fcm和firebase_我如何最终使Netlify Functions,Firebase和GraphQL一起工作
fcm和firebase
In a previous post I confessed defeat in attempting to get an AWS Lambda GraphQL server to connect to a Firebase server. I didn’t give up right away, though, and a short time later found a different Node package to achieve what I couldn’t before.
在上一篇文章中,我承认尝试使AWS Lambda GraphQL服务器连接到Firebase服务器失败。 但是,我没有立即放弃,不久之后,又找到了另一个Node包来实现我以前无法实现的目标。
Why use AWS Lambda to host a GraphQL server? Scalability would be the obvious reason, but I did it to learn.
为什么使用AWS Lambda托管GraphQL服务器? 可伸缩性将是显而易见的原因,但是我这样做是要学习的。
我学到了很多 (And I learned a lot)
Especially when it came to deployment. I used Netlify Functions to manage the deployment of both the AWS Lambda functions and the React client that calls them. There was more to this than I originally thought.
特别是在部署时。 我使用Netlify Functions来管理AWS Lambda函数和调用它们的React客户端的部署。 这比我最初想象的要多。
There are several ways to deploy a project using Netlify:
有几种使用Netlify部署项目的方法:
邮寄并运输 (zip-it-and-ship-it)
This is a utility that works a lot like webpack: for each function, it creates an archive file which bundles the function along with its dependencies. Like webpack, it only pulls in dependencies that are actually required by the function.
这是一个非常类似于webpack 的实用程序 :对于每个功能,它都会创建一个存档文件,该文件将功能及其依赖项捆绑在一起。 与webpack一样,它只提取函数实际需要的依赖项。
Netlify expects /functions folder by convention. When writing new functions, its source is at the same level as any NodeJS modules it needs as dependencies. If you add a new function that has new module dependencies, then they go into the node_modules folder (using yarn add or npminstall --save).
Netlify按惯例要求/ functions文件夹。 编写新函数时,其源代码与它作为依赖项所需的所有NodeJS模块处于同一级别。 如果添加具有新模块依赖项的新函数,则它们将进入node_modules文件夹(使用yarn add或npm install --save )。
The following shows two lambda functions along with a single node_modules folder:
下面显示了两个lambda函数以及一个node_modules文件夹:
To use zip-it-and-ship-it, you write a simple JavaScript program that is called by the package.json build script.
要使用zip-it-and-ship-it,请编写一个简单JavaScript程序,该程序由package.json构建脚本调用。
zipIt.js
zipIt.js
const { zipFunctions } = require('@netlify/zip-it-and-ship-it')zipFunctions('functions', 'functions-dist')And this would be invoked something like so:
这将被这样调用:
package.json
package.json
"build": "npm-run-all build:*","build:app": "react-scripts build","build:functions": "node ./zipFuncs.js",Once built, several .zip files are generated . Those archives contain the function code as well as a node_modules folder which is not the original, but contains only those dependencies needed by each function:
构建完成后,将生成几个.zip文件。 这些归档文件包含功能代码以及不是原始文件的node_modules文件夹,而仅包含每个函数所需的依赖项:
netlify-lambda (netlify-lambda)
This deployment mechanism is similar to the above, but uses babel and webpack to perform its duties. If your comfortable and familiar with webpack, this might be the deployment option for you.
此部署机制与上述类似,但是使用babel和webpack来执行其职责。 如果您熟悉并熟悉webpack,那么这可能是您的部署选项。
持续部署 (continuous deployment)
The continuous deployment option is available if you’re using one of the supported repositories (GitHub, GitLab, or Bitbucket). Once you push changes to your repository, Netlify is notified and will run your build processes, which may involve zip-it-and-ship-it or netlify-lambda…but you also have the option of deploying unbundled functions to your repository, and Netlify will use zip-it-and-ship-it behind the scenes.
如果您使用受支持的存储库之一(GitHub,GitLab或Bitbucket),则可以使用持续部署选项。 将更改推送到存储库后,Netlify会收到通知,并将运行您的构建过程,该过程可能涉及zip-it-and-ship-it或netlify-lambda…,但是您还可以选择将非捆绑功能部署到存储库中,并且Netlify将在幕后使用zip-and-ship-it 。
Netlify CLI (Netlify CLI)
The Netlify CLI offers yet another way to deploy, without much fuss or mystery. There are two main deployment options:
Netlify CLI提供了另一种部署方式,无需大惊小怪。 有两个主要的部署选项:
netlify deploywill push the local project to a Netlify server. You first have to invoke the build step locally, though.netlify deploy会将本地项目推送到Netlify服务器。 不过,您首先必须在本地调用构建步骤。netlify devcreates a local server, along with a proxy to your lambda functions, and kicks off the application. It does not require a build step.netlify dev创建本地服务器以及lambda函数的代理,然后启动该应用程序。 它不需要生成步骤。
There is also a script to help you create your lambda functions: netlify function:create. If you use this method, you will get a folder structure different than shown previously:
还有一个脚本可帮助您创建lambda函数: netlify function:create 。 如果使用此方法,您将获得不同于先前显示的文件夹结构:
In this case, each function has its own folder, along with a node_modules and package.json file (plus others not shown, such as .lock files). Similar to what would be in the .zip archives that zip-it-and-ship-it creates.
在这种情况下,每个函数都有其自己的文件夹,以及一个node_modules和package.json文件(以及未显示的其他文件,例如.lock文件)。 类似于zip-it-and-ship-it创建的.zip档案中的内容。
Now, if you do generate your lambdas this way, continuous deployment will break, as zip-it-and-ship-it doesn’t handle this folder structure by itself. You can put something like this in your build script to fix continuous deployment:
现在,如果您确实以这种方式生成了lambda,则连续部署将中断,因为zip-it-and-ship-它不能单独处理此文件夹结构。 您可以在构建脚本中添加以下内容以修复连续部署:
"build": "npm-run-all build:*",
"build:app": "react-scripts build",
"build:functions": "yarn --cwd functions/func1 install",
"build:functions": "yarn --cwd functions/func2 install",These build steps will install the dependencies needed by each lambda.
这些构建步骤将安装每个lambda所需的依赖项。
这个例子 (The Example)
Your homework assignment is to set up a Netlify account and a Firebase account. The app will use Netlify Identity to login to the Netlify service. You will also need to grab a Firebase credentials JSON file and put it somewhere in your project (the example uses fake-creds.json, which is FAKE, so won’t work).
您的家庭作业是设置一个Netlify帐户和一个Firebase帐户 。 该应用程序将使用Netlify身份登录到Netlify服务。 您还需要获取Firebase凭证JSON文件并将其放在项目中的某个位置(该示例使用了fake-creds.json,即FAKE ,因此将无法使用)。
关于申请 (About the application)
Being a geek, I’m building a database of chess openings. I have an openings book in a JSON file, from which I’ll load the database. In this somewhat contrived example, the book is actually stored with the lambda function in the /functions/pgnfen folder (netlify function:create pgnfen), however the loading is triggered by the React client through a GraphQL mutation call.
作为一个极客,我正在建立国际象棋棋盘的数据库。 我有一个JSON文件中的空缺册,将从中加载数据库。 在这个人为设计的示例中,这本书实际上与lambda函数一起存储在/ functions / pgnfen文件夹中( netlify function:create pgnfen ),但是,加载是由React客户端通过GraphQL突变调用触发的。
创建lambda函数 (Creating the lambda function)
I used apollo-server-lambda add a GraphQL API frontend to the Firestore database. To talk to Firestore, I use firebase-admin. When using netlify function:create to create your function, it will ask what template to use; in this case, the correct choice is in blue:
我使用apollo-server-lambda将GraphQL API前端添加到Firestore数据库。 要与Firestore交谈,我使用firebase-admin 。 使用netlify function:create创建函数时,它将询问要使用的模板; 在这种情况下,正确的选择为蓝色:
In addition, I have added some utility functions and supporting GraphQL schema and resolvers.
此外,我添加了一些实用程序功能并支持GraphQL模式和解析器。
lambda函数 (The lambda function)
The core of the whole operation is in /functions/pgnfen.js. It creates the server, logs into firebase, makes the necessary GraphQL declarations, and finally invokes the handler function that receives requests from the client and passes them on to the database via GraphQL resolvers:
整个操作的核心在/functions/pgnfen.js 。 它创建服务器,登录到Firebase,进行必要的GraphQL声明,最后调用处理程序函数,该函数从客户端接收请求,并将它们通过GraphQL解析器传递给数据库:
/* eslint-disable no-unused-vars */
const apolloLambda = require('apollo-server-lambda');
const admin = require('firebase-admin');
const typeDefs = require('./schema.gql');
const { fetchGames, addOpenings } = require('./resolvers');const {ApolloServer,
} = apolloLambda;const credential = require('./fake-creds.json');admin.initializeApp({credential: admin.credential.cert(credential),
});const resolvers = {Query: {allGames: (root, args, context) => [], //TBD},Mutation: {addOpenings: async (root, args, context) => addOpenings(root, args, { ...context, admin }),},
};const server = new ApolloServer({typeDefs,resolvers,
});exports.handler = server.createHandler({cors: {origin: '*',credentials: true,},},
);模式 (The Schema)
The schema defines the GraphQL API. ‘Nuf said.
该模式定义了GraphQL API。 努夫说。
const typeDefs = `type Mutation {addOpenings(start: Int!, end: Int!) : Int!
}
`module.exports = typeDefs;解析器 (The resolver)
This resolves the GraphQL addOpenings mutation into Firestore queries (batched, in this case), then sends back a count of documents submitted (if successful):
这会将GraphQL addOpenings突变解析为Firestore查询(在这种情况下为批处理),然后发送回已提交的文档数(如果成功):
const openings = require('./scid.js');const addOpenings = async (_, { start, end }, { admin }) => {const db = admin.firestore();const batch = db.batch();const fens = db.collection('chess/openings/fen');const data = openings.slice(start, end);data.forEach((opening) => {const id = opening.fen.replace(/\//g, '$');const doc = fens.doc(id);batch.set(doc, opening);});await batch.commit();return data.length;
};module.exports = { addOpenings };开幕书 (The opening book)
The JSON version of the opening book consists of an SCID (an opening identifier based on ECO), as well as the opening name and its FEN. Each one becomes a document in the database.
开幕书的JSON版本由SCID(基于ECO的开幕标识符),开幕名称及其FEN组成 。 每个都成为数据库中的一个文档。
/* eslint-disable comma-dangle */
module.exports = [{SCID: 'A00b',desc: '"Barnes Opening"',fen: 'rnbqkbnr/pppppppp/8/8/8/5P2/PPPPP1PP/RNBQKBNR b KQkq - 0 1'},{SCID: 'A00b',desc: '"Fried fox"',fen: 'rnbqkbnr/pppp1ppp/8/4p3/8/5P2/PPPPPKPP/RNBQ1BNR b kq - 1 2'},{SCID: 'A00c',desc: '"Kadas Opening"',fen: 'rnbqkbnr/pppppppp/8/8/7P/8/PPPPPPP1/RNBQKBNR b KQkq h3 0 1'},...
];创建客户端 (Creating the client)
I’m using apollo-client in the React application. The easiest way to do so is create-react-app, then toss in [apollo-boost] to get a skeletal client up and running quickly. Then create a React component to trigger a call to the lambda, using the GraphQL API it provides.
我在React应用程序中使用apollo-client。 最简单的方法是create-react-app,然后折腾[apollo-boost]以使骨架客户端快速启动并运行。 然后使用它提供的GraphQL API创建一个React组件来触发对lambda的调用。
The component will provide the start/end indices of the opening book to load, and a submit button.
该组件将提供要加载的打开书的开始/结束索引,以及一个提交按钮。
Here’s a condensed version of the component code:
这是组件代码的精简版本:
/* eslint-disable no-alert */
import React, { useState } from 'react';
import fetch from 'node-fetch';
import ApolloClient, { gql } from 'apollo-boost';const styles = {
//...
};const client = new ApolloClient({uri: '/.netlify/functions/pgnfen', //the lambda URLfetch,
});export default () => {const [start, setStart] = useState(0);const [end, setEnd] = useState(5);const clickHandler = async () => {const mutation = gql`mutation {addOpenings(start: ${start}, end: ${end})}`;// eslint-disable-next-line no-consoleconst count = await client.mutate({ mutation }).catch((e) => { window.alert(e); });// console.dir(count);window.alert(`${count.data.addOpenings} documents written`);};const startEndHandler = (evt) => {if (evt.target.name === 'start') {setStart(evt.target.value);} else {setEnd(evt.target.value);}};return (
//...<input type="button" onClick={clickHandler} value="Load Scids" /> Row start: <input name="start" type="number" step="5" style={styles.numInput} onChange={startEndHandler} value={start} />
Row end: <input name="end" type="number" step="5" style={styles.numInput} onChange={startEndHandler} value={end} />
//...);
};And the mutation response will show in a window alert box:
突变响应将显示在窗口警报框中:
增加了奖励! (Added bonus!)
Since I used apollo-server-lambda as a basis for the Netlify Function, I can go directly to the service endpoint via URL and it will bring up GraphQL Playground:
由于我使用apollo-server-lambda作为Netlify功能的基础,因此我可以通过URL直接转到服务端点,它将打开GraphQL Playground:
Here I can test queries and mutations prior to embedding them in my React client code.
在这里,我可以在将查询和变异嵌入到我的React客户端代码中之前对其进行测试。
Also, invoking `netlify dev` gives me a hot server courtesy of create-react-app, so I can see result of code changes in “real” time.
另外 ,调用`netlify dev`会给我一个由create-react-app提供的热门服务器,因此我可以看到“实时”代码更改的结果。
That’s it! Here’s a link to source.
而已! 这是到source的链接。
翻译自: https://www.freecodecamp.org/news/netlify-functions-firebase-and-graphql-working-together-at-last/
fcm和firebase
相关文章:

深入了解Mvc路由系统
请求一个MVC页面的处理过程 1.浏览器发送一个Home/Index 的链接请求到iis。iis发现时一个asp.net处理程序。则调用asp.net_isapi 扩展程序发送asp.net框架 2.在asp.net的第七个管道事件中会遍历UrlRoutingModule中RouteCollection的RoteBase集合 通过调用其GetRouteData方法进行…
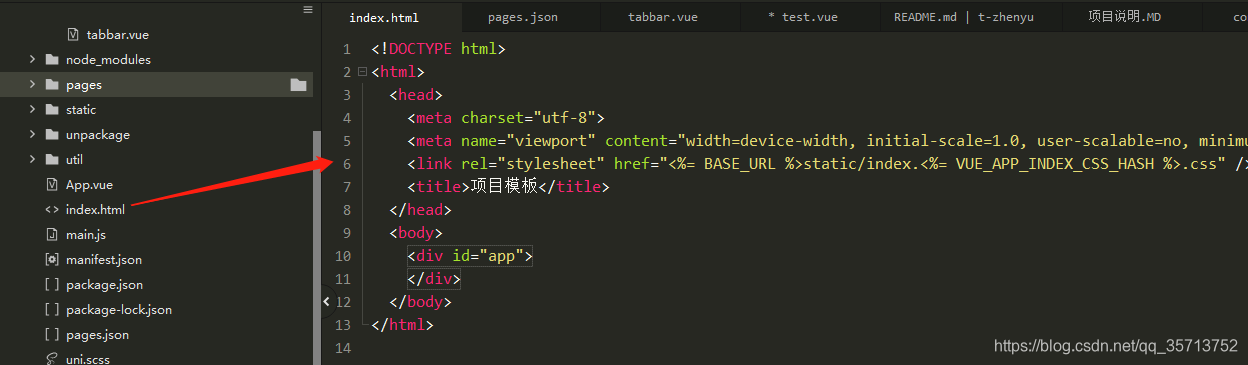
uni-app h5页面左上角出现“取消“字眼解决办法
在项目根目录的index.html中加上一行代码 <link rel"stylesheet" href"<% BASE_URL %>static/index.<% VUE_APP_INDEX_CSS_HASH %>.css" /> 如图:
unity编辑器扩展_01(在工具栏中创建一个按钮)
代码: [MenuItem("Tools/Test",false,1)] static void Test() { Debug.Log("test"); } 注意:MenuItem中第一个参数:需要创建选项在工具栏中的路径,此路径的父目录可以是Unity中已存在的,也…
postgres语法_SQL Create Table解释了MySQL和Postgres的语法示例
postgres语法A table is a group of data stored in a database.表是存储在数据库中的一组数据。 To create a table in a database you use the CREATE TABLE statement. You give a name to the table and a list of columns with its datatypes.要在数据库中创建表&#…
jquery-ajax请求:超时设置,增加 loading 提升体验
前端发送Ajax请求到服务器,服务器返回数据这一过程,因原因不同耗时长短也有差别,且这段时间内页面显示空白。如何优化这段时间内的交互体验,以及长时间内服务器仍未返回数据这一问题,是我们开发中不容忽视的重点。 常见…
第三章.SQL编程
2016年3月2日13:55:17(记忆笔记) 变量是存储数据的容器。 如何在SQL中定义自己的变量! First:第一套变量定义 整型 Declare num int Set num10 Print num 第二套变量定义 字符串类型(char varchar nvarchar) Declare name nvarchar(32) Set name’小帅’ Pri…
移动端自动播放音视频实现代码
视频组件 <video :custom-cache"false" :src"item.voideoUrl" :id"audio index" :vslide-gesture-in-fullscreen"false" :direction0 :enable-progress-gesture"false" :show-fullscreen-btn"false" loop obj…
grafana美人鱼_编码美人鱼–我如何从海洋生物学家转到前端开发人员
grafana美人鱼I have wanted to share my story for a while, but I didn’t know exactly how to start, or even what name to give it. 我想分享我的故事一段时间,但我不知道确切的开头,甚至不知道用什么名字。 But recently I was talking with som…

网络安全基础扫盲
1. 名词解释 APT 高级持续性威胁。利用先进的攻击手段对特定目标进行长期持续性网络攻击的攻击形式。其高级性主要体现在APT在发动攻击之前需要对攻击对象的业务流程和目标系统进行精确的收集。 VPN 虚拟专用网络(Virtual private network) VPN是Virtual…
Install Package and Software
svn http://tortoisesvn.sourceforge.net/ git https://download.tortoisegit.org/ http://git-for-windows.github.io/转载于:https://www.cnblogs.com/exmyth/p/5246529.html
小程序保存网络图片
小程序保存网络实现流程: 1.把图片下载到本地 2.检查用户的授权状态(三种状态:未授权,已授权,未同意授权),判断是否授权保存图片的能力,如果是用户点击了不同意授权给小程序保存图…
aws 认证_引入#AWSCertified挑战:您的第一个AWS认证之路
aws 认证You may already know that Amazon Web Services (AWS) is the largest, oldest, and most popular cloud service provider. But did you know they offer professional certifications, too?您可能已经知道Amazon Web Services(AWS)是最大,最古老和最受欢…
node!!!
node.js Node是搞后端的,不应该被被归为前端,更不应该用前端的观点去理解,去面试node开发人员。所以这份面试题大全,更侧重后端应用与对Node核心的理解。 github地址: https://github.com/jimuyouyou/node-interview-questions 注…
POJ 1556 The Doors(计算几何+最短路)
这题就是,处理出没两个点。假设能够到达,就连一条边,推断可不能够到达,利用线段相交去推断就可以。最后求个最短路就可以 代码: #include <cstdio> #include <cstring> #include <algorithm> #inclu…

* core-js/modules/es6.array.fill in ./node_modules/_cache-loader@2.0.1@cache-loader/dist/cjs.js??ref
运行Vue项目报错,报错截图如下: 导致该错误的原因是core-js版本不对: 解决方法:安装淘宝镜像 $ cnpm install core-js2 安装完成重新运行就可以了 外: 清除npm缓存命令 : npm cache clean -f
github创建静态页面_如何在10分钟内使用GitHub Pages创建免费的静态站点
github创建静态页面Static sites have become all the rage, and with good reason – they are blazingly fast and, with an ever growing number of supported hosting services, pretty easy to set up. 静态站点已成为流行,并且有充分的理由-它们非常快速&…
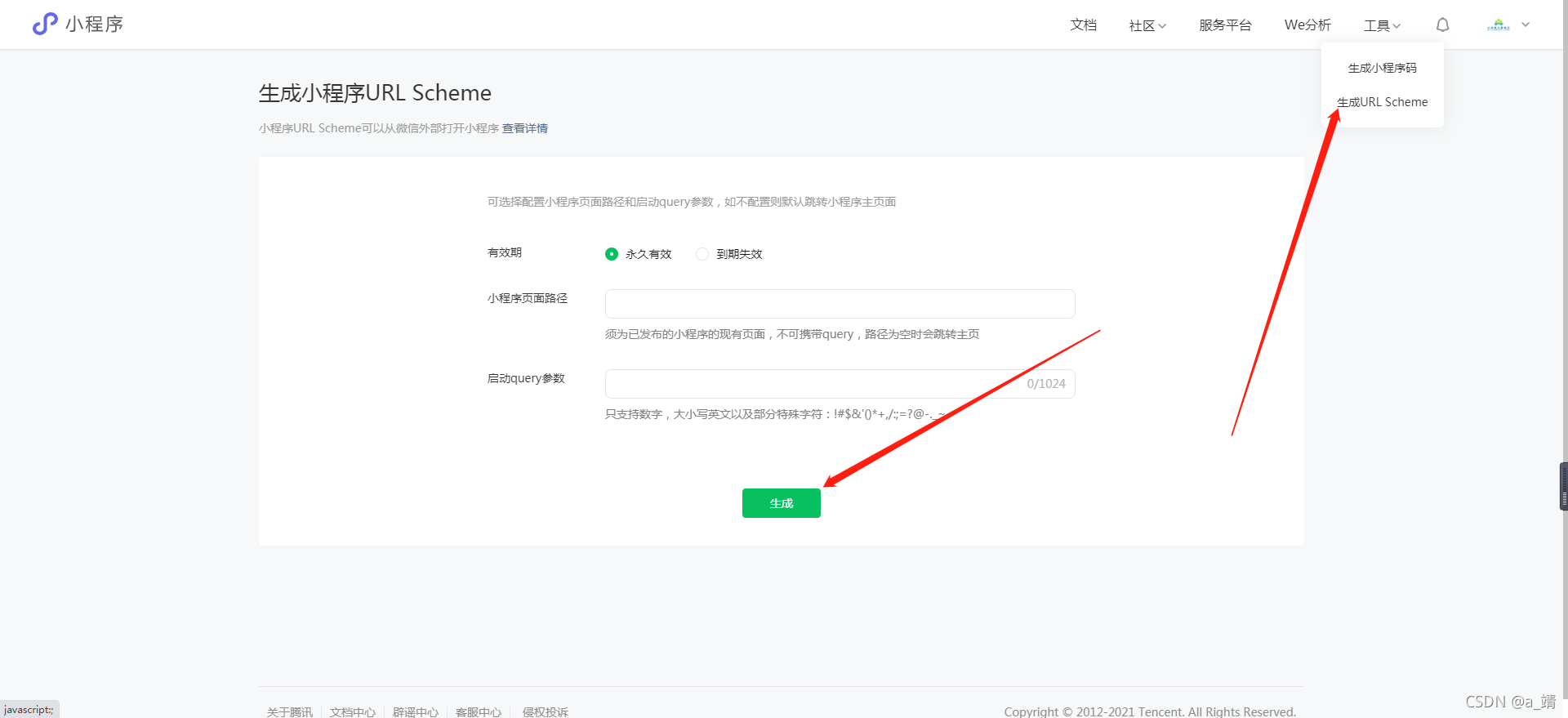
小程序生成网址链接,网址链接跳转小程序
登录小程序后台,点击右上角的工具,生成小程序URL Scheme , 可以得出一个 weixin://dl/business/?tbAXXXXX 这样的链接,点击就可以调整到小程序拉,但是这种只能在微信打开哦。

appium-chromedriver@3.0.1 npm ERR! code ELIFECYCLE npm ERR! errno 1
解决方法: npm install appium-chromedriver3.0.1 --ignore-scripts 或者(安装方法): npm install appium-chromedriver --chromedriver_cdnurlhttp://npm.taobao.org/mirrors/chromedriver 官网地址:https://www.npmj…
linux下QT Creator常见错误及解决办法
最近因为在做一个关于linux下计算机取证的小项目,需要写一个图形界面,所以想到了用QT来写,选用了linux下的集成开发环境QT Creator5.5.1,但刚刚安装好,竟然连一个"hello world"的样例都跑不起来,…
如何使用JavaScript Math.floor生成范围内的随机整数-已解决
快速解决方案 (Quick Solution) function randomRange(myMin, myMax) {return Math.floor(Math.random() * (myMax - myMin 1) myMin); }代码说明 (Code Explanation) Math.random() generates our random number between 0 and ≈ 0.9. Math.random()生成介于0和≈0.9之间的…
小白的未来与展望
新的起点,新的挑战与机遇 1.在php制作,研发上的知识点及语法编辑重点要按照老师的要求完全掌握。作为对自己以后前进方向上坚实的基础。 2.php语言开发编写上,希望能够在不久的将来能够有自己的独特的理解及研发出更多的更为简洁方便的编写方…
uniapp移动端H5在线预览PDF等文件实现源码及注解
uniapp移动端H5预览文件实现分为两个场景处理: (这里以预览PDF文件为示例,在线预览就是查看网络文件) 1. IOS客户端预览PDF文件 IOS客户端预览PDF文件可以通过跳转文件地址实现预览,因为苹果手机的浏览器自带阅读器 2. 安卓客户端预览PDF文件 安卓客户端需要在源码添…
如何使用Python和Tkinter构建Toy Markdown编辑器
Markdown editors are trending these days. Everybody is creating a markdown editor, and some of them are innovative while some of them are boring. Markdown编辑器近来呈趋势。 每个人都在创建降价编辑器,其中有些人很创新,而有些人很无聊。 A…
Hadoop 分布式环境搭建
1.集群机器: 1台 装了 ubuntu 14.04的 台式机 1台 装了ubuntu 16.04 的 笔记本 (机器更多时同样适用) 搭建步骤: 准备工作: 使两台机器处于同一个局域网:相互能够 ping 通 主机名称 …
常见报错——Uncaught TypeError: document.getElementsByClassName(...).addEventListener is not a function...
这是因为选择器没有正确选择元素对象 document.getElementsByClassName(...)捕捉到的是该类名元素的数组 正确的访问方式应该是: document.getElementsByClassName(...)[0].addEventListener... 使用遍历为每个class添加监听: var classObj document.ge…
uniapp富文本兼容视频实现方案
使用 mp-html 富文本插件,就可以支持富文本内的视频播放。 安装: npm install mp-html 使用方法 <template><view><mp-html :content"html" /></view> </template> <script>import mpHtml from /comp…
循环神经网络 递归神经网络_如何用递归神经网络预测空气污染
循环神经网络 递归神经网络After the citizen science project of Curieuze Neuzen, I wanted to learn more about air pollution to see if I could make a data science project out of it. On the website of the European Environment Agency, you can find a huge amount…
mysql like 命中索引
反向索引案例:CREATE TABLE my_tab(x VARCHAR2(20)); INSERT INTO my_tab VALUES(abcde); COMMIT;CREATE INDEX my_tab_idx ON my_tab(REVERSE(x)); SELECT * FROM my_tab t WHERE REVERSE(t.x) LIKE REVERSE(%cde);//避免使用like时索引不起作用 修改反向索引为正…
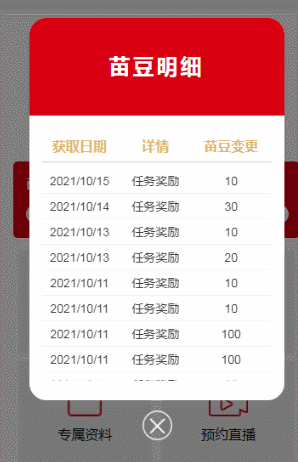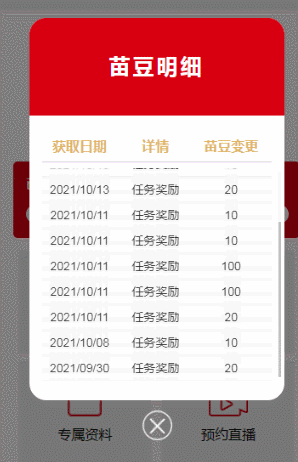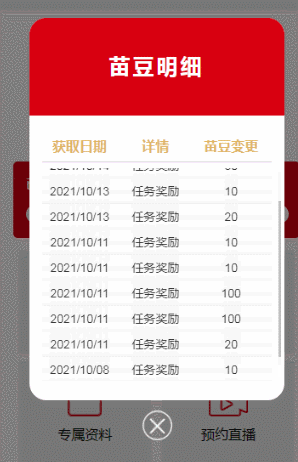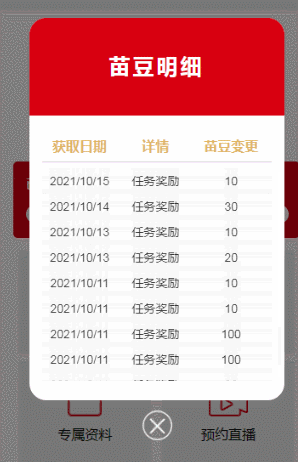
CSS超出隐藏并且能滚动
效果图 实现CSS代码: height: 500rpx; overflow-x: hidden; overflow-y: scroll; 效果图的代码: <!-- 豆豆明细弹窗 --><view class"mxBoom" v-show"mxBoom"><view class"mxBoomContent"><view c…
Oracle学习之段区块初步概念
段:一张表可以视为一个段 区:Oracle 给段分配空间的最小单位,表建好后,Oracle就会给表分配物理上连续的空间,叫做区 块:Oracle IO的最小单位,buffer cache中缓存的是dbf文件,由于dbf…