如何使用FaunaDB + GraphQL
I have one or two projects I maintain on Netlify, in addition to hosting my blog there. It’s an easy platform to deploy to, and has features for content management (CMS) and lambda functions (by way of AWS).
除了在其中托管我的博客外,我在Netlify上维护一个或两个项目。 这是一个易于部署的平台,并具有内容管理(CMS)和lambda函数(通过AWS)的功能。
What I needed for my latest project, though, was a database. Netlify has integrated FaunaDB: a NoSQL, document-oriented database. Fauna has recently boasted support for GraphQL, which is a big plus. At no charge and with a simplified setup, why not try it?
不过,我最近的项目需要的是数据库。 Netlify集成了FaunaDB :一个NoSQL,面向文档的数据库。 Fauna最近夸耀了对GraphQL的支持 ,这是一个很大的优势。 免费使用简化的设置,为什么不尝试呢?
数据库 (The database)
Fauna has a unique approach to managing transactions across globally distributed data stores, so that that database records don’t get out of sync when they’re updated from points far and wide. This is a problem for global enterprises with high transaction volumes, but irrelevant for my small project.
Fauna具有一种独特的方法来管理全球分布的数据存储中的事务 ,从而使数据库记录从远处更新时也不会不同步。 对于具有高交易量的全球企业而言,这是一个问题,但与我的小项目无关。
应用程序 (The application)
I’m a chess player of middling ability and I want to set up data to do analysis of master-level chess games. SQL or NoSQL didn’t matter—I’ve worked with both and either would support my application’s modest needs.
我是中级能力的国际象棋选手,我想建立数据来分析大师级国际象棋游戏。 SQL或NoSQL无关紧要-我已经使用了两者,并且两者都可以满足我的应用程序的适度需求。
I love GraphQL, and have been using it since 2016. I don’t want my GraphQL schema exposed on the client side, though. The way around this is to have lambda functions to do the GraphQL requests, then have the client use those functions as a sort of proxy.
我喜欢GraphQL,自2016年以来一直在使用它。不过,我不希望我的GraphQL模式在客户端公开。 解决方法是让lambda函数执行GraphQL请求,然后让客户端将这些功能用作代理。
实施 (The implementation)
I started with netlify-fauna-example*. This doesn’t use GraphQL; instead the example’s Netlify Functions use FQL: Fauna Query Language. You can execute queries via fauna shell, or by using a NodeJS client module. The following uses the client to insert a todoItem into the todos collection:
我从netlify-fauna-example *开始。 这不使用GraphQL; 而是示例的Netlify函数使用FQL: 动物查询语言 。 您可以通过动物外壳或使用NodeJS客户端模块执行查询。 以下使用客户端将todoItem插入todos集合中:
todos-create.js
todos-create.js
.../* construct the fauna query */return client.query(q.Create(q.Ref('classes/todos'), todoItem)).then((response) => {console.log('success', response)/* Success! return the response with statusCode 200 */return callback(null, {statusCode: 200,body: JSON.stringify(response)})}).catch((error) => {console.log('error', error)/* Error! return the error with statusCode 400 */return callback(null, {statusCode: 400,body: JSON.stringify(error)})})To use GraphQL, I need to create a database on Fauna, and then import a GraphQL schema. Once you’ve created an account on Fauna, you can do all this through their dashboard.
要使用GraphQL,我需要在Fauna上创建一个数据库,然后导入GraphQL模式。 在Fauna上创建帐户后,您可以通过其仪表板进行所有操作。
Once done, a set of collections (akin to tables in SQL) are created based on my imported GraphQL type definitions. Interestingly, new types and fields are also added to handle stuff like identifying instances and managing relations between types. For instance, my type for Opening was:
完成后,将基于导入的GraphQL类型定义创建一组集合(类似于SQL中的表)。 有趣的是,还添加了新的类型和字段来处理诸如标识实例和管理类型之间的关系之类的事情。 例如,我的开幕类型是:
type Opening {desc: String!fen: String!SCID: String!
}and when I go to the dashboard, open GraphQL Playground, and look at the schema, I see:
当我转到仪表板时,打开GraphQL Playground并查看架构,我看到:
OpeningInput and OpeningPage were added by Fauna, in addition to the _id and _ts fields in Opening.
除了Opening中的_id和_ts字段外,Fauna还添加了OpeningInput和OpeningPage。
查询和变异 (Queries and Mutations)
There are certain queries and mutations that will be automatically implemented for you by Fauna if you define them in the schema you created. When I define the type to hold chess opening information, I may then include the following Query and Mutation definitions in my schema:
如果您在创建的架构中定义了某些查询和变异,那么Fauna将自动为您实现这些查询和变异。 当我定义的类型,以保持国际象棋开放的信息,我可以再包括我的架构下面的查询和突变的定义:
type Query {allOpenings: [Opening]
}And FaunaDB will provide an implementation.
FaunaDB将提供一个实现。
lambda函数 (lambda functions)
The original lambdas in netlify-fauna-example speak FQL. To convert these to GraphQL requests, use a fetch library such as node-fetch, and make HTTPS requests to the Fauna GraphQL endpoint using an client like the one included with apollo-boost:
netlify-fauna示例中的原始lambda 表示 FQL。 要将其转换为GraphQL请求,请使用诸如node-fetch之类的访存库,并使用apollo-boost附带的客户端向Fauna GraphQL端点发出HTTPS请求:
import ApolloClient from 'apollo-boost';
import gql from 'graphql-tag'
import fetch from 'node-fetch'
import authorization from './authorization'const URL = 'https://graphql.fauna.com/graphql'const client = new ApolloClient({uri: URL,fetch,request: operation => {operation.setContext({headers: {authorization},});},
})exports.handler = (event, context, callback) => {const allOpeningFens = gql` query openings {allOpenings {data {fen}}}`;client.query({ query: allOpeningFens }).then(results => {callback(null, {statusCode: 200,body: JSON.stringify(results),})}).catch(e => callback(e))
}The code above requests the FEN strings for all the openings in the Opening collection.
上面的代码要求Opening集合中所有开口的FEN字符串。
现在完成了吗? 没有。 (Are we done now? No.)
Fauna’s GraphQL support is in a functional but still formative stage. One of the things I wanted to do was have batch insert ability so I wouldn’t have to insert once opening at a time into the Opening collection. This mutation isn’t created by Fauna automatically (though it is ticketed feature request), so I had to define a resolver for it.
Fauna的GraphQL支持处于功能性但仍处于形成阶段。 我想做的一件事是具有批处理插入功能,因此我不必每次打开一次就将其插入到Opening集合中。 该突变不是由Fauna自动创建的(尽管它是有票证的功能请求),因此我必须为其定义解析器。
Fauna has a @resolver directive that can be used on mutation definitions. It will direct Fauna to use a user-defined function written in FQL; these can be written directly in the shell. For a collection of simple types like Opening, the resolver FQL is pretty straightforward.
Fauna具有@resolver指令,可用于突变定义。 它将指示Fauna使用以FQL编写的用户定义函数; 这些可以直接写在shell中。 对于像Opening这样的简单类型的集合,解析器FQL非常简单。
First, I go to the FaunaDB Console Shell, and create the function add_openings:
首先,我转到FaunaDB Console Shell,并创建函数add_openings :
CreateFunction({name: "add_openings",body: Query(Lambda(["openings"],Map(Var("openings"),Lambda("X", Create(Collection("Opening"), { data: Var("X") })))))Openings is an array, and the Map method executes Create call on each element. I then add a @resolver directive to my mutation definition in the schema I will import (referred to as a custom resolver):
开口是一个数组,并且Map方法对每个元素执行Create调用。 然后,在要导入的架构中的突变定义中添加一个@resolver指令(称为自定义解析器 ):
type Mutation {addOpenings(openings: [OpeningInput]) : [Opening]! @resolver(name: "add_openings" paginated:false)
}Now when the mutation is executed via the GraphQL client, add_openings is called and will insert all games passed in as a parameter to the mutation. From the GraphQL client it looks like this:
现在,当通过GraphQL客户端执行变异时,将调用add_openings并将插入作为参数传递给变异的所有游戏。 从GraphQL客户端看起来像这样:
import ApolloClient from 'apollo-boost';
import gql from 'graphql-tag'
import fetch from 'node-fetch'
import authorization from './authorization'const URL = 'https://graphql.fauna.com/graphql'const client = new ApolloClient({uri: URL,fetch,request: operation => {operation.setContext({headers: {authorization},});},
})exports.handler = (event, context, callback) => {const addScidDocs = gql`mutation($scid: [OpeningInput]) {addOpenings(openings: $scid) {desc}}`const json = JSON.parse(event.body)client.mutate({mutation: addScidDocs,variables: { scid: json },}).then(results => {console.log({ results })callback(null, {statusCode: 200,body: JSON.stringify(results),})}).catch(e => callback(e.toString()))// callback(null, { statusCode: 200, body: event.body })
}老鸡蛋问题 (The old chicken and egg problem)
You’ll notice in the mutation above that I refer to the OpeningInput type. In order for me to import my schema into Fauna, that type has to be defined. But… when I imported Opening, Fauna auto-generated that type for me. When I define it in my schema later (for the mutation), I essentially override that type. Since that generated type is used in generated mutations (ie., createOpening, singular), by overriding that type definition in my own schema I could possibly break one of the generated mutations.
您会在上面的变体中注意到,我指的是OpeningInput类型。 为了使我的架构导入Fauna,必须定义该类型。 但是……当我导入Opening时,Fauna为我自动生成了该类型。 稍后(在突变中)在架构中定义它时,我实际上将覆盖该类型。 由于该生成的类型用于生成的突变(即createOpening,单数),因此通过在我自己的模式中覆盖该类型定义,我可能会破坏其中一个生成的突变。
The solution suggested is to not override the OpeningInput type, but to rename my input type to something like MyOpeningInput. That ensures that my import schema validates, and doesn’t mess with what the generated mutations expect.
建议的解决方案是不覆盖OpeningInput类型,而将我的输入类型重命名为MyOpeningInput。 这样可以确保我的导入模式有效,并且不会与生成的突变预期的内容发生冲突。
The problem gets messier, though, when you use the @relation directive. That directive generates types used to relate two other type instances.
但是,当您使用@relation指令时,问题变得更加混乱。 该指令生成用于关联其他两个类型实例的类型。
Here’s the relation in my import schema. Note the directive:
这是我的导入模式中的关系。 注意指令:
type Game {header: Header! @relationfens: [String!]!opening: Opening @relation
}type Header {Event: StringDate: String!White: String!WhiteElo: StringBlack: String!BlackElo: StringECO: StringResult: String
}To store a Game, I need to have also a required Header (Opening is not required). The relation is maintained by a Fauna-generated ref field on the Header. It's defined for the mutation through the use of a GameHeaderRelation type that allows the creation of both Game and Header in a single mutation. Here are the relevant generated types:
要存储游戏,我还需要有一个必需的标题(不需要打开)。 该关系由Header上的Fauna生成的ref字段维护。 它是通过使用GameHeaderRelation类型为突变定义的,该类型允许在单个突变中同时创建Game和Header。 以下是相关的生成类型:
input GameHeaderRelation {create: HeaderInputconnect: ID
}input GameInput {header: GameHeaderRelationfens: [String!]!opening: GameOpeningRelation
}type Mutation {createGame(data: GameInput!): Game!
}Now to add a game with the required header info, I can call the mutation like so, from within the Playground:
现在要添加具有所需标题信息的游戏,我可以在Playground中这样调用变体:
mutation CreateGameWithHeader {createGame(data: {fens: [],header: { create: {date: "2004.10.16", white: "Morozevich, Alexander", ...} ) {_idfensheader {data {datewhite}}}
}Let' say I now want to create a mutation to batch upload multiple games. Unfortunately I don’t have access to the generated GameHeaderRelation type, or any of the other input types. My import schema won’t validate without those defined if I try to use them in my bulk mutation definition. Again, bulk mutations are a ticketed feature request, so they should be available soon. Yet this type of issue will arise regarding any custom resolver’s use of types.
假设我现在要创建一个变异,以批量上传多个游戏。 不幸的是,我无权访问生成的GameHeaderRelation类型或任何其他输入类型。 如果我尝试在批量突变定义中使用导入模式,则没有定义的导入模式将无法验证。 再次,批量突变是一项已签单的功能请求,因此应尽快提供。 但是,任何类型的自定义解析程序的使用都会出现这种类型的问题。
I though for a minute that the solution would be to download the generate schema (from Playground), then modify it with my bulk mutations. However, I am overriding __the otherwise-generated types on import, which is not what I want to happen.
尽管有一分钟,我的解决方案是(从Playground)下载生成模式,然后使用批量突变对其进行修改。 但是,我在导入时覆盖了 __否则生成的类型,这不是我想要的。
解决方法:在FQL中编写自定义解析器 (The workaround: write a custom resolver in FQL)
As stated, I need to ensure that when I create a function for my addGames resolver to call, there has to be a Header created first for each game.
如上所述,我需要确保在创建要供addGames解析程序调用的函数时,必须为每个游戏首先创建一个Header。
The GraphQL Schema resolver attribute calls the FQL add_games function:
GraphQL Schema解析器属性调用FQL add_games函数:
addGames(games: [GameInput]) : [Game]! @resolver(name: "add_games", paginated: false)And here’s the function definition for add_games:
这是add_games的函数定义:
CreateFunction({name: "add_games",body: Query(Lambda(["games"],Map(Var("games"),Lambda("X", [Create(Collection("Game"), {data: Merge(Var("X"), {header: Select(["ref"],Create(Collection("Header"), {data: Select(["header"], Var("X"))}))})})]))))
}I’m not an FQL expert (see acknowledgments), but this code is readable (from innermost outward):
我不是FQL专家(请参阅致谢),但是该代码是可读的(从最里面向外):
- creates a header instance创建一个头实例
- selects its generated reference field “ref”选择其生成的参考字段“ ref”
- merges that reference as field “header” into the a data object “X”将该引用作为字段“标头”合并到数据对象“ X”中
- “X” represents one element of the input array parameter “games” (GameInput)“ X”代表输入数组参数“ games”(GameInput)的一个元素
I should note that one of Fauna’s engineers stated that maintaining references by hand is “tricky”. It requires understanding of what is going on beneath the covers. The @embedded type of relation may be easier to implement in FQL if the relation is one-to-one, as in this case.
我应该指出,动物区系的一位工程师说, 手工维护参考是“棘手的”。 它需要了解幕后情况。 如果这种关系是一对一的,则@嵌入类型的关系可能更容易在FQL中实现。
从这往哪儿走… (Where to go from here…)
Fauna’s support team and Slack community forum members have been exceedingly helpful with questions and have even offered help with implementing FQL functions. They’re also forthcoming when onsite documentation is incomplete or wrong.
Fauna的支持团队和Slack社区论坛成员对问题的帮助非常大,甚至为实施FQL功能提供了帮助。 当现场文档不完整或不正确时,也可以使用它们。
Performance wasn’t great: the bulk insert of a 1000 small documents executed in matters of seconds, which is slow. However I didn’t use pagination in my resolvers, and that may make a significant difference. It is also possible that the GraphQL features are in a slower debuggable configuration as Fauna ramps up the feature set.
性能不是很好:在几秒钟内即可批量插入1000个小文档,这很慢。 但是,我没有在解析器中使用分页,这可能会带来很大的不同。 随着Fauna扩展功能集,GraphQL功能也可能处于较慢的可调试配置中。
To write custom resolvers, it is necessary to master FQL. Its LISPish syntax will appeal to some, but I find it verbose and “nesty”. For simple CRUD operations it is fine. You may not find yourself writing many custom resolvers, either.
要编写自定义解析器,必须掌握FQL 。 它的LISPish语法会吸引一些人,但我觉得它冗长而“笨拙”。 对于简单的CRUD操作,就可以了。 您也可能找不到编写许多自定义解析器的方法。
I chose to try Fauna not for its strengths, but for convenience. I may come back to it in a few months and see how it has progressed.
我选择尝试Fauna并不是因为其优势,而是为了方便。 我可能会在几个月后再来看看它的进展情况。
Acknowledgements
致谢
I’d like to thank Summer Schrader, Chris Biscardi, and Leo Regnier for their patience and insight.
我要感谢Summer Schrader,Chris Biscardi和Leo Regnier的耐心和见识。
* I guess my life isn’t interesting enough: when I clone a project like netlify-fauna-example, I will usually then run npm update outdated and npm audit fix. I can expect to encounter issues when I do this, but in practice I usually resolve them in an hour or two.
*我想我的生活不够有趣:当我克隆一个像netlify-fauna-example这样的项目时,通常我会运行npm update outdated和npm audit fix 。 我可以期望在执行此操作时会遇到问题,但实际上,我通常在一两个小时内解决它们。
Not this time. I deleted node_modules, package-lock.json, and even did a forced clean of the cache before reinstalling everything. Didn’t work. I eventually switched over to yarn, deleted the above (but left the updated version info in package.json alone) and installed. After a few hiccups, success! Here are the dependency versions I would up with:
这次不行。 我删除了node_modules,package-lock.json,甚至在重新安装所有内容之前都强制清除了缓存。 没用 我最终切换到yarn ,删除了以上内容(但仅在package.json中保留了更新的版本信息)并安装了。 经过几次打,,成功! 这是我要使用的依赖项版本:
"dependencies": {"apollo-boost": "^0.4.4","chess.js": "^0.10.2","encoding": "^0.1.12","faunadb": "^2.8.0","graphql": "^14.5.7","graphql-tag": "^2.10.1","node-fetch": "^2.6.0","react": "^16.9.0","react-dom": "^16.9.0","react-scripts": "^3.1.1"},"devDependencies": {"http-proxy-middleware": "^0.20.0","markdown-magic": "^1.0.0","netlify-lambda": "^1.6.3","npm-run-all": "^4.1.5"},翻译自: https://www.freecodecamp.org/news/how-to-use-faunadb/
相关文章:
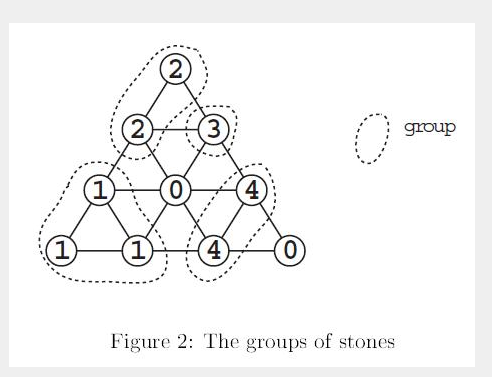
POJ 1414 Life Line(搜索)
题意: 给定一块正三角形棋盘,然后给定一些棋子和空位,棋子序号为a(1<a<9),group的定义是相邻序号一样的棋子。 然后到C(1<N<9)棋手在空位放上自己序号C的棋子, 放完后&a…

MySQL_数据库操作语句
ZC:数据库名/表名/字段名 都使用小写字母 1、 创建 数据库 和 表 的时候,都要指定 编码方式为 utf-8 ! ! ! 因为 执行命令“show variables like char%;”后可以看到 character_set_database 的值为 latin1,即 默认创建数据库是使用的 字符编…
H5打开预览PDF,PPT等文件
实现代码: pdfUrl 写你的文件路径 <iframe :src"//www.xdocin.com/xdoc?_functo&_formathtml&_cache1&_xdocpdfUrl"width"100%"height"100%"frameborder"0"> </iframe> 可以直接打开看
广播代码_代码广播:专为编码而设计的24/7音乐
广播代码阅读本文时,您可以继续阅读Code Radio。 (You can go ahead and start listening to Code Radio while you read this) Most developers I know listen to music while they code. When the meetings are over, the headphones come out.我认识的大多数开发…

从 Android 静音看正确的查bug的姿势?
0、写在前面 没抢到小马哥的红包,无心回家了,回公司写篇文章安慰下自己TT。。话说年关难过,bug多多,时间久了难免头昏脑热,不辨朝暮,难识乾坤。。。艾玛,扯远了,话说谁没踩过坑&…
SecureCRT中sqlplus,使用Backspace删除时 ^H^H
在“Session Options” - "Terminal" - "Mapped Keys" - "Other mappings",选择“Backspace sends delete”。转载于:https://www.cnblogs.com/Clark-cloud-database/p/7813867.html
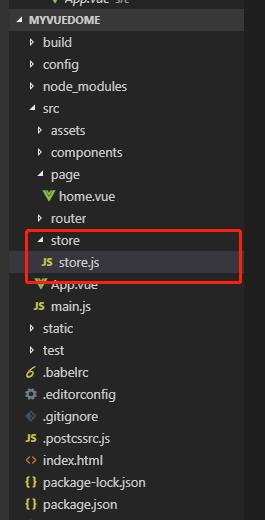
在vue中使用vuex,修改state的值示例
1、 安装 vuex npm install vuex -S 2、在目录下创建store文件 3、 在store.js编辑一个修改state的方法 然后在mian.js中全局引入 最后在组件中使用 这个的功能是运用mutations 修改state中的值
软件开发 自由职业_自由职业? 这里有7个可以出售软件开发服务的地方
软件开发 自由职业Web developers need clients. This is true whether you are a full-time freelancer or you freelance on the side.Web开发人员需要客户。 无论您是全职自由职业者,还是身旁的自由职业者,都是如此。 So if youve ever asked: "…
生成SSH key
1、打开终端,输入下面的代码 ,注意:$your_email为占位符,此处输入你自己的email ssh-keygen -t rsa -C "$your_email" 2、查看生成的公钥,输入下面的代码 cat ~/.ssh/id_rsa.pub 3、复制公钥(公钥…
[转载]二叉树(BST,AVT,RBT)
二叉查找树(Binary Search Tree)是满足如下性质的二叉树:①若它的左子树非空,则左子树上所有结点的值均小于根结点的值;②若它的右子树非空,则右子树上所有结点的值均大于根结点的值;③左、右子树本身又各是一棵二叉查…
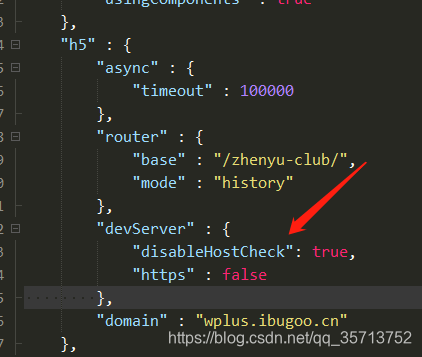
Invalid Host header 问题解决
出现该问的原因: 因为新版的 webpack-dev-server 出于安全考虑,默认检查 hostname,如果hostname不是配置内的就不能访问。 解决办法:设置跳过host检查 打开你的项目全局搜索 devServer ,在 devServer 里面添加 &quo…
react hooks使用_为什么要使用React Hooks?
react hooks使用The first thing you should do whenever youre about to learn something new is ask yourself two questions -每当您要学习新东西时,应该做的第一件事就是问自己两个问题- Why does this thing exist? 为什么这东西存在? What probl…
算法 - 字符串匹配
http://blog.csdn.net/linhuanmars/article/details/20276833 转载于:https://www.cnblogs.com/qlky/p/7817471.html
工作流入门链接
百度百科-工作流 http://baike.baidu.com/link?urlZjElBNByyZz_ItLtd_Uqt3Sadcwv0-4CDO806vKQWJDuUOFybbkzpg8GOB1EU71w8bT4x64RoRXBrFXa7o_dK 企业应用工作流的好处http://jingyan.baidu.com/article/90895e0fe9c56164ec6b0b24.html工作流管理的好处http://blog.sina.com.cn/…
uniapph5配置index.html模板路径不生效解决办法
很简单,关闭应用再重新启动试试,还不行的话,重启IDE
终端软件升级功能开发_5个很棒的终端技巧可帮助您升级为开发人员
终端软件升级功能开发There are plenty of beginner tutorials around that help you learn command line basics, such as cd, ls, pwd and so on...but what about that fancy magic youve seen more experienced developers use?周围有很多初学者教程可以帮助您学习命令行基…

自定义左右侧滑菜单
实现效果: 左右侧滑菜单,侧滑栏占主屏比为60%监听触控,自定义滑动动画,当侧边栏滑动超过50%松开触控将自动滑动到60%,未超过50%松开触控回归侧边栏隐藏为主屏设置蒙版效果,根据侧滑菜单的占屏比设置主屏蒙版…
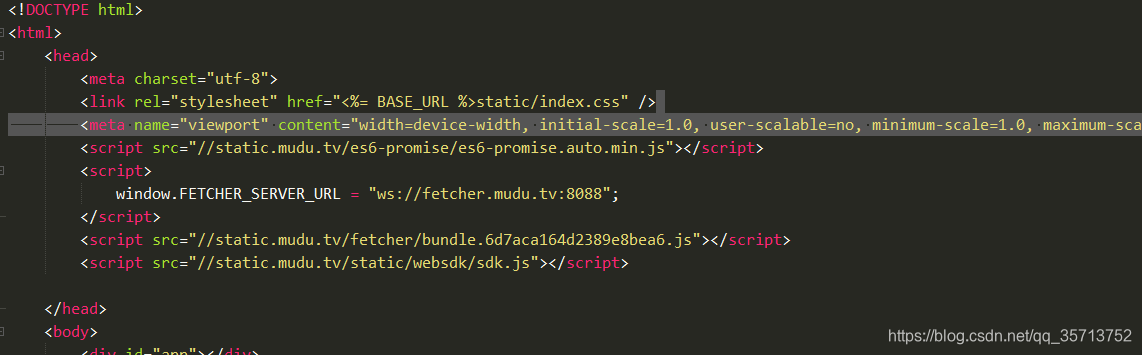
uniapp设置模板路径页面样式混乱解决办法
乱了就在html里面加上下面这行代码试试 <link rel"stylesheet" href"<% BASE_URL %>static/index.css" /> <meta name"viewport" content"widthdevice-width, initial-scale1.0, user-scalableno, minimum-scale1.0, maxim…
JavaScript获取当前日期,昨天,今天日期以及任意天数间隔日期
<script language"JavaScript" type"text/javascript"> function GetDateStr(AddDayCount) { var dd new Date(); dd.setDate(dd.getDate()AddDayCount);//获取AddDayCount天后的日期 var y dd.getYear(); var m dd.getMonth()1;//获取当前月份…
snapd_snapd使管理Nextcloud变得轻而易举
snapdAs I’ve described in both my Linux in Action book and Linux in Motion course, Nextcloud is a powerful way to build a file sharing and collaboration service using only open source software running on your own secure infrastructure. It’s DropBox, Skyp…
atitit.跨架构 bs cs解决方案. 自定义web服务器的实现方案 java .net jetty HttpListener...
atitit.跨架构 bs cs解决方案. 自定义web服务器的实现方案 java .net jetty HttpListener 1. 自定义web服务器的实现方案,基于原始socket vs 基于tcpListener vs 基于HttpListener1 2. download1 3. Lib3 4. Code3 5. HttpListener类4 6. Reef5 1. 自定义web服务器…
Python高级函数--map/reduce
名字开头大写 后面小写;练习: 1 def normalize(name): 2 return name[0].upper() name[1:].lower() 3 L1 [adam, LISA, barT] 4 L2 list(map(normalize, L1)) 5 print(L2) reduce求积: 1 from functools import reduce 2 3 def prod(…
样式集(9) - 切换Tab菜单
先上效果图 下面是以vue实现的示例代码: 代码解析: 很简单的代码,直接复制粘贴使用吧~ 别忘记一键三连哦,点赞,收藏,关注,谢谢~ 后续持续更新更多干货哦!! <temp…
python字典{:4}_Python字典101:详细的视觉介绍
python字典{:>4}欢迎 (Welcome) In this article, you will learn how to work with Python dictionaries, an incredibly helpful built-in data type that you will definitely use in your projects.在本文中,您将学习如何使用Python字典ÿ…
asp.net提交危险字符处理方法之一
在form表单提交前,可以在web页面,submit按钮的click事件中,使用js函数对,可能有危险字符的内容进行编码。 有3个函数可用: encodeURI() 函数可把字符串作为 URI 进行编码。 escape() 函数可对字符串进行编码࿰…
mysql帐号,权限管理
-> use mysql; //选择数据库 -> select host,user,password from user; //查询已有用户 -> insert into user (host,user,password) values(localhost,kiscms,password(kiscms)); //插入一个用户 -> select host,user,password from user; //再次查询用户 -> fl…
样式集(10) - 滑动删除功能实现,VUE完整源码附效果图
先看效果图 实现方式: 使用 scroll-view 标签,进行横向滑动,达到左滑出现删除按钮, 注:如果不是使用uni-app或者小程序框架,没有 scroll-view 组件的话可以通过CSS实现哦 下面看uni-app的实现代码&#…
机器学习关键的几门课程_互联网上每门机器学习课程,均按您的评论排名
机器学习关键的几门课程by David Venturi大卫文图里(David Venturi) 互联网上每门机器学习课程,均按您的评论排名 (Every single Machine Learning course on the internet, ranked by your reviews) A year and a half ago, I dropped out of one of the best com…
[POJ2104]K-th Number(区间第k值 记录初始状态)
题目链接:http://poj.org/problem?id2104 给n个数和m个查询,查询[i, j]内第k小的数是多少。(主席树、划分树那种高大上的姿势叒不会啊QAQ 可以在维护这n个数的同时维护刚刚输入的时候他们的下标,之后预处理排序一次,查…

Geant4采用make和cmake编译运行geant4自带例子的方法
该教程介绍如何将geant4中自带的例子通过camke编译成可执行文件,并运行程序。 1 在linux主目录下创建一个geant4_workdir目录,并将geant4自带的例子B1复制到该目录下,如图1所示,geant4自带的B1源文件所在目录为geant4安装目录&…