循环神经网络 递归神经网络_如何用递归神经网络预测空气污染
循环神经网络 递归神经网络
After the citizen science project of Curieuze Neuzen, I wanted to learn more about air pollution to see if I could make a data science project out of it. On the website of the European Environment Agency, you can find a huge amount of data and information about air pollution.
在Curieuze Neuzen的公民科学项目结束后 ,我想了解有关空气污染的更多信息,以查看是否可以从中进行数据科学项目。 在欧洲环境署的网站上,您可以找到有关空气污染的大量数据和信息。
In this notebook, we will focus on the air quality in Belgium, and more specifically on the pollution by sulphur dioxide (SO2). The data can be downloaded via https://www.eea.europa.eu/data-and-maps/data/aqereporting-2/be.
在本笔记本中,我们将重点关注比利时的空气质量,尤其是二氧化硫(SO2)的污染。 可以通过https://www.eea.europa.eu/data-and-maps/data/aqereporting-2/be下载数据。
The zip file contains separate files for different air pollutants and aggregation levels. The first digit represents the pollutant ID as described in the vocabulary. The file used in this notebook is BE_1_2013–2015_aggregated_timeseries.csv. This is the SO2 pollution in Belgium, but you can also find similar data for other European countries.
该zip文件包含用于不同空气污染物和聚集水平的单独文件。 第一位代表词汇表中描述的污染物ID。 该笔记本中使用的文件为BE_1_2013–2015_aggregated_timeseries.csv。 这是比利时的SO2污染,但您也可以找到其他欧洲国家的类似数据。
Descriptions of the fields in the CSV files are available on the data download page. More background information on air pollutants can be found on Wikipedia.
CSV文件中字段的描述可在数据下载页面上找到 。 有关空气污染物的更多背景信息可以在Wikipedia上找到。
项目设置 (Project Set-up)
# Importing packages
from pathlib import Path
import pandas as pd
import numpy as np
import pandas_profiling
%matplotlib inline
import matplotlib.pyplot as plt
import warnings
warnings.simplefilter(action = 'ignore', category = FutureWarning)
from sklearn.preprocessing import MinMaxScalerfrom keras.preprocessing.sequence import TimeseriesGenerator
from keras.models import Sequential
from keras.layers import Dense, LSTM, SimpleRNN
from keras.optimizers import RMSprop
from keras.callbacks import ModelCheckpoint, EarlyStopping
from keras.models import model_from_json# Setting the project directory
project_dir = Path('/Users/bertcarremans/Data Science/Projecten/air_pollution_forecasting')加载数据 (Loading the data)
date_vars = ['DatetimeBegin','DatetimeEnd']agg_ts = pd.read_csv(project_dir / 'data/raw/BE_1_2013-2015_aggregated_timeseries.csv', sep='\t', parse_dates=date_vars, date_parser=pd.to_datetime)
meta = pd.read_csv(project_dir / 'data/raw/BE_2013-2015_metadata.csv', sep='\t')print('aggregated timeseries shape:{}'.format(agg_ts.shape))
print('metadata shape:{}'.format(meta.shape))数据探索 (Data Exploration)
Let’s use pandas_profiling to inspect the data.
让我们使用pandas_profiling来检查数据。
pandas_profiling.ProfileReport(agg_ts)I won’t show the output of pandas_profiling in this story in order not to clutter it with charts. But you can find it in my GitHub repo.
我不会在这个故事中显示pandas_profiling的输出,以免使图表混乱。 但是您可以在我的GitHub存储库中找到它。
The pandas_profiling report shows us the following:
pandas_profiling报告向我们显示以下内容:
- There are 6 constant variables. We can remove these from the data set.有6个常量变量。 我们可以将它们从数据集中删除。
- No missing values exist, so probably we will not need to apply imputation.没有遗漏的值存在,因此可能我们将不需要应用估算。
AirPollutionLevel has some zeroes, but this could be perfectly normal. On the other hand, these variables have some extreme values, which might be incorrect recordings of air pollution.
AirPollutionLevel有一些零,但这可能是完全正常的。 另一方面,这些变量具有一些极端值,可能是不正确的空气污染记录。
There are 53 AirQualityStations, which are probably the same as the SamplingPoints. AirQualityStationEoICode is simply a shorter code for the AirQualityStation, so that variable can also be removed.
有53个AirQualityStation ,可能与SamplingPoints相同。 AirQualityStationEoICode只是AirQualityStation的较短代码,因此也可以删除该变量。
There are 3 values for AirQualityNetwork (Brussels, Flanders and Wallonia). Most measurements come from Flanders.
AirQualityNetwork有3个值(布鲁塞尔,法兰德斯和瓦隆)。 大多数测量来自法兰德斯。
DataAggregationProcess: most rows contain data aggregated as the 24-hour mean of one day of measurements (P1D). More information on the other values can be found here. In this project, we will only consider P1D values.
DataAggregationProcess :大多数行包含的数据汇总为一天的24小时平均值(P1D)。 有关其他值的更多信息,请参见此处 。 在此项目中,我们将仅考虑P1D值。
DataCapture: Proportion of valid measurement time relative to the total measured time (time coverage) in the averaging period, expressed as a percentage. Almost all rows have about 100% of valid measurement time. Some rows have a DataCapture that is slightly lower than 100%.
DataCapture :有效测量时间相对于平均周期中相对于总测量时间(时间覆盖)的比例,以百分比表示。 几乎所有行都有大约100%的有效测量时间。 有些行的DataCapture略低于100%。
DataCoverage: Proportion of valid measurement included in the aggregation process within the averaging period, expressed as a percentage. In this data set, we have a minimum of 75%. According to the definition of this variable values below 75% should not be included for air quality assessments, which explains why these rows are not present in the data set.
DataCoverage :平均期间内聚合过程中包含的有效度量的比例,以百分比表示。 在此数据集中,我们的最低要求为75%。 根据此变量的定义,空气质量评估不应包括低于75%的值,这解释了为什么这些行不出现在数据集中。
TimeCoverage: highly correlated to DataCoverage and will be removed from the data.
TimeCoverage :与DataCoverage高度相关,将从数据中删除。
UnitOfAirPollutionLevel: 423 rows have a unit of count. To have a consistent target variable we will remove the records with this type of unit.
UnitOfAirPollutionLevel :423行有一个计数单位。 为了获得一致的目标变量,我们将删除具有此类单位的记录。
DateTimeBegin and DateTimeEnd: the histogram does not provide enough detail here. This needs to be analyzed further.
DateTimeBegin和DateTimeEnd :直方图在此处未提供足够的详细信息。 这需要进一步分析。
DateTimeBegin和DateTimeEnd (DateTimeBegin and DateTimeEnd)
The histogram in the pandas_profiling combined multiple days per bin. Let’s look at a daily level how these variables behave.
pandas_profiling中的直方图每个bin组合了多天。 让我们每天来看一下这些变量的行为。
每个日期有多个汇总级别 (Multiple aggregation levels per date)
DatetimeBegin: a large number of records on the 1st of January of 2013, 2014, 2015 and 1st of October of 2013 and 2014.
DatetimeBegin :2013年1月1日,2014年,2015年以及2013年和2014年10月1日的大量记录。
DatetimeEnd: a large number of records on the 1st of January of 2014, 2015, 2016 and 1st of April of 2014 and 2015.
DatetimeEnd :2014年1月1日,2015年,2016年以及2014年和2015年4月1日的大量记录。
plt.figure(figsize=(20,6))
plt.plot(agg_ts.groupby('DatetimeBegin').count(), 'o', color='skyblue')
plt.title('Nb of measurements per DatetimeBegin')
plt.ylabel('number of measurements')
plt.xlabel('DatetimeBegin')
plt.show()The outliers in the number of records are related to the multiple aggregation levels (DataAggregationProcess). The values in DataAggregationProcess on these dates reflect the time period between DatetimeBegin and DatetimeEnd. For example, the 1st of January 2013 is the start date of a one-year measurement period until the 1st of January 2014.
记录数量中的异常值与多个聚合级别(DataAggregationProcess)相关。 这些日期的DataAggregationProcess中的值反映了DatetimeBegin和DatetimeEnd之间的时间段。 例如,2013年1月1日是一个为期一年的测量周期的开始日期,直到2014年1月1日为止。
As we are only interested in the daily aggregation level, filtering out the other aggregation levels will solve this issue. We can also remove DatetimeEnd for that reason.
由于我们只对每日聚合级别感兴趣,因此过滤掉其他聚合级别将解决此问题。 因此,我们也可以删除DatetimeEnd。
每日汇总级别缺少时间步 (Missing timesteps on daily aggregation level)
As we can see below, not all SamplingPoints have data for all DatetimeBegin in the three-year period. These are most likely days where the DataCoverage variable was below 75%. So on these days, we do not have sufficient valid measurements. Later in this notebook, we will use measurements on prior days to predict the pollution on the current day.
如下所示, 并非所有SamplingPoints都具有三年期内所有DatetimeBegin的数据 。 这些天最有可能是DataCoverage变量低于75%的日子。 因此,在这些天里,我们没有足够的有效度量。 在本笔记本的后面,我们将使用前几天的测量结果来预测当日的污染。
To have similarly sized timesteps, we will need to insert rows for the missing DatetimeBegin per SamplingPoint. We will insert the measurement data of the next day with valid data.
为了具有类似大小的时间步,我们将需要为每个SamplingPoint插入缺少的DatetimeBegin的行。 我们将在第二天的测量数据中插入有效数据 。
Secondly, we will remove the SamplingPoints with too many missing timesteps. Here we will take an arbitrary number of 1.000 timesteps as the minimum number of required timesteps.
其次,我们将删除缺少太多时间步长的SamplingPoints 。 在这里,我们将取任意数量的1.000个时间步作为所需的最小时间步数。
ser_avail_days = agg_ts.groupby('SamplingPoint').nunique()['DatetimeBegin']
plt.figure(figsize=(8,4))
plt.hist(ser_avail_days.sort_values(ascending=False))
plt.ylabel('Nb SamplingPoints')
plt.xlabel('Nb of Unique DatetimeBegin')
plt.title('Distribution of Samplingpoints by the Nb of available measurement days')
plt.show()资料准备 (Data Preparation)
数据清理 (Data Cleaning)
Based on the data exploration, we will do the following to clean the data:
基于数据探索,我们将执行以下操作以清理数据:
- Keeping only records with DataAggregationProcess of P1D仅使用P1D的DataAggregationProcess保留记录
- Removing records with UnitOfAirPollutionLevel of count删除具有UnitOfAirPollution计数级别的记录
- Removing unary variables and other redundant variables删除一元变量和其他冗余变量
- Removing SamplingPoints which have less than 1000 measurement days删除少于1000天的测量点
df = agg_ts.loc[agg_ts.DataAggregationProcess=='P1D', :]
df = df.loc[df.UnitOfAirPollutionLevel!='count', :]
df = df.loc[df.SamplingPoint.isin(ser_avail_days[ser_avail_days.values >= 1000].index), :]
vars_to_drop = ['AirPollutant','AirPollutantCode','Countrycode','Namespace','TimeCoverage','Validity','Verification','AirQualityStation','AirQualityStationEoICode','DataAggregationProcess','UnitOfAirPollutionLevel', 'DatetimeEnd', 'AirQualityNetwork','DataCapture', 'DataCoverage']
df.drop(columns=vars_to_drop, axis='columns', inplace=True)为缺少的时间步插入行 (Inserting rows for the missing timesteps)
For each SamplingPoint, we will first insert (empty) rows for which we do not have a DatetimeBegin. This can be done by creating a complete multi-index with all SamplingPoints and over the range between the minimum and maximum DatetimeBegin. Then, reindex will insert the missing rows but with NaN for the columns.
对于每个SamplingPoint,我们将首先插入我们没有DatetimeBegin的(空)行。 这可以通过创建一个具有所有SamplingPoints且在最小和最大DatetimeBegin之间的范围内的完整多索引来完成。 然后, reindex将插入缺少的行,但列为NaN。
Secondly, we use bfill and specify to impute the missing values with the values of the next row with valid data. The bfill method is applied to a groupby object to limit the backfilling within the rows of each SamplingPoint. That way we do not use the values of another SamplingPoint to fill in the missing values.
其次,我们使用bfill并指定使用有效数据的下一行的值来估算缺失值。 bfill方法应用于groupby对象,以限制每个SamplingPoint行中的回填。 这样,我们就不会使用另一个SamplingPoint的值来填写缺失的值。
A samplepoint to test whether this operation worked correctly is SPO-BETR223_00001_100 for the date 2013–01–29.
测试该操作是否正常工作的样本点是SPO-BETR223_00001_100 ,日期为2013–01–29 。
dates = list(pd.period_range(min(df.DatetimeBegin), max(df.DatetimeBegin), freq='D').values)
samplingpoints = list(df.SamplingPoint.unique())new_idx = []
for sp in samplingpoints:for d in dates:new_idx.append((sp, np.datetime64(d)))df.set_index(keys=['SamplingPoint', 'DatetimeBegin'], inplace=True)
df.sort_index(inplace=True)
df = df.reindex(new_idx)
#print(df.loc['SPO-BETR223_00001_100','2013-01-29']) # should contain NaN for the columnsdf['AirPollutionLevel'] = df.groupby(level=0).AirPollutionLevel.bfill().fillna(0)
#print(df.loc['SPO-BETR223_00001_100','2013-01-29']) # NaN are replaced by values of 2013-01-30
print('{} missing values'.format(df.isnull().sum().sum()))处理多个时间序列 (Handling multiple time series)
Alright, now we have a data set that is cleaned and does not contain any missing values. One aspect that makes this data set particular is that we have data for multiple samplingpoints. So we have multiple time series.
好了,现在我们有一个已清理的数据集,其中不包含任何缺失值。 使该数据集特别重要的一个方面是,我们拥有多个采样点的数据。 因此,我们有多个时间序列。
One way to deal with that is to create dummy variables for the samplingpoints and use all records to train the model. Another way is to build a separate model per samplingpoint.
一种解决方法是为采样点创建虚拟变量,并使用所有记录来训练模型。 另一种方法是为每个采样点构建一个单独的模型 。
In this notebook, we will do the latter. We will, however, limit the notebook to do that for only one samplingpoint. But the same logic can be applied to every samplingpoint.
在此笔记本中,我们将进行后者。 但是,我们将限制笔记本计算机仅对一个采样点执行此操作。 但是,可以将相同的逻辑应用于每个采样点。
df = df.loc['SPO-BETR223_00001_100',:]拆分训练,测试和验证集 (Split train, test and validation set)
We split off a test set in order to evaluate the performance of the model. The test set will not be used during the training phase.
我们分离了一个测试集,以评估模型的性能。 在训练阶段将不使用测试仪。
- train set: data until July 2014火车:截至2014年7月的数据
- validation set: 6 months between July 2014 and January 2015验证集:2014年7月至2015年1月之间的6个月
- test set: data of 2015测试集:2015年数据
train = df.query('DatetimeBegin < "2014-07-01"')
valid = df.query('DatetimeBegin >= "2014-07-01" and DatetimeBegin < "2015-01-01"')
test = df.query('DatetimeBegin >= "2015-01-01"')缩放比例 (Scaling)
# Save column names and indices to use when storing as csv
cols = train.columns
train_idx = train.index
valid_idx = valid.index
test_idx = test.index# normalize the dataset
scaler = MinMaxScaler(feature_range=(0, 1))
train = scaler.fit_transform(train)
valid = scaler.transform(valid)
test = scaler.transform(test)保存处理后的数据集 (Save the processed datasets)
That way we don’t need to redo the preprocessing every time we rerun the notebook.
这样,我们不必在每次重新运行笔记本时都重做预处理。
train = pd.DataFrame(train, columns=cols, index=train_idx)
valid = pd.DataFrame(valid, columns=cols, index=valid_idx)
test = pd.DataFrame(test, columns=cols, index=test_idx)train.to_csv('../data/processed/train.csv')
valid.to_csv('../data/processed/valid.csv')
test.to_csv('../data/processed/test.csv')造型 (Modeling)
First, we read in the processed data sets. Secondly, we create a function to plot the training and validation loss for the different models we will build.
首先,我们读入处理后的数据集。 其次,我们创建一个函数来绘制将要构建的不同模型的训练和验证损失。
train = pd.read_csv('../data/processed/train.csv', header=0, index_col=0).values.astype('float32')
valid = pd.read_csv('../data/processed/valid.csv', header=0, index_col=0).values.astype('float32')
test = pd.read_csv('../data/processed/test.csv', header=0, index_col=0).values.astype('float32')def plot_loss(history, title):plt.figure(figsize=(10,6))plt.plot(history.history['loss'], label='Train')plt.plot(history.history['val_loss'], label='Validation')plt.title(title)plt.xlabel('Nb Epochs')plt.ylabel('Loss')plt.legend()plt.show()val_loss = history.history['val_loss']min_idx = np.argmin(val_loss)min_val_loss = val_loss[min_idx]print('Minimum validation loss of {} reached at epoch {}'.format(min_val_loss, min_idx))使用TimeseriesGenerator准备数据 (Prepare data with the TimeseriesGenerator)
The TimeseriesGenerator of Keras helps us building the data in the correct format for modeling.
Keras的TimeseriesGenerator可帮助我们以正确的格式构建数据以进行建模。
length: number of timesteps in the generated sequence. Here we want to look back an arbitrary number of n_lag timesteps. In reality, n_lag could depend on how the predictions will be used. Suppose the Belgian government can take some actions to reduce the SO2 pollution around a samplingpoint (for instance prohibit the entrance of diesel cars in a city for a certain period of time). And suppose the government needs 14 days before the corrective actions can go in effect. Then it would make sense to set n_lag to 14.
length:生成的序列中的时间步数。 在这里,我们想回顾任意数量的n_lag时间步长。 实际上,n_lag可能取决于如何使用预测。 假设比利时政府可以采取一些措施来减少采样点附近的SO2污染(例如,在一段时间内禁止柴油车进入城市)。 并假设政府需要14天的时间才能采取纠正措施。 然后将n_lag设置为14。
sampling_rate: number of timesteps between successive timesteps in the generated sequence. We want to keep all timesteps, so we leave this to the default of 1.
sample_rate:所生成序列中连续时间步之间的时间步数。 我们希望保留所有时间步长,因此将其保留为默认值1。
stride: this parameter influences how much the generated sequences will overlap. As we do not have much data, we leave it to the default of 1. This means that two sequences generated after one another overlap with all timesteps except one.
步幅:此参数影响所生成序列的重叠量。 由于没有太多数据,因此将其保留为默认值1。这意味着,一个接一个生成的两个序列与除一个以外的所有时间步重叠。
batch_size: number of generated sequences in each batch
batch_size:每批中生成的序列数
n_lag = 14train_data_gen = TimeseriesGenerator(train, train, length=n_lag, sampling_rate=1, stride=1, batch_size = 5)
valid_data_gen = TimeseriesGenerator(train, train, length=n_lag, sampling_rate=1, stride=1, batch_size = 1)
test_data_gen = TimeseriesGenerator(test, test, length=n_lag, sampling_rate=1, stride=1, batch_size = 1)递归神经网络 (Recurrent Neural Networks)
Traditional neural networks have no memory. Consequently, they do not take into account previous input when processing the current input. In sequential data sets, like time series, the information of previous time steps is typically relevant for predicting something in the current step. So a state about the previous time steps needs to be maintained.
传统的神经网络没有记忆 。 因此,在处理当前输入时,它们不考虑先前的输入。 在顺序数据集(如时间序列)中,先前时间步长的信息通常与预测当前步长有关。 因此,需要保持有关先前时间步骤的状态 。
In our case, the air pollution at time t might be influenced by air pollution in previous timesteps. So we need to take that into account. Recurrent Neural Networks or RNNs have an internal loop by which they maintain a state of previous timesteps. This state is then used for the prediction in the current timestep. The state is reset when a new sequence is being processed.
在我们的案例中,时间t处的空气污染可能会受到先前时间步长中空气污染的影响。 因此,我们需要考虑到这一点。 递归神经网络或RNN具有一个内部循环,通过它们可以保持先前时间步的状态。 然后将此状态用于当前时间步的预测。 处理新序列时,将重置状态。
For an illustrated guide about RNNs, you should definitely read the article by Michael Nguyen.
有关RNN的插图指南,您绝对应该阅读Michael Nguyen的文章 。
For our case, we use a SimpleRNN of the Keras package. We also specify an EarlyStopping callback to stop the training when there were 10 epochs without any improvement in the validation loss. The ModelCheckpoint allows us to save the weights of the best model. The model architecture still needs to be saved separately.
对于我们的情况,我们使用Keras包的SimpleRNN 。 我们还指定了EarlyStopping回调,以在10个纪元时停止训练,而验证损失没有任何改善。 通过ModelCheckpoint ,我们可以节省最佳模型的权重。 模型架构仍然需要单独保存。
simple_rnn = Sequential()
simple_rnn.add(SimpleRNN(4, input_shape=(n_lag, 1)))
simple_rnn.add(Dense(1))
simple_rnn.compile(loss='mae', optimizer=RMSprop())checkpointer = ModelCheckpoint(filepath='../model/simple_rnn_weights.hdf5', verbose=0, save_best_only=True)
earlystopper = EarlyStopping(monitor='val_loss', patience=10, verbose=0)
with open("../model/simple_rnn.json", "w") as m:m.write(simple_rnn.to_json())simple_rnn_history = simple_rnn.fit_generator(train_data_gen, epochs=100, validation_data=valid_data_gen, verbose=0, callbacks=[checkpointer, earlystopper])
plot_loss(simple_rnn_history, 'SimpleRNN - Train & Validation Loss')长期短期记忆网络 (Long Short Term Memory Networks)
An RNN has a short memory. It has difficulty remembering information from many timesteps ago. This occurs when the sequences are very long.
RNN的记忆力很差 。 它很难记住许多时间之前的信息。 当序列很长时会发生这种情况。
In fact, it is due to the vanishing gradient problem. The gradients are values that update the weights of a neural network. When you have many timesteps in your RNN the gradient for the first layers becomes very tiny. As a result, the update of the weights of the first layers is negligible. This means that the RNN is not capable of learning what was in the early layers.
实际上,这是由于梯度消失的缘故。 梯度是更新神经网络权重的值。 当您的RNN中有许多时间步长时,第一层的梯度会变得非常小。 结果,第一层的权重的更新可忽略不计。 这意味着RNN无法学习早期阶段的内容。
So we need a way to carry the information of the first layers to later layers. LSTMs are better suited to take into account long-term dependencies. Michael Nguyen wrote an excellent article with a visual description of LSTMs.
因此,我们需要一种将第一层的信息传递到后续层的方法。 LSTM更适合考虑长期依赖性。 Michael Nguyen撰写了一篇出色的文章, 对LSTM进行了直观描述 。
简单的LSTM模型 (Simple LSTM model)
simple_lstm = Sequential()
simple_lstm.add(LSTM(4, input_shape=(n_lag, 1)))
simple_lstm.add(Dense(1))
simple_lstm.compile(loss='mae', optimizer=RMSprop())checkpointer = ModelCheckpoint(filepath='../model/simple_lstm_weights.hdf5', verbose=0, save_best_only=True)
earlystopper = EarlyStopping(monitor='val_loss', patience=10, verbose=0)
with open("../model/simple_lstm.json", "w") as m:m.write(simple_lstm.to_json())simple_lstm_history = simple_lstm.fit_generator(train_data_gen, epochs=100, validation_data=valid_data_gen, verbose=0, callbacks=[checkpointer, earlystopper])
plot_loss(simple_lstm_history, 'Simple LSTM - Train & Validation Loss')堆叠式LSTM模型 (Stacked LSTM model)
In this model, we will be stacking multiple LSTM layers. That way the model will learn other abstractions of input data over time. In other words, representing the input data at different time scales.
在此模型中,我们将堆叠多个LSTM层。 这样,模型将随着时间的推移学习输入数据的其他抽象。 换句话说, 以不同的时标表示输入数据 。
To do that in Keras, we need to specify the parameter return_sequences in the LSTM layer preceding another LSTM layer.
为此,在Keras中,我们需要在另一个LSTM层之前的LSTM层中指定参数return_sequences 。
stacked_lstm = Sequential()
stacked_lstm.add(LSTM(16, input_shape=(n_lag, 1), return_sequences=True))
stacked_lstm.add(LSTM(8, return_sequences=True))
stacked_lstm.add(LSTM(4))
stacked_lstm.add(Dense(1))
stacked_lstm.compile(loss='mae', optimizer=RMSprop())checkpointer = ModelCheckpoint(filepath='../model/stacked_lstm_weights.hdf5', verbose=0, save_best_only=True)
earlystopper = EarlyStopping(monitor='val_loss', patience=10, verbose=0)
with open("../model/stacked_lstm.json", "w") as m:m.write(stacked_lstm.to_json())stacked_lstm_history = stacked_lstm.fit_generator(train_data_gen, epochs=100, validation_data=valid_data_gen, verbose=0, callbacks=[checkpointer, earlystopper])
plot_loss(stacked_lstm_history, 'Stacked LSTM - Train & Validation Loss')绩效评估 (Evaluating Performance)
Based on the minimum validation losses the SimpleRNN seems to outperform the LSTM models, although the metrics are close to each other.
基于最小的验证损失,尽管指标彼此接近,但SimpleRNN似乎胜过LSTM模型。
With the evaluate_generator method, we can evaluate the models on the test data (generator). This will give us the loss on the test data. We will first load the model architecture from the JSON files and the best model’s weights.
使用valuate_generator方法,我们可以根据测试数据(生成器)评估模型。 这将使我们损失测试数据。 我们将首先从JSON文件和最佳模型的权重中加载模型架构。
def eval_best_model(model):# Load model architecture from JSONmodel_architecture = open('../model/'+model+'.json', 'r')best_model = model_from_json(model_architecture.read())model_architecture.close()# Load best model's weightsbest_model.load_weights('../model/'+model+'_weights.hdf5')# Compile the best modelbest_model.compile(loss='mae', optimizer=RMSprop())# Evaluate on test dataperf_best_model = best_model.evaluate_generator(test_data_gen)print('Loss on test data for {} : {}'.format(model, perf_best_model))eval_best_model('simple_rnn')
eval_best_model('simple_lstm')
eval_best_model('stacked_lstm')- Loss on test data for simple_rnn: 0.01638169982337905simple_rnn的测试数据损失:0.01638169982337905
- Loss on test data for simple_lstm: 0.015934137431135205simple_lstm的测试数据损失:0.015934137431135205
- Loss on test data for stacked_lstm: 0.015420083056716116stacked_lstm的测试数据损失:0.015420083056716116
结论 (Conclusion)
In this story, we used a Recurrent Neural Network and two different architectures for an LSTM. The best performance comes from the stacked LSTM consisting of a few hidden layers.
在这个故事中,我们为LSTM使用了递归神经网络和两种不同的体系结构。 最佳性能来自由几个隐藏层组成的堆叠LSTM 。
There are definitely a number of things worth investigating further that could improve the model's performance.
肯定有很多值得进一步研究的事情可以改善模型的性能。
Use the hourly data (another CSV file available on the EEA website) and try out other sampling strategies than the daily data.
使用每小时数据(EEA网站上的另一个CSV文件),并尝试除每日数据外的其他抽样策略 。
Use the data about the other pollutants as features to predict SO2 pollution. Perhaps other pollutants are correlated to the SO2 pollution.
使用有关其他污染物的数据作为预测SO2污染的特征。 也许其他污染物与二氧化硫污染有关。
Construct other features based on the date. A nice write-up can be found in the PDF of one of the winners of the Power Laws Forecasting competition of Driven Data.
根据date构造其他功能 。 在《 驱动数据的幂定律预测》竞赛的获奖者之一的PDF中可以找到不错的文章。
I’ve learned a lot about recurrent neural networks by doing this project. I hope you’ve enjoyed it. Feel free to leave any comments!
通过完成这个项目,我已经学到了很多有关递归神经网络的知识。 希望您喜欢它。 随时留下任何评论!
翻译自: https://www.freecodecamp.org/news/forecasting-air-pollution-recurrent-neural-networks/
循环神经网络 递归神经网络
相关文章:

mysql like 命中索引
反向索引案例:CREATE TABLE my_tab(x VARCHAR2(20)); INSERT INTO my_tab VALUES(abcde); COMMIT;CREATE INDEX my_tab_idx ON my_tab(REVERSE(x)); SELECT * FROM my_tab t WHERE REVERSE(t.x) LIKE REVERSE(%cde);//避免使用like时索引不起作用 修改反向索引为正…
CSS超出隐藏并且能滚动
效果图 实现CSS代码: height: 500rpx; overflow-x: hidden; overflow-y: scroll; 效果图的代码: <!-- 豆豆明细弹窗 --><view class"mxBoom" v-show"mxBoom"><view class"mxBoomContent"><view c…
Oracle学习之段区块初步概念
段:一张表可以视为一个段 区:Oracle 给段分配空间的最小单位,表建好后,Oracle就会给表分配物理上连续的空间,叫做区 块:Oracle IO的最小单位,buffer cache中缓存的是dbf文件,由于dbf…
github充当服务器_如何创建充当链接HTML按钮
github充当服务器Sometimes you may want to use a button to link to another page or website rather than to submit a form or something like that. This is fairly simple to do and can be achieved in several ways.有时,您可能希望使用按钮链接到另一个页面…
provide和inject,Vue父组件直接给孙子组件传值
Provide / Inject 该页面假设你已经阅读过了组件基础。如果你还对组件不太了解,推荐你先阅读它。 通常,当我们需要从父组件向子组件传递数据时,我们使用 props。想象一下这样的结构:有一些深度嵌套的组件,而深层的子组…
用欧几里得算法求最大公约数_欧几里得算法:GCD(最大公约数),用C ++和Java示例解释...
用欧几里得算法求最大公约数For this topic you must know about Greatest Common Divisor (GCD) and the MOD operation first.对于本主题,您必须首先了解最大公约数(GCD)和MOD操作。 最大公约数(GCD) (Greatest Common Divisor (GCD)) The GCD of two or more in…

eclipse 重启/打开内置浏览器
重启 Eclipse 重启选项允许用户重启 Eclipse。 我们可以通过点击 File 菜单选择 Restart 菜单项来重启 Eclipse。 Eclipse 内置浏览器 Web 浏览器 Eclipse 系统内部自带了浏览器,该浏览器可以通过点击 Window 菜单并选择 Show View > Other,在弹出来的…

JConsole的使用
一、JConsole是什么 从Java 5开始 引入了 JConsole。JConsole 是一个内置 Java 性能分析器,可以从命令行或在 GUI shell 中运行。您可以轻松地使用 JConsole(或者,它更高端的 “近亲” VisualVM )来监控 Java 应用程序性能和跟踪 …

折线图表动画(历史进程效果)
代码环境:uniapp 秋云uCharts图表组件https://demo.ucharts.cn/#/代码说明: 在插件市场导入插件秋云 ucharts echarts 高性能跨全端图表组件 - DCloud 插件市场uCharts v2.3上线,支持nvue!全新官方图表组件,支持H5及APP用ECharts渲染图表,uniapp可视化首选组件

不要只是为您的代码做些毛-用Prettier修复它
Linting makes our lives easier because it tells us what’s wrong with our code. But how can we avoid doing the actual work that goes into fixing it?Linting使我们的生活更轻松,因为它告诉我们代码有什么问题。 但是,如何避免进行修复工作呢&…
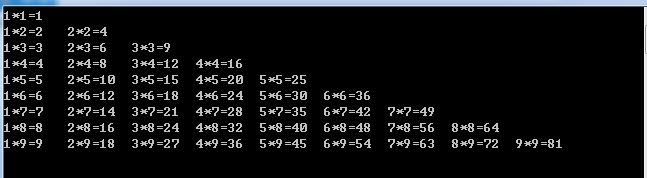
循环语句(2)
for的嵌套 //99乘法表for (int a 1; a < 9; a)-----控制行{for (int i 1; i < a; i)------控制列{Console.Write(i "*" a "" (a * i) "\t");}Console.WriteLine();}Console.ReadLine(); 结果 打印星号 //直角在左上for (int i …
通过Shell脚本将VSS项目批量创建并且提交迁移至Gitlab
脚本运行环境:Git Bash 系统环境:Windows 10 Pro 1709 VSS版本:Microsoft Visual SourceSafe 2005 我的VSS工作目录结构如下: D:\work\ --vss ----project1 ------src ------README.md ------ ...... ----project2 ------doc ----…
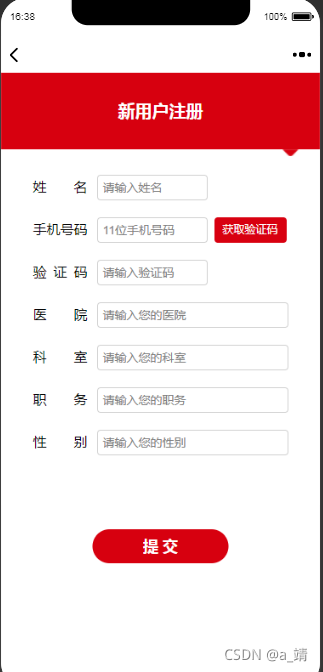
样式集(11)注册页面样式,全部代码附效果图
效果图: 代码: <template><view class"page"><view class"top">新用户注册</view><image :src"sanjiao" mode"widthFix" class"sanjiao"></image><!-- <…
quickselect_QuickSelect:使用代码示例解释的快速选择算法
quickselect什么是QuickSelect? (What is QuickSelect?) QuickSelect is a selection algorithm to find the K-th smallest element in an unsorted list.QuickSelect是一种选择算法,用于在未排序的列表中查找第K个最小的元素。 算法说明 (The Algori…
《Linux命令行与shell脚本编程大全 第3版》Shell脚本编程基础---34
以下为阅读《Linux命令行与shell脚本编程大全 第3版》的读书笔记,为了方便记录,特地与书的内容保持同步,特意做成一节一次随笔,特记录如下:转载于:https://www.cnblogs.com/guochaoxxl/p/7894620.html
CSS超出部分隐藏,显示滚动条
实现功能: 固定一个高度,超出该高度的部分就隐藏,并且显示滚动条能上拉下滑滚动 实现代码: height: 500rpx; overflow-x: hidden; overflow-y: scroll; 实现功能: 固定一个宽度,超出该宽度的部分就隐藏…
第二周学习进度
好久的编程实现,居然没有编完整,看来自己需要加班学习了!第二周学习进度如下: 第二周所花时间(包括上课)共计21小时代码量(行)220博客量(篇)4了解到的知识 1.…
如何在C ++中从容器中删除元素
How to remove elements from container is a common C interview question, so you can earn some brownie points if you read this page carefully. 如何从容器中删除元素是C 常见的面试问题,因此,如果仔细阅读此页,可以赚取布朗尼积分。 …
【BZOJ4282】慎二的随机数列 乱搞
【BZOJ4282】慎二的随机数列 Description 间桐慎二是间桐家著名的废柴,有一天,他在学校随机了一组随机数列, 准备使用他那强大的人工智能求出其最长上升子序列,但是天有不测风云,人有旦夕祸福,柳洞一成路过…
git phpstorm 配置
http://jingyan.baidu.com/album/a948d65105faed0a2dcd2ea2.html?stepindex2&st2&os0&bd_page_type1&net_type3 http://jingyan.baidu.com/article/20095761cbef40cb0721b417.html转载于:https://www.cnblogs.com/fyy-888/p/5272862.html
CSS动画无限循环
实现代码 div{animation:myanimation 5s infinite; }keyframes myanimation {from {top:0px;}to {top:200px;} } 注:animation ->Css3动画属性 myanimation->随便命名 infinite 可重复 ,去掉就不重复了 top可以改为宽高,或者方向等等任何CSS属性 form 开始 to结束…
apple id无法创建_我如何为我的Apple收藏夹创建网站
apple id无法创建A while ago I started an Apple collection. Ive been following Apple hardware (and its aesthetics) since I was a teenager, but at that time I didnt the have money to own a Mac. 前一段时间,我开始了一个苹果系列。 从我十几岁起我就一直…

bzoj1562[NOI2009]变换序列——2016——3——12
任意门:http://www.lydsy.com/JudgeOnline/problem.php?id1562 题目: 对于0,1,…,N-1的N个整数,给定一个距离序列D0,D1,…,DN-1,定义一个变换序列T0,T1,…,TN-1使得每个i,Ti的环上距离等于Di。一个合法的变换序列应是0,1,…,N-1的…
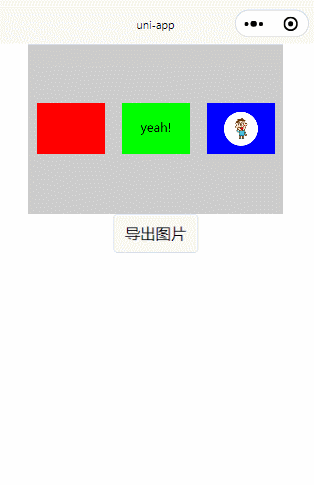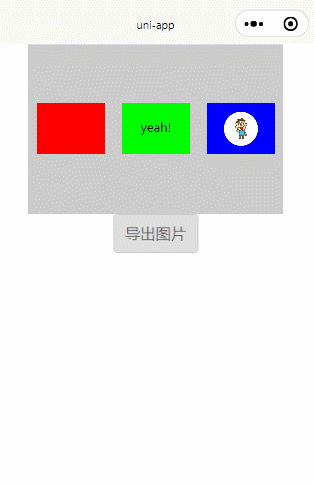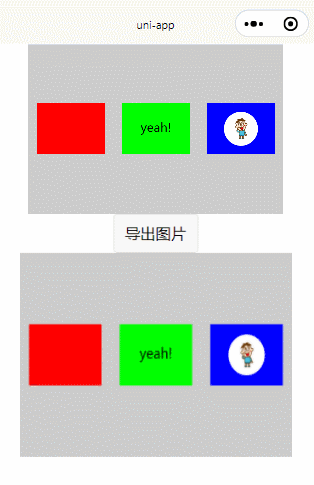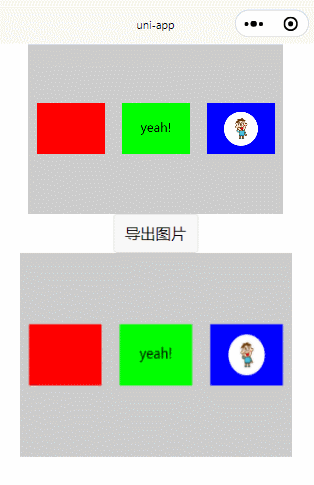
把view或者div绘制 canvas ,导出图片功能实现完整源码附效果图(兼容H5和小程序)
先看下效果图:(上面灰色块内的用div和CSS写出来的,然后绘制到canvas) 实现此功能需要使用到一个微信小程序的插件,插件官方文档地址: wxml-to-canvas | 微信开放文档 本博客代码环境,uniapp&a…
C 语言中的 switch 语句 case 后面是否需要加大括号
事件原由为编辑器的自动缩进,当 case 换行后不自动缩进。 于是在在想可以可否在 case 后面再大括号,让其自动缩进。 查了资料,发现 case 是可以加大括号的,相当于代码块。 而且还有另外一个用途,可以代码块头部定义变量…
问题 c: 插入排序_插入排序:它是什么,以及它如何工作
问题 c: 插入排序Insertion sort is a simple sorting algorithm for a small number of elements.插入排序是一种针对少量元素的简单排序算法。 例: (Example:) In Insertion sort, you compare the key element with the previous elements. If the previous ele…

在Java连接hbase时出现的问题
问题1: java.net.ConnectException: Connection refused: no further information zookeeper.ClientCnxn: Session 0x0 for server null zookeeper未启动,或无法连接,从查看各节点zookeeper启动状态、端口占用、防火墙等方面查看原因。问题2&…
codeforces 8C. Looking for Order 状压dp
题目链接 给n个物品的坐标, 和一个包裹的位置, 包裹不能移动。 每次最多可以拿两个物品, 然后将它们放到包里, 求将所有物品放到包里所需走的最小路程。 直接状压dp就好了。 #include <iostream> #include <vector> #…
H5刷新当前页面
location.reload();
sql的外键约束和主键约束_SQL主键约束用示例解释
sql的外键约束和主键约束A primary key is a column or a set of columns that uniquely identifies each row in a table.主键是一列或一组列,它们唯一地标识表中的每一行。 It’s called a “constraint” because it causes the system to restrict the data al…