[分享]五种提高 SQL 性能的方法
标签:sql 优化 server [推送到技术圈] 有时, 为了让应用程序运行得更快,所做的全部工作就是在这里或那里做一些很小调整。啊,但关键在于确定如何进行调整!迟早您会遇到这种情况:应用程序中的 SQL 查询不能按照您想要的方式进行响应。它要么不返回数据,要么耗费的时间长得出奇。如果它降低了报告或您的企业应用程序的速度,用户必须等待的时间过长,他们就会很不满意。就像您的父母不想听您解释为什么在深更半夜才回来一样,用户也不会听你解释为什么查询耗费这么长时间。(“对不起,妈妈,我使用了太多的 LEFT JOIN。”)用户希望应用程序响应迅速,他们的报告能够在瞬间之内返回分析数据。就我自己而言,如果在 Web 上冲浪时某个页面要耗费十多秒才能加载(好吧,五秒更实际一些),我也会很不耐烦。 为了解决这些问题,重要的是找到问题的根源。那么,从哪里开始呢?根本原因通常在于数据库设计和访问它的查询。在本月的专栏中,我将讲述四项技术,这些技术可用于提高基于 SQL Server? 的应用程序的性能或改善其可伸缩性。我将仔细说明 LEFT JOIN、CROSS JOIN 的使用以及 IDENTITY 值的检索。请记住,根本没有神奇的解决方案。调整您的数据库及其查询需要占用时间、进行分析,还需要大量的测试。这些技术都已被证明行之有效,但对您的应用程序而言,可能其中一些技术比另一些技术更适用。 从 __insert返回 IDENTITY我决定从遇到许多问题的内容入手:如何在执行 SQL __insert后检索 IDENTITY 值。通常,问题不在于如何编写检索值的查询,而在于在哪里以及何时进行检索。在 SQL Server 中,下面的语句可用于检索由最新在活动数据库连接上运行的 SQL 语句所创建的 IDENTITY 值: __select@@IDENTITY 这个 SQL 语句并不复杂,但需要记住的一点是:如果这个最新的 SQL 语句不是 INSERT,或者您针对非 __insertSQL 的其他连接运行了此 SQL,则不会获得期望的值。您必须运行下列代码才能检索紧跟在 __insertSQL 之后且位于同一连接上的 IDENTITY,如下所示: __insertINTO Products (ProductName) VALUES ('Chalk')
__select@@IDENTITY在一个连接上针对 Northwind 数据库运行这些查询将返回一个名称为 Chalk 的新产品的 IDENTITY 值。所以,在使用 ADO 的 Visual Basic? 应用程序中,可以运行以下语句: Set oRs = oCn._execute("SET NO__countON;__insertINTO Products _
(ProductName) VALUES ('Chalk');__select@@IDENTITY")
lProductID = oRs(0)此代码告诉 SQL Server 不要返回查询的行计数,然后执行 __insert语句,并返回刚刚为这个新行创建的 IDENTITY 值。SET NO__countON 语句表示返回的记录集有一行和一列,其中包含了这个新的 IDENTITY 值。如果没有此语句,则会首先返回一个空的记录集(因为 __insert语句不返回任何数据),然后会返回第二个记录集,第二个记录集中包含 IDENTITY 值。这可能有些令人困惑,尤其是因为您从来就没有希望过 __insert会返回记录集。之所以会发生此情况,是因为 SQL Server 看到了这个行计数(即一行受到影响)并将其解释为表示一个记录集。因此,真正的数据被推回到了第二个记录集。当然您可以使用 ADO 中的 NextRecordset 方法获取此第二个记录集,但如果总能够首先返回该记录集且只返回该记录集,则会更方便,也更有效率。 此方法虽然有效,但需要在 SQL 语句中额外添加一些代码。获得相同结果的另一方法是在 __insert之前使用 SET NO__countON 语句,并将 __select@@IDENTITY 语句放在表中的 FOR __insert触发器中,如下面的代码片段所示。这样,任何进入该表的 __insert语句都将自动返回 IDENTITY 值。 CREATE TRIGGER trProducts___insertON Products FOR __insertAS __select@@IDENTITY GO 触发器只在 Products 表上发生 __insert时启动,所以它总是会在成功 __insert之后返回一个 IDENTITY。使用此技术,您可以始终以相同的方式在应用程序中检索 IDENTITY 值。 内嵌视图与临时表某些时候,查询需要将数据与其他一些可能只能通过执行 GROUP BY 然后执行标准查询才能收集的数据进行联接。例如,如果要查询最新五个定单的有关信息,您首先需要知道是哪些定单。这可以使用返回定单 ID 的 SQL 查询来检索。此数据就会存储在临时表(这是一个常用技术)中,然后与 Products 表进行联接,以返回这些定单售出的产品数量: CREATE TABLE #Temp1 (OrderID INT NOT NULL, _OrderDate DATETIME NOT NULL) __insertINTO #Temp1 (OrderID, OrderDate) __select TOP 5 o.OrderID, o.OrderDate FROM Orders o ORDER BY o.OrderDate DESC __select p.ProductName, SUM(od.Quantity) AS ProductQuantity FROM #Temp1 t INNER JOIN [Order Details] od ON t.OrderID = od.OrderIDINNER JOIN Products p ON od.ProductID = p.ProductID GROUP BY p.ProductName ORDER BY p.ProductName DROP TABLE #Temp1 这些 SQL 语句会创建一个临时表,将数据插入该表中,将其他数据与该表进行联接,然后除去该临时表。这会导致此查询进行大量 I/O 操作,因此,可以重新编写查询,使用内嵌视图取代临时表。内嵌视图只是一个可以联接到 FROM 子句中的查询。所以,您不用在 tempdb 中的临时表上耗费大量 I/O 和磁盘访问,而可以使用内嵌视图得到同样的结果: __selectp.ProductName, SUM(od.Quantity) AS ProductQuantity FROM (__selectTOP 5 o.OrderID, o.OrderDateFROM Orders o ORDER BY o.OrderDate DESC) t INNER JOIN [Order Details] od ON t.OrderID = od.OrderIDINNER JOIN Products p ON od.ProductID = p.ProductID GROUP BYp.ProductName ORDER BYp.ProductName 此查询不仅比前面的查询效率更高,而且长度更短。临时表会消耗大量资源。如果只需要将数据联接到其他查询,则可以试试使用内嵌视图,以节省资源。 避免 LEFT JOIN 和 NULL当然,有很多时候您需要执行 LEFT JOIN 和使用 NULL 值。但是,它们并不适用于所有情况。改变 SQL 查询的构建方式可能会产生将一个花几分钟运行的报告缩短到只花几秒钟这样的天壤之别的效果。有时,必须在查询中调整数据的形态,使之适应应用程序所要求的显示方式。虽然 TABLE 数据类型会减少大量占用资源的情况,但在查询中还有许多区域可以进行优化。SQL 的一个有价值的常用功能是 LEFT JOIN。它可以用于检索第一个表中的所有行、第二个表中所有匹配的行、以及第二个表中与第一个表不匹配的所有行。例如,如果希望返回每个客户及其定单,使用 LEFT JOIN 则可以显示有定单和没有定单的客户。 此工具可能会被过度使用。LEFT JOIN 消耗的资源非常之多,因为它们包含与 NULL(不存在)数据匹配的数据。在某些情况下,这是不可避免的,但是代价可能非常高。LEFT JOIN 比 INNER JOIN 消耗资源更多,所以如果您可以重新编写查询以使得该查询不使用任何 LEFT JOIN,则会得到非常可观的回报(请参阅图 1 中的图)。 图 1 查询 加快使用 LEFT JOIN 的查询速度的一项技术涉及创建一个 TABLE 数据类型,插入第一个表(LEFT JOIN 左侧的表)中的所有行,然后使用第二个表中的值更新 TABLE 数据类型。此技术是一个两步的过程,但与标准的 LEFT JOIN 相比,可以节省大量时间。一个很好的规则是尝试各种不同的技术并记录每种技术所需的时间,直到获得用于您的应用程序的执行性能最佳的查询。 测试查询的速度时,有必要多次运行此查询,然后取一个平均值。因为查询(或存储过程)可能会存储在 SQL Server 内存中的过程缓存中,因此第一次尝试耗费的时间好像稍长一些,而所有后续尝试耗费的时间都较短。另外,运行您的查询时,可能正在针对相同的表运行其他查询。当其他查询锁定和解锁这些表时,可能会导致您的查询要排队等待。例如,如果您进行查询时某人正在更新此表中的数据,则在更新提交时您的查询可能需要耗费更长时间来执行。 避免使用 LEFT JOIN 时速度降低的最简单方法是尽可能多地围绕它们设计数据库。例如,假设某一产品可能具有类别也可能没有类别。如果 Products 表存储了其类别的 ID,而没有用于某个特定产品的类别,则您可以在字段中存储 NULL 值。然后您必须执行 LEFT JOIN 来获取所有产品及其类别。您可以创建一个值为“No Category”的类别,从而指定外键关系不允许 NULL 值。通过执行上述操作,现在您就可以使用 INNER JOIN 检索所有产品及其类别了。虽然这看起来好像是一个带有多余数据的变通方法,但可能是一个很有价值的技术,因为它可以消除 SQL 批处理语句中消耗资源较多的 LEFT JOIN。在数据库中全部使用此概念可以为您节省大量的处理时间。请记住,对于您的用户而言,即使几秒钟的时间也非常重要,因为当您有许多用户正在访问同一个联机数据库应用程序时,这几秒钟实际上的意义会非常重大。 灵活使用笛卡尔乘积对于此技巧,我将进行非常详细的介绍,并提倡在某些情况下使用笛卡尔乘积。出于某些原因,笛卡尔乘积 (CROSS JOIN) 遭到了很多谴责,开发人员通常会被警告根本就不要使用它们。在许多情况下,它们消耗的资源太多,从而无法高效使用。但是像 SQL 中的任何工具一样,如果正确使用,它们也会很有价值。例如,如果您想运行一个返回每月数据(即使某一特定月份客户没有定单也要返回)的查询,您就可以很方便地使用笛卡尔乘积。 图 2 中的 SQL 就执行了上述操作。 虽然这看起来好像没什么神奇的,但是请考虑一下,如果您从客户到定单(这些定单按月份进行分组并对销售额进行小计)进行了标准的 INNER JOIN,则只会获得客户有定单的月份。因此,对于客户未订购任何产品的月份,您不会获得 0 值。如果您想为每个客户都绘制一个图,以显示每个月和该月销售额,则可能希望此图包括月销售额为 0 的月份,以便直观标识出这些月份。如果使用 图 2 中的 SQL,数据则会跳过销售额为 0 美元的月份,因为在定单表中对于零销售额不会包含任何行(假设您只存储发生的事件)。 图 3 中的代码虽然较长,但是可以达到获取所有销售数据(甚至包括没有销售额的月份)的目标。首先,它会提取去年所有月份的列表,然后将它们放入第一个 TABLE 数据类型表 (@tblMonths) 中。下一步,此代码会获取在该时间段内有销售额的所有客户公司的名称列表,然后将它们放入另一个 TABLE 数据类型表 (@tblCus-tomers) 中。这两个表存储了创建结果集所必需的所有基本数据,但实际销售数量除外。 第一个表中列出了所有月份(12 行),第二个表中列出了这个时间段内有销售额的所有客户(对于我是 81 个)。并非每个客户在过去 12 个月中的每个月都购买了产品,所以,执行 INNER JOIN 或 LEFT JOIN 不会返回每个月的每个客户。这些操作只会返回购买产品的客户和月份。 笛卡尔乘积则可以返回所有月份的所有客户。笛卡尔乘积基本上是将第一个表与第二个表相乘,生成一个行集合,其中包含第一个表中的行数与第二个表中的行数相乘的结果。因此,笛卡尔乘积会向表 @tblFinal 返回 972 行。最后的步骤是使用此日期范围内每个客户的月销售额总计更新 @tblFinal 表,以及选择最终的行集。 如果由于笛卡尔乘积占用的资源可能会很多,而不需要真正的笛卡尔乘积,则可以谨慎地使用 CROSS JOIN。例如,如果对产品和类别执行了 CROSS JOIN,然后使用 WHERE 子句、DISTINCT 或 GROUP BY 来筛选出大多数行,那么使用 INNER JOIN 会获得同样的结果,而且效率高得多。如果需要为所有的可能性都返回数据(例如在您希望使用每月销售日期填充一个图表时),则笛卡尔乘积可能会非常有帮助。但是,您不应该将它们用于其他用途,因为在大多数方案中 INNER JOIN 的效率要高得多。 拾遗补零这里介绍其他一些可帮助提高 SQL 查询效率的常用技术。假设您将按区域对所有销售人员进行分组并将他们的销售额进行小计,但是您只想要那些数据库中标记为处于活动状态的销售人员。您可以按区域对销售人员分组,并使用 HAVING 子句消除那些未处于活动状态的销售人员,也可以在 WHERE 子句中执行此操作。在 WHERE 子句中执行此操作会减少需要分组的行数,所以比在 HAVING 子句中执行此操作效率更高。HAVING 子句中基于行的条件的筛选会强制查询对那些在 WHERE 子句中会被去除的数据进行分组。 另一个提高效率的技巧是使用 DISTINCT 关键字查找数据行的单独报表,来代替使用 GROUP BY 子句。在这种情况下,使用 DISTINCT 关键字的 SQL 效率更高。请在需要计算聚合函数(SUM、COUNT、MAX 等)的情况下再使用 GROUP BY。另外,如果您的查询总是自己返回一个唯一的行,则不要使用 DISTINCT 关键字。在这种情况下,DISTINCT 关键字只会增加系统开销。 您已经看到了,有大量技术都可用于优化查询和实现特定的业务规则,技巧就是进行一些尝试,然后比较它们的性能。最重要的是要测试、测试、再测试。在此专栏的将来各期内容中,我将继续深入讲述 SQL Server 概念,包括数据库设计、好的索引实践以及 SQL Server 安全范例。 |
转载于:https://blog.51cto.com/zanchun/296914
相关文章:

Win7/Win2008下IIS配置Asp站点启用父路径的设置方法
iis日志错误如下: 修改路径文件权限问题依旧。 解决方式: 转载于:https://www.cnblogs.com/xzlive/p/10904125.html

软件与Cache
Cache是提高CPU性能的一种技术手段,通过Cache存储器把程序频繁用到的指令和数据存储起来,等再次访问该指令或数据时CPU可以直接从Cache中读取而不用访问主存从而能提高程序运行的效率。 Cache背后的理论基础是程序运行的“局部性”原理, “…
Fiddler监控面板显示Server栏(Fiddler v5.0)
1.点击Rules下的Customize Rules.js,会打开Fiddler ScriptEditor 2.去掉 UI.lvSessions.AddBoundColumn("Server", 50, "response.server"); 前的注释符号并保存脚本,监控面板即显示Server栏 转载于:https://www.cnblogs.com/kakaln/p/8207073.…
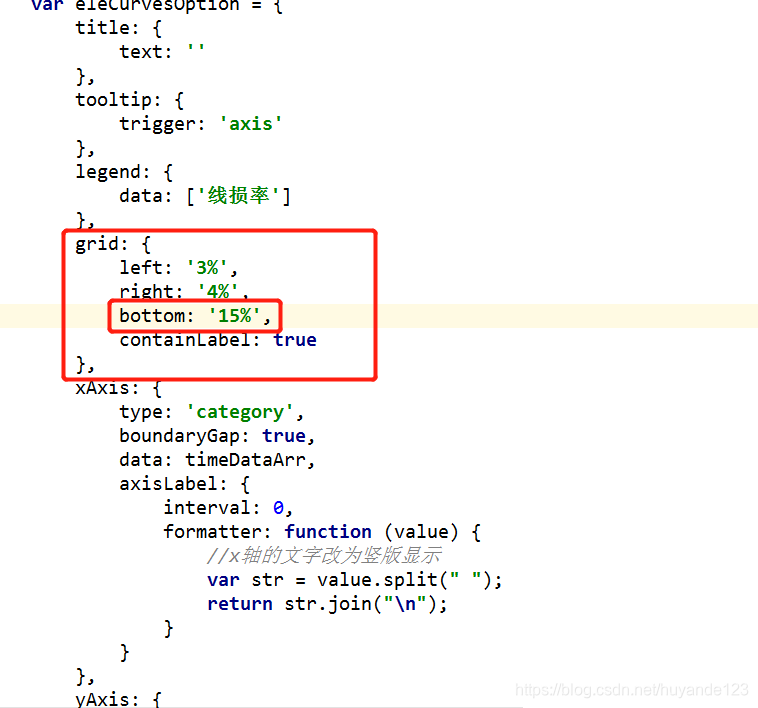
echarts datazoom 显示的位置设置
设置grid属性里的bottom var eleCurves document.getElementById(eleCourtsBeforeCurves);var eleCurvesChart echarts.init(eleCurves);var eleCurvesOption {title: {text: },tooltip: {trigger: axis},legend: {data: [线损率]},grid: {left: 3%,right: 4%,bottom: 15%,…
php file函数在内容与底层逻辑分离的应用
最近在学习dedecms的源代码,看到了一个file函数的应用。在权限管理页面,权限页面内容全部由txt文件记录,用file函数读取txt内容,再将内容转换成html表现形式。是个不错的内容与逻辑层分离的解决方案。file()-- 把整个文件读入一个…
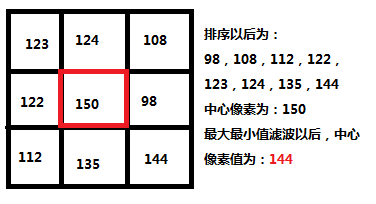
最大最小值滤波
最大最小值滤波 最大最小值滤波是一种比较保守的图像处理手段,与中值滤波类似,首先要排序周围像素和中心像素值,然后将中心像素值与最小和最大像素值比较,如果比最小值小,则替换中心像素为最小值,如果中心像…

Java获取Mybatis动态生成的sql
前提:已经编写好相应的接口个xml文件 public void exportExcel_bw() throws Exception {//封装sql需要查询的sql的条件Map<String, Object> paramMap new HashMap();paramMap.put("parentName", "权限管理");paramMap.put("pageBe…
哲学是什么?(选自:苏菲的世界)
亲爱的苏菲: 人的嗜好各有不同。有些人搜集古钱或外国邮票,有些人喜欢刺绣,有些人则利用大部分的时间从事某种活动。 另外许多人以阅读为乐,但阅读的品味人各不同。有些人只看报纸或漫画,有些人喜欢看小说,…
SQL语句统计错误率
2018年的第一篇博客就以此作为开端吧 :D 最近在项目中碰到需要统计类似错误率之类的需求,原本这功能是之前做的,但是最近测的时候发现出了点问题,显示的结果不对。这就比较尴尬了。。。 于是就进行debug,发现之前写的查询SQL有问…

Microsoft Surface Toolkit Beta 版发布
目前微软发布的这款Microsoft Surface Toolkit 仍是Beta 版。其中包括一些列控件(Control)、API、模板(Template)以及程序样例和文档供开发者使用。只要具备.NET Framework 4.0、WPF 4.0 和带有Windows Touch 功能并安装Windows 7…

第四节 RabbitMQ在C#端的应用-客户端连接
第四节 RabbitMQ在C#端的应用-客户端连接 原文:第四节 RabbitMQ在C#端的应用-客户端连接版权声明:未经本人同意,不得转载该文章,谢谢 https://blog.csdn.net/phocus1/article/details/87357911 1.在VS2013中新建控制台程序,然后添加引用:.NET…

Android控件之ImageView探究
ImageView控件是一个图片控件,负责显示图片。 以下模拟手机图片查看器 目录结构 main.xml布局文件 <?xml version"1.0"encoding"utf-8"?><LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"androi…

R. ftp软件
转载于:https://www.cnblogs.com/youyuanjuyou/p/8257976.html
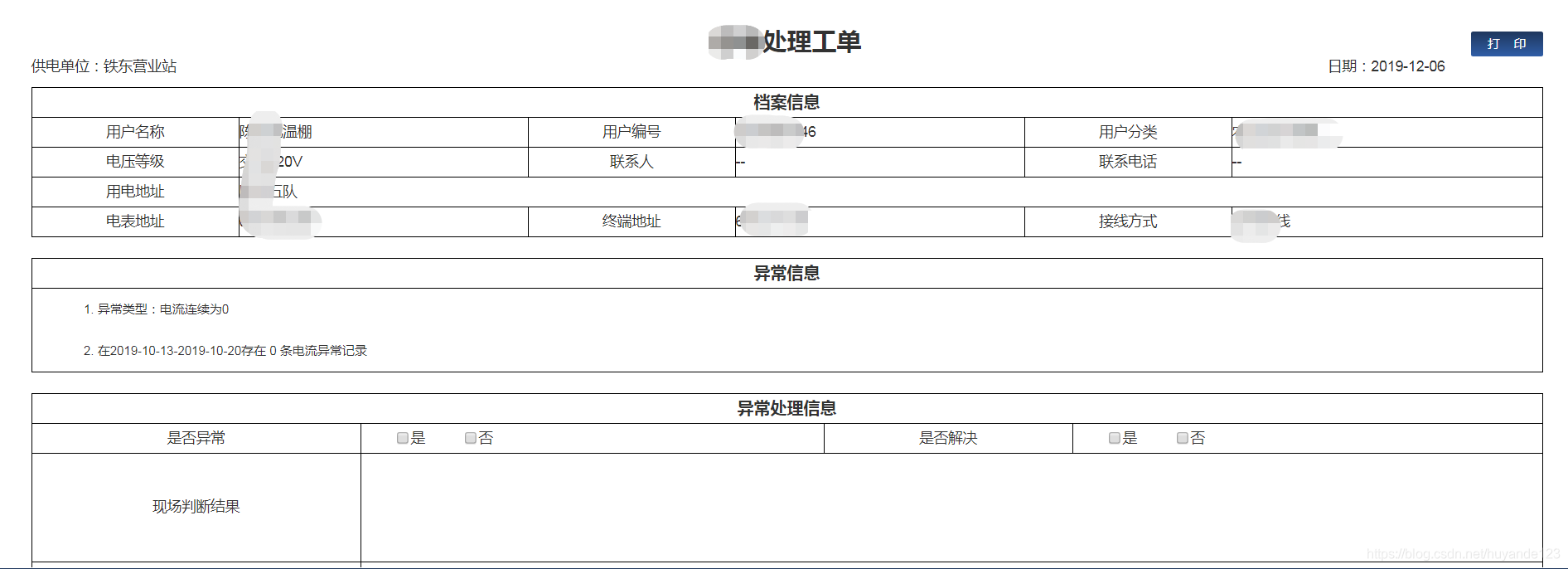
Js打印表格时部分边框不显示(table 标签)
问题如下: 原始表单 ,需要打印在浏览器上打印该表单 出以下效果 原因:是因为当表被复制到一个新窗口时,您的CSS不被保留。你可以通过将一些相关的CSS传递到document.write()方法中的新窗口来解决这个问题。…
35岁以前成功的12条黄金法则(1)
第一章:一个目标 一艘没有航行目标的船,任何方向的风都是逆风。 1、你为什么是穷人,第一点就是你没有立下成为富人的目标。 2、你的人生核心目标是什么?杰出人士与平庸之辈的根本差别并不是天赋、机遇,而在于有无目标。…
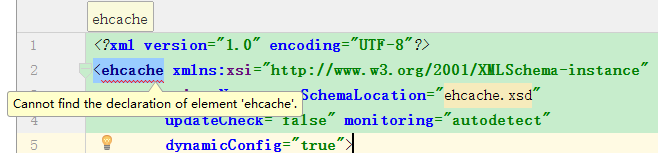
idea配置echache.xml报错Cannot resolve file 'ehcache.xsd'
解决方法: 打开settings->languages&frameworks->schemas and dtds ,添加地址 http://ehcache.org/ehcache.xsd 然后将ehcache.xml 这里做修改 转载于:https://www.cnblogs.com/liaojie970/p/8270570.html
linux环境安装python-pip
参考:https://blog.csdn.net/u013372487/article/details/51726002 1、通过wget方式安装 # wget https://bootstrap.pypa.io/get-pip.py --no-check-certificate #不检查证书,尽量避免使用(某些情况下加入no-check-certificate 即可成功安装) # python…
NLP学习 资料总结
NLP目前应用于7个重要领域: 1.句法语义分析:对于给定的句子,进行分词、词性标记、命名实体识别和链接、句法分析、语义角色识别和多义词消歧。 2.信息抽取:从给定文本中抽取重要信息。通俗来说就是,了解谁在什么时候、…

一生受益的三个小故事
转载于:https://www.cnblogs.com/88223100/archive/2011/02/22/three_stories.html

VS2008中Web Reference和Service Reference的区别
很早就发现在vs2008中应用web service有两种方式,即Add Web Reference和Add Service Reference,但是一直不是很清楚这两者有什么区别。趁着今天有空实验一下这两者的区别并记录下来供大家参考。 首先在网上查找,发现有如下两个主要区别&#…
详细记录python的range()函数用法
详细记录python的range()函数用法 使用python的人都知道range()函数很方便,今天再用到他的时候发现了很多以前看到过但是忘记的细节。这里记录一下range(),复习下list的slide,最后分析一个好玩儿的冒泡程序。 这里记录一下: >>> ran…
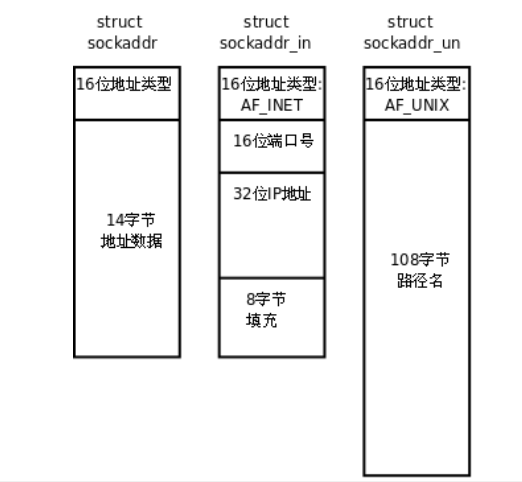
socket编程和并发服务器
socket这个词可以表示很多概念: 在TCP/IP协议中,“IP地址TCP或UDP端口号”唯一标识网络通讯中的一个进程,“IP地址端口号”就称为socket。 在TCP协议中,建立连接的两个进程各自有一个socket来标识,那么这两个socket组成…

基于协同过滤算法实现选课推荐系统
新版本教务管理系统 教务管理系统 选课功能1.系统功能 1、用户账户管理 2、学生个人信息的查看与修改 3、学生的网上选课与课程的评分 4、教师个人信息的查看与修改 5、教师对学生课程评价结果的查看 6、管理员对学生信息与教师信息的查看与添加 7、管理员对课程的增删改查 8、…
linux access函数判断文件存取权限
access(判断是否具有存取文件的权限)相关函数 stat,open,chmod,chown,setuid,setgid表头文件 #include<unistd.h>定义函数 int access(const char * pathname,int mode);函数说明 access(…

Python天天美味(35) - 细品lambda
lambda函数也叫匿名函数,即,函数没有具体的名称。先来看一个最简单例子: deff(x): returnx**2printf(4)Python中使用lambda的话,写成这样 g lambdax : x**2printg(4)lambda表达式在很多编程语言都有对应的实现。比如C#&#x…
jvm:分析工具
bin/jvisualvm.exe 可查看类实例数 bin/jconsole.exe 监控线程,堆,等 http://blog.csdn.net/yaowj2/article/details/7107818 https://blog.csdn.net/janekeyzheng/article/details/41075791 转载于:https://www.cnblogs.com/chen-msg/p/8275299.html
Django 路由分发
Django 路由分发 当一个url请求过来之后1、先到项目主目录下的urls内。2、由这个url做处理分发给其他app内的urls。 一级路由:主目录urls内引入include from django.conf.urls import url,include urlpatterns [# 指定分发的app目录名称url(r^cmdb/,include("…

NHibernate从入门到精通系列(7)——多对一关联映射
内容摘要 多对一关联映射概括 多对一关联映射插入和查询 多对一关联映配置介绍 一、多对一关联映射概括 关联关系是实体类与实体类之间的结构关系,分别为“多对一”、“一对一”、“多对多”。然而“多对一”是怎样描述的呢?让我们参考图1.1所示…

PLSQ执行同样的sql,使用mybatis进行动态拼装执行的时候非常慢的问题解决
如题,项目中碰到了同样的sql,在plsql中执行很快,几乎秒出,但在程序中使用mybatis框架时,却非常的慢,前提是动态拼装的sql。在使用写死的参数,不会出现很慢的效果。最后发现是使用 #{xxx} 去注入…

雨林木风爱好者GHOSTXP装机版_NTFS_SP3_2010_03
系统简介:系统下载参考地址:http://www.51ghostxp.cn/winxp/230.htm迅雷地址:thunder://QUFodHRwOi8vZG93bjUuZ2hvc3QyLmNuL0dIT1NUWFBfU1AzeWxtZmFpaGFvemhlXzIwMTBfMDNbTlRGU10uaXNvWlo雨林木风爱好者GHOSTXP装机版_NTFS_SP3_2010_03主要特点: 此系统采用硬盘安装…