Rocksdb iterator 的 Forward-scan 和 Reverse-scan 的性能差异
前言
最近在读 MyRocks 存储引擎2020年的论文,因为这个存储引擎是在Rocksdb之上进行封装的,并且作为Facebook 内部MySQL的底层引擎,用来解决Innodb的空间利用率低下 和 压缩效率低下的问题。而且MyRocks 在接入他们UDB 之后成功达成了他们的目标:将以万为单位的服务器集群server个数缩减了一半。
MyRocks 在facebook内部的成功实践证明了LSM-tree的存储引擎经过一系列优化之后能够达到和B±tree存储引擎性能接近且节约大量存储成本的目的。对于我们底层存储引擎开发者来说,MyRocks 的实践过程在rocksdb上做了大量的通用型特性的开发。其中就包括针对rocksdb的反向迭代的优化。
迭代器 正向 或者 反向 扫描 描述
关于迭代器的扫描方向,大体代码如下:
- 正向扫描(字节序升序扫描)
最终的结果类似:auto begin_it = db->NewIterator(rocksdb::ReadOptions()); for (begin_it->SeekToFirst(); begin_it->Valid(); begin_it->Next()) {assert(begin_it->Valid()); } delete begin_it;3499211612 3586334585 3890346734 545404204 581869302 - 反向扫描(字节序降序扫描)
最终的扫描结果类似:auto it = db->NewIterator(rocksdb::ReadOptions()); for (it->SeekToLast(); it->Valid(); it->Prev()) {assert(it->Valid()); } delete it;581869302 545404204 3890346734 3586334585 3499211612
这两种扫描方式中我们使用单机存储引擎大多数的scan都是第一种方式,即按照key写入的顺序,从头开始遍历。
然而方向扫描 则是在数据库使用单机存储引擎中出现的需求,单机引擎没办法在分布式场景支持MVCC,所以一般上层分布式数据库会为每一个写入到引擎的key都会增加一个时间戳,来支持多版本。很多时候需要按照key的更新时间降序扫描key,这个时候一般情况就需要通过第二种方式来进行扫描。这个问题在 MyRocks 接入 UDB 的实现过程中就是一个痛点,UDB 会有固定的场景需要按照更新时间降序获取好友关系。
先不说两种方式的实现,我们先看看两种方式的扫描性能。
性能测试
测试描述:完全随机写入2百万 条key,扫描的时候不打开block-cache。
测试代码:
#include <iostream>
#include <unistd.h>
#include <random>
#include <sys/time.h>#include <rocksdb/db.h>
#include <rocksdb/table.h>
#include <rocksdb/status.h>
#include <rocksdb/options.h>using namespace std;
using namespace rocksdb;static const int write_count = 2000000;
rocksdb::DB* db = nullptr;
rocksdb::Options option;
std::mt19937 generator_; // 随机数生成器static string seq_value(int num) {return string(100, 'a' + (num % 26));
}uint64_t NowMicros() {struct timeval tv;gettimeofday(&tv, nullptr);return static_cast<uint64_t>(tv.tv_sec* 1000000 + tv.tv_usec);
}void OpenDB() {option.create_if_missing = true;option.compression = rocksdb::CompressionType::kNoCompression;option.comparator = rocksdb::ReverseBytewiseComparator();rocksdb::BlockBasedTableOptions table_options;table_options.no_block_cache = true;table_options.cache_index_and_filter_blocks = false;option.table_factory.reset(NewBlockBasedTableFactory(table_options));auto s = rocksdb::DB::Open(option, "./db", &db);if (!s.ok()) {cout << "open faled : " << s.ToString() << endl;exit(-1);}cout << "Finish open !"<< endl;
}void DoWrite() {int j = 0;while (j < write_count) {string key = std::to_string(generator_());string value = seq_value(j);auto s = db->Put(rocksdb::WriteOptions(),key, value);if (!s.ok()) {cout << "Put value failed: " << s.ToString() << endl;exit(-1);}j++;}cout << "Finish write !" << endl;
}void ForwardTraverse() {uint64_t start_ts = NowMicros();auto begin_it = db->NewIterator(rocksdb::ReadOptions());for (begin_it->SeekToFirst(); begin_it->Valid(); begin_it->Next()) {assert(begin_it->Valid());}delete begin_it;cout << "ForwardTraverse use time: " << NowMicros() - start_ts << endl;
}void ReverseTraverse() {uint64_t start_ts = NowMicros();auto begin_it = db->NewIterator(rocksdb::ReadOptions());for (begin_it->SeekToLast(); begin_it->Valid(); begin_it->Prev()) {assert(begin_it->Valid());}delete begin_it;cout << "BackwardTraverse use time: " << NowMicros() - start_ts << endl;
}int main() {OpenDB();DoWrite();ForwardTraverse();ReverseTraverse();return 0;
}
测试结果:
...
87
Finish open !
Finish write !
ForwardTraverse use time: 496311
BackwardTraverse use time: 565935
88
Finish open !
Finish write !
ForwardTraverse use time: 447470
BackwardTraverse use time: 565372
89
Finish open !
Finish write !
ForwardTraverse use time: 441705
BackwardTraverse use time: 563440
...
测试了100次,基本都是这个耗时的量级,可以发现两种扫描的耗时相差15%-25%。如果MyRocks 中使用传统的反向扫描,性能则相比于本身的正向扫描损失15-25%,这对于想要节约50% 集群server的目标来收显然不可忍。
当然,还有更为方便的测试方式,就是使用db_bench,可以使用它的readseq和readreverse两种benchmark进行测试,因为我是在mac上,rocksdb的完整编译不太方便,跑db_bench有点麻烦,就写一个简单的小脚本测试就可以了。
正反 扫描迭代器 实现
通过使用两种迭代器,我们能够很容易发现两种扫描的方式差异主要体现在获取下一个key的方式,一个是Next,一个是Prev。
我们将刚才的sst文件dump出来,可以发现sst内部的datablock 存储的key的方式本身就是字节升序存储,而且为了节约存储成本,底层实际采用的是delta方式的存储。即如果两个key拥有公共前缀,则两个key的实际形态是公共前缀+后面一个不同的字符进行存储,并非存储完整的两个key,所以 在prev的时候不仅仅需要读当前key,还需要找到前面第比他小的key来进行key的delta补全。
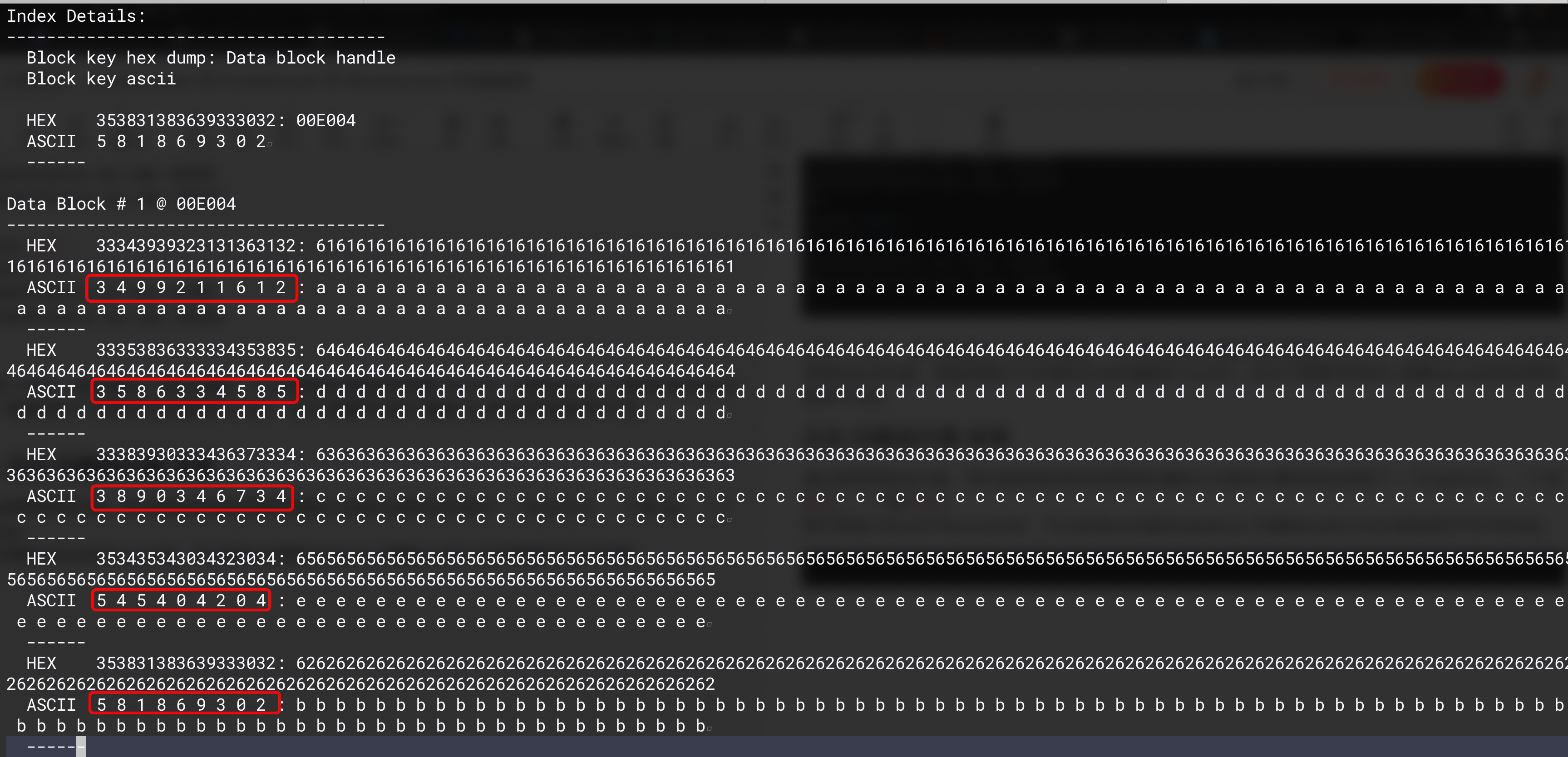
再分别看看我们的Next和 Prev的实现
在Next中,无需考虑其他,只需要按照顺序拿到key,并根据key的类型进行相应的处理就可以了。
void DBIter::Next() {assert(valid_);assert(status_.ok());PERF_CPU_TIMER_GUARD(iter_next_cpu_nanos, env_);// Release temporarily pinned blocks from last operation// 释放上一次Next占用的资源ReleaseTempPinnedData();local_stats_.skip_count_ += num_internal_keys_skipped_;local_stats_.skip_count_--;num_internal_keys_skipped_ = 0;bool ok = true;if (direction_ == kReverse) {is_key_seqnum_zero_ = false;if (!ReverseToForward()) {ok = false;}} else if (!current_entry_is_merged_) {// If the current value is not a merge, the iter position is the// current key, which is already returned. We can safely issue a// Next() without checking the current key.// If the current key is a merge, very likely iter already points// to the next internal position.assert(iter_.Valid());iter_.Next();PERF_COUNTER_ADD(internal_key_skipped_count, 1);}local_stats_.next_count_++;if (ok && iter_.Valid()) { // 根据key的类型处理就可以了。FindNextUserEntry(true /* skipping the current user key */,prefix_same_as_start_);} else {is_key_seqnum_zero_ = false;valid_ = false;}if (statistics_ != nullptr && valid_) {local_stats_.next_found_count_++;local_stats_.bytes_read_ += (key().size() + value().size());}
}
而Prev的实现则没有这么单一了,因为底层的存储本身是升序存储,Next只需要在mem/imm/l0(多个iter)/l1/l2… 这一些迭代器做堆排序就可以了。prev还需要不断得向前读,直到读到一个restart点(读完完整的data-block)确认好当前key的delta部分。
如下代码是Prev的核心部分实现:
void DBIter::PrevInternal() {while (iter_.Valid()) {saved_key_.SetUserKey(ExtractUserKey(iter_.key()),!iter_.iter()->IsKeyPinned() || !pin_thru_lifetime_ /* copy */);if (prefix_extractor_ && prefix_same_as_start_ &&prefix_extractor_->Transform(saved_key_.GetUserKey()).compare(prefix_start_key_) != 0) {// Current key does not have the same prefix as startvalid_ = false;return;}assert(iterate_lower_bound_ == nullptr || iter_.MayBeOutOfLowerBound() ||user_comparator_.Compare(saved_key_.GetUserKey(),*iterate_lower_bound_) >= 0);if (iterate_lower_bound_ != nullptr && iter_.MayBeOutOfLowerBound() &&user_comparator_.Compare(saved_key_.GetUserKey(),*iterate_lower_bound_) < 0) {// We've iterated earlier than the user-specified lower bound.valid_ = false;return;}// 对当前key的type进行处理,确保读到的key是最新的// 如果读到的是merge类型,则需要不断得向前mege// 如果读到的是Delete类型,则需要不断得向前读,// 直到遇到一个大于这个key版本的key//(reverse过程中遇到的delete版本较低,需要继续向前读才能读到同一个userkey的更新版本)if (!FindValueForCurrentKey()) { // assigns valid_return;}// Whether or not we found a value for current key, we need iter_ to end up// on a smaller key.// 不断得向前扫描,直到找到了一个小于当前key的key才结束。if (!FindUserKeyBeforeSavedKey()) {return;}if (valid_) {// Found the value.return;}if (TooManyInternalKeysSkipped(false)) {return;}}// We haven't found any key - iterator is not validvalid_ = false;
}
总结下来就是Prev的过程需要读额外的key,因为prev的过程同一个user key的更新版本需要不断得向前读,才能读到。相比于Next原生 就能读到当前userkey的最新版本来说 scan的代价确实大了不少。
更底层的迭代器的Prev和Next可以看block.cc中的DataBlockIter,它提供了在不同 datablock 之间如何通过和 indexblock 的 restart点来读取指定的key。
优化
MyRocks 开发之前的性能测试 就发现了Rocksdb的这个问题,那他们也提出了比较友好的解决方案,那就是Reverse Comparator。我们知道Rocksdb 的key的写入/读取顺序是依赖 Comparator ,也就是sst内部的有序是由Comparator决定的。
就像是 我们为一个vector排序,可以通过一个自定义comparator来决定vector中元素的排序行为。对于Rocksdb来说,这个Comparator 作用的地方主要是 memtable中skiplist的构建以及 compaction过程中将key写入一个新的sst。所以这个comparator 决定了keys在sst文件中的顺序。所以,MyRocks 针对 Reverse-scan 痛点 实现了Reverse Comparator : ReverseBytewiseComparator,它就是指定key的存储顺序和原来相反。
可以通过options.comparator = rocksdb::ReverseBytewiseComparator();指定,因为UDB的这种reverse-scan 模式比较固定,所以可以在构建db的时候直接用这个comparator。很明显这个优化的好处就是将原来的Reverse-scan 变更为 Forward-scan,性能能够提升10-15%的样子(可以使用上面的代码进行测试)。
总结
这里MyRocks 开发团队 仅仅实现了一个ReverseBytewiseComparator 在MyRocks 的 scan 痛点中 得到这样的优化提升,所以能够看出来 Rocksdb 的可扩展性。在MyRocks 的论文中也有很多次表示对Rocksdb 可扩展性的认可。
同样,我们也能理解到rocksdb 这个引擎的定位 并不是说实现了一个全方位性能超越B±tree 的引擎,而是针对 任何用户的workload 经过非常简单的开发或者参数调整 能够达到超越其他引擎 或者 与其他引擎持平 的性能/功能。Rocksdb 将应用的可扩展性做到了极致,这是它广受欢迎的关键。
相关文章:

Java知多少(29)覆盖和重载
在类继承中,子类可以修改从父类继承来的方法,也就是说子类能创建一个与父类方法有不同功能的方法,但具有相同的名称、返回值类型、参数列表。如果在新类中定义一个方法,其名称、返回值类型和参数列表正好与父类中的相同࿰…
Java项目:清新论坛系统(java+SSM+mysql+maven+tomcat)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:本系统分用户前台和管理员后台。 用户前台主要功能有: 用户注册 用户登录 浏览帖子 回复帖子 修改个人资料 管理员后台的功能有: 管理论坛版块 用户管…
JUnit4.11 理论机制 @Theory 完整解读
最近在研究JUnit4,大部分基础技术都是通过百度和JUnit的官方wiki学习的,目前最新的发布版本是4.11,结合代码实践,发现官方wiki的内容或多或少没有更新,Theory理论机制章节情况尤为严重,不知道这章wiki对应的…

树链剖分——线段树区间合并bzoj染色
线段树区间合并就挺麻烦了,再套个树链就更加鬼畜,不过除了代码量大就没什么其他的了。。 一些细节:线段树每个结点用结构体保存,pushup等合并函数改成返回一个结构体,这样好写一些 struct Seg{int lc,rc,tot;Seg(){lcr…
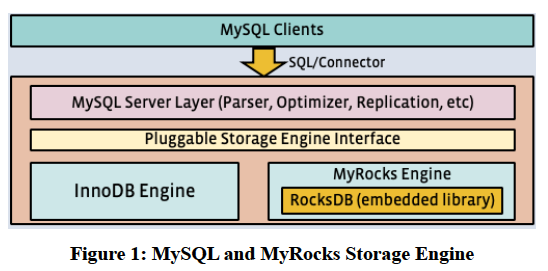
MyRocks: 为facebool 的社交图谱服务的LSM-tree存储引擎
文章目录概览1. UDB 架构2. UDB 表格式3. Rocksdb:针对flash存储优化过的第三方库3.1 Rocksdb架构3.2 为什么选择Rocksdb4. MyRocks / Rocksdb 开发历程4.1 设计目标4.2 性能挑战4.2.1 降低CPU的消耗4.2.2 降低range-scan 的延时消耗4.2.3 磁盘空间和Compaction 的一…
Java项目:精品酒店管理系统(java+SSM+mysql+maven+tomcat)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:主要功能主要功能会员管理,住客管理,房间管 理,系统管理,以及一些重要数据的展示导出维护等等; 二、项目运行 环境配置&…
iOS自动布局一
Align: Pin: 转载于:https://www.cnblogs.com/123qw/p/4404167.html
C#实现路由器断开连接,更改公网ip
publicstaticvoidDisconnect(){stringurl "断 线"; stringuri "http://192.168.1.1/userRpm/StatusRpm.htm?Disconnect"System.Web.HttpUtility.UrlEncode(url, System.Text.Encoding.GetEncoding("gb2312")) "&wan1"; str…
Go中的iota
当时在学习Iota这个知识点的时候仅仅是一笔掠过,比如这种 const(aiotab c) 一眼看出他怎么使用的时候就觉得自己已经懂得了 再到后来看到这样的例子 const(a 5*iotab c )以及 const(a 1<<(10*iota)bc ) 第一…
从 SSLTLS 的底层实现来看 网络安全的庞大复杂体系
文章目录前言1. HTTP协议通信的问题1.1 tcpdump 抓取http 请求包1.2 报文分析1.3 HTTP 协议问题2. SSL & TLS 协议的基本介绍和历史演进3. TLS 1.2 实现加密传输的过程3.1 TLS HandShake 协议概览3.2 第一次握手:ClientHello3.3 第二次握手:从Server…

UICollectionView
UICollectionView 多列的UITableView,最简单的形式,类似于iBooks中书架的布局,书架中放着你下载的和购买的电子书。 最简单的UICollectionView是一个GridView,可以多列的方式进行展示。 包含三部分,都是UIView的子类: …

Java项目:课程资源管理+在线考试平台(java+SSH+mysql+maven+tomcat)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 管理员可以增删改查教材、教材商、入库教材、用户(用 户包括学生和教师)可以对教材商、教材进行。xcel的导入 导出操作。教师可以领取入库的教材,可以退还教…

python twisted 笔记
2019独角兽企业重金招聘Python工程师标准>>> 1.Twisted框架构建简单的C/S 要写一个基于twisted框架的服务器,你要实现事件处理器,它处理诸如一个新的客户端连接、新的数据到达和客户端连接中断等情况。 在Twisted中,你的事件处理器定义在一个…

决策树J48算法
1. J48原理 2. 举例 3. 总结 1. J48原理 基于从上到下的策略,递归的分治策略,选择某个属性放置在根节点,为每个可能的属性值产生一个分支,将实例分成多个子集,每个子集对应一个根节点的分支,然后在每个分支…
分布式系统 一致性模型的介绍 以及 zookeeper的 “线性一致性“ 讨论
文章目录1. 一致性 概览1.1 分布式系统的 “正确性”1.2 线性一致性(Linearizability)1.3 顺序一致性(Sequential consistency)1.4 因果一致性(Casual consistency)1.5 最终一致性(Eventual consistency)2. Zookeeper 的 “线性一致性” 问题3. 参考一致性算是分布式系统的定位…
Java项目:(小程序)全套商城系统(spring+spring mvc+mybatis+layui+微信小程)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 商品模块: 商品添加、规格设置,商品上下架等 订单模块: 下单、购物车、支付,发货、收货、评 退款等 营销模块: 积分、优惠券、分销、砍价、拼团、秒 多…
【转】[退役]纪念我的ACM——headacher@XDU
转自:http://hi.baidu.com/headacher/item/5a2ce1d50609091b20e25022 退役了,是时候总结一下我ACM的生涯了。虽然很舍不得,但这段回忆很值得纪念。ACM生涯虽然结束,但是新生活总要继续,还有很多东西需要我去学习&#…
VMware扩大硬盘后修改Linux逻辑卷大小
一、背景随着业务的不断成熟,数据库积累的数据也越来越多了。前些天发现服务器的磁盘将要满了。因此向虚拟化管理员申请增加磁盘空间。由于这个系统是建立在威睿的vSphere平台上的,因此虚拟化管理员只简单地通过 VMware vSphere Client 扩大了磁盘空间&a…
axios与ajax区别
1.jQuery ajax $.ajax({ type: POST, url: url, data: data, dataType: dataType, success: function () {}, error: function () {}});优缺点: 本身是针对MVC的编程,不符合现在前端MVVM的浪潮基于原生的XHR开发,XHR本身的架构不清晰,已经有…
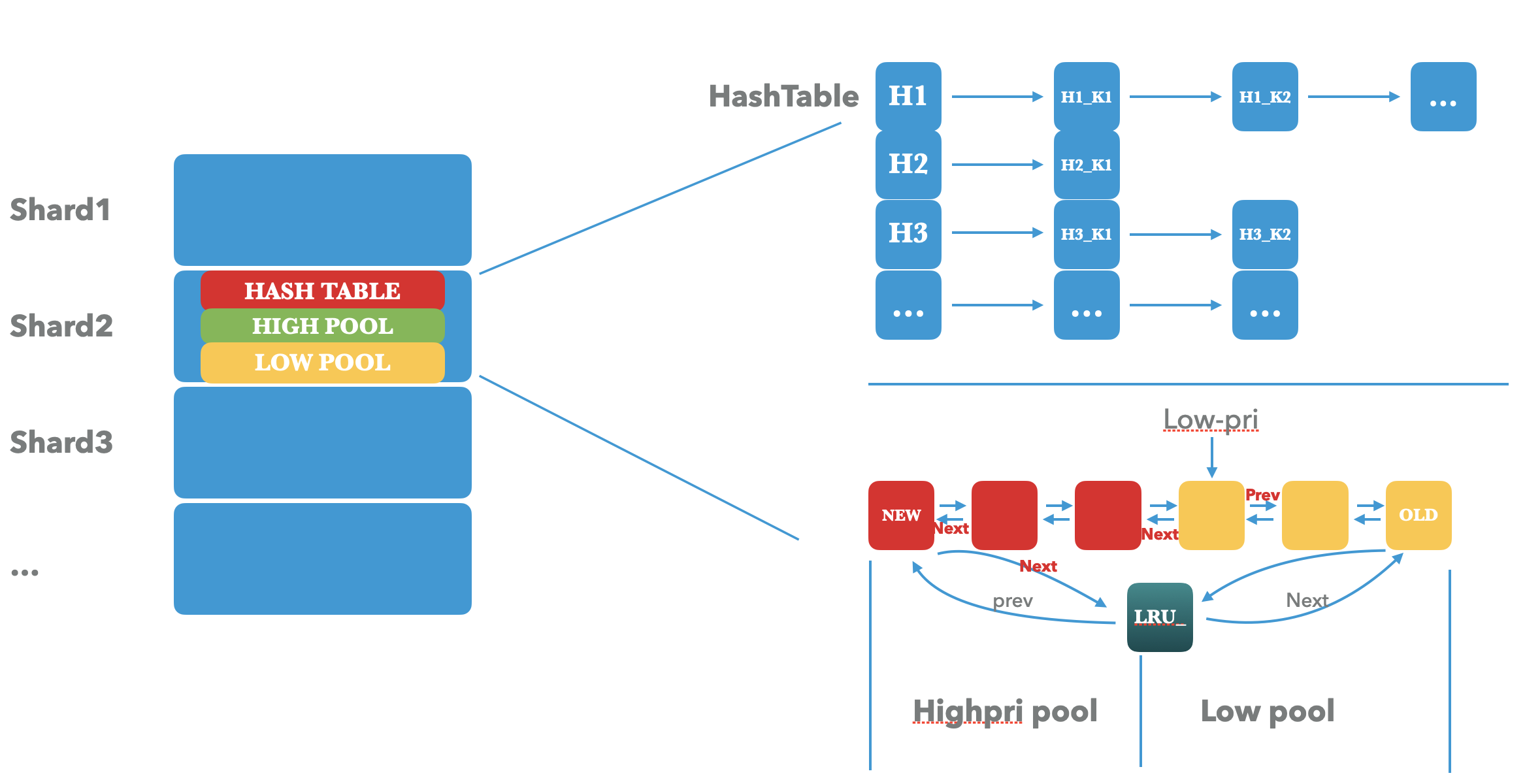
单机 “5千万以上“ 工业级 LRU cache 实现
文章目录前言工业级 LRU Cache1. 基本架构2. 基本操作2.1 insert 操作2.2 高并发下 insert 的一致性/性能 保证2.3 Lookup操作2.4 shard 对 cache Lookup 性能的影响2.4 Erase 操作2.5 内存维护3. 优化前言 近期做了很多 Cache 优化相关的事情,因为对存储引擎较为熟…
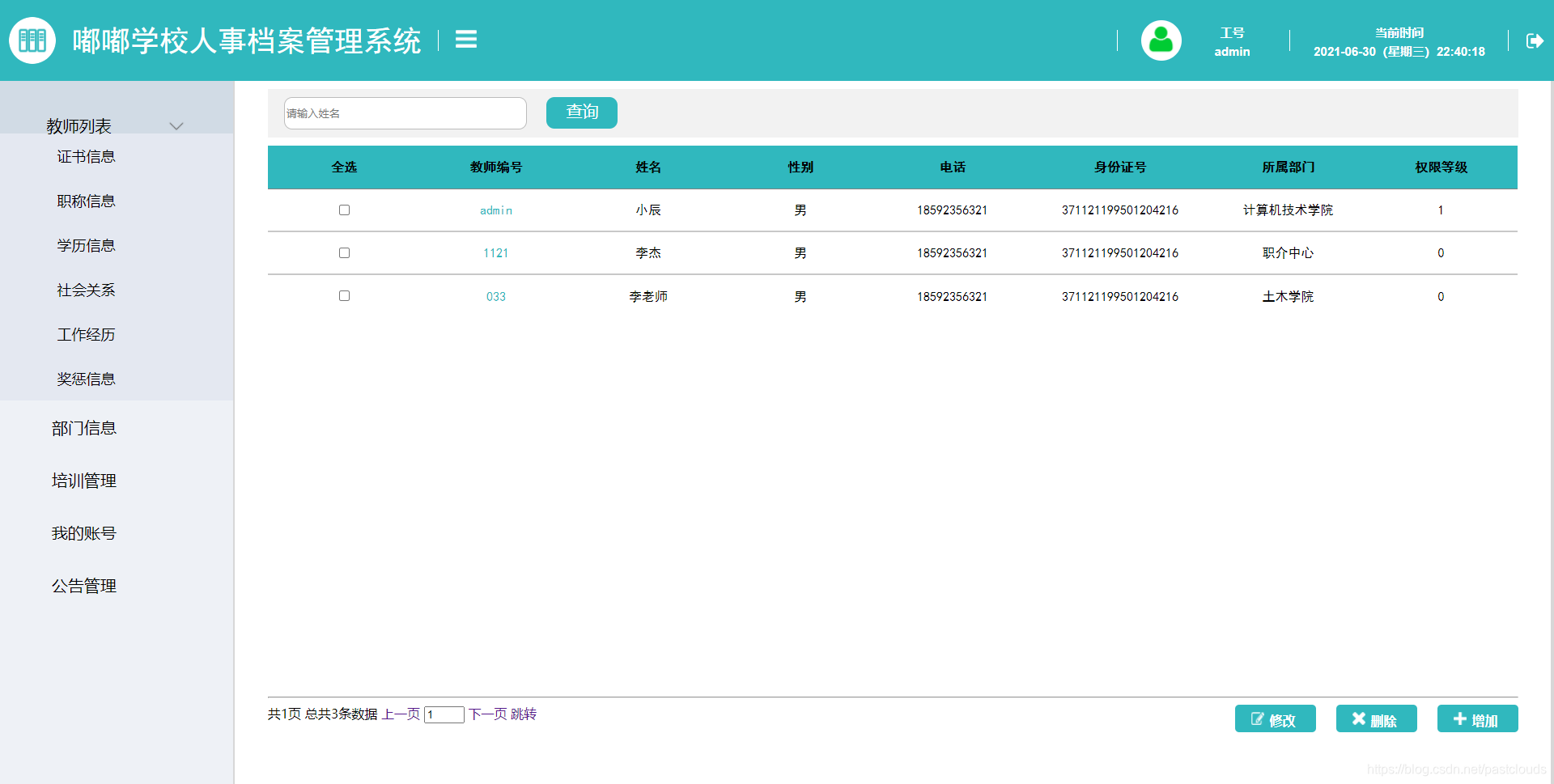
Java项目:校园人力人事资源管理系统(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 校园人力资源管理系统:学校部门管理,教室管理,学历信息管理,职务,教师职称,奖励,学历,社会关系,工作…

GPS部标平台的架构设计(十)-基于Asp.NET MVC构建GPS部标平台
在当前很多的GPS平台当中,有很多是基于asp.NETsiverlight开发的遗留项目,代码混乱而又难以维护,各种耦合和关联,要命的是界面也没见到比Javascript做的控件有多好看,随着需求的增多,平台已经臃肿不堪。 设计…
关于CSDN不给任何通知强制关闭我的6年博客,我深表痛心
关于CSDN不给任何通知强制关闭我的6年博客,我深表痛心。最近有很长一段时间没有去csdn博客了, 前几天去看的时候发现博客被封闭了。 我联系了管理员,但是没有得到任何回复。 我猜想,可能是不是我在博客文章里面加入 自己网站的网…
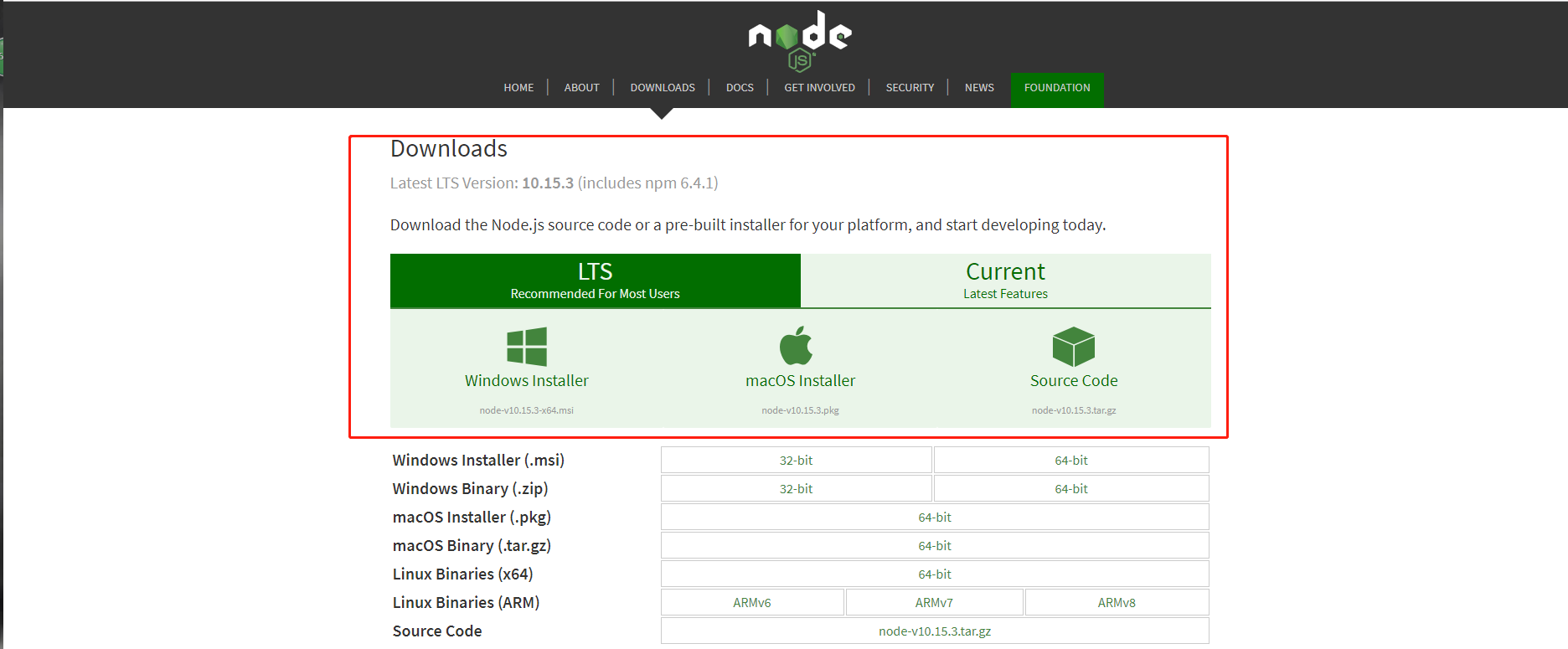
Vue 环境搭建(win10)
1.安装node node官网安装地址 推荐安装稳定版本(LTS)以及安装路径为系统盘(C) 查看node安装成功否 注释:以下命令使用 命令提示符(管理员)权限,win10 对user权限的限制了访问权限。node -v 查看…

Java项目:化妆品商城系统(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统主要实现的功能有: 网上商城系统,前台后台管理,用户注册,登录,上架展示,分组展示,搜索,收…
python 绘图脚本系列简单记录
简单记录平时画图用到的python 便捷小脚本 1. 从单个文件输入 绘制坐标系图 #!/usr/bin/python # coding: utf-8 import matplotlib.pyplot as plt import numpy as np import matplotlib as mpl import sysfile_name1 sys.argv[1] data_title sys.argv[2] print(file_name1…
iOS-c语言小练习01
// // main.c // C-变量的地址 // // Created by cgq on 15/4/9. // Copyright (c) 2015年 cgq. All rights reserved. // #include <stdio.h> //访问变量的地址 void test1() { char a A; int b 44; printf("a的值:%d\n",a); pri…
蓝桥杯 【基础练习】 十六进制转八进制
问题描述给定n个十六进制正整数,输出它们对应的八进制数。输入格式输入的第一行为一个正整数n (1<n<10)。接下来n行,每行一个由0~9、大写字母A~F组成的字符串,表示要转换的十六进制正整数,每个十六进…

泛在网:泛在网
ylbtech-泛在网:泛在网泛在网络来源于拉丁语Ubiquitous,从字面上看就是广泛存在的,无所不在的网络。也就是人置身于无所不在的网络之中,实现人在任何时间、地点,使用任何网络与任何人与物的信息交换,基于个…

Mac 从Makefile 编译 Rocksdb 源码的一些注意事项
文章目录前言Makefile 编译流程1. 平台变量/环境变量的初始化。2. 编译需要的源码文件变量初始化。3. include 目录的设置。4. 编译的执行逻辑。问题记录1:可能的打包命令ar 失效问题5. 执行具体的编译指令问题记录2: jar 包编译前言 最近在Mac 本地编译Rocksdb 过…