mysql中的%_mysql入门
MySQL
数据库
1 数据库概念(了解)
1.1 什么是数据库
数据库就是用来存储和管理数据的仓库!
数据库存储数据的优先:
可存储大量数据;
方便检索;
保持数据的一致性、完整性;
安全,可共享;
通过组合分析,可产生新数据。
1.2 数据库的发展历程
没有数据库,使用磁盘文件存储数据;
层次结构模型数据库;
网状结构模型数据库;
关系结构模型数据库:使用二维表格来存储数据;
关系-对象模型数据库;
MySQL就是关系型数据库!
1.3 常见数据库
Oracle(神喻):甲骨文(最高!);
DB2:IBM;
SQL Server:微软;
Sybase:赛尔斯;
MySQL:甲骨文;
1.4 理解数据库
RDBMS = 管理员(manager)+仓库(database)
database = N个table
table:
表结构:定义表的列名和列类型!
表记录:一行一行的记录!
我们现在所说的数据库泛指“关系型数据库管理系统(RDBMS - Relational database management system)”,即“数据库服务器”。
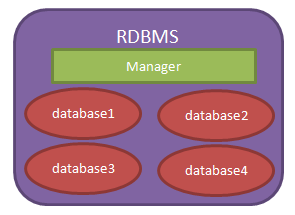
当我们安装了数据库服务器后,就可以在数据库服务器中创建数据库,每个数据库中还可以包含多张表。

数据库表就是一个多行多列的表格。在创建表时,需要指定表的列数,以及列名称,列类型等信息。而不用指定表格的行数,行数是没有上限的。下面是tab_student表的结构:

当把表格创建好了之后,就可以向表格中添加数据了。向表格添加数据是以行为单位的!下面是s_student表的记录:
s_id s_name s_age s_sex
S_1001 zhangSan 23 male
S_1002 liSi 32 female
S_1003 wangWu 44 male
大家要学会区分什么是表结构,什么是表记录。
1.5 应用程序与数据库
应用程序使用数据库完成对数据的存储!

2 安装MySQL数据库
2.1 安装MySQL
参考:MySQL安装图解.doc
2.2 MySQL目录结构
MySQL的数据存储目录为data,data目录通常在C:\Documents and Settings\All Users\Application Data\MySQL\MySQL Server 5.1\data位置。在data下的每个目录都代表一个数据库。
MySQL的安装目录下:
bin目录中都是可执行文件;
my.ini文件是MySQL的配置文件;
3 基本命令
3.1 启动和关闭mysql服务器
启动:net start mysql;
关闭:net stop mysql;
在启动mysql服务后,打开windows任务管理器,会有一个名为mysqld.exe的进程运行,所以mysqld.exe才是MySQL服务器程序。
3.2 客户端登录退出mysql
在启动MySQL服务器后,我们需要使用管理员用户登录MySQL服务器,然后来对服务器进行操作。登录MySQL需要使用MySQL的客户端程序:mysql.exe
登录:mysql -u root -p 123 -h localhost;
-u:后面的root是用户名,这里使用的是超级管理员root;
-p:后面的123是密码,这是在安装MySQL时就已经指定的密码;
-h:后面给出的localhost是服务器主机名,它是可以省略的,例如:mysql -u root -p 123;
退出:quit或exit;
在登录成功后,打开windows任务管理器,会有一个名为mysql.exe的进程运行,所以mysql.exe是客户端程序。
SQL语句
SQL概述
1.1 什么是SQL
SQL(Structured Query Language)是“结构化查询语言”,它是对关系型数据库的操作语言。它可以应用到所有关系型数据库中,例如:MySQL、Oracle、SQL Server等。SQ标准(ANSI/ISO)有:
SQL-92:1992年发布的SQL语言标准;
SQL:1999:1999年发布的SQL语言标签;
SQL:2003:2003年发布的SQL语言标签;
这些标准就与JDK的版本一样,在新的版本中总要有一些语法的变化。不同时期的数据库对不同标准做了实现。
虽然SQL可以用在所有关系型数据库中,但很多数据库还都有标准之后的一些语法,我们可以称之为“方言”。例如MySQL中的LIMIT语句就是MySQL独有的方言,其它数据库都不支持!当然,Oracle或SQL Server都有自己的方言。
1.2 语法要求
SQL语句可以单行或多行书写,以分号结尾;
可以用空格和缩进来来增强语句的可读性;
关键字不区别大小写,建议使用大写;
2 分类
DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;
DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据);
DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
DQL(Data Query Language):数据查询语言,用来查询记录(数据)。
3 DDL
3.1 基本操作
查看所有数据库名称:SHOW DATABASES;
切换数据库:USE mydb1,切换到mydb1数据库;
3.2 操作数据库
创建数据库:CREATE DATABASE [IF NOT EXISTS] mydb1;
创建数据库,例如:CREATE DATABASE mydb1,创建一个名为mydb1的数据库。如果这个数据已经存在,那么会报错。例如CREATE DATABASE IF NOT EXISTS mydb1,在名为mydb1的数据库不存在时创建该库,这样可以避免报错。
删除数据库:DROP DATABASE [IF EXISTS] mydb1;
删除数据库,例如:DROP DATABASE mydb1,删除名为mydb1的数据库。如果这个数据库不存在,那么会报错。DROP DATABASE IF EXISTS mydb1,就算mydb1不存在,也不会的报错。
修改数据库编码:ALTER DATABASE mydb1 CHARACTER SET utf8
修改数据库mydb1的编码为utf8。注意,在MySQL中所有的UTF-8编码都不能使用中间的“-”,即UTF-8要书写为UTF8。
3.3 数据类型
MySQL与Java一样,也有数据类型。MySQL中数据类型主要应用在列上。
常用类型:
int:整型
double:浮点型,例如double(5,2)表示最多5位,其中必须有2位小数,即最大值为999.99;
decimal:泛型型,在表单钱方面使用该类型,因为不会出现精度缺失问题;
char:固定长度字符串类型;
varchar:可变长度字符串类型;
text:字符串类型;
blob:字节类型;
date:日期类型,格式为:yyyy-MM-dd;
time:时间类型,格式为:hh:mm:ss
timestamp:时间戳类型;
3.4 操作表
创建表:
CREATE TABLE 表名(
列名 列类型,
列名 列类型,
......
);
例如:
CREATE TABLE stu(
sid CHAR(6),
sname VARCHAR(20),
age INT,
gender VARCHAR(10)
);
再例如:
CREATE TABLE emp(
eid CHAR(6),
ename VARCHAR(50),
age INT,
gender VARCHAR(6),
birthday DATE,
hiredate DATE,
salary DECIMAL(7,2),
resume VARCHAR(1000)
);
查看当前数据库中所有表名称:SHOW TABLES;
查看指定表的创建语句:SHOW CREATE TABLE emp,查看emp表的创建语句;
查看表结构:DESC emp,查看emp表结构;
删除表:DROP TABLE emp,删除emp表;
修改表:
修改之添加列:给stu表添加classname列:
ALTER TABLE stu ADD (classname varchar(100));
修改之修改列类型:修改stu表的gender列类型为CHAR(2):
ALTER TABLE stu MODIFY gender CHAR(2);
修改之修改列名:修改stu表的gender列名为sex:
ALTER TABLE stu change gender sex CHAR(2);
修改之删除列:删除stu表的classname列:
ALTER TABLE stu DROP classname;
修改之修改表名称:修改stu表名称为student:
ALTER TABLE stu RENAME TO student;
4 DML
4.1 插入数据
语法:
INSERT INTO 表名(列名1,列名2, …) VALUES(值1, 值2)
INSERT INTO stu(sid, sname,age,gender) VALUES('s_1001', 'zhangSan', 23, 'male');
INSERT INTO stu(sid, sname) VALUES('s_1001', 'zhangSan');
语法:
INSERT INTO 表名 VALUES(值1,值2,…)
因为没有指定要插入的列,表示按创建表时列的顺序插入所有列的值:
INSERT INTO stu VALUES('s_1002', 'liSi', 32, 'female');
注意:所有字符串数据必须使用单引用!
4.2 修改数据
语法:
UPDATE 表名 SET 列名1=值1, … 列名n=值n [WHERE 条件]
UPDATE stu SET sname=’zhangSanSan’, age=’32’, gender=’female’ WHERE sid=’s_1001’;
UPDATE stu SET sname=’liSi’, age=’20’ WHERE age>50 AND gender=’male’;
UPDATE stu SET sname=’wangWu’, age=’30’ WHERE age>60 OR gender=’female’;
UPDATE stu SET gender=’female’ WHERE gender IS NULL
UPDATE stu SET age=age+1 WHERE sname=’zhaoLiu’;
4.3 删除数据
语法:
DELETE FROM 表名 [WHERE 条件]
DELETE FROM stu WHERE sid=’s_1001’003B
DELETE FROM stu WHERE sname=’chenQi’ OR age > 30;
DELETE FROM stu;
语法:
TRUNCATE TABLE 表名
TRUNCATE TABLE stu;
虽然TRUNCATE和DELETE都可以删除表的所有记录,但有原理不同。DELETE的效率没有TRUNCATE高!
TRUNCATE其实属性DDL语句,因为它是先DROP TABLE,再CREATE TABLE。而且TRUNCATE删除的记录是无法回滚的,但DELETE删除的记录是可以回滚的(回滚是事务的知识!)。
5 DCL
5.1 创建用户
语法:
CREATE USER 用户名@地址 IDENTIFIED BY '密码';
CREATE USER user1@localhost IDENTIFIED BY ‘123’;
CREATE USER user2@’%’ IDENTIFIED BY ‘123’;
5.2 给用户授权
语法:
GRANT 权限1, … , 权限n ON 数据库.* TO 用户名
GRANT CREATE,ALTER,DROP,INSERT,UPDATE,DELETE,SELECT ON mydb1.* TO user1@localhost;
GRANT ALL ON mydb1.* TO user2@localhost;
5.3 撤销授权
语法:
REVOKE权限1, … , 权限n ON 数据库.* FORM 用户名
REVOKE CREATE,ALTER,DROP ON mydb1.* FROM user1@localhost;
5.4 查看用户权限
语法:
SHOW GRANTS FOR 用户名
SHOW GRANTS FOR user1@localhost;
5.5 删除用户
语法:
DROP USER 用户名
DROP USER user1@localhost;
5.6 修改用户密码
语法:
USE mysql;
UPDATE USER SET PASSWORD=PASSWORD(‘密码’) WHERE User=’用户名’ and Host=’IP’;
FLUSH PRIVILEGES;
UPDATE USER SET PASSWORD=PASSWORD('1234') WHERE User='user2' and Host=’localhost’;
FLUSH PRIVILEGES;
数据查询语法(DQL)
DQL就是数据查询语言,数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。
语法:
SELECT selection_list /*要查询的列名称*/
FROM table_list /*要查询的表名称*/
WHERE condition /*行条件*/
GROUP BY grouping_columns /*对结果分组*/
HAVING condition /*分组后的行条件*/
ORDER BY sorting_columns /*对结果分组*/
LIMIT offset_start, row_count /*结果限定*/
创建名:
学生表:stu
字段名称 字段类型 说明
sid char(6) 学生学号
sname varchar(50) 学生姓名
age int 学生年龄
gender varchar(50) 学生性别
CREATE TABLE stu (
sid CHAR(6),
sname VARCHAR(50),
age INT,
gender VARCHAR(50)
);
INSERT INTO stu VALUES('S_1001', 'liuYi', 35, 'male');
INSERT INTO stu VALUES('S_1002', 'chenEr', 15, 'female');
INSERT INTO stu VALUES('S_1003', 'zhangSan', 95, 'male');
INSERT INTO stu VALUES('S_1004', 'liSi', 65, 'female');
INSERT INTO stu VALUES('S_1005', 'wangWu', 55, 'male');
INSERT INTO stu VALUES('S_1006', 'zhaoLiu', 75, 'female');
INSERT INTO stu VALUES('S_1007', 'sunQi', 25, 'male');
INSERT INTO stu VALUES('S_1008', 'zhouBa', 45, 'female');
INSERT INTO stu VALUES('S_1009', 'wuJiu', 85, 'male');
INSERT INTO stu VALUES('S_1010', 'zhengShi', 5, 'female');
INSERT INTO stu VALUES('S_1011', 'xxx', NULL, NULL);
雇员表:emp
字段名称 字段类型 说明
empno int 员工编号
ename varchar(50)员工姓名
job varchar(50)员工工作
mgr int 领导编号
hiredate date 入职日期
sal decimal(7,2)月薪
comm decimal(7,2)奖金
deptno int 部分编号
CREATE TABLE emp(
empno INT,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
comm decimal(7,2),
deptno INT
) ;
INSERT INTO emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp values(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp values(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp values(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp values(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp values(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp values(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp values(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp values(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
部分表:dept
字段名称 字段类型 说明
deptno int 部分编码
dname varchar(50)部分名称
loc varchar(50)部分所在地点
CREATE TABLE dept(
deptno INT,
dname varchar(14),
loc varchar(13)
);
INSERT INTO dept values(10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO dept values(20, 'RESEARCH', 'DALLAS');
INSERT INTO dept values(30, 'SALES', 'CHICAGO');
INSERT INTO dept values(40, 'OPERATIONS', 'BOSTON');
1 基础查询
1.1 查询所有列
SELECT * FROM stu;
1.2 查询指定列
SELECT sid, sname, age FROM stu;
2 条件查询
2.1 条件查询介绍
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
=、!=、<>、、>=;
BETWEEN…AND;
IN(set);
IS NULL;
AND;
OR;
NOT;
2.2 查询性别为女,并且年龄50的记录
SELECT * FROM stu
WHERE gender='female' AND ge<50;
2.3 查询学号为S_1001,或者姓名为liSi的记录
SELECT * FROM stu
WHERE sid ='S_1001' OR sname='liSi';
2.4 查询学号为S_1001,S_1002,S_1003的记录
SELECT * FROM stu
WHERE sid IN ('S_1001','S_1002','S_1003');
2.5 查询学号不是S_1001,S_1002,S_1003的记录
SELECT * FROM tab_student
WHERE s_number NOT IN ('S_1001','S_1002','S_1003');
2.6 查询年龄为null的记录
SELECT * FROM stu
WHERE age IS NULL;
2.7 查询年龄在20到40之间的学生记录
SELECT *
FROM stu
WHERE age>=20 AND age<=40;
或者
SELECT *
FROM stu
WHERE age BETWEEN 20 AND 40;
2.8 查询性别非男的学生记录
SELECT *
FROM stu
WHERE gender!='male';
或者
SELECT *
FROM stu
WHERE gender<>'male';
或者
SELECT *
FROM stu
WHERE NOT gender='male';
2.9 查询姓名不为null的学生记录
SELECT *
FROM stu
WHERE NOT sname IS NULL;
或者
SELECT *
FROM stu
WHERE sname IS NOT NULL;
3 模糊查询
当想查询姓名中包含a字母的学生时就需要使用模糊查询了。模糊查询需要使用关键字LIKE。
3.1 查询姓名由5个字母构成的学生记录
SELECT *
FROM stu
WHERE sname LIKE '_____';
模糊查询必须使用LIKE关键字。其中 “_”匹配任意一个字母,5个“_”表示5个任意字母。
3.2 查询姓名由5个字母构成,并且第5个字母为“i”的学生记录
SELECT *
FROM stu
WHERE sname LIKE '____i';
3.3 查询姓名以“z”开头的学生记录
SELECT *
FROM stu
WHERE sname LIKE 'z%';
其中“%”匹配0~n个任何字母。
3.4 查询姓名中第2个字母为“i”的学生记录
SELECT *
FROM stu
WHERE sname LIKE '_i%';
3.5 查询姓名中包含“a”字母的学生记录
SELECT *
FROM stu
WHERE sname LIKE '%a%';
4 字段控制查询
4.1 去除重复记录
去除重复记录(两行或两行以上记录中系列的上的数据都相同),例如emp表中sal字段就存在相同的记录。当只查询emp表的sal字段时,那么会出现重复记录,那么想去除重复记录,需要使用DISTINCT:
SELECT DISTINCT sal FROM emp;
4.2 查看雇员的月薪与佣金之和
因为sal和comm两列的类型都是数值类型,所以可以做加运算。如果sal或comm中有一个字段不是数值类型,那么会出错。
SELECT *,sal+comm FROM emp;
comm列有很多记录的值为NULL,因为任何东西与NULL相加结果还是NULL,所以结算结果可能会出现NULL。下面使用了把NULL转换成数值0的函数IFNULL:
SELECT *,sal+IFNULL(comm,0) FROM emp;
4.3 给列名添加别名
在上面查询中出现列名为sal+IFNULL(comm,0),这很不美观,现在我们给这一列给出一个别名,为total:
SELECT *, sal+IFNULL(comm,0) AS total FROM emp;
给列起别名时,是可以省略AS关键字的:
SELECT *,sal+IFNULL(comm,0) total FROM emp;
5 排序
5.1 查询所有学生记录,按年龄升序排序
SELECT *
FROM stu
ORDER BY sage ASC;
或者
SELECT *
FROM stu
ORDER BY sage;
5.2 查询所有学生记录,按年龄降序排序
SELECT *
FROM stu
ORDER BY age DESC;
5.3 查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序
SELECT * FROM emp
ORDER BY sal DESC,empno ASC;
6 聚合函数
聚合函数是用来做纵向运算的函数:
COUNT():统计指定列不为NULL的记录行数;
MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
6.1 COUNT
当需要纵向统计时可以使用COUNT()。
查询emp表中记录数:
SELECT COUNT(*) AS cnt FROM emp;
查询emp表中有佣金的人数:
SELECT COUNT(comm) cnt FROM emp;
注意,因为count()函数中给出的是comm列,那么只统计comm列非NULL的行数。
查询emp表中月薪大于2500的人数:
SELECT COUNT(*) FROM emp
WHERE sal > 2500;
统计月薪与佣金之和大于2500元的人数:
SELECT COUNT(*) AS cnt FROM emp WHERE sal+IFNULL(comm,0) > 2500;
查询有佣金的人数,以及有领导的人数:
SELECT COUNT(comm), COUNT(mgr) FROM emp;
6.2 SUM和AVG
当需要纵向求和时使用sum()函数。
查询所有雇员月薪和:
SELECT SUM(sal) FROM emp;
查询所有雇员月薪和,以及所有雇员佣金和:
SELECT SUM(sal), SUM(comm) FROM emp;
查询所有雇员月薪+佣金和:
SELECT SUM(sal+IFNULL(comm,0)) FROM emp;
统计所有员工平均工资:
SELECT SUM(sal), COUNT(sal) FROM emp;
或者
SELECT AVG(sal) FROM emp;
6.3 MAX和MIN
查询最高工资和最低工资:
SELECT MAX(sal), MIN(sal) FROM emp;
7 分组查询
当需要分组查询时需要使用GROUP BY子句,例如查询每个部门的工资和,这说明要使用部分来分组。
7.1 分组查询
查询每个部门的部门编号和每个部门的工资和:
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno;
查询每个部门的部门编号以及每个部门的人数:
SELECT deptno,COUNT(*)
FROM emp
GROUP BY deptno;
查询每个部门的部门编号以及每个部门工资大于1500的人数:
SELECT deptno,COUNT(*)
FROM emp
WHERE sal>1500
GROUP BY deptno;
7.2 HAVING子句
查询工资总和大于9000的部门编号以及工资和:
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno
HAVING SUM(sal) > 9000;
注意,WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
8 LIMIT
LIMIT用来限定查询结果的起始行,以及总行数。
8.1 查询5行记录,起始行从0开始
SELECT * FROM emp LIMIT 0, 5;
注意,起始行从0开始,即第一行开始!
8.2 查询10行记录,起始行从3开始
SELECT * FROM emp LIMIT 3, 10;
8.3 分页查询
如果一页记录为10条,希望查看第3页记录应该怎么查呢?
第一页记录起始行为0,一共查询10行;
第二页记录起始行为10,一共查询10行;
第三页记录起始行为20,一共查询10行;
完整性约束
完整性约束是为了表的数据的正确性!如果数据不正确,那么一开始就不能添加到表中。
1 主键
当某一列添加了主键约束后,那么这一列的数据就不能重复出现。这样每行记录中其主键列的值就是这一行的唯一标识。例如学生的学号可以用来做唯一标识,而学生的姓名是不能做唯一标识的,因为学习有可能同名。
主键列的值不能为NULL,也不能重复!
指定主键约束使用PRIMARY KEY关键字
创建表:定义列时指定主键:
CREATE TABLE stu(
sid CHAR(6) PRIMARY KEY,
sname VARCHAR(20),
age INT,
gender VARCHAR(10)
);
创建表:定义列之后独立指定主键:
CREATE TABLE stu(
sid CHAR(6),
sname VARCHAR(20),
age INT,
gender VARCHAR(10),
PRIMARY KEY(sid)
);
修改表时指定主键:
ALTER TABLE stu
ADD PRIMARY KEY(sid);
删除主键(只是删除主键约束,而不会删除主键列):
ALTER TABLE stu DROP PRIMARY KEY;
2 主键自增长
MySQL提供了主键自动增长的功能!这样用户就不用再为是否有主键是否重复而烦恼了。当主键设置为自动增长后,在没有给出主键值时,主键的值会自动生成,而且是最大主键值+1,也就不会出现重复主键的可能了。
创建表时设置主键自增长(主键必须是整型才可以自增长):
CREATE TABLE stu(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(20),
age INT,
gender VARCHAR(10)
);
修改表时设置主键自增长:
ALTER TABLE stu CHANGE sid sid INT AUTO_INCREMENT;
修改表时删除主键自增长:
ALTER TABLE stu CHANGE sid sid INT;
3 非空
指定非空约束的列不能没有值,也就是说在插入记录时,对添加了非空约束的列一定要给值;在修改记录时,不能把非空列的值设置为NULL。
指定非空约束:
CREATE TABLE stu(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(10) NOT NULL,
age INT,
gender VARCHAR(10)
);
当为sname字段指定为非空后,在向stu表中插入记录时,必须给sname字段指定值,否则会报错:
INSERT INTO stu(sid) VALUES(1);
插入的记录中sname没有指定值,所以会报错!
4 唯一
还可以为字段指定唯一约束!当为字段指定唯一约束后,那么字段的值必须是唯一的。这一点与主键相似!例如给stu表的sname字段指定唯一约束:
CREATE TABLE tab_ab(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(10) UNIQUE
);
INSERT INTO sname(sid, sname) VALUES(1001, 'zs');
INSERT INTO sname(sid, sname) VALUES(1002, 'zs');
当两次插入相同的名字时,MySQL会报错!
5 外键
主外键是构成表与表关联的唯一途径!
外键是另一张表的主键!例如员工表与部门表之间就存在关联关系,其中员工表中的部门编号字段就是外键,是相对部门表的外键。
我们再来看BBS系统中:用户表(t_user)、分类表(t_section)、帖子表(t_topic)三者之间的关系。

例如在t_section表中sid为1的记录说明有一个分类叫java,版主是t_user表中uid为1的用户,即zs!
例如在t_topic表中tid为2的记录是名字为“Java是咖啡”的帖子,它是java版块的帖子,它的作者是ww。
外键就是用来约束这一列的值必须是另一张表的主键值!!!
创建t_user表,指定uid为主键列:
CREATE TABLE t_user(
uid INT PRIMARY KEY AUTO_INCREMENT,
uname VARCHAR(20) UNIQUE NOT NULL
);
创建t_section表,指定sid为主键列,u_id为相对t_user表的uid列的外键:
CREATE TABLE t_section(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(30),
u_id INT,
CONSTRAINT fk_t_user FOREIGN KEY(u_id) REFERENCES t_user(uid)
);
修改t_section表,指定u_id为相对t_user表的uid列的外键:
ALTER TABLE t_section
ADD CONSTRAINT fk_t_user
FOREIGN KEY(u_id)
REFERENCES t_user(uid);
修改t_section表,删除u_id的外键约束:
ALTER TABLE t_section
DROP FOREIGN KEY fk_t_user;
6 表与表之间的关系
一对一:例如t_person表和t_card表,即人和身份证。这种情况需要找出主从关系,即谁是主表,谁是从表。人可以没有身份证,但身份证必须要有人才行,所以人是主表,而身份证是从表。设计从表可以有两种方案:
在t_card表中添加外键列(相对t_user表),并且给外键添加唯一约束;
给t_card表的主键添加外键约束(相对t_user表),即t_card表的主键也是外键。
一对多(多对一):最为常见的就是一对多!一对多和多对一,这是从哪个角度去看得出来的。t_user和t_section的关系,从t_user来看就是一对多,而从t_section的角度来看就是多对一!这种情况都是在多方创建外键!
多对多:例如t_stu和t_teacher表,即一个学生可以有多个老师,而一个老师也可以有多个学生。这种情况通常需要创建中间表来处理多对多关系。例如再创建一张表t_stu_tea表,给出两个外键,一个相对t_stu表的外键,另一个相对t_teacher表的外键。
编码
1 查看MySQL编码
SHOW VARIABLES LIKE 'char%';

因为当初安装时指定了字符集为UTF8,所以所有的编码都是UTF8。
character_set_client:你发送的数据必须与client指定的编码一致!!!服务器会使用该编码来解读客户端发送过来的数据;
character_set_connection:通过该编码与client一致!该编码不会导致乱码!当执行的是查询语句时,客户端发送过来的数据会先转换成connection指定的编码。但只要客户端发送过来的数据与client指定的编码一致,那么转换就不会出现问题;
character_set_database:数据库默认编码,在创建数据库时,如果没有指定编码,那么默认使用database编码;
character_set_server:MySQL服务器默认编码;
character_set_results:响应的编码,即查询结果返回给客户端的编码。这说明客户端必须使用result指定的编码来解码;
2 控制台编码
修改character_set_client、character_set_results、character_set_connection为GBK,就不会出现乱码了。但其实只需要修改character_set_client和character_set_results。
控制台的编码只能是GBK,而不能修改为UTF8,这就出现一个问题。客户端发送的数据是GBK,而character_set_client为UTF8,这就说明客户端数据到了服务器端后一定会出现乱码。既然不能修改控制台的编码,那么只能修改character_set_client为GBK了。
服务器发送给客户端的数据编码为character_set_result,它如果是UTF8,那么控制台使用GBK解码也一定会出现乱码。因为无法修改控制台编码,所以只能把character_set_result修改为GBK。
修改character_set_client变量:set character_set_client=gbk;
修改character_set_results变量:set character_set_results=gbk;
设置编码只对当前连接有效,这说明每次登录MySQL提示符后都要去修改这两个编码,但可以通过修改配置文件来处理这一问题:配置文件路径:D:\Program Files\MySQL\MySQL Server 5.1\ my.ini
3 MySQL工具
使用MySQL工具是不会出现乱码的,因为它们会每次连接时都修改character_set_client、character_set_results、character_set_connection的编码。这样对my.ini上的配置覆盖了,也就不会出现乱码了。

编码
1. 查看MySQL数据库编码
* SHOW VARIABLES LIKE 'char%';
2. 编码解释
* character_set_client:MySQL使用该编码来解读客户端发送过来的数据,例如该编码为UTF8,那么如果客户端发送过来的数据不是UTF8,那么就会出现乱码
* character_set_results:MySQL会把数据转换成该编码后,再发送给客户端,例如该编码为UTF8,那么如果客户端不使用UTF8来解读,那么就会出现乱码
其它编码只要支持中文即可,也就是说不能使用latin1
3. 控制台乱码问题
* 插入或修改时出现乱码:
> 这时因为cmd下默认使用GBK,而character_set_client不是GBK的原因。我们只需让这两个编码相同即可。
> 因为修改cmd的编码不方便,所以我们去设置character_set_client为GBK即可。
* 查询出的数据为乱码:
> 这是因为character_set_results不是GBK,而cmd默认使用GBK的原因。我们只需让这两个编码相同即可。
> 因为修改cmd的编码不方便,所以我们去设置character_set_results为GBK即可。
* 设置变量的语句:
> set character_set_client=gbk;
> set character_set_results=gbk;
注意,设置变量只对当前连接有效,当退出窗口后,再次登录mysql,还需要再次设置变量。
为了一劳永逸,可以在my.ini中设置:
设置default-character-set=gbk即可。
4. 指定默认编码
我们在安装MySQL时已经指定了默认编码为UTF8,所以我们在创建数据库、创建表时,都无需再次指定编码。
为了一劳永逸,可以在my.ini中设置:
设置character-set-server=utf8即可。
MySQL数据库备份与还原
备份和恢复数据
1 生成SQL脚本
在控制台使用mysqldump命令可以用来生成指定数据库的脚本文本,但要注意,脚本文本中只包含数据库的内容,而不会存在创建数据库的语句!所以在恢复数据时,还需要自已手动创建一个数据库之后再去恢复数据。
mysqldump –u用户名 –p密码 数据库名>生成的脚本文件路径

现在可以在C盘下找到mydb1.sql文件了!
注意,mysqldump命令是在Windows控制台下执行,无需登录mysql!!!
2 执行SQL脚本
执行SQL脚本需要登录mysql,然后进入指定数据库,才可以执行SQL脚本!!!
执行SQL脚本不只是用来恢复数据库,也可以在平时编写SQL脚本,然后使用执行SQL 脚本来操作数据库!大家都知道,在黑屏下编写SQL语句时,就算发现了错误,可能也不能修改了。所以我建议大家使用脚本文件来编写SQL代码,然后执行之!
SOURCE C:\mydb1.sql

注意,在执行脚本时需要先行核查当前数据库中的表是否与脚本文件中的语句有冲突!例如在脚本文件中存在create table a的语句,而当前数据库中已经存在了a表,那么就会出错!
还可以通过下面的方式来执行脚本文件:
mysql -uroot -p123 mydb1
mysql –u用户名 –p密码 数据库

这种方式无需登录mysql!
多表查询
多表查询有如下几种:
合并结果集;
连接查询
内连接
外连接
左外连接
右外连接
全外连接(MySQL不支持)
自然连接
子查询
1 合并结果集
作用:合并结果集就是把两个select语句的查询结果合并到一起!
合并结果集有两种方式:
UNION:去除重复记录,例如:SELECT * FROM t1 UNION SELECT * FROM t2;
UNION ALL:不去除重复记录,例如:SELECT * FROM t1 UNION ALL SELECT * FROM t2。


要求:被合并的两个结果:列数、列类型必须相同。
2 连接查询
连接查询就是求出多个表的乘积,例如t1连接t2,那么查询出的结果就是t1*t2。

连接查询会产生笛卡尔积,假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}。可以扩展到多个集合的情况。
那么多表查询产生这样的结果并不是我们想要的,那么怎么去除重复的,不想要的记录呢,当然是通过条件过滤。通常要查询的多个表之间都存在关联关系,那么就通过关联关系去除笛卡尔积。
你能想像到emp和dept表连接查询的结果么?emp一共14行记录,dept表一共4行记录,那么连接后查询出的结果是56行记录。
也就你只是想在查询emp表的同时,把每个员工的所在部门信息显示出来,那么就需要使用主外键来去除无用信息了。

使用主外键关系做为条件来去除无用信息
SELECT * FROM emp,dept WHERE emp.deptno=dept.deptno;

上面查询结果会把两张表的所有列都查询出来,也许你不需要那么多列,这时就可以指定要查询的列了。
SELECT emp.ename,emp.sal,emp.comm,dept.dname
FROM emp,dept
WHERE emp.deptno=dept.deptno;

还可以为表指定别名,然后在引用列时使用别名即可。
SELECT e.ename,e.sal,e.comm,d.dname
FROM emp AS e,dept AS d
WHERE e.deptno=d.deptno;
2.1 内连接
上面的连接语句就是内连接,但它不是SQL标准中的查询方式,可以理解为方言!SQL标准的内连接为:
SELECT *
FROM emp e
INNER JOIN dept d
ON e.deptno=d.deptno;
内连接的特点:查询结果必须满足条件。例如我们向emp表中插入一条记录:

其中deptno为50,而在dept表中只有10、20、30、40部门,那么上面的查询结果中就不会出现“张三”这条记录,因为它不能满足e.deptno=d.deptno这个条件。
2.2 外连接(左连接、右连接)
外连接的特点:查询出的结果存在不满足条件的可能。
左连接:
SELECT * FROM emp e
LEFT OUTER JOIN dept d
ON e.deptno=d.deptno;
左连接是先查询出左表(即以左表为主),然后查询右表,右表中满足条件的显示出来,不满足条件的显示NULL。
这么说你可能不太明白,我们还是用上面的例子来说明。其中emp表中“张三”这条记录中,部门编号为50,而dept表中不存在部门编号为50的记录,所以“张三”这条记录,不能满足e.deptno=d.deptno这条件。但在左连接中,因为emp表是左表,所以左表中的记录都会查询出来,即“张三”这条记录也会查出,但相应的右表部分显示NULL。

2.3 右连接
右连接就是先把右表中所有记录都查询出来,然后左表满足条件的显示,不满足显示NULL。例如在dept表中的40部门并不存在员工,但在右连接中,如果dept表为右表,那么还是会查出40部门,但相应的员工信息为NULL。
SELECT * FROM emp e
RIGHT OUTER JOIN dept d
ON e.deptno=d.deptno;

连接查询心得:
连接不限与两张表,连接查询也可以是三张、四张,甚至N张表的连接查询。通常连接查询不可能需要整个笛卡尔积,而只是需要其中一部分,那么这时就需要使用条件来去除不需要的记录。这个条件大多数情况下都是使用主外键关系去除。
两张表的连接查询一定有一个主外键关系,三张表的连接查询就一定有两个主外键关系,所以在大家不是很熟悉连接查询时,首先要学会去除无用笛卡尔积,那么就是用主外键关系作为条件来处理。如果两张表的查询,那么至少有一个主外键条件,三张表连接至少有两个主外键条件。
3 自然连接
大家也都知道,连接查询会产生无用笛卡尔积,我们通常使用主外键关系等式来去除它。而自然连接无需你去给出主外键等式,它会自动找到这一等式:
两张连接的表中名称和类型完成一致的列作为条件,例如emp和dept表都存在deptno列,并且类型一致,所以会被自然连接找到!
当然自然连接还有其他的查找条件的方式,但其他方式都可能存在问题!
SELECT * FROM emp NATURAL JOIN dept;
SELECT * FROM emp NATURAL LEFT JOIN dept;
SELECT * FROM emp NATURAL RIGHT JOIN dept;
4 子查询
子查询就是嵌套查询,即SELECT中包含SELECT,如果一条语句中存在两个,或两个以上SELECT,那么就是子查询语句了。
子查询出现的位置:
where后,作为条件的一部分;
from后,作为被查询的一条表;
当子查询出现在where后作为条件时,还可以使用如下关键字:
any
all
子查询结果集的形式:
单行单列(用于条件)
单行多列(用于条件)
多行单列(用于条件)
多行多列(用于表)
练习:
工资高于甘宁的员工。
分析:
查询条件:工资>甘宁工资,其中甘宁工资需要一条子查询。
第一步:查询甘宁的工资
SELECT sal FROM emp WHERE ename='甘宁'
第二步:查询高于甘宁工资的员工
SELECT * FROM emp WHERE sal > (${第一步})
结果:
SELECT * FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename='甘宁')
子查询作为条件
子查询形式为单行单列
工资高于30部门所有人的员工信息
分析:
查询条件:工资高于30部门所有人工资,其中30部门所有人工资是子查询。高于所有需要使用all关键字。
第一步:查询30部门所有人工资
SELECT sal FROM emp WHERE deptno=30;
第二步:查询高于30部门所有人工资的员工信息
SELECT * FROM emp WHERE sal > ALL (${第一步})
结果:
SELECT * FROM emp WHERE sal > ALL (SELECT sal FROM emp WHERE deptno=30)
子查询作为条件
子查询形式为多行单列(当子查询结果集形式为多行单列时可以使用ALL或ANY关键字)
查询工作和工资与殷天正完全相同的员工信息
分析:
查询条件:工作和工资与殷天正完全相同,这是子查询
第一步:查询出殷天正的工作和工资
SELECT job,sal FROM emp WHERE ename='殷天正'
第二步:查询出与殷天正工作和工资相同的人
SELECT * FROM emp WHERE (job,sal) IN (${第一步})
结果:
SELECT * FROM emp WHERE (job,sal) IN (SELECT job,sal FROM emp WHERE ename='殷天正')
子查询作为条件
子查询形式为单行多列
查询员工编号为1006的员工名称、员工工资、部门名称、部门地址
分析:
查询列:员工名称、员工工资、部门名称、部门地址
查询表:emp和dept,分析得出,不需要外连接(外连接的特性:某一行(或某些行)记录上会出现一半有值,一半为NULL值)
条件:员工编号为1006
第一步:去除多表,只查一张表,这里去除部门表,只查员工表
SELECT ename, sal FROM emp e WHERE empno=1006
第二步:让第一步与dept做内连接查询,添加主外键条件去除无用笛卡尔积
SELECT e.ename, e.sal, d.dname, d.loc
FROM emp e, dept d
WHERE e.deptno=d.deptno AND empno=1006
第二步中的dept表表示所有行所有列的一张完整的表,这里可以把dept替换成所有行,但只有dname和loc列的表,这需要子查询。
第三步:查询dept表中dname和loc两列,因为deptno会被作为条件,用来去除无用笛卡尔积,所以需要查询它。
SELECT dname,loc,deptno FROM dept;
第四步:替换第二步中的dept
SELECT e.ename, e.sal, d.dname, d.loc
FROM emp e, (SELECT dname,loc,deptno FROM dept) d
WHERE e.deptno=d.deptno AND e.empno=1006
子查询作为表
子查询形式为多行多列
相关文章:

关于timewait状态
四次挥手 主动关闭连接的一方,调用close,协议层发送FIN包,在TCP报头的FIN字段设置为1,意思是我要和你断开链接,主动关闭连接的一方进入到了FIN_WATI_1状态 被动关闭的一方收到了FIN包之后,协议层回复ACK包…

DWZ基于ajax重复请求的修复
在同一个通用上传插件,每次都需要客户端去请求服务器,返回的html页面,如果请求的间隔很短的话,ajax会认为是重复作废的请求,这个时候需要修改一下源码来达到在短时间内重复请求也能得到响应找到js/dwz.ajax.js修改源码为function ajaxTodo(url, callback){t Date.parse(new D…

TLS/HTTPS 证书生成与验证
https://www.cnblogs.com/kyrios/p/tls-and-certificates.html 最近在研究基于ssl的传输加密,涉及到了key和证书相关的话题,走了不少弯路,现在总结一下做个备忘 科普:TLS、SSL、HTTPS以及证书 不少人可能听过其中的超过3个名词&am…
高并发系统搭建:web负载均衡
高并发系统搭建:web负载均衡 所谓的负载均衡就是让多个请求尽量均衡的分配到不同的机器上面去 1. HTTP负载均衡 当用户的请求发来之后,web服务器通过修改HTTP响应报头中的Location标记,返回一个新的url,然后浏览器继续请求这个…
centos 7.0 安装mysql_CentOS 7.0yum安装MySQL
1.下载mysql的repo源$ wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm2.安装mysql-community-release-el7-5.noarch.rpm包$ sudo rpm -ivh mysql-community-release-el7-5.noarch.rpm安装这个包后,会获得两个mysql的yum repo源:/…
UVa 11174 - Stand in a Line
http://uva.onlinejudge.org/index.php?optioncom_onlinejudge&Itemid8&pageshow_problem&problem2115 数学的特点在于不断的推导,此题还需要用到 欧拉定理和逆元的相关性质,推荐博客(有部分小错误):http…
计算背板带宽方法
背板带宽:端口数*端口速率*2包转发率:接口带宽(bps)/8bit/(64812)千兆包转发率:1.488Mpps百兆:0.1488Mpps万兆:14.88Mpps例如2950G-48背板2*1000*248*100*213600Mbps13.6Gbps相当于13.6/26.8个千…
Windows下安装PHP开发环境
一、Apache 因为Apache官网只提供源代码,如果要使用必须得自己编译,这里我选择第三方安装包Apache Lounge。 进入Apachelounge官方下载地址:http://www.apachelounge.com/download/首先下载并安装vc redist,这是Apache运行必需的一…
高并发简单设计
系统内存不足,主要是每次来一个请求的时候,就要创建倒排的哈希,这个时候如果高并发的情况下,就会出现问题,每次一个倒排索引占据内存,内存只有2G肯定是不够使用的 可以根据日志分析的结果,看看…
mysql 8.0数据备份恢复_第7章 备份和恢复
## 目录- 备份和恢复类型- 数据库备份方法- 例备份和恢复策略- 使用mysqldump进行备份- 使用二进制日志进行- 点时间(增量)恢复- MyISAM表维护和崩溃恢复备份数据库非常重要,这样您就可以恢复数据,并在发生问题时再次启动并运行,例如系统崩溃…

CSS 实例之打开大门
本个实例主要的效果如下图所示 本案例主要运用到了3D旋转和定位技术。具体步骤如下: 1、首先在页面主体加三个很简单的div标签: <div class"door"><div class"door-l"></div><div class"door-r">…
为 Asp.net 网站新增发送手机短信功能
本文旨在帮助那些为网站发送手机短信正在寻求解决方案还未最终找到解决方案的朋友提供参考。 适合人群 须满足一下条件之一,如果以下3个条件您都不满足,为节约您宝贵的时间,请终止阅读本篇文章。 条件如下: 1.一条短信内容进行短信…
搜索引擎Killed原因排查
问题描述 腾讯云单核2G内存,运行程序的时候,程序有时会挂掉了,设置ulimit -c unlimited之后,想要core文件,结果程序运行的时候,直接提示killed,没有出现core文件 调研查询 killed的原因多是因…
mysql 8.0配置主从同步_MySQL8.0.19开启GTID主从同步CentOS8
前言本次搭建目标为1主2从MySQL主从同步结构。采用CentOS8作为操作系统,IP为[10.0.0.211,10.0.0.212,10.0.0.213]。MySQL版本为8.0.19,端口均采用3306。本文仅讲解主从配置,因此安装MySQL的方式请参考安装文档。GTID模式介绍一、GTID Replica…


IO流总结笔记三
字节流: 抽象基类:InputStream, OutputStream。 字节流可以操作任何数据。注意:字符流使用的数组是字符数组。Char [] chs 字节流使用的数组是字节数组。Byte [] bt 转换流: 特点:1,是字节流…

awk1.0 — awk基础
简介 grep,sed,awk被称为Linux文本处理的三剑客,各有特点 grep:适合文本的匹配和查找 sed:编辑匹配到的文本 awk:对文本进行格式化输出 awk简介 awk的基本语法是 awk [options] Pattern {Actions} …
mysql dump 参数_mysqldump常用参数
收集一些常用的mysqldump命令组合。备份数据库1.导出结构不导出数据 **复制代码代码如下:2.导出数据不导出结构3.导出数据和表结构4.导出特定表的结构导入数据:由于mysqldump导出的是完整的SQL语句,所以用mysql客户程序很容易就能把数据导入了࿱…
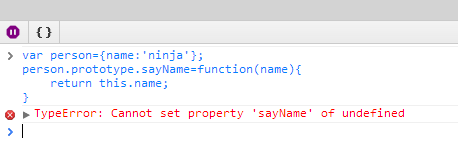
细心看完这篇文章,刷新对Javascript Prototype的理解
var person{name:ninja}; person.prototype.sayNamefunction(){return this.name; } 分析上面这段代码,看看有没有问题? 没错,这段代码是有问题的,我们可以通过Chrome看一下执行结果: 错误提示说找不到sayName 属性&am…

那些值得回味的MySQL的基础知识
那些值得回味的MySQL的基础知识 MySQL零碎知识点整理 题记: 在如今甚是流行的MySQL中有些基础的知识却是我们日常工作中处理问题容易忘却的一部分,所以不能忘了本,那么我们现在就去回忆那些曾经熟悉的基本吧,废话不多说了 基础常识ÿ…

awk2.0 — awk分隔符
再次重申awk的语法 awk [options] ‘Pattern {Actions}’ file1,file2… awk默认分隔符是空格,分隔符有分为“输入分隔符”和“输出分隔符”。 输入分隔符:awk在处理每一行文本的时候,以默认的空格将文本分隔成一个个单词作为变量。 输出分…
【C++自我精讲】基础系列二 const
【C自我精讲】基础系列二 const 0 前言 分三部分:const用法、const和#define比较、const作用。 1 const用法 const常量:const可以用来定义常量,不可改变,const常量在定义时必须初始化(extern修饰时是特例)。…
mysql system命令_mysql命令
关闭防火墙和selinux:systemctl stop firewalld.servicesetenforce 0永久关闭防火墙和selinux:systemctl disable firewalld.servicesed -i ‘/^SELINUX/s#enforcing#disabled#g’ /etc/selinux/config安装wget:yum install -y wget国内yum源:wget -O /etc/yum.repos.d/CentOS-…
django教程目录
什么是web框架? Do a web framework ourselves MVC和MTV模式 django的流程和命令行工具 Django的配置文件(settings) Django URL (路由系统) Django Views(视图函数) Template基础 Models admin的配置 Middleware cache Cookie & Session…
VRRP在企业网中的应用(H3C设备)
一:实验原理①VRRP概述:随着Internet的发展,人们对网络的可靠性的要求越来越高。对于局域网用户来说,能够时刻与外部网络保持联系是非常重要的。通常情况下,内部网络中的所有主机都设置一条相同的缺省路由,…
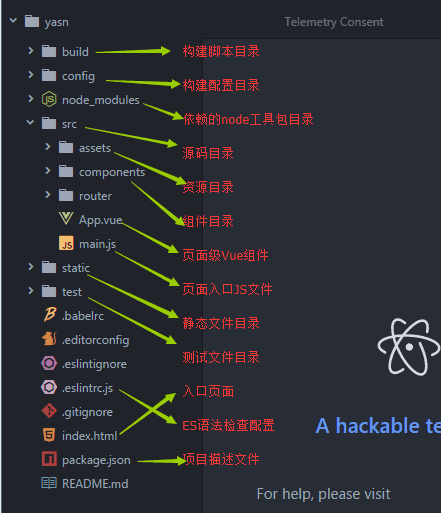
vue-cli脚手架(框架)
一、创建vue项目 npm install vue-cli -g #-g全局 (sudo)npm install vue-cli -g #mac笔记本vue-init webpack myvue #项目的名字 cd muvue npm install npm run dev 二、目录结构的说明 出现下面这样的图就说明成功了 三、import和require的区别 import一定要放在文件顶部…

poj 1679 次小生成树
次小生成树的求法: 1.Prime法 定义一个二维数组F[i][j]表示点i到点j在最小生成树中的路径上的最大权值。有个知识就是将一条不在最小生成树中的边Edge加入最小生成树时,树中要去掉的边就是Edge连接的两个端点i,j的F[i][j]。这样就能保存找到的生成树时次小生成树。 …
mysql金库模式_Python vault-anyconfig包_程序模块 - PyPI - Python中文网
vaultanyconfig" rel"nofollow">使用加载和转储功能扩展hvac hashicorp vault客户端任何配置。这允许自动混合来自保险库的机密,允许您存储配置填充了所有详细信息的文件保存为机密,然后访问hashicorp保险库将机密加载到内存字典中。支…

awk3.0 — awk变量
awk有一些内置变量和外置变量,内置变量就是awk自带的变量,用户可以拿来直接使用,如FS,OFS等 awk常用内置变量如下几种: FS:输入单词分隔符,默认是空格 OFS:输出单词分隔…

关于yum库的相关问题
局域网共享yum库的两种方式: 一种是基于HTTP的,需要配置httpd。 一种是基于FTP的。需要FTP的支持。 具体设置参数可参照网上的相关教程。 yum库的建立主要涉及到两点: 1、 Yum服务器安装createrepo并创建仓库 2、 安装完成之后,在…