logistic回归 如何_第七章:利用Python实现Logistic回归分类模型
免责声明:本文是通过网络收集并结合自身学习等途径合法获取,仅作为学习交流使用,其版权归出版社或者原创作者所有,并不对涉及的版权问题负责。若原创作者或者出版社认为侵权,请联系及时联系,我将立即删除文章,十分感谢!
注:来源刘顺祥《从零开始学Python数据分析与挖掘》,版权归原作者或出版社所有,仅供学习使用,不用于商业用途,如有侵权请留言联系删除,感谢合作。
在实际的数据挖掘中,站在预测类问题的角度来看,除了需要预测连续型的因变量,还需要预判离散型的因变量。对于连续型变量的预 测,例如,如何根据产品的市场价格、广告力度、销售渠道等因素预测利润的高低、基于患者的各种身体指标预测其病症的发展趋势、如何根据广告的内容、摆放的位置、图片尺寸的大小、投放时间等因素预测其被单击的概率等,类似这样的问题基本上可以借助于第7章和第8章所介绍的多元线性回归模型、岭回归模型或LASSO回归模型来解决;而对于离散型变量的判别,例如,某件商品在接下来的1个月内是否被销售、根据人体内的某个肿瘤特征,判断其是否为恶性肿瘤、如何依据用户的信用卡信息认定其是否为优质客户等,对于这类问题又该如何解决呢?
本章将介绍另一种回归模型,它与线性回归模型存在着千丝万缕的关系,但与之相比,它属于非线性模型,专门用来解决二分类的离散问题。正如上文所说,商品是否被销售、肿瘤是否为恶性、客户是否具有优质性等都属于二分类问题,而这些问题都可以通过Logistic回归模型解决。
Logistic回归模型目前是最受工业界所青睐的模型之一,例如电商企业利用该模型判断用户是否会选择某种支付方式、金融企业通过该模型将用户划分为不同的信用等级、旅游类企业则运用该模型完成酒店客户的流失概率预测。该模型的一个最大特色,就是相对于其他很多分类算法(如SVM、神经网络、随机森林等)来说,具有很强的可解释性。接下来,将通过本章详细介绍有关Logistic回归模型的来龙去脉,读者将会掌握如下几方面内容:
如何构建Logistic回归模型以及求解参数;
Logistic回归模型的参数解释;
模型效果的评估都有哪些常用方法; 如何基于该模型完成实战项目。
7.1 Logistic模型的构建
正如前文所说,Logistic回归是一种非线性的回归模型,但它又和线性回归模型有关,所以其属于广义的线性回归分析模型。可以借助该模型实现两大用途,一个是寻找“危险”因素,例如,医学界通常使用模型中的优势比寻找影响某种疾病的“坏”因素;另一个用途是判别新样本所属的类别,例如根据手机设备的记录数据判断用户是处于行走状态还是跑步状态。
首先要回答的是,为什么Logistic回归模型与线性回归模型有关, 为了使读者能够理解这个问题的答案,需要结合图7-1来说明。
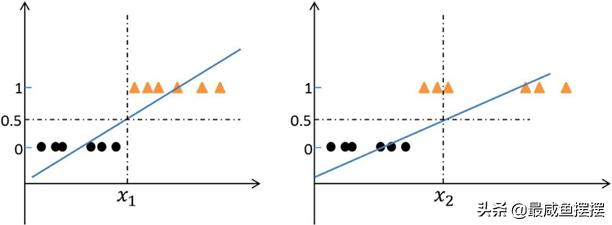
图7-1 类别型因变量与线性拟合线
如图7-1所示,假设x轴表示的是肿瘤体积的大小;y轴表示肿瘤是否为恶性,其中0表示良性,1表示恶性;垂直和水平的虚线均属于参考线,其中水平参考线设置在y=0.5处。很明显,这是一个二分类问题,
如果使用线性回归模型预测肿瘤状态的话,得到的不会是0,1两种值, 而是实数范围内的某个值。如果以0.5作为判别标准,左图呈现的回归模型对肿瘤的划分还是比较合理的,因为当肿瘤体积小于x1时,都能够将良性肿瘤判断出来,反之亦然;再来看右图,当恶性肿瘤在x轴上相对分散时,得到的线性回归模型如图中所示,最终导致的后果就是误判的出现,当肿瘤体积小于x2时,会有两个恶性肿瘤被误判为良性肿瘤。
所以,直接使用线性回归模型对离散型的因变量建模,容易导致错误的结果。按照图7-1的原理,线性回归模型的预测值越大(如果以0.5 作为阈值),则肿瘤被判为恶性的可能性就越大,反之亦然。如果对线性回归模型做某种变换,能够使预测值被“压缩”在0~1之间,那么这个范围就可以理解为恶性肿瘤的概率。所以,预测值越大,转换后的概率值就越接近于1,从而得到肿瘤为恶性的概率也就越大,反之亦然。对Logistic回归模型熟悉的读者一定知道这个变换函数,不错,它就是Logit函数,该函数的表达式为:
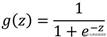
其中,z∈(-∞,+∞)。很明显,当z趋于正无穷大时,e-z将趋于0,进而导致g(z)逼近于1;相反,当z趋于负无穷大时,e-z会趋于正无穷大, 最终导致g(z)逼近于1;当z=0时,e-z=1,所以得到g(z)=0.5,通过如图7-2 所示也能够说明这个结论。
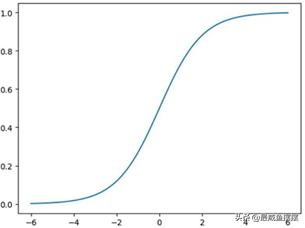
图7-2 Logit函数的可视化
如果将Logit函数中的z参数换成多元线性回归模型的形式,则关于线性回归的Logit函数可以表达为:
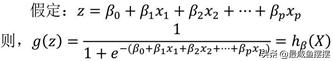
上式中的hβ(X)也被称为Logistic回归模型,它是将线性回归模型的预测值经过非线性的Logit函数转换为[0,1]之间的概率值。假定,在已知X和β的情况下,因变量取1和0的条件概率分别用hβ(X)和1-hβ(X)表示,则这个条件概率可以表示为:
P(y=1|X;β)=hβ(X)=p P(y=0|X;β)=1-hβ(X)=1-p
接下来,可以利用这两个条件概率将Logistic回归模型还原成线性
回归模型,具体推导如下:
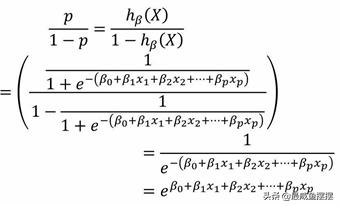
公式中的p/(1-p)通常称为优势(odds)或发生比,代表了某个事件发生与不发生的概率比值,它的范围落在(0, +∞)之间。如果对发生比p/(1-p)取对数,则如上公式可以表示为:
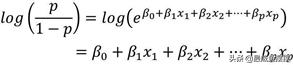
是不是很神奇,完全可以将Logistic回归模型转换为线性回归模型的形式,但问题是,因变量不再是实际的y值,而是与概率相关的对数值。所以,无法使用我们在第7章所介绍的方法求解未知参数β,而是采用极大似然估计法,接下来将重点介绍有关Logistic回归模型的参数求解问题。
7.1.1 Logistic模型的参数求解
重新回顾上一节所介绍的事件发生概率与不发生概率的公式,可以将这两个公式重写为一个公式,具体如下:
P(y|X;β)=hβ(X)y× 1-hβ(X) 1-y
其实如上的概率值就是关于hβ(X)的函数,即事件发生的概率函数。可以简单描述一下这个函数,当某个事件发生时(如因变量y用1表
示),则上式的结果为hβ(X),反之结果为1-hβ(X),正好与两个公式所表示的概率完全一致。
1. 极大似然估计
为了求解公式中的未知参数β,就需要构建一个目标函数,这个函数就是似然函数。似然函数的统计背景是,如果数据集中的每个样本都是互相独立的,则n个样本发生的联合概率就是各样本事件发生的概率乘积,故似然函数可以表示为:
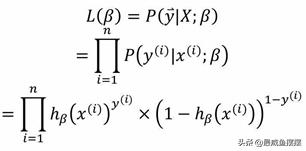
其中,上标i表示第i个样本。接下来要做的就是求解使目标函数达到最大的未知参数β,而上文提到的极大似然估计法就是实现这个目标的方法。为了方便起见,将似然函数L(β)做对数处理:
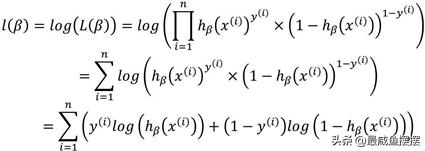
如上公式为对数似然函数,如想得到目标函数的最大值,通常使用的套路是对目标函数求导,进一步令导函数为0,进而可以计算出目标函数中的未知参数。接下来,尝试这个套路,计算目标函数的最优解。
步骤一:知识铺垫
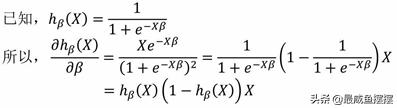
步骤二:目标函数求导
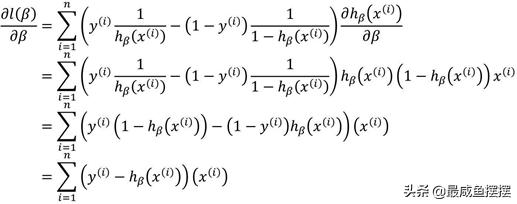
步骤三:令导函数为0
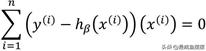
很显然,通过上面的公式无法得到未知参数β的解,因为它不是关于β的多元一次方程组。所以只能使用迭代方法来确定参数β的值,迭代过程会使用到经典的梯度下降算法。
2. 梯度下降
由于对似然函数求的是最大值,因此直接用梯度下降方法不合适, 因为梯度下降专门用于解决最小值问题。为了能够适用梯度下降方法, 需要在目标函数的基础之上乘以-1,即新的目标函数可以表示为:
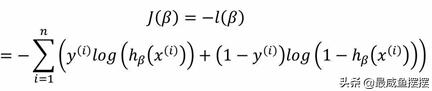
既然无法利用导函数直接求得未知参数β的解,那就结合迭代的方法,对每一个未知参数βj做梯度下降,通过梯度下降法可以得到βj的更新过程,即
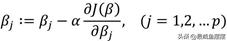
其中,α为学习率,也称为参数βj变化的步长,通常步长可以取0.1,0.05,0.01等。如果设置的α过小,会导致βj变化微小,需要经过多次迭代,收敛速度过慢;但如果设置的α过大,就很难得到理想的βj值, 进而导致目标函数可能是局部最小。
根据前文对目标函数的求导过程,可以沿用至对分量βj的求导,故目标函数对分量βj偏导数可以表示成:
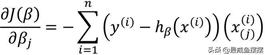
其中,表示第j个变量在第i个样本上的观测值,所以利用梯度下降的迭代过程可以进一步表示为:
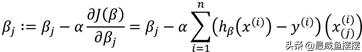
7.1.2 Logistic模型的参数解释
对于线性回归模型而言,参数的解释还是比较容易理解的,例如以产品成本、广告成本和利润构建的多元线性回归模型为例,在其他条件不变的情况下,广告成本每提升一个单位,利润将上升或下降几个单位便是广告成本系数的解释。对于Logistic回归模型来说,似乎就不能这样解释了,因为它是由线性回归模型的Logit变换而来,那应该如何解释Logistic回归模型的参数含义呢?
在上一节曾提过发生比的概念,即某事件发生的概率p与不发生的概率(1-p)之间的比值,它是一个以e为底的指数,并不能直接解释参数β 的含义。发生比的作用只能解释为在同一组中事件发生与不发生的倍 数。例如,对于男性组来说,患癌症的概率是不患癌症的几倍,所以并不能说明性别这个变量对患癌症事件的影响有多大。但是使用发生比 率,就可以解释参数β的含义了,即发生比之比。
假设影响是否患癌的因素有性别和肿瘤两个变量,通过建模可以得到对应的系数β1和β2,则Logistic回归模型可以按照事件发生比的形式改写为:
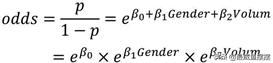
分别以性别变量和肿瘤体积变量为例,解释系数β1和β2的含义。假设性别中男用1表示,女用0表示,则:
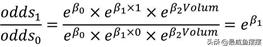
所以,性别变量的发生比率为eβ1,表示男性患癌的发生比约为女性患癌发生比的eβ1倍,这是对离散型自变量系数的解释。如果是连续型的自变量,也是用类似的方法解释参数含义,假设肿瘤体积为Volum0,当肿瘤体积增加1个单位时,体积为Volum0+1,则:
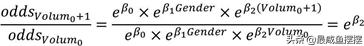
所以,在其他变量不变的情况下,肿瘤体积每增加一个单位,将会使患癌发生比变化eβ2倍,这个倍数是相对于原来的Volum0而言的。
当βk为正数时,ek将大于1,表示xk每增加一个单位时,发生比会相应增加;当βk为负数时,ek将小于1,说明xk每增加一个单位时,发生比会相应减小;当βk为0时,ek将等于1,表明无论xk如何变化,都无法使发生比发生变化。
7.2 分类模型的评估方法
7.1.1节介绍了如何利用梯度下降法求解Logistic回归模型的未知参数β,当模型参数得到后,就可以用来对新样本的预测,但预测效果的好坏该如何评估是一个值得研究的问题。第8章中涉及线性回归模型的评估指标,即RMSE,但它只能用于连续型的因变量评估。对于离散型的因变量有哪些好的评估方法呢?本节的重点就是回答这个问题,介绍有关混淆矩阵、ROC曲线、K-S曲线等评估方法。
7.2.1 混淆矩阵
假设以肿瘤为例,对于实际的数据集会存在两种分类,即良性和恶性。如果基于Logistic回归模型将会预测出样本所属的类别,这样就会得到两列数据,一个是真实的分类序列,另一个是模型预测的分类序 列。所以,可以依据这两个序列得到一个汇总的列联表,该列联表就称为混淆矩阵。这里构建一个肿瘤数据的混淆矩阵,0表示良性(负
例),1表示恶性(正例,一般被理解为研究者所感兴趣或关心的那个分类),见表7-1。

表7-1 混淆矩阵
混淆矩阵中的字母均表示对应组合下的样本量,通过混淆矩阵,有一些重要概念需要加以说明,它们分别是:
A:表示正确预测负例的样本个数,用TN表示。
B:表示预测为负例但实际为正例的个数,用FN表示。C:表示预测为正例但实际为负例的个数,用FP表示。D:表示正确预测正例的样本个数,用TP表示。 A+B:表示预测负例的样本个数,用PN表示。
C+D:表示预测正例的样本个数,用PP表示。A+C:表示实际负例的样本个数,用AN表示。B+D:表示实际正例的样本个数,用AP表示。
准确率:表示正确预测的正负例样本数与所有样本数量的比值, 即(A+D)/(A+B+C+D),该指标用来衡量模型对整体数据的预测效果,用Accuracy表示。
正例覆盖率:表示正确预测的正例数在实际正例数中的比例,即D/(B+D),该指标反映的是模型能够在多大程度上覆盖所关心的类别,用Sensitivity表示。
负例覆盖率:表示正确预测的负例数在实际负例数中的比例,即
A/(A+C),用Specificity表示。
正例命中率:与正例覆盖率比较相似,表示正确预测的正例数在预测正例数中的比例,即D/(C+D),这个指标在做市场营销的时候非常有用,例如对预测的目标人群做活动,实际响应的人数越多,说明模型越能够刻画出关心的类别,用Precision表示。
如果使用混淆矩阵评估模型的好坏,一般会选择准确率指标Accuracy、正例覆盖率指标Sensitivity和负例覆盖率Specificity指标。这三个指标越高,说明模型越理想。
混淆矩阵的构造可以通过Pandas模块中的crosstab函数实现,也可以借助于sklearn子模块metrics中的confusion_matrix函数完成。
7.2.2 ROC曲线
ROC曲线则是通过可视化的方法实现模型好坏的评估,它使用两个指标值进行绘制,其中x轴为1-Specificity,即负例错判率;y轴为Sensitivity,即正例覆盖率。在绘制ROC曲线过程中,会考虑不同的阈值下Sensitivity与1-Specificity之间的组合变化。为了更好地理解ROC曲线的绘制过程,这里虚拟一个数据表格,见表7-2。
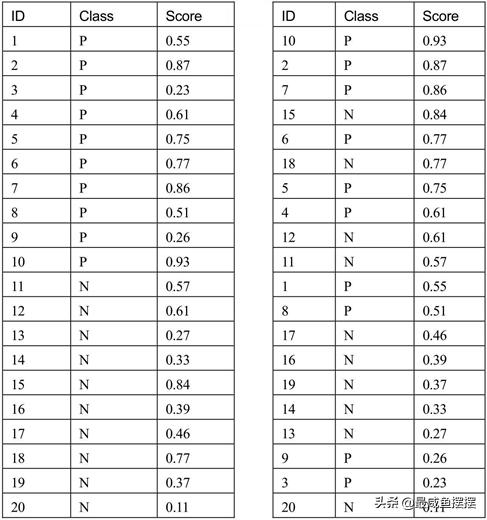
表7-2 模拟绘制ROC曲线的数据
如表7-2所示,ID列表示样本的序号;Class列表示样本实际的分 类,P表示正例,N表示负例;Score列表示模型得分,即通过Logistic模型计算正例的概率值。将原始数据按照Score列降序后得到右表的结
果,对于Logistic模型来说,通常会选择Score为0.5作为判断类别的阈值,若Score大于0.5,则判断样本为正例,否则为负例。但是在对模型做评估时,通常会选择不同的Score,计算对应的Sensitivity和Specificity,进而得到ROC曲线。下面将尝试几个不同的Score值作为演练。
(1) 如果Score大于0.85,则将样本预测为正例,反之样本归属于负例,根据数据所示,实际的10个正例中,满足条件的只有3个样本
(2、7、10号样本),所以得到的正例覆盖率Sensitivity为0.3;实际的10个负例中,得分均小于0.85,说明负例的覆盖率为1,则1-Specificity 为0。最终得到的组合点为(0.85,0.3,0)。
(2) 如果Score大于0.65,则将样本预测为正例,反之样本归属于负例,根据数据所示,实际的10个正例中,满足条件的有5个样本(5、6、2、7、10号样本),所以得到的正例覆盖率Sensitivity为0.5;实际的
10个负例中,有8个样本得分小于0.85(除了15与18号),说明负例的覆盖率为0.8,则1-Specificity为0.2。最终得到的组合点为
(0.65,0.5,0.2)。
(3) 如果Score大于0.5,则将样本预测为正例,反之样本归属于负例,根据数据所示,实际的10个正例中,满足条件的有8个样本(除了 3、9号样本),所以得到的正例覆盖率Sensitivity为0.8;实际的10个负例中,有6个样本(13、14、16、17、19、20)得分小于0.5,说明负例的覆盖率为0.6,则1-Specificity为0.4。最终得到的组合点为
(0.5,0.8,0.4)。
(4) 如果Score大于0.35,则将样本预测为正例,反之样本归属于负例,根据数据所示,实际的10个正例中,满足条件的有8个样本(除了3、9号样本),所以得到的正例覆盖率Sensitivity为0.8;实际的10个负例中,只有3个样本(13、14、20)得分小于0.35,说明负例的覆盖率为0.3,则1-Specificity为0.7。最终得到的组合点为(0.35,0.8,0.7)。
虽然上面的内容比较啰唆,但相信读者一定明白ROC曲线中x轴和y 轴的值是如何得到的了,最终可以利用上面测试的几个Score阈值,得到如图7-3所示的ROC曲线。
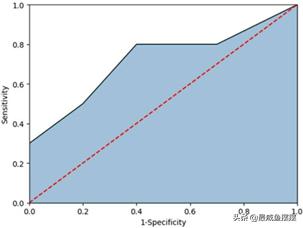
图7-3 ROC曲线的示意图
图7-3中的红色线为参考线,即在不使用模型的情况下,Sensitivity 和1-Specificity之比恒等于1。通常绘制ROC曲线,不仅仅是得到上方的图形,更重要的是计算折线下的面积,即图中的阴影部分,这个面积称为AUC。在做模型评估时,希望AUC的值越大越好,通常情况下,当AUC在0.8以上时,模型就基本可以接受了。
所幸的是,sklearn模块提供了计算Sensitivity和1-Specificity的函数,函数名称为roc_curve,该函数分布于子模块metrics中。
7.2.3 K-S曲线
K-S曲线是另一种评估模型的可视化方法,与ROC曲线的画法非常相似,具体步骤如下:
按照模型计算的Score值,从大到小排序。
取出10%、20%、…、90%所对应的分位数,并以此作为Score的阈值,计算Sensitivity和1-Specificity的值。
将10%、20%、…、90%这样的分位点用作绘图的x轴,将Sensitivity和1-Specificity两个指标值用作绘图的y轴,进而得到两条曲线。
很不幸,Python中并没有直接提供绘制K-S曲线的函数,这里不妨按照上方的步骤,自编绘制K-S曲线的函数,代码如下:

读者可以先跳过这个自定义函数,因为代码中调用了关于Sensitivity和1-Specificity的第三方计算函数,当读者读完本章内容后, 再回到此处,会对自定义函数有更深的理解。为了使读者了解K-S曲线的样子,这里不妨以上面虚拟的数据表为例,绘制对应的K-S曲线:
# 导入虚拟数据virtual_data = pd.read_excel(r'C:甥敳獲AdministratorDeskto # 应用自定义函数绘制k-s曲线plot_ks(y_test = virtual_data.Class, y_score = virtual_data.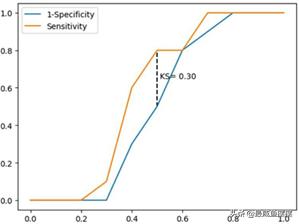
图7-4 K-S曲线的示意图
如图7-4所示,两条折线分别代表各分位点下的正例覆盖率和1-负例覆盖率,通过两条曲线很难对模型的好坏做评估,一般会选用最大的KS值作为衡量指标。KS的计算公式为:KS=Sensitivity-(1- Specificity)= Sensitivity+ Specificity-1。对于KS值而言,也是希望越大越好,通常情况下,当KS值大于0.4时,模型基本可以接受。
7.3 Logistic回归模型的应用
本节的实战部分将使用手机设备搜集的用户运动数据为例,判断用户所处的运动状态,即步行还是跑步。该数据集一共包含88588条记录,6个与运动相关的自变量,其中三个与运动的加速度有关,另三个与运动方向有关。接下来将利用该数据集构建Logistic回归模型,并预测新样本所属的运动状态。
7.3.1 模型的构建
第一步要做的就是运用Python构建Logistic回归模型,读者可以借助于sklearn的子模块linear_model,调用LogisticRegression类,有关该“类”的语法和参数含义如下:
LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1intercept_scaling=1, class_weight=None, 'liblinear',max_iter=100, multi_class='ovr', verbose=0, warm_stapenalty:为Logistic回归模型的目标函数添加正则化惩罚项,与线性回归模型类似,默认为l2正则。
dual:bool类型参数,是否求解对偶形式,默认为False,只有当penalty参数为'l2'、solver参数为'liblinear'时,才可使用对偶形 式。
tol:用于指定模型跌倒收敛的阈值。
C:用于指定惩罚项系数Lambda的倒数,值越小,正则化项越大。
fit_intercept:bool类型参数,是否拟合模型的截距项,默认为True。
intercept_scaling:当solver参数为'liblinear'时该参数有效,主要是为了降低X矩阵中人为设定的常数列1的影响。
class_weight:用于指定因变量类别的权重,如果为字典,则通过字典的形式{class_label:weight}传递每个类别的权重;如果为字符串'balanced',则每个分类的权重与实际样本中的比例成反比, 当各分类存在严重不平衡时,设置为'balanced'会比较好;如果为None,则表示每个分类的权重相等。
random_state:用于指定随机数生成器的种子。
solver:用于指定求解目标函数最优化的算法,默认为'liblinear', 还有其他选项,如牛顿法'newton-cg'、L-BFGS拟牛顿法'lbfgs'。max_iter:指定模型求解过程中的最大迭代次数,默认为100。multi_class:如果因变量不止两个分类,可以通过该参数指定多分类问题的解决办法,默认采用'ovr',即one-vs-rest方法,还可以指定'multinomial',表示直接使用多分类逻辑回归模型(Softmax 分类)。
verbose:bool类型参数,是否输出模型迭代过程的信息,默认为0,表示不输出。
warm_start:bool类型参数,是否基于上一次的训练结果继续训练模型,默认为False,表示每次迭代都是从头开始。
n_jobs:指定模型运算时使用的CPU数量,默认为1,如果为-1, 表示使用所有可用的CPU。
需要说明的是,当fit_intercept设置为True时,相当于在X数据集上人为地添加了常数列1,用于计算模型的截距项;LogisticRegression类不仅仅可以针对二元问题做分类,还可以解决多元问题,通过设置参数multi_class为'multinomial',实现Softmax分类,并利用随机梯度下降法求解参数。下面通过该“类”对手机设备数据建模,代码如下:
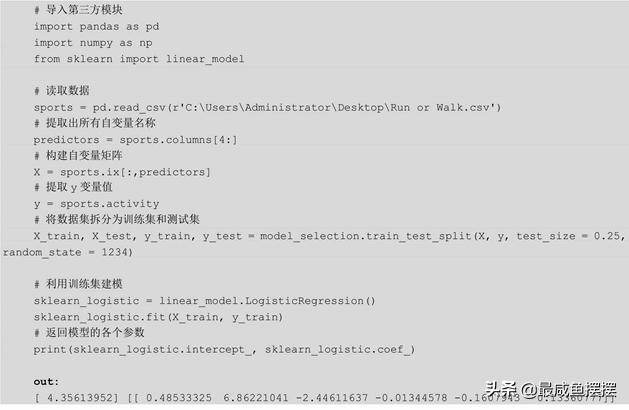
首先简单描述一下上方的代码,当数据读入到Python内存中时,需要将数据集拆分为两部分,分别用于建模和测试,测试的目的就是用于评估模型拟合效果的好坏。最终得到如上所示的回归系数,第一个数值为模型的截距项,后面的6个数值分别为各自变量的系数值,故可以将Logistic回归模型表示为:
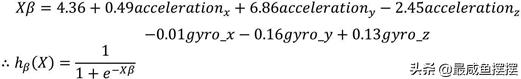
当某些构建好后,需要对模型的回归系数做相应的解释,故将各变量对应的优势比(发生比率)汇总到表7-3中。

表7-3 各系数的优势比
以acceleration_x变量为例,在其他因素不变的情况下,x轴方向的加速度每增加一个单位,会使跑步发生比变化1.62倍。从系数的大小来看,x轴与y轴上的加速度是导致跑步状态的重要因素,z轴上的运动方向是判定跑步状态的重要因素。
7.3.2 模型的预测
基于上方的模型,利用测试集上的X数据,预测因变量y。预测功能的实现需要借助于predict“方法”,代码如下:
# 模型预测sklearn_predict = sklearn_logistic.predict(X_test) # 预测结果统计pd.Series(sklearn_predict).value_counts()out:012121110026如上结果所示,得到测试上因变量的预测统计,其中判断步行状态的样本有12 121个,跑步状态的样本有10 026个。单看这两个数据,无法确定模型预测的是否准确,所以需要对模型预测效果做定量的评估。
7.3.3 模型的评估
在7.2节,我们介绍了分类模型的常用评估方法,如混淆矩阵、ROC曲线和K-S曲线,下面我们尝试利用这三种方法来判断模型的拟合效果,代码如下:

如上结果所示,返回一个2×2的数组,该数组就是简单的混淆矩 阵。矩阵中的行表示实际的运动状态,列表示模型预测的运动状态。进
而基于该矩阵计算模型预测的准确率Accuracy、正例覆盖率Sensitivity和负例覆盖率Specificity,计算过程如下:

如上结果所示,模型的整体预测准确率达到85.24%,而且正确预测到正例在实际正例中占比超过80%,正确预测到的负例在实际负例中更是接近90%,相对而言模型更好地拟合了负例的特征。总体来说,模型的预测准确率还是非常高的。
当然,还可以对混淆矩阵做可视化展现,这就要用到seaborn模块中的heatmap函数了,即绘制热力图:
# 导入第三方模块import seaborn as snsimport matplotlib.pyplot as plt# 绘制热力图sns.heatmap(cm, annot = True, fmt = '.2e',cmap = 'GnBu')# 图形显示plt.show()见图7-5。
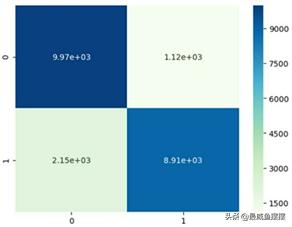
图7-5 混淆矩阵的可视化
如图7-5所示,将混淆矩阵映射到热力图中,颜色越深的区块代表样本量越多。图中非常醒目地展示了主对角线上的区块颜色要比其他地方深很多,说明正确预测正例和负例的样本数目都很大。
接下来使用可视化的方法对模型进行评估,首先绘制最为常见的
ROC曲线,然后将对应的AUC值体现在图中,具体代码如下:

如图7-6所示,绘制的是模型在预测集上的ROC曲线,曲线下的面积高达0.93,远远超过常用的评估标准0.8。所以,可以认定拟合的Logistic回归模型是非常合理的,能够较好地刻画数据特征。需要说明的是,在利用子模块metrics中的roc_curve函数计算不同阈值下Sensitivity和1-Specificity时,函数的第二个参数y_score代表正例的预测概率,而非实际的预测值。
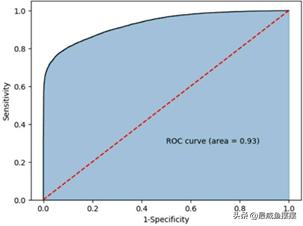
图7-6 ROC曲线
接下来,再利用前文介绍的自定义函数,绘制K-S曲线,进一步论证模型的拟合效果,代码如下:
# 调用自定义函数,绘制K-S曲线plot_ks(y_test = y_test, y_score = y_score, positive_flag =见图7-7。
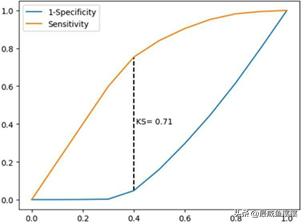
图7-7 K-S曲线
如图7-7所示,绘制了模型对应的K-S曲线,中间的虚线表示,在40%的分位点处,计算得到Sensitivity和1-Specificity之间的最大差为0.71,即KS值。通常,KS值大于0.4时就可以表明模型的拟合效果是不错的,这里得到的结果为0.71,进一步验证了前面混淆矩阵和ROC曲线得出的结论。
到目前为止,基本上进入了本章的尾声阶段,从理论到建模再到模型评估都已经一一跟读者进行了介绍。下面将介绍另一种实现Logistic 回归模型的Python工具,即statsmodels,这里就不详细介绍每一段代码的含义了,读者可以根据代码的注释吸收里面的内容:

针对如上代码,需要说明三点容易犯错的地方:
第一步建模中使用了Logit类,如果直接把自变量X带入到模型,将不会拟合模型的截距项,故需要对X_train和X_test运用add_constant函数,增加常数为1的列。
第二步中,在对模型预测时,返回的并不是具体的某个分类,而是样本被预测为正例的概率值。所以,如需得到具体的样本分 类,还需要对概率值做切分,即大于等于0.5则为正例,否则为负例。
在第四步的绘制K-S曲线中,对预测概率值sm_y_probability做了重索引,主要是因为自定义函数中要求y_test参数值与y_score参数值具有相同的行索引。
7.4 本章小结
本章首次介绍了有关分类数据的预测模型——Logistic回归,并详细讲述了相关的理论知识与应用实战,内容包含模型的构建、参数求解的推导、回归系数的解释、模型的预测以及几种常用的模型评估方法。通过本章内容的学习,读者掌握了有关Logistic回归模型的来龙去脉, 进而可以将该模型应用到实际的工作中。
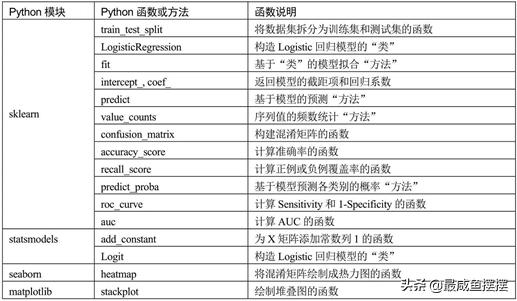
为了使读者掌握有关本章内容所涉及的函数和“方法”,这里将其重新梳理一下,以便读者查阅和记忆。
相关文章:

多年没有管理的技术博客了,即日起开始管理起技术博客
多年没有管理的技术博客了,即日起开始管理起技术博客,希望朋友们一如既往的支持转载于:https://www.cnblogs.com/flashicp/archive/2012/08/14/2639054.html
GNS3的默认Telnet程序改成secureCRT
编辑-首选项-一般里的“终端命令”改为C:\Users\ldy\AppData\Local\VanDyke Software\SecureCRT\SecureCRT.exe /t /telnet %h %p 前面是SecureCRT程序的目录, /t是指建立一个新标签 , /telnet的意思是走Telnet协议, %h是要telnet到的主机&am…

关于Vue实例的生命周期created和mounted的区别
关于作者 程序开发人员,不拘泥于语言与技术,目前主要从事PHP和前端开发,使用Laravel和VueJs,App端使用Apicloud混合式开发。合适和够用是最完美的追求。 个人网站:http://www.linganmin.cn 最近刚写了一个手机在线播放…
UVa 10112 - Myacm Triangles
UVa第一卷最后一题。 求内部不含点并且面积最大的三角形。 暴力。 代码如下: 1 #include<iostream>2 #include<cstdio>3 #include<cmath>4 #include<cstring>5 6 using namespace std;7 8 typedef struct node9 { 10 char ch; 11 i…
[转]ASP.NET1.0升级ASP.NET2.0问题总结
来自:http://www.enet.com.cn/article/2006/0310/A20060310510518.shtml1.Global.asax文件的处理形式不一样,转化后将出现错误 在vs2003中Global.asax具有代码后置文件,2.0下, 将代码分离文件移到 App_Code 目录下,以便…
python文本编码转换_Python: 转换文本编码
最近在做周报的时候,需要把csv文本中的数据提取出来制作表格后生产图表。 在获取csv文本内容的时候,基本上都是用with open(filename, encoding UTF-8) as f:来打开csv文本,但是实际使用过程中发现有些csv文本并不是utf-8格式,从而…
ipone 网页版的iphone
本文摘自:http://www.cocoachina.com/bbs/m/list.php?fid6#list
import static
import static(静态导入)是JDK1.5中的新特性,一般我们导入一个类都用 import com.....ClassName;而静态导入是这样:import static com.....ClassName.*;这里多了个static,还有就是类名ClassName后面多了个 .* …

poj1423
http://acm.pku.edu.cn/JudgeOnline/problem?id1423n!(log10(sqrt(4.0*acos(0.0)*n))n*(log10(n)-log10(exp(1.0)))1);n1 除外 转载于:https://www.cnblogs.com/FCWORLD/archive/2011/03/12/1982355.html
python缩进在程序中长度统一且强制使用_Python习题纠错1
February, 1991 0.9.1 2.Python语言的缩进只要统一即可,不一定是4个空格(尽管这是惯例)。 Python缩进在程序中长度统一且强制使用. 3.IPO:Input Process Output 4.Python合法命名的首字符不能是数字。 5.Python保留字:…
ASP.NET MVC3 在WebGrid中用CheckBox选中行
分三步走 1.保证你的webgrid包含在form中 using (Html.BeginForm("Assign","Home")) { } 2.在webgrid中加一列checkbox grid.Column(header: "Assign?", format: <text><input class"check-box" id"assi…
Delphi中使用IXMLHTTPRequest如何用POST方式提交带参
http://blog.sina.com.cn/s/blog_51a71c010100gbua.html说明:服务器端为JAVA,编码UTF-8,返回数据编码UTF-8;数据交换格式JSON。procedure TloginForm.loginBtnClick(Sender: TObject);var jo: ISuperObject; //JSON接口 req: IX…

Windows图标:有一些你未必知道的东西
有一天,我的程序在任务栏的应用程序中看起来是这样的很奇怪,我的图标明明不是这样的,在资源管理器的文件夹里面,我的图标能够正常显示,在桌面的任务栏里,也能正常的显示,唯独在任务管理器里显示…
几种函数式编程语言
1、函数式编程语言有:lisp,hashshell,erlang等。 2、在函数中的参数,有一一对应的,也有指定模式的,还有使用能数组。如*argp(元组),**argp(字典)。 3、在pyphon语言中有一些内置的函…
python逐个读取文件并处理_逐个读取多个文件并用python进行处理
我在python中使用Pybrain(神经网络库)进行图像处理。我在一个目录中有196个文件,它保存在下面代码中的所有_文件中。我试着打开每个文件并分别对每个文件进行处理,但它将所有文件数据放在一个字符串中,我希望每个文件逐…
HDU 2102 A计划
该题是一道典型的搜索题, #include<stdio.h> #include<stdlib.h> #include<string.h> struct Node {int x, y;int time;int flag; }q[100024]; int d[4][2]{ 0,1,1,0,0,-1,-1,0 }; int N,M; char map[2][13][13]; void getxy( int &X,int &a…
node.js是做什么的?
作者:厂长链接:https://www.zhihu.com/question/33578075/answer/56951771来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。国外有一篇非常好的Node.js 介绍文章,从原理入手讲解&#x…
K8S - Kubernetes简介
Kubernetes Kubernetes(简称K8s,用8代替8个字符“ubernete”)是Google开源的一个容器编排引擎,支持自动化部署、大规模可伸缩、应用容器化管理。 Kubernetes 是目前最为广泛且流行的容器编排调度系统,也是现在用来构建…
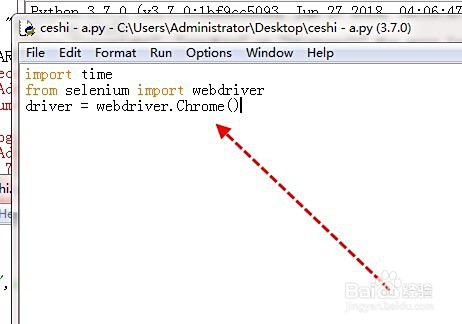
python中filenotfounderror_Python3 报错 FileNotFoundError: [WinError 2]
Python3 报错 FileNotFoundError: [WinError 2]工具/原料 Python3.7 chromedriver 方法/步骤 1 首先,打开py文件,如图,有如下代码。 import time from selenium import webdriver driver webdriver.Chrome()2 然后运行py文件,run…
Push Notifications
push notification 使用: 参考资源: http://tiny4cocoa.com/thread-1406-1-1.html http://bbs.ldci.com.cn/read.php?tid-19971.html http://www.cocoachina.com/bbs/read.php?tid-3770-keyword-apns.html http://code.google.com/p/apns-python-wrapper/ http://…

[原创]Bash中的$*和$@的区别
2019独角兽企业重金招聘Python工程师标准>>> 在Bash脚本中,$*和$都用于表示执行脚本时所传入的参数。先通过一个例子看看他们的区别: #!/bin/bash # testvar.sh echo "-------------ISF is set to \"-seperator\" ------------" IFS…
文本处理工具之grep和egrep
文本处理工具之grep和egrep grep全称global search regular expression (RE) and print out the line正则表达式(一类字符所书写的模式pattern) 元字符:不表示字符本身的意义,用于额外功能性的描述基本正则表达式的元字符 字符匹配…

【转】堆栈和托管堆 c#
原文地址:http://blog.csdn.net/baoxuetianxia/archive/2008/11/04/3218913.aspx首先堆栈和堆(托管堆)都在进程的虚拟内存中。(在32位处理器上每个进程的虚拟内存为4GB) 堆栈stack 堆栈中存储值类型。 堆栈实际上是向…

python特性和属性_Python之属性、特性和修饰符
原博文 2018-03-17 11:08 − 作为面对对象的核心内容,将从以下一个方面进行总结: 1. property和property 2. __getattribute__()、__getattr__()、__setattr__()、__delattr__() 3. 描述符__get__()、__set__()、__delete__()... 相关推荐 2019-09-28 21…
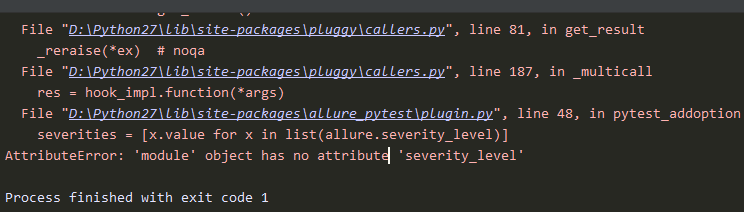
pytest+allure环境别人电脑运行正常,自己运行不正常几种情况
1. AttributeError:module’ object has no attribute severity_level 之前运行都是正常的,想弄allure报告,就使用pip install allure-pytest 命令安装了,其实该命令的作用是会把你当前版本的pytest卸载掉,然后安装 al…

进驻宝岛 不闪式3D热潮来临?
本来说一直要换眼镜的,现在趁年底有空,专门去逛眼镜店。在逛宝岛的时候,发现了专门设立的不闪式3D体验区,供消费者体验。笔者在宝岛眼镜体验了下3D眼镜,觉得非常不错,特别分享下。自从LG Display开始全面进…
BZOJ3782 上学路线 【dp + Lucas + CRT】
题目链接 BZOJ3782 题解 我们把终点也加入障碍点中,将点排序,令\(f[i]\)表示从\((0,0)\)出发,不经过其它障碍,直接到达\((x_i,y_i)\)的方案数 首先我们有个大致的方案数\({x_i y_i \choose x_i}\) 但是中途可能会经过一些其它障碍…
007本周总结报告
这周感觉自己什么也没做,好没有成就感。这周大部分的时间都用来学车了,自己也是东跑西跑的,然而车也没有学好,java也学习的少的可伶。自己总是感觉自己学车都要忙死了。哪有什么时间学习java啊,能学好车就不错了。其实…
python max函数_Python3
max(x, y[, z...]):Number|Sequence 入参类型不能混入(要么全Number(int|float|complex|bool),要么全序列)。 入参是序列的话: 单序列入参,返回序列中最大的一个数值多序列入参, 按索引顺序,逐一…
Linux Mount Windows域用户限制的共享文件夹
sud现在一直使用linux作为主要的办公os,但是最近公司统一使用windows域服务器了,共享就出现比较打的问题了,原因如下:1、linux下通常mount windows共享文件夹Linux下使用smbfs形式访问windows共享文件夹是众所周知的事情ÿ…