openlayers map获取全部feature_tf2.0基础-tf.data与tf.feature_column

7.2.1 tf.data
使用 tf.data API 可以轻松处理大量数据、不同的数据格式以及复杂的转换。tf.data API 在 TensorFlow 中引入了两个新的抽象类:
tf.data.Dataset表示一系列元素,其中每个元素包含一个或多个Tensor对象。:- 创建来源(例如
Dataset.from_tensor_slices()),以通过一个或多个tf.Tensor对象构建数据集。 - 应用转换(例如
Dataset.batch()),以通过一个或多个tf.data.Dataset对象构建数据集。 - dataset如果用于tf.estimator, 必须是字典形式的feature, label
- 创建来源(例如
tf.data.Iterator提供了从数据集中提取元素的主要方法。Iterator.get_next()返回的操作会在执行时生成Dataset的下一个元素,并且此操作通常充当输入管道代码和模型之间的接口。
我们建议使用 TensorFlow 的 Dataset API,它可以解析各种数据。概括来讲,Dataset API 包含下列类:
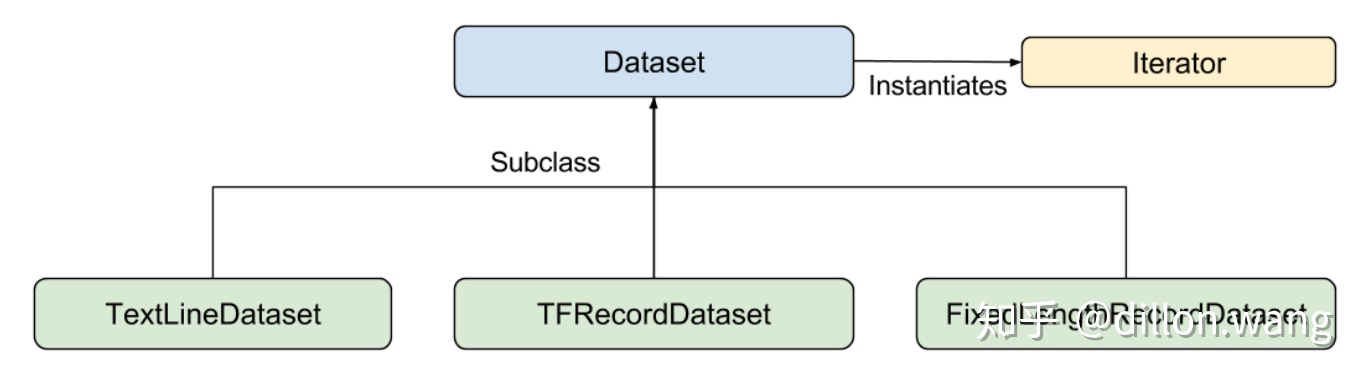
Dataset- 包含创建和转换数据集的方法的基类。您还可以通过该类从内存中的数据或 Python 生成器初始化数据集。TextLineDataset- 从文本文件中读取行。TFRecordDataset- 从 TFRecord 文件中读取记录。FixedLengthRecordDataset- 从二进制文件中读取具有固定大小的记录。Iterator- 提供一次访问一个数据集元素的方法。
1 使用机制
- 1、要启动输入管道,您必须定义来源。例如,要通过内存中的某些张量构建
Dataset,可以使用tf.data.Dataset.from_tensor_slices()。或者,如果输入数据以推荐的 TFRecord 格式存储在磁盘上,那么您可以构建tf.data.TFRecordDataset。 - 2、一旦有了
Dataset对象,可以将其转换为新的Dataset,方法是链接tf.data.Dataset对象上的方法调用。例如,您可以应用单元素转换,例如Dataset.map()(为每个元素应用一个函数),也可以应用多元素转换(例如Dataset.batch())。 - 3、如果需要获取
Dataset中的值。通过此对象,可以一次访问数据集中的一个元素(通过调用Dataset.make_one_shot_iterator()),Iterator.get_next()。
2 tf.data.Dataset.from_tensor_slices获取数据
一个数据集包含多个元素,每个元素的结构都相同。一个元素包含一个或多个 tf.Tensor 对象,这些对象称为组件。可以通过 Dataset.output_types 和 Dataset.output_shapes 属性检查数据集元素各个组件的推理类型和形状。这些属性的嵌套结构映射到元素的结构,此元素可以是单个张量、张量元组,也可以是张量的嵌套元组。例如:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10]))
print(dataset1.output_types)
print(dataset1.output_shapes)dataset2 = tf.data.Dataset.from_tensor_slices((tf.random_uniform([4]),tf.random_uniform([4, 100], maxval=100, dtype=tf.int32)))
print(dataset2.output_types)
print(dataset2.output_shapes)dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
print(dataset3.output_types)
print(dataset3.output_shapes)为元素的每个组件命名通常会带来便利性,例如,如果它们表示训练样本的不同特征。除了元组之外,还可以使用 collections.namedtuple 或将字符串映射到张量的字典来表示 Dataset 的单个元素
dataset = tf.data.Dataset.from_tensor_slices({"a": tf.random_uniform([4]),"b": tf.random_uniform([4, 100], maxval=100, dtype=tf.int32)})
print(dataset.output_types)
print(dataset.output_shapes)3 创建迭代器
构建了表示输入数据的 Dataset 后,下一步就是创建 Iterator 来访问该数据集中的元素。
单次迭代器是最简单的迭代器形式,仅支持对数据集进行一次迭代,不需要显式初始化。单次迭代器可以处理基于队列的现有输入管道支持的几乎所有情况,但它们不支持参数化。以 Dataset.range() 为例:
dataset = tf.data.Dataset.range(100)
iterator = dataset.make_one_shot_iterator()
next_element = iterator.get_next()for i in range(100):value = sess.run(next_element)注:要在input_fn中使用Dataset(input_fn 属于tf.estimator.Estimator),只需返回Dataset即可,框架将负责创建和初始化迭代器。
4 读取输入数据
- 读取现有数组数据
features:Python 字典,其中:- 每个键都是特征的名称。
- 每个值都是包含此特征所有值的数组。
label- 包含每个样本的标签值的数组。
features = {'SepalLength': np.array([6.4, 5.0]),'SepalWidth': np.array([2.8, 2.3]),'PetalLength': np.array([5.6, 3.3]),'PetalWidth': np.array([2.2, 1.0])}labels = np.array([2, 1])在函数中调用
def train_input_fn(features, labels, batch_size):""""""dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))dataset = dataset.shuffle(1000).repeat().batch(batch_size)return datasetdataset.make_one_shot_iterator().get_next()上面的代码段会将 features 和 labels 数组作为 tf.constant() 指令嵌入在 TensorFlow 图中。这样非常适合小型数据集,但会浪费内存,因为会多次复制数组的内容,但是不能达到 tf.GraphDef协议缓冲区的 2GB 上限。
- 读取CSV、文本数据
filenames = ["1.txt", "2.txt"]
dataset = tf.data.TextLineDataset(filenames)默认情况下,TextLineDataset 会生成每个文件的每一行。所以通过长会使用 Dataset.map() 预处理数据
Dataset.map(f) 转换通过将指定函数 f 应用于输入数据集的每个元素来生成新数据集。
4 Dataset的转换(transformations)
当使用Dataset.map(),Dataset.flat_map(),以及Dataset.filter()转换时,它们会对每个element应用一个function
dataset1 = dataset1.map(lambda x: ...)- 读取TFRecord 数据
- TFRecords部分讲解
5 训练的数据集大小指定
tf.data API 提供了两种主要方式来处理同一数据的多个epoch。要迭代数据集多个周期,最简单的方法是使用 Dataset.repeat() 转换。例如,要创建一个将其输入重复 10 个周期的数据集:
dataset = dataset.map(...)
dataset = dataset.repeat(10)
dataset = dataset.batch(32)如果 Dataset.repeat()中没有参数 转换将无限次地重复输入。
- 随机重排输入数据
Dataset.shuffle() 转换会使用算法随机重排输入数据集:它会维持一个固定大小的缓冲区,并从该缓冲区统一地随机选择下一个元素。
dataset = dataset.map(...)
dataset = dataset.shuffle(buffer_size=10000)
dataset = dataset.batch(32)
dataset = dataset.repeat()7.2.2 特征处理tf.feature_colum
特征列
Estimator 的 feature_columns 参数来指定模型的输入。特征列在输入数据(由input_fn返回)与模型之间架起了桥梁。要创建特征列,请调用 tf.feature_column 模块的函数。本文档介绍了该模块中的 9 个函数。如下图所示,除了 bucketized_column 外的函数要么返回一个 Categorical Column 对象,要么返回一个 Dense Column 对象。
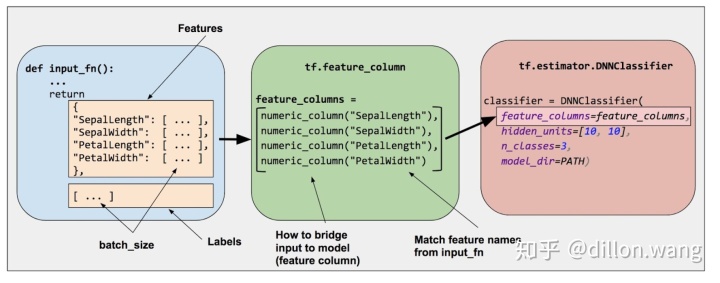
要创建特征列,请调用 tf.feature_column 模块的函数。本文档介绍了该模块中的 9 个函数。如下图所示,除了 bucketized_column 外的函数要么返回一个 Categorical Column 对象,要么返回一个 Dense Column 对象。
1,数值列(tf.feature_column.numeric_column)
2,分桶列(tf.feature_column.bucketized_column)
3,分类标识列(tf.feature_column.categorical_column_with_identity)
4,分类词汇列(tf.feature_column.categorical_column_with_vocabulary_list 或者 tf.feature_column.categorical_column_with_vocabulary_file)
5,经过哈希处理的列(tf.feature_column.categorical_column_with_hash_bucket)
6,组合列(tf.feature_column.crossed_column)
7,指标列(tf.feature_column.indicator_column)
8,嵌入列(tf.feature_column.embedding_column)
- Numeric column(数值列)
Iris 分类器对所有输入特徵调用 tf.feature_column.numeric_column 函数:SepalLength、SepalWidth、PetalLength、PetalWidth
tf.feature_column 有许多可选参数。如果不指定可选参数,将默认指定该特征列的数值类型为 tf.float32。
numeric_feature_column = tf.feature_column.numeric_column(key="SepalLength")- Bucketized column(分桶列)
通常,我们不直接将一个数值直接传给模型,而是根据数值范围将其值分为不同的 categories。上述功能可以通过 tf.feature_column.bucketized_column 实现。以表示房屋建造年份的原始数据为例。我们并非以标量数值列表示年份,而是将年份分成下列四个分桶:
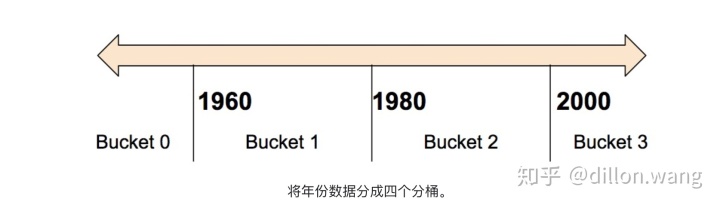
模型将按以下方式表示这些分桶:
日期范围表示为…< 1960 年[1, 0, 0, 0]>= 1960 年但 < 1980 年[0, 1, 0, 0]>= 1980 年但 < 2000 年[0, 0, 1, 0]>= 2000 年[0, 0, 0, 1]
# 首先,将原始输入转换为一个numeric column
numeric_feature_column = tf.feature_column.numeric_column("Year")# 然后,按照边界[1960,1980,2000]将numeric column进行bucket
bucketized_feature_column = tf.feature_column.bucketized_column(source_column = numeric_feature_column,boundaries = [1960, 1980, 2000])- Categorical identity column(类别标识列)
输入的列数据就是为固定的离散值,假设您想要表示整数范围 [0, 4)。在这种情况下,分类标识映射如下所示:
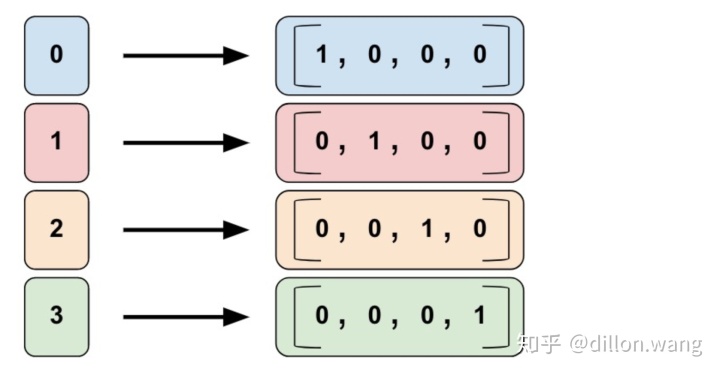
identity_feature_column = tf.feature_column.categorical_column_with_identity(key='my_feature_b',num_buckets=4) # Values [0, 4)- Categorical vocabulary column(类别词汇表)
我们不能直接向模型中输入字符串。我们必须首先将字符串映射为数值或类别值。Categorical vocabulary column 可以将字符串表示为one_hot格式的向量。
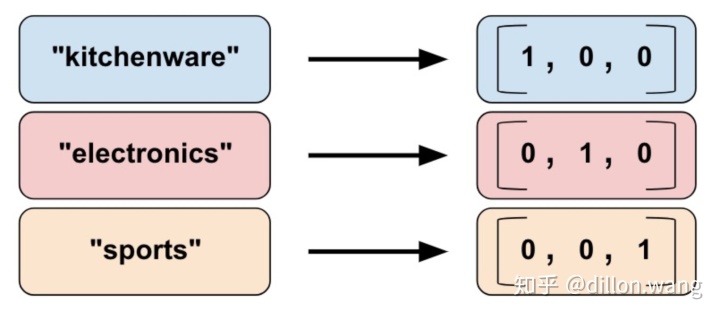
vocabulary_feature_column =tf.feature_column.categorical_column_with_vocabulary_list(key=feature_name_from_input_fn,vocabulary_list=["kitchenware", "electronics", "sports"])- Hashed Column(哈希列)
处理的示例都包含很少的类别。但当类别的数量特别大时,我们不可能为每个词汇或整数设置单独的类别,因为这将会消耗非常大的内存。对于此类情况,我们可以反问自己:“我愿意为我的输入设置多少类别?
hashed_feature_column =tf.feature_column.categorical_column_with_hash_bucket(key = "some_feature",hash_bucket_size = 100) # The number of categories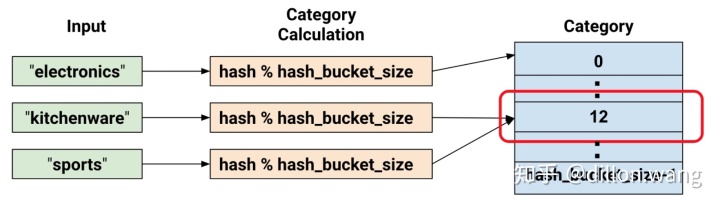
- 其它列处理
- Crossed column(组合列),深度排序算法进行讲解
此外,推荐一个高速油管,1080P无压力:注册 - 柚子云
相关文章:

项目活动定义 概述
项目活动定义概述 项目活动定义是确认和描述项目的特定活动,它把项目的组成要素加以细分为可管理的更小部分,以便更好地管理和控制。 确定计划活动需要确定和记载计划完成的工作。活动定义过程识别处于工作分解结构(WBS)最下层,叫…
如何判断CPU、内存、磁盘的性能瓶颈?
1.如何判断CPU、内存、磁盘的瓶颈? CPU瓶颈 1) 查看CPU利用率。建议CPU指标如下 a) User Time:65%~70% b) System Time:30%~35% c) Idle:0%~5% 如果us,sy高于这个指标可以判断CPU有瓶颈 使用top…
一个苹果手机移动电源也能让他拽得跟二五八万似的
一个苹果手机移动电源也能让他拽得跟二五八万似的~~低调一定是美德,尤其是在见过各种JP人类之后,我真心在心里呐喊,你丫稍微低调一点会死啊!!!是的,这个世界上不可能不存在拽得调子高的人&#…

Confluence 6 配置服务器基础地址
服务器基础地址(Server Base URL)是用户访问 Confluence 的 URL 地址。这个基础的 URL 地址必须与你在浏览器中访问 Confluence 中的地址。 Confluence 将会在安装的时候自动侦测基础的 URL,但是如果你的站点 URL 修改了,或者你的…

python gui编程框架添加工具栏_python gui编程,我是初学者。用tk,制作下拉菜单的command不分我想打开另一个界面。如和解决,求解!!...
展开全部 from tkinter import * def new_file(): print("Open new file") def open_file(): print("Open existing file") def stub_action(): print("Menu select") def makeCommandMenu(): CmdBtn Menubutton(mBar, textButton Commands, un…
这样在一个sql里完成更新和插入,只用一次数据库连接,效率提高了
代码如下,请给出具体修改代码 public void AddCategory(string nCategoryName, int nImgId, int nBelongToId, int nShopId, int nSortId) { int CategoryId 0; string cmdText "Select top 1 CategoryId from ProductCategory where Categ…
USACO Section 1.5 Checker Challenge
经典八皇后问题 只写的最基本的,对称剪枝,位运算都没有用,以后有时间再看 1 /* ID:linyvxi1 2 PROB:checker 3 LANG:C 4 */ 5 #include <stdio.h> 6 #include <stdlib.h> 7 #include <string.h> 8 int N; 9 int tota…
使用JavaScript实现在页面上所有内容加载完之前一直显示loading...页面
Html 1 <body class"is-loading">2 <div class"curtain">3 <div class"loader">4 loading...5 </div>6 </div> 7 <div>8 <!--这里 正文 -->9 </div> 10 </body> …
SpringCloud + Consul服务注册中心 + gateway网关
1 启动Consul 2 创建springcloud-consul项目及三个子模块 2.1 数据模块consul-producer 2.2 数据消费模块consul-consumer 2.3 gateway网关模块 3 测试及项目下载 1、首先安装Consul并启动Consul,端口号为8500 2、创建一个maven项目springcloud-consul࿰…
MySql按日期进行统计(前一天、本周、某一天)[转载]
转自:http://www.yovisun.me/mysql-date-statistics.html 在mysql数据库中,常常会遇到统计当天的内容。例如,在user表中,日期字段为:log_time 统计当天 sql语句为: select * from user where date(log_time…
右键新建里面没有word和excel_Windows10系统下如何将Sublime Text3添加到右键快捷菜单?...
由于本人用的Sublime Text是汉化绿色版的,不仅仅是因为绿色版免去了安装步骤 解压即用,还因为里面整合了常用的高效率必备插件,但是发现右键竟然没有用Sublime Text打开的快捷菜单,这对于我使用Sublime Text 打开一些代码文档会有…

NOI2011 道路修建
题目连接:http://221.192.240.123:8586/JudgeOnline/showproblem?problem_id1670 题意自便。 相关知识:树的遍历,非递归DFS写法。 分析:因为树的边给定,所以从哪个点开始求都是一样的。递归求出每个点的的子树个数&am…

Wiener Filter
假设分别有两个WSS process:$x[n]$,$y[n]$,这两个process之间存在某种关系,并且我们也了解这种关系。现在我们手头上有process $x[n]$,目的是要设计一个LTI系统,使得系统输出$y[n]$,不过$y[n]$是…

c++ string replace_JAVA应用程序开发之String类常用API
【本文详细介绍了JAVA应用开发中的String类常用API,欢迎读者朋友们阅读、转发和收藏!】1 基本概念API ( Application Interface 应用程序接口)是类中提供的接口,类库是类的集合。在 Java 语言中可以通过 import 关键字导入相关的类࿰…
强大的Charles的使用,强大的flutter1.9
<a href"http://www.cocoachina.com/articles/37551?filterios"> 强大的Charles强大的flutter转载于:https://www.cnblogs.com/henusyj-1314/p/11586350.html
多层次架构设计前言
因为 php 原生来就是要辅助 HTML 的产生,所以程式码跟 HTML 码混在一起写,正是 PHP 的特点也是优点,但正也造成很多分工上的问题,也就是你在写 php 的同时,你也必须很了解 前端、后端技能,像是 DataBase, H…
在java的程序里date类型比较大小
Date a; Date b; 假设现在你已经实例化了a和b a.after(b)返回一个boolean,如果a的时间在b之后(不包括等于)返回trueb.before(a)返回一个boolean,如果b的时间在a之前(不包括等于)返回truea.equals(b)返回一个…

linux安装ActiveMQ
1. 下载: # wget https://archive.apache.org/dist/activemq/5.14.0/apache-activemq-5.14.0-bin.tar.gz 2. 解压: # tar zxvf apache-activemq-5.14.0-bin.tar.gz -C ../ 3. 配置环境变量: # vim /etc/profile 4. 启动: # active…
用递归来判断输入的字符串是否是回文
设计思路:导入Scanner类输入字符串,再将输入的字符串转化为字符数组,然后从字符串左右两侧依次比较字符chu是否相同,若相同递归返回读取的字符个数,若返回字符的个数输入字符串的长度,则输出该字符串是回文…
js高级程序设计之跨浏览器事件处理
//事件 var EventUtil { //添加事件 addHandler:function (element, type, handler) { //element:DOM对象,type:事件类型,handler:事件函数 if (element.addEventListener) { //是否存在DOM2级方法 element.addEventListener(type, handler, false); } else if (element.attac…
在python中使用关键字define定义函数_python自定义函数def的应用详解
这里是三岁,来和大家唠唠自定义函数,这一个神奇的东西,带大家白话玩转自定义函数 自定义函数,编程里面的精髓! def 自定义函数的必要函数:def 使用方法:def 函数名(参数1,参数2&…

在Win7 + VMware7下安装Xcode 4
我的Mac OS X是在Win7下虚拟机上安装的,我先把xcode_4.0.2_and_ios_sdk_4.3.dmg下载到Win7下某个目录下,然后共享该目录,然后启动Mac OS X,开始安装:1. 找到Win7下xcode_4.0.2_and_ios_sdk_4.3.dmg所在的共享文件夹&am…
plsql误删除数据,提交事务后如何找回?
select *from tbs_rep_template as of timestamp to_timestamp(2018-07-12 14:23:00, yyyy-mm-dd hh24:mi:ss)where tplname like %工业管道定期检验报告%;--其中2018-07-12 14:23:00为:误删数据的大致时刻的提前时间转载于:https://www.cnblogs.com/demon09/p/9300756.html

配置flutter For IOS
https://www.cnblogs.com/lovestarfish/p/10628205.html第一步,下载flutter最新版,解压到自己的目录里: 提供网址:https://flutter.io/setup-macos/ 第二步,终端配置环境,这里我配知道了IOS,安…

Unity3D 镜面反射
原创文章如需转载请注明:转载自 脱莫柔Unity3D学习之旅 QQ群:【119706192】 本文链接地址: Unity3D 镜面反射 这是官方CharacterCustomization事例中的镜面反射shader。 1.首先需要一个plane当镜子,将代码MirrorReflection.cs文件绑定到镜子…
python后端学什么框架_献给正在学习python的你, 10个最受欢迎的Python开源框架
很多小伙伴在学习wen的时候说,有没有几个常用的框架,好多小伙伴都只说对了其中几个,只有少部分是说正确的,想要了解更多,欢迎大家订阅微信公众号:Python从程序猿到程序员,或者加4913.08659&…
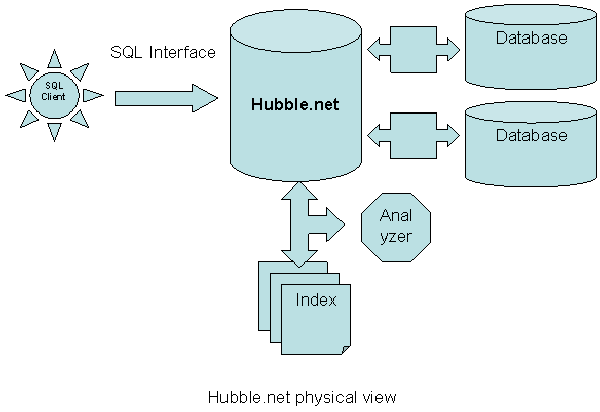
HubbleDotNet 简介 (转)
系统简介 HubbleDotNet 是一个基于.net framework 的开源免费的全文搜索数据库组件。开源协议是 Apache 2.0。HubbleDotNet提供了基于SQL的全文检索接口,使用者只需会操作SQL,就可以很快学会使用HubbleDotNet进行全文检索。 HubbleDotNet可以实现全文索引…
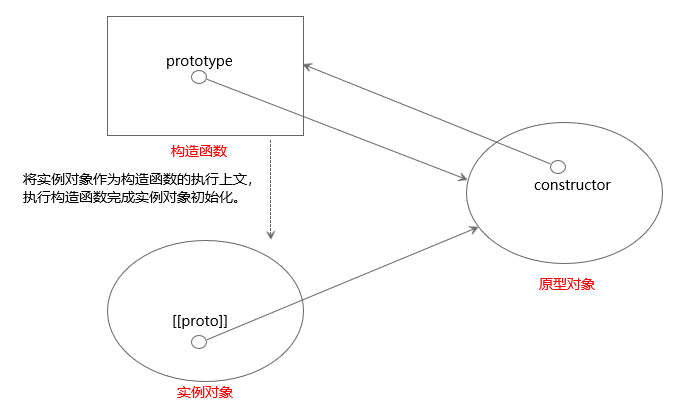
JavaScript夯实基础系列(四):原型
在JavaScript中有六种数据类型:number、string、boolean、null、undefined以及对象,ES6加入了一种新的数据类型symbol。其中对象称为引用类型,其他数据类型称为基础类型。在面向对象编程的语言中,对象一般是由类实例化出来的&…
python中意外缩进是什么意思_Python 的缩进是不是反人类的设计?
前些天,我写了《Python为什么使用缩进来划分代码块?》,文中详细梳理了 Python 采用缩进语法的 8 大原因。我极其喜欢这种简洁优雅的风格,所以对它赞美有加。 然而文章发出去后,非常意外,竟收到了大量的反对…
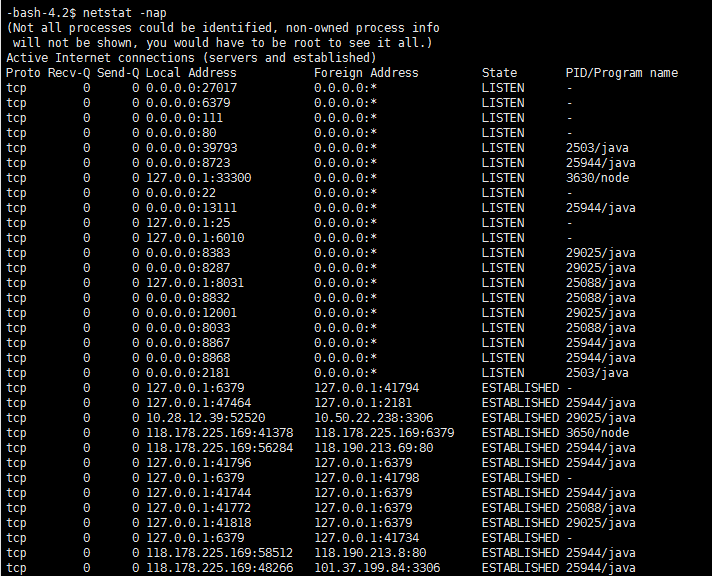
netstat命令
使用netstat -nap可以查看当前发送和接收队列,Send-Q 很高时表示发送队列太长,可能网络阻塞 转载于:https://www.cnblogs.com/wx170119/p/11606909.html