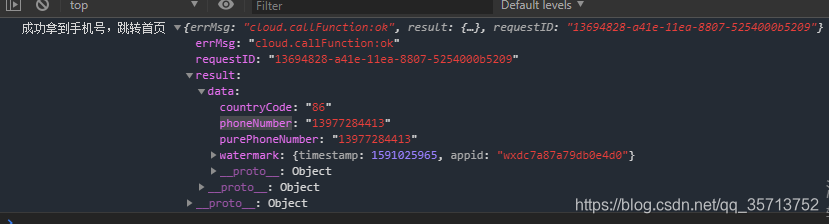
小程序云开发获取手机号完整代码 云函数中网络请求第三方接口
小程序云开发获取手机号完整代码 效果图: 小程序代码 <button open-type"getPhoneNumber" bindgetphonenumber"getPhoneNumber">登录</button> getPhoneNumber: function (e) {var that this;if (!e.detail.errMsg || e.detail.…

集合恒等式定律及文氏图
1、分配律 1.1 A∩(B∪C) (A∩B)∪(A∩C) 说明:从左至右,图1中三角形区域为 A,草绿色区域为 (B∪C),即有三角形又有草绿色底色的区域即为 A∩(B∪C) 图2中三角形区域为 (A∩B),草绿色区域为 (A∩C),三角形…
微信 小程序布局 水平菜单
<!-- 菜单列表部分 --><view class"wear-menu"><view classmenu-box wx:key"menu" wx:for"{{menuList}}" wx:for-index"index"><view class"menu-img" bindtap"selectMenu" data-index"…

keras神经网络回归预测_如何使用Keras建立您的第一个神经网络来预测房价
keras神经网络回归预测by Joseph Lee Wei En通过李维恩 一步一步的完整的初学者指南,可使用像Deep Learning专业版这样的几行代码来构建您的第一个神经网络! (A step-by-step complete beginner’s guide to building your first Neural Network in a c…
transform总结
1. 用jquery的css方法获取transform得到的是矩阵matrix,不利于获取translate的值, 优先使用dom.style.webKitTransform进行transform的读写 2. 从transform中读取translate的值方法 //jquery版本 function fGetTranslate($obj,type){var transformMatrix obj.css(&…
uni-app 音频控制
选择不同的音频,销毁上一个音频,播放最新的音频文件。 效果图: 音频组件代码: <template><view id"share_card" class"share_card"><view class"top"><img class"ms" :class…
推荐5款实用的jQuery时间轴插件
1、使用CSS3和jQuery制作的水平时间轴 这是一个可以在PC和移动端表现非常棒的水平时间轴,它由上部水平滑块和下部时间点对应的内容区块,点击时间轴上的时间点,下部内容会滑动到对应的内容区块。使用CSS3和jQuery技术使得时间轴滑块可以左右滑…
devkit_如何使用NodeMCU Devkit和Firebase数据库开始物联网
devkitby Jibin Thomas吉宾托马斯(Jibin Thomas) 如何使用NodeMCU Devkit和Firebase数据库开始物联网 (How to get started with IoT using NodeMCU Devkit and Firebase database) “The Internet will disappear. There will be so many IP addresses, so many devices, sen…
洛谷p1162填涂颜色(dfs写法)
这道题本是放在试炼场bfs里的,但是我觉得dfs好写些 所以就用dfs过了 题目如下 题目描述 由数字0 组成的方阵中,有一任意形状闭合圈,闭合圈由数字1构成,围圈时只走上下左右4个方向。现要求把闭合圈内的所有空间都填写成2.例如&…
Microsoft .NET Framework 4.6.1
适用于操作系统平台:Windows 7 SP1、Windows 8、Windows 8.1、Windows 10、Windows Server 2008 R2 SP1、Windows Server 2012 和 Windows Server 2012 R2 .NET Framework 4.6.1 官方更新介绍页面 http://msdn.microsoft.com/en-us/library/ms171868%28vvs.110%29.a…
VUE还没生效,页面闪屏的问题解决办法 v-cloak
当网络较慢,网页还在加载 Vue.js ,而导致 Vue 来不及渲染,这时页面就会显示出 Vue 源代码。我们可以使用 v-cloak 指令来解决这一问题。 html: <div id"app">{{context}} </div>js: <script…
如何使用Python创建,读取,更新和搜索Excel文件
This article will show in detail how to work with Excel files and how to modify specific data with Python.本文将详细显示如何使用Excel文件以及如何使用Python修改特定数据。 First we will learn how to work with CSV files by reading, writing and updating them.…

字符串基本操作
1.已知‘星期一星期二星期三星期四星期五星期六星期日 ’,输入数字(1-7),输出相应的‘星期几’ s"星期一星期二星期三星期四星期五星期六星期日" iint(eval(input("请输入1-7的数字:"))) print(s[3*(i-1):3*i…
IOS长按识别二维码失败
IOS长按不识别二维码,出现放大图片的问题解决。 CSS加入样式: touch-callout: none; -webkit-touch-callout: none; -ms-touch-callout: none; -moz-touch-callout: none; 代码: <!DOCTYPE html> <html><head><s…
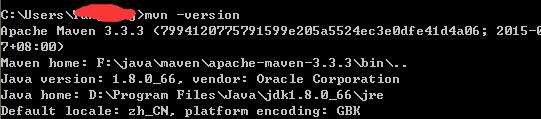
从svn下载的Mavn项目,到本地后不识别(MyEcplise)
从svn上面现在的mavn的项目到本地不识别的原因 1.首先要确认本机的mavn的环境是否正确。 2.查看本机的Myecplise的mavn的环境配置是否正确 3.在cmd当中执行命令 mvn -Dwtpversion1.0 eclipse:myeclipse ,可能svn上面的文件是eclipse建立的,需要进行转化。…
python导入外部包_您会喜欢的10个外部Python软件包
python导入外部包by Adam Goldschmidt亚当戈德施密特(Adam Goldschmidt) 您会喜欢的10个外部Python软件包 (10 External Python packages you are going to love) Python is an experiment in how much freedom programmers need. Too much freedom and nobody can read anoth…

【转修正】sql server行版本控制的隔离级别
在SQL Server标准的已提交读(READ COMMITTED)隔离级别下,一个读操作会和一个写操作相互阻塞。未提交读(READ UNCOMMITTED)虽然不会有这种阻塞,但是读操作可能会读到脏数据,这是大部分用户不能接…
【机器学习基石笔记】八、噪声和错误
噪声的来源: 1、noise in y 2、noise in x 在有noise的情况下,vc bound还会work么??? 之前,x ~ p(x) 现在 y ~ P( y | x ) 在hoeffding的部分,只要 (x, y) 联合分布满足某个分布, 结…
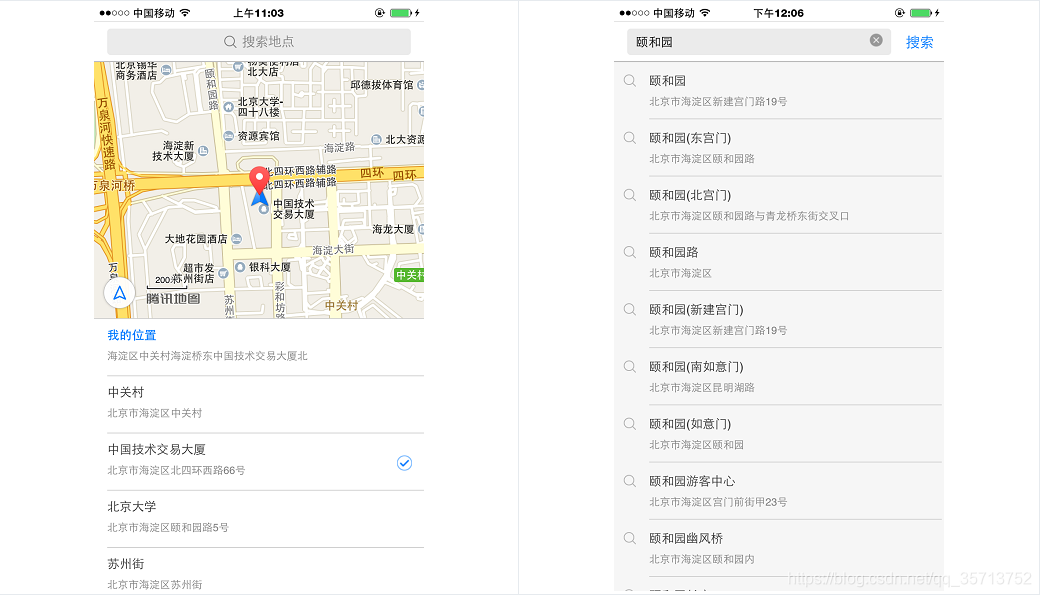
H5用户地址位置选择地点获取经纬度(效果图)
效果图: uni-app <template><view class"flex-v flex-c wrap"><web-view src"https://apis.map.qq.com/tools/locpicker?search1&type1&key7QKBZ-SJ2HF-7TFJS-JL5NE-E6ZD7-SWFW5&referer鏅鸿兘鍚嶇墖"></we…
学习sql注入:猜测数据库_对于SQL的热爱:为什么要学习它以及它将如何帮助您...
学习sql注入:猜测数据库I recently read a great article by the esteemed craigkerstiens describing why he feels SQL is such a valuable skill for developers. This topic really resonated with me. It lined up well with notes I’d already started sketching out fo…

C++入门经典-例6.14-通过指针连接两个字符数组
1:字符数组是一个一维数组,引用字符数组的指针为字符指针,字符指针就是指向字符型内存空间的指针变量。 char *p; char *string"www.mingri.book"; 2:实例,通过指针连接两个字符数组,代码如下&am…
创建一个没有边框的并添加自定义文字的UISegmentedControl
//个性推荐 歌单 主播电台 排行榜NSArray* promoteArray["个性推荐","歌单","主播电台","排行榜"];UISegmentedControl* promoteSgement[[UISegmentedControl alloc]initWithItems:promoteArray];promoteSgement.frameCGRectMake(0, 6…
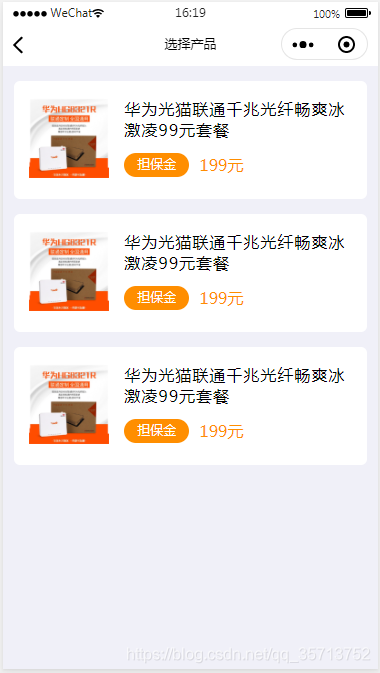
样式集(一) 通用商品列表样式
上图: 上代码: // pages/choosePackage/choosePackage.js Page({data: {list:[1,2,3],},onLoad: function (options) {},nav_upInfo(){wx.navigateTo({url: ../upInfo/upInfo,})}, }) <!--pages/choosePackage/choosePackage.wxml--> <view c…
2019 6月编程语言_今年六月您可以开始学习650项免费的在线编程和计算机科学课程...
2019 6月编程语言Seven years ago, universities like MIT and Stanford first opened up free online courses to the public. Today, more than 900 schools around the world have created thousands of free online courses, popularly known as Massive Open Online Cours…
mybatis分页练手
最近碰到个需求,要做个透明的mybatis分页功能,描述如下:目标:搜索列表的Controller action要和原先保持一样,并且返回的json需要有分页信息,如: ResponseBody RequestMapping(value"/searc…
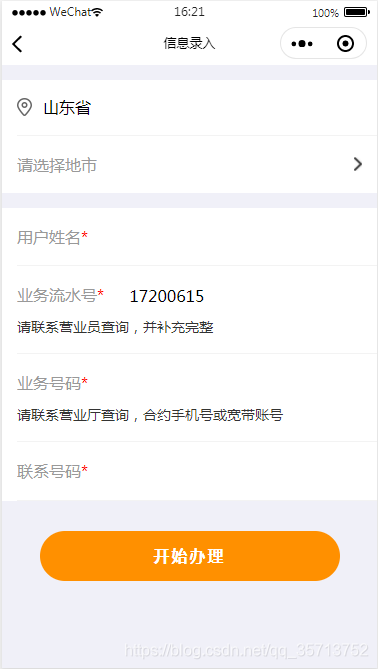
样式集(二) 信息填写样式模板
上图: 代码: // pages/upInfo/upInfo.js Page({data: {tipsTxt: "请填写正确的业务流水号",showTips: false,showCityList:false,city:"",cityList:["济南市","青岛市","枣庄市","东营市"…
12小时进制的时间输出的编辑代码
关于时间输出的编辑代码个人思考了很久,包括顺序,进位之类的,求完善和纠错 public class yunsuanfu {public static void main(String[] arg){double t2;int h38;int m100;int s100;if(s>60){m(s/60)m;ss%60;}if (m>60){h(m/60)h;mm%6…
c++每调用一次函数+1_每个开发人员都应该知道的一些很棒的现代C ++功能
c每调用一次函数1As a language, C has evolved a lot.作为一种语言,C 已经发展了很多。 Of course this did not happen overnight. There was a time when C lacked dynamism. It was difficult to be fond of the language.当然,这并非一overnight而…
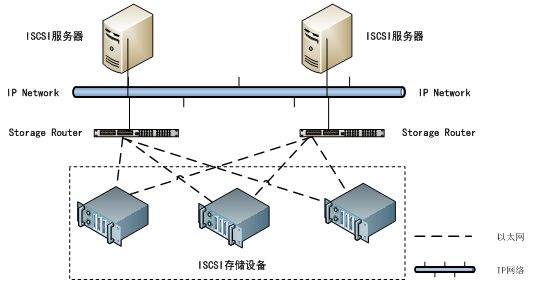
Linux ISCSI配置
一、简介 iSCSI(internet SCSI)技术由IBM公司研究开发,是一个供硬件设备使用的、可以在IP协议的上层运行的SCSI指令集,这种指令集合可以实现在IP网络上运行SCSI协议,使其能够在诸如高速千兆以太网上进行路由选择。iSCS…
样式集(三)成功页面样式模板
上图: 代码: <!--pages/result/result.wxml--> <view><image class"scc" src"/img/scc.png"></image><view class"resuil">办理成功</view> </view> <view class"btn…