ElasticSearch安装使用 操作索引
文章目录
- 1.下载并安装
- 2.了解es的配置文件**elasticsearch-.yml**(中文配置详解)
- 3.使用head插件
- 1.使用谷歌浏览器head插件
- 2.使用压缩中的head程序
- 4.使用kibana(安装)
- 1.什么是kibana
- 2.kibana国际化,将kibana设值成中文
- 3.启动(es先启动)
- 5.使用es
- 1.es的核心概念
- 2.rest风格操作es
- 1.操作索引
1.下载并安装
链接:https://pan.baidu.com/s/1CpUaKukE5fWxqRSo0t_L9g
提取码:qys8版本为:7.6.1
资料:elasticsearch(win/linux)/kibana/head插件/kibana
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a0J1zGRH-1594953520774)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a0J1zGRH-1594953520774)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
解压windows的es文件,并到bin目录点击elasticsearch.bat ,启动es
2.了解es的配置文件elasticsearch-.yml(中文配置详解)
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please see the documentation for further information on configuration options:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration.html>
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
# 集群名称,默认是elasticsearch
# cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 节点名称,默认从elasticsearch-2.4.3/lib/elasticsearch-2.4.3.jar!config/names.txt中随机选择一个名称
# node.name: node-1
#
# Add custom attributes to the node:
#
# node.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
# 可以指定es的数据存储目录,默认存储在es_home/data目录下
# path.data: /path/to/data
#
# Path to log files:
# 可以指定es的日志存储目录,默认存储在es_home/logs目录下
# path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
# 锁定物理内存地址,防止elasticsearch内存被交换出去,也就是避免es使用swap交换分区
# bootstrap.memory_lock: true
#
#
#
# 确保ES_HEAP_SIZE参数设置为系统可用内存的一半左右
# Make sure that the `ES_HEAP_SIZE` environment variable is set to about half the memory
# available on the system and that the owner of the process is allowed to use this limit.
#
# 当系统进行内存交换的时候,es的性能很差
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
#
# 为es设置ip绑定,默认是127.0.0.1,也就是默认只能通过127.0.0.1 或者localhost才能访问
# es1.x版本默认绑定的是0.0.0.0 所以不需要配置,但是es2.x版本默认绑定的是127.0.0.1,需要配置
# Set the bind address to a specific IP (IPv4 or IPv6):
#
# network.host: 192.168.0.1
#
#
# 为es设置自定义端口,默认是9200
# 注意:在同一个服务器中启动多个es节点的话,默认监听的端口号会自动加1:例如:9200,9201,9202...
# Set a custom port for HTTP:
#
# http.port: 9200
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html>
#
# --------------------------------- Discovery ----------------------------------
#
# 当启动新节点时,通过这个ip列表进行节点发现,组建集群
# 默认节点列表:
# 127.0.0.1,表示ipv4的回环地址。
# [::1],表示ipv6的回环地址
#
# 在es1.x中默认使用的是组播(multicast)协议,默认会自动发现同一网段的es节点组建集群,
# 在es2.x中默认使用的是单播(unicast)协议,想要组建集群的话就需要在这指定要发现的节点信息了。
# 注意:如果是发现其他服务器中的es服务,可以不指定端口[默认9300],如果是发现同一个服务器中的es服务,就需要指定端口了。
# Pass an initial list of hosts to perform discovery when new node is started:
#
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
# discovery.zen.ping.unicast.hosts: ["host1", "host2"]
#
#
#
#
# 通过配置这个参数来防止集群脑裂现象 (集群总节点数量/2)+1
# Prevent the "split brain" by configuring the majority of nodes (total number of nodes / 2 + 1):
#
# discovery.zen.minimum_master_nodes: 3
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html>
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
# 一个集群中的N个节点启动后,才允许进行数据恢复处理,默认是1
# gateway.recover_after_nodes: 3
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-gateway.html>
#
# ---------------------------------- Various -----------------------------------
# 在一台服务器上禁止启动多个es服务
# Disable starting multiple nodes on a single system:
#
# node.max_local_storage_nodes: 1
#
# 设置是否可以通过正则或者_all删除或者关闭索引库,默认true表示必须需要显式指定索引库名称
# 生产环境建议设置为true,删除索引库的时候必须显式指定,否则可能会误删索引库中的索引库。
# Require explicit names when deleting indices:
#
# action.destructive_requires_name: true
3.使用head插件
1.使用谷歌浏览器head插件
在谷歌商店搜索elasticsearch并安装
2.使用压缩中的head程序
解压
或者克隆改程序 ,按照说明文档按照程序
https://github.com/mobz/elasticsearch-head.git
程序运行环境要求
- node
- npm
当使用本地搭建的head程序连接本地的es服务,可能会出现跨域的问题,需要在elasticsearch-.yml添加跨域的配置
http.cors.enabled: true
http.cors.allow-origin: "*"
4.使用kibana(安装)
解压
注意:kibana需要和es 的版本要对应起来使用
1.什么是kibana
Kibana 是一个为 Logstash 和 ElasticSearch 提供的日志分析的 Web 接口。可使用它对日志进行高效的搜索、可视化、分析等各种操作。
2.kibana国际化,将kibana设值成中文
3.启动(es先启动)
5.使用es
1.es的核心概念
- 索引
- 字段类型
- 文档
es与关系型数据库对比认识(es是面向文档的)
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包 含多 个文档(行),每个文档中又包含多个字段(列)。
集群,节点,索引,类型,文档,分片,映射是什么?
物理设计:
elasticsearch 在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2。 当我们索引一篇文档时,可以通过这样的一各 顺序找到 它: 索引 ▷ 类型 ▷ 文档ID ,通过这个组合我们就能索引到某个具体的文档。 注意:ID不必是整 数,实际上它是个字 符串。
文档
就是一条一条的数据
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch 中,文档有几个 重要属性 :
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含 key:value!
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一个json对象! fastjson进行自动转换!}
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用, 在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个 新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类 型,可以是字符 串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种 映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。 类型中对于字段的定义称为映射, 比如 name 映 射为字符串类型。 我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段, 比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这 个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它 是整形。 但是elasticsearch也可能猜不对, 所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库不一样,先定义好字段,然后再使用。
索引
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段 和其他设置。 然后它们被存储到了各个分片上了。
我们来研究下分片是如何工作的。 物理设计 :节点和分片 如何工作
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的,如果 你创建索引,那么索引将会有个5个分片 ( primary shard ,又称主分片 ) 构成的,每一个主分片会有一个 副本 ( replica shard ,又称复制分片 )
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某 个节点挂掉 了,数据也不至于丢失。 实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件 目录,倒排索引的结构使 得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的 关键字。
倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的 全文搜索, 一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。 例 如,现在有两个文档, 每个文档包含如下内容:
Study every day, good good up to forever # 文档1包含的内容
To forever, study every day, good good up # 文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包 含所有不重 复的词条的排序列表,然后列出每个词条出现在哪个文档 :
现在,我们试图搜索 to forever,只需要查看包含每个词条的文档 score
两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键 字的文档都将返回。 再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构 :
如果要搜索含有 python 标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快 的多。只需要 查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率! elasticsearch的索引和Lucene的索引对比 在elasticsearch中, 索引 (库)这个词被频繁使用,这就是术语的使用。 在elasticsearch中,索引被 分为多个分片,每份 分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成 的。别问为什么,谁让elasticsearch使用Lucene作为底层呢! 如无特指,说起索引都是指elasticsearch 的索引。
ik分词器的使用
2.rest风格操作es
它主要用于客户端和服务器交 互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
1.操作索引
增加索引(POST/PUT)请求
POST /test01/type01/1 #/索引名称/类型/文档id(不指定会自动创建)
{"name":"hello world"
}查询索引信息
GET /test01/type01/1 #/索引名称/类型/文档id
创建文档时 指定类型
es中文档有那些类型
创建索引时,指定索引类型 (必须是PUT请求,POST请求不行)
PUT /test02
{"mappings":{"properties":{"name":{"type":"text"},"age":{"type":"long"},"brithday":{"type":"date"}}}
}
查询刚创建的索引信息
查看索引情况
GET _cat/ #获取es当前的信息
删除索引
DELETE /test01
删除索引的文档
DELETE /test02/_doc/1
相关文章:

36.两个链表的第一个公共结点——剑指offer
/* 找出2个链表的长度,然后让长的先走两个链表的长度差,然后再一起走 (因为2个链表用公共的尾部) */ class Solution { public:ListNode* FindFirstCommonNode( ListNode *pHead1, ListNode *pHead2) {int len1 findListLenth(pH…

浅析SAAS数据模型设计(Oracle)
目前SAAS平台对于大家来说并不陌生,市场上真正属于SAAS应用的并不是特别多,还有很大一部分是ASP的模式在运行,不管对于公司还是技术部门都是很大的挑战。去年在做elearning项目的时候其实也就是一个ASP的模式扩展,ASP模式本身就会…
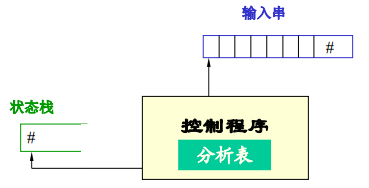
编译原理(六)自底向上分析之LR分析法
自底向上分析之LR分析法 说明:以老师PPT为标准,借鉴部分教材内容,AlvinZH学习笔记。 基本概念 1. LR分析:从左到右扫描(L)自底向上进行规约(R),是规范规约,也即最右推导(规范推导)&a…
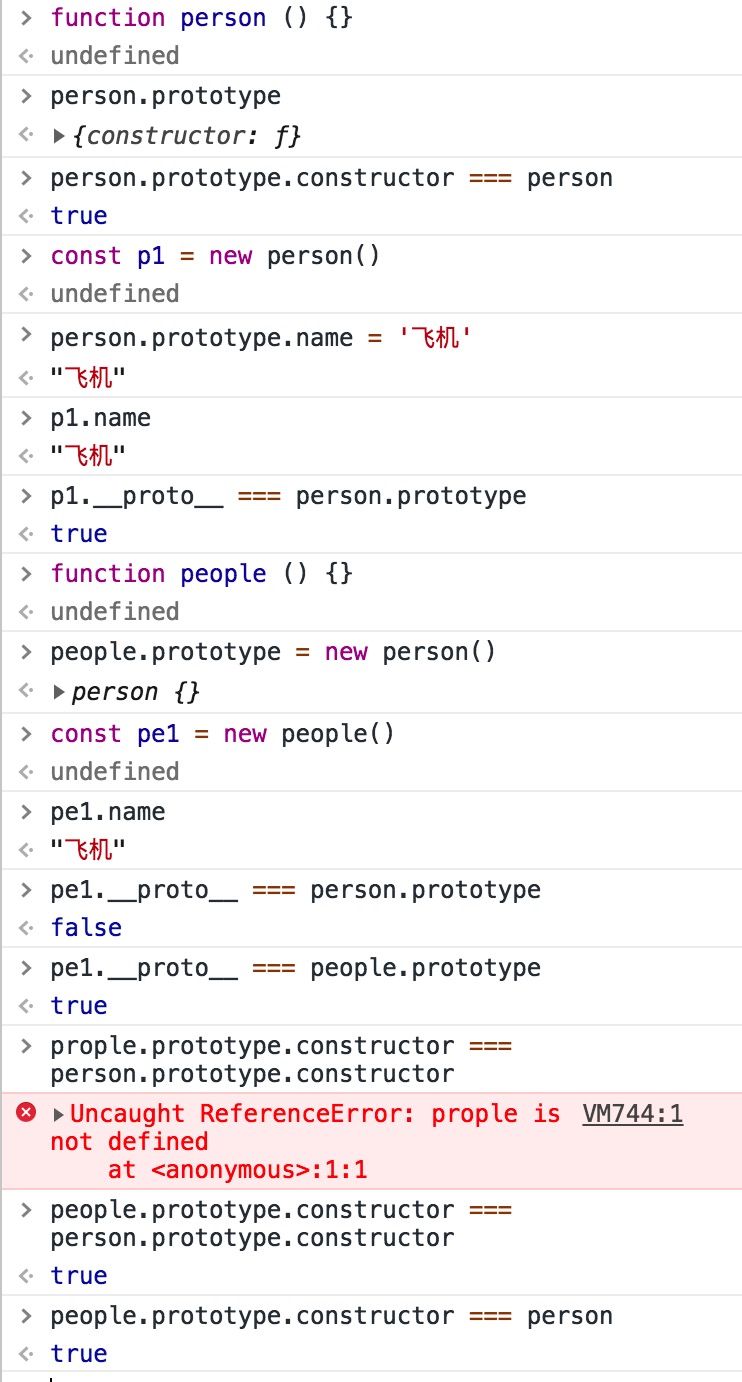
一篇文章让你搞懂原型和原型链
每一个构造函数在被创建的时候,会自动创建一个相应的对象,这个对象就是原型对象,这个函数有一个指向该对象的指针。举个例子: 下面创建了一个函数person。 function person () { } 则 person.prototype 就是原型对象。而原型对象里…
elasticsearch 文档操作
文章目录single API1.添加数据2.更新数据PUTPOST --此方式更零活,可指定修改指定字段2.查询数据简单查询--根据id查询根据查询条件查询 --query string search根据查询条件查询--query DSL1.term/terms 过滤2.range过滤3.exists 和 missing 过滤4.bool过滤5.bool查询…

一起学WP7 XNA游戏开发(八. 让3d model动起来)
如何让3d model动起来,其实就是要给model的bone设置动作,这样整个model就会动起来了。一.获取Bones在fbx文件中可以看到所有bones的名称,这样就可以通过名称来获取到bones。turretBone tankModel.Bones["turret_geo"];…
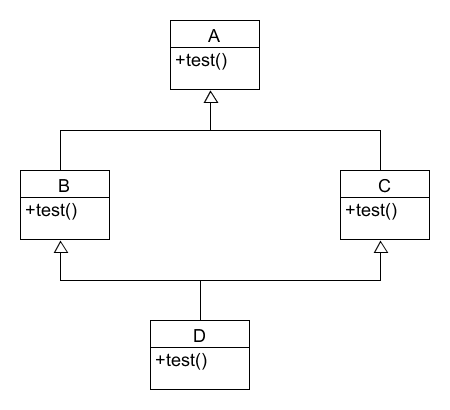
【Python】解析Python中类的使用
目录结构: contents structure [-]类的基本使用专有方法继承单重继承多重继承砖石继承1.类的基本使用 下面是类使用的一个简单案例, class person:"person 类的描述信息"def __init__(self,name"",age0):self.name nameself.age a…

hive中array嵌套map以及行转列的使用
1. 数据源信息 {"student": {"name":"king","age":11,"sex":"M"},"sub_score":[{"subject":"语文","score":80},{"subject":"数学","score&qu…
SpringBoot 操作elasticsearch
SpringBoot 操作elasticsearch 版本环境 jdk1.8elasticsearch 7.6.1 maven <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>注意版本…
替换WCF默认序列化方式
创建类 : using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.ServiceModel.Description; using System.Xml; using System.Runtime.Serialization; namespace Kingge.Mini.Network { public class NetDataContra…
Linux下vi编辑器命令精华版
最近开始使用vi编辑器,用了几天,发现其实还是比较好用的。对自己常用的命令做个总结,以备实时查阅。一下内容是对网络多篇文章的总结。进入vi的命令:vi filename :打开或新建文件,并将光标置于第一行首 vi filename &…
测试用例评审关注点
测试用例评审关注点 1、用例设计是否清晰、合理、简洁; 2、用例是否高效对需求进行覆盖,是否覆盖测试需求上的所有功能点; 3、优先级是否合理; 4、用例是否有很好的可执行性(例如用例的“执行步骤”、“期待结果”是否…
命令行收集(DOS/Linux/nc/xscan/xsniffer)
#1 一: net use \\ip\ipc$ " " /user:" " 建立IPC空链接 net use \\ip\ipc$ "密码" /user:"用户名" 建立IPC非空链接 net use h: \\ip\c$ "密码" /user:"用户名" 直接登陆后映射对方C:到…
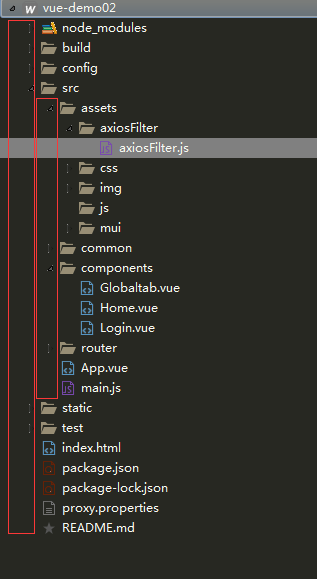
偏前端 - vue-cli(axios请求数据==》token+按接口参数顺序(参数值拼接base64)- MD5)...
token按接口参数顺序(参数值拼接base64)-> MD5) 请教于“喵咪”,再此特别鸣谢!~ 特别强调:import qs from qs; 这个内部方法一定要用哦。参数签名base64md5都成功的情况华。接口还是爆500,就是和这个有关…
Docker 搭建elasticsearch 7.6.x集群
Docker 搭建elasticsearch 7.6.x集群 文章目录拉取镜像设置Elasticsearch挂载目录编写elasticsearch.yml配置文件node-1node-2node-3创建镜像验证是否搭建成功问题max virtual memory areas vm.max_map_count [65530] is too low, increase to at least参考拉取镜像 docker pu…
乐嘉性格色彩分析测试题
乐嘉<性格色彩>分析测试题 说明:最符合你的句子用红色作标记 1. 关于人生观,我的内心其实是: A 希望能够有尽量多的人生体验,所以会有非常多样化的想法。 B在小心合理的基础上,谨慎地确定自己的目标ÿ…
OAuth_1
OAuth2.0是一个应用之间彼此访问数据的开源授权协议。比如,一个游戏应用可以 访问Facebook的用户数据。用户访问web游戏应用,该游戏应用要求用户通过Facebook 登录。用户登录到Facebook,再重定向回游戏应用,游戏应用就可以访问用户…
ubuntu 使用阿里云 apt 源
以下内容来自 https://opsx.alibaba.com/mirror Ubuntu对应的“帮助”信息 修改方式:打开 /et/apt/sources.list将http://archive.ubuntu.com/替换为mirrors.aliyun.com即可 PS:网络上的信息,一定得注意时效性。以下内容,均为此时…
ecos 编译时无法找到 tclConfig.sh 和 tkConfig.sh
这是因为 tcl-devel tk-devel 一般系统中默认是不安装的,至少cent-os 5.5 和fedora 11是这样的,安装这两个包即可。 # yum install tcl-devel tk-devel 补记: ubuntu 10.04.2 上为了便于多个版本的tcl的存在,tcl被安装的位置不太一…

从消息处理角度看应用程序与windows的关系(图示)
转载于:https://blog.51cto.com/gzkhrh/338533
002:用Python设计第一个游戏
笔记 什么是BIF? 答:BIF 即 Built-in Functions,内置函数。为了方便快速编写脚本程序,Python 提供了非常丰富的内置函数,我们只需要直接调用即可,例如 print() 的功能是“打印到屏幕”,input() …
哑谜,回文和暴力之美
暴力搜索是一个有趣的东西。至少刘汝佳是这么认为的。编程之美的4.10节就是典型的暴力题。虽然作者将其难度定义为一颗星,但却不能因此认为这个类型的问题就是那么容易的,很多可能需要一些有创造力的想法。 不妨试试下面这几道题: Island of …

身份证敏感信息处理 图片添加蒙版
实现效果 需要的jar包 <!-- https://mvnrepository.com/artifact/com.jhlabs/filters --><dependency><groupId>com.jhlabs</groupId><artifactId>filters</artifactId><version>2.0.235-1</version></dependency> 调…
Linux bash管道符“|”使用介绍与例子
https://blog.csdn.net/wangqianyilynn/article/details/75576815转载于:https://www.cnblogs.com/dhName/p/10967718.html
PostgreSQL第一步:安装
PostgreSQL是一个自由的对象-关系数据库服务器(数据库管理系统),它在灵活的BSD-风格许可证下发行。它在其他开放源代码数据库系统(比如MySQL和Firebird),和专有系统比如Oracle、Sybase、IBM的DB2和Microsof…
【Henu ACM Round#15 A】 A and B and Chess
【链接】 我是链接,点我呀:) 【题意】 在这里输入题意 【题解】 统计大写和小写的个数。 比较答案。输出即可。 【代码】 #include <bits/stdc.h> using namespace std;string s[10]; map<char,int> dic; int inc[300];int main() {for (int i 0;i < 8;i)cin…
[转载] static class 静态类(Java)
一般情况下是不可以用static修饰类的。如果一定要用static修饰类的话,通常static修饰的是匿名内部类。 在一个类中创建另外一个类,叫做成员内部类。这个成员内部类可以静态的(利用static关键字修饰),也可以是非静态…
tomcat监控-psi-probe使用
什么是psi-probe 这是一款 Tomcat 管理和监控工具,前身是 Lambda Probe。由于 Lambda Probe 2006不再更新,所以 PSI Probe 算是对其的一个 Fork 版本并一直更新至今。 下载 下载地址:https://github.com/psi-probe/psi-probe 百度网盘地址…
配置文件app.config
无论对于客户端程序还是web应用程序,配置文件的作用不言而喻,现总结用法如下: 1. 创建配置节类 必须创建继承自ConfigurationSection的对象才能进行配置数据读写操作,ConfigurationSection提供了索引器用来获取和设置配置数据&…
windows远程桌面如果超出最大连接数, 使用命令行mstsc /console登录即可
远程桌面如果超出最大连接数, 使用命令行mstsc /console登录即可。 (也可以用 mstsc /admin) 可以在运行里使用mstsc /console /v:IP:远程端口即可强制登录; 如果直接在远程桌面连接端使用就直接输入/console /v:IP:远程端口. 如:mstsc /cons…