知乎如何洞察你的真实喜好?首页信息流技术揭秘

11月8-9日,由中国 IT 社区 CSDN 与硅谷 AI 社区 AICamp 联合出品的 2018 AI 开发者大会(AI NEXTCon) 在北京举行,就人工智能的最新技术及深度实践,进行了全方位的解读及论证。本文是机器学习技术专题中知乎首页业务总监、首页推荐技术负责人张瑞的演讲实录。
信息爆炸时代,信息过载已经成为互联网核心问题之一,而通过AI、机器学习等技术过滤低质无用信息,推动有价值信息的生产和迭代,被视为一种有效解决方案。以知乎为例,这家知识内容平台很早就开始着手机器学习的开发实践,并于2016年正式组建机器学习团队,利用站内丰富的中文语料库训练AI算法,推动有价值信息更高效触达用户,为内容产业提供了很好的技术借鉴。日前,在2018AI开发者大会上,知乎首页业务总监张瑞就机器学习在知乎首页中的应用做了技术分享。以下是分享内容摘要。
一、知乎信息流推荐框架
知乎的信息流推荐框架是一个基于多策略融合的多源内容推荐系统,代号“水晶球”。如图所示,在这个系统中,首页上出现的内容经历过两次排序。第一次是从数十个推荐队列里被“召回”,第二次是在合并后经过深层神经网络(DNN)的“排序”。
“召回”的第一个步骤是,召回模块根据用户的历史行为表现(用户画像、内容标签、内容源信息),确定数十个推荐队列。这数十个推荐队列是含有特定标签的内容池,有些队列里内容性质相似,比如热点新闻队列、视频队列,还有的队列与用户行为紧密相关,比如关注关系队列、搜索关键词队列。比如说,根据用户的关注关系向外扩展更多关注关系,根据用户兴趣召回感兴趣的内容,根据搜索关键词进行相关推荐。
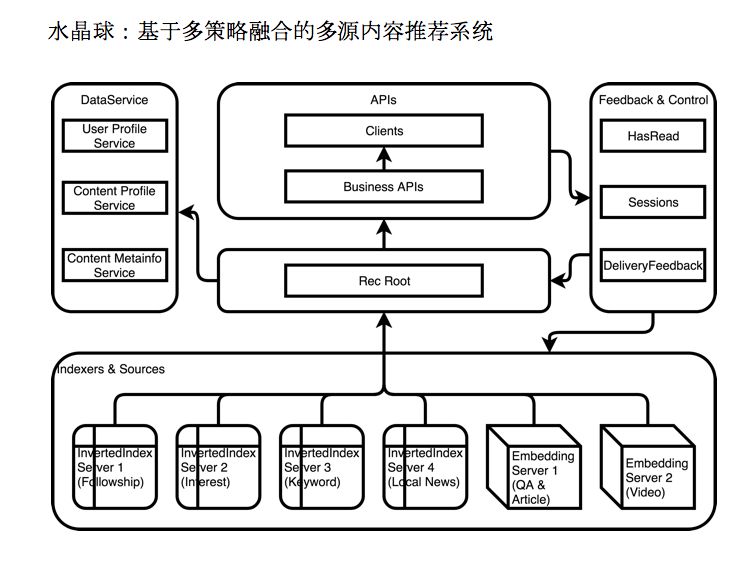
“召回”过程的第二个步骤是,各召回源根据用户的需求分别将自己的队列中的内容做排序后,按召回数量返回内容。我们会从内容类型、内容质量、召回技术三个维度对内容分类,召回源的数据经过汇聚之后会进行融合,最后,DNN可以在20ms内对这些数据完成打分和排序过程,决定推送给用户的内容。
API的数据还会反馈到Feedback&Control的模块里面,应用这些数据进行业务控制的操作,比如我们会记录每个用户看到的内容是什么,大家都知道在Feed信息流推荐有个很重要的应用是去重,推荐内容不能是有重复的,我们会用过滤保证推出来的内容没有重复。用户在一天里面看到哪些内容点击了哪些内容,这些内容都可以为业务提供一定数据支撑。
二、知乎信息流推荐系统的技术演进
2016年之前,知乎的Feed流是比较简单的,你关注了什么样的人,这个人产生的各种各样的动态会在你的界面进行时间倒序的排序,和朋友圈的逻辑非常相似。2010年初我们上线了一个叫EdgeRank的排序系统,第一代Feed流算法在这个系统支持下取得了一定收益,系统维持了一年时间。
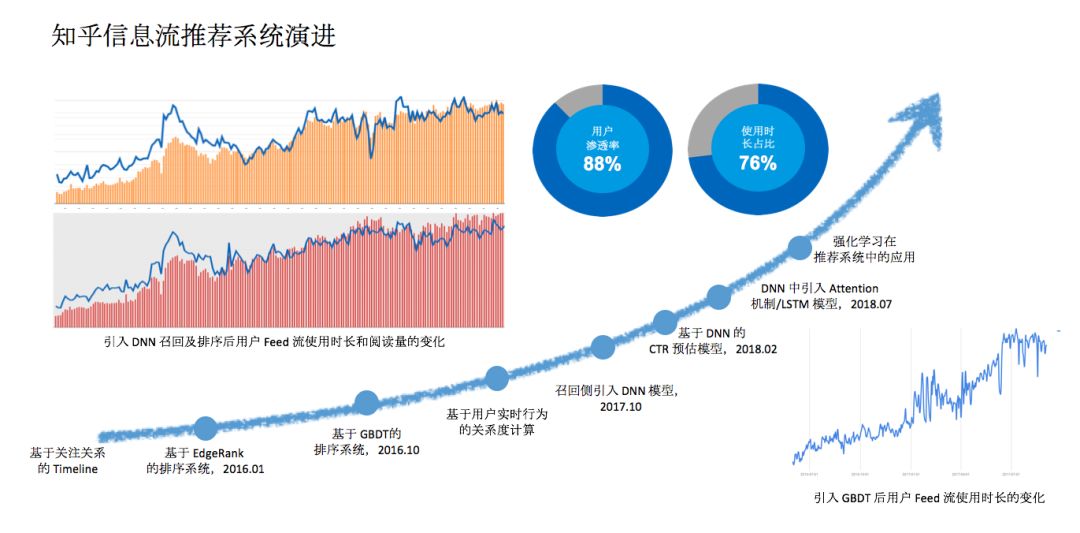
2010年10月份知乎上线了一个基于GBDT的排序系统,对召回的内容进行一个排序。我们使用GBDT做排序持续了一年时间,引入GBDT后用户的Feed流使用时长的变化,是呈上升的趋势。在使用 GBDT 进行排序的过程中,我们逐步完善了我们用户画像和内容分析的系统,在用户特征和内容特征方面做了非常多工作,把用户的实时行为集成到GBDT里面,用户Feed流使用时长得到了激增。
2017年10月开始知乎先后在召回侧和排序侧引入DNN模型,在引入之后的2017年10月份到2018年7月份周期内,知乎的使用时长和阅读量也呈现出快速增长。
在这之后,我们又做了一些优化工作,一个是7月份在DNN做的优化,把注意力机制和LSTM模型引入到DNN的模型里面去,一个是尝试强化学习在推荐系统中的应用。经过这么长时间的优化之后知乎的信息流系统已经在知乎整体业务中占了非常大的体量,用户渗透率(即有多少用户会有效来到首页看内容)达到88%,使用时长占比(包括刷知乎的时长以及在知乎中消费内容的时长等)达到76%。
三、Feed流推荐系统中的AI应用
基于深度学习的推荐召回模型
知乎在2017年上线了基于深度学习的推荐召回1.0版本,左边这张图是第一版上线时候的深度学习召回网络框架,整个系统把用户和用户的特征表示成了网络,它和库里几万条内容做了一个多分类,在上层进行SoftMax。整个网络训练下来可以得到两个成果。首先是一个 User Representation Network,它把用户信息表示成128维的网络,我们用了画像里的所有信息,包括他的兴趣标签、各种各样的用户信息,都会放到模型的输入里面去,这个输入经过四层网络之后得到用户128维的 Embedding 表示。与此同时,使用Faiss作为向量化ANN召回的Backend,用ANN召回的方式从这几个条目里选出他最感兴趣的内容推荐给他,这是整个召回框架的工作过程。
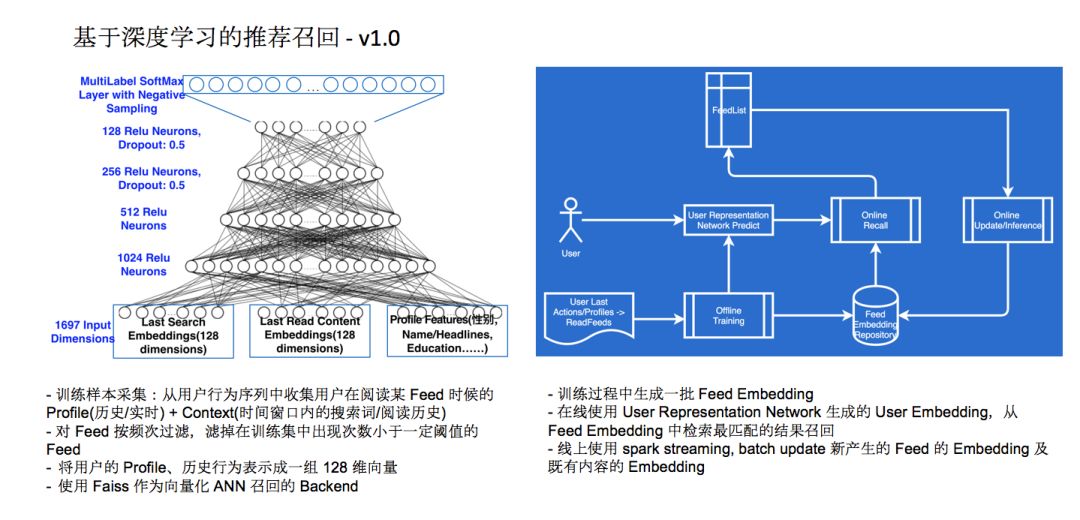
我们在训练集里包含了几万个内容的Embedding,我们首先会在训练中生成一批Embedding,比如今天的数据来自于过去一周内分发量比较高的数据,这些内容数据会生成Embedding,我们先通过这些召回源把这些机制分发出去,还有一批内容是新产生的、未在训练集中包含的内容,这些内容通过其他的渠道分发出去之后,可以得到看到内容用户的Embedding是什么以及点击这些内容用户的Embedding是什么,我们可以利用这份数据把这些新产生内容的Embedding计算出来更新到Embedding库里面去,这个时候就可以拿到每天新产生内容的表示,并且把这些内容推荐出来。
后来我们又对召回框架进行了2.0升级。在1.0版本的召回框架里,“新内容Embedding怎么得到的”这个问题是延迟解决的。用户的表示网络和Embedding召回在效果收益非常明显,协同过滤用户矩阵分解最常用的方法就是ALS,我们拿了一个关键的指标也就是召回从这几万条里挑出的100个结果里准确度有多少,这100个结果里有没有预测到用户下次点击的数据,在这个指标上, DNN 比起ALS来讲提升了10倍的量级,我们希望一个内容产生之后马上算出Embedding放到网络里。
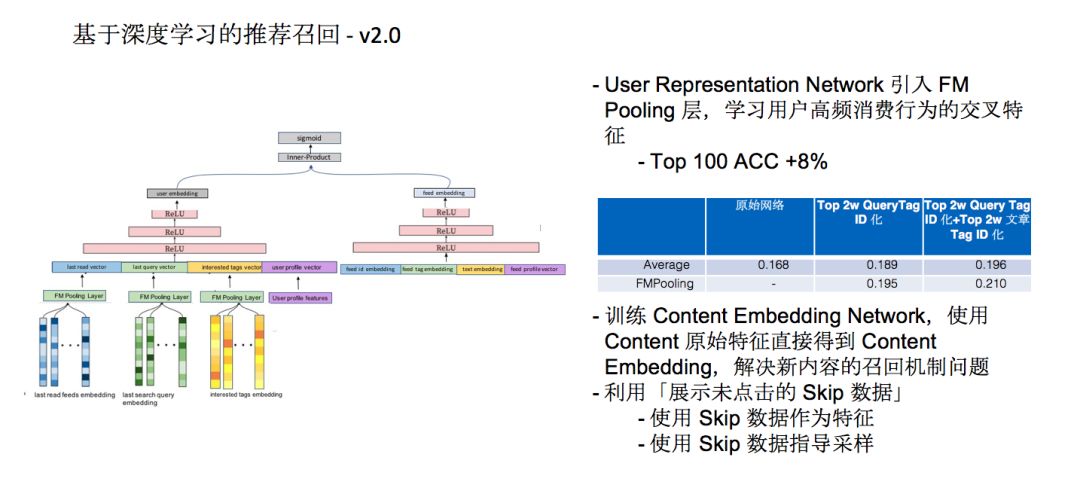
在2.0版本中,我们尝试了三个层面的技术升级:
使用了Content的原始特征,一个内容上打了标签,原始数据比如长度有多少,有没有图片,经过三层的网络之后会生成Feed Embedding,可以直接得到Content Embedding,解决新内容的召回机制问题。
在用户表示网络这一侧我们也做了优化,这个网络里就是一个最简单的全链接神经网络,我们做优化的时候是在User Representation Network引入FM Pooling层,学习用户高频消费行为的交叉特征,会让Top100的精确度提高8%。
用户在Feed流里有,“展示未点击的Skip数据”比线上“展示已点击数据”量级还要高,代表用户对内容并不是真正感兴趣。第一,我们把展示未点击的数据作为特征引入到User Representation Network里面,其中会用到历史搜索和历史阅读数据。第二,我们会把Skip数据作为指导采样的一种方式,训练大规模的标签Embedding时我们往往把正向数据之外的其他数据都当成负向数据使用,所有负向采样的sample都是在剩下的数据中,根据概率的方式或控制采样频率的方式提取。展示了但是跳过 的内容会在采样的时候加大权重,把它成为负例的概率变得更大,让用户的行为来指导采样。
Skip这两个数据为Top100 ACC产生了比较好的效果,从召回数据里来的CTR和整体的阅读量都有比较大的提高。
基于深度学习的 CTR 预估模型
知乎还在排序侧采用了CTR预估的模型。1.0版本总体结构和基于DNN的召回框架类似,使用两层Relu而不是直接点积作为Embedding的预估网络。这个模型上线一段时间之后,我们刚开始没有进行任何的参数裁剪的操作,收效没有达到我们的预期。后来我们做了一个简单的尝试,按照业务的理解把特征组合成不同的Field,这些Field之间先做连接,用户先分成N个Field,比如,Field1是自己填写的资料,Field2是用户兴趣标签,Field3是历史搜索行为,先经过一个简单的子网络再全连接到上层。这个 trick能够有效的减少特征在初始输入时候的错误交叉,会减轻模型的过拟合,线上应用则达到了非常明显的收益,AUC提升了1%,CTR提升了5.8%。
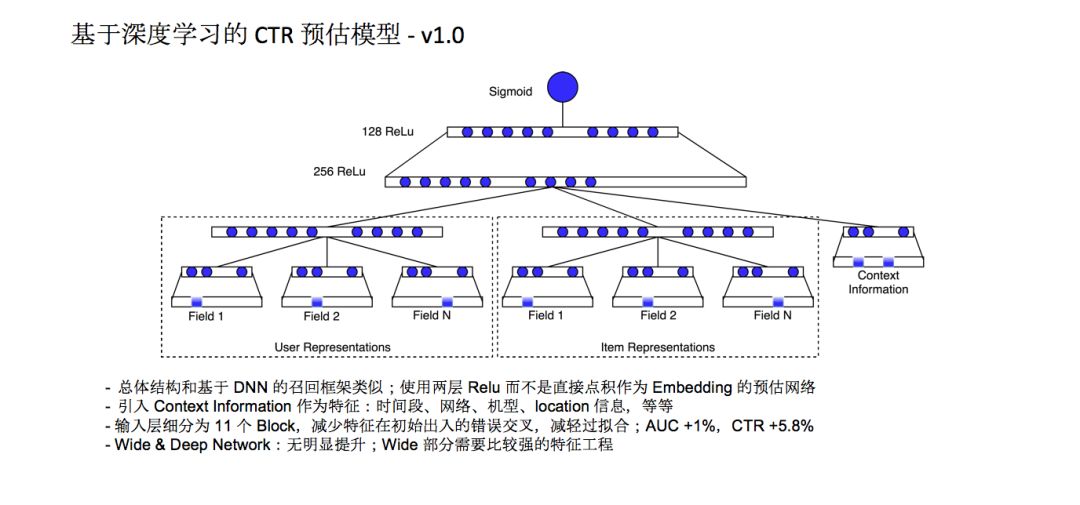
使用了DNN之后,我们还试用了谷歌出品的Wide & Deep Network,Deep是图上部分,效果没有明显的提升。随后我们做了一个分析判断,发现Wide & Deep Network的 wide 部分,都会在原始特征输入交叉方面做一个比较强的特征工程,否则所有信息在Deep部分已经得到比较好的应用,Wide 部分并没有提供什么额外的输入,也不会拿到特别好的数据表现。
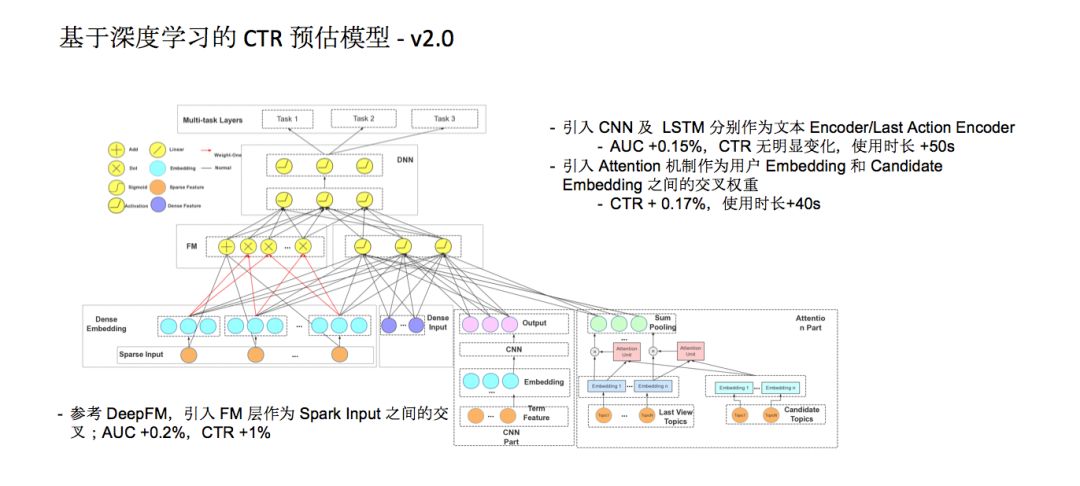
今年我们开始在深度学习的CTR预估模型上尝试更加激进更有意思的优化,也就是2.0版本。其中最早引入的优化还是特征之间的交叉,我们引入FM层作为这些类别之间的Sparse Input之间的交叉,AUC提升了0.2%,CTR提升了1%。引入CNN及LSTM分别作为文本Encoder/Last Action Encoder,单用户使用时长提高50秒。
第三个trick参考了阿里的一篇论文,我们引入Attention机制作为用户Embedding和CandidateEmbedding之间的交叉权重。举个例子,用户点击的十篇文章中,有九篇是关于体育的一篇是关于互联网的,等到下次体育相关内容的分数会比互联网相关内容的分数高得特别离谱,平均之后互联网信息淹没在体育信息里,但互联网内容也是用户喜欢的,权重却很难发挥出来。我们引入Attention机制,把用户的阅读历史跟当前候选集里相关的数据和权重学习之后,收到了良好效果,单用户使用时长增加了40秒左右。
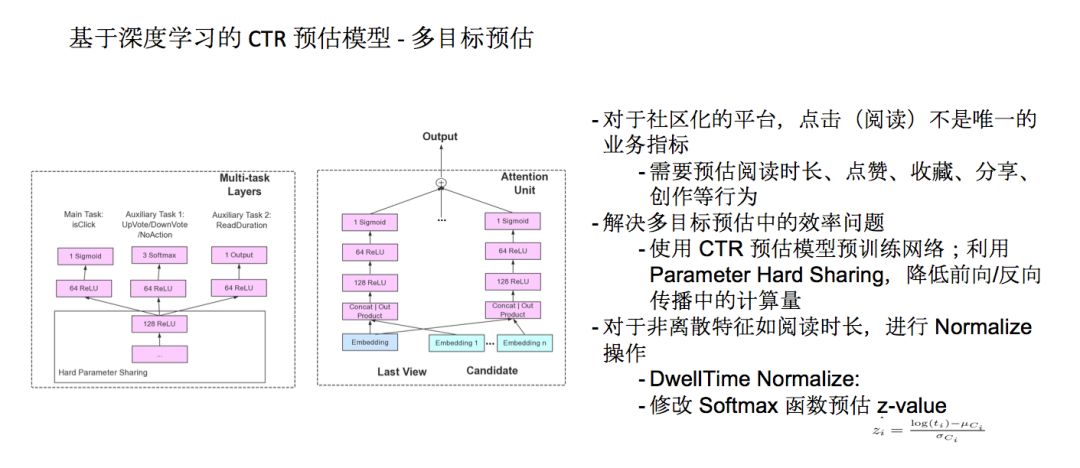
知乎是一个社区化的平台,常常需要平衡很多指标的收益,预估阅读时长、点赞、收藏、分享、创作等行为。为了解决多目标预估中训练和预测效率问题,我们使用了CTR预估模型预训练网络,利用Parameter Hard Sharing,点击和点赞这两层共享之前的权重,会有一个独立的隐藏层model task自己的目标,这样能降低前向/反向传播中的计算量。
我们常常预估到一些非离散的目标,对于非离散目标如阅读时长,很多同行的做法是线性预估的方式预估,你阅读了60秒,我尽量把预测的值逼近。知乎的做法是,把一篇文章的阅读时长做一个Normalize操作。我们观察了一下阅读时长的分布,这个分布与正态分布比较类似。所以我们使用了 z-value 来对阅读市场进行离散化,离散化之后会把阅读时长分为五等——没点击、点击了阅读时长低、点击了阅读时长中等、点击了阅读时长偏高、点击了阅读时长非常高——将连续值预测转化成离散值预测。
在训练过程中,我们也修改了 Softmax 函数,如果预测出的档数和实际用户阅读时长档数差太多,我们加一个比较大的修改函数,让这种样本的 loss 加大。阅读时长这个模型上线之后,对知乎的使用时长和单篇文章的阅读时长都有提升。
四、Feed流推荐系统中遇到的实际问题
模型训练问题
样本组织方面,大家可以看到刚才我们用了很多实时特征,这些实时特征对用户和样本来讲都是不断变化的,最初知乎组织这些样本的时候都是使用从离线库里Join数据的方式做特征的梳理,后来我们发现线上往往会出现特征穿越的状况,你在线下记录的日志毕竟不是实时的,日志都是流失的放到数据库里,处理数据流的过程中也会出现顺序上的错误,所以我们会在线上进行实施打点避免穿越。
对于CTR预估的正向样本和负向样本,后者与前者相比存在几倍的量级差异。通常我们会对正负样本进行不同采样率的实验,不同的业务指标下采样率不一样,最终回有一个最佳的采样率。但采样率多少跟数据的分布和业务需要预估的指标特性相关,1比1不一定是最好的采样比例。
特征工程方面,我们在实际应用场景里发现对于分布范围比较大的特征,有一万个赞也有几万个赞的,做CTR预估的过程中赞量的影响会变得非常不平均,所以通常会进行特征的归一化和boxing,分成不同的段输入到CTR预估模型里达到比较好的效果。
模型评估方面,AUC是基础指标,我们发现AUC是一个特别基础的指标,对于两份离线文件之间的评估确实有比较大的意义,尤其AUC在现在状态下大家都训练到0.7或0.8的水平,上线之后各种数据指标并不一定能提升那么多,我们做了一个DCG Gain收益的指标,它具有更高的参考意义。
业务问题
多样性问题如何解决?大家都知道Feed流里很多时候最精准不一定是用户最想要的,重复太多对于各种线上业务数据的改进也不一定是正向的结果,我们会引入各种框架进行业务导向的调权、打散、隔离和禁闭,一个内容出现几次之后你没有点击,之后都不会推荐相似的内容。
如何避免「信息茧房」的产生?以各种行为表现预估的方式去排序和推荐的推荐系统,最后会让用户传递一个信息茧房,推荐列表里翻来覆去就是这么几个内容。我们的解决方案是,采用一个Explore & Exploit机制,针对老用户及兴趣比较均匀的用户,适当减少兴趣探测手段,在探测过程中也会尽量使用Tag之间的关联信息增强探测效率。
-【完】-
精彩推荐
◆
BDTC 2018
◆
2018 中国大数据技术大会将于 12 月 6 - 8 日在新云南皇冠假日酒店举行。汇聚超百位国内外实力讲师从学界翘楚到行业一线大拿:
管晓宏:中国科学院院士;
张宏江:源码资本投资合伙人;
张晓东:美国俄亥俄州立大学 Robert M. Critchfield 讲席教授;
陈性元:北京信息科学技术研究院副院长;
周靖人:阿里巴巴集团副总裁;
李浩源:Alluxio 公司创始人&CEO
......
全方位立体解读大数据时代的技术进程,为众技术爱好者奉上一场优质干货盛宴。

推荐阅读
公开课报名 | 详解CNN-pFSMN模型以及在语音识别中的应用
干货(附源代码) | 爬取一万条b站评论,分析9.7分的新番凭啥这么火?
程序员如何 Get 分布式锁的正确姿势?
让你崩溃无语的程序命名有哪些?
2年2亿美金,澳本聪耗得起BCH内战又怎样?
刚写完排序算法,就被开除了…
胜过iPhone XS?Google Pixel的“夜视功能”是怎样炼成的
相关文章:

[Web开发] 微软的RSS协议扩展 - FeedSync 介绍 (4)
上一篇文章介绍了在2台电脑上同时修改数据的feedsync 同步过程, 今天再讨论一下当在2台电脑上同时删除同一个数据的情况。 假设最初feed 里面数据是这样的<item><sx:sync id"ep2.100" updates"1" deleted"false" noconflict…
weblogic 修改控制台密码
关掉weblogic所有进程切换到域下面$cd /home/weblogic/Oracle/Middleware/user_projects/domains/jydomain/security$java -classpath /home/weblogic/Oracle/Middleware/wlserver_10.3/server/lib/weblogic.jar weblogic.security.utils.AdminAccount weblogic weblogic123 …

WPF框架的内存泄漏BUG
用户在使用GIX4某模块的过程中,内存只见加不见减。我们怀疑出现了内存泄漏,所以我花了相当一段时间来进行此问题的排查。 我使用Red Gate公司的产品ANTS Memory Profiler 5进行应用程序的内存进行监视。并在过程中修改程序中出现的一些问题。但是最后留下…
java map深拷贝_java 实现Map的深复制
在java中有一个比较有趣的特性,在对对象进行赋值,或者clone时候一般都是我们所说的浅复制,Object A B;也就是说我们获取的并非在堆中重新分配的一块内存,而是一个指向原有数据内存的一个引用。这样的后果就是我们修改了A中的属性…

出门问问工程副总裁黄美玉入选IEEE Fellow,曾担任微软Cortana首席NLP科学家
虽然 IEEE(国际电子电气工程协会)2019 年的 Fellow 评选结果还未正式出炉,但记者刚刚获悉,IEEE Fellow 又新增一名华人科学家入选——出门问问工程副总裁、Mobvoi AI Lab 的负责人黄美玉博士。黄美玉博士是由于其在语音/语言技术领…

Windows2003服务器不支持FLV视频的解决方法
Windows2003服务器不支持FLV视频的解决方法2007年10月19日 星期五 10:43 A.M.原因:WIN2003加强了IIS6的MIME验证,一切未注册扩展文件格式统统显示404错误。手动在IIS中HTTP头->MIME添加MIME影射关系,MIME类型: video/x-flv 扩展名:.flv&am…
mpi并行 java_【并行计算】用MPI进行分布式内存编程(一)
通过上一篇关于并行计算准备部分的介绍,我们知道MPI(Message-Passing-Interface 消息传递接口)实现并行是进程级别的,通过通信在进程之间进行消息传递。MPI并不是一种新的开发语言,它是一个定义了可以被C、C和Fortran程序调用的函数库。这些函…
JQuery——选择器分类
JQuery选择器1 什么是JQuery选择器快速高效的找到指定节点,支持css语法设置页面2 JQuery选择器分类2.1 基本选择器CSS选择器层级选择器表单域选择器2.2 过滤选择器简单过滤选择器内容过滤选择器属性过滤选择器子元素过滤选择器表单域属性过滤选择器可见性过…
3月6日工作日志-88250
今天: 1. 与zy、vanessa一起使用mingle做了开发计划 2. 使用了XStream重写了XML格式的Dynamic Dictionary Basic Engine TODO: 1. 提高Dynamic Dict引擎的效率 2. 分片转换一部43W词汇的英-中词库(按字母、大小写分片) 转载于:https:/…

专注文本处理,达观数据完成B轮融资,累计融资超2亿元
11月22日,达观数据宣布成功完成1.6亿元B轮融资,由宽带旗下基金晨山资本领投,元禾重元、联想之星、钟鼎资本及老股东等跟投。达观数据总部位于上海张江高科技园区,目前已在北京、成都、深圳、西安等地开设分支机构。2015年获真格基…
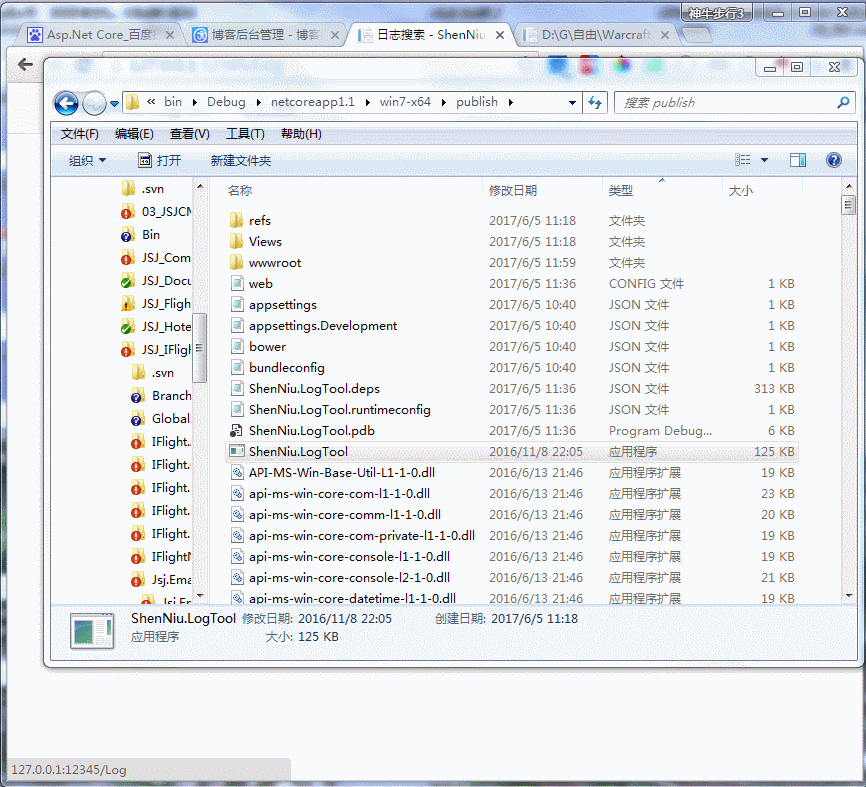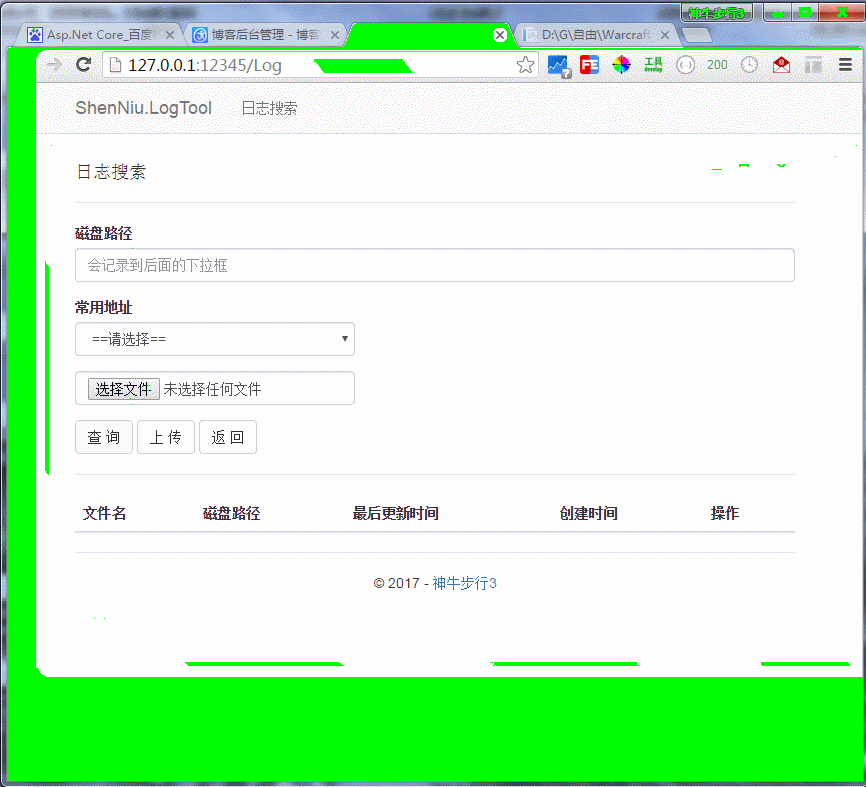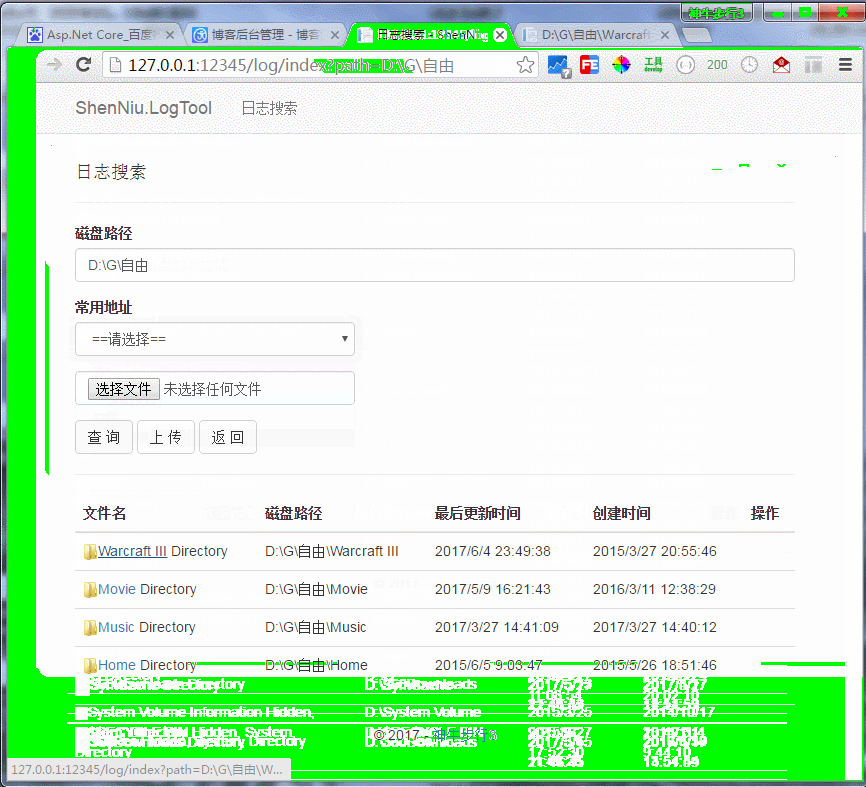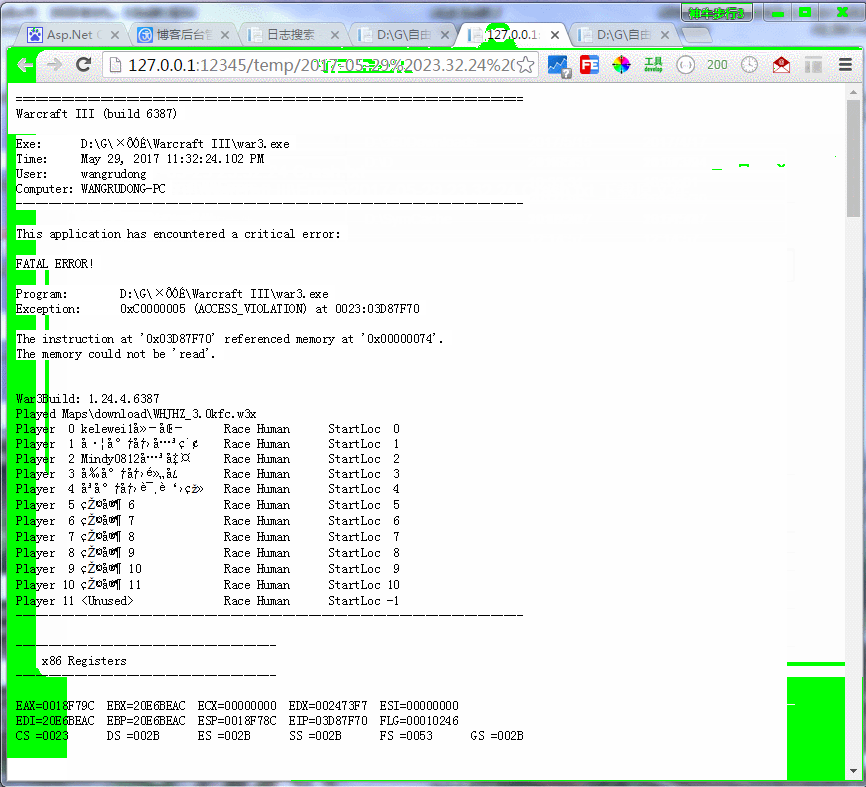
Asp.Net Core写个共享磁盘文件Web查看器
查看器功能说明与演示 本查看器主要是为了方便大家查看服务器上的日志,这里没有考虑其他安全性问题,比如特定人员登录才能查看,这个需要您们自己去增加;如果你服务器有对外开放了ip,那么运行这个软件的时候建议考虑配置…

ImageNet时代将终结?何恺明新作:Rethinking ImageNet Pre-training
译者 | 刘畅 林椿眄整理 | Jane出品 | AI科技大本营Google 最新的研究成果 BERT 的热度还没褪去,大家都还在讨论是否 ImageNet 带来的预训练模型之风真的要进入 NLP 领域了。如今,Facebook AI Research 的何恺明、Ross Girshick 及 Piotr Dollar 三位大佬…
java 序列化 缓存_java_缓冲流、转换流、序列化流
一、缓冲流缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。字节缓冲流构造方法创建字节缓冲输入流:BufferedInputStream bi…
QQ2007去广告教程(本地vip)
只要是vip就可以去掉广告了 关键函数QQHelperDll.dll的IsQQServiceEnable 在入口点修改: mov eax,1 retn 好了这样就成了本地的vip了 因为那个dll的版本太多了不能通用,所以就不提供下载了(我的版本7.1.644.1777) 同时qq每次升级都有可能替换…
java instanceof 报错_java instanceof方法
基本用法null instanceof Object 为false; null instanceof 任意类 为false;任意实例 instanceof 对应的类或者父类 都为true;基本数据类型 instanceof Object 编译时会报错(如 int a;a instanceof Object 编译不通过)ÿ…
grep的常用命令语法
grep的常用命令语法 1. 双引号引用和单引号引用 在g r e p命令中输入字符串参数时,最好将其用双引号括起来。例如:“m y s t r i n g”。这样做有两个原因,一是以防被误解为 s h e l l命令,二是可以用来查找多个单词组成的字符串&…

千呼万唤始出来!OpenCV 4.0正式发布!
作者 | 周强(本文为作者独立观点,转载请联系作者)来源 | 我爱计算机视觉OpenCV 4.0 正式版来啦!重回英特尔的 OpenCV 终于迎来一次大版本更新,增加了诸多新特性,快来一起看看吧~因为 OpenCV 最开…
ORA-01031: insufficient privileges的解决方法
原文出自:http://www.chinaunix.net/jh/19/132866.html############################################# # # NAME: troubleshoot connect internal.txt # # DESCRIPTION: # connect internal # connect / as sysdba 要口令问题:# refer (METALINK,ORACLEDOC), # me…
java 线程通讯_java多线程(五)线程通讯
1.1. 为什么要线程通信多个线程并发执行时,在默认情况下CPU是随机切换线程的,有时我们希望CPU按我们的规律执行线程,此时就需要线程之间协调通信。1.2. 线程通讯方式线程间通信常用方式如下:l 休眠唤醒方式:Object的w…

合并排序(C语言实现)
递归算法是把一个问题分解成和自身相似的子问题,然后再调用自身把相应的子问题解决掉。这些算法用到了分治思想。其基本模式如下: 分解:把一个问题分解成与原问题相似的子问题 解决:递归的解各个子问题 合并:合并子问题…
工程实践也能拿KDD最佳论文?解读Embeddings at Airbnb
作者 | Mihajlo Grbovic,Airbnb 资深机器学习科学家译者 | Lang Yang,Airbnb 工程经理【导读】本文最早于 2018 年 5 月 13 日发表,主要介绍了机器学习的嵌入技术在 Airbnb 爱彼迎房源搜索排序和实时个性化推荐中的实践。Airbnb 爱彼迎的两位…
计算点、线、面等元素之间的交点、交线、封闭区域面积和闭合集(续1)
继续上一节的内容,本节主要讲解三维空间中射线、线段与平面及三维物体的交点及距离的计算,它们在碰撞检测和可见性剔除等应用中是必不可少的。首先给出3D空间下点乘和叉乘的定义与定理的推导,再谈如何应用到程序编码的工作中。 设三维空间中任…

android 抓取native层奔溃
使用android的breakpad工具 使用这个工具需要下载Breakpad的源码,然后进行编译,编译之后会生成两个工具 我们使用这两个工具来解析奔溃的位置。这里我们可以下载已经编译好的工具 下载地址是:链接:http://pan.baidu.com/s/1jIiU5c…

渗透各行各业,这家RPA外企宣布全面进军中国市场
11月15日,全球机器人流程自动化(RPA)领域平台UiPath首次在中国举办UiPath Together年度大会,来自自动化、人工智能和机器学习领域的行业专家,以及来自中国和世界的领先公司的客户与合作伙伴共同参与了此次活动。在此次…
java gettext_JAVA中getText()怎么从一个JTextArea中读出内容?
想先创建一个JTextArea,然后在里面输入内容(几个字母),然后用getText读出里面的内容,可是好像只能是先在JTextArea里面写,然后getText才能读出,而不能先运行,在图形界面的JTex...想先创建一个JTextArea&…

想在SqlDbHelper.cs类中加的垃圾方法
虽然没改写SqlDbHelper.cs类的能力,但好不容易想出来的,放着留个纪念~~~~~/**//// <summary> /// 执行SQL语句,返回第一行,第一列(sea) /// </summary> /// <param na…
java全站_javaWeb_全站编码
目的 : 实现javaweb项目的全站编码问题需要解决的问题 : 在何时进行编码问题的解决, 在何处进行编码问题的解决, 才用什么方法进行解决设计思路 : 在Filter进行全站的编码转换, 对于GET请求 : 使用装饰者模式(是你有你一切拜托你), 修改Request.getParameter()方法, 在getparam…
在Linux系统中修改目录的权限如何恢复
在我工作中的某一天执行了chmod -R 777 /home后我十分后悔,这下不知道该怎么办?心里面很是着急。此时灵机一动问了一下谷哥,终于找到了方法解决此问题,不过前提是要自己做了文件权限备份工作,现在我就给大家讲解一下我…
.Net Framework 3.5 结构图
从打印社用A0或A1的纸打出来,大概10RMB,看起来超爽。 转载于:https://www.cnblogs.com/habin/archive/2008/03/15/1107196.html

关于CVPR 2019投稿的一些感想
作者 | 胡国圣,英国 anyvision 高级研究员,从事深度学习,人脸识别的研究。一年一度的 CVPR 是人工智能的机器视觉方向最重要的学术会议,每年吸引都会全球最顶尖的大学和公司的研究人员投稿,文章如果被录用,…