python数字类型及运算_Python基础之(基本数据类型及运算)
一、运算
1.1、算数运算

1.2、比较运算:

1.3、赋值运算:

1.4、逻辑运算:

1.5、成员运算:

针对逻辑运算的进一步研究:
1、在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
2、 x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。
3、Python运算符优先级,以下表格列出了从最高到最低优先级的所有运算符:
运算符描述
**
指数 (最高优先级)
~ + -
按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@)
* / % //
乘,除,取模和取整除
+ -
加法减法
>> <<
右移,左移运算符
&
位 'AND'
^ |
位运算符
<= < > >=
比较运算符
<> == !=
等于运算符
= %= /= //= -= += *= **=
赋值运算符
is is not
身份运算符
in not in
成员运算符
not and or
逻辑运算符
二、基本数据类型
2.1、数字,int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
2.2、布尔值(bool)
True、False
1、0
真、假
2.3、字符串(str)
"hello world"
在Python中,加了引号的字符都被认为是字符串
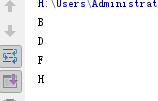
2.3.1、索引:
a = 'ABCDEFGHIJK'
print(a[1])
print(a[3])
print(a[5])
print(a[7])
执行结果:
2.3.2、切片,切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串
a = 'ABCDEFGHIJK'
print(a[1:3])
print(a[0:5])
print(a[0:]) #默认从开始到最后
print(a[0:-1]) # -1 是列表中最后一个元素的索引,但是取不到
print(a[0:5:2]) #加步长
print(a[5:0:-2]) #反向加步长
执行结果:

2.3.3、字符串常用方法:
最常用的为:join(字符串拼接)\spilt(切割)\find(查找)\strip(去空格)\upper、lower(大小写转换)\encode、decode(编码、解码)
a="abcABC"
#公共方法len(a),type(a)
a.capitalize() #首字母大写
a.upper() #转换大写
a.lower() #转换小写
a.swapcase() #大小写转换
a.casefold() #转换小写
a.title() #转换成标题
a.center(20,"*")#设置宽度,并居中,20为总长度,*为空白处填充
a.ljust(20,"*") #左边
a.rjust(20,"*") #右边
a.zfill(20) #默认使用0填充,长度20
a.expandtabs() #补tab键
a.count("xx",star,end) #计数出现次数,star开始位置,end结束位置
a.strip() #去全部空格、换行
a.lstrip("xx") #去除左边 xx
a.lstrip() #去左边空格
a.rstrip() #去右边空格
a.partition("s") #字符串按照第一个s进行分割,分三份 (包含分割元素s)
a.split("s") #a.split("s",2) 按照s进行分割 ,2为分割次数 (不包含分割元素s)
a.splitlens() #按换行符分割
a.find("ex",start=None, end=None) #找到第一个对应字符串的索引,默认是找整体,也可单独指定判断位置 (找不到返回-1)
(a.index()与find相同,但找不到报错 )
a.endswith("x") #以判断x结尾
a.startswith("x",start=None, end=None)#判断以x开头,默认是找整体,也可单独指定判断位置
a.isalnum() #判断字符串中包含数字或字符
a.isalpha()#判断是否是字符
a.isdeciml() #判断是否是数字 (10进制数字)
a.isdigit()#判断是否是数字,支持特殊形式
a.isdentifier() #判断字母、数字、下划线
a.islower()#判断是否小写
a.isupper()#判断是否是大写
a.isnumeric()#判断是否是数字 支持特殊字符(中文)
a.isprintable() #判断是否包含不可显示的字符如:\t \n
a.isspace() #判断是否全部 是空格
a.istitle() #判断是否是标题
a.replace("xx","oo") #xx替换oo
a.join(xxx) #字符串拼接,a作为拼接符,重新拼接xxx (" ".join(xx) "xx".join(dd))
a.format(name="xxxx") #替换name
a.format_map
a.encode() #编码 str转换bytes
a.decode() #解码 获得字符串类型对象
2.4、列表 (list)
列表是python中的基础数据类型之一,列表是有序的,有索引值,可切片,方便取值。其基本操作有:索引、切片、追加、删除、长度、切片、循环、包含
2.4.1、创建列表:
a=["name","age","job","addr"]
2.4.2、增加
li = ["a","b","c"]
li.append("d") #增加到末尾
print(li)
li.insert(0,"aa") #按索引位置增加
print(li)
li.extend(['q,w,e']) #迭代增加
print(li)
li.extend('w')
li.extend('p,l,m')
print(li)
执行结果:

2.4.3、删除
li = ["a","b","c"]
l1 = li.pop(1) #按照位置去删除,有返回值,默认删除最后一个值
print(l1)
print(li)
del li[1:3] #按照位置去删除,也可切片删除没有返回值。
print(li)
li.remove('a') #按照元素去删除
print(li)
执行结果:

2.4.4、改
li = ["a","b","c","d"]
li[1] = 'dfasdfas'
print(li)
li[1:3] = ['b1','c1']
print(li)
执行结果:

2.4.5、查
切片去查,或者循环去查,与str的切片、索引相同
2.4.6 其他补充:
li = []
li.reverse() #将当前列表反转
li.sort() #排序 默认从小到大
li.sort(reverse=True) #从大到小
li.copy() #浅拷贝
li.count(xxx) #计算元素xxx出现的次数
li.index(xx) #根据元素值获取其索引位置
li.clear() #清空列表
2.5、字典 (dict) 无序
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
创建字典:
dict = {"k1":"v1","k2":"v2"}
2.5.1、增加
dic = {"k1":"v1","k2":"v2"}
dic['li'] = ["a","b","c"]
dic.setdefault('k','v') #在字典中添加键值对,如果只有键那对应的值是none,但是如果原字典中存在设置的键值对,则他不会更改或者覆盖。
print(dic)
执行结果:

2.5.2 、删除
dic = {"name":"crazyjump","age":18,"job":"民工"}
dic_pop = dic.pop("a",'无key默认返回值') # pop根据key删除键值对,并返回对应的值,如果没有key则返回默认返回值
print(dic_pop)
print(dic)
del dic["name"] # 没有返回值。
print(dic)
dic_pop1 = dic.popitem() # 随机删除字典中的某个键值对,将删除的键值对以元祖的形式返回
print(dic_pop1)
print(dic)
dic_clear = dic.clear() # 清空字典
print(dic,dic_clear) # {} None
执行结果:

2.5.3、改
dic = {"name":"crazyjump","age":18,"job":"民工"}
dic1 = {"age":20,"k":"v"}
dic.update(dic1) # 将dic1所有的键值对覆盖添加(相同的覆盖,没有的添加)到dic中
print(dic)
执行结果:
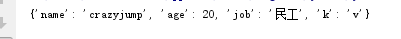
2.5.4、查
dic = {"name":"crazyjump","age":18,"job":"民工"}
value = dic["name"]
print(value)
print(dic.get("n")) #key值不存在返回None
print(dic.get("s",12 )) #值不存在,返回定义的12
dic.setdefault("x","z") #不存在就新增,存在获取当前值
print(dic.setdefault("name","z"))
print(dic)
执行结果:

2.5.5、字典的循环
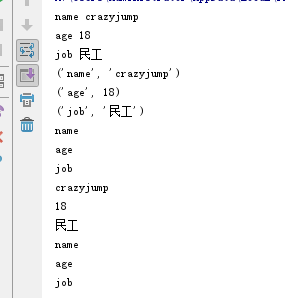
dic = {"name": "crazyjump", "age": 18, "job": "民工"}
for k, v in dic.items():
print(k, v)
for k in dic.items():
print(k)
for k in dic.keys():
print(k)
for v in dic.values():
print(v)
for k in dic:
print(k)
执行结果:
2.5.6、补充(可迭代对象)
dic = {"name":"crazyjump","age":18,"job":"民工"}
l = dic.items()
print(l)
k = dic.keys()
print(k)
v = dic.values()
print(v)
执行结果:

2.6、元组 (tuple)
元组不可被修改,不能被增加或者删除。但可以被查询,字符串的切片操作同样适用于元组
新建元组:
tu=(11,22,33,"aaa")
2.7、集合 (set)
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
去重,把一个列表变成集合,就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系。
2.7.1、创建集合:
set1 = set({1,2,'xxx'})
set2 = {1,2,'xxx'}
2.7.2、增加
set1={"a","b",12,"c"}
set1.add("d") #增加
set1.update('A') #迭代增加
print(set1)
set1.update('哈哈')
print(set1)
set1.update([1,2,3])
print(set1)
执行结果:

2.7.3、删
set1={"a","b",12,"c"}
set1.pop() #删除任意一个
set1.remove(12) #删除指定xx,指定的元素不存在会报错
set1.discard("xx") #删除指定xx ,指定的元素不存在不会报错
print(set1)
set1.clear() #清空集合
print(set1)
执行结果:
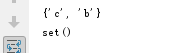
补充:集合查询使用循环即可
2.7.4、集合的其他操作
2.7.4.1、交集 (& 或者 intersection)
set1 = {1,7,8,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2)
print(set1.intersection(set2))
执行结果:

2.7.4.2、并集(| 或者 union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2)
print(set2.union(set1))
执行结果:

2.7.4.3、差集。(- 或者 difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2)
print(set1.difference(set2)) #set独有的
执行结果:

2.7.4.4、反交集。 (^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2)
print(set1.symmetric_difference(set2))
执行结果:

2.7.4.5、子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
2.7.4.6、frozenset不可变集合,让集合变成不可变类型。
s = frozenset('barry')
print(s,type(s)) # frozenset({'a', 'y', 'b', 'r'})
三、数据类型总结
3.1、数字:不可变,直接访问
3.2、字符串:不可变,顺序访问
3.3、列表:可变、有序、顺序访问
3.4、字典:可变、无序、key值访问
3.5、元组:不可变、有序、顺序访问
3.6、布尔值:不可变
3.7、集合:无序、不重复
补充
一、格式化输出:
1.1、%s
name = input('你的姓名:')
age = input('你的年龄:')
job = input('你的工作:')
info = "欢迎 %s,你的年龄是:%s ,你的工作是:%s "%(name,age,job)
print(info)
执行结果:

%s就是代表字符串占位符,除此之外,还有%d是数字占位符,%f是浮点数, 如果把上面的age后面的换成%d,就代表你必须只能输入数字,否则就会报错 (另%3==3%%)
1.2、srt.format()
a = "{},{}".format("hello","world")
# 默认顺序
b = "{1},{0},{1}".format("hello","world")
#指定顺序
c = "{name},{age}".format(name="crazyjump",age=12)
print("a:",a)
print("b:",b)
print("c:",c)
执行结果:

二、for 循环(用户按照顺序循环可迭代对象的内容):
msg = "crazyjump"
for item in msg:
print(item)
data = [1,2,3,4]
for item in msg:
print(iterm)
三、enumrate为可迭代的对象添加序号
li = ['a','b','c','d','e']
for i in enumerate(li):
print(i)
for index,name in enumerate(li,1): #索引默认从0开始,可改成1开始
print(index,name)
执行结果:

四、range 指定范围,生成指定数字。
for i in range(1,10):
print(i)
for i in range(1,10,2): # 步长
print(i)
for i in range(10,1,-2): # 反向步长
print(i)
五、深浅拷贝
5.1、浅拷贝 (id() 对象的内存地址)
li = ["a", "b", ['crazy', 'jump']]
l1 = li.copy()
print(li, id(li))
print(l1, id(l1))
li[1] = "c"
print(l1, id(l1))
print(li, id(li))
li[2][0] = 'DB'
print(l1, id(l1[2]))
print(li, id(li[2]))
执行结果:
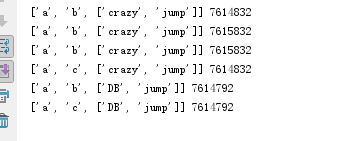
对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
5.2、深拷贝
import copy
l1 = ["a",['crazy','jump']]
l2 = copy.deepcopy(l1)
print(l1,id(l1))
print(l2,id(l2))
l1[0] = 222
print(l1,id(l1))
print(l2,id(l2))
l1[1][0]="db"
print(l1,id(l1[1]))
print(l2,id(l2[1]))
执行结果:
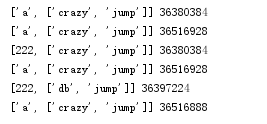
对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变
相关文章:

AJAX跨域访问解决方案
Case I. Web代理的方式 (on Server A) 即用户访问A网站时所产生的对B网站的跨域访问请求均提交到A网站的指定页面,由该页面代替用户页面完成交互,从而返回合适的结果。此方案可以解决现阶段所能够想到的多数跨域访问问题,但要求A网站提供Web…
什么是生成器?
在python中, 要产生一个列表,可以这样写: a[] for i in range(10): a.append(i*2) 但是,这样挺麻烦的,产生一个列表,需要三行语句。所以,有人就想到能不能一行代码来表示呢?其实&a…
一项横断面人群研究中比较放射学阴性的中轴脊柱关节炎患者与强制性脊柱炎患者之间的差别...
原文 译文 Patients with Non-Radiographic Axial Spondyloarthritis Differ From Patients with Ankylosing Spondylitis in Several aspects– Results of a Cross-Sectional Cohort Study Uta Kiltz 1, Xenofon Baraliakos2, Pantelis Karakostas2, Manfred Igelmann…
day12-事务
day12总结[c1] 今日内容 l 事务 l 连接池 事务 事务概述 为了方便演示事务,我们需要创建一个account表: CREATE TABLE account( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(30), balance NUMERIC(10.2) ); INSERT INTO…
ThinkPHP基础概念
OOP 面向对象编程(Object Oriented Programming,OOP,面向对象程序设计)是一种计算机编程架构。OOP 的一条基本原则是计算机程序是由单个能够起到子程序作用的单元或对象组合而成。OOP 达到了软件工程的三个主要目标:重…
008本周总结报告
这周主要做了下PTA的编程题目的练习和学习和了解了java的多线程,了解了进程和线程的定义,区别,联系等,并知道了多线程的利与弊,并了解了JVM下的多运行机制(本质是CPU 对应用程序的快速换)&#…
python3.8.5是python3吗_Python 升级到3.8.5
mac osx 安装最新版本的3.8.5 将/usr/local/bin目录下的python3.8和pip3.8复制一份并修改为python和pip。 修改python的路径,之后source文件。 输出requirements.txt到桌面 安装新版本的第三方库,我使用的第三方库很多,更新很慢。头大啊。 验…
不看后悔 如何删除WIN7的100M隐藏分区
http://notebook.it168.com/a2010/1101/1120/000001120453_2.shtml
tomcat下面web应用发布路径配置 ( 即虚拟目录配置 )
https://blog.csdn.net/AnQ17/article/details/52122236转载于:https://www.cnblogs.com/gangpao/p/9223504.html
strcpy +memcpy实现循环右移
#include<stdio.h>#include<assert.h>#include<string.h>char *strcpy(char*strDest,const char*strSrc){assert(strDest!NULL&&strSrc!NULL);char * addr strDest;while( *strSrc!\0)*strDest *strSrc;*strDest \0;return addr;}//循环移动steps…

python查看目录下的文件_Python——查看目录下所有的目录和文件
原博文 2019-05-06 19:31 − 写程序我们经常会遇到需要遍历某一个目录下的所有文件这个操作,然而python有现成的库,只需要2个循环就可以搞定。 1 import os 2 3 def all_path(dirname): 4 5 result []#所有的文件 6 7 for ma... 相关推荐 2019-12-10 14…
负载均衡策略深入剖析
在实际应用中,我们可能不想仅仅是把客户端的服务请求平均地分配给内部服务器,而不管服务器是否宕机。而是想使Pentium III服务器比Pentium II能接受更多的服务请求,一台处理服务请求较少的服务器能分配到更多的服务请求,出现故障的…
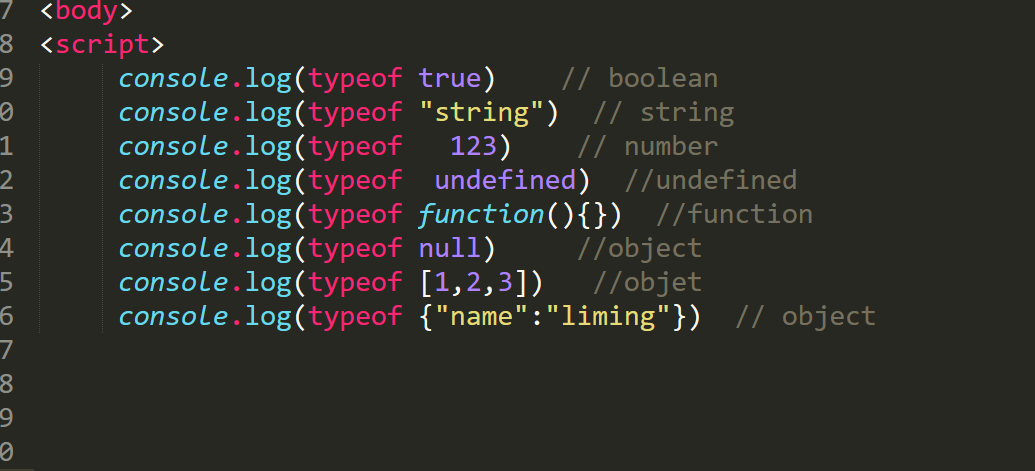
js 验证数据类型的4中方法
1.typeof 可以检验基本数据类型 但是引用数据类型(复杂数据类型)无用; 总结 : typeof 无法识别引用数据类型 包括 bull; 2.instanceof是一个二元运算符,左操作数是一个对象,右操作数是一个构造函数。如…
有关 ecshop 属性 {$goods.goods_attr|nl2br} 标签的赋值问题
1、nl2br() 函数在字符串中的每个新行 (\n) 之前插入 HTML 换行符 (<br />)。 2、 如果要向{$goods.goods_attr|nl2br}赋新值,这个值是保存在数据库中的,用户在商品页(goods.php)选择了商品属性(goods.attr)之后,点击"购买"就…
linux cp 强制覆盖_Linux基本操作教程
Linux基本操作教程点击蓝字关注我们01.Linux系统简介Linux,全称GNU/Linux,是一套免费使用和自由传播的类UNIX操作系统,其内核由林纳斯本纳第克特托瓦兹于1991年第一次释出,它主要受到Minix和Unix思想的启发,是一个基于…
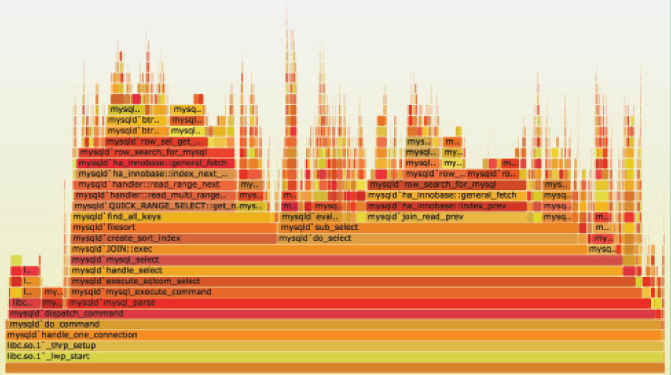
火焰图(Flame Graphs)的安装和基本用法
火焰图(Flame Graphs) 一、概述: 火焰图(flame graph)是性能分析的利器,通过它可以快速定位性能瓶颈点。 perf 命令(performance 的缩写)是 Linux 系统原生提供的性能分析工具&#…
用TCP/IP进行网际互联一
地址解析协议ARP主机知道某个目的主机的IP就可以知道该目的主机的物理地址。改进ARP每个ARP广播分组中都包含有发送方自身的IP和物理地址的绑定,接收方在处理ARP分组时,先在自己的缓存中更新发送方IP到物理地址的绑定信息。ARP是一个隐藏底层网络物理编址…
【learning】矩阵树定理
问题描述 给你一个图(有向无向都ok),求这个图的生成树个数 一些概念 度数矩阵:\(a[i][i]degree[i]\),其他等于\(0\) 入度矩阵:\(a[i][i]in\_degree[i]\),其他等于\(0\) 出度矩阵࿱…
各大知名企业的Research展示
大公司為了要拉開彼此的差距, 除了專注於目前的產品外, 都會為了未來做準備, 而這些研究通常都會做一個 Research 的專區來呈現成果, 如下述列表: Google ResearchYahoo! ResearchThe Facebook ProjectMicrosoft Research - Turning Ideas into Reality微軟亞洲研究院IBM Resea…
解决Eclipse添加新server时无法选择Tomcat7的问题
关闭Eclipse删除WorkSpace目录下/.metadata/.plugins/org.eclipse.core.runtime/.settings目录中的org.eclipse.wst.server.core.prefs和org.eclipse.jst.server.tomcat.core.prefs重启Eclipse转载于:https://www.cnblogs.com/tnsay/p/11466746.html

java 判断object类型_Java学习-方法与多态的学习心得
一 1.什么是方法重写方法的重写或方法的覆盖(overriding)子类根据需求对从父类继承的方法进行重新编写重写时,可以用super.方法的方式来保留父类的方法构造方法不能被重写 2.方法重写规则(1)方法名相同(2)参数列表相同(3)返回值类型相同或者是…
实习日志(2)2011-12-30
这篇文章并没有给出如何使用ResultSet的具体例子,只是从ResultSet的功能性上进行了详细的讲述。希望这篇文章对大家理解ResultSet能够有所帮助。下面就是这篇文章的具体内容。 结果集(ResultSet)是数据中查询结果返回的一种对象,可以说结果集是一个…
Javascript使用三大家族和事件来DIY动画效果相关笔记(一)
1.offset家族◆offsetWidth和offsetHeight表示盒子真实的宽度高度,这个真实的宽度包括 四周的边框、四周的padding、及定义的宽度高度或内容撑开的高度和宽度,可以用来检测盒子实际的大小,属性也是只读不可写的,返回的是不带单位的…
React 学习
一、搭建webpack4.x环境 1.创建工程文件夹(ReactDemo) 2.在工程文件夹下,快速初始化项目 npm init -y // 创建一个package.json文件 3.在工程文件夹下,创建源码文件夹(src)和编译打包文件夹…

python创建mysql数据库_python 怎么创建create mysql的数据库
展开全部 我采用的是MySQLdb操作的MYSQL数据库。先来一个简单的例2113子吧: import MySQLdb try: connMySQLdb.connect(hostlocalhost,userroot,passwdroot,dbtest,port3306) curconn.cursor() cur.execute(select * from user) cur.close() conn.close() except My…
杂谈---改变个人习惯
在提升编码技术的过程,自己也在生活中学到了很多。发现了自己的很多缺陷:不够勇敢、不够冒险、骄傲的无厘头,还有自己对情绪的掌控远没有自己想象的那么有火候,这段时间也得好好谢谢她,要不然我压根意识不到问题有多严…
ldconcig详解
ldconfig是一个动态链接库管理命令,为了让动态链接库为系统所共享,还需运行动态链接库的管理命令--ldconfigldconfig 命令的用途,主要是在默认搜寻目录(/lib和/usr/lib)以及动态库配置文件/etc/ld.so.conf内所列的目录下,搜索出可共享的动态链接库(格式如前介绍,lib…
第3章—高级装配—条件化的Bean
条件化的Bean 通过活动的profile,我们可以获得不同的Bean。Spring 4提供了一个更通用的基于条件的Bean的创建方式,即使用Conditional注解。 Conditional根据满足某个特定的条件创建一个特定的Bean。比如,当某一个jar包在一个类路径下时&#…

c#委托与事件(二)
这篇博客是在上篇的基础开始讲述了一下委托的一些用法,首先我举一个例子说明了一下前面章节的知识点,接下来我说了将方法作为参数传递的一个案例,接下来实现了一个委托实现冒泡排序的方法,如果你们和我一样正在学习,希…
互联网公司java面试题(一)
1、JDK和JRE区别? JDK是整个JAVA的核心,包括了Java运行环境JRE,一堆Java工具和Java基础的类库。通过JDK开发人员将源码文件(java文件)编译成字节码文件(class文 件)。JRE是Java运行环境,不含开发环境,即没有编译器和调…