如何使用Python创建,读取,更新和搜索Excel文件
This article will show in detail how to work with Excel files and how to modify specific data with Python.
本文将详细显示如何使用Excel文件以及如何使用Python修改特定数据。
First we will learn how to work with CSV files by reading, writing and updating them. Then we will take a look how to read files, filter them by sheets, search for rows/columns, and update cells of xlsx files.
首先,我们将通过读取,写入和更新CSV文件来学习如何使用它们。 然后,我们将了解如何读取文件,按工作表过滤它们,搜索行/列以及更新xlsx文件的单元格。
Let’s start with the simplest spreadsheet format: CSV.
让我们从最简单的电子表格格式开始:CSV。
第1部分-CSV文件 (Part 1 — The CSV file)
A CSV file is a comma-separated values file, where plain text data is displayed in a tabular format. They can be used with any spreadsheet program, such as Microsoft Office Excel, Google Spreadsheets, or LibreOffice Calc.
CSV文件是用逗号分隔的值文件,其中纯文本数据以表格格式显示。 它们可以与任何电子表格程序一起使用,例如Microsoft Office Excel,Google Spreadsheets或LibreOffice Calc。
CSV files are not like other spreadsheet files though, because they don’t allow you to save cells, columns, rows or formulas. Their limitation is that they also allow only one sheet per file. My plan for this first part of the article is to show you how to create CSV files using Python 3 and the standard library module CSV.
CSV文件与其他电子表格文件不同,因为它们不允许您保存单元格,列,行或公式。 它们的局限性在于它们每个文件也只允许一张纸。 我对本文第一部分的计划是向您展示如何使用Python 3和标准库模块CSV创建CSV文件。
This tutorial will end with two GitHub repositories and a live web application that actually uses the code of the second part of this tutorial (yet updated and modified to be for a specific purpose).
本教程将以两个GitHub存储库和一个实时Web应用程序结尾,该Web应用程序实际上使用了本教程第二部分的代码(但已针对特定目的进行了更新和修改)。
写入CSV文件 (Writing to CSV files)
First, open a new Python file and import the Python CSV module.
首先,打开一个新的Python文件并导入Python CSV模块。
import csvCSV模块 (CSV Module)
The CSV module includes all the necessary methods built in. These include:
CSV模块包含所有必需的内置方法。这些方法包括:
- csv.readerCSV阅读器
- csv.writercsv作家
- csv.DictReadercsv.DictReader
- csv.DictWritercsv.DictWriter
- and others和别的
In this guide we are going to focus on the writer, DictWriter and DictReader methods. These allow you to edit, modify, and manipulate the data stored in a CSV file.
在本指南中,我们将重点介绍writer,DictWriter和DictReader方法。 这些使您可以编辑,修改和操作CSV文件中存储的数据。
In the first step we need to define the name of the file and save it as a variable. We should do the same with the header and data information.
第一步,我们需要定义文件名并将其保存为变量。 我们应该对标头和数据信息做同样的事情。
filename = "imdb_top_4.csv"
header = ("Rank", "Rating", "Title")
data = [
(1, 9.2, "The Shawshank Redemption(1994)"),
(2, 9.2, "The Godfather(1972)"),
(3, 9, "The Godfather: Part II(1974)"),
(4, 8.9, "Pulp Fiction(1994)")
]Now we need to create a function named writer that will take in three parameters: header, data and filename.
现在我们需要创建一个名为writer的函数,该函数将包含三个参数: header , data和filename 。
def writer(header, data, filename):passThe next step is to modify the writer function so it creates a file that holds data from the header and data variables. This is done by writing the first row from the header variable and then writing four rows from the data variable (there are four rows because there are four tuples inside the list).
下一步是修改writer函数,以便它创建一个保存来自标头和数据变量的数据的文件 。 这是通过从header变量中写入第一行,然后从data变量中写入四行来完成的(有四行,因为列表中有四个元组)。
def writer(header, data, filename):with open (filename, "w", newline = "") as csvfile:movies = csv.writer(csvfile)movies.writerow(header)for x in data:movies.writerow(x)The official Python documentation describes how the csv.writer method works. I would strongly suggest that you to take a minute to read it.
官方Python文档描述了csv.writer方法的工作方式。 我强烈建议您花一点时间阅读它。
And voilà! You created your first CSV file named imdb_top_4.csv. Open this file with your preferred spreadsheet application and you should see something like this:
和瞧! 您创建了第一个CSV文件,名为imdb_top_4.csv。 使用您喜欢的电子表格应用程序打开此文件,您应该看到类似以下内容的内容:
The result might be written like this if you choose to open the file in some other application:
如果选择在其他应用程序中打开文件,结果可能会这样写:
更新CSV文件 (Updating the CSV files)
To update this file you should create a new function named updater that will take just one parameter called filename.
要更新此文件,您应该创建一个名为updater的新函数,该函数将仅使用一个名为filename的参数。
def updater(filename):with open(filename, newline= "") as file:readData = [row for row in csv.DictReader(file)]# print(readData)readData[0]['Rating'] = '9.4'# print(readData)readHeader = readData[0].keys()writer(readHeader, readData, filename, "update")This function first opens the file defined in the filename variable and then saves all the data it reads from the file inside of a variable named readData. The second step is to hard code the new value and place it instead of the old one in the readData[0][‘Rating’] position.
此函数首先打开在filename变量中定义的文件 ,然后将从文件读取的所有数据保存在名为readData的变量内 。 第二步是对新值进行硬编码,而不是将旧值放置在readData [0] ['Rating']位置。
The last step in the function is to call the writer function by adding a new parameter update that will tell the function that you are doing an update.
函数的最后一步是通过添加新的参数更新来调用writer函数,该更新将告诉函数您正在执行更新。
csv.DictReader is explained more in the official Python documentation here.
有关csv.DictReader的更多信息,请参见此处的官方Python文档。
For writer to work with a new parameter, you need to add a new parameter everywhere writer is defined. Go back to the place where you first called the writer function and add “write” as a new parameter:
为了使writer使用新参数,您需要在定义writer的任何地方添加新参数。 返回您第一次调用writer函数的地方,并添加“ write”作为新参数:
writer(header, data, filename, "write")Just below the writer function call the updater and pass the filename parameter into it:
在writer函数的下面,调用updater并将filename参数传递给它:
writer(header, data, filename, "write")
updater(filename)Now you need to modify the writer function to take a new parameter named option:
现在,您需要修改writer函数以采用名为option的新参数:
def writer(header, data, filename, option):From now on we expect to receive two different options for the writer function (write and update). Because of that we should add two if statements to support this new functionality. First part of the function under “if option == “write:” is already known to you. You just need to add the “elif option == “update”: section of the code and the else part just as they are written bellow:
从现在开始,我们期望对writer函数有两个不同的选择( write和update )。 因此,我们应该添加两个if语句来支持此新功能。 您已经知道“ if option ==” write:”下的函数的第一部分。 您只需要在代码中添加“ elif option ==” update”:部分和else部分,如下所示:
def writer(header, data, filename, option):with open (filename, "w", newline = "") as csvfile:if option == "write":movies = csv.writer(csvfile)movies.writerow(header)for x in data:movies.writerow(x)elif option == "update":writer = csv.DictWriter(csvfile, fieldnames = header)writer.writeheader()writer.writerows(data)else:print("Option is not known")Bravo! Your are done!
太棒了! 大功告成!
Now your code should look something like this:
现在,您的代码应如下所示:
You can also find the code here:
您还可以在这里找到代码:
https://github.com/GoranAviani/CSV-Viewer-and-Editor
https://github.com/GoranAviani/CSV-Viewer-and-Editor
In the first part of this article we have seen how to work with CSV files. We have created and updated one such file.
在本文的第一部分,我们已经了解了如何使用CSV文件。 我们已经创建并更新了一个这样的文件。
第2部分-xlsx文件 (Part 2 — The xlsx file)
For several weekends I have worked on this project. I have started working on it because there was a need for this kind of solution in my company. My first idea was to build this solution directly in my company’s system, but then I wouldn’t have anything to write about, eh?
在几个周末中,我一直在从事这个项目。 我已经开始进行此工作,因为我的公司需要这种解决方案。 我的第一个想法是直接在公司的系统中构建此解决方案,但那时我什么都没写,是吗?
I build this solution using Python 3 and openpyxl library. The reason why I have chosen openpyxl is because it represents a complete solution for creating worksheets, loading, updating, renaming and deleting them. It also allows us to read or write to rows and columns, merge or un-merge cells or create Python excel charts etc.
我使用Python 3和openpyxl库构建此解决方案。 之所以选择openpyxl,是因为它代表了创建工作表,加载,更新,重命名和删除工作表的完整解决方案。 它还允许我们读取或写入行和列,合并或取消合并单元格或创建Python excel图表等。
Openpyxl术语和基本信息 (Openpyxl terminology and basic info)
- Workbook is the name for an Excel file in Openpyxl.工作簿是Openpyxl中Excel文件的名称。
- A workbook consists of sheets (default is 1 sheet). Sheets are referenced by their names.一个工作簿由工作表组成(默认为1张工作表)。 工作表按其名称引用。
- A sheet consists of rows (horizontal lines) starting from the number 1 and columns (vertical lines) starting from the letter A.一张纸由从数字1开始的行(水平线)和从字母A开始的列(垂直线)组成。
- Rows and columns result in a grid and form cells which may contain some data (numerical or string value) or formulas.行和列形成一个网格并形成一个单元格,其中可能包含一些数据(数字或字符串值)或公式。
Openpyxl in nicely documented and I would advise that you take a look here.
Openpyxl的文档很好,我建议您在这里看看。
The first step is to open your Python environment and install openpyxl within your terminal:
第一步是打开您的Python环境并在终端中安装openpyxl :
pip install openpyxlNext, import openpyxl into your project and then to load a workbook into the theFile variable.
接下来,将openpyxl导入到您的项目中,然后将工作簿加载到theFile变量中。
import openpyxltheFile = openpyxl.load_workbook('Customers1.xlsx')
print(theFile.sheetnames)
currentSheet = theFile['customers 1']
print(currentSheet['B4'].value)As you can see, this code prints all sheets by their names. It then selects the sheet that is named “customers 1” and saves it to a currentSheet variable. In the last line, the code prints the value that is located in the B4 position of the “customers 1” sheet.
如您所见,此代码按名称打印所有工作表。 然后,它选择名为“ customers 1”的工作表并将其保存到currentSheet变量中。 在最后一行,代码将打印位于“ customers 1”表的B4位置的值。
This code works as it should but it is very hard coded. To make this more dynamic we will write code that will:
该代码可以正常工作,但是很难编码。 为了使它更具动态性,我们将编写以下代码:
Read the file
读取文件
Get all sheet names
获取所有工作表名称
Loop through all sheets
循环浏览所有工作表
In the last step, the code will print values that are located in B4 fields of each found sheet inside the workbook.
在最后一步,代码将打印位于工作簿内每个找到的工作表的B4字段中的值。
import openpyxltheFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnamesprint("All sheet names {} " .format(theFile.sheetnames))for x in allSheetNames:print("Current sheet name is {}" .format(x))currentSheet = theFile[x]print(currentSheet['B4'].value)This is better than before, but it is still a hard coded solution and it still assumes the value you will be looking for is in the B4 cell, which is just silly :)
这比以前更好,但是它仍然是一个硬编码的解决方案,它仍然假定您要查找的值在B4单元格中,这很愚蠢:)
I expect your project will need to search inside all sheets in the Excel file for a specific value. To do this we will add one more for loop in the “ABCDEF” range and then simply print cell names and their values.
我希望您的项目需要在Excel文件的所有工作表中搜索特定值。 为此,我们将在“ ABCDEF”范围内再添加一个for循环,然后仅打印单元格名称及其值。
import openpyxltheFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnamesprint("All sheet names {} " .format(theFile.sheetnames))for sheet in allSheetNames:print("Current sheet name is {}" .format(sheet))currentSheet = theFile[sheet]# print(currentSheet['B4'].value)#print max numbers of wors and colums for each sheet#print(currentSheet.max_row)#print(currentSheet.max_column)for row in range(1, currentSheet.max_row + 1):#print(row)for column in "ABCDEF": # Here you can add or reduce the columnscell_name = "{}{}".format(column, row)#print(cell_name)print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))We did this by introducing the “for row in range..” loop. The range of the for loop is defined from the cell in row 1 to the sheet’s maximum number or rows. The second for loop searches within predefined column names “ABCDEF”. In the second loop we will display the full position of the cell (column name and row number) and a value.
为此,我们引入了“ for range in .. ”循环。 for循环的范围是从第1行的单元格到工作表的最大数目或行数定义的。 第二个for循环搜索在预定义的列名称“ ABCDEF ”内进行。 在第二个循环中,我们将显示单元格的完整位置(列名和行号)和一个值。
However, in this article my task is to find a specific column that is named “telephone” and then go through all the rows of that column. To do that we need to modify the code like below.
但是,在本文中,我的任务是找到一个名为“电话”的特定列,然后遍历该列的所有行。 为此,我们需要修改如下代码。
import openpyxltheFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnamesprint("All sheet names {} " .format(theFile.sheetnames))def find_specific_cell():for row in range(1, currentSheet.max_row + 1):for column in "ABCDEFGHIJKL": # Here you can add or reduce the columnscell_name = "{}{}".format(column, row)if currentSheet[cell_name].value == "telephone":#print("{1} cell is located on {0}" .format(cell_name, currentSheet[cell_name].value))print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))return cell_namefor sheet in allSheetNames:print("Current sheet name is {}" .format(sheet))currentSheet = theFile[sheet]This modified code goes through all cells of every sheet, and just like before the row range is dynamic and the column range is specific. The code loops through cells and looks for a cell that holds a text “telephone”. Once the code finds the specific cell it notifies the user in which cell the text is located. The code does this for every cell inside of all sheets that are in the Excel file.
修改后的代码遍历每张纸的所有单元格,就像行范围是动态的并且列范围是特定的之前一样。 该代码循环遍历单元格并查找包含文本“电话”的单元格。 一旦代码找到了特定的单元格,它将通知用户文本位于哪个单元格中。 该代码对Excel文件中所有工作表中的每个单元格执行此操作。
The next step is to go through all rows of that specific column and print values.
下一步是遍历该特定列的所有行并打印值。
import openpyxltheFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnamesprint("All sheet names {} " .format(theFile.sheetnames))def find_specific_cell():for row in range(1, currentSheet.max_row + 1):for column in "ABCDEFGHIJKL": # Here you can add or reduce the columnscell_name = "{}{}".format(column, row)if currentSheet[cell_name].value == "telephone":#print("{1} cell is located on {0}" .format(cell_name, currentSheet[cell_name].value))print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))return cell_namedef get_column_letter(specificCellLetter):letter = specificCellLetter[0:-1]print(letter)return letterdef get_all_values_by_cell_letter(letter):for row in range(1, currentSheet.max_row + 1):for column in letter:cell_name = "{}{}".format(column, row)#print(cell_name)print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))for sheet in allSheetNames:print("Current sheet name is {}" .format(sheet))currentSheet = theFile[sheet]specificCellLetter = (find_specific_cell())letter = get_column_letter(specificCellLetter)get_all_values_by_cell_letter(letter)This is done by adding a function named get_column_letter that finds a letter of a column. After the letter of the column is found we loop through all rows of that specific column. This is done with the get_all_values_by_cell_letter function which will print all values of those cells.
这可以通过添加一个名为get_column_letter的函数来找到列的字母来完成。 找到该列的字母后,我们遍历该特定列的所有行。 这是通过get_all_values_by_cell_letter函数完成的,该函数将打印这些单元格的所有值。
结语 (Wrapping up)
Bra gjort! There are many thing you can do after this. My plan was to build an online app that will standardize all Swedish telephone numbers taken from a text box and offer users the possibility to simply copy the results from the same text box. The second step of my plan was to expand the functionality of the web app to support the upload of Excel files, processing of telephone numbers inside those files (standardizing them to a Swedish format) and offering the processed files back to users.
胸罩gjort! 此后您可以做很多事情。 我的计划是构建一个在线应用程序,以标准化从文本框中获取的所有瑞典电话号码,并为用户提供简单地从同一文本框中复制结果的可能性。 我计划的第二步是扩展Web应用程序的功能,以支持Excel文件的上载,处理这些文件中的电话号码(将它们标准化为瑞典格式)并将处理后的文件提供给用户。
I have done both of those tasks and you can see them live in the Tools page of my Incodaq.com site:
我已经完成了这两项任务,您可以在我的Incodaq.com网站的“工具”页面上实时看到它们:
https://tools.incodaq.com/
https://tools.incodaq.com/
Also the code from the second part of this article is available on GitHub:
另外,本文第二部分的代码也可以在GitHub上找到:
https://github.com/GoranAviani/Manipulate-Excel-spreadsheets
https://github.com/GoranAviani/Manipulate-Excel-spreadsheets
Thank you for reading! Check out more articles like this on my Medium profile: https://medium.com/@goranaviani and other fun stuff I build on my GitHub page: https://github.com/GoranAviani
感谢您的阅读! 在我的中型资料上查看更多类似的文章: https : //medium.com/@goranaviani和我在GitHub页面上构建的其他有趣的东西: https : //github.com/GoranAviani
翻译自: https://www.freecodecamp.org/news/how-to-create-read-update-and-search-through-excel-files-using-python-c70680d811d4/
相关文章:

字符串基本操作
1.已知‘星期一星期二星期三星期四星期五星期六星期日 ’,输入数字(1-7),输出相应的‘星期几’ s"星期一星期二星期三星期四星期五星期六星期日" iint(eval(input("请输入1-7的数字:"))) print(s[3*(i-1):3*i…

IOS长按识别二维码失败
IOS长按不识别二维码,出现放大图片的问题解决。 CSS加入样式: touch-callout: none; -webkit-touch-callout: none; -ms-touch-callout: none; -moz-touch-callout: none; 代码: <!DOCTYPE html> <html><head><s…
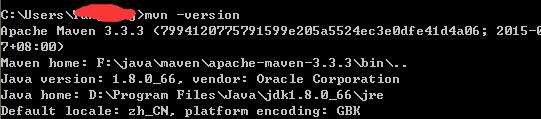
从svn下载的Mavn项目,到本地后不识别(MyEcplise)
从svn上面现在的mavn的项目到本地不识别的原因 1.首先要确认本机的mavn的环境是否正确。 2.查看本机的Myecplise的mavn的环境配置是否正确 3.在cmd当中执行命令 mvn -Dwtpversion1.0 eclipse:myeclipse ,可能svn上面的文件是eclipse建立的,需要进行转化。…
python导入外部包_您会喜欢的10个外部Python软件包
python导入外部包by Adam Goldschmidt亚当戈德施密特(Adam Goldschmidt) 您会喜欢的10个外部Python软件包 (10 External Python packages you are going to love) Python is an experiment in how much freedom programmers need. Too much freedom and nobody can read anoth…

【转修正】sql server行版本控制的隔离级别
在SQL Server标准的已提交读(READ COMMITTED)隔离级别下,一个读操作会和一个写操作相互阻塞。未提交读(READ UNCOMMITTED)虽然不会有这种阻塞,但是读操作可能会读到脏数据,这是大部分用户不能接…
【机器学习基石笔记】八、噪声和错误
噪声的来源: 1、noise in y 2、noise in x 在有noise的情况下,vc bound还会work么??? 之前,x ~ p(x) 现在 y ~ P( y | x ) 在hoeffding的部分,只要 (x, y) 联合分布满足某个分布, 结…
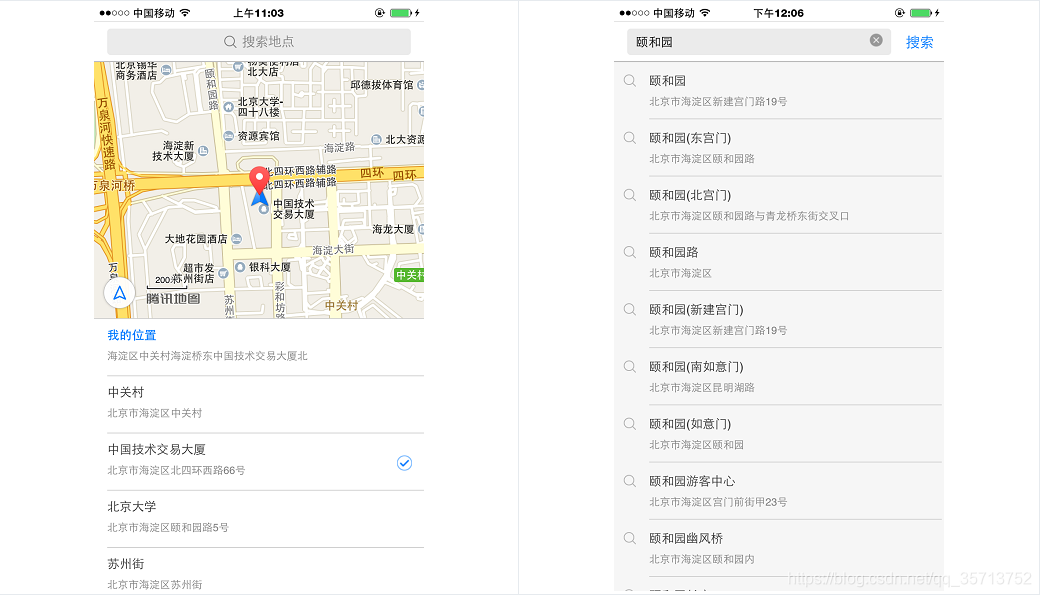
H5用户地址位置选择地点获取经纬度(效果图)
效果图: uni-app <template><view class"flex-v flex-c wrap"><web-view src"https://apis.map.qq.com/tools/locpicker?search1&type1&key7QKBZ-SJ2HF-7TFJS-JL5NE-E6ZD7-SWFW5&referer鏅鸿兘鍚嶇墖"></we…
学习sql注入:猜测数据库_对于SQL的热爱:为什么要学习它以及它将如何帮助您...
学习sql注入:猜测数据库I recently read a great article by the esteemed craigkerstiens describing why he feels SQL is such a valuable skill for developers. This topic really resonated with me. It lined up well with notes I’d already started sketching out fo…

C++入门经典-例6.14-通过指针连接两个字符数组
1:字符数组是一个一维数组,引用字符数组的指针为字符指针,字符指针就是指向字符型内存空间的指针变量。 char *p; char *string"www.mingri.book"; 2:实例,通过指针连接两个字符数组,代码如下&am…
创建一个没有边框的并添加自定义文字的UISegmentedControl
//个性推荐 歌单 主播电台 排行榜NSArray* promoteArray["个性推荐","歌单","主播电台","排行榜"];UISegmentedControl* promoteSgement[[UISegmentedControl alloc]initWithItems:promoteArray];promoteSgement.frameCGRectMake(0, 6…
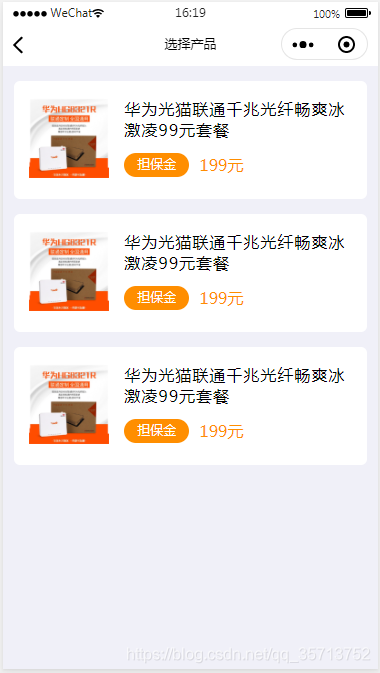
样式集(一) 通用商品列表样式
上图: 上代码: // pages/choosePackage/choosePackage.js Page({data: {list:[1,2,3],},onLoad: function (options) {},nav_upInfo(){wx.navigateTo({url: ../upInfo/upInfo,})}, }) <!--pages/choosePackage/choosePackage.wxml--> <view c…
2019 6月编程语言_今年六月您可以开始学习650项免费的在线编程和计算机科学课程...
2019 6月编程语言Seven years ago, universities like MIT and Stanford first opened up free online courses to the public. Today, more than 900 schools around the world have created thousands of free online courses, popularly known as Massive Open Online Cours…
mybatis分页练手
最近碰到个需求,要做个透明的mybatis分页功能,描述如下:目标:搜索列表的Controller action要和原先保持一样,并且返回的json需要有分页信息,如: ResponseBody RequestMapping(value"/searc…
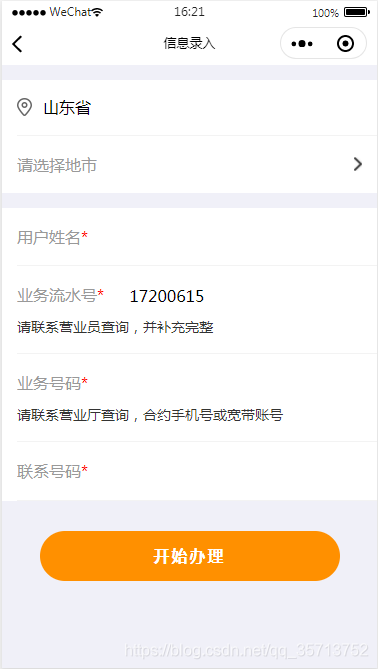
样式集(二) 信息填写样式模板
上图: 代码: // pages/upInfo/upInfo.js Page({data: {tipsTxt: "请填写正确的业务流水号",showTips: false,showCityList:false,city:"",cityList:["济南市","青岛市","枣庄市","东营市"…
12小时进制的时间输出的编辑代码
关于时间输出的编辑代码个人思考了很久,包括顺序,进位之类的,求完善和纠错 public class yunsuanfu {public static void main(String[] arg){double t2;int h38;int m100;int s100;if(s>60){m(s/60)m;ss%60;}if (m>60){h(m/60)h;mm%6…
c++每调用一次函数+1_每个开发人员都应该知道的一些很棒的现代C ++功能
c每调用一次函数1As a language, C has evolved a lot.作为一种语言,C 已经发展了很多。 Of course this did not happen overnight. There was a time when C lacked dynamism. It was difficult to be fond of the language.当然,这并非一overnight而…
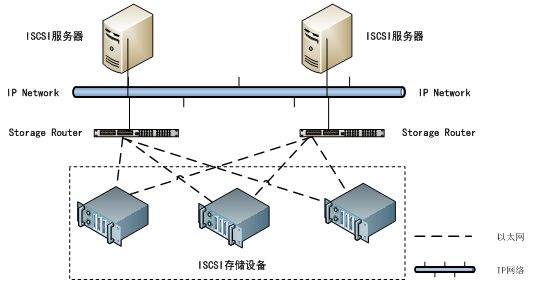
Linux ISCSI配置
一、简介 iSCSI(internet SCSI)技术由IBM公司研究开发,是一个供硬件设备使用的、可以在IP协议的上层运行的SCSI指令集,这种指令集合可以实现在IP网络上运行SCSI协议,使其能够在诸如高速千兆以太网上进行路由选择。iSCS…
样式集(三)成功页面样式模板
上图: 代码: <!--pages/result/result.wxml--> <view><image class"scc" src"/img/scc.png"></image><view class"resuil">办理成功</view> </view> <view class"btn…
C#中Request.servervariables参数
整理一下,我在asp.net下遍历的Request.servervariables这上集合,得出的所有参数如下: : Request.ServerVariables["ALL_HTTP"] 客户端发送的http所有报头信息 返回例:HTTP_CACHE_CONTROL:max-age0 HTT…
打开浏览器的包 node_如何发布可在浏览器和Node中使用的软件包
打开浏览器的包 nodeWhen you create a package for others to use, you have to consider where your user will use your package. Will they use it in a browser-based environment (or frontend JavaScript)? Will they use it in Node (or backend JavaScript)? Or bot…
存储过程中SELECT与SET对变量赋值
Create proc insert_bookparam1char(10),param2varchar(20),param3money,param4moneyoutputwith encryption---------加密asinsert into book(编号,书名,价格)Values(param1,param2,param3)select param4sum(价格) from bookgo执行例子:declare total_price moneyex…
AngularJs $resource 高大上的数据交互
$resource 创建一个resource对象的工厂函数,可以让你安全的和RESFUL服务端进行数据交互。 需要注入 ngResource 模块。angular-resource[.min].js 默认情况下,末尾斜杠(可以引起后端服务器不期望出现的行为)将从计算后的URL中剥离…

样式集(四)搜索框样式
上图: 代码: // pages/search/search.js var textPage({data: {input_val:"",list:[]},input_p(e){this.setData({input_val:e.detail.value})},onLoad: function (options) {}, }) <view classpage_row bindtap"suo"><vi…
初步了解React Native的新组件库firstBorn
first-born is a React Native UI Component Framework, which follows the design methodology Atomic Design by Brad Frost.first-born是React Native UI组件框架,它遵循Brad Frost的设计方法Atomic Design 。 Version 1.0.0 was recently published as an npm …
less里面calc() 语法
转载 Less的好处不用说大家都知道,确实让写CSS的人不在痛苦了,最近我在Less里加入calc时确发现了有点问题,我在Less中这么写: div { width : calc(100% - 30px); } 结果Less把这个当成运算式去执行了,结果…

基于XMPP的IOS聊天客户端程序(XMPP服务器架构)
最近看了关于XMPP的框架,以文本聊天为例,需要发送的消息为: <message type"chat" from"kangserver.com" to"testserver.com"> <body>helloWord</body> </message> …
小程序云开发,判断数据库表的两个字段匹配 云开发数据库匹配之 and 和 or 的配合使用
云开发数据库匹配之 and 和 or 的配合使用 代码: // 获取成员消息onMsg2() {let that thiswx.cloud.init({env: gezi-ofhmx})const DB wx.cloud.database()const _ DB.command;var aa "1"var bb "2"DB.collection(message_logging).where…
react引入多个图片_重新引入React:v16之后的每个React更新都已揭开神秘面纱。
react引入多个图片In this article (and accompanying book), unlike any you may have come across before, I will deliver funny, unfeigned and dead serious comic strips about every React update since v16. It’ll be hilarious, either intentionally or unintention…
75. Find Peak Element 【medium】
75. Find Peak Element 【medium】 There is an integer array which has the following features: The numbers in adjacent positions are different.A[0] < A[1] && A[A.length - 2] > A[A.length - 1].We define a position P is a peek if: A[P] > A[P-1…
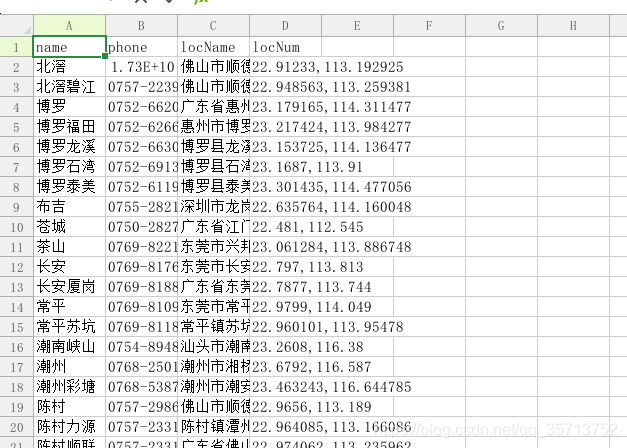
云开发地图标记导航 云开发一次性取所有数据
地图取 elx 表格的经纬度数据,存到云开发数据库里面,然后标记在地图上,点击地图的标记可以实现路线规划,导航,拨打电话。 elx数据格式如下: 云开发的数据库不能直接导入elx,所以需要转换为csv文…