从JoinBatchGroup 代码细节 来看Rocksdb的相比于leveldb的写入优势
文章目录
- 1. Rocksdb写入模型
- 2. LevelDB写入的优化点
- 3. Rocksdb 的优化
- 1. Busy Loop
- 2. Short Wait -- SOMETIMES busy Loop
- 3. Long-wait
- 4. 测试验证
- 4. 总结
1. Rocksdb写入模型
本节讨论一下Rocksdb在写入链路上的一个优化点,这个优化细节可以说将Rocksdb这个存储引擎的优秀代码能力和他们对整个操作系统的理解 展现得淋漓尽致。
Ps 本文涉及的rocksdb代码版本是6.6.3
首先一张图简单介绍一下Rocksdb多线程下的写入模型。
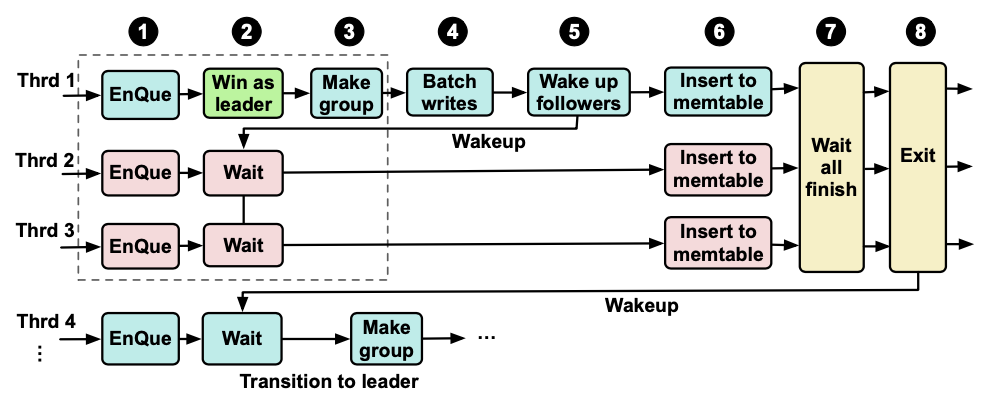
Rocksdb 多线程下默认的写入方式会按照上图模型进行:
1 2 3 步 总体上是说将并发写入的多个线程 中选出一个leader(一般由这个线程队列 中的第一个线程担当leader),由这个leader将所有要写入的数据做一个batch group,其他的线程则处于等待状态。
4 5 步 的时候 leader完成了batch 写wal,唤醒其他的等待线程。
6 7 8 则所有的线程可以并发写memtable。
2. LevelDB写入的优化点
提升写吞吐的能力主要就是通过多线程的数据batch,来加速wal的写入,这个优化其实leveldb 也同样做了,如下:
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {...MutexLock l(&mutex_);writers_.push_back(&w);while (!w.done && &w != writers_.front()) {w.cv.Wait();}if (w.done) {return w.status;}...
}
可以看到底层是通过w.cv.Wait()来让follwer等待,也就是通过pthread_cond_wait函数。pthread_cond_wait到条件变量的线程唤醒中涉及到FUTEX_WAIT到FUTEX_WAKE的状态转变,这个时间平均需要10us,因为这个函数内部实现需要对互斥量加锁/解锁。这个过程整个leader - batch模型的写入会因为pthread_cond_wait 中的条件锁发生耗时代价高昂的context switch,这个耗时对于先写page-cache的wal来说实在是不利于整体吞吐的提升。
后续会在rocksdb的优化中通过实际代码会演示这个上下文切换的过程对性能损失有多严重,当然更直观的对比就是Rocksdb的吞吐和leveldb同等配置下的吞吐。
3. Rocksdb 的优化
基于以上leveldb batch写入模型通过条件锁让follower线程等待,这会造成耗时高昂的context switch 。
所以Rocksdb 将pthread_cond_wait 优化为了如下三步:
- Busy Loop with pause
- Short wait – SOMETIMES busy Loop with yield
- Long wait – Blocking Wait
接下来可以依次看看
优化实现的入口函数是WriteThread::JoinBatchGroup —> WriteThread::AwaitState
1. Busy Loop
这第一步的优化主要是通过让线程循环忙等待一段时间,在至强(xeon)CPU下,一次循环大概需要7ns,而这里会忙等待200次,总共超过1us的时间。这段时间足够Leader的writer 完成WriteBatch的写入,而且这个时间忙等会让follower线程占用CPU,并不会发生context switch。这里相比于leveldb的pthread_cond_wait上下文消耗的10us量级来说已经小了很多。
for (uint32_t tries = 0; tries < 200; ++tries) {state = w->state.load(std::memory_order_acquire);if ((state & goal_mask) != 0) {return state;}port::AsmVolatilePause();}
其中AsmVolatilePause函数主要是执行asm volatile("pause");执行pause指令,官方对pause指令的描述如下:
Improves the performance of spin-wait loops. When executing a “spin-wait loop,” a Pentium 4 or Intel Xeon processor suffers a severe performance penalty when exiting the loop because it detects a possible memory order violation. The PAUSE instruction provides a hint to the processor that the code sequence is a spin-wait loop. The processor uses this hint to avoid the memory order violation in most situations, which greatly improves processor performance. For this reason, it is recommended that a PAUSE instruction be placed in all spin-wait loops.
主要是用来提升spin-wait-loop的性能,一般CPU执行spin-wait在循环退出的时候检测指令的内存序发生变化会重排指令流水线,从而造成性能损失。而pause指令则能够告诉CPU 进程当前处于spin-wait状态,这个时候能够避免CPU流水线的指令重排,从而能够减少性能的损失。
2. Short Wait – SOMETIMES busy Loop
如果Rocksdb能够准确得预测 当前线程的等待时间,那其实就不需要这个优化了,只需要段时间的Loop和长时间的Long-wait就可以了。但是实际的应用场景中无法预知线程的具体等待时间(比如Rocksdb leader写WAL过程中其他的follower正在等待,但是这个时候磁盘是HDD,那一次写入可能达到ms的时间;或者nvme的写入十几us的时间;这一些时间都是需要follower等待)。
那么Short-Wait就是用来解决这种处于loop到long-wait之间的线程等待优化的,细节还是很有意思的。
if (max_yield_usec_ > 0) {update_ctx = Random::GetTLSInstance()->OneIn(sampling_base);if (update_ctx || yield_credit.load(std::memory_order_relaxed) >= 0) {// we're updating the adaptation statistics, or spinning has >// 50% chance of being shorter than max_yield_usec_ and causing no// involuntary context switchesauto spin_begin = std::chrono::steady_clock::now();// this variable doesn't include the final yield (if any) that// causes the goal to be metsize_t slow_yield_count = 0;auto iter_begin = spin_begin;// 这里的循环不是无止境的,max_yield_usec_ 是通过外部options参数控制// 默认是100while ((iter_begin - spin_begin) <=std::chrono::microseconds(max_yield_usec_)) {// 先让出时间片std::this_thread::yield();// 抢占时间片// state满足条件,则跳出循环state = w->state.load(std::memory_order_acquire);if ((state & goal_mask) != 0) {// successwould_spin_again = true;break;}auto now = std::chrono::steady_clock::now();if (now == iter_begin ||now - iter_begin >= std::chrono::microseconds(slow_yield_usec_)) {// conservatively count it as a slow yield if our clock isn't// accurate enough to measure the yield duration++slow_yield_count;if (slow_yield_count >= kMaxSlowYieldsWhileSpinning) {// Not just one ivcsw, but several. Immediately update yield_credit// and fall back to blockingupdate_ctx = true;break;}}iter_begin = now;}}}
主体逻辑先看上面的while循环中,还是像开始的Loop中一样判断state是否满足条件,如果满足则退出循环。state不满足条件的话通过 std::this_thread::yield();能够将剩下的时间片交给其他的线程执行。当下一次循环时需要执行state.load的时候再次抢占CPU的时间片。不过这个循环并不是无限执行的,会执行max_yield_usec_(us), 这个max_yield_usec_参数是通过外部的两个option指定的,如果enable_write_thread_adaptive_yield为真,则将write_thread_max_yield_usec设置为执行的时间,否则设置为0。所以这里循环的默认执行时间是100us。
那如果执行了100us的时间,发现state并没有发生变化,这段时间这么多次的cpu context switch是不是就无用了,还消耗了大量的CPU。显然rocksdb不允许这么low且低效的做法,这也就是剩下的while循环内的逻辑要做的事情。主要就是判断yield的执行时间来判断,如果当前循环让出的时间片超过db_options.write_thread_slow_yield_usec也就是slow_yield_usec_的3us,且连续超过3次,则认为当前等待满足state的时间过久,需要切换到 Long-wait了。
以上代码最开始也有几个判断进入while循环的条件:
if (max_yield_usec_ > 0) {update_ctx = Random::GetTLSInstance()->OneIn(sampling_base);if (update_ctx || yield_credit.load(std::memory_order_relaxed) >= 0) {......}}
首先需要max_yield_usec_大于0,由外部参数控制,默认是100。如果不满足,则进入long-wait。
判断update_ctx是否不等于0,这里通过随机函数 的OneIn来判断,sampling_base是256,则这里有255/256概率是为true的 ,或者判断yield_credit是否>0,针对yield_credit的更新则是通过判断short-wait 阶段中是否满足了条件,满足的话则让yield_credit+1, 如果short-wait不满足,则会-1。也就是只要short-wait的时间能够持续满足state的条件,那么每次的执行大多数都会集中到short-wait中。 同时,这一是Rocksdb 在写吞吐和系统CPU时间的消耗之间所做的权衡,因为频繁的short-wait,也就意味着拼房的context switch,也就是更多的CPU消耗。
关于yield_credit 的更新逻辑如下:
如果short-wait中满足条件之后会将would_spin_again置为true,也就是会给yield_credit +1,否则就-1。
if (update_ctx) {// Since our update is sample based, it is ok if a thread overwrites the// updates by other threads. Thus the update does not have to be atomic.auto v = yield_credit.load(std::memory_order_relaxed);// fixed point exponential decay with decay constant 1/1024, with +1// and -1 scaled to avoid overflow for int32_t//// On each update the positive credit is decayed by a facor of 1/1024 (i.e.,// 0.1%). If the sampled yield was successful, the credit is also increased// by X. Setting X=2^17 ensures that the credit never exceeds// 2^17*2^10=2^27, which is lower than 2^31 the upperbound of int32_t. Same// logic applies to negative credits.v = v - (v / 1024) + (would_spin_again ? 1 : -1) * 131072;yield_credit.store(v, std::memory_order_relaxed);}
实际On NVME设备的测试过程中并发写Rocksdb会发现大多数线程等待都会进入到short-wait。后续会有一段简单的测试代码以及测试结果来看一下这一部分的优化对Rocksdb吞吐的影响。。。看对比测试,影响真是挺大的。
3. Long-wait
如果前两个等待阶段都没有满足state的状态变更,那么就只能进入和leveldb逻辑一样的long-wait阶段了,通过cond.Wait来长等待。
uint8_t WriteThread::BlockingAwaitState(Writer* w, uint8_t goal_mask) {// We're going to block. Lazily create the mutex. We guarantee// propagation of this construction to the waker via the// STATE_LOCKED_WAITING state. The waker won't try to touch the mutex// or the condvar unless they CAS away the STATE_LOCKED_WAITING that// we install below.w->CreateMutex();auto state = w->state.load(std::memory_order_acquire);assert(state != STATE_LOCKED_WAITING);if ((state & goal_mask) == 0 &&w->state.compare_exchange_strong(state, STATE_LOCKED_WAITING)) {...w->StateCV().wait(guard, [w] {return w->state.load(std::memory_order_relaxed) != STATE_LOCKED_WAITING;});}...
}
这里也有优化,通过CreateMutex 仅仅会创建好condvar 和 mutex,但是当实际state 不满足条件,需要等待的时候才会执行condvar.Wait()。
可以说是Rocksdb将这一部分代码优化到了极致。
4. 测试验证
通过如下写入函数简单验证一下开启short-wait和关闭short-wait对写入吞吐的影响有多大,单db 压10个线程,除了下面提到的一个对比参数之外其他都用默认的参数:
void DBWrite(int num) {double ts = now();int db_num = num % FLAGS_multidb_nums;while (true) {std::string key = std::to_string(generator_());std::string value(FLAGS_value_len, 'x');if(num == 0) {rocksdb::SetPerfLevel(rocksdb::PerfLevel::kEnableTimeExceptForMutex);rocksdb::get_perf_context()->Reset();// rocksdb::get_iostats_context()->Reset();}src_db[db_num]->Put(rocksdb::WriteOptions(), "test_graph_"+key, value);++g_op_W;if(num == 0 && now() - ts >= 1) { // 每隔一秒,打印一次0号线程的延时数据rocksdb::SetPerfLevel(rocksdb::PerfLevel::kDisable);std::cout<< "\nwrite_thread_wait_nanos "<< rocksdb::get_perf_context()->write_thread_wait_nanos<< std::endl;ts = now();}}
}
一种是开启enable_write_thread_adaptive_yield,也是默认的选项。
一种是关闭以上选项。
## 关闭选项
write_thread_wait_nanos 14766
write_speed : 186138write_thread_wait_nanos 43489
write_speed : 181371write_thread_wait_nanos 41962
write_speed : 177163write_thread_wait_nanos 33322
write_speed : 171145## 开启选项
write_thread_wait_nanos 14880
write_speed : 388869write_thread_wait_nanos 14267
write_speed : 353567write_thread_wait_nanos 12905
write_speed : 364561write_thread_wait_nanos 11570
write_speed : 363793
可以看到关闭了short-wait,在10个写入的并发情况下性能差异2x,且关闭选项之后都并发足够多时会大概率等待在long-wait中,这也是这也是关闭short-wait选项之后write_thread_wait_nanos 的时间过长的原因。所以这里的short-wait相比于leveldb的有更为明显的提升,而且在更大的并发场景,rocksdb的优势会更大。
4. 总结
- Rocksdb从leveldb对写入batch模型的pthread_cond_wait 中优化出来这么多,目的还是为了进一步提升写吞吐;当然也会带来更多的CPU消耗,比如short-wait策略。
- 内核的理解需要进一步加强,在Rocksdb的这一部分优化中 需要对内核的线程调度/CPU的指令重排 由足够深入的理解之后才能写出这样的代码。其实对于我们这种代码功底还不够的人来说,直接深入到内核其实有点难的,还是先把相关的功能用熟练之后再考虑。比如内存屏障,CPU时间片转移的基本函数等。
真的是跟着Rocksdb 底层学习存储引擎才能学到引擎内核的精髓啊,每一个代码细节都被精心雕琢打磨。
一些操作系统耗时信息:
| tables | are |
|---|---|
| 互斥锁耗时 | 25ns |
| 访存耗时 | 100us |
| 上下文切换耗时 | 3us |
| nvme 随机读写耗时 | 10-20us |
| 机械盘寻址时间 | 5-10ms |
相关文章:
Java项目:嘟嘟网上商城系统(java+jdbc+jsp+mysql+ajax)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 商品的分类展示,用户的注册登录,购物车,订单结算, 购物车加减,后台商品管理,分类管理,订单…

SOAPUI请求及mockservice 使用
1、新建soap Project,输入wsdl的地址,运行request 2.邮件Project,建立mockservice,建立多个response,选在mock operation,选择response dispa…

空间直角坐标系与球面坐标互转
空间直角坐标系与球面坐标互转 1 using System;2 using System.Collections.Generic;3 using System.Linq;4 using System.Text;5 6 namespace AppSurveryTools.SphericalAndCartesian7 {8 class CartesianCoord9 { 10 public double x; 11 public dou…

Ajax 的优势和不足
Ajax 的优势 1. 不需要插件支持 Ajax 不需要任何浏览器插件,就可以被绝大多数主流浏览器所支持,用户只需要允许 JavaScript 在浏览器上执行即可。 2. 优秀的用户体验 这是 Ajax 技术的最大优点,能在不刷新整个页面的前提下更新数据࿰…
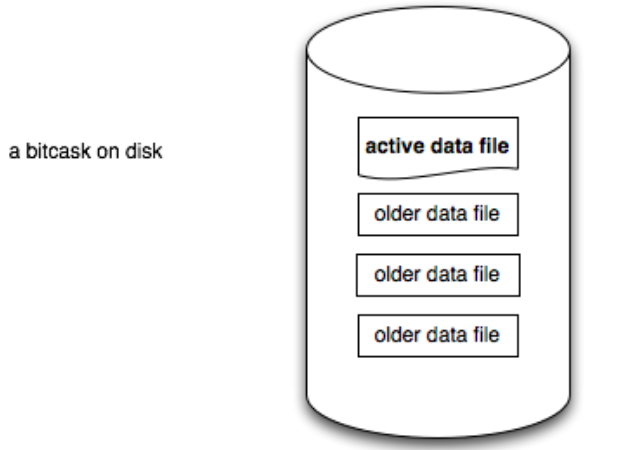
BitCask 持久化hash存储引擎 原理介绍
文章目录前言引擎背景引擎原理1. 磁盘数据结构2. 内存数据结构3. 读流程4. 数据合并总结前言 最近工作中部分项目中,对存储引擎的需求希望高性能的写、点查,并不需要Range。这里看到大家总会提到BitCask这个存储引擎方案,并不是很了解&#…

C# Socket系列三 socket通信的封包和拆包
通过系列二 我们已经实现了socket的简单通信 接下来我们测试一下,在时间应用的场景下,我们会快速且大量的传输数据的情况! 1 class Program2 {3 static void Main(string[] args)4 {5 TCPListener tcp n…

Java项目:CRM客户管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 用户管理,系统管理,客户管理,客户服务,客户关怀, 销售机会,统计管理等等。 二、项目运行 环境配置&#x…

Android 获取标题栏的高度
2019独角兽企业重金招聘Python工程师标准>>> 通过获取内容区域的 rect 的 top 值就是状态栏和标题栏的高度,也就可以得到标题栏的高度了, [java] view plaincopy int contentTop getWindow().findViewById(Window.ID_ANDROID_CONTENT).getTo…
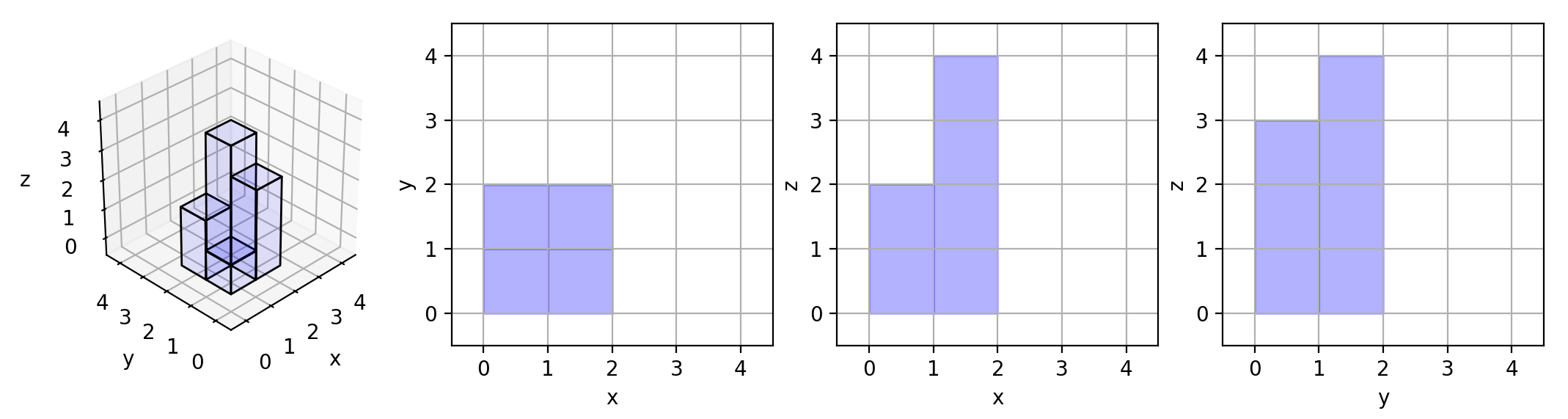
力扣—— 三维形体投影面积
在 N * N 的网格中,我们放置了一些与 x,y,z 三轴对齐的 1 * 1 * 1 立方体。 每个值 v grid[i][j] 表示 v 个正方体叠放在单元格 (i, j) 上。 现在,我们查看这些立方体在 xy、yz 和 zx 平面上的投影。 投影就像影子,将…
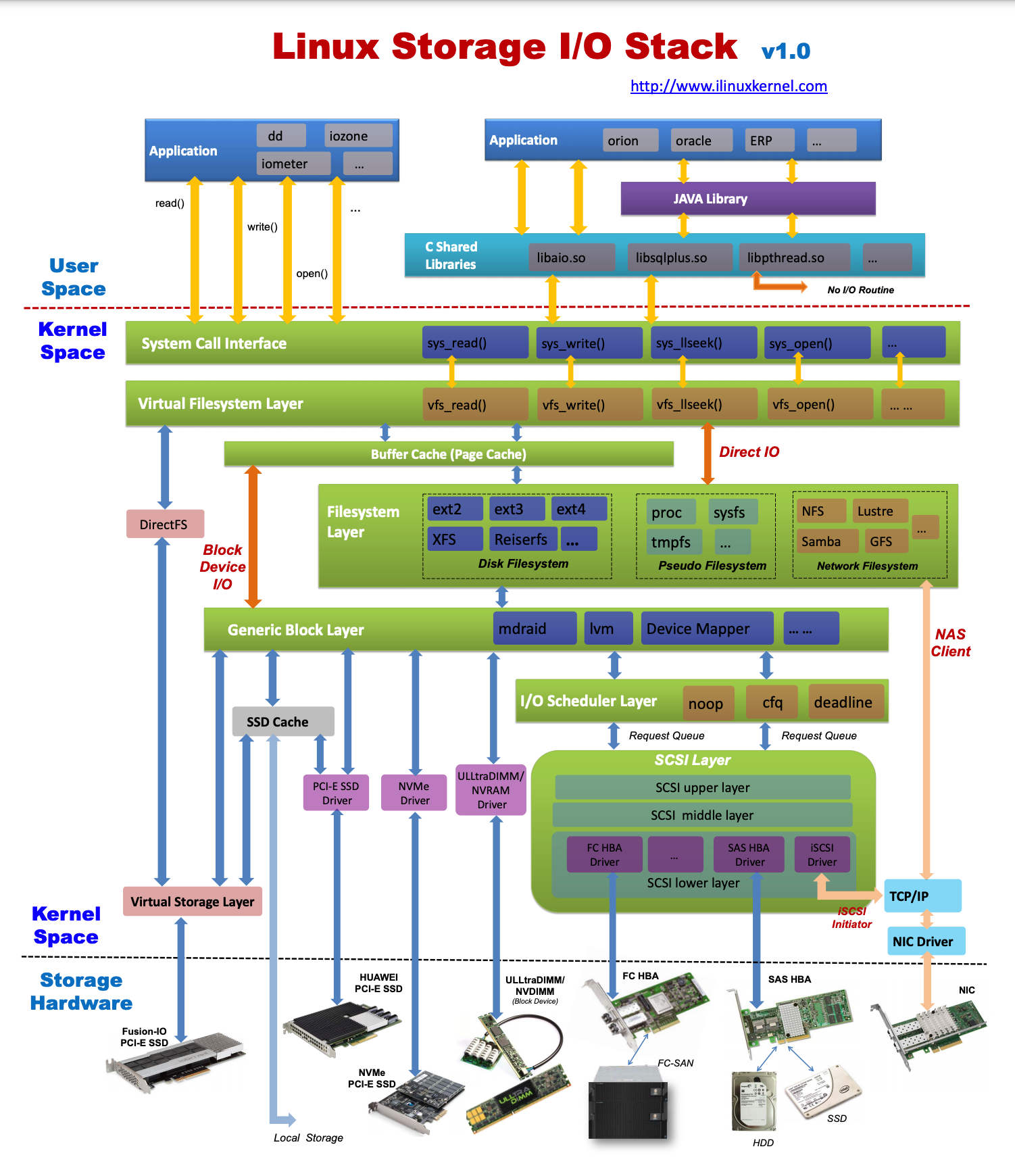
一图带你入门Linux 存储I/O栈
发现了一个内核大佬 的 Linux 存储I/O栈,很清晰!!! 原地址如下: http://ilinuxkernel.com/?p1559 【侵删】

Java项目:在线美食网站系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:用户的注册登录,美食浏览,美食文化,收藏百 科,趣味问答,食谱等等功能等等。 二、项目运行 环境配置:…

性能测试中传——lr理论基础(四)
转载于:https://blog.51cto.com/fuwenchao/1346435
滑动定位的三种方法,以及热启动(五)
from init_driver.Init_driver import init_driverdriver init_driver()# 坐标-->坐标,定位滑动 driver.swipe(309, 1353, 537, 511, duration3000)# 元素-->元素,定位滑动 start_ele driver.find_element_by_xpath("//*[contains(text, 通…
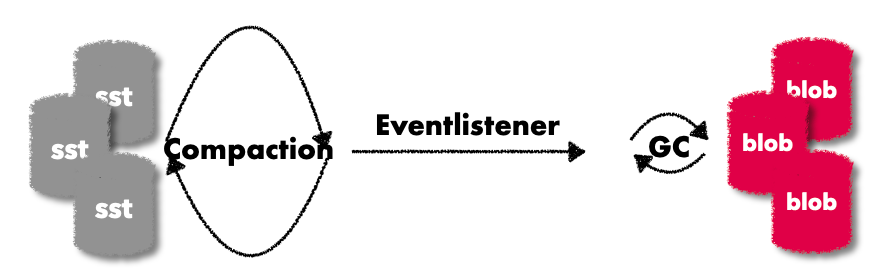
TitanDB GC详细实现原理 及其 引入的问题
文章目录1. 为什么要有GC2. GC的触发条件3. GC的核心逻辑1. blob file形态2. GC Prepare3. GC pick file4. GC run4. GC 引入的问题5. Titan的测试代码通过本篇,能够从TitanDB的源代码中看到 key/value 分离之后引入的一些复杂性,这个复杂性很难避免。 …
Java项目:医院住院管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 住院病人管理,住院病房管理,医生管理,药品管理,仪 器管理等等。 二、项目运行 环境配置: Jdk1.8 Tomcat8.…
1m网速是什么意思,1m带宽是什么意思
1M网速下载速度应是多少?我怎么才50多KB?? 建议: 一般来说是90到100算正常。最高能达到120 带究竟该有多快 揭开ADSL真正速度之谜 常常使用ADSL的用户,你知道ADSL的真正速度吗?带着这个疑问我们将问题一步一步展开。…
泛型实体类List绑定到repeater
泛型实体类List<>绑定到repeater 后台代码: private void bindnewslist(){long num 100L;List<Model.news> news _news.GetList(out num);this.newslist.DataSource news;this.newslist.DataBind();} 说明:Model.news是实体类,…

Qt4.8.5移植
这两天搞了Qt移植 因为不小心 耽误了挺多时间 但是也比较好的掌握了 现在记录一下 准备工具: tslib-1.16 qt-everywhere-opensource-src-4.8.5.tar 下载路径: tslib-1.16下载: https://github.com/kergoth/tslib/releases/download/1.16/t…
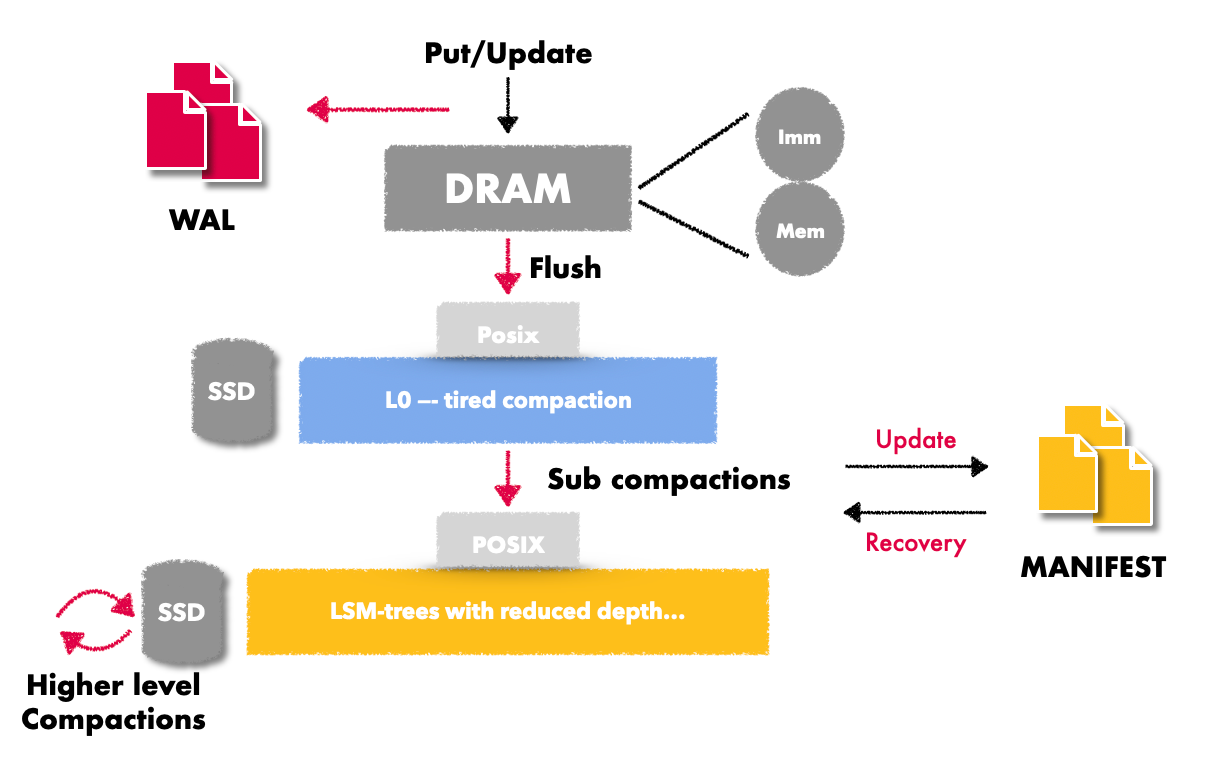
Rocksdb 通过ingestfile 来支持高效的离线数据导入
文章目录前言使用方式实现原理总结前言 很多时候,我们使用数据库时会有离线向数据库导入数据的需求。比如大量用户在本地的一些离线数据,想要将这一些数据导入到已有的数据库中;或者说NewSQL场景中部分机器离线,重新上线之后的数…
Java项目:企业人事管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能介绍:员工管理,用户管理,部门管理,文档管理, 职位管理等等。 二、项目运行 环境配置: Jdk1.8 Tomcat8.5 mysql Eclispe (I…

XCODE 6.1.1 配置GLFW
最近在学习opengl的相关知识。第一件事就是配环境(好烦躁)。了解了一下os x下的OpenGL开源库,主要有几个:GLUT,freeglut,GLFW等。关于其详细的介绍可以参考opengl网站(https://www.opengl.org/wiki/Related_toolkits_and_APIs)。由…
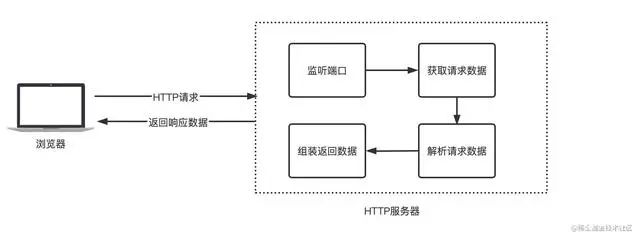
SpringCloud远程调用为啥要采用HTTP,而不是RPC?
通俗的说法就是:比如说现在有两台服务器A和B,一个应用部署在A服务器上,另一个应用部署在B服务器上,如果A应用想要调用B应用提供的方法,由于他们不在一台机器下,也就是说它们不在一个JVM内存空间中,是无法直接调用的,需要通过网络进行调用,那这个调用过程就叫做RPC。建立Socket连接至少需要一对套接字,其中一个运行于客户端,称为ClientSocket ,另一个运行于服务器端,称为ServerSocket ,套接字之间的连接过程分为三个步骤:服务器监听,客户端请求,连接确认。

vs快捷键及常用设置(vs2012版)
vs快捷键: 1、ctrlf F是Find的简写,意为查找。在vs工具中按此快捷键,可以查看相关的关键词。比如查找哪些页面引用了某个类等。再配合查找范围(整个解决方案、当前项目、当前文档等),可以快速的找到问题所在…
python_day10
小甲鱼python学习笔记 爬虫之正则表达式 1.入门(要import re) 正则表达式中查找示例: >>> import re >>> re.search(rFishC,I love FishC.com) <re.Match object; span(7, 12), matchFishC> >>> #单纯的这种…
Graphics2D API:Canvas操作
在中已经介绍了Canvas基本的绘图方法,本篇介绍一些基本的画布操作.注意:1、画布操作针对的是画布,而不是画布上的图形2、画布变换、裁剪影响后续图形的绘制,对之前已经绘制过的内容没有影响。
关于Titandb Ratelimiter 失效问题的一个bugfix
本文简单讨论一下在TitanDB 中使用Ratelimiter的一个bug,也算是一个重要bug了,相关fix已经提了PR到tikv 社区了pull-210。 这个问题导致的现象是ratelimiter 在titandb Flush/GC 生成blobfiled的过程中无法生效,也就是无法限制titandb的主要…
Java项目:前台预定+后台管理酒店管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能介绍: 前台用户端:用户注册登录,房间展示,房间分类,房间 按价格区间查询,房间评论,房间预订等等 后台管…
Solr初始化源码分析-Solr初始化与启动
用solr做项目已经有一年有余,但都是使用层面,只是利用solr现有机制,修改参数,然后监控调优,从没有对solr进行源码级别的研究。但是,最近手头的一个项目,让我感觉必须把solrn内部原理和扩展机制弄…
iOS :UIPickerView reloadAllComponets not work
编辑信息页面用了很多选择栏,大部分都用 UIPickerView 来实现。在切换数据显示的时候, UIPickerView 不更新数据,不得其解。Google 无解,原因在于无法描述自己的问题,想想应该还是代码哪里写错了。 写了个测试方法&…
单相计量芯片RN8209D使用经验分享(转)
单相计量芯片RN8209D使用经验分享转载于:https://www.cnblogs.com/LittleTiger/p/10736060.html