Linux NUMA 架构 :基础软件工程师需要知道一些知识
文章目录
- 前言
- 从物理CPU、core到HT(hyper-threading)
- UMA(Uniform memory access)
- NUMA架构
- NUMA下的内存分配策略
- 1. MPOL_DEFAULT
- 2. MPOL_BIND
- 3. MPOL_INTERLEAVE
- 4. MPOL_PREFERRED
- 5. 一些NUMA架构下的内核配置
- 总结
- 参考
前言
NUMA(Non-Uniform memory access)非一致性内存访问 作为当下新型的硬件架构,其对操作系统CPU和内存资源整合的底层实现细节是作为分布式存储/数据库研发的工程师需要掌握得一种技术。这样,我们才能够在这一些架构以及更新的存储介质(AEP/BPS)之上开发出性能更友好的基础软件。
通过本篇 你能够知道如下几个关于NUMA的知识:
- NUMA 出现的缘由
- NUMA 的基本架构 及 相关工具
- NUMA 的几种内存模式
从物理CPU、core到HT(hyper-threading)
我们的CPU是在服务器主板之上,十几年前的一个物理CPU只会有一个物理核心(core),因为主板就这么大,不能再增加物理CPU的个数了,为了提升CPU性能,硬件厂商只能在物理CPU基础上增加物理核心数目,由单core到2个、4个。。。为了进一步利用好core资源,Intel以及其他芯片厂商开发了超线程(hyper-threading)技术,来让一个物理core能够运行2个内核线程,从而产生了逻辑核(processor)的概念。
在linux相关的系统可以通过如下指令查看相关的指标:
- 查看物理CPU数目:
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l - 查看core数目:
cat /proc/cpuinfo | grep "cpu cores" | uniq - 查看总的逻辑核的数目:
cat /proc/cpuinfo| grep "processor"| wc -l - 查看cpu型号:
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
以上相关指标也可以直接通过命令lscpu看到,正因为CPU的算力越来越高,我们不能让算力资源浪费,应该尽己所能让cpu每时每刻都能够释放自己强大的算力,这也是NUMA架构的出现的主要原因,为了更好得展现这个过程,可以继续向下看。
UMA(Uniform memory access)
在介绍NUMA之前,肯定是需要先了解一下一致性内存访问UMA 的设计,这里的介绍能够告诉你为什么系统硬件架构会演化成当前NUMA这样架构。
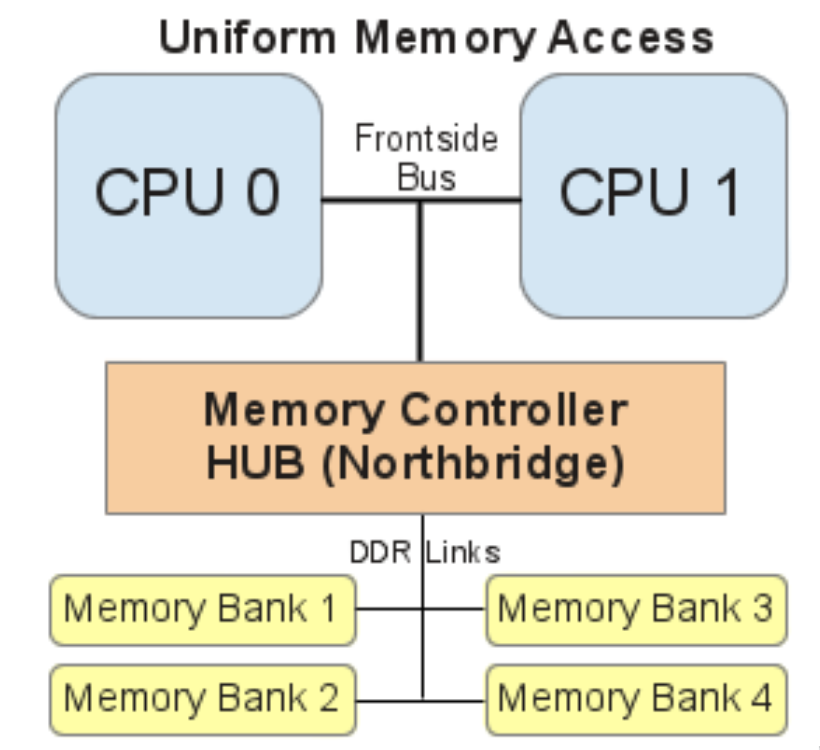
如上图,是NUMA架构之前的CPU访问内存的方式。在主板上的两个物理CPU 通过前端总线链接,来同步各自内部的cpu cache的数据,当cpu要访问的数据不在cpu cache中,则需要通过北桥控制器 以及与其链接的数据地址总线访问内存。
随着CPU物理core增加以及HT技术的产生,这么多core的数据访问都需要通过共享的frontside bus以及北桥控制器来访问内存,这个时候的frontside bus便成为了CPU性能的瓶颈。
NUMA架构
这个时候通过引入NUMA架构,来提升CPU对内存访问的效率。
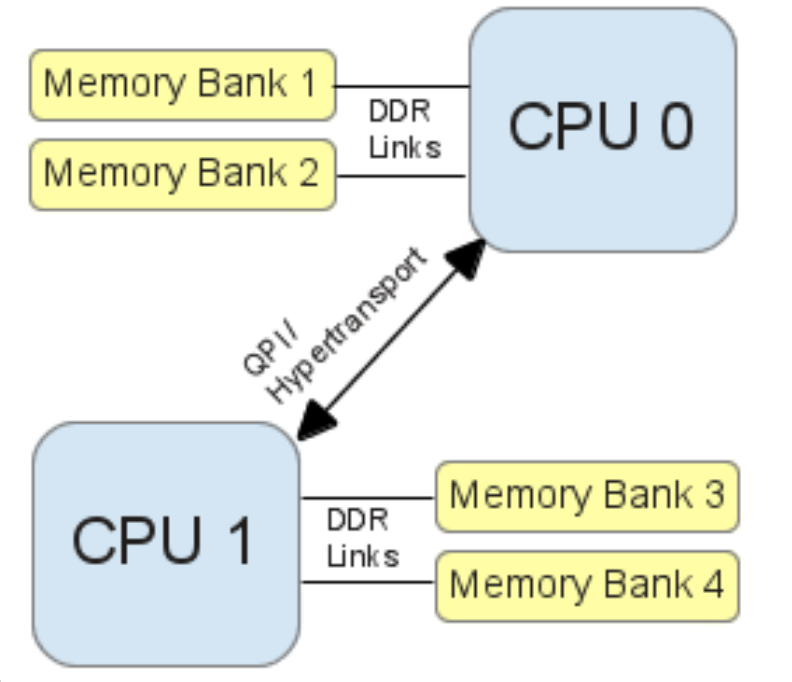
如上图,物理CPU之间通过QPI进行通信,而内存插槽则设置到各自CPU附近,去掉了北桥控制器,物理CPU直接通过数据总线来访问内存,这个架构下整个CPU访存可以横向扩展了,物理CPU的个数可以增加,且只需要为其设置相临近的可访问内存就可以了。
但也会引入一些问题,这个时候对于CPU1 ,内存条3和4就距离自己比较近,而内存条1和2 就距离自己比较远了。也就是NUMA架构引入了针对内存访问的local 和 remote概念。

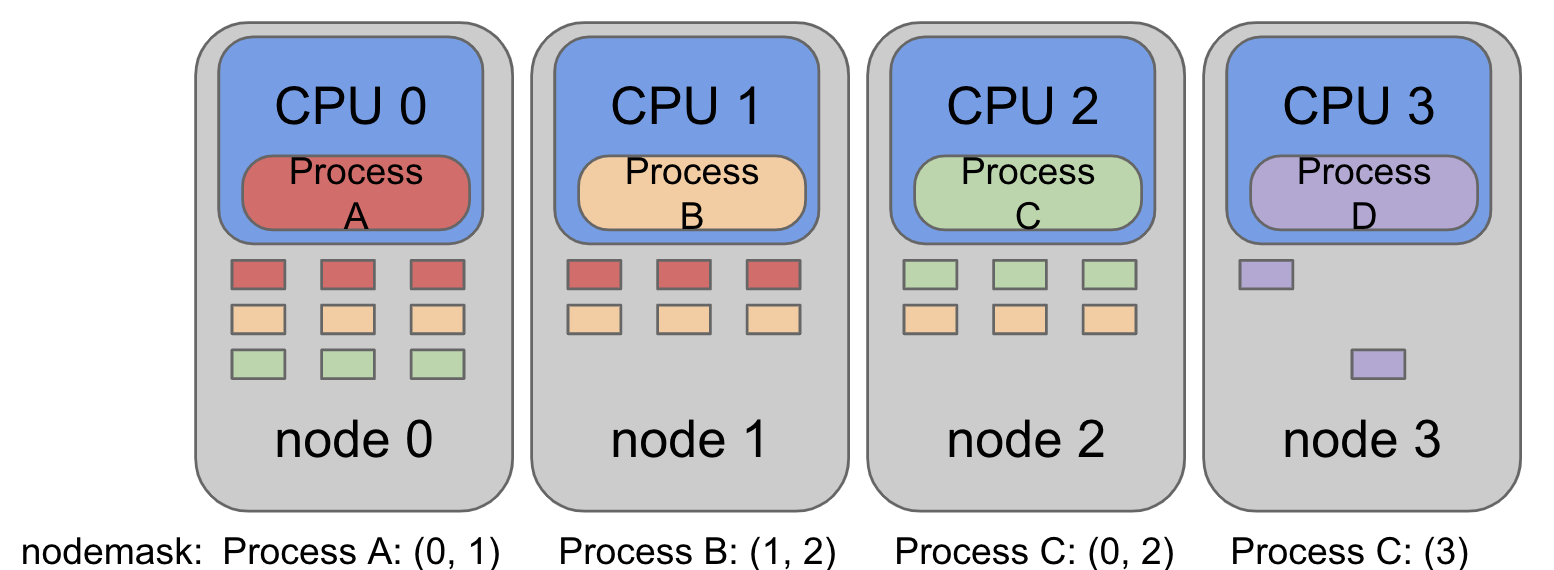
通过下图来更进一步得了解一下NUMA架构下cpu访问内存的remote和local方式:
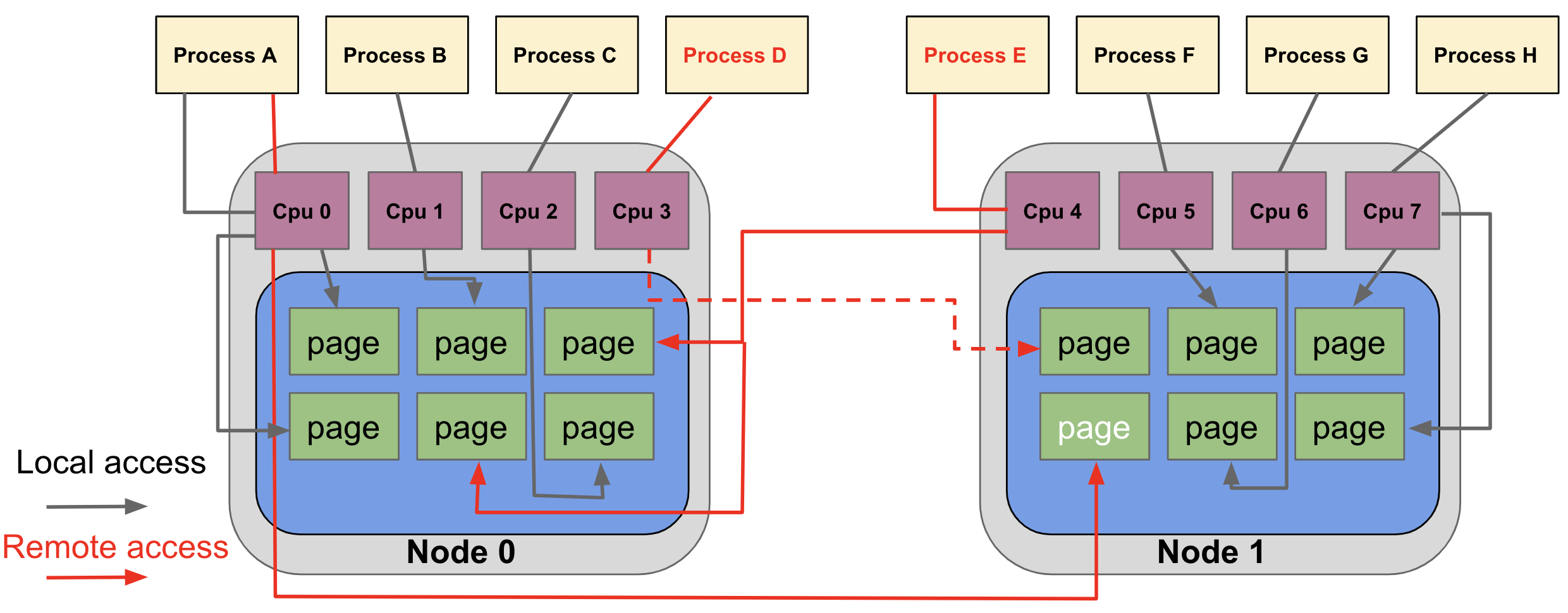
其中:
- 每一个黄色的方块代表一个用户进程
- Node0,Node1 就是将我们上面介绍的NUMA架构中的CPU和距离自己近的内存进行绑定,形成一个Node
- 每一个Node对应一个物理cpu,其中的cpu0,cpu1,cpu2…代表之前提到的core,也就是每个物理cpu之上会有多个core
- 蓝色的部分代表自己的距离物理CPU比较近的内存条。
用户进程ProcessA绑定在一个核心/HT上运行(cpu0),如果操作系统为这个用户进程分配的内存页在node1上,那么cpu0需要通过QPI+DDR从node1的内存中读取数据,这样就产生了remote访存的概念。这个时候有人会说为什么不把ProcessA迁移到Node1的CPU核心之上呢,但是ProcessA的内存页可能在两个node内存之上都有分配,这个时候总会有一些内存页需要remote访问。
所以NUMA架构下, 我们想要让用户进程拥有良好的内存访问性能,需要让用户进程只在一个node下运行,也就是需要绑定NUMA。
具体可已通过如下方式:
numactl --cpunodebind=0 --membind=0 user_process
用户进程绑定在node0的CPU和内存上,也就用户进程由node0的cpu来调度,并且就近分配node0中的内存。
如果我们仅仅想要进程从单一的node上分配内存,可以通过如下方式来运行。
测试如下代码:
#include <stdio.h>
#include <stdlib.h>
void main(int argc, char *argv[])
{int i, j;char *c;/* Allocate 4GB memory */for (i = 0; i < 1024; i++) {for (j = 0; j < 1024; j++) {c = malloc(4096);*c = 0xff;}}while (1);
}
总共分配4G的内存,通过如下方式运行,仅仅绑定内存从node1上分配,不限制cpu的调度node。
$ gcc malloc.c; $ numactl --membind=1 --cpunodebind=1 ./a.out &
[2] 43565
$ sudo numastat -p 43565Per-node process memory usage (in MBs) for PID 43565 (a.out)Node 0 Node 1--------------- ---------------
Huge 0.00 0.00
Heap 0.00 4112.00
Stack 0.00 0.01
Private 0.00 0.07
---------------- --------------- ---------------
Total 0.00 4112.09
接下来我们可以通过NUMA的几种内存模式来看操作系统如何使用NUMA。
可以通过
numastat或者lscpu来确认自己的系统是否支持NUMA,如果有多个node,则表示自己的系统是支持NUMA的。
NUMA下的内存分配策略
这里主要介绍四种NUMA下的内核分配策略
command 工具可以指定设置:numactl/numastat/migratepages
系统调用 函数也可以设置:
#include <numaif.h>
// 为当前进程以及该进程的子进程 设置内存分配策略,默认是default方式
long set_mempolicy(int mode, const unsigned long *nodemask, unsigned long maxnode);// 为一个内存range 设置内存分配策略,比如MPOL_BIND
long mbind(void *addr, unsigned long len, int mode, const unsigned long *nodemask, unsigned long maxnode, unsigned flags);// 将当前进程的所有内存page迁移到其他的node中
long migrate_pages(int pid, unsigned long maxnode, const unsigned long *old_nodes, const unsigned long *new_nodes);
接下来看看详细的内存分配策略
1. MPOL_DEFAULT
这个策略下,在用户进程申请内存过程中 系统会优先从local node进行分配,如果local node中的内存不足,则会从nearby的node内存中进行分配。
2. MPOL_BIND
这个策略下的内存分配可以通过set_mempolicy 设置进程的内存分配方式 或者 通过mbind 来指定一段 memory range的分配方式。
在这个策略下,我们通过在对应系统调用中设置nodemask来指定当前进程内存可分配内存页的node,且这个策略的内存分配方式比较严格。
如下图:
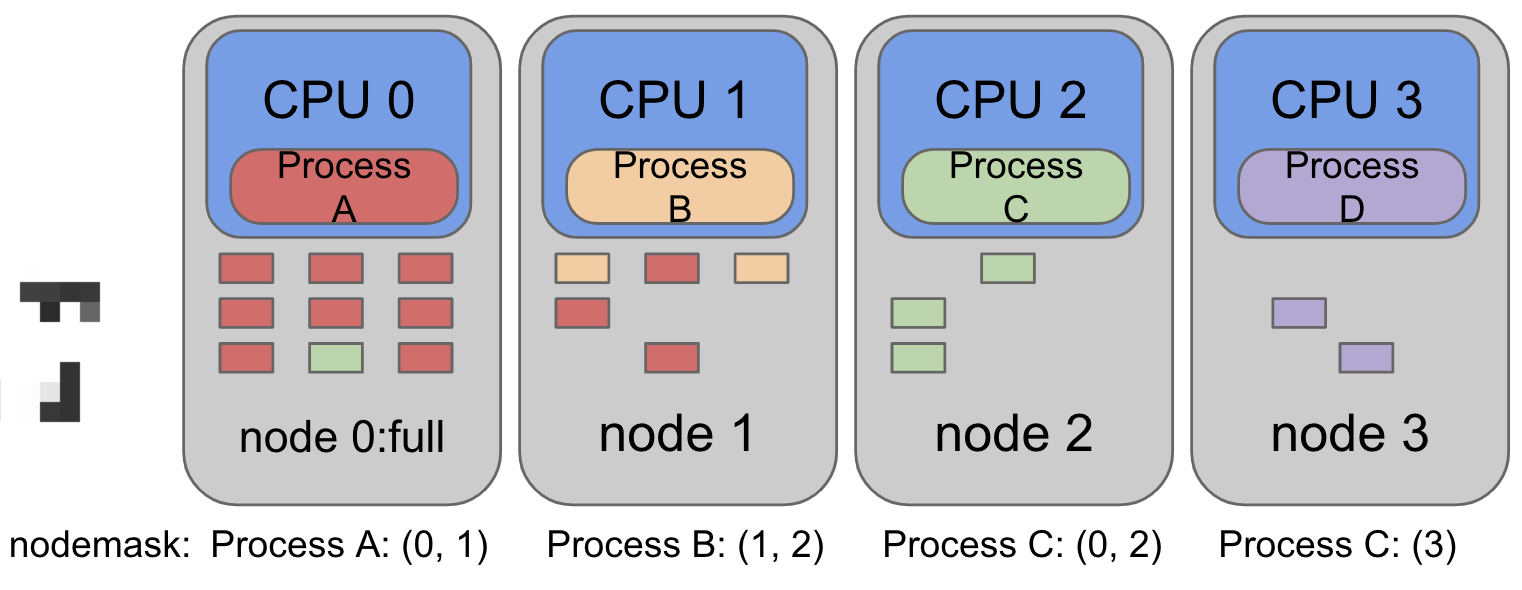
以ProcessA为例,其设置的nodemask指定了(0,1)两个node,也就是processA在CPU0上运行时会优先从node0上分配内存,如果node0的内存已经被分配满了,则系统会从node1位processA分配,也就是上图中node1的内存页中有红色部分的原因。
同理,其他的进程需要内存时操作系统也是按照其设置的nodemask中的节点来进行分配。
如果nodemask设置的node都没有内存了,即使其他的node中仍然有内存,也会发生OOM 或者其他的内存不足问题。
3. MPOL_INTERLEAVE
这个策略也是linux-kernel 启动过程默认的内存分配策略。
大体就是 从nodemask设置的node中交错分配内存。
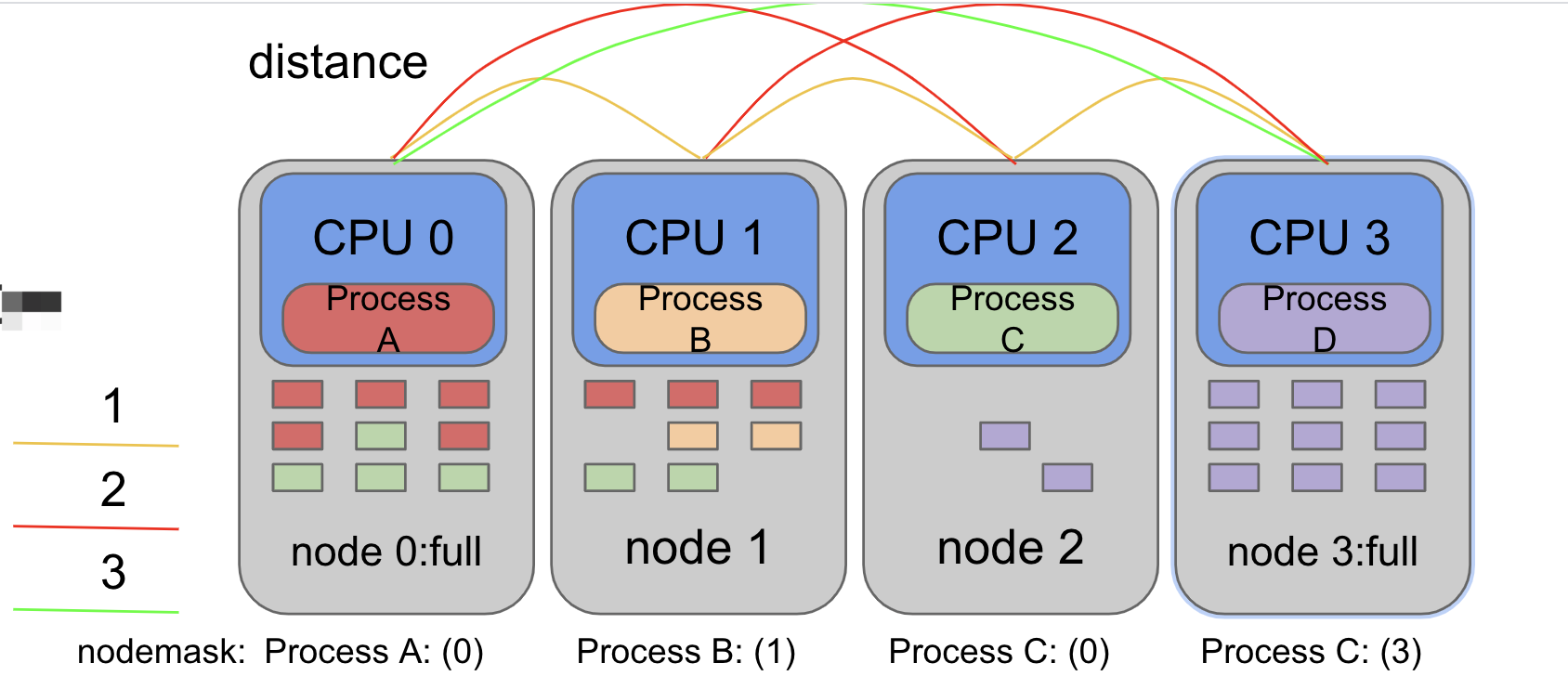
如上图,ProcessA 在 interleave模式下 设置了node0和node1 ,则第一个内存页会先从node0上分配,第二个内存页从node1上分配,依此。
操作系统boot-up时设置这样的分配策略的目的是为了降低单个node下的内存访问负载,当初始化进程启动之后 操作系统会将kernel的内存分配策略切换成 DEFAULT方式,也就是默认从local node进行内存分配。
4. MPOL_PREFERRED
这个策略下操作系统的内存分配会优先从距离自己近的node进行分配,如果nodemask 设置了一个或者多个node,则nodemask中的node会被当作就近内存 ,从这一些设置的node中进行内存分配。
如下图:
ProcessC 的nodemask配置了node0, 则ProcessC的内存分配会优先从node0中进行分配,可以看到node0中绿色的内存页。如果node0满了,且nodemask只设置了一个node,则ProcessC会从就近node中进行分配,比如node1。
关于不同node的 distance,这个是由操作系统来维护的,主要根据不同node之间访问内存消耗的时间来设置的。映射到实际的主板上,就类似前文介绍NUMA架构中的node和node之间的物理距离,只是这里node会更多一些。
5. 一些NUMA架构下的内核配置
$ sudo sysctl -a | grep -i numa
kernel.numa_balancing = 1 # How to disable numa balance? It can also be put into the kernel command by "numa_balancing=disable"
kernel.numa_balancing_scan_delay_ms = 1000
kernel.numa_balancing_scan_period_max_ms = 60000
kernel.numa_balancing_scan_period_min_ms = 1000
kernel.numa_balancing_scan_size_mb = 256
vm.numa_zonelist_order = default
总结
NUMA架构 是当下高性能服务器主流架构,尤其是搭配PMEM或者NVM 这样的非易失性内存存储介质,我们想要发挥这一些硬件高吞吐低延时的性能,一定是需要利用好NUMA特性才能发挥其性能。
比如针对PMEM的测试中,绑定NUAM和不绑定NUMA 测试出来的性能差异还是比较大的,感兴趣的同学可以用如下fio配置测试一下。
[global]
ioengine=libpmem
direct=1
norandommap=1
randrepeat=0
runtime=60
time_based
size=1G
directory=./fio
group_reporting
[read256B-rand]
bs=256B
rw=randread
numjobs=32
iodepth=4
cpus_allowed=0-15,16-31 #绑定NUMA
总的来说,如果大家做基础软件相关的研发,像分布式存储/分布式数据库等,在当今主流服务器架构下,一定需要对NUMA架构有足够的了解,否则无法将系统性能做到极致。
关于NUMA相关的内核实现,内核如何调度不同的numa node 中的CPU和内存以及I/O,如何实现numa node之间的互信 ,这一些底层实现都是非常复杂却十分精妙的,想要完全掌握,内核的基础实现是需要有一个概览的过程的,后续继续探索。
参考
相关参考论文均已放在github:numa-github
相关文章:

Java项目:网上书城+后台管理系统(java+jsp+servlert+mysql+ajax)
源码获取:博客首页 "资源" 里下载! 一、项目简述(附带IW文档) 功能: 前台: * 用户模块 * 分类模块 * 图书模块 * 购物车模块 * 订单模块 后台: * 管理员模块 * 分类管理模块 * 图书管理模块 * 订单模块 …

java.util.concurrent包API学习笔记
newFixedThreadPool 创建一个固定大小的线程池。 shutdown():用于关闭启动线程,如果不调用该语句,jvm不会关闭。 awaitTermination():用于等待子线程结束,再继续执行下面的代码。该例中我设置一直等着子线程结束。Java…
oracle读书记录
很久没有关注自己怕博客了,差不多有两年了。虽然这两年来一直关注51CTO,每天上班打开电脑或者周末在家开启电脑的时候都会浏览一下,这已经是习惯了,但是把自己的blog给忘了。今天,周末,2013年12月21日,同往…
输入、方法的运用
/ /猜数游戏,编写一个功能,完成猜数游戏,产生一个1~10之间的随机数 //与输入的数对对比,返回结果 猜中和没猜中 import java.util.Scanner; //引入(输入)的util包Scanner public class HelloWorld { public static void main(String[] args) {System…
Rocksdb 利用recycle_log_file_num 重用wal-log文件
recycle_log_file_num 复用wal文件信息, 优化wal文件的空间分配,减少pagecache中文件元信息的更新开销。 为同事提供了一组rocksdb写优化参数之后有一个疑惑的现象被问到,发现之前的一些代码细节有遗忘情况,同时也发现了这个参数…
Java项目:网上商城系统(java+jsp+servlert+mysql+ajax)
源码获取:博客首页 "资源" 里下载! 一、项目简述(需求文档PPT) 功能: 主页显示热销商品;所有商品展示,可进行商品搜索;点 击商品进入商品详情页,显示库存&…
clock函数返回负值~ (转)
使用clock() 函数来进行计时,时不时的返回一个很大的负数,怎么检查也检查不出错误,现在找出错误原因,给大家分享一下。 来源网页:http://kebe-jea.blogbus.com/logs/33603387.html 跑实验的时候,结果时不时…
c实现面向对象编程(3)
http://blog.csdn.net/kennyrose/article/details/7564105转载于:https://www.cnblogs.com/pengkunfan/p/3486612.html
echarts - 条形图grid设置距离绘图区域的距离
在一些数据量过大的情况下,在一个固定的区域绘图往往需要对图表绘制区域的大小进行动态改变。这时候设置条形图距离绘图区域上下左右的距离可使用如下方式:表示条形图的柱子距离绘图区左边30%,距离右边40%,而距离顶部和底部分别为…
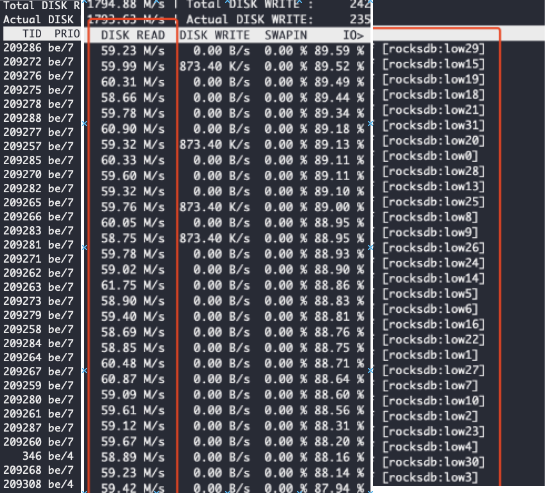
TitanDB 中使用Compaction Filter ,产生了预期之外几十倍的读I/O
Compaction过程中 产生大量读I/O 的背景 项目中因大value 需求,引入了PingCap 参考Wisckey 思想实现的key-value分离存储 titan, 使用过程中因为有用到Rocksdb本身的 CompactionFilter功能,所以就直接用TitanDB的option 传入了compaction fi…
Java项目:前台+后台精品图书管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 登录注册,办理借阅。借阅记录,预约借阅,借出未还, 借阅逾期,学生管理,图书管理,书库分类查询搜索…
消除 activity 启动时白屏、黑屏问题
默认情况下 activity 启动的时候先把屏幕刷成白色,再绘制界面,绘制界面或多或少有点延迟,这段时间中你看到的就是白屏,显然影响用户体验,怎么消除呢? 在 Activity theme 设置style 即可 1 <style na…

理解并实施:HSRP(CCNA200-120新增考点)
理解并实施:HSRP思科热备路由器协议HSRP(HotStandby Router Protocol)是企业级网络路由器的故障冗余服务。如图9.116所示,192.168.2.0/24的子网需要与目标192.168.5.2的计算机通信。192.168.2.0/24的子网有两台出口路由器,一台是R…
使用机智云APP控制战舰V3 (转)
源:使用机智云APP控制战舰V3 转载于:https://www.cnblogs.com/LittleTiger/p/10725586.html
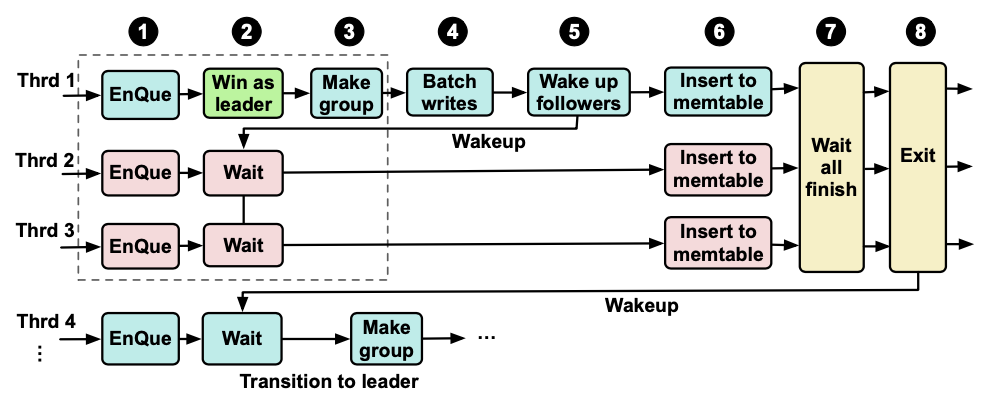
从JoinBatchGroup 代码细节 来看Rocksdb的相比于leveldb的写入优势
文章目录1. Rocksdb写入模型2. LevelDB写入的优化点3. Rocksdb 的优化1. Busy Loop2. Short Wait -- SOMETIMES busy Loop3. Long-wait4. 测试验证4. 总结1. Rocksdb写入模型 本节讨论一下Rocksdb在写入链路上的一个优化点,这个优化细节可以说将Rocksdb这个存储引擎…
Java项目:嘟嘟网上商城系统(java+jdbc+jsp+mysql+ajax)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 商品的分类展示,用户的注册登录,购物车,订单结算, 购物车加减,后台商品管理,分类管理,订单…

SOAPUI请求及mockservice 使用
1、新建soap Project,输入wsdl的地址,运行request 2.邮件Project,建立mockservice,建立多个response,选在mock operation,选择response dispa…

空间直角坐标系与球面坐标互转
空间直角坐标系与球面坐标互转 1 using System;2 using System.Collections.Generic;3 using System.Linq;4 using System.Text;5 6 namespace AppSurveryTools.SphericalAndCartesian7 {8 class CartesianCoord9 { 10 public double x; 11 public dou…
Ajax 的优势和不足
Ajax 的优势 1. 不需要插件支持 Ajax 不需要任何浏览器插件,就可以被绝大多数主流浏览器所支持,用户只需要允许 JavaScript 在浏览器上执行即可。 2. 优秀的用户体验 这是 Ajax 技术的最大优点,能在不刷新整个页面的前提下更新数据࿰…
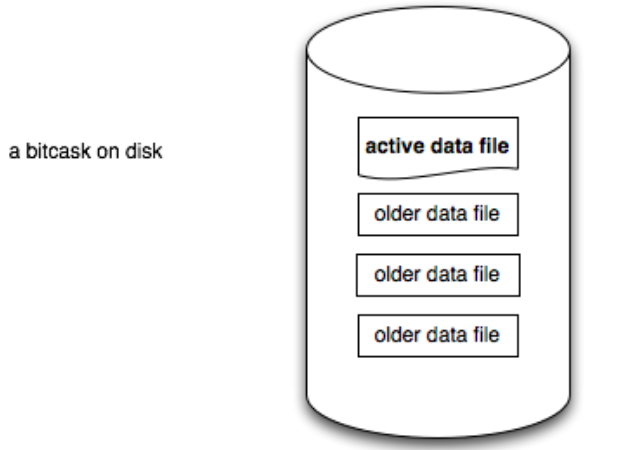
BitCask 持久化hash存储引擎 原理介绍
文章目录前言引擎背景引擎原理1. 磁盘数据结构2. 内存数据结构3. 读流程4. 数据合并总结前言 最近工作中部分项目中,对存储引擎的需求希望高性能的写、点查,并不需要Range。这里看到大家总会提到BitCask这个存储引擎方案,并不是很了解&#…

C# Socket系列三 socket通信的封包和拆包
通过系列二 我们已经实现了socket的简单通信 接下来我们测试一下,在时间应用的场景下,我们会快速且大量的传输数据的情况! 1 class Program2 {3 static void Main(string[] args)4 {5 TCPListener tcp n…

Java项目:CRM客户管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 用户管理,系统管理,客户管理,客户服务,客户关怀, 销售机会,统计管理等等。 二、项目运行 环境配置&#x…

Android 获取标题栏的高度
2019独角兽企业重金招聘Python工程师标准>>> 通过获取内容区域的 rect 的 top 值就是状态栏和标题栏的高度,也就可以得到标题栏的高度了, [java] view plaincopy int contentTop getWindow().findViewById(Window.ID_ANDROID_CONTENT).getTo…
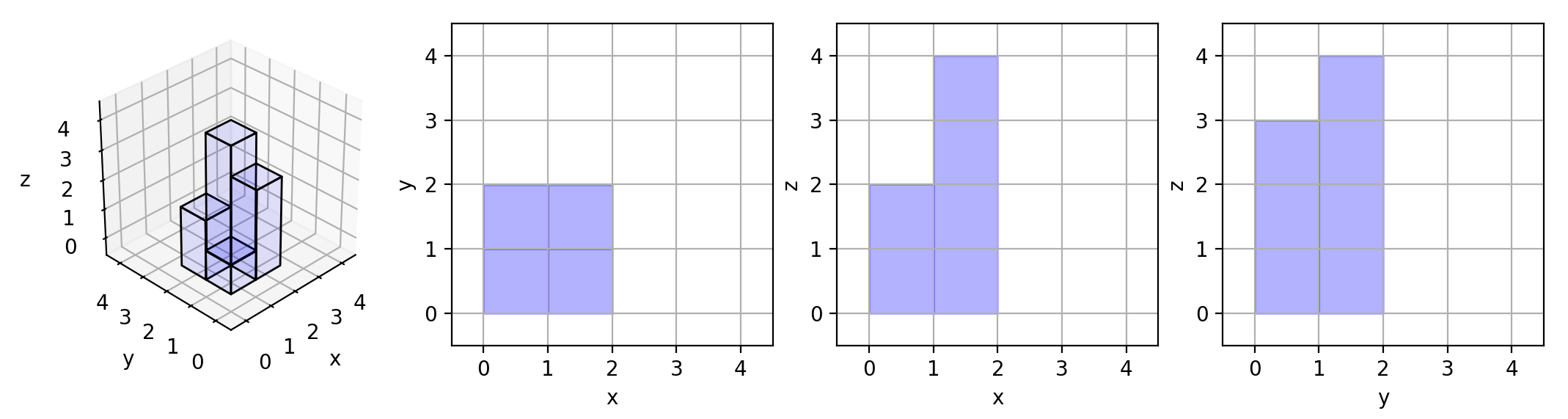
力扣—— 三维形体投影面积
在 N * N 的网格中,我们放置了一些与 x,y,z 三轴对齐的 1 * 1 * 1 立方体。 每个值 v grid[i][j] 表示 v 个正方体叠放在单元格 (i, j) 上。 现在,我们查看这些立方体在 xy、yz 和 zx 平面上的投影。 投影就像影子,将…
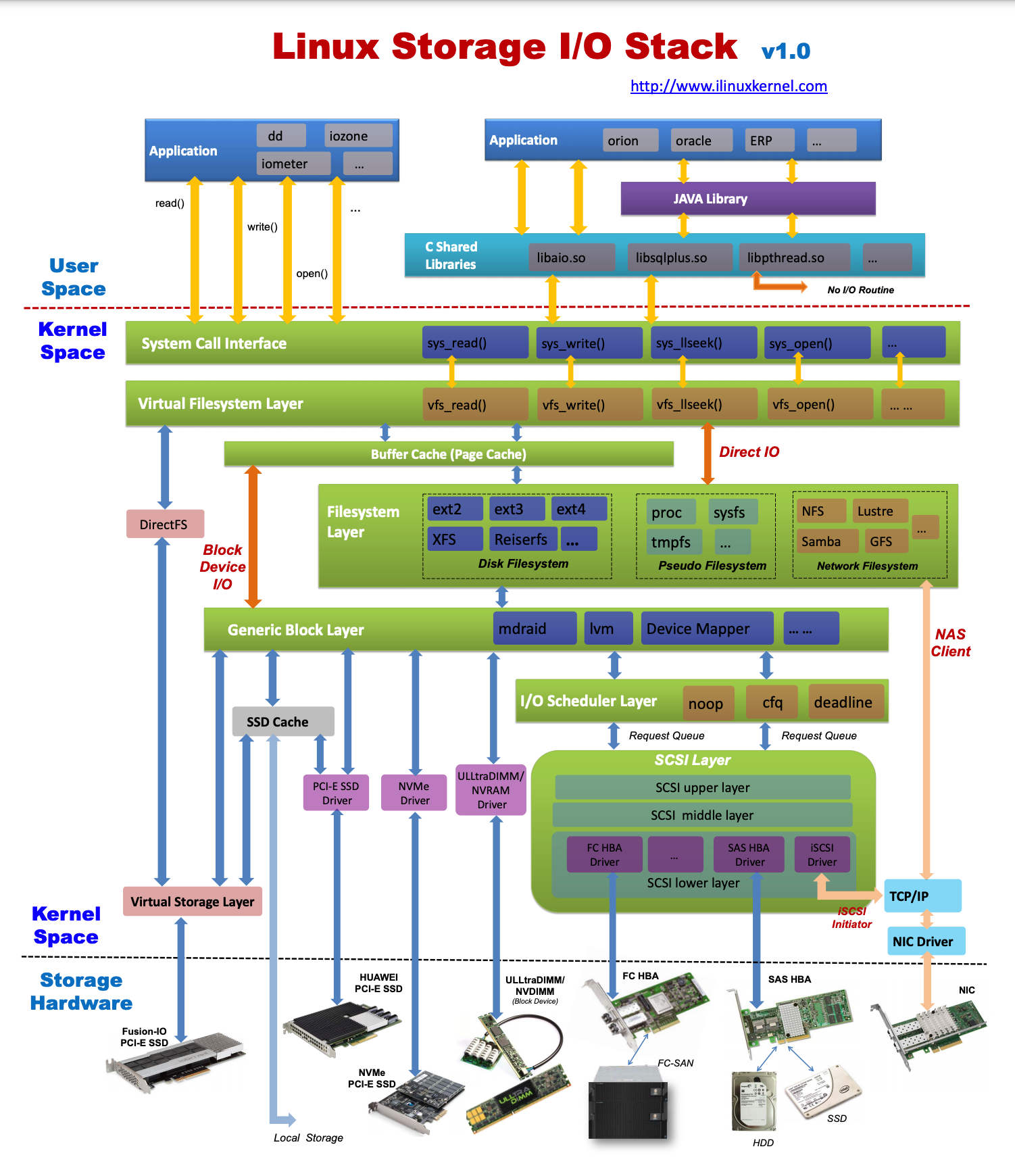
一图带你入门Linux 存储I/O栈
发现了一个内核大佬 的 Linux 存储I/O栈,很清晰!!! 原地址如下: http://ilinuxkernel.com/?p1559 【侵删】

Java项目:在线美食网站系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:用户的注册登录,美食浏览,美食文化,收藏百 科,趣味问答,食谱等等功能等等。 二、项目运行 环境配置:…

性能测试中传——lr理论基础(四)
转载于:https://blog.51cto.com/fuwenchao/1346435
滑动定位的三种方法,以及热启动(五)
from init_driver.Init_driver import init_driverdriver init_driver()# 坐标-->坐标,定位滑动 driver.swipe(309, 1353, 537, 511, duration3000)# 元素-->元素,定位滑动 start_ele driver.find_element_by_xpath("//*[contains(text, 通…
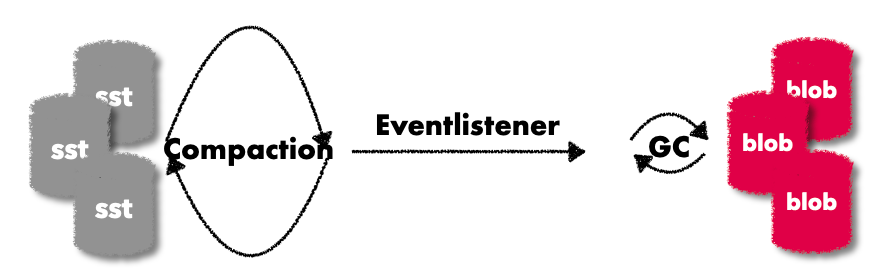
TitanDB GC详细实现原理 及其 引入的问题
文章目录1. 为什么要有GC2. GC的触发条件3. GC的核心逻辑1. blob file形态2. GC Prepare3. GC pick file4. GC run4. GC 引入的问题5. Titan的测试代码通过本篇,能够从TitanDB的源代码中看到 key/value 分离之后引入的一些复杂性,这个复杂性很难避免。 …
Java项目:医院住院管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 住院病人管理,住院病房管理,医生管理,药品管理,仪 器管理等等。 二、项目运行 环境配置: Jdk1.8 Tomcat8.…