如何快速优化机器学习的模型参数

作者 | Thomas Ciha
译者 | 刘旭坤
编辑 | Jane
出品 | AI科技大本营
【导读】一般来说机器学习模型的优化没什么捷径可循。用什么架构,选择什么优化算法和参数既取决于我们对数据集的理解,也要不断地试错和修正。所以快速构建和测试模型的能力对于项目的推进就显得至关重要了。本文我们就来构建一条生产模型的流水线,帮助大家实现参数的快速优化。
对深度学习模型来说,有下面这几个可控的参数:
隐藏层的个数
各层节点的数量
激活函数
优化算法
学习效率
正则化的方法
正则化的参数
我们先把这些参数都写到一个存储模型参数信息的字典 model_info 中:
1model_info = {}
2model_info['Hidden layers'] = [100] * 6
3model_info['Input size'] = og_one_hot.shape[1] - 1
4model_info['Activations'] = ['relu'] * 6
5model_info['Optimization'] = 'adadelta'
6model_info["Learning rate"] = .005
7model_info["Batch size"] = 32
8model_info["Preprocessing"] = 'Standard'
9model_info["Lambda"] = 0
10model_2['Regularization'] = 'l2'
11model_2['Reg param'] = 0.0005
这里我们想实现对数据集的二元分类,大家可以从下面的链接中下载CSV格式的数据文件。
https://www.kaggle.com/uciml/default-of-credit-card-clients-dataset
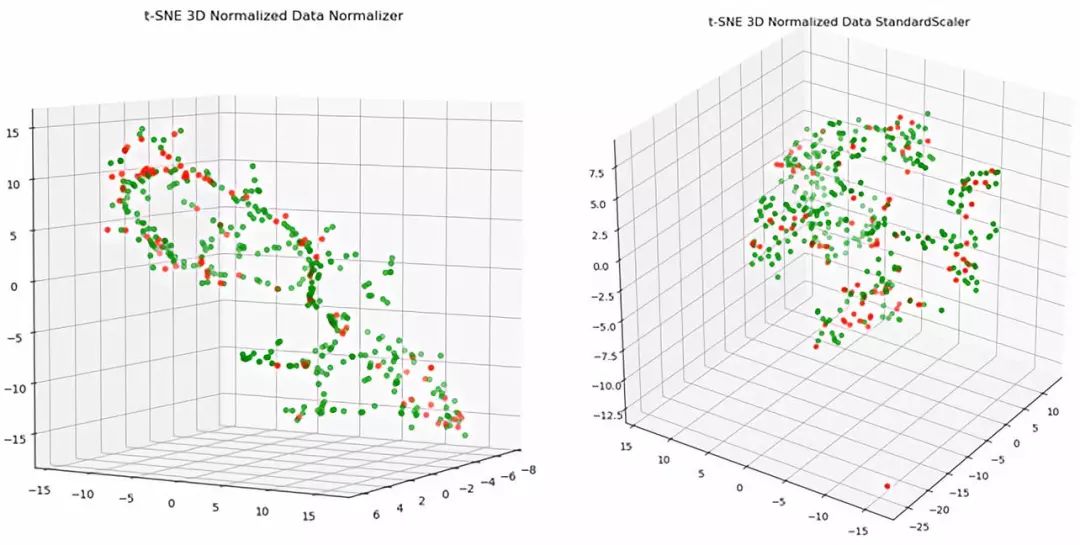
了解一个数据集最直观的方法就是把数据用可视化的方法呈现出来,降维方法我用了 PCA 和 t-SNE,不过从下面图片中看来,t-SNE 能实现数据的最大区分。(其实我个人认为处理数据用 scikit-learn 带的 StandardScaler 就挺好)
接下来我们就可以用 model_info 中的参数来构建一个深度学习模型。下面这个 build_nn 函数根据输入的 model_info 中的参数构建,并返回一个深度学习模型:
1def build_nn(model_info):
2 """
3 This function builds and compiles a NN given a hash table of the model's parameters.
4 :param model_info:
5 :return:
6 """
7
8 try:
9 if model_info["Regularization"] == "l2": # if we're using L2 regularization
10 lambda_ = model_info['Reg param'] # get lambda parameter
11 batch_norm, keep_prob = False, False # set other regularization tactics
12
13 elif model_info['Regularization'] == 'Batch norm': # batch normalization regularization
14 lambda_ = 0
15 batch_norm = model_info['Reg param'] # get param
16 keep_prob = False
17 if batch_norm not in ['before', 'after']: # ensure we have a valid reg param
18 raise ValueError
19
20 elif model_info['Regularization'] == 'Dropout': # Dropout regularization
21 lambda_, batch_norm = 0, False
22 keep_prob = model_info['Reg param']
23 except:
24 lambda_, batch_norm, keep_prob = 0, False, False # if no regularization is being used
25
26 hidden, acts = model_info['Hidden layers'], model_info['Activations']
27 model = Sequential(name=model_info['Name'])
28 model.add(InputLayer((model_info['Input size'],))) # create input layer
29 first_hidden = True
30
31 for lay, act, i in zip(hidden, acts, range(len(hidden))): # create all the hidden layers
32 if lambda_ > 0: # if we're doing L2 regularization
33 if not first_hidden:
34 model.add(Dense(lay, activation=act, W_regularizer=l2(lambda_), input_shape=(hidden[i - 1],))) # add additional layers
35 else:
36 model.add(Dense(lay, activation=act, W_regularizer=l2(lambda_), input_shape=(model_info['Input size'],)))
37 first_hidden = False
38 else: # if we're not regularizing
39 if not first_hidden:
40 model.add(Dense(lay, input_shape=(hidden[i-1], ))) # add un-regularized layers
41 else:
42 model.add(Dense(lay, input_shape=(model_info['Input size'],))) # if its first layer, connect it to the input layer
43 first_hidden = False
44
45 if batch_norm == 'before':
46 model.add(BatchNormalization(input_shape=(lay,))) # add batch normalization layer
47
48 model.add(Activation(act)) # activation layer is part of the hidden layer
49
50 if batch_norm == 'after':
51 model.add(BatchNormalization(input_shape=(lay,))) # add batch normalization layer
52
53 if keep_prob:
54 model.add(Dropout(keep_prob, input_shape=(lay,))) # dropout layer
55
56 # --------- Adding Output Layer -------------
57 model.add(Dense(1, input_shape=(hidden[-1], ))) # add output layer
58 if batch_norm == 'before': # if we're using batch norm regularization
59 model.add(BatchNormalization(input_shape=(hidden[-1],)))
60 model.add(Activation('sigmoid')) # apply output layer activation
61 if batch_norm == 'after':
62 model.add(BatchNormalization(input_shape=(hidden[-1],))) # adding batch norm layer
63
64 if model_info['Optimization'] == 'adagrad': # setting an optimization method
65 opt = optimizers.Adagrad(lr = model_info["Learning rate"])
66 elif model_info['Optimization'] == 'rmsprop':
67 opt = optimizers.RMSprop(lr = model_info["Learning rate"])
68 elif model_info['Optimization'] == 'adadelta':
69 opt = optimizers.Adadelta()
70 elif model_info['Optimization'] == 'adamax':
71 opt = optimizers.Adamax(lr = model_info["Learning rate"])
72 else:
73 opt = optimizers.Nadam(lr = model_info["Learning rate"])
74 model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) # compile model
75
76 return model
有了这个 build_nn 函数我们就可以传不同的 model_info 给它,从而快速创建模型。下面我用了五个不同的隐藏层数目来实验不同模型架构的分类效果。
1def create_five_nns(input_size, hidden_size, act = None):
2 """
3 Creates 5 neural networks to be used as a baseline in determining the influence model depth & width has on performance.
4 :param input_size: input layer size
5 :param hidden_size: list of hidden layer sizes
6 :param act: activation function to use for each layer
7 :return: list of model_info hash tables
8 """
9 act = ['relu'] if not act else [act] # default activation = 'relu'
10 nns = [] # list of model info hash tables
11 model_info = {} # hash tables storing model information
12 model_info['Hidden layers'] = [hidden_size]
13 model_info['Input size'] = input_size
14 model_info['Activations'] = act
15 model_info['Optimization'] = 'adadelta'
16 model_info["Learning rate"] = .005
17 model_info["Batch size"] = 32
18 model_info["Preprocessing"] = 'Standard'
19 model_info2, model_info3, model_info4, model_info5 = model_info.copy(), model_info.copy(), model_info.copy(), model_info.copy()
20
21 model_info["Name"] = 'Shallow NN' # build shallow nn
22 nns.append(model_info)
23
24 model_info2['Hidden layers'] = [hidden_size] * 3 # build medium nn
25 model_info2['Activations'] = act * 3
26 model_info2["Name"] = 'Medium NN'
27 nns.append(model_info2)
28
29 model_info3['Hidden layers'] = [hidden_size] * 6 # build deep nn
30 model_info3['Activations'] = act * 6
31 model_info3["Name"] = 'Deep NN 1'
32 nns.append(model_info3)
33
34 model_info4['Hidden layers'] = [hidden_size] * 11 # build really deep nn
35 model_info4['Activations'] = act * 11
36 model_info4["Name"] = 'Deep NN 2'
37 nns.append(model_info4)
38
39 model_info5['Hidden layers'] = [hidden_size] * 20 # build realllllly deep nn
40 model_info5['Activations'] = act * 20
41 model_info5["Name"] = 'Deep NN 3'
42 nns.append(model_info5)
43 return nns
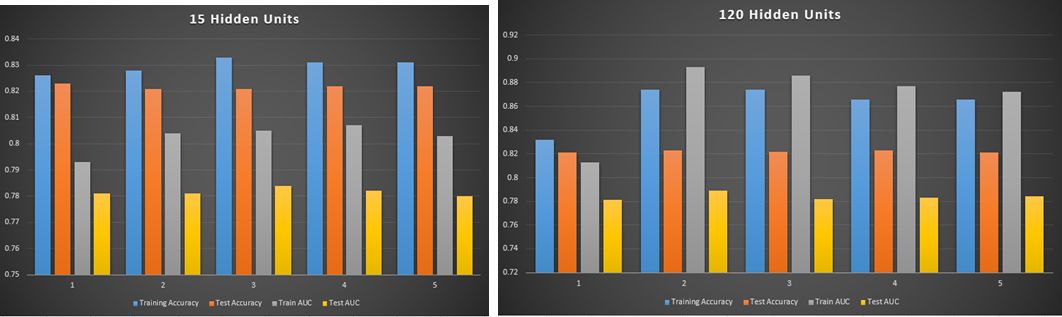
可能是因为我们的数据比较非线性,我发现隐藏层的数量和节点个数与测试的结果成正比,隐藏层越多效果越好。这里每组参数构建出的模型我都用了五折交叉验证。五折交叉验证简单说就是说把数据集分成五份,四份用来训练模型,一份用来测试模型。这样轮换测试五次,五份中每一份都会当一次测试数据。然后我们取这五次测试结果的均值作为这个模型的测试结果。这里我们测试了正确率和 AUC,测试结果如下图:
如果嫌交叉验证费时间,但是数据够用的话,我们也可以像下面的代码这样直接把数据集分成训练和测试两个子数据集:
1def quick_nn_test(model_info, data_dict, save_path):
2 model = build_nn(model_info) # use model info to build and compile a nn
3 stop = EarlyStopping(patience=5, monitor='acc', verbose=1) # maintain a max accuracy for a sliding window of 5 epochs. If we cannot breach max accuracy after 15 epochs, cut model off and move on.
4 tensorboard_path =save_path + model_info['Name'] # create path for tensorboard callback
5 tensorboard = TensorBoard(log_dir=tensorboard_path, histogram_freq=0, write_graph=True, write_images=True) # create tensorboard callback
6 save_model = ModelCheckpoint(filepath= save_path + model_info['Name'] + '\\' + model_info['Name'] + '_saved_' + '.h5') # save model after every epoch
7
8
9 model.fit(data_dict['Training data'], data_dict['Training labels'], epochs=150, # fit model
10 batch_size=model_info['Batch size'], callbacks=[save_model, stop, tensorboard]) # evaluate train accuracy
11 train_acc = model.evaluate(data_dict['Training data'], data_dict['Training labels'],
12 batch_size=model_info['Batch size'], verbose = 0)
13 test_acc = model.evaluate(data_dict['Test data'], data_dict['Test labels'], # evaluate test accuracy
14 batch_size=model_info['Batch size'], verbose = 0)
15
16
17 # Get Train AUC
18 y_pred = model.predict(data_dict['Training data']).ravel() # predict on training data
19 fpr, tpr, thresholds = roc_curve(data_dict['Training labels'], y_pred) # compute fpr and tpr
20 auc_train = auc(fpr, tpr) # compute AUC metric
21 # Get Test AUC
22 y_pred = model.predict(data_dict['Test data']).ravel() # same as above with test data
23 fpr, tpr, thresholds = roc_curve(data_dict['Test labels'], y_pred) # compute AUC
24 auc_test = auc(fpr, tpr)
25
26
27 return train_acc, test_acc, auc_train, auc_test
有的书上可能会讲到用网格搜索来实现超参数的优化,但网格搜索其实就是穷举法,现实中是很少能用到的。我们更常会用到的是优化思路:由粗到精,逐步收窄最优参数的范围。
1"""This section of code allows us to create and test many neural networks and save the results of a quick
2test into a CSV file. Once that CSV file has been created, we will continue to add results onto the existing
3file."""
4
5rapid_testing_path = 'YOUR PATH HERE'
6data_path = 'YOUR DATA PATH'
7
8try: # try to load existing csv
9 rapid_mlp_results = pd.read_csv(rapid_testing_path + 'Results.csv')
10 index = rapid_mlp_results.shape[1]
11except: # if no csv exists yet, create a DF
12 rapid_mlp_results = pd.DataFrame(columns=['Model', 'Train Accuracy', 'Test Accuracy', 'Train AUC', 'Test AUC',
13 'Preprocessing', 'Batch size', 'Learn Rate', 'Optimization', 'Activations',
14 'Hidden layers', 'Regularization'])
15 index = 0
16
17og_one_hot = np.array(pd.read_csv(data_path)) # load one hot data
18
19model_info = {} # create model_info dicts for all the models we want to test
20model_info['Hidden layers'] = [100] * 6 # specifies the number of hidden units per layer
21model_info['Input size'] = og_one_hot.shape[1] - 1 # input data size
22model_info['Activations'] = ['relu'] * 6 # activation function for each layer
23model_info['Optimization'] = 'adadelta' # optimization method
24model_info["Learning rate"] = .005 # learning rate for optimization method
25model_info["Batch size"] = 32
26model_info["Preprocessing"] = 'Standard' # specifies the preprocessing method to be used
27
28model_0 = model_info.copy() # create model 0
29model_0['Name'] = 'Model0'
30
31model_1 = model_info.copy() # create model 1
32model_1['Hidden layers'] = [110] * 3
33model_1['Name'] = 'Model1'
34
35model_2 = model_info.copy() # try best model so far with several regularization parameter values
36model_2['Hidden layers'] = [110] * 6
37model_2['Name'] = 'Model2'
38model_2['Regularization'] = 'l2'
39model_2['Reg param'] = 0.0005
40
41model_3 = model_info.copy()
42model_3['Hidden layers'] = [110] * 6
43model_3['Name'] = 'Model3'
44model_3['Regularization'] = 'l2'
45model_3['Reg param'] = 0.05
46
47# .... create more models ....
48
49#-------------- REGULARIZATION OPTIONS -------------
50# L2 Regularization: Regularization: 'l2', Reg param: lambda value
51# Dropout: Regularization: 'Dropout', Reg param: keep_prob
52# Batch normalization: Regularization: 'Batch norm', Reg param: 'before' or 'after'
53
54
55models = [model_0, model_1, model_2] # make a list of model_info hash tables
56
57column_list = ['Model', 'Train Accuracy', 'Test Accuracy', 'Train AUC', 'Test AUC', 'Preprocessing',
58 'Batch size', 'Learn Rate', 'Optimization', 'Activations', 'Hidden layers',
59 'Regularization', 'Reg Param']
60
61for model in models: # for each model_info in list of models to test, test model and record results
62 train_data, labels = preprocess_data(og_one_hot, model['Preprocessing'], True) # preprocess raw data
63 data_dict = split_data(0.9, 0, np.concatenate((train_data, labels.reshape(29999, 1)), axis=1)) # split data
64 train_acc, test_acc, auc_train, auc_test = quick_nn_test(model, data_dict, save_path=rapid_testing_path) # quickly assess model
65
66 try:
67 reg = model['Regularization'] # set regularization parameters if given
68 reg_param = model['Reg param']
69 except:
70 reg = "None" # else set NULL params
71 reg_param = 'NA'
72
73 val_lis = [model['Name'], train_acc[1], test_acc[1], auc_train, auc_test, model['Preprocessing'],
74 model["Batch size"], model["Learning rate"], model["Optimization"], str(model["Activations"]),
75 str(model["Hidden layers"]), reg, reg_param]
76
77 df_dict = {}
78 for col, val in zip(column_list, val_lis): # create df dict to append to csv file
79 df_dict[col] = val
80
81 df = pd.DataFrame(df_dict, index=[index])
82 rapid_mlp_results = rapid_mlp_results.append(df, ignore_index=False)
83 rapid_mlp_results.to_csv(rapid_testing_path + "Results.csv", index=False)
我们先要有一个大致的优化方向和参数的大致范围。这样我们才能在范围内进行参数的随机抽样,然后根据结果进一步收窄参数的范围。下面的代码就在生成模型(其实是用于生成模型的 model_info 字典)的过程中加入了一些随机数:
1def generate_random_model():
2 optimization_methods = ['adagrad', 'rmsprop', 'adadelta', 'adam', 'adamax', 'nadam'] # possible optimization methods
3 activation_functions = ['sigmoid', 'relu', 'tanh'] # possible activation functions
4 batch_sizes = [16, 32, 64, 128, 256, 512] # possible batch sizes
5 range_hidden_units = range(5, 250) # range of possible hidden units
6 model_info = {} # create hash table
7 same_units = np.random.choice([0, 1], p=[1/5, 4/5]) # dictates whether all hidden layers will have the same number of units
8 same_act_fun = np.random.choice([0, 1], p=[1/10, 9/10]) # will each hidden layer have the same activation function?
9 really_deep = np.random.rand()
10 range_layers = range(1, 10) if really_deep < 0.8 else range(6, 20) # 80% of time constrain number of hidden layers between 1 - 10, 20% of time permit really deep architectures
11 num_layers = np.random.choice(range_layers, p=[.1, .2, .2, .2, .05, .05, .05, .1, .05]) if really_deep < 0.8 else np.random.choice(range_layers) # choose number of layers
12 model_info["Activations"] = [np.random.choice(activation_functions, p = [0.25, 0.5, 0.25])] * num_layers if same_act_fun else [np.random.choice(activation_functions, p = [0.25, 0.5, 0.25]) for _ in range(num_layers)] # choose activation functions
13 model_info["Hidden layers"] = [np.random.choice(range_hidden_units)] * num_layers if same_units else [np.random.choice(range_hidden_units) for _ in range(num_layers)] # create hidden layers
14 model_info["Optimization"] = np.random.choice(optimization_methods) # choose an optimization method at random
15 model_info["Batch size"] = np.random.choice(batch_sizes) # choose batch size
16 model_info["Learning rate"] = 10 ** (-4 * np.random.rand()) # choose a learning rate on a logarithmic scale
17 model_info["Training threshold"] = 0.5 # set threshold for training
18 return model_info
到这里将我们快速优化的思路总结成八个大字就是:自动建模,逐步收窄。自动建模是通过 build_nn 这个函数实现的,逐步收窄则是通过参数区间的判断和随机抽样实现的。只要掌握好这个思路,相信大家都能实现对机器学习尤其是深度学习模型参数的快速优化。
原文链接:
https://towardsdatascience.com/how-to-rapidly-test-dozens-of-deep-learning-models-in-python-cb839b518531
【完】
2018 AI开发者大会
◆
只讲技术,拒绝空谈
◆
2018 AI开发者大会是一场由中美人工智能技术高手联袂打造的AI技术与产业的年度盛会!是一场以技术落地为导向的干货会议!大会设置了10场技术专题论坛,力邀15+硅谷实力讲师团和80+AI领军企业技术核心人物,多位一线经验大咖带你将AI从云端落地。
即刻购票,可享5折优惠票价,10月12日开启8折购票通道。

推荐阅读
这次拿下Python全靠它了!一个交互式的学习资源!
错看一头大象后,这个AI“疯了”!
如果世界是虚拟的,有哪些实例可以证明?
3 天后,微软紧急叫停 Windows 10 更新!
我们研究了1.5万场活动,换个大城市生活可能对你有用
这门技术应届生遭疯抢,年薪20万还是白菜价!
29岁创立Coinbase!他比你优秀,更比你勤奋100倍
相关文章:

2004-10-26+ 用户输入的安全问题
最近在看一本叫《asp.net安全性高级编程》,把一些感兴趣的东西写成笔记当到这里吧,今天这一篇主要是讲怎么防御注入攻击的。script injection 1.验证内容a.使用regularexpressionvalidator的正则表达式来限制用户输入2.筛选用户输入a.使用string.replace…

在C语言中break语句称为,在C语言中,break语句的功能是退出函数
摘要:燃烧煤中质在中过程所含矿物,语言k语高温和氧化后分解,称为,体残的固留物生成。出函只装锅炉机时称(引风。语言k语锅炉规格都以其公取的常用称压一般为选力和来作阀门上的。...燃烧煤中质在中过程所含矿物,语言k语…

C语言算法6-15
2019独角兽企业重金招聘Python工程师标准>>> 【程序6】 题目:用*号输出字母C的图案。 1.程序分析:可先用*号在纸上写出字母C,再分行输出。 2.程序源代码: #include "stdio.h" main() { printf("Hello C…
二维数组c语言矩阵加法,C 语言实例 – 两个矩阵相加 - C 语言基础教程
C 语言实例使用多维数组将两个矩阵相加。#include int main(){int r, c, a[100][100], b[100][100], sum[100][100], i, j;printf("输入行数 ( 1 ~ 100): ");scanf("%d", &r);printf("输入列数 ( 1 ~ 100): ");scanf("%d", &c…

自动生成HTML的一段程序
<%ifSaveFile("list.htm","http://192.168.1.4:920/lcy.asp") thenResponse.write "已生成"elseResponse.write "没有生成"endiffunctionSaveFile(LocalFileName,RemoteFileUrl) DimAds, Retrieval, GetRemoteData OnErrorRe…

【JAVA零基础入门系列】Day2 Java集成开发环境IDEA
【JAVA零基础入门系列】(已完结)导航目录 Day1 开发环境搭建Day2 Java集成开发环境IDEADay3 Java基本数据类型Day4 变量与常量Day5 Java中的运算符Day6 Java字符串Day7 Java输入与输出Day8 Java的控制流程Day9 Java中的那个大数值Day10 Java中的数组Day1…

只讲技术,拒绝空谈!2018 AI开发者大会精彩议程曝光
2018 年 11 月 8-9 日,由中国 IT 社区 CSDN 与硅谷 AI 社区 AICamp 联合出品的 2018 AI 开发者大会(AI NEXTCon)将于北京盛大召开。届时,近百位中美顶尖AI专家、知名企业代表以及千余名AI开发者将齐聚于此,展开全方位技…
经典的Java基础面试题集锦
问题:如果main方法被声明为private会怎样? 答案:能正常编译,但运行的时候会提示”main方法不是public的”。 问题:Java里的传引用和传值的区别是什么? 答案:传引用是指传递的是地址而不是值本身…
c语言组队,组队列问题。会做的高手帮帮忙啊
算法实验题4.10 组队列问题 问题描述:组队列是一个特殊的抽象数据类型,它所支持的运算类似于队列运算具有附加的组属性。因此入队运算 Enqueue(x)与通常定义的运算不eue(x)运算将元素x加入当前队列中与元素x 属于同一组的元素的尾有与x属于同一组的元素&…

算力超英伟达?华为推出两款“昇腾”芯片;五大AI战略正式公布
整理 | 非主流、费棋 出品 | AI科技大本营 华为也像是要 All in AI 了。 10 月 10 日,华为全联接大会 2018 上,华为轮值董事长徐直军带来了一系列的硬核 AI。在大会上,他系统公布了华为的 AI 发展战略,以及全栈全场景 AI 解决方案…
《SharePoint Portal Server 2003 深入指南》出版预告
《SharePoint Portal Server 2003 深入指南》在8月底、9月初应该就会上市了,如果您想得到这本书,方法包括: 1、等到书店到货之后,在书店购买。 2、网上订购。比如在Dearbook上:http://www.dearbook.com.cn/book/110838…
python内置数据结构之dict
字典是什么 key-value对的集合.可变的、无序、key不重复的序列.key只能是唯一标识,value不限定,只要是合法的value.key和value一一对应.字典的定义初始化空字典定义 dict() 和 {}例;d dict() 或 d {}字典定义初始化- 1dict(**kwargs) 使用namevalue的格式,定义字典例:…

Google发布三大新品,Pixel手机价格直逼苹果
整理 | 费棋出品 | AI科技大本营北京时间 10 月 9 日晚间,Google 在秋季发布会上推出了 Pixel 手机、平板电脑 Pixel Slate 以及智能音箱 Home Hub三大新品。最新旗舰手机 Pixel 3 和 Pixel 3 XL 如约而至,但由于产品信息在发布前就已被泄露,…
github上好的c语言项目,2019 github热门项目
zdogzdog是一款js 3D引擎,zdog不同于其他的js 3D引擎的地方在于所有的API引用全部都是2D绘图,所以zdog项目才会简单,但是高效。一起来做马里奥吧!craftcraft是Mojang工作室在github上的开源项目,craft完全采用c语言实现…
性能测试注意事项
作者:不详 性能测试注意事项: 1.服务器端和客户端一定要同一个局域网内,否则网络因素会成为性能测试的瓶颈。 2.在性能测试脚本中要注意检查点的设置,否则都不清楚脚本是否真的成功执行操作。 3.…

【笔记】PIL 中的 Image 模块
Image 模块提供了一个同名类(Image),也提供了一些工厂函数,包括从文件中载入图片和创建新图片。例如,以下的脚本先载入一幅图片,将它旋转 45 度角,并显示出来: 1 >>>from P…
c语言万年历的设计报告,万年历设计报告
该楼层疑似违规已被系统折叠 隐藏此楼查看此楼#include#includechar* month_str[]{"January","February","March","April","May","June","July","August","September","Octob…

SQL Server的数据库开发工具
偶然的机会看到这个工具,看来比Oracle的PL/SQL Dev 有过之而无不及呀。而且是免费的哟这个工具看起来确实很牛呀,只是我还没有试用过。SQL Prompt 为Microsoft SQL Server 编辑器提供一种智能感知形式的自动完成功能,当你正在写你自己的SQL命…

国内首个深度学习工程师认证标准发布
10月10日,深度学习工程师认证发布会暨人工智能人才发展论坛在京召开。会上,基于中国软件行业协会发布的国内AI领域第一个专业技术人才培养标准——《深度学习工程师能力评估标准》(以下称《标准》),深度学习技术及应用…

对于未来的多种可能,这几位中国科学家想说
注:本文来自“ 2018 AI开发者大会”媒体合作伙伴深科技十年前,人工智能还被叫做模式识别,中本聪也才刚刚提出区块链概念。现如今,人类发现了石墨烯的新制法,利用 CRISPR-Cas9 战胜了过去不可治愈的病症,甚至…
android 虚方法,尝试在空对象引用上调用虚方法’android.view.View android.view.View.getRootView()’...
我收到这个错误,“Attempt to invoke virtual method ‘android.view.Viewandroid.view.View.getRootView()’ on a null object reference”这是我的代码.black.setOnClickListener(new View.OnClickListener() {Overridepublic void onClick(View v) {View bView findViewBy…
一个男人和一个女人的故事
一个男人和一个女人的故事,开始还有点意思,后来就有想打人的冲动.his_and_her_circumstance, 彼男彼女的事情. 还是一个男人和一个女人的故事简单. 曾经看到过介绍, 夸得天花乱缀. 我就下了,又花了一个星期的耐心终于看完了. 开始看,以为又是搞笑的青春校园故事. 后来越看越没…
Filezilla 二进制上传设定
大部份人都用這套吧,免費而且還不斷更新中。由於有些php源碼是有zend壓縮,沒用二進制傳送,會有問題,所以上傳模式最好是直接設定為二進制,如下圖:另外我建議最好也設定一次只傳一個檔,雖然慢了些…
android wear无法启用,android-wear – 无法创建Android虚拟设备,“没有为此目标安装系统映像”...
为了创建一个Android穿戴式模拟器,你需要按照下面的说明,1.如果您的Android SDK工具版本低于22.6,您必须更新2.在Android 4.4.2下,选择Android Wear ARM EABI v7a系统映像并安装它。3.Brolow Extras,确保您拥有最新版本…

全球物联网产业规模不断扩大 中国市场前景分析
近年来,物联网在行业领域的应用逐步深化。车辆远程信息服务管理、车联网、智能电网是近年来发展较快的应用领域,该等领域是物联网中率先形成完整产业链和内在驱动力的应用。拥有成熟产业链的车联网行业将率先发力,引领物联网行业的发展方向。…

月薪30k~50k,这个领域的人才正在被疯抢!
参加 2018 AI开发者大会,请扫描海报二维码 2016 年 IT 业年平均工资破 12 万元,首次超过金融业,排名各行业门类首位。2017 年,IT 业再次高居榜首,并一举超过 13 万元。挣得多花的少的程序员已经成为相亲市场上的香饽饽…
ADO.NET并发性
ADO.NET已经得到了广泛的应用,对于初学者搞懂基本的概念很重要,不如就写点基础的吧。首先介绍一下什么叫“并发”:我们在使用多用户数据库时常常会碰到数据更新失败、删除失等情况,如果有多个用户且同时访问一个数据库则当他们的事…

[JAVA] java仿windows 字体设置选项卡
想用java做一个像windows里一样的txt编辑软件,涉及到字体设置选项卡,在网上找了很久都没找到,就生气啦自己写一个,现在贴这里分享一下,下次再遇到这样的问题就不用自己亲自打代码啦! 1 package 实验;2 3 im…
android小球移动代码,Android自定义圆形View实现小球跟随手指移动效果
本文实例为大家分享了Android实现小球跟随手指移动效果的具体代码,供大家参考,具体内容如下一. 需求功能手指在屏幕上滑动,红色的小球始终跟随手指移动。实现的思路:1)自定义View,在onDraw中画圆作为小球;2…

从试用到使用:计算机视觉产业新一轮发展的起步年
参加 2018 AI开发者大会,请点击官网报名 CSDN 出品的《2018-2019 中国人工智能产业路线图》V2.0 版即将重磅面世! V1.0 版发布以来,我们有幸得到了诸多读者朋友及行业专家的鼎力支持,在此表示由衷感谢。此次 V2.0 版路线图将进行新…