单机 “5千万以上“ 工业级 LRU cache 实现
文章目录
- 前言
- 工业级 LRU Cache
- 1. 基本架构
- 2. 基本操作
- 2.1 insert 操作
- 2.2 高并发下 insert 的一致性/性能 保证
- 2.3 Lookup操作
- 2.4 shard 对 cache Lookup 性能的影响
- 2.4 Erase 操作
- 2.5 内存维护
- 3. 优化
前言
近期做了很多 Cache 优化相关的事情,因为对存储引擎较为熟悉,所以深入研究了 Rocksdb 的Cache实现,可以说是朴实无华得展示了工业级Cache的细节,非常精彩。
欣赏实现的同时做了一些简单的代码验证,同时将整个 Cache 的实现做了一番梳理,发现真实处处都是设计,基本的算法实现只是最基础的能力,如何设计实现的每一个细节 与 我们的cpu cacheline 运行体系绑定,如何实现insert/lockup 链路中的无锁,如何不影响性能的基础上保持对Cache的内存控制,如何让频繁的内存分配和释放不是cache的性能瓶颈… 等等都是需要非常多的设计。
本篇及下一篇将主体介绍两种 Rocksdb 实现的高性能 工业级 Cache中的LRUCache 和 ClockCache。
相关的Cache 实现代码 以及 通用的cache_bench 工具 已经单独摘出来,并在其上补充了一些更好展示cache内部状态的功能,代码路径:https://github.com/BaronStack/Cache_Bench。
编译运行:
# 1. 编译
sh build.sh ;
# 2. 执行压测
./cache_bench -threads=32 \
-lookup_percent=100 \
-erase_percent=0 \
-insert_percent=0 \
-num_shard_bits=10 \
-cache_size=2147483648 \
-use_clock_cache=false # 使用的是 LRU Cache# 3. 输出
Number of threads : 32
Ops per thread : 1200000
Cache size : 2147483648
Num shard bits : 10
Max key : 1073741824
Populate cache : 0
Insert percentage : 0%
Lookup percentage : 100%
Erase percentage : 0%
Test count : 1
----------------------------
1 Test: complete in 0.670 s; QPS = 57348698
整体介绍整个 Cache 体系实现之前,我们先思考一下我们的生产环境对Cache 的功能/性能 需求:
- Cache的读性能至关重要,Cache的存在大多数是为了弥补我们热点 低延时需求的场景下的高昂I/O代价,所以高性能的读 一定是必要的,良好的数据结构的选型是关键,且要优于从page-cache读,不然我们干嘛需要单独的cache,直接存在page-cache得了(不考虑内存占用问题)。
- 高并发场景下需要保证Cache的可靠性。比如,我们多线程下insert的时候需要保证cache数据结构更新的原子性。这里的更新包括insert/erase。所以在更新链路上可能需要加锁,如何解决锁引入的 CPU 上下文切换的代价?
- 友好的内存控制功能。我们的线上机器往往不是一个服务在运行,为了防止内存无止境的消耗引发操作系统的OOM或者其他服务的swap ,则需要对当前服务的Cache所占用的内存进行限制。这个时候,怎样尽可能得保证可能得热点长期存在于Cache之中,则需要我们重点关注。
- 一些边缘功能的实现。更高效的分配器选型,cache的insert/erase 会涉及到非常频繁的内存操作,如何保证在复杂的workload场景(key-value大小差异非常大,几个byte 到 几 M;频繁的插入和Erase)能够对Cache拿到的内存有一个高效的管理,在对分配器底层有足够了解的情况下 选择合适的分配器能够起到加速cache使用 的作用。
综合来看,一个工业级高效Cache的实现是需要 深入理解数据结构、操作系统的CPU子系统、内存子系统的实现 才能保证最终的产出是高效合理 满足工业级需求的。
限于作者能力有限,希望能在有限的能力基础上为大家展示更多的实现细节,一起品鉴,如有不足,麻烦一定指正。
工业级 LRU Cache
介绍 Rocksdb 对LRU cache的改造之前,先概览一下 LRU cache,顾名思义,LRU(Least recently used),近期使用最少的缓存单元将会被优先淘汰。
关于LRU的基本算法实现,网上介绍的太多了,基础的链表就能够满足针对LRU的插入/删除/查找了,这里就不做过多的展开了。我们直接进入正题,也就是Rocksdb 的LRU Cache如何在满足以上那几个需求的过程中针对LRU 做了哪一些改造。
1. 基本架构
先看一下整体的LRU Cache的架构:
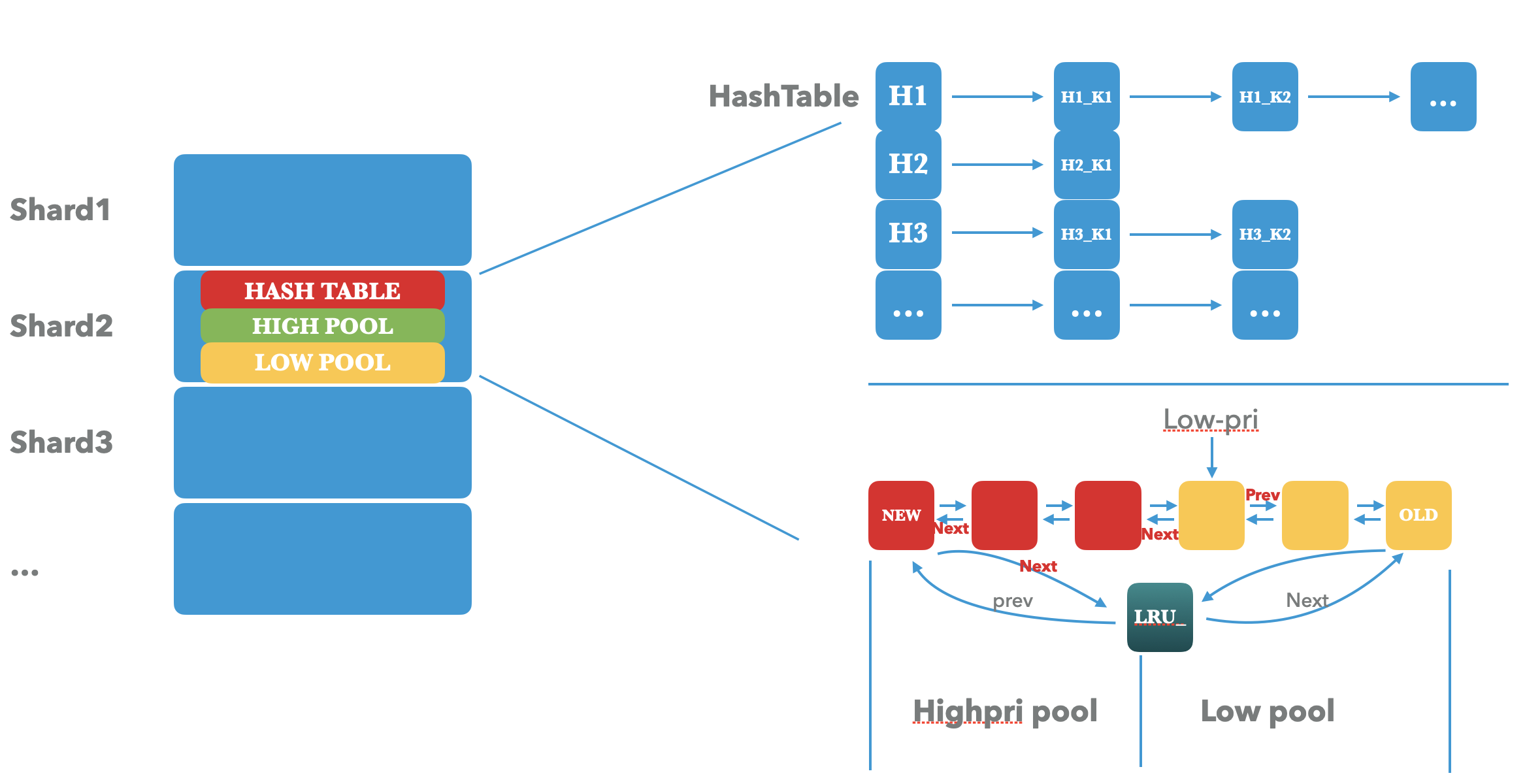
是不是看起来和 基本的LRU 实现有很大的差异,先整体介绍一下整个架构中每一个组件的作用,后续将详细介绍这几个组件是为了解决需求中的什么问题而引入的:
- shard。 我们可以看到,整个LRU cahce 从外部来看是一个个分开的shard,每一个shard内部才是真正的lru cache的底层实现。上层的用户请求 在进入cache操作之前 会先经过hash映射到预先创建好的一个个shard中,然后才是针对每个cache内部的操作。
- HashTable。 这个组件是为了加速shard内部 lru cache查找的,将要操作的key进行hash生成唯一的一个hash值,这个key的操作将落在某一个hash-bucket之中,通过单链表来解决hash冲突。每次针对hash表的链表插入都会采用头插法,保证越新的key将采越靠近bucket头部。
- High pri pool / Low pri pool。高优先级缓存池和低优先级缓存池 是主体的Cache部分,也就是 LRU 维护数据的主体部分。
lru_是高优先级pool的head,也是整个cache的head,所有高优先级的entry的插入都先插入到lru头部。low-pri是低优先级pool的尾部,所有针对低优先级pool的更新也都会插入到low-pri的尾部。从上图可以看到,高优先级pool的尾部和低优先级pool的尾部相接,这样从整个lru_链表来看,lru的prev就是整个lru-cache的最新的元素,lrv的next就是lru-cache的最旧的元素。
2. 基本操作
针对Cache的几个基本操作包括如下几种:
virtual bool Insert(const Slice& key, uint32_t hash, void* value,size_t charge,void (*deleter)(const Slice& key, void* value),Cache::Handle** handle,Cache::Priority priority) override;virtual Cache::Handle* Lookup(const Slice& key, uint32_t hash) override;virtual bool Ref(Cache::Handle* handle) override;virtual bool Release(Cache::Handle* handle,bool force_erase = false) override;virtual void Erase(const Slice& key, uint32_t hash) override;
更细粒度的一些数据结构的指标如下,能够直接将Cache 拥有的内部结构暴漏出来:
每一个cache entry 维护了一个 LRUHandle,可以看作是用来标识一个key-value
struct LRUHandle {void* value; void (*deleter)(const Slice&, void* value);LRUHandle* next_hash;LRUHandle* next;LRUHandle* prev;size_t charge; // TODO(opt): Only allow uint32_t?size_t key_length;// The hash of key(). Used for fast sharding and comparisons.uint32_t hash;// The number of external refs to this entry. The cache itself is not counted.uint32_t refs;enum Flags : uint8_t {// Whether this entry is referenced by the hash table.IN_CACHE = (1 << 0),// Whether this entry is high priority entry.IS_HIGH_PRI = (1 << 1),// Whether this entry is in high-pri pool.IN_HIGH_PRI_POOL = (1 << 2),// Wwhether this entry has had any lookups (hits).HAS_HIT = (1 << 3),};uint8_t flags;char key_data[1];
其中 主体部分包括:
- key_data: 实际插入的key数据部分
- value: 实际的value数据
- deleter ,是一个回调函数,用来清理ref=0, in-cache=false的key-value
- next_hash,是hashtable 中解决hash冲突的单链表
- next/prev: hpri, lrpi 中的双向链表
- charge,表示当前handle的大小
- hash,当前key的hash值,主要被用做hash-table/ high/low pool 中的key的查找,用来标识唯一key
- refs, key被引用的次数
- flags, 其四个字节分别被枚举类型 Flags 中的四个标识来用。这四个标识,将用来决定一个 LRUHandle 应该存储于哪里。
前面提到我们的shard cache 为了加速查找性能,引入了 hashtable, 基本的table 数据结构可以参考LRUHandleTable。
每一个 shard 则维护了这个 Cache 的内部信息,通过如下数据结构能够更直观得看到 Cache 的内部情况。
// Initialized before use.size_t capacity_;......LRUHandle lru_;LRUHandle* lru_low_pri_;LRUHandleTable table_;size_t usage_;size_t lru_usage_;......
};
- capacity。 当前shard的初始容量,我们外部配置的LRU cache大小会被均分到多个cache shard中
- lru_。高优先级pool的双向循环链表的表头,也是整个lru 链表的表头。
- lru_low_pri。低优先级pool,总是指向低优先级pool的链表头。
- table_。 hashtable 。
- usage_。整个shard 当前的使用总容量,包含lru_usage_的容量。
- lru_usage_。两个pool中的链表使用容量。
大体的shard 以及 shard内部数据结构就介绍这么多,下来我们从一些基础的操作来看看整个 shard 内部的状态。
2.1 insert 操作
了解LRU Cache最直接的办法就是从Insert 中来看,insert 会涉及针对每一个组件的操作,同时会夹杂着cache 满之后的数据淘汰过程,这也是Cache的算法基础体现。
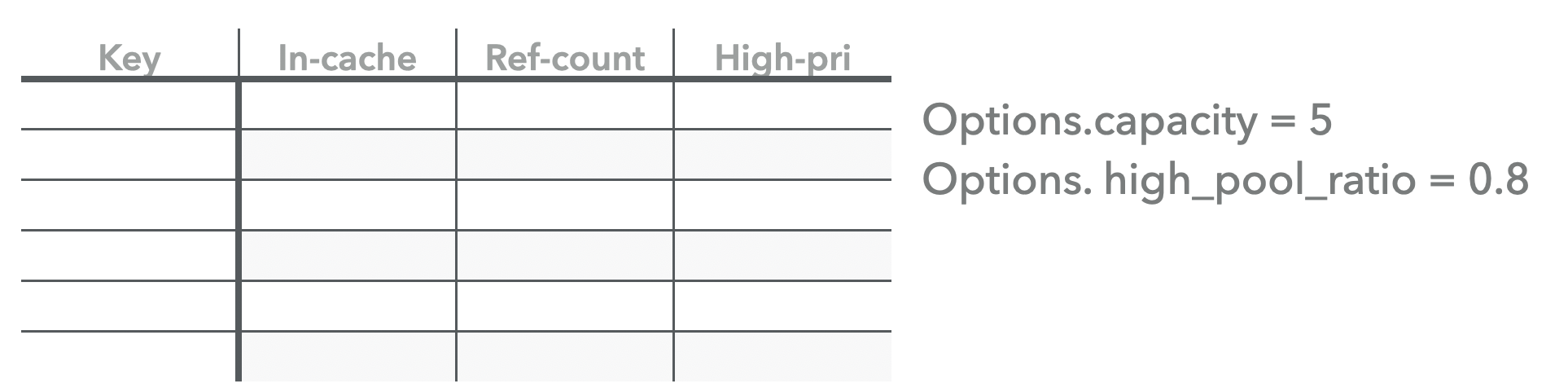
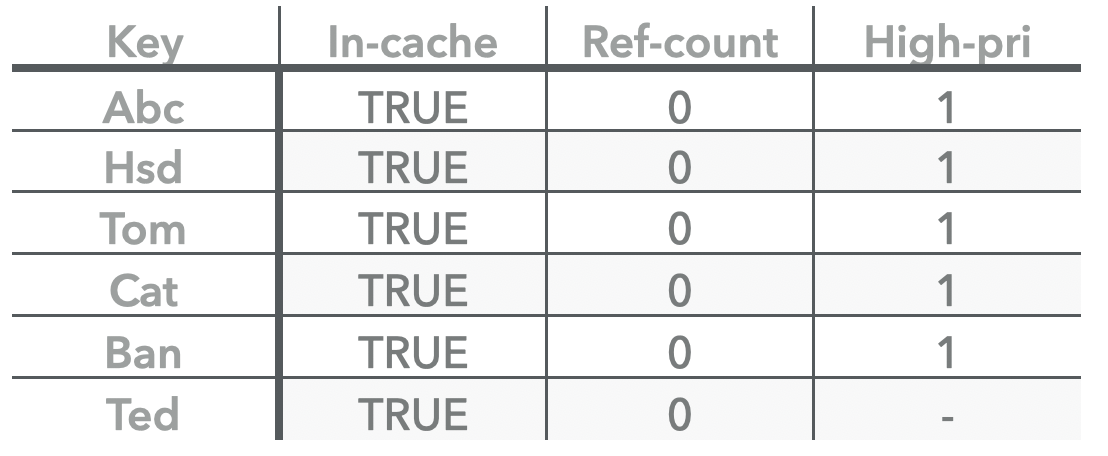
最开始的Cache中没有任何数据,我们初始化cache的一些配置如下:
ps: 这里的capacity实际是当前shard cache的大小,单位是bytes, 这里的5 是为了后续说明整个插入过程而用一种有歧义的方式来表示,可以看作是当前shard中能够保存多少个key-value的entry个数。
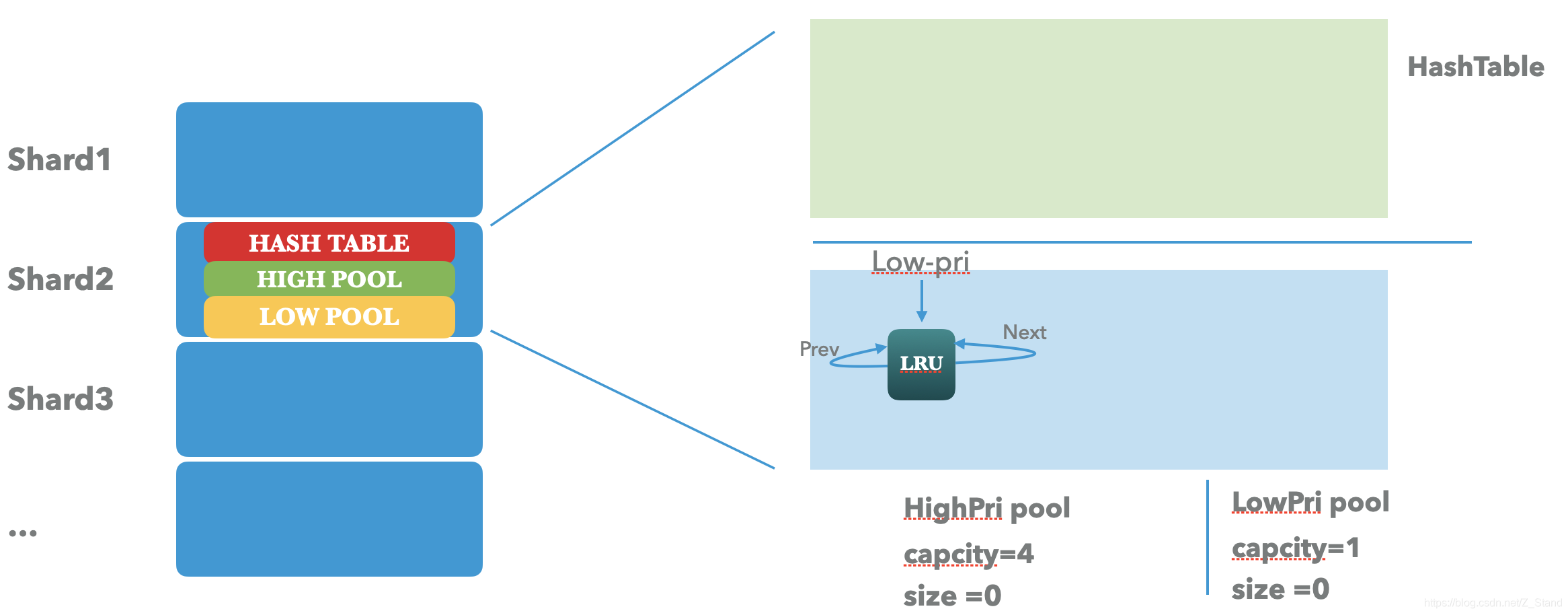
那么初始化之后的cache 情况如下:
- hashtable 只有在有key的时候才会动态初始化填充。
- high pri pool 根据初始时设置的cache 比例,将会初始化为capacity 为 4,且对双向循环链表进行初始化。
- low pri pool 则直接取 high 剩下的容量。
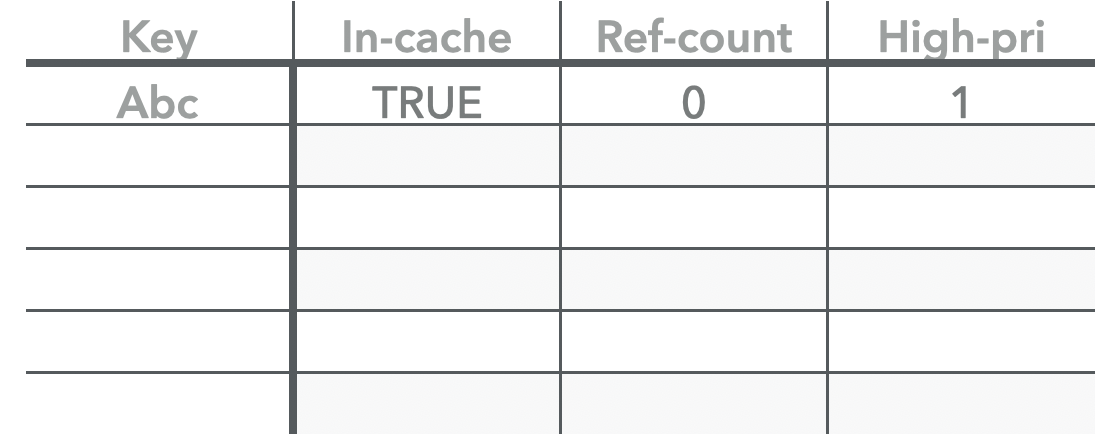
当我们插入一条enry的时候,经过对key的hash 可以知道这个key将落在哪一个shard,后续的操作都将针对这个shard来进行,接下来我们看看一条 key 在shard cache内部 的数据流:
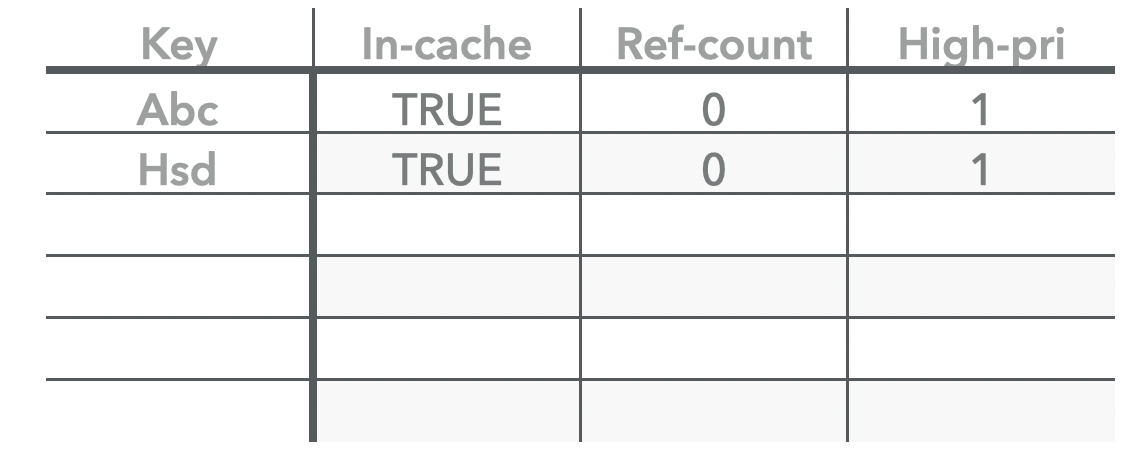
第一次插入的时候需会同步在hashtable 和 high-pool和之中,同时设置count 为0.
high pool 有充足的容量之前的插入都会先插入到highpool之中,如果high pool满了,会将high pool中最旧的数据淘汰到low pool之中。
则在shard cache中的插入过程如下:
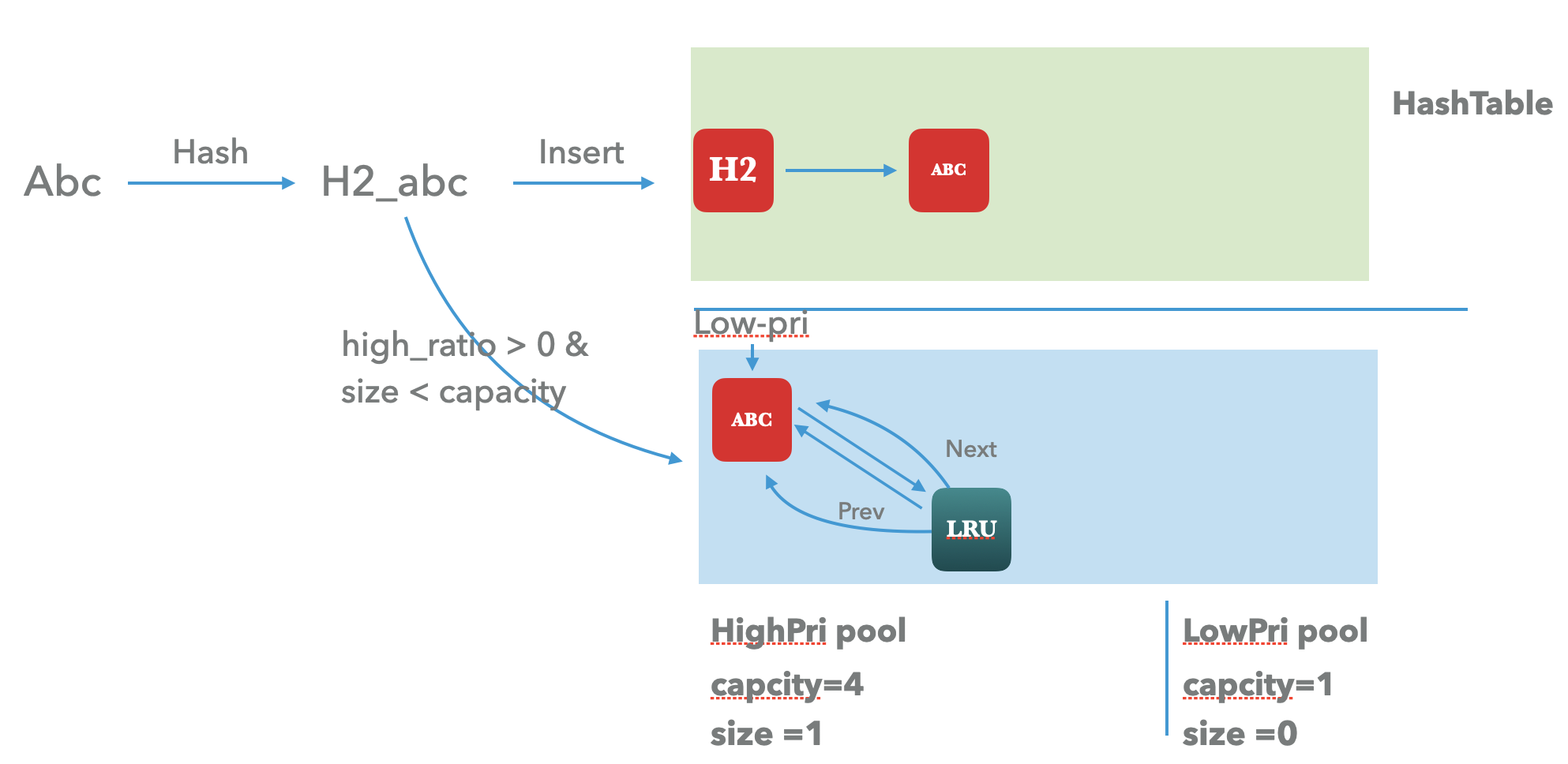
key在选择指定shard 操作之前会做一次hash, 带着这个hash值操作接下来的shard。
- 首先是更新hashtable,拿着这个hash值通过
hash & (length_ - 1)选择对应的hash-bucket,并采用头插法插入到这个bucket后的单链表中。 - 其次更新high pool 或者 low pool。判断初始参数设置的high pool的比例是否大于0,以及当前pool 是否未满,如果是则优先更新high pool,否则更新low pool。所以会先采用头插法,插入到lru_头部(高优先级 pool)。
第二次的插入也是类似的。
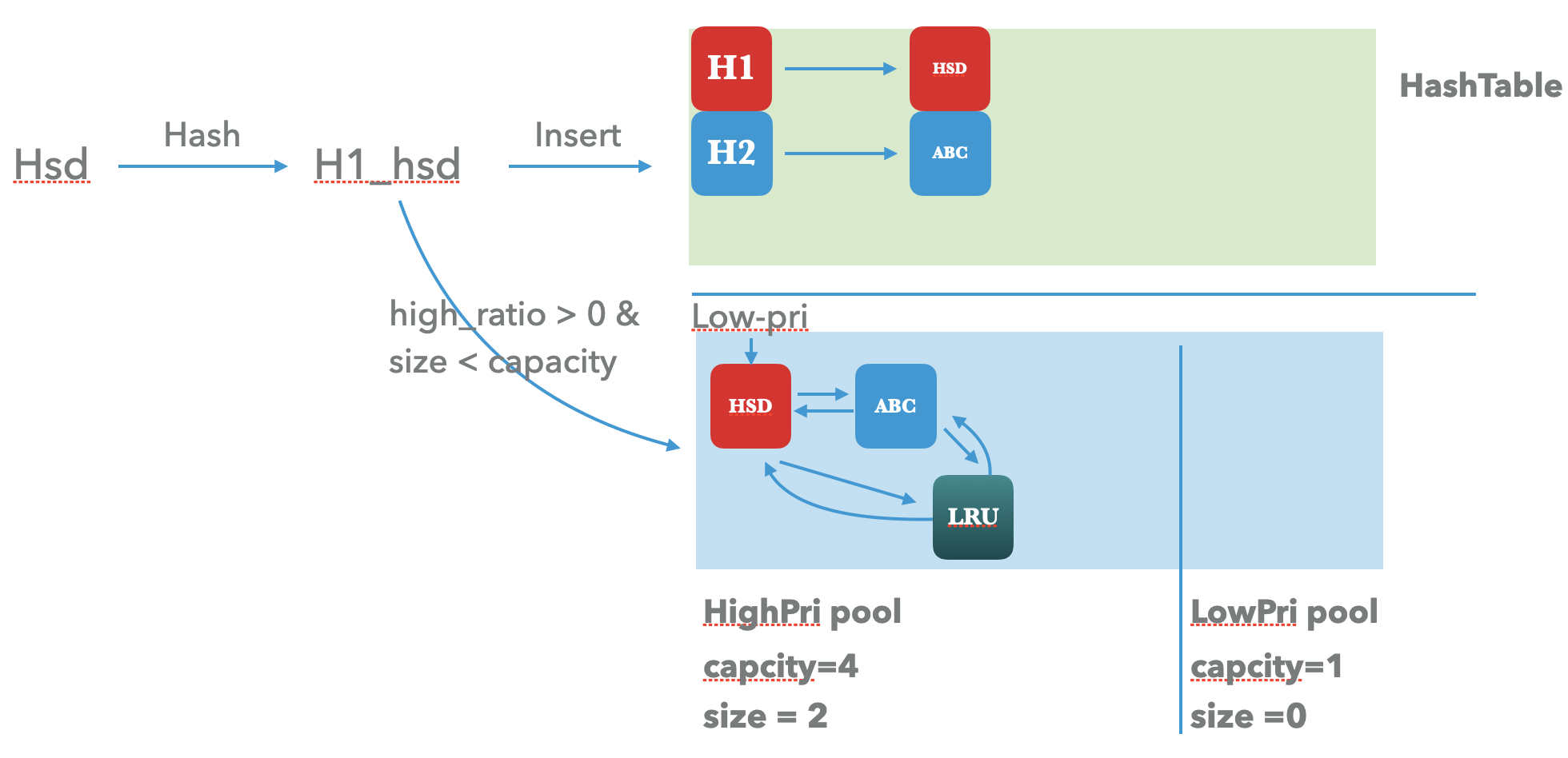
后续的插入针对hash-table 的更新 以及 lru_ 链表的更新都是采用头插法。
当high pool 插满之后,则需要将high pool最旧的元素插入到 low pool之中,这个时候就需要将low_pri的指针放在high pool的末尾了。
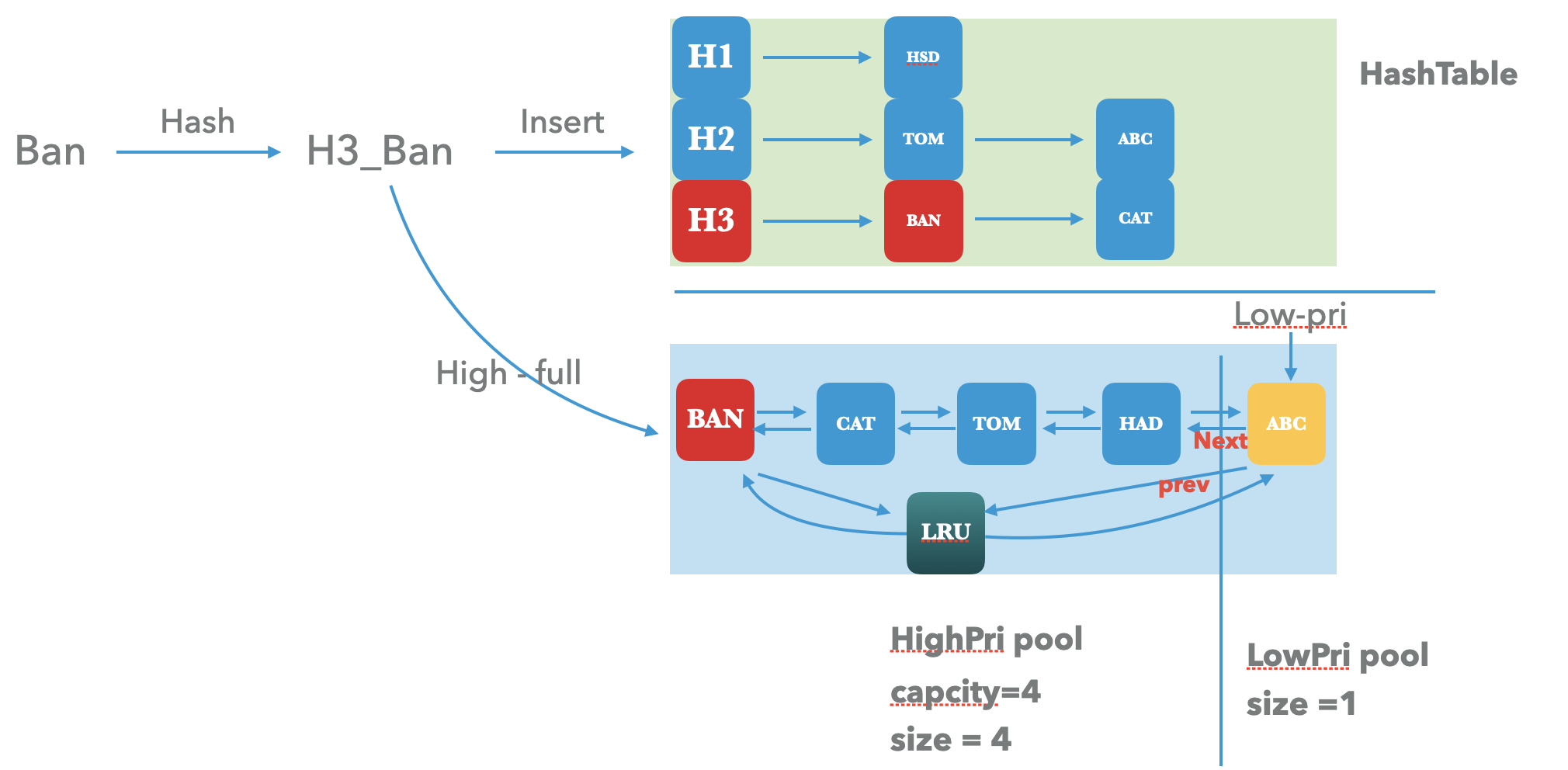
Ban 这个字符串需要插入到high pool的时候发现满了,插入还是会先插入到high pool的头部,但是low-pri指针需要需要向后移动一次,low-pri的next 直接指向的是high pool的末尾元素。
此时,在high-pool之中,头指针的lru_.prev指向的是最新的key,lru_.next指向的是最旧的key。
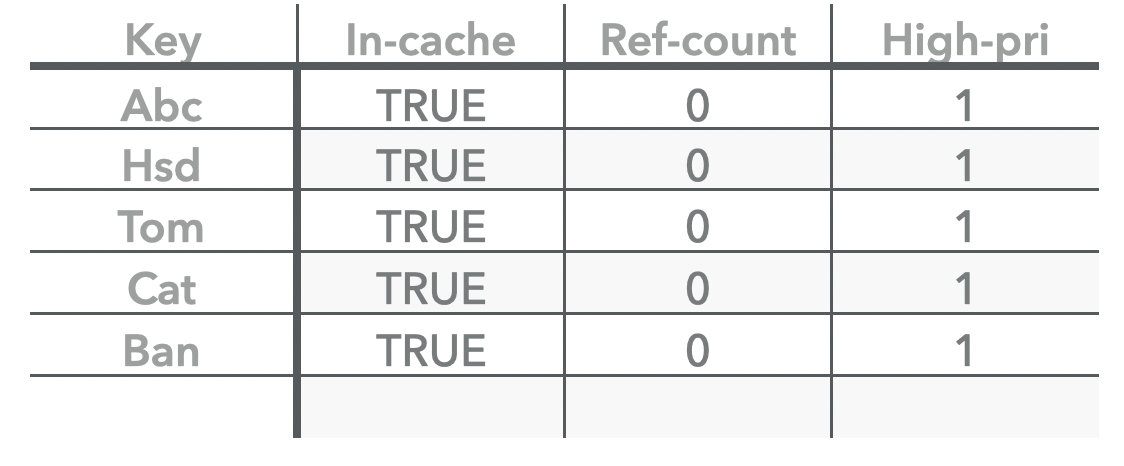
此时我们可以看到当前的shard-cache已经满了,那后续的insert将是什么样的行为呢,再插入一条key看看。
主体主要是两个步骤:
- 尝试插入新的key
Ted之前,会先检测插入后的容量是否超过capacity。这里显然是超过了,会出发cache evict,即从cache中移除最旧的一条key,显然就是lru.next指向的 abc了。现将abc 从hashtable 中移除,同时在其ref count为0的时候从lru-list中移除。 - 将新的key
Ted按照之前的方式插入到 hash-table 和 lru-list之中,并将high pool的最旧的keyhsd放在low-pool之中。
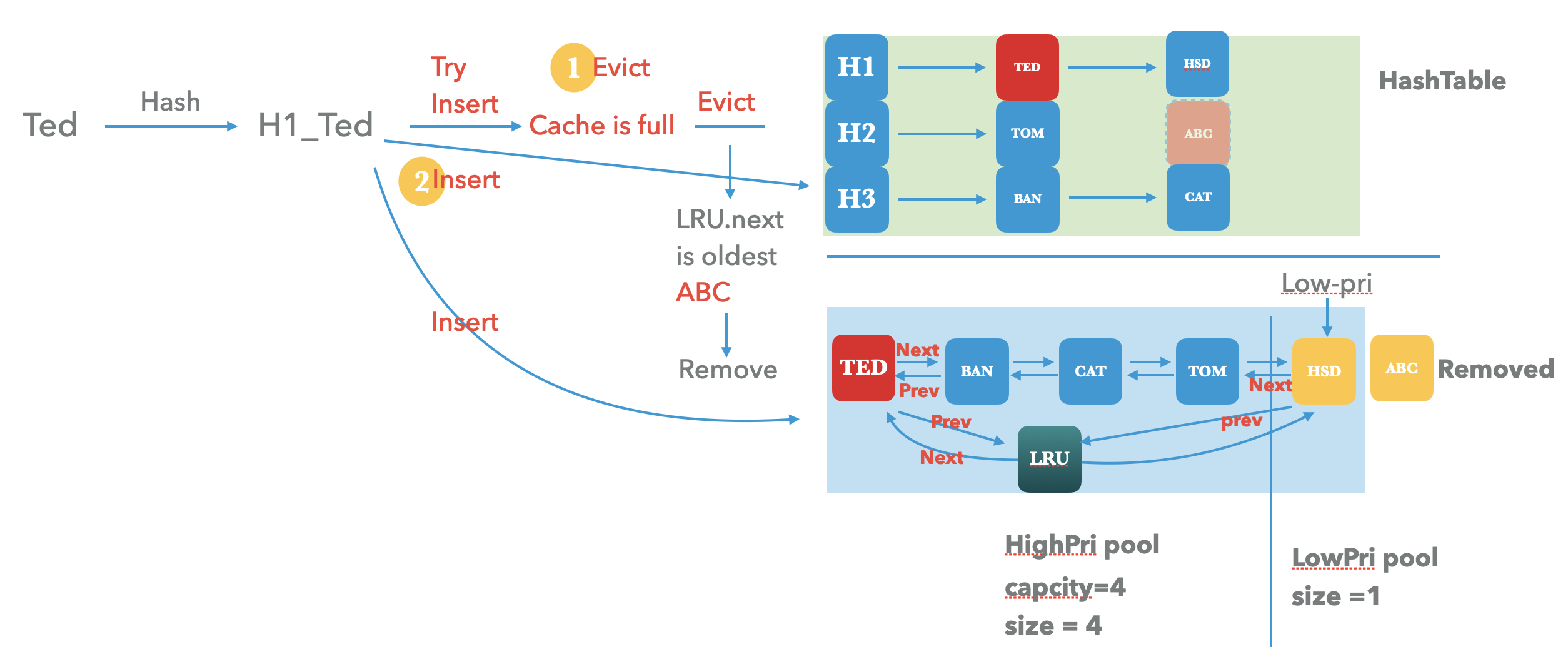
到此,基本的插入过程就已经很清晰了,我们能够看到high-pool的头插法 + low-pool 的尾插法 是能够完整的维护LRU Cache的特性。
可以看到,高低优先级 pool的功能,是为了尽可能得让热点key在cache中驻留的时间最长。而hashtable 的能力则是一个cache-key的全集,能够在需要lookup的时候以最快的速度找到目标key。
2.2 高并发下 insert 的一致性/性能 保证
这个时候,我们再回头看看我们的工业级需求。
可以看到Insert的过程涉及大量的指针更新(针对high/low/hashtable),所以针对同一个shard-cache的更新,如果我们不想出现指针指向的丢失或者指向错误,那就需要保证每一次更新的原子性了,那就需要引入锁机制了。
但是这个锁不应该影响整个shard的其他读取/更新操作,只需要保证当前handle的更新是一个排他锁,所以LRU-Cache的更新锁粒度是 key。锁的范围是 从 key 在 hashtable 中的更新到 key在lru-list 中的更新。
这把锁锁住了当前CPU 多次访存操作,而在高并发的cahce更新场景性能将非常难看,使用我们的cache-bench 做如下几个测试。
# 单shard 单线程的 纯 insert./cache_bench -threads=1 -lookup_percent=0 -erase_percent=0 -insert_percent=100 -num_shard_bits=0 -cache_size=2147483648 -use_clock_cache=false
Number of threads : 1
Ops per thread : 1200000
Cache size : 2147483648
Num shard bits : 0
Max key : 1073741824
Populate cache : 0
Insert percentage : 100%
Lookup percentage : 0%
Erase percentage : 0%
Test count : 1
----------------------------
1 Test: complete in 0.919 s; QPS = 1306012# 单shard 16线程的 纯 insert
./cache_bench -threads=16 -lookup_percent=0 -erase_percent=0 -insert_percent=100 -num_shard_bits=0 -cache_size=2147483648 -use_clock_cache=false
Number of threads : 16
Ops per thread : 1200000
Cache size : 2147483648
Num shard bits : 0
Max key : 1073741824
Populate cache : 0
Insert percentage : 100%
Lookup percentage : 0%
Erase percentage : 0%
Test count : 1
----------------------------
1 Test: complete in 38.139 s; QPS = 503421
可以看到如果我们只维护一个整体的cache,那在这种高并发场景下的性能将巨差,从单线程的130w 降到 16线程的 50w,因为针对一个cache - shard 的原子更新让多核场景的cpu根本无法发挥用处,性能显然会很差。
虽然锁 保证了多线程下的Cache一致性, 但是高并发场景的性能是用户所不能接受的。而为了提升多核硬件中高并发下的性能,cache的分shard策略是必然的。
如下测试,多shard的多线程显然比单shard 好很多,而这一点在cache的lookup heavy场景体现的更加明显,后面有详细的测试数据。
./cache_bench -threads=16 -lookup_percent=0 -erase_percent=0 -insert_percent=100 -num_shard_bits=5 -cache_size=2147483648 -use_clock_cache=false
Number of threads : 16
Ops per thread : 1200000
Cache size : 2147483648
Num shard bits : 5
Max key : 1073741824
Populate cache : 0
Insert percentage : 100%
Lookup percentage : 0%
Erase percentage : 0%
Test count : 1
----------------------------
1 Test: complete in 7.874 s; QPS = 2438406
2.3 Lookup操作
那我们继续。
接下来看看 LRU 的查找操作,查找很简单。
查找的大体过程如下:
- 先从hashtable 中查找,如果找不到直接返回。
- 找到了,拿着找到的handle 返回即可。
- 同时,为了提升lookup 命中cache的key的热度,会标记当前key为命中。再次insert 当前key时,则会直接放在高优先级的pool中。
- 判断其ref是否为0,如果是会将其从lru链表中移除,但因为它被查找过,所以还会在hashtable中保留一份它的key-handle。
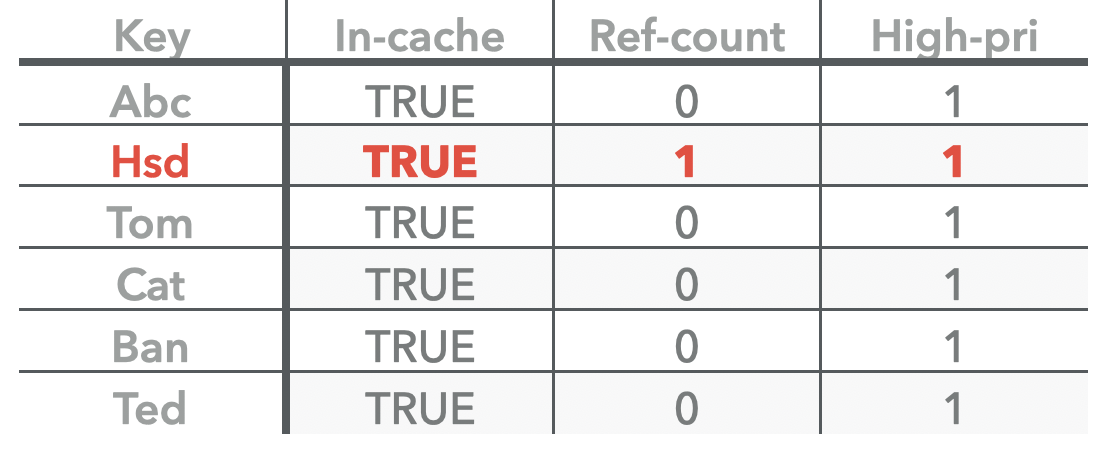
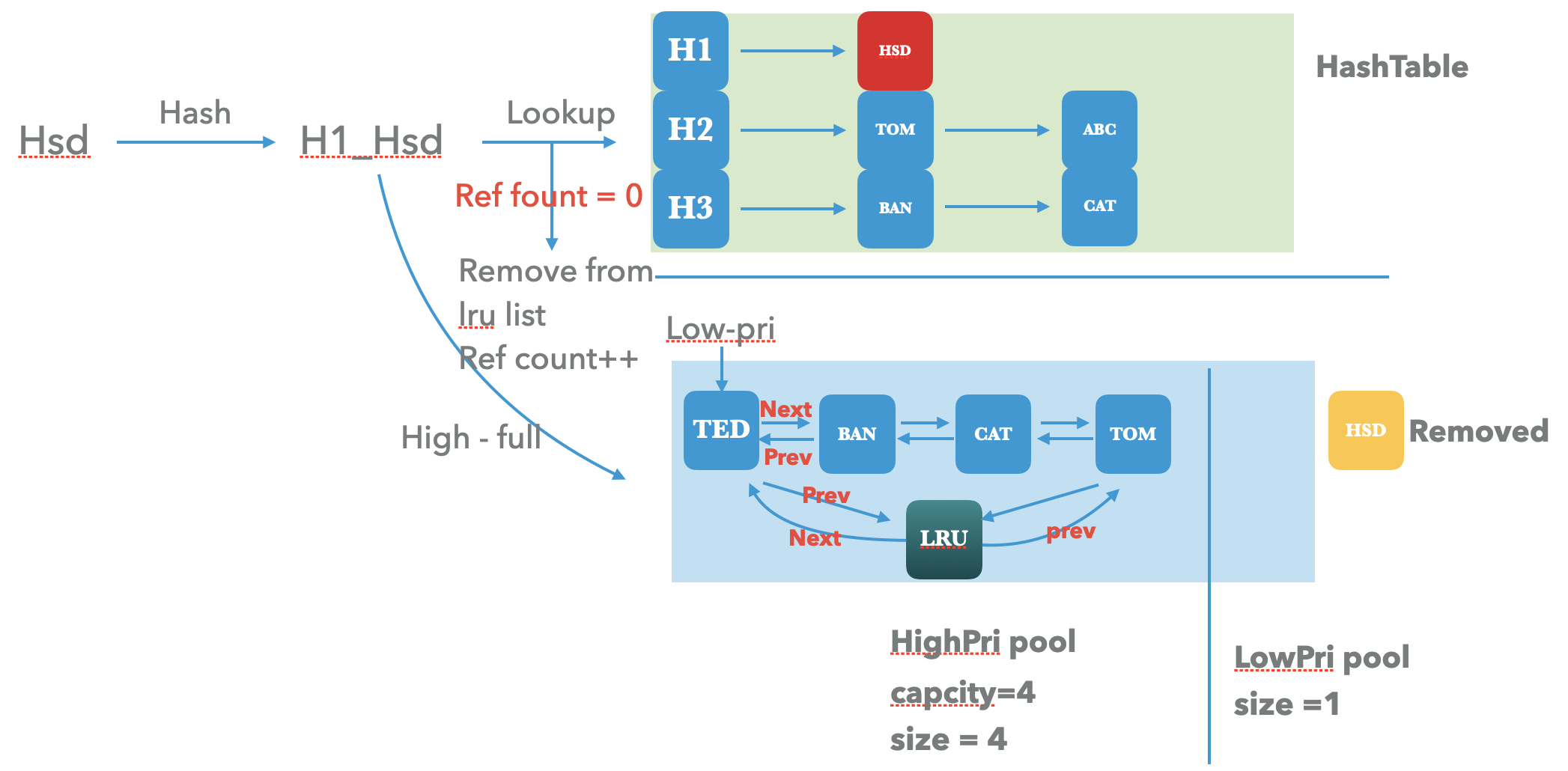
如果ref count 为0 时,对于Cache来说再次进行操作就可以进行清理了,因为 目的是为了让热点key长期驻留在cache中。而lookup则表明这个key是一个热点key,所以会将其保留在HashTable中,因为之前的ref count 为0,则会从LRU 中移除,但是会标记hit,在后续的insert 操作则会再次添加到lru-cache的high-pool中。
所以,Lookup操作也会有指针的更新,也就需要锁的保护了。
Cache::Handle* LRUCacheShard::Lookup(const Slice& key, uint32_t hash) {MutexLock l(&mutex_);LRUHandle* e = table_.Lookup(key, hash);if (e != nullptr) {assert(e->InCache());if (!e->HasRefs()) {// The entry is in LRU since it's in hash and has no external references// LRU 双向链表中的移除操作。LRU_Remove(e);}e->Ref();e->SetHit();}return reinterpret_cast<Cache::Handle*>(e);
}
所以,因为工业级cache对一致性的需求引入了锁,那我们想要提升性能,分shard仍然有很大的需求了,对于shard来说 无非引入了一点内存管理的代价而已,性能上key的按hash映射是位运算,可能就几个ns,根本没有什么消耗。
2.4 shard 对 cache Lookup 性能的影响
我们来测试一下Lookup性能,保持80% 的lookup和20% 的insert,分别看一下单shard下单线程和多线程的性能 已经 多shard下的多线程性能。
# 单线程 单sharda
./cache_bench -threads=1 -lookup_percent=80 -erase_percent=0 -insert_percent=20 -num_shard_bits=0 -cache_size=2147483648 -use_clock_cache=false
Number of threads : 1
Ops per thread : 1200000
Cache size : 2147483648
Num shard bits : 0
Max key : 1073741824
Populate cache : 0
Insert percentage : 20%
Lookup percentage : 80%
Erase percentage : 0%
Test count : 1
----------------------------
1 Test: complete in 0.273 s; QPS = 4398988# 多线程 单shard
./cache_bench -threads=16 -lookup_percent=80 -erase_percent=0 -insert_percent=20 -num_shard_bits=0 -cache_size=2147483648 -use_clock_cache=false
Number of threads : 16
Ops per thread : 1200000
Cache size : 2147483648
Num shard bits : 0
Max key : 1073741824
Populate cache : 0
Insert percentage : 20%
Lookup percentage : 80%
Erase percentage : 0%
Test count : 1
----------------------------
1 Test: complete in 18.037 s; QPS = 1064451
可以看到,单shard下的单线程有440w /s 的吞吐,而 多线程仅有106w。
再跑一下多shard的场景,我们跑了1024个shard,可以看到性能能够达到 1950w/s (在lookup 比例更高一些的场景,随着shard个数的增加,性能甚至能够达到线性,当然实际shard个数大于2^20 的时候性能就开始退化了)。
./cache_bench -threads=16 -lookup_percent=80 -erase_percent=0 -insert_percent=20 -num_shard_bits=10 -cache_size=2147483648 -use_clock_cache=false
Number of threads : 16
Ops per thread : 1200000
Cache size : 2147483648
Num shard bits : 10
Max key : 1073741824
Populate cache : 0
Insert percentage : 20%
Lookup percentage : 80%
Erase percentage : 0%
Test count : 1
----------------------------
1 Test: complete in 0.984 s; QPS = 19504108
所以LRU cache 之上的shard 封装,真的可以说是工业级高并发cache上 设计层面的一个 必备能力了。
2.4 Erase 操作
后面的 Erase操作这里便不再多说了,和lookup的操作时类似的。优先从hashtable中清理,如果key-handle的引用计数为0,则会从 high/low pool中的cache中移除,同样因为设计cache的更新,所以还是有锁的参与来原子更新cache的双向链表。
void LRUCacheShard::Erase(const Slice& key, uint32_t hash) {LRUHandle* e;bool last_reference = false;{MutexLock l(&mutex_);e = table_.Remove(key, hash);if (e != nullptr) {assert(e->InCache());e->SetInCache(false);if (!e->HasRefs()) {// The entry is in LRU since it's in hash and has no external referencesLRU_Remove(e);usage_ -= e->charge;last_reference = true;}}}// Free the entry here outside of mutex for performance reasons// last_reference will only be true if e != nullptrif (last_reference) {e->Free();}
}
2.5 内存维护
- 外部设置的Cache大小会被均分给设置的多个shard。
LRUCache::LRUCache(size_t capacity, int num_shard_bits,bool strict_capacity_limit, double high_pri_pool_ratio,std::shared_ptr<MemoryAllocator> allocator,bool use_adaptive_mutex) : ShardedCache(capacity, num_shard_bits, strict_capacity_limit,std::move(allocator)) {// 2^num_shard_bits 个 shardnum_shards_ = 1 << num_shard_bits;shards_ = reinterpret_cast<LRUCacheShard*>(port::cacheline_aligned_alloc(sizeof(LRUCacheShard) * num_shards_));// 均分的总cache大小size_t per_shard = (capacity + (num_shards_ - 1)) / num_shards_;for (int i = 0; i < num_shards_; i++) {new (&shards_[i])LRUCacheShard(per_shard, strict_capacity_limit, high_pri_pool_ratio,use_adaptive_mutex);} } - 每个Cache内部,Lru high/low pool的总内存大小 lru_usge_ 是包含在 hashtable 的内存占用总大小usage之内的。
hashtable的usage 是每一个handle 都要进行更新的,insert/erase 都需要操作hashtable。
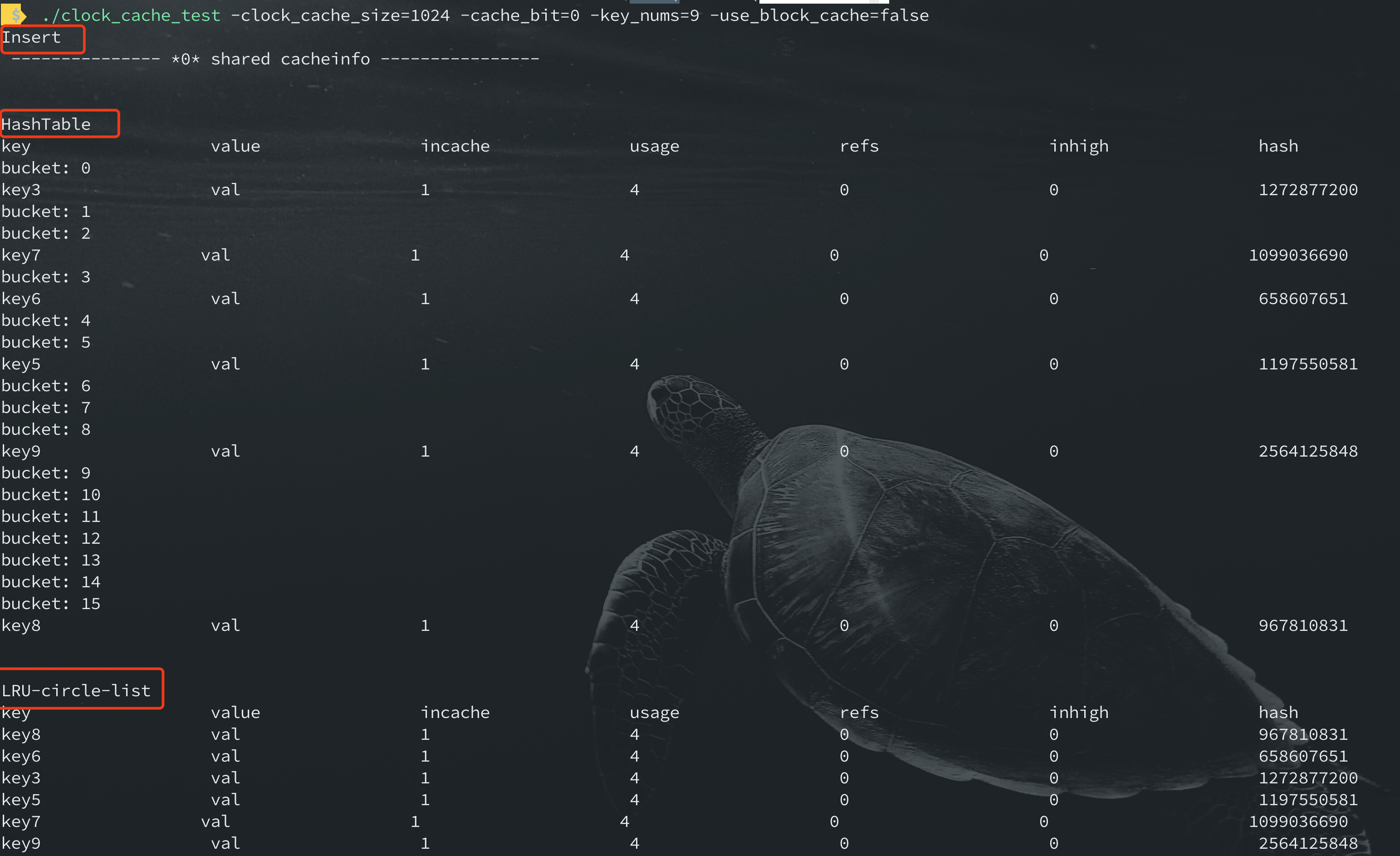
如果想要看到更细粒度的cache内部状态,则可以通过如下命令
编译运行的话进入到cd example; make test即可,会详细得打印每个shard cache内部hashtable , lru 双向链表的状态。
3. 优化
通过以上的一些实现架构和细节上的描述,我们能够总结出 rocksdb 的工业级lru cache 相比于传统lru-cache 的优化点:
- 多次提到过的 并且在性能测试中性能突出的 分shard能力。
- 为了保证Cache一致性的操作锁。
- 为了提升Cache 读性能的hashtable 以及 高低优先级pool,hash table用来加速key的查找,并且尽可能得保证热点key保存在了 内存中。
- 支持指定不同的分配器来作为LRUCache的默认分配器。(本篇没有对不同分配器的性能进行测试,直接使用的是操作系统默认的malloc/free)
- 内存控制管理能力,超过限制,则按照LRU策略从优先从low pool中淘汰数据(其本身也是整个LRU Cache中较旧的数据,其头部则是整个lru 双向链表最旧的数据)。
相关代码 和 benchmark 工具 :https://github.com/BaronStack/Cache_Bench
这个LRU Cache是作为Rocksdb的默认cache,同时Rocksdb还提供了另外一种可选的Cache : ClockCache。因为它选用了tbb:concurrent_hash_map 作为索引,底层选择deque 作为clock algorighm的实现。因为TBB 库本身的无锁操作,从而在Cache的并发操作上有了不小的提升。
限于篇幅原因,ClockCache的介绍会单独进行,包括基本的架构设计 以及 tbb 的 无锁化(并发erase) 实现细节。
相关文章:
Java项目:校园人力人事资源管理系统(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 校园人力资源管理系统:学校部门管理,教室管理,学历信息管理,职务,教师职称,奖励,学历,社会关系,工作…

GPS部标平台的架构设计(十)-基于Asp.NET MVC构建GPS部标平台
在当前很多的GPS平台当中,有很多是基于asp.NETsiverlight开发的遗留项目,代码混乱而又难以维护,各种耦合和关联,要命的是界面也没见到比Javascript做的控件有多好看,随着需求的增多,平台已经臃肿不堪。 设计…

关于CSDN不给任何通知强制关闭我的6年博客,我深表痛心
关于CSDN不给任何通知强制关闭我的6年博客,我深表痛心。最近有很长一段时间没有去csdn博客了, 前几天去看的时候发现博客被封闭了。 我联系了管理员,但是没有得到任何回复。 我猜想,可能是不是我在博客文章里面加入 自己网站的网…
Vue 环境搭建(win10)
1.安装node node官网安装地址 推荐安装稳定版本(LTS)以及安装路径为系统盘(C) 查看node安装成功否 注释:以下命令使用 命令提示符(管理员)权限,win10 对user权限的限制了访问权限。node -v 查看…

Java项目:化妆品商城系统(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统主要实现的功能有: 网上商城系统,前台后台管理,用户注册,登录,上架展示,分组展示,搜索,收…
python 绘图脚本系列简单记录
简单记录平时画图用到的python 便捷小脚本 1. 从单个文件输入 绘制坐标系图 #!/usr/bin/python # coding: utf-8 import matplotlib.pyplot as plt import numpy as np import matplotlib as mpl import sysfile_name1 sys.argv[1] data_title sys.argv[2] print(file_name1…
iOS-c语言小练习01
// // main.c // C-变量的地址 // // Created by cgq on 15/4/9. // Copyright (c) 2015年 cgq. All rights reserved. // #include <stdio.h> //访问变量的地址 void test1() { char a A; int b 44; printf("a的值:%d\n",a); pri…
蓝桥杯 【基础练习】 十六进制转八进制
问题描述给定n个十六进制正整数,输出它们对应的八进制数。输入格式输入的第一行为一个正整数n (1<n<10)。接下来n行,每行一个由0~9、大写字母A~F组成的字符串,表示要转换的十六进制正整数,每个十六进…

泛在网:泛在网
ylbtech-泛在网:泛在网泛在网络来源于拉丁语Ubiquitous,从字面上看就是广泛存在的,无所不在的网络。也就是人置身于无所不在的网络之中,实现人在任何时间、地点,使用任何网络与任何人与物的信息交换,基于个…

Mac 从Makefile 编译 Rocksdb 源码的一些注意事项
文章目录前言Makefile 编译流程1. 平台变量/环境变量的初始化。2. 编译需要的源码文件变量初始化。3. include 目录的设置。4. 编译的执行逻辑。问题记录1:可能的打包命令ar 失效问题5. 执行具体的编译指令问题记录2: jar 包编译前言 最近在Mac 本地编译Rocksdb 过…

Java项目:在线考试系统(单选,多选,判断,填空,简答题)(java+Springboot+ssm+mysql+html+maven)
源码获取:博客首页 "资源" 里下载! 功能: 学生信息 班级 专业 学号 姓名 在线考试 成绩查询 个人信息 密码修改 教师管理 教师编号 姓名 所教科目 题库管理 单选题 多选题 填空题 判断题,简答题(人工…
看了极光推送技术原理的几点思考
看了极光推送技术原理的几点思考 分类: android2012-11-26 20:50 16586人阅读 评论(18) 收藏 举报目录(?)[] 移动互联网应用现状 因为手机平台本身、电量、网络流量的限制,移动互联网应用在设计上跟传统 PC 上的应用很大不一样,需要根据手机…

查询远程或本地计算机的登录账户
用下面这个函数能获取远程或本地电脑的当前登录用户,同时附加了它的计算机名,所以当你查询多台电脑时将知道结果从哪里来。function Get-LoggedOnUser {param([String[]]$ComputerName $env:COMPUTERNAME)$ComputerName | ForEach-Object {(quser /SERV…
LIS ZOJ - 4028
http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode4028 memset超时 这题竟然是一个差分约束 好吧呢 对于每一个a[i], l < a[i] < r 那么设一个源点s 使 l < a[i] - s < r 是不是就能建边了 然后对于每一个f[i] 如果前面有一个相等的f[j] 则肯定 a[i…
存储引擎 K/V 分离下的index回写问题
前言 近期在做on nvme hash引擎相关的事情,对于非全序的数据集的存储需求,相比于我们传统的LSM或者B-tree的数据结构来说 能够减少很多维护全序上的计算/存储资源。当然我们要保证hash场景下的高写入能力,append-only 还是比较友好的选择。 …
经典贪心法:时间序列问题及其全局最优性证明
贪心算法是指在对问题求解时,总做出在当前看来是最好的选择。也就是说,不从整体上加以考虑,它所作出的仅仅是在某种意义上的局部最优解。一旦贪心算法求出了一个可行解,就要确定这个算法是否找到了最优解。为此,要么证…
Java项目:在线水果商城系统(java+JSP+Spring+SpringMVC +MyBatis+html+mysql)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 区分为管理员用户和普通用户,普通用户:用户注册登录,首页水果展示,商品分类展示,购物车添加,下单&…
曲苑杂坛--收缩数据库文件
很多人在删除大量数据后收缩数据库,却发现没法收缩到预期效果。 由于使用DBCC SHRINKFILE来收缩数据文件时,是针对数据区来收缩,因此可以先使用DBCC SHOWFILESTATS来查看文件中未使用的分区数(TotalExtents-UsedExtents),如果删除…
python字典去重
今天实习的web大表哥说帮我看环境不过前提是要我帮他写个python合并列表的demo,大概思路就是利用zip库进行keys和values的遍历,然后在输出就行key1{name1:小明,name2:小红} key2{小明:[men,20],小红:[women,30]} for k,v in zip(key1.values(),key1.keys()):for i, …
关于 线程模型中经常使用的 __sync_fetch_and_add 原子操作的性能
最近从 kvell 这篇论文中看到一些单机存储引擎的优秀设计,底层存储硬件性能在不远的未来可能不再是主要的性能瓶颈,反而高并发下的CPU可能是软件性能的主要限制。像BPS/AEP/Optane-SSD 等Intel 推出的硬件存储栈已经能够在延时上接近DRAM的量级ÿ…
R 语言爬虫 之 cnblog博文爬取
Cnbolg Crawl a). 加载用到的R包 ##library packages needed in this case library(proto) library(gsubfn) ## Warning in doTryCatch(return(expr), name, parentenv, handler): 无法载入共享目标对象‘/Library/Frameworks/R.framework/Resources/modules//R_X11.so’&#…
Java项目:宿舍管理系统(java+jsp+SSM+Spring+mysql)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:包括学生管理,班级管理,宿舍管理,人员信息维 护。维修登记,卫生管理,访客管理等等。 二、项目运行 环境配置&am…

项目管理5大过程组,42个过程一句话讲解
2019独角兽企业重金招聘Python工程师标准>>> 启动过程组:(1)制定项目章程:诞生项目,并为项目经理“正名”;(2)识别干系人:搞清楚谁与项目相关;规划…
Android Q 变更和新特性
安全和隐私变更 隐私保护是Android Q重要的主题之一,Android Q带来了一系列增强用户隐私保护的变更。 1 应用文件存储空间限制 应用访问限制是Android Q影响最大变更之一。在Android Q系统中,应用只可以通过路径读取自己应用沙箱内的文件,如果…

KVell 单机k/v引擎:用最少的CPU 来调度Nvme的极致性能
文章目录前言KVell背景业界引擎使用Nvme的问题CPU 会是 LSM-kv 存储的瓶颈CPU 也会是 Btree-kv 存储的瓶颈KVell 设计亮点 及 总体架构实现KVell 设计亮点1. Share nothing2. Do not sorted on disk, but keep indexes in memory3. Aim for fewer syscalls , not for sequentia…
android录像增加时间记录(源码里修改)
需要做一个功能,录像和播放时都显示录时的时间,参考文章链接找不到了,不好意思,这里记录一下,防止下次找不到了。另一篇关于源码录像的流程请参考 http://www.verydemo.com/demo_c131_i79000.html 在源码CameraSource.…
Java项目:在线旅游系统(java+jsp+SSM+Spring+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:用户的登录注册,旅游景点的展示,旅游预订,收藏,购买,以及酒店住宿留言等等,后台管理员,订单…
混合式APP开发中中间件方案Rexsee
发现Rexsee时,他已经一年多没有更新过了,最后版本是2012年的。 他的实现思路是通过Android自带的Java - Javascript 桥机制,在WebView中的JavaScript同Java进行通信,而这样的话即Javascript可以直接创建原生UI界面,以获…
vue 前端框架 (三)
VUE 生命周期 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><script type"text/javascript" src"js/vue.js"></script><link rel"stylesheet" type"te…
Rocksdb 的 MergeOperator 简单使用记录
本篇仅仅是一个记录 MergeOperator 的使用方式。 Rocksdb 使用MergeOperator 来代替Update 场景中的读改写操作,即用户的一个Update 操作需要调用rocksdb的 Get Put 接口才能完成。 而这种情况下会引入一些额外的读写放大,对于支持SQL这种update 频繁的…