MyRocks: 为facebool 的社交图谱服务的LSM-tree存储引擎
文章目录
- 概览
- 1. UDB 架构
- 2. UDB 表格式
- 3. Rocksdb:针对flash存储优化过的第三方库
- 3.1 Rocksdb架构
- 3.2 为什么选择Rocksdb
- 4. MyRocks / Rocksdb 开发历程
- 4.1 设计目标
- 4.2 性能挑战
- 4.2.1 降低CPU的消耗
- 4.2.2 降低range-scan 的延时消耗
- 4.2.3 磁盘空间和Compaction 的一些挑战
- 4.3 使用 MyRocks 的更多优势
- 4.3.1 在线备份和恢复功能
- 4.3.2 即使有很多二级索引 也能提供很好的扩展能力
- 4.3.3 在替换和插入操作中不需要额外的读取
- 4.3.4 拥有更多压缩的空间
- 5. 生产环境的数据迁移 工具
- 5.1 MyShadow - shadow 查询测试
- 5.2 数据正确性校验
- 5.3 实际的迁移过程
- 6. 性能
- 7. 总结
概览
论文地址:MyRocks: LSM-Tree Database Storage Engine Serving Facebook’s Social Graph
个人觉这篇论文优质的地方体现在:
- facebook 工程师们 解决业务复杂问题的思路。从前期的调研 + 测试 + 开发 + 周边服务建设 都是层层递进,基本痛点 + 解决痛点的技术方向 都在前期调研完成,有效得保证后续工作的价值。
- 对作为第三方库的单机引擎(Rocksdb) 整体功能理解得更加透彻(能够更加灵活得使用 Rocksdb 了),也会明白底层软件一定是放在一个个有价值的业务中才能展现其底层的价值,就像wiredtiger 接入 mongodb。
当然MyRocks 在facebook中解决的问题 就类似 X-DB在polardb 要解决的问题。
Facebook中 UDB(user database)数据库主要用来存储 最为重要的社交关系数据。由于历史包袱,当然也不算是包袱,最开始UDB是使用MySQL + innnodb 作为后端存储。随着数据量的不断增长,到现在(2020)为止有一些痛点需要克服,这一些痛点主要是由于innodb存储引擎引入的。
- B+ 树索引引入的空间碎片(内存+磁盘,主要是磁盘成本)
- 压缩效率低下
- 每个行事务 会额外消耗13B的存储空间。
后续会详细介绍innodb 中为什么会有这三个问题。
综上问题,Facebook开发者考虑引入LSM-tree 架构的存储引擎,能够拥有良好的空间利用率,并且在服务好read/write的同时保持低延时,这样就很完美。这个时候如果从头研发一个新架构的成熟存储引擎,需要花费太多的时间(以年为单位计算)。所以,Rocksdb这个第三方库进入了他们的视野,只需要在其上对接一个MySQL的可插拔存储引擎接口就能在不需要修改MySQL的客户端协议,SQL层 以及 复制相关代码的情况下完成我们的需求。
大体架构:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rcnzmnq1-1624793173446)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210618092702585.png)]](https://img-blog.csdnimg.cn/20210627192639213.png)
有了一个能快速解决问题的方向,接下来就是定目标了。官方大佬大手一挥,我们要利用myrocks 减少UDB中50%的servers成本。
ps: 这里减少50% 并不是空穴来风,理论上如果保持和innodb同能能力的吞吐和延时的情况下,降低50%的存储成本 以及 cpu/内存 消耗,就能够达到这个目标。
存储成本中 LSM-tree本身就能够降低这样的写放大。如果lsm-tree所有层都写满,leveled-merge 策略下,写放大1.11…,而b+tree 的(空间碎片)写放大则基本在1.5以上。相关数据可以参考Optimizing-Space-Amplification-in-RocksDB。
空间放大,理论上天然就能够满足存储成本的需求,而CPU和内存 的降低则对myrocks 是一个挑战。减少50%的服务器,意味着算力降了一半,这在rocksdb 的compaction/flush 的高CPU消耗中是一个痛点。
所以,开发者们列出了 MyRocks 支持 UDB核心特性 开发过程中面临的挑战:
- CPU/IO/内存 压力增加。相当于同样的资源需面临之前2x的请求压力。
- rocksdb的顺序scan性能 比 逆序scan性能好,但相比于innodb中的B±tree底层叶子结点的双向链表来说差很多。实际的UDB应用中有很大的需求需要反向scan,这需要对rocksdb的迭代器做一些优化。
- 在LSM-tree中会有更多的key之间的比较(点读/scan/compaction),都是对CPU的消耗。
- LSM-tree的读依赖bloom-filter来过滤不存在的key,这会增加内存负担。
- scan性能比innodb差很多。
- tombstone管理,innodb是in-place-update,所以不回有tombstone。而lsm-tree则会直接追加一条key,如果清理不及时,会造成空间放大以及影响scan性能。
- LSM-tree 的 compaction 会消耗I/O资源,从而造成write-stall 以及 上层read latency-spike。
这一些挑战会涉及到 rocksdb 的大量特性开发,但这一些开发相比一个全新的存储引擎来说也不算什么了。当然,这一些特性在后续的rocksdb中并不仅仅是为了 MyRocks 的定制,每一个特性都能够通用到其他的rocksdb用户中。
除了针对Rocksdb 的核心特性开发之外,还有数据迁移工具的开发(万级别的服务器数据的迁移需要非常谨慎):
- 生产数据的导入:
- MyShandow工具:同步截取用户请求,并插入到MyRock 所在的服务器中。
- Data correctness 工具:数据校验工具,会比对 innodb和myrocks 实例 中索引以及依据索引查找到的数据内容。
- 旧数据的替换:
- MyRocks提供 bulkload 来快速加载旧数据。
- 每一个Innodb的实例替换到MyRocks 实例之后即可删除Innodb实例,这其实对于 MySQL 这种存储引擎之间数据是独立的 的数据库来说很简答。
Facebook在2017年,基本完成了 UDB 的数据从 Innodb 到 MyRocks 的迁移。实际的收益则是降低了63%的存储成本,75%的磁盘I/O压力,二级索引维护的开销和读性能的加速让CPU的消耗略有降低(LSM-tree相比于 b±tree来说 很不容易了),从而整体达到了之前50%以上的server缩减。
Facebook 工程师通过这个实践案例得出了几个非常有价值的结论:
- 建立在LSM-tree上的数据库 在经过一些定制化的调优 还是非常有价值的。(这个在阿里的X-DB也有证明),当然这个还是看数据库的主体应用场景。
- 记录了想要替换一个成熟的B±tree存储引擎所遇到的性能挑战 以及 做出的对应的优化。
- 在不同数据库/存储引擎 之间的迁移工具还是很常见的,本paper的实践则比较好得展示了整个迁移过程的思路和方法。
接下来将详细介绍 MyRocks 是如何 解决列出来的这一些痛点 以及 相关迁移工具的详细设计细节,这个过程很有趣,更值得学习。
1. UDB 架构
从UDB的架构演进到对底层存储的各种需求,能够看到一个很明显的现象就是 存储成本的缩减是我们基础软件的核心,希望用最少的成本尽可能得满足用户需求。
UDB是facebook 内部大规模应用的全球分片数据库服务,其中应用了MySQL的上百种特性。早期的UDB服务是运行在HDD之上,因为HDD性能有限,所以集群的服务器负载需要被严格得监控,防止达到HDD的性能上限。随着SSD 高性能存储硬件的普及,在2010年开始,将SSD接入UDB中作为HDD底层存储的cahce,虽然单台服务器成本增加了,但是吞吐缺提升了一个量级,单台机器可以存储的数据量也上升了。
在2013年,UDB 将所有的HDD都替换为了SSD,这个时候问题就凸显出来了, 虽然吞吐不受限制了, 但是存储成本却快速上升,SSD本身没有HDD那样的大数据量的存储,却仍然要保证那么多数据的存储,这个时候解约存储成本就是一个首要问题了。针对innodb的压缩引入了很多其他的问题:
压缩数据。MySQL的innodb是支持数据压缩的,但是也只有50%的压缩率,这对UDB来说并不是一个满意的结果。
存储引擎带来的问题:
- 空间利用率太低。通过对innodb存储引擎的深入研究,发现了innodb的b-tree 索引碎片会造成磁盘25-30% 的空间被浪费掉(完全碎片的空间,无法继续存储)。他们也尝试通过碎片整理进行优化,但是收效甚微。原因是 UDB接受的数据存储基本都是不固定大小的随机写,这种workload下本身B-tree会产生很多索引碎片,而进行碎片整理的过程必然要对管理磁盘块的指针进行移动,这回额外得消耗系统CPU/SSD寿命,间接降低了系统的性能。
- 压缩率不高。Innodb默认的管理磁盘的数据块大小是16KB,为了保证压缩后的页面可以单独更新,这里将压缩后可以生成的块大小预定义为了1K, 2K, 4K, 或者 8K。如果设置的key_block_size 是8K, 16KB的数据经过压缩后为5KB,但也只能占用8K的存储空间,这样有也就只有50%的压缩率。而设置更小的key_block_size则会产生更多的B-tree的分裂,从而消耗更多的CPU。在Innodb中对于经常更新的表使用的是8kb的key_block_size,而不经常更新的则使用4kb,所以整体的压缩率其实并不高。
Innodb过高的写放大造成的写性能问题。
a. Innodb的B-tree 脏(更新)数据页最终会被回写到磁盘中,而在大量的随机写入场景下这样的回写会很频繁。再加上key_block_size的配置,对于一个数据表的单行 几个字节的修改也会造成8K的回写。
b. Innodb还有double-write 机制,防止异常宕机之后的数据丢失问题。
上面说的几个关于innodb的问题并不是很好优化且优化效果甚微,所以UDB开发者们急切得需要一个高空间利用率、低写放大的数据库实现。最终发现LSM- tree 架构能够很好得解决这两个问题。而且 LSM-tree 因为其分层架构,对于带有缓存的存储系统来说天然具有优势。
尽管LMS-tree 的这一些潜在优势很有吸引力,且能解决B-tree的痛点,但仍然会有以下两个难题:
- 当时并没有一个在生产环境 且 闪存设备 上 被验证过的LSM-tree 数据库。
- UDB 仍然需要提供大量的读吞吐。原因是UDB 表中都有主键,因此插入key的时候需要执行主键约束的检查并更新或者删除之前的行,这个时候需要读到之前的行数据,而在大量更新的场景下就会产生大量的读。但LSM-tree 在read-heavy场景以及flash-storage下不一定拥有良好的性能。
2. UDB 表格式
UDB 存储社交数据的表主要有两种格式(类似图的点和边):
- 对象
- 对象关联数据。
每个对象和关系都有定义其特征的类型(fbtype 和 assoc_type)。 fbtype 或 assoc_type 确定存储对象或关联的物理表。
- 公共对象表称为 fbobj_info,它用来存储公共对象。key可以用fbtype + fbid 表示,value则是对象本身以序列化格式存储在“数据”列中,其格式取决于每个 fbtype。
- 而关联表存储对象之间的关系。 例如,assoc_comments 表存储对 Facebook 活动(例如帖子)的评论关联数据,key 可以用:id+accoc_type表示。 关联表用二级索引 id1_type 优化range scan 性能。 因为获取与 id (id1) 关联的 ids (id2) 列表是 Facebook 上的常见逻辑,例如获取喜欢某个帖子的人的标识符列表。
从shcema 的角度来看,对于对象表的访问方式类似于k/v存储,而非关系型存储。且在社交图谱中的操作中,一个事务往往会修改相同id1的对象表和关联表。所以,实际的存储中这两张表也会存放在同一个数据库实例。
3. Rocksdb:针对flash存储优化过的第三方库
Rocksdb 是在2012年基于LevelDB 做出来的单机存储引擎,主要在flash-ssd这样的存储设备上做了很多优化。它当时也是为了解决其他数据库在使用闪存设备过程中的存储性能问题而推出的,且在UDB调研的时候已经应用在了facebook 内部ZippyDB,Laser, Dragon等数据库之中。Rocksdb 在开始研发的时候对业界的主流数据结构做了大量的调研,最后选择了 LSM-tree , 只有这个数据结构在拥有足够低的写放大的同时读性能也能得到很好的平衡。
3.1 Rocksdb架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CUxf8yp3-1624793173449)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210626143828737.png)]](https://img-blog.csdnimg.cn/20210627192716478.png)
写路径
a. 先写WAL
b. 追加写内存的一个buffer组件 Memtable,返回用户完成写请求。
c. Memtable达到阈值,Flush到SST(sorted string tables)。每一个SST都会按照顺序来存储数据,这一些数据会被分割为多个data blocks。每个sst还有一个index block, 其中保存了每一个datablock的第一个key,用作二分查找对应的data-block。多个ssts会被组织成一个个Level,每个level中都有一批 sst(类似上图)。d. 为了让每一个level的大小不回超过限制,同时清理过期的key,会从Ln中选择出一些ssts 与 Ln+1 中有重叠的sst进行合并,将新的sst 写入到Ln+1中。
读路径
a. 先读所有的memtableb. 读每一个sst内部的bloomfilter, 用来过滤当前sst不存在的key的查找。
c. 所有的L0 的ssts,每个sst都会读一次(二分查找)
d. 所有Ln的ssts,整层进行二分查找
3.2 为什么选择Rocksdb
正如前面说到的,UDB使用MySQL存储引擎过程中遇到的两个主要痛点:磁盘空间利用率,写放大。而这两个问题在 LSM-tree 的架构中都能得到很好的解决。
- 对于写放大来说:LSM-tree 是Append-only 架构,这不同于 B-tree 的inplace-update,能够天然解决空间利用率问题。再说一下写放大,Innodb 中更新一行的几个字节都要写入8K, 对于 LSM-tree 来说,每次写入磁盘都会batch累计一批数据,除了每个sst的最后一次写入之外不会存在很小的流量写入。
- 再来看空间利用率问题:
- 前面说过B-tree 因为索引碎片问题,会导致20-30% 的空间被浪费,完全无法使用。Rocksdb out-of-place update 并不会有这样的问题,唯一要担心的是tombstone的删除并不及时(Compaciton删除)。但在经过调优之后,这个tombstone对空间消耗的影响能够降到10%以内。
- 再来看压缩,Innodb 16KB压缩为5KB,但是还得写入8KB,也就是压缩率为50%。而对于 rocksdb 来说压缩5KB 就写入5KB。
- 最后再来对比一下单行事务的大小。对于 Innodb 来说,一个单行的事务操作需要额外增加 6B 的trasaction-id + 7B 的 回滚指针。而对于 Rocksdb 来说,单行事务中 每一个 key 仅仅会保存一个7B 的seq-number,而且这个seq-number 在key 处于最后一层的时候会被置为0,0对于压缩来说非常友好。
综上来看,Rocksdb 能够很好得解决 Innodb 的空间利用率 和 写放大问题。那Facebook 的工程师终于决定 基于 rocksdb 来开发一个 MyRocks 存储引擎 作为MySQL 的插件引擎。在MySQL5.6 版本中,已经实现了MyRocks,而且通过 TPC-C 的benchmark 进行压测,性能表现良好。
4. MyRocks / Rocksdb 开发历程
这一节我们能够学习到开发一个复杂大型项目的一些方法论。重构 和 迁移一个大型数据库的数据是一个大工程,所以开始工作之前他们先制定了一些目标,虽然高效得实现这一些功能,但相应实现的可靠性、隐私、安全性 和 简单性 也都非常重要。
4.1 设计目标
保留一些应用已经存在的特性和操作。
比如实现MyRocks 的过程中,让MySQL 不用变更Client接口和SQL 层的协议对接就能直接使用 MyRocks 是最好不过。这样一些MySQL 的工具:instance-monitering, backup, failover 都能够直接使用了。缩短项目完成周期。
这个项目并不是说需要花费几年的时间来完成一个非常棒的数据库,并再花费几年时间完成迁移工具的开发。因为UDB 的数据量还在不断增长,想要让UDB 的痛点得到解决,这种工程量并不是可取的。他们是通过如下两种方式缩短MyRocks 的上线周期的:a. UDB 的表格式是固定的,所以在调研/分析 MyRocks 的设计的同时会优先将 MyRocks 的表格式/索引格式 设计出来,因为这一些格式是底层实现,一旦固定下来,后续基本不太可能变化。
b. 在开发MyRocks 的过程中,还在用开源的LinkBench 收集 UDB on Innodb 上的用户 workload ,这一些 workload 后续会被用来对每一个 MyRocks 完成 的特性进行针对性压测,从而降低后续的测试成本。
设定清晰的性能 目标。
MyRocks 需要提升性能的同时不希望牺牲一致性。所以在替换 innodb 这件事情上有两个目标。
a. 降低数据库的空间利用率 50% 以上
b. 降低空间利用率的同时并不会增加CPU/ IO 的消耗。在这两个清晰的目标驱动下,我们能够知道接下来所面临的困难。想要节省50% 的磁盘空间,意味着单个MySQL 实例将要面对之前两倍的数据压力。虽然MyRocks 能够使用更少的CPU 和 IO 来处理写入,但也会因此引入更多的读。
设计选择。
a. 为了Rocksdb 满足 MyRocks 的特性,会增加一些额外的特性到开源社区中,而这一些特性也能够应用在其他类似的数据库中。b. 集群索引结构的设计。UDB 本身使用了 Innodb 的聚集索引结构,由于所有的列都存在,可以通过一次read 就能读到主键。MyRocks 的设计中也采用这样的聚集索引结构。二级索引会包含一个主键列用来索引主键key,但并不会包含row id。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ro3HypxQ-1624793173451)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210626154649254.png)]](https://img-blog.csdnimg.cn/20210627192746721.png)
4.2 性能挑战
MyRocks 的开发过程中对 读性能做了几点的优化从而能够和 Innodb 的性能接近,同时针对 大量 tombstone 能够降低scan性能 和 消耗很多空间的问题 做了一些优化, 接下来将会详细讨论这一些优化点。
4.2.1 降低CPU的消耗
Mem-comparable keys
在LSM-tree 中的读取 会有比 Innodb 读取中更多的 key 比较操作。在Range-scan下,Innodb 中我们还需要一次二分查找就能找到起始key,而在LSM-tree 中需要为每一个有序部分进行二分查找(所有mmetable/ imm, L0的所有sst,L1-Ln的每一层),并且使用一个最小堆来进行排序。这个起始key的查找 在 LSM-tree 中就会多几次 key的比较。而在接下来的读取过程中,Innodb 只需要顺序读下去,LSM-tree 却需要在最小堆至少一次和旧版本key的比较,保证返回的是最新的key。针对这种比较场景,MyRocks 实现了 bytewise-comparable Comparator 来让MyRocks 中的key比较的时候使用字节序的方式(CPU 位运算效率还是很高的,计算单元中的大量的门电路都是比较机器码的)。
Reverse key Comparator
方向扫描 则是在数据库使用单机存储引擎中出现的需求,单机引擎没办法在分布式场景支持MVCC,所以一般上层分布式数据库会为每一个写入到引擎的key都会增加一个时间戳,来支持多版本。很多时候需要按照key的更新时间降序扫描key,这个时候一般情况就需要通过第二种方式来进行扫描。这个问题在 MyRocks 接入 UDB 的实现过程中就是一个痛点,UDB 会有固定的场景需要按照更新时间降序获取好友关系。关于key的反向比较器的实现 也就是针对Rocksdb 迭代器中Prev 性能问题的规避方式。通过实现一个反向比较器,可以让key的存储按照原本相反的排序方式存储在SST中,这样原本应该Prev扫描的结果就可以直接转化为Next 的高效扫描了。
更多的 Rocksdb 这里的细节和测试可以参考:
Rocksdb iterator 的 Forward-scan 和 Reverse-scan 的性能差异Faster Approximate Size to Scan Calculation
更高效得预估 key-range 之间的 数据库的大小。这个需求来自于 MySQL 优化器根据用户SQL 生成执行计划的时候需要预先知道 这个操作会消耗多长时间。比如 MySQL 拿到一个查询请求,它会拿到一个这个范围的最小key和最大key传给 存储引擎,MyRocks 此时要预估扫描的成本 并返回给MySQL。
这里 Rocksdb 的实现是通过确认最小key 和 最大key 所处block 之间的距离(包括memtable/imm的大小)。这个过程需要扫描计算每一个Rocksdb 组件的累积大小,会有较高的CPU开销。这里主要通过两方面进行优化:
a. 强制要求给出特定的索引。这就能完全跳过计算 最大key和最小key 之间的距离了。因为社交关系图谱查询是高度统一的(查找好友关系),因此多个SQL查询中增加这个提示能够减少大部分的类似计算的开销。b. Rocksdb 的实现 计算 两个key-range 之间数据大小的算法优化。通过首先预估两个key 之间完整的 SST 的大小,如果确定它们并不会显著改变结果的预期,则跳过剩余部分 SSTs 的扫描。比如 发现一个SST 的key-range 全部在整个key之间,则直接加上这个SST 的大小,如果在SST key-range 的end key 在start key之前,则跳过这个key,只有有 sst 的key-range 落在两个key之间才会进一步计算SST内部的重叠部分。
实现代码如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ewiw9cQV-1624793173452)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210626163333530.png)]](https://img-blog.csdnimg.cn/20210627192805466.png)
4.2.2 降低range-scan 的延时消耗
Prefix-Bloom filter
在UDB数据库中,会有大量的 range-scan 产生,这对 LSM-tree 来说是一个不小的挑战。
在传统的B-tree 中,Range query 会从一个叶子节点开始,通过双向链表 向前或者向后读几个leaf page就可以了。对于LSM-tree 来说则有两部分:Seek 和 Next 操作。其中Seek操作耗时较多,很多时候需要从SST 中读取一个data block, 而且 即使这个 key 不在这个data block 也会被读出来。这个过程会消耗更多的I/O 和 解压缩的CPU。为了降低这种情况下的Scan耗时,Rocksdb 实现了 prefix bloomfilter 能够跳过任何不包括start key的datablock的读取,当然只需要消耗部分存储空间。
Reducing Tombstone on Deletes and Updates
在Rocksdb 中 Compaction 是一个影响读写性能的主要因素。其中最大的痛点是如何处理大量删除产生的 tombstone,这一些 tombstone 的增加 会严重影响scan性能。而在UDB 的更新场景中,意味着针对一个 old key 的删除 和 new key的写入(同一个user-key 的 不同value)。如果UDB中针对 MyRocks 的index key有非常频繁的update,那接下来 针对包含这个index-key 的range-scan 会扫描它所有的 tombstone(UDB 会有非常频繁的针对二级索引的range-scan ),而这一些tombstone只有被compaction到最后一层才会清理。
因为以上tombstone 造成的问题,Rocksdb 开发出了 SingleDelete 特性。与传统的Delete 类型相比,SingleDelete 在删除 Old-key类型为Put 的操作时能够直接清理掉,无需等待compaciton到Lmax。
这个特性仅适用与一个 user-key的一次Put,如果针对一个user-key有多次Put,比如Put(key=1, value=1), Put(key=1, value=2) 接下来调用SingDelete(key=1),这种情况下(key=1,value=1)还会能够被读到,这是一个数据不一致的情况。在MyRocks 中,这种情况不会出现,因为 MyRocks 能够保证针对二级索引的更新仅仅会 有一次Put,不允许针对同一个二级索引 更新多次。
针对SingleDelete 的这个问题的测试可以使用如下测试代码:
rocksdb::WriteOptions wopts; string value; wopts.sync = true;// 第一个SST 文件,包含一个Put db->Put(wopts, "key1", "value1" ); db->Flush(rocksdb::FlushOptions());// 第二个SST 文件,包含一个Put + SingleDelete db->Put(wopts, "key1", "value2" ); db->SingleDelete(wopts, "key1"); db->Flush(rocksdb::FlushOptions());// 保证前两个文件能够被 compaction 到 db->CompactRange(rocksdb::CompactRangeOptions(), nullptr, nullptr);// 还是能够读到 db->Get(rocksdb::ReadOptions(), "key1", &value); cout << "key1's value after singledelete :" << value << endl;Trigger Compaction based on Tombstone
当UDB 删除大量的行时,一些sst 可能会被大量的tombstone填充,这一些tomestone 会严重影响scan性能
Rocksdb 通过 TableCollection 实现了一个Deletion Triggered Compaction (DTC),当发现sst 中 tombstone 过多且超过一定的阈值,则直接针对当前sst 触发新的compaction。
关于DTC 的实现细节和性能测试可以参考Rocksdb和Lethe 对Delete问题的优化
下图是LinkBench 在大量tombstone 下 用未优化过的Rocksdb 和 DTC / SingleDelete 的对比测试,可以发现DTC+SingleDelete 能够有效解决tombstone 过多对用户性能的影响。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9IlesKiw-1624793173454)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210626173520034.png)]](https://img-blog.csdnimg.cn/20210627192836334.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1pfU3RhbmQ=,size_16,color_FFFFFF,t_70)
4.2.3 磁盘空间和Compaction 的一些挑战
降低内存使用。
为了提升读性能,会为每一个SST生成一个bloom filter,这一些bloom filter在正常读时候都会被加载到内存中。为了降低他们对内存的消耗,Rocksdb 扩展了Bloomfilter ,允许Bloom filter在LSM-tree 的最后一层不创建bloom filter。如果我们将层的增大比例调整为10, 那90%的数据都会被存放在最后一层,这样能够减少90%的bloom filter的创建,从而减少90%的内存消耗。对于之前层的Bloom filter来说,则仍然有效。当然,这会让最后一层 不存在的key的过滤失效,而这里则选择了牺牲CPU 来保证内存的权衡。
减少因为Compaction造成的SSD降速
MyRocks 依赖SSD 内部的 Trim Command 来降低SSD内部的写放大,从而达到提升SSD吞吐性能的目的。但是我们会发现SSD的性能 在 Trim命令的时候 会有一段下跌。而这个情况 在 Rocksdb的Compaction 过程中更为频繁,compaction 完成之后会将旧文件批量删除,这个时候会有大量的Trime 命令,从而造成SSD 的性能下降。
为了减缓这个问题,Rocksdb 实现了RateLimiter 来降低Compaction/Flush 针对SSD的写入速度,保证了底层IO的稳定。同时在非全双工的SSD主控下,能够有效降低写入的增加对上层业务读的Latency 的影响。
物理移除过期数据
这个功能很有意思。在UDB的社交图谱数据中,之前提到对象的标识fbid 是单调递增的,而对象表内的对象的修改会随着时间的推移逐渐减少。尤其是当一个对象被删除了,那基本不会有针对这个对象的更新操作了。后续的 插入/更新/删除 操作基本都只针对这个新的对象了,这个时候之前旧的对象操作数据可能会大概率集中在一个sst文件中,而这个sst文件因为不会和其他的sst文件有重叠,基本不会被compaction调度到,落到最后一层,从而无法被删除掉。
为了解决上面的问题, Rocksdb开发了period compaction功能,就是设置一个period时间,会在这个时间内检查每个SSD文件的年龄,如果年龄超过了period设置的时间,那会直接让这个SST 参与Compaction,直到最后一层,从被有效清理掉。
参数设置可以通过:
options.periodic_compaction_seconds进行设置(仅在Level Compaction策略中生效)。Bullk loading
造成Rocksdb LSM- tree write-stall 最主要的原因是短时间大量的写入。像在线的schema 变更,在线数据导入 都会产生大量的写入。而Innodb 到 MyRocks 迁移工具则是在线数据导入场景,会产生大量的写入,如果还是按照MyRocks 的数据写入接口的话会有大量的额外写入(memetable->flush->多层Compaciton),如何保证这个操作不会影响正常的写入请求(不产生write-stall),Rocksdb 设计了Bulk loading。这个特性在Rocksdb 外部通过sst_file_writer API 接口遇险创建好SST,新的SST通过Ingest接口直接 插入到 LSM-tree 的Lmax中,并同步更新Rocksdb 的Manifest。这个过程会bypass memtable, L0->Lmax-1 的compaction。
如下是 Innodb / MyRocks 读写接口/ MyRocks Bulkload 下的性能对比:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-65CWdYxp-1624793173455)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210626182452619.png)]](https://img-blog.csdnimg.cn/2021062719285813.png)
关于更多Bulkload 的实现细节,可以参考Rocksdb 通过ingestfile 来支持高效的离线数据导入
4.3 使用 MyRocks 的更多优势
4.3.1 在线备份和恢复功能
MyRocks 实现了逻辑备份功能 和 ReadOnly Snapshot Read来解决一致性读问题。在Innodb 中一致性读是通过Undo log实现的,UNDO LOG 是通过链表实现的,在创建事务快照之后需要保留针对这个事务的所有更改,方便后续的事务回滚,而在同一行频繁更新多次,这会造成read snapshot 显著变慢,遍历UNDO LOG 进行重放。而对于MyRocks来说,会为每一行维护一个版本。
恢复数据的时候MyRocks 提供了Bulkload特性,性能显著高于Rocksdb。
数据备份功能的实现是 物理复制一个副本的实例。这个过程是在Rocksdb 打一个checkpoint ,并且会将所有的SSTs和WAL files 发送到一个备份的地方。
4.3.2 即使有很多二级索引 也能提供很好的扩展能力
MyRocks 中在操作二级索引的时候不会产生随机读IO。这个相比于Innodb的in-place update来说确实是很有优势。在MyRocks中 insert操作就是Rocksdb的Put,update操作对应Rocksdb的 SingleDelete + Put,delete 二级索引对应 Rocksdb 的 SingleDelete。可以看到这个过程不会产生额外的读请求,而在Innodb中则需要额外的Get/GetForUpdate 操作。在上面的Bullkload 优势的测试中 也能够看到MyRocksd 在这个场景下本身性能也比 Innodb有优势。
4.3.3 在替换和插入操作中不需要额外的读取
大体和前面的提到的优势类似。在MySQL 的 REPLACE 语法中需要插入或者覆盖一个新行,Innodb 需要读一下新插入行的 主键,确认这个主键所在的行是否存在,如果存在,那先删除旧行,再插入新行;如果不存在,则直接插入新行。这个操作对于 MyRocks 来说只需要一次 rocksdb 的Put 就可以。
4.3.4 拥有更多压缩的空间
MyRocks 的 Rocksdb 本身数据是分层存储,如果每一层都被填充满,那90% 的数据会落在最后一层。这样可以在不同的层使用不同的压缩算法, 大多数情况我们读请求是落在靠近上层的数据中,这样可以针对L0 + L1 使用更高效的压缩/解压缩算法 LZ4,在最后一层的压缩算法可以算则 Zstandard 算法。
5. 生产环境的数据迁移 工具
以上功能facebook 工程师在一年半左右的时间完成了开发和功能正确的测试。接下来就开始从Innodb的实例进行数据迁移到 MyRocks 实例。毕竟 MyRocks 还没有在生产环境跑过,这个时候为了防止软件内部的一些cornor case 的异常问题,迁移之前将 MyRocks 的实例 的复制机制禁止掉了,也就是仅仅从 Innodb 实例中拉取数据到 MyRocks实例 ,且读流量不会切到 MyRocks 实例上,这样能够保证即使 拉取数据 到 MyRocks 之上出现core 或者 数据一致性问题时 不会影响生产环境的正常服务。这个时候,针对 MyRocks 的各种异常测试 以及 自动化工具都能安全放心的跑起来了。
先从导出 Innodb 的表,通过 MyRocks 的bulkload 功能导入到 MyRocks实例。因为 Innodb 具有聚集索引,从它的实例中导出的数据已经是 按照主键排过序的,这个时候就可以直接 bulkload 到 MyRocks中。对于每一个副本集,可以按照每小时 200-300G的速度 迁移到 MyRocks 实例中。接下来详细看看具体的数据迁移工具实现 和 数据一致性校验工具的实现。
5.1 MyShadow - shadow 查询测试
这个工具出现的目的是 为了让 上限之前的 MyRocks 实例能够在生产环境的 workload下得到足够多的稳定性和性能测试,包括确认 CPU 和 IO 使用率是否在和Innodb的对比预期之内 以及 一些预期之外的奔溃异常回归测试是否能够保证数据的可靠性。
MyShadow 实现架构如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VGwow5qU-1624793173456)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210627175328681.png)]](https://img-blog.csdnimg.cn/20210627192925262.png)
在facebook的生产环境中,维护了一个 MySQL Audit 插件,能够捕获生产环境的workload并记录在 内部的日志服务中。MyShadow 支持从日志服务中将这一些捕获的生产环境的请求 重放到目标 MyRocks 实例,从而能够在 MyRocks 上线之前就得到生产环境 workload 的测试情况。
这里 MyShadow 的实现应该是使用 Rocksdb 的 trace_replay 功能
5.2 数据正确性校验
使用一个新的数据库在线替换原有的数据库,在数据正确性方面是一个非常大的挑战。以Innodb 的数据作为参考(原本生产环境的数据,正确性没有问题),通过工具将其中的数据 和 写入到 MyRocks 中的数据进行对比来确认 MyRocks 中数据的正确性。
这个正确性校验工具主要有三种模式:Single, Pair 和 Select。
- Single 模式 主要用来检查 处于同一张表的 Primary keys 和 Secondary keys 的一致性,具体是验证是通过检查 所处表内的行数 和 重叠列的校验和是否相同来确认的。这个过程 能够发现一些 MyRocks 或 Rocksdb 内部的一些bug。比如 Rocksdb compaction的bug,没有正确处理Delete 类似的key,导致索引不一致。
- Pari 模式 对整个表进行扫描,通过read snapshot 获取表内某一个状态 下的 Innodb 实例和 MyRocks 实例之间的 row counts和 校验和。这个模式能够发现在Single mode下未发现的问题
- Select 模式。这个模式有点类似 pair 模式,但并不是扫描整张表。而是 对MyShadow 捕获的 workload 执行 select 语句,并比较语句的结果在 Innodb 实例 和 MyRocks 实例之间的差异,如果不同则表示数据不一致。
关于数据校验过程的步骤可以参考如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dIKqwUOc-1624793173457)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210627181728786.png)]](https://img-blog.csdnimg.cn/20210627192944903.png)
其中:Primary instance1 是 innodb实例,Replice instance2,3 是 MyRocks实例
5.3 实际的迁移过程
在通过了 MyShadow 的测试 和 数据正确性的测试之后,接下来就要将MyRocks 实例正式移植到生产环境了。
迁移过程分为三个阶段(如下图),持续了整整一年。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9iPQ2vIa-1624793173457)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210627182739964.png)]](https://img-blog.csdnimg.cn/20210627193002646.png)
- 第一步(上图中的第二步) 当时 每一个 MySQL 副本集中有 6个 MySQL 实例(1primary, 5replicas)。这个时候将两个 副本 中的实例切换为 MyRocks。 MyRocks 实例会从 Innodb的 Primary 实例复制数据。读请求主要是落在副本实例上,所以这个配置下跑几个月能够再次确认 MyRocks 时能够扛住读流量。
- 第二步(上图中的第三步),这一步开始之前经过了很长时间的测试。因为这一步需要将 Primary instance 切换为 MyRocks, 这让facebook 的工程师们有点慌。因为切换之后所有的写入 都会经过 Primary,事关数据一致性的核心。在觉得解决了 “所有” 的问题之后,这一步开始了。将 Primary 实例 切换为了 MyRocks,保留三个innodb 的副本实例。切换之后他们 监控了整个应用 所有的异常行为,发现,,,都正常(严谨中的严谨)。这之后又跑了大概几个月的时间,没有什么问题之后终于能够确认 所有的实例都能够切换到 MyRocks 了。
- 第三步 替换所有的实例为 MyRocks。整个UDB中有成千上万个 MySQL 副本集,后续的迁移就是时间上的花费了。但还有一些副本集中 保存有 Innodb 实例,来持续进行 Innodb 和 MyRocks 的对比测试。
6. 性能
直接贴一张表来看看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AWmDd0Xb-1624793173458)(/Users/zhanghuigui/Library/Application Support/typora-user-images/image-20210627184418213.png)]](https://img-blog.csdnimg.cn/20210627193025980.png)
最初的目标是解约 50% 的服务器,这里可以看到切换到MyRocks 之后 空间成本下降了 63%,而且 能够提供更有优势的CPU利用率 和 更低的写放大(写放大降低了4倍),在以百PB为量级的数据库中,这样的优化效果可以说是非常成功了。
从 Innodb 到 MyRocks 的成功实践 也吸引了 facebook 内部 HBSE-Messenger 到 MySQL + MyRocks的迁移,HBase (LSM-tree )在facebook 的痛点是大量的GC 导致 CPU被耗尽,迁移到MySQL + MyRocks 之上极大得缓解了这个问题。更多的相关细节可以参考Migration Messenger storage to Optimize Performance。
7. 总结
作者们 对 MyRocks 的 高效 成功实践做了一些总结,总结的比较散,当然越靠近前面的肯定越重要了:
强无敌的PE(production engineer),是MySQL和Rocksdb 的内核开发者,对现有项目有非常深入的底层理解,同时也对 Innodb 和 Rocksdb 的特性有足够的了解,能够在较短得时间内分析清楚问题 并 在实践中能快速排查解决迁移到生产环境遇到的问题。这才保证项目的高效性和成功性。
对 底层硬件存储 和 操作系统的运行机制有足够的了解也很重要
完整高效的自动化迁移工具 能够让最终的效率事半功倍。
完善的监控体系 能够让问题排查高效且有迹可循。
工具的兼容性,像MyShandow 和 data correctness tool 就兼容 Innodb 和 MyRocks,这样方便两者的性能对比。
用好Rocksdb 不容易,这玩意参数太多了。。。。。。一些结合workload 的最优参数的摸索估计还需要不少时间(也被吐槽了,,,不可否认的是引擎的灵活性非常重要,能够适用更多的可优化的场景)。
相关文章:
Java项目:精品酒店管理系统(java+SSM+mysql+maven+tomcat)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:主要功能主要功能会员管理,住客管理,房间管 理,系统管理,以及一些重要数据的展示导出维护等等; 二、项目运行 环境配置&…
iOS自动布局一
Align: Pin: 转载于:https://www.cnblogs.com/123qw/p/4404167.html

C#实现路由器断开连接,更改公网ip
publicstaticvoidDisconnect(){stringurl "断 线"; stringuri "http://192.168.1.1/userRpm/StatusRpm.htm?Disconnect"System.Web.HttpUtility.UrlEncode(url, System.Text.Encoding.GetEncoding("gb2312")) "&wan1"; str…
Go中的iota
当时在学习Iota这个知识点的时候仅仅是一笔掠过,比如这种 const(aiotab c) 一眼看出他怎么使用的时候就觉得自己已经懂得了 再到后来看到这样的例子 const(a 5*iotab c )以及 const(a 1<<(10*iota)bc ) 第一…
从 SSLTLS 的底层实现来看 网络安全的庞大复杂体系
文章目录前言1. HTTP协议通信的问题1.1 tcpdump 抓取http 请求包1.2 报文分析1.3 HTTP 协议问题2. SSL & TLS 协议的基本介绍和历史演进3. TLS 1.2 实现加密传输的过程3.1 TLS HandShake 协议概览3.2 第一次握手:ClientHello3.3 第二次握手:从Server…

UICollectionView
UICollectionView 多列的UITableView,最简单的形式,类似于iBooks中书架的布局,书架中放着你下载的和购买的电子书。 最简单的UICollectionView是一个GridView,可以多列的方式进行展示。 包含三部分,都是UIView的子类: …

Java项目:课程资源管理+在线考试平台(java+SSH+mysql+maven+tomcat)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 管理员可以增删改查教材、教材商、入库教材、用户(用 户包括学生和教师)可以对教材商、教材进行。xcel的导入 导出操作。教师可以领取入库的教材,可以退还教…

python twisted 笔记
2019独角兽企业重金招聘Python工程师标准>>> 1.Twisted框架构建简单的C/S 要写一个基于twisted框架的服务器,你要实现事件处理器,它处理诸如一个新的客户端连接、新的数据到达和客户端连接中断等情况。 在Twisted中,你的事件处理器定义在一个…

决策树J48算法
1. J48原理 2. 举例 3. 总结 1. J48原理 基于从上到下的策略,递归的分治策略,选择某个属性放置在根节点,为每个可能的属性值产生一个分支,将实例分成多个子集,每个子集对应一个根节点的分支,然后在每个分支…
分布式系统 一致性模型的介绍 以及 zookeeper的 “线性一致性“ 讨论
文章目录1. 一致性 概览1.1 分布式系统的 “正确性”1.2 线性一致性(Linearizability)1.3 顺序一致性(Sequential consistency)1.4 因果一致性(Casual consistency)1.5 最终一致性(Eventual consistency)2. Zookeeper 的 “线性一致性” 问题3. 参考一致性算是分布式系统的定位…
Java项目:(小程序)全套商城系统(spring+spring mvc+mybatis+layui+微信小程)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 商品模块: 商品添加、规格设置,商品上下架等 订单模块: 下单、购物车、支付,发货、收货、评 退款等 营销模块: 积分、优惠券、分销、砍价、拼团、秒 多…
【转】[退役]纪念我的ACM——headacher@XDU
转自:http://hi.baidu.com/headacher/item/5a2ce1d50609091b20e25022 退役了,是时候总结一下我ACM的生涯了。虽然很舍不得,但这段回忆很值得纪念。ACM生涯虽然结束,但是新生活总要继续,还有很多东西需要我去学习&#…
VMware扩大硬盘后修改Linux逻辑卷大小
一、背景随着业务的不断成熟,数据库积累的数据也越来越多了。前些天发现服务器的磁盘将要满了。因此向虚拟化管理员申请增加磁盘空间。由于这个系统是建立在威睿的vSphere平台上的,因此虚拟化管理员只简单地通过 VMware vSphere Client 扩大了磁盘空间&a…
axios与ajax区别
1.jQuery ajax $.ajax({ type: POST, url: url, data: data, dataType: dataType, success: function () {}, error: function () {}});优缺点: 本身是针对MVC的编程,不符合现在前端MVVM的浪潮基于原生的XHR开发,XHR本身的架构不清晰,已经有…
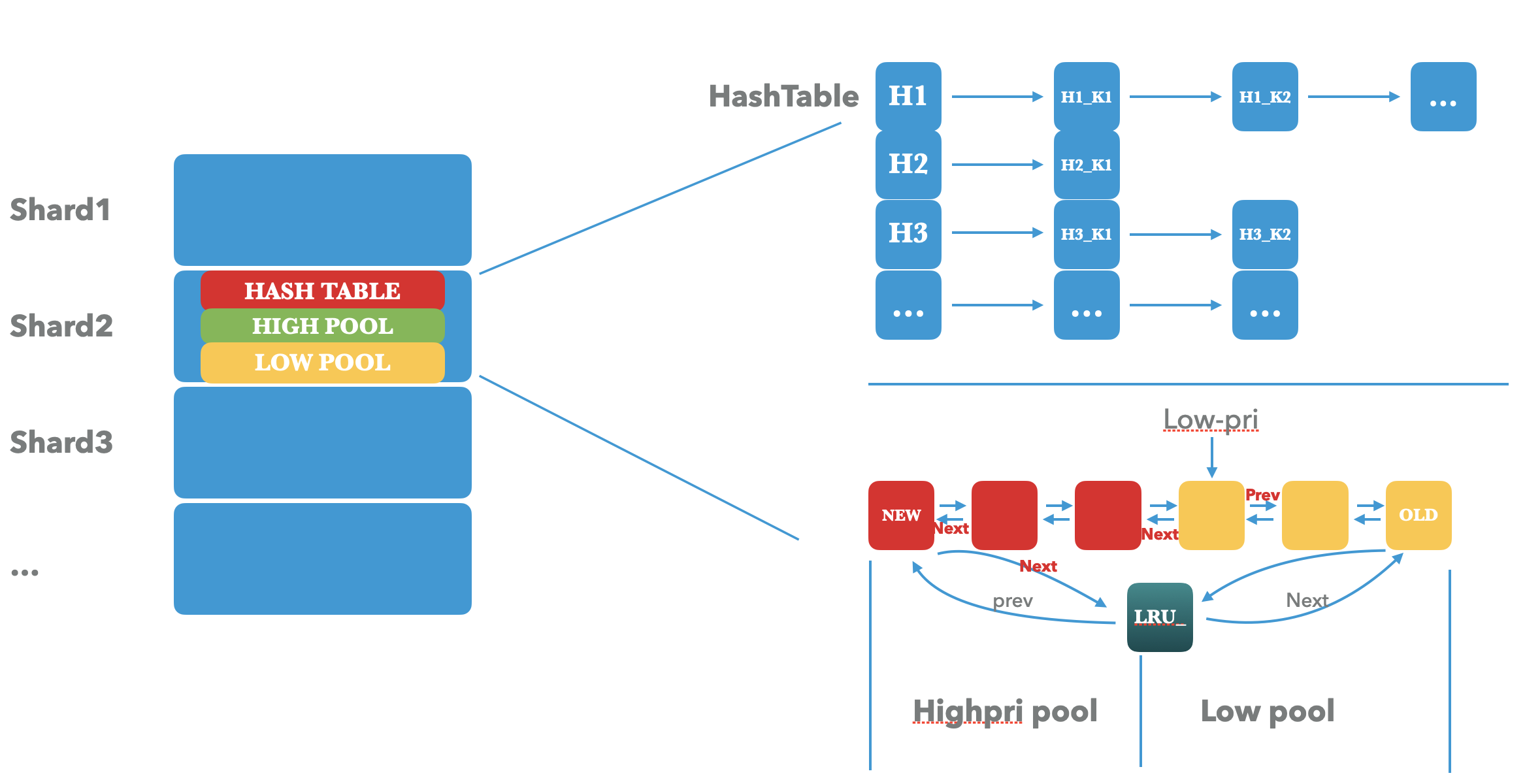
单机 “5千万以上“ 工业级 LRU cache 实现
文章目录前言工业级 LRU Cache1. 基本架构2. 基本操作2.1 insert 操作2.2 高并发下 insert 的一致性/性能 保证2.3 Lookup操作2.4 shard 对 cache Lookup 性能的影响2.4 Erase 操作2.5 内存维护3. 优化前言 近期做了很多 Cache 优化相关的事情,因为对存储引擎较为熟…
Java项目:校园人力人事资源管理系统(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 校园人力资源管理系统:学校部门管理,教室管理,学历信息管理,职务,教师职称,奖励,学历,社会关系,工作…

GPS部标平台的架构设计(十)-基于Asp.NET MVC构建GPS部标平台
在当前很多的GPS平台当中,有很多是基于asp.NETsiverlight开发的遗留项目,代码混乱而又难以维护,各种耦合和关联,要命的是界面也没见到比Javascript做的控件有多好看,随着需求的增多,平台已经臃肿不堪。 设计…
关于CSDN不给任何通知强制关闭我的6年博客,我深表痛心
关于CSDN不给任何通知强制关闭我的6年博客,我深表痛心。最近有很长一段时间没有去csdn博客了, 前几天去看的时候发现博客被封闭了。 我联系了管理员,但是没有得到任何回复。 我猜想,可能是不是我在博客文章里面加入 自己网站的网…
Vue 环境搭建(win10)
1.安装node node官网安装地址 推荐安装稳定版本(LTS)以及安装路径为系统盘(C) 查看node安装成功否 注释:以下命令使用 命令提示符(管理员)权限,win10 对user权限的限制了访问权限。node -v 查看…

Java项目:化妆品商城系统(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统主要实现的功能有: 网上商城系统,前台后台管理,用户注册,登录,上架展示,分组展示,搜索,收…
python 绘图脚本系列简单记录
简单记录平时画图用到的python 便捷小脚本 1. 从单个文件输入 绘制坐标系图 #!/usr/bin/python # coding: utf-8 import matplotlib.pyplot as plt import numpy as np import matplotlib as mpl import sysfile_name1 sys.argv[1] data_title sys.argv[2] print(file_name1…
iOS-c语言小练习01
// // main.c // C-变量的地址 // // Created by cgq on 15/4/9. // Copyright (c) 2015年 cgq. All rights reserved. // #include <stdio.h> //访问变量的地址 void test1() { char a A; int b 44; printf("a的值:%d\n",a); pri…
蓝桥杯 【基础练习】 十六进制转八进制
问题描述给定n个十六进制正整数,输出它们对应的八进制数。输入格式输入的第一行为一个正整数n (1<n<10)。接下来n行,每行一个由0~9、大写字母A~F组成的字符串,表示要转换的十六进制正整数,每个十六进…

泛在网:泛在网
ylbtech-泛在网:泛在网泛在网络来源于拉丁语Ubiquitous,从字面上看就是广泛存在的,无所不在的网络。也就是人置身于无所不在的网络之中,实现人在任何时间、地点,使用任何网络与任何人与物的信息交换,基于个…

Mac 从Makefile 编译 Rocksdb 源码的一些注意事项
文章目录前言Makefile 编译流程1. 平台变量/环境变量的初始化。2. 编译需要的源码文件变量初始化。3. include 目录的设置。4. 编译的执行逻辑。问题记录1:可能的打包命令ar 失效问题5. 执行具体的编译指令问题记录2: jar 包编译前言 最近在Mac 本地编译Rocksdb 过…

Java项目:在线考试系统(单选,多选,判断,填空,简答题)(java+Springboot+ssm+mysql+html+maven)
源码获取:博客首页 "资源" 里下载! 功能: 学生信息 班级 专业 学号 姓名 在线考试 成绩查询 个人信息 密码修改 教师管理 教师编号 姓名 所教科目 题库管理 单选题 多选题 填空题 判断题,简答题(人工…
看了极光推送技术原理的几点思考
看了极光推送技术原理的几点思考 分类: android2012-11-26 20:50 16586人阅读 评论(18) 收藏 举报目录(?)[] 移动互联网应用现状 因为手机平台本身、电量、网络流量的限制,移动互联网应用在设计上跟传统 PC 上的应用很大不一样,需要根据手机…

查询远程或本地计算机的登录账户
用下面这个函数能获取远程或本地电脑的当前登录用户,同时附加了它的计算机名,所以当你查询多台电脑时将知道结果从哪里来。function Get-LoggedOnUser {param([String[]]$ComputerName $env:COMPUTERNAME)$ComputerName | ForEach-Object {(quser /SERV…
LIS ZOJ - 4028
http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode4028 memset超时 这题竟然是一个差分约束 好吧呢 对于每一个a[i], l < a[i] < r 那么设一个源点s 使 l < a[i] - s < r 是不是就能建边了 然后对于每一个f[i] 如果前面有一个相等的f[j] 则肯定 a[i…
存储引擎 K/V 分离下的index回写问题
前言 近期在做on nvme hash引擎相关的事情,对于非全序的数据集的存储需求,相比于我们传统的LSM或者B-tree的数据结构来说 能够减少很多维护全序上的计算/存储资源。当然我们要保证hash场景下的高写入能力,append-only 还是比较友好的选择。 …