【Spark】Spark基础练习题(一)
题目:
1、创建一个1-10数组的RDD,将所有元素*2形成新的RDD
2、创建一个10-20数组的RDD,使用mapPartitions将所有元素*2形成新的RDD
3、创建一个元素为 1-5 的RDD,运用 flatMap创建一个新的 RDD,新的 RDD 为原 RDD 每个元素的 平方和三次方 来组成 1,1,4,8,9,27…
4、创建一个 4 个分区的 RDD数据为Array(10,20,30,40,50,60),使用glom将每个分区的数据放到一个数组
5、创建一个 RDD数据为Array(1, 3, 4, 20, 4, 5, 8),按照元素的奇偶性进行分组
6、创建一个 RDD(由字符串组成)Array(“xiaoli”, “laoli”, “laowang”, “xiaocang”, “xiaojing”, “xiaokong”),过滤出一个新 RDD(包含“xiao”子串)
7、创建一个 RDD数据为1 to 10,请使用sample不放回抽样
8、创建一个 RDD数据为1 to 10,请使用sample放回抽样
9、创建一个 RDD数据为Array(10,10,2,5,3,5,3,6,9,1),对 RDD 中元素执行去重操作
10、创建一个分区数为5的 RDD,数据为0 to 100,之后使用coalesce再重新减少分区的数量至 2
11、创建一个分区数为5的 RDD,数据为0 to 100,之后使用repartition再重新减少分区的数量至 3
12、创建一个 RDD数据为1,3,4,10,4,6,9,20,30,16,请给RDD进行分别进行升序和降序排列
13、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 6和4 to 10,求并集
14、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 6和4 to 10,计算差集,两个都算
15、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 6和4 to 10,计算交集
16、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 6和4 to 10,计算 2 个 RDD 的笛卡尔积
17、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 5和11 to 15,对两个RDD拉链操作
18、创建一个RDD数据为List((“female”,1),(“male”,5),(“female”,5),(“male”,2)),请计算出female和male的总数分别为多少
19、创建一个有两个分区的 RDD数据为List((“a”,3),(“a”,2),(“c”,4),(“b”,3),(“c”,6),(“c”,8)),取出每个分区相同key对应值的最大值,然后相加
20、 创建一个有两个分区的 pairRDD数据为Array((“a”, 88), (“b”, 95), (“a”, 91), (“b”, 93), (“a”, 95), (“b”, 98)),根据 key 计算每种 key 的value的平均值
21、统计出每一个省份广告被点击次数的 TOP3,数据在access.log文件中
数据结构:时间戳,省份,城市,用户,广告 字段使用空格分割。
样本如下:
1516609143867 6 7 64 16
1516609143869 9 4 75 18
1516609143869 1 7 87 12
22、读取本地文件words.txt,统计出每个单词的个数,保存数据到 hdfs 上
23、读取 people.json 数据的文件, 每行是一个 json 对象,进行解析输出
24、保存一个 SequenceFile 文件,使用spark创建一个RDD数据为
Array((“a”, 1),(“b”, 2),(“c”, 3)),保存为SequenceFile格式的文件到hdfs上
25、读取24题的SequenceFile 文件并输出
26、读写 objectFile 文件,把 RDD 保存为objectFile,RDD数据为Array((“a”, 1),(“b”, 2),(“c”, 3)),并进行读取出来
27、使用内置累加器计算Accumulator.txt文件中空行的数量
28、使用Spark广播变量
用户表:
id name age gender(0|1)
001,刘向前,18,0
002,冯 剑,28,1
003,李志杰,38,0
004,郭 鹏,48,2
要求,输出用户信息,gender必须为男或者女,不能为0,1
使用广播变量把Map(“0” -> “女”, “1” -> “男”)设置为广播变量,最终输出格式为
001,刘向前,18,女
003,李志杰,38,女
002,冯 剑,28,男
004,郭 鹏,48,男
29、mysql创建一个数据库bigdata0407,在此数据库中创建一张表
CREATE TABLE user (
id int(11) NOT NULL AUTO_INCREMENT,
username varchar(32) NOT NULL COMMENT ‘用户名称’,
birthday date DEFAULT NULL COMMENT ‘生日’,
sex char(1) DEFAULT NULL COMMENT ‘性别’,
address varchar(256) DEFAULT NULL COMMENT ‘地址’,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
数据如下:
依次是:姓名 生日 性别 省份
安荷 1998/2/7 女 江苏省
白秋 2000/3/7 女 天津市
雪莲 1998/6/7 女 湖北省
宾白 1999/7/3 男 河北省
宾实 2000/8/7 男 河北省
斌斌 1998/3/7 男 江苏省
请使用spark将以上数据写入mysql中,并读取出来。
30、在hbase中创建一个表student,有一个 message列族
create ‘student’, ‘message’
scan ‘student’, {COLUMNS => ‘message’}
给出以下数据,请使用spark将数据写入到hbase中的student表中,并进行查询出来
数据如下:
依次是:姓名 班级 性别 省份,对应表中的字段依次是:name,class,sex,province
飞松 3 女 山东省
刚洁 1 男 深圳市
格格 4 女 四川省
谷菱 5 女 河北省
国立 2 男 四川省
海涛 3 男 广东省
含芙 3 女 四川省
华敏 4 女 上海市
乐和 2 男 上海市
乐家 3 男 黑龙江
乐康 4 男 湖北省
乐人 5 男 四川省
乐水 3 男 北京市
乐天 4 男 河北省
乐童 5 男 江苏省
乐贤 1 男 陕西省
乐音 2 男 广东省
李仁 3 男 湖北省
立涛 3 女 陕西省
凌青 4 女 湖北省
陆涛 4 男 山东省
媚媚 5 女 河南省
梦亿 4 男 江苏省
铭忠 5 男 四川省
慕梅 3 女 北京市
鹏吉 1 男 上海市
娉婷 4 女 河南省
淇峰 2 男 广东省
庆元 3 男 上海市
庆滋 4 男 北京市
丘东 5 男 江苏省
荣郑 1 男 黑龙江
蕊蕊 5 女 四川省
尚凯 2 男 北京市
诗涵 1 女 河南省
淑凤 2 女 天津市
淑娇 3 女 上海市
淑燕 4 女 河北省
淑怡 4 女 广东省
思璇 2 女 湖北省
苏华 3 女 山东省
苏梅 4 女 四川省
听荷 5 女 深圳市
文怡 1 女 天津市
文怡 2 女 河北省
香凝 3 女 山东省
翔云 4 女 河南省
小芸 5 女 深圳市
答案:
package scalaimport org.apache.hadoop.hbase.{Cell, CellUtil, HBaseConfiguration}
import org.apache.hadoop.hbase.client.{Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}object demo02 {val sc: SparkContext = new SparkContext(new SparkConf().setMaster("local").setAppName("demo02"))// 1、创建一个1-10数组的RDD,将所有元素*2形成新的RDDval data1 = sc.makeRDD(1 to 10)val data1Result = data1.map(_ * 2)// 2、创建一个10-20数组的RDD,使用mapPartitions将所有元素*2形成新的RDDval data2 = sc.makeRDD(10 to 20)val data2Result = data2.mapPartitions(_.map(_ * 2))// 3、创建一个元素为 1-5 的RDD,运用 flatMap创建一个新的 RDD,新的 RDD 为原 RDD 每个元素的 平方和三次方 来组成 1,1,4,8,9,27..val data3 = sc.makeRDD(1 to 5)val data3Result = data3.flatMap(x => Array(math.pow(x, 2), math.pow(x, 3)))// 4、创建一个 4 个分区的 RDD数据为Array(10,20,30,40,50,60),使用glom将每个分区的数据放到一个数组val data4 = sc.makeRDD(Array(10, 20, 30, 40, 50, 60))val data4Result = data4.glom()// 5、创建一个 RDD数据为Array(1, 3, 4, 20, 4, 5, 8),按照元素的奇偶性进行分组val data5 = sc.makeRDD(Array(1, 3, 4, 20, 4, 5, 8))val data5Result = data5.groupBy(x => if (x % 2 == 0) "偶数" else "奇数")// 6、创建一个 RDD(由字符串组成)Array("xiaoli", "laoli", "laowang", "xiaocang", "xiaojing", "xiaokong"),过滤出一个新 RDD(包含“xiao”子串)val data6 = sc.makeRDD(Array("xiaoli", "laoli", "laowang", "xiaocang", "xiaojing", "xiaokong"))val data6Result = data6.filter(_.contains("xiao"))// 7、创建一个 RDD数据为1 to 10,请使用sample不放回抽样val data7 = sc.makeRDD(1 to 10)val data7Result = data7.sample(false, 0.5, 1)// 8、创建一个 RDD数据为1 to 10,请使用sample放回抽样val data8 = sc.makeRDD(1 to 10)val data8Result = data8.sample(true, 0.5, 1)// 9、创建一个 RDD数据为Array(10,10,2,5,3,5,3,6,9,1),对 RDD 中元素执行去重操作val data9 = sc.makeRDD(Array(10, 10, 2, 5, 3, 5, 3, 6, 9, 1))val data9Result = data9.distinct()// 10、创建一个分区数为5的 RDD,数据为0 to 100,之后使用coalesce再重新减少分区的数量至 2val data10 = sc.makeRDD(0 to 100, 5)val data10Result = data10.coalesce(2)// 11、创建一个分区数为5的 RDD,数据为0 to 100,之后使用repartition再重新减少分区的数量至 3val data11 = sc.makeRDD(0 to 100, 5)val data11Result = data11.repartition(3)// 12、创建一个 RDD数据为1,3,4,10,4,6,9,20,30,16,请给RDD进行分别进行升序和降序排列val data12 = sc.makeRDD(Array(1, 3, 4, 10, 4, 6, 9, 20, 30, 16))val data12Result1 = data12.sortBy(x => x)val data12Result2 = data12.sortBy(x => x, false)// 13、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 6和4 to 10,求并集val data13_1 = sc.makeRDD(1 to 6)val data13_2 = sc.makeRDD(4 to 10)val data13Result = data13_1.union(data13_2)// 14、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 6和4 to 10,计算差集,两个都算val data14_1 = sc.makeRDD(1 to 6)val data14_2 = sc.makeRDD(4 to 10)val data14Result_1 = data14_1.subtract(data14_2)val data14Result_2 = data14_2.subtract(data14_1)// 15、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 6和4 to 10,计算交集val data15_1 = sc.makeRDD(1 to 6)val data15_2 = sc.makeRDD(4 to 10)val data15Result_1 = data15_1.intersection(data15_2)// 16、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 6和4 to 10,计算 2 个 RDD 的笛卡尔积val data16_1 = sc.makeRDD(1 to 6)val data16_2 = sc.makeRDD(4 to 10)val data16Result = data16_1.cartesian(data16_2)// 17、创建两个RDD,分别为rdd1和rdd2数据分别为1 to 5和11 to 15,对两个RDD拉链操作val data17_1 = sc.makeRDD(1 to 5)val data17_2 = sc.makeRDD(11 to 15)val data17Result = data17_1.zip(data17_2)// 18、创建一个RDD数据为List(("female",1),("male",5),("female",5),("male",2)),请计算出female和male的总数分别为多少val data18 = sc.makeRDD(List(("female", 1), ("male", 5), ("female", 5), ("male", 2)))val data18Result = data18.reduceByKey(_ + _)// 19、创建一个有两个分区的 RDD数据为List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),取出每个分区相同key对应值的最大值,然后相加/*** (a,3),(a,2),(c,4)* (b,3),(c,6),(c,8)*/val data19 = sc.makeRDD(List(("a", 3), ("a", 2), ("c", 4), ("b", 3), ("c", 6), ("c", 8)), 2)data19.glom().collect().foreach(x => println(x.mkString(",")))val data19Result = data19.aggregateByKey(0)(math.max(_, _), _ + _)// 20、创建一个有两个分区的 pairRDD数据为Array(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),根据 key 计算每种 key 的value的平均值val data20 = sc.makeRDD(Array(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)))val data20Result = data20.map(x => (x._1, (x._2, 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2))// 21、统计出每一个省份广告被点击次数的 TOP3,数据在access.log文件中// 数据结构:时间戳,省份,城市,用户,广告 字段使用空格分割。val file1 = sc.textFile("input20200407/access.log")file1.map { x => var datas = x.split(" "); (datas(1), (datas(4), 1)) }.groupByKey().map {case (province, list) => {val tuples = list.groupBy(_._1).map(x => (x._1, x._2.size)).toList.sortWith((x, y) => x._2 > y._2).take(3)(province, tuples)}}.collect().sortBy(_._1).foreach(println)// 22、读取本地文件words.txt,统计出每个单词的个数,保存数据到 hdfs 上val file2 = sc.textFile("file:///F:\\study\\题库\\大数据题库\\words.txt")file2.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile("hdfs://node01:8020/20200407_wordsOutput")// 23、读取 people.json 数据的文件, 每行是一个 json 对象,进行解析输出import scala.util.parsing.json.JSONval file3 = sc.textFile("input20200407/people.json")val result: RDD[Option[Any]] = file3.map(JSON.parseFull)// 24、保存一个 SequenceFile 文件,使用spark创建一个RDD数据为Array(("a", 1),("b", 2),("c", 3)),保存为SequenceFile格式的文件到hdfs上val data24 = sc.makeRDD(Array(("a", 1), ("b", 2), ("c", 3)))data24.saveAsSequenceFile("hdfs://node01:8020/20200407_SequenceFile")// 25、读取24题的SequenceFile 文件并输出val data25: RDD[(String, Int)] = sc.sequenceFile[String, Int]("hdfs://node01:8020/20200407_SequenceFile/part-00000")// 26、读写 objectFile 文件,把 RDD 保存为objectFile,RDD数据为Array(("a", 1),("b", 2),("c", 3)),并进行读取出来val data26_1 = sc.makeRDD(Array(("a", 1), ("b", 2), ("c", 3)))data26_1.saveAsObjectFile("output20200407/20200407_objectFile")val data26_2 = sc.objectFile("output20200407/20200407_objectFile")// 27、使用内置累加器计算Accumulator.txt文件中空行的数量val data27 = sc.textFile("input20200407/Accumulator.txt")var count = sc.longAccumulator("count")data27.foreach { x => if (x == "") count.add(1) }println(count.value)/*** 28、使用Spark广播变量* 用户表:* id name age gender(0|1)* 001,刘向前,18,0* 002,冯 剑,28,1* 003,李志杰,38,0* 004,郭 鹏,48,1* 要求,输出用户信息,gender必须为男或者女,不能为0,1* 使用广播变量把Map("0" -> "女", "1" -> "男")设置为广播变量,最终输出格式为* 001,刘向前,18,女* 003,李志杰,38,女* 002,冯 剑,28,男* 004,郭 鹏,48,男*/val data28 = sc.textFile("input20200407/user.txt")val sex = sc.broadcast(Map("0" -> "女", "1" -> "男"))data28.foreach { x => var datas = x.split(","); println(datas(0) + "," + datas(1) + "," + datas(2) + "," + sex.value(datas(3))) }/*** 29、mysql创建一个数据库bigdata0407,在此数据库中创建一张表* CREATE TABLE `user` (* `id` int(11) NOT NULL AUTO_INCREMENT,* `username` varchar(32) NOT NULL COMMENT '用户名称',* `birthday` date DEFAULT NULL COMMENT '生日',* `sex` char(1) DEFAULT NULL COMMENT '性别',* `address` varchar(256) DEFAULT NULL COMMENT '地址',* PRIMARY KEY (`id`)* ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;* 数据如下:* 依次是:姓名 生日 性别 省份* 安荷 1998/2/7 女 江苏省* 白秋 2000/3/7 女 天津市* 雪莲 1998/6/7 女 湖北省* 宾白 1999/7/3 男 河北省* 宾实 2000/8/7 男 河北省* 斌斌 1998/3/7 男 江苏省* 请使用spark将以上数据写入mysql中,并读取出来。*/val data29 = sc.textFile("input20200407/users.txt")val driver = "com.mysql.jdbc.Driver"val url = "jdbc:mysql://localhost:3306/bigdata0407"val username = "root"val password = "root"/*** MySQL插入数据*/data29.foreachPartition {data =>Class.forName(driver)val connection = java.sql.DriverManager.getConnection(url, username, password)val sql = "INSERT INTO `user` values (NULL,?,?,?,?)"data.foreach {tuples => {val datas = tuples.split(" ")val statement = connection.prepareStatement(sql)statement.setString(1, datas(0))statement.setString(2, datas(1))statement.setString(3, datas(2))statement.setString(4, datas(3))statement.executeUpdate()statement.close()}}connection.close()}/*** MySQL查询数据*/var sql = "select * from `user` where id between ? and ?"val jdbcRDD = new JdbcRDD(sc,() => {Class.forName(driver)java.sql.DriverManager.getConnection(url, username, password)},sql,0,44,3,result => {println(s"id=${result.getInt(1)},username=${result.getString(2)}" +s",birthday=${result.getDate(3)},sex=${result.getString(4)},address=${result.getString(5)}")})jdbcRDD.collect()/*** 30、在hbase中创建一个表student,有一个 message列族* create 'student', 'message'* scan 'student', {COLUMNS => 'message'}* 给出以下数据,请使用spark将数据写入到hbase中的student表中,并进行查询出来* 数据如下:* 依次是:姓名 班级 性别 省份,对应表中的字段依次是:name,class,sex,province*///org.apache.hadoop.hbase.mapreduce.TableInputFormatval conf = HBaseConfiguration.create()conf.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181")conf.set(TableInputFormat.INPUT_TABLE, "student")/*** HBase插入数据*/val dataRDD: RDD[String] = sc.textFile("input20200407/student.txt")val putRDD: RDD[(ImmutableBytesWritable, Put)] = dataRDD.map {//飞松 3 女 山东省case line => {val datas = line.split("\t")val rowkey = Bytes.toBytes(datas(0))val put = new Put(rowkey)put.addColumn(Bytes.toBytes("message"), Bytes.toBytes("name"), Bytes.toBytes(datas(0)))put.addColumn(Bytes.toBytes("message"), Bytes.toBytes("class"), Bytes.toBytes(datas(1)))put.addColumn(Bytes.toBytes("message"), Bytes.toBytes("sex"), Bytes.toBytes(datas(2)))put.addColumn(Bytes.toBytes("message"), Bytes.toBytes("province"), Bytes.toBytes(datas(3)))(new ImmutableBytesWritable(rowkey), put)}}val jobConf = new JobConf(conf)//org.apache.hadoop.hbase.mapred.TableOutputFormatjobConf.setOutputFormat(classOf[TableOutputFormat])jobConf.set(TableOutputFormat.OUTPUT_TABLE, "student")putRDD.saveAsHadoopDataset(jobConf)/*** HBase查询数据*/val hbaseRDD: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])hbaseRDD.foreach {case (rowKey, result) => {val cells: Array[Cell] = result.rawCells()for (cell <- cells) {println(Bytes.toString(CellUtil.cloneRow(cell)) + "\t" +Bytes.toString(CellUtil.cloneFamily(cell)) + "\t" +Bytes.toString(CellUtil.cloneQualifier(cell)) + "\t" +Bytes.toString(CellUtil.cloneValue(cell)))}}}
}相关文章:
Python(27)_字符串的常用的方法2
#-*-coding:utf-8-*-字符串操作s " bowen " # 从右边删 s1 s.rstrip() print(len(s1)) s2 s1.lstrip() print(len(s2)) 从右边删除元素,从左边删除元素,这个在以后项目中经常用到 二、计算个数 #-*-coding:utf-8-*-字符串操作s " bo…

tensorflow1
1、什么是tensorflow tensorflow是一个开源软件库,使用data flow graphs进行数值计算,最初由Google大脑团队开发,用于机器学习和深度卷积网络的研究,同样适用于其他广泛的领域。 2、访问tensorflow官网:在Windows的hos…

大型企业门户网站设计开发一般性原则和建议
[适用范围] 本文所述的原则、建议适用于大型企业信息门户网站的设计和开发,注意不是小型企业网站、一般企业电子商务网站、企业级Web应用系统。 [一般性原则] 一、网站设计原则 第一原则:内容丰富、明确 网站主要是为浏览着提供信息服务的,作…
8月第3周回顾:四巨头发三大新闻 一报告引多家争议
8月15日是51CTO.com成立两周年的日子,网站举办了多种活动进行了庆祝;凑巧的是,IT界在本周也热闹非凡:微软、甲骨文、IBM和Sun联手送上三份重要新闻;国内一份个人安全的报告引起一场小小的风波——这些都足以让关注IT技…
车辆匹配和平均车速计算
数据测试内容以及详情见 https://github.com/xueyeyu/avgsp /* 作者:雪夜羽 平均车速计算(sqlserver)基于电警 QQ:1412900482 */ import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement…
为何 Map接口不继承Collection接口
1.首先Map提供的是键值对映射(即Key和value的映射),而collection提供的是一组数据(并不是键值对映射)。 如果map继承了collection接口,那么所有实现了map接口的类到底是用map的键值对映射数据还是用collec…

Linux 开机网络无法自动连接配置、网络开机自动连接
第一步:查看开机后网络是否正常连接? 1、图形界面开机后直接看右上角的网络是否连接正常(如图一)。 图一(表示未正常连接↑↑↑↑↑↑↑↑↑) 2、如果是命令页面的,可以使用命令查看网络连接情况…
sql中将分隔字符串转为临时表的方法
问题: 要求将 一字符串 0,1,2,3,4,5 ;将,分隔后的每一内容转为一行记录到数据库表中declare table_串转数组 table( adapt_object int default 0) declare tmp_str varchar(100) declare tmp_index int select tmp_index 1 select tmp_str 0,1,12,03,4,5,a,…
每天学一点flash(15) xml的一些常见写法
今天下了大雨来了,什么地方去不了,只好将想写的东西都记载下来。 一些常见的一些xml写法,收集目的就是为了代码调试方便: 一.简单数组单值形 <?xml version"1.0" encoding"UTF-8"?> <i…
spark为什么比hive速度快?
spark是什么? spark是针对于大规模数据处理的统一分析引擎,通俗点说就是基于内存计算的框架 spark和hive的区别? spark的job输出结果可保存在内存中,而MapReduce的job输出结果只能保存在磁盘中,io读取速度要比内存中…

kotlin 练习
kotlin基础语法 samychen 关注 2017.05.28 17:07* 字数 1224 阅读 2434评论 0喜欢 6每种编程语言都有一定的语法、语义和执行顺序(同步),学习一种新语言也都是从这三者出发,下面我们就只针对kotlin的语法来做简单的介绍。 Kotlin有自己的特性不该被Java的…
软件设计之 数据库设计
[按语:在软件设计或是动态网站开发中,数据库设计时很重要,我觉得可以说是开发工作的核心部分,所以学好数据库设计,是很重要的,也是大有前途的。。。]◆.概念首先要搞清楚容易混淆的两个概念&…
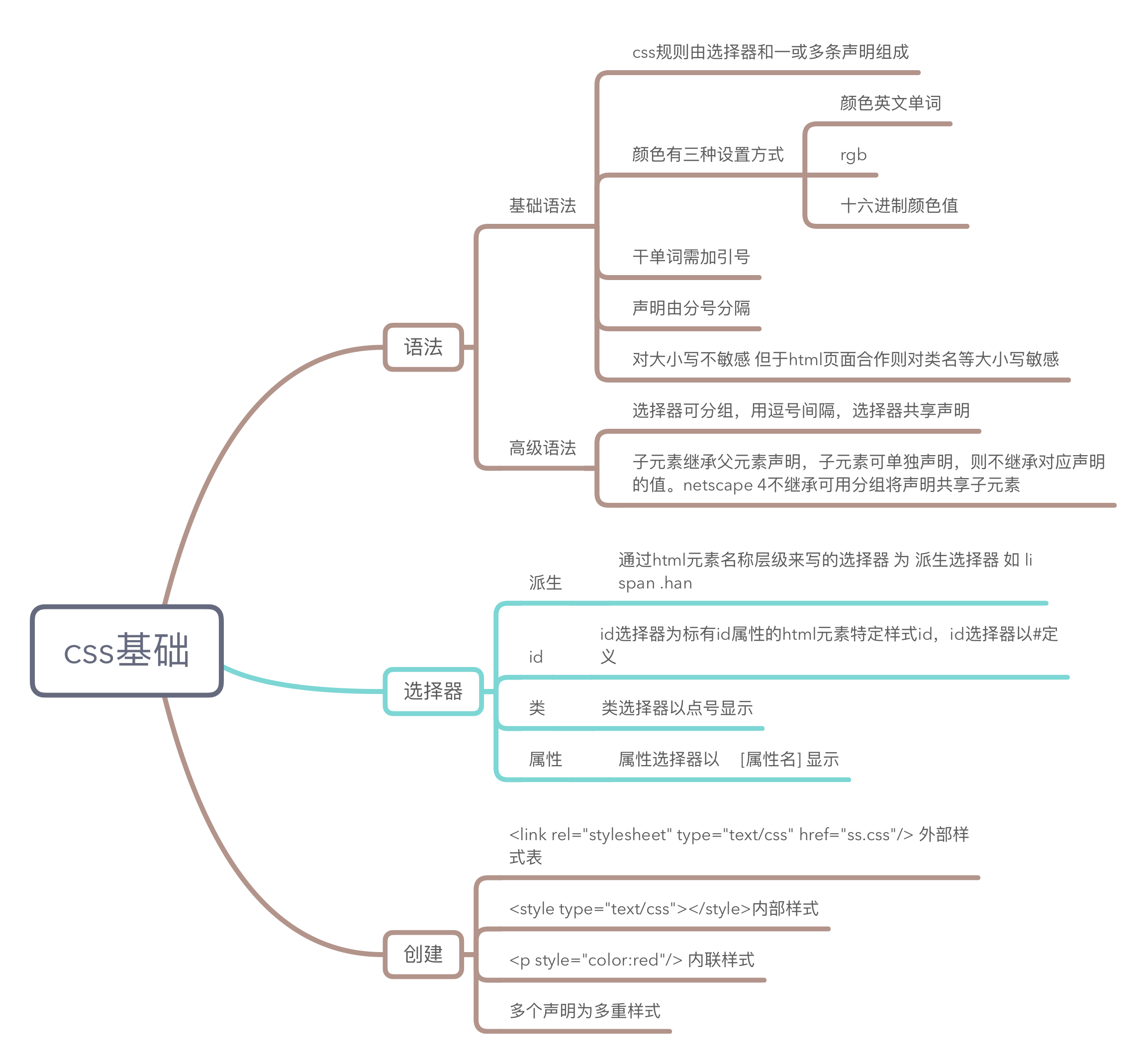
css结构思维导图
以下的图是根据css基础,样式,框模型,定位以及选择器这几个方面总结出来的思维导图,方便记忆以及查询。 转载于:https://www.cnblogs.com/yuexiuyi/p/7352516.html
C#类的修饰符
访问修饰符:public:访问不受限制。protected:访问仅限于包含类或从包含类派生的类型。只有包含该成员的类以及继承的类可以存取.Internal:访问仅限于当前程序集。只有当前工程可以存取.protected internal:访问仅限于当前程序集或…
Appium+Python 自动化测试一之:环境安装(Android篇)
目前网上有大量AppiumPython的APP自动化测试的资料,这里我只是记录一下自己安装的过程,好让自己以后忘记的时候再翻起来看看,快速上手,不想再像之前那样踩坑。 注:因为之前玩过Robot FrameworkSelenium2,所…
sql server 2005 T-SQL @@TOTAL_READ (Transact-SQL)
返回 SQL Server 自上次启动后由 SQL Server 读取(非缓存读取)的磁盘的数目。 Transact-SQL 语法约定 语法 TOTAL_READ 返回类型 integer 备注 若要显示包含多项 SQL Server 统计信息(包括读写活动)的报表,请运行 sp_m…
存储结构分四类:顺序存储、链接存储、索引存储 和 散列存储
存储结构分四类:顺序存储、链接存储、索引存储 和 散列存储。 顺序结构和链接结构适用在内存结构中。 顺序表每个单元都是按物理顺序排列的,如果你想访问那个单元你可以根据提供的指针等直接访问到需要的东西,但是链表是逻辑连续不是物理连续…
[luoguP2618] 数字工程(DP)
传送门 离线处理。。。 先线性筛一遍。 直接预处理出所有答案。 注意要用push,用乘法,常数小。 #include <cstdio> #include <cstring> #define N 1000001 #define min(x, y) ((x) < (y) ? (x) : (y))int n, cnt; int f[N], prime[N]; b…

QOS的qmtoken 1
在有拥塞的时候高层协议如TCP可能自己可以控制下拥塞,因此你的队列效果可能不明显了,这个时候TCP就是,网络拥塞丢包增加,重传增加。此时可以定义波特率修改接口带宽,从而从底层截掉带宽制作拥塞或使用LR,LR…
关于SQL的基础知识点
文章目录一 了解SQL二 检索数据三 排序检索数据四 过滤数据五 高级数据过滤六 用通配符进行过滤七 创建计算字段八 使用数据处理函数九 汇总数据十 分组数据十一、 子查询十二、 联结表十三、 创建高级联结十四 组合查询十五 插入数据十六 更新和删除数据十七 创建和操纵表十八…
DB-MySQL:MySQL 事务
ylbtech-DB-MySQL:MySQL 事务1.返回顶部 1、MySQL 事务 MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息…
asp.net程序性能优化的七个方面
asp.net程序性能优化的七个方面 一、数据库操作 1、用完马上关闭数据库连接 访问数据库资源需要创建连接、打开连接和关闭连接几个操作。这些过程需要多次与数据库交换信息以通过身份验证,比较耗费服务器资 源。ASP.NET中提供了连接池(Connection Pool&a…
如何在Windows Server 2008 Core里面添加Role~~~
SERVER CORE 中添加服务器添加AD:在SERVER CORE 下安装AD必须使用UNATTEND文件来进行安装以下是一个UNATTED文件的实例; DCPROMO unattend file (automatically generated by dcpromo); Usage:; dcpromo.exe /unattend:F:\LONGHORN.txt;[DCInstall]; New forest p…

关于MySQL的四种事务隔离级别!
本文实验的测试环境:Windows 10cmdMySQL5.6.36InnoDB 一、事务的基本要素(ACID) 原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环…
[PKUWC2018]随机算法
题意:https://loj.ac/problem/2540 给定一个图(n<20),定义一个求最大独立集的随机化算法 产生一个排列,依次加入,能加入就加入 求得到最大独立集的概率 loj2540 「PKUWC 2018」随机算法 本质就是计数题 每个点有三种状态&#…
angular4 note
纪录作为新手,用新版angular遇到的一些细节点 1. .angular-cli.json文件 一开始没注意这个文件干啥的,直到我发现有个第三方js,我既没有在index.html里看到引用,也没看到在js代码里有import,找了好久,在这…
初学 Delphi 嵌入汇编[3] - 第一个 Delphi 与汇编的例子
前面知道了一个汇编的赋值指令(MOV), 再了解一个加法指令(ADD), 就可以做个例子了.譬如: ADD AX,BX; 这相当于 Delphi 中的 AX : AX BX;另外提前来个列表 - Delphi 可以用汇编管理以下寄存器:32 位寄存器: EAX EBX ECX EDX ESP EBP ESI EDI16 位寄存器: AX BX CX DX SP BP SI …
通过应用程序域AppDomain加载和卸载程序集之后,如何再返回原来的主程序域
实现目的:动态加载dll,执行完毕之后可以随时卸载掉,并可以替换这些dll,以在运行中更新dll中的类。 其实就是通过应用程序域AppDomain加载和卸载程序集。 在这方面微软有篇文章http://www.microsoft.com/china/msdn/archives/libra…

Sql语法---DDL
1.SQL的定义 结构化查询语言(Structured Query Language)简称SQL,SQL语句就是对数据库进行操作的一种语言。 2.SQL的作用 通过SQL语句我们可以方便的操作数据库中的数据、表、数据库等。 3.SQL的分类 1. DDL(Data Definition Language)数据定义语言用来定义数据库对象ÿ…
Java程序员三年的工作经验,却不如一个新人的工资高???
文章目录一、关于程序员的几个阶段第一阶段:三年第二阶段:五年第三阶段:十年二、关于项目经验三、关于专业技能1、基本语法2、集合3、设计模式4、多线程5、JDK源码6、框架7、数据库8、数据结构和算法分析9、Java虚拟机10、Web方面的一些问题四…