如何用机器学习方法进行数据建模?(文末福利)

本文节选自CCF大数据教材系列丛书之《大数据导论》,由中国科学院院士梅宏主编。本书系统地介绍大数据涵盖的内容,包括数据与大数据概述、大数据感知与获取、大数据存储与管理、大数据分析、大数据处理、大数据治理、大数据安全与隐私等。
近年来,数据资源的不断丰富、计算能力的快速提升, 推动数据驱动的智能快速兴起。大量智能应用通过对数据的深度融合与 挖掘,帮助人们采用新的视角和新的手段,全方位、全视角展现事物的 演化历史和当前状态,掌握事物的全局态势和细微差别;归纳事物发展 的内在规律,预测预判事物的未来状态;分析各种备选方案可能产生的 结果,从而为决策提供最佳选项。当然,第三次浪潮还刚刚开启、方兴 未艾,大数据理论和技术还远未成熟,智能化应用发展还处于初级阶段。 然而,聚集和挖掘数据资源,开发和释放数据蕴含的巨大价值,已经成 为信息化新阶段的共识。——梅宏
(1)按搜索策略划分特征选择算法
根据算法进行特征选择所用的搜索策略,可以把特征选择算法分为采用全局最优搜索策略、随机搜索策略和启发式搜索策略3类。
(2)评价函数
评价函数的作用是评价产生过程所提供的特征子集的好坏。根据其工作原理,评价函数主要分为筛选器(filter)和封装器(wrapper)两大类。
筛选器通过分析特征子集内部的特点来衡量其好坏。筛选器一般用作预处理,与分类器的选择无关,常用的度量方法有相关性、距离、信息增益、一致性等。
运用相关性来度量特征子集的好坏是基于这样假设:好的特征子集所包含的特征应该是与分类的相关度较高,而特征之间相关度较低的;运用距离度量进行特征选择是基于这样的假设:好的特征子集应该使得属于同一类的样本距离尽可能小,属于不同类的样本之间的距离尽可能大;使用信息增益作为度量函数的动机在于:假设存在特征子集A和特征子集B,分类变量为C,若A的信息增益比B大,则认为选用特征子集A的分类结果比B好,因此倾向于选用特征子集A。一致性指的是:若样本1与样本2属于不同的分类,但在特征A和B上的取值完全一样,那么特征子集{A, B}不应该选作最终的特征集。
筛选器由于与具体的分类算法无关,因此其在不同的分类算法之间的推广能力较强,而且计算量也较小。
封装器实质上是一个分类器,封装器用选取的特征子集对样本集进行分类,分类的精度作为衡量特征子集好坏的标准。封装器由于在评价的过程中应用了具体的分类算法进行分类,因此其推广到其他分类算法的效果可能较差,而且计算量也较大。使用特定的分类器,用给定的特征子集对样本集进行分类,用分类的精度来衡量特征子集的好坏。
数据建模
数据建模是从大数据中找出知识的过程,常用的手段是机器学习和数据挖掘。所谓数据挖掘可以简单地理解为“数据挖掘 = 机器学习+数据库”。从商业层次来说,数据挖掘是企业按既定业务目标,对大量企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化。从技术层次来说,数据挖掘是通过分析,从大量数据中寻找其规律的技术。
机器学习
在心理学理论中,学习是指(人或动物)依靠经验的获得而使行为持久变化的过程。在机器学习场景下,不同的学者有不同的理解和定义。比如西蒙(Simon)认为:如果一个系统能够通过执行某种过程而改进它的性能,这就是学习;明斯基(M. Minsky)认为:学习是在人们头脑中(心理内部)进行有用的变化;汤姆·米切尔(Tom M. Mitchell)认为:对于某类任务T和性能度P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么,我们称这个计算机程序从经验E中学习。根据不同的分类准则,机器学习又可以分为不同的类别,具体参见表4-2。
表4-2 不同分类准则意义下的机器学习
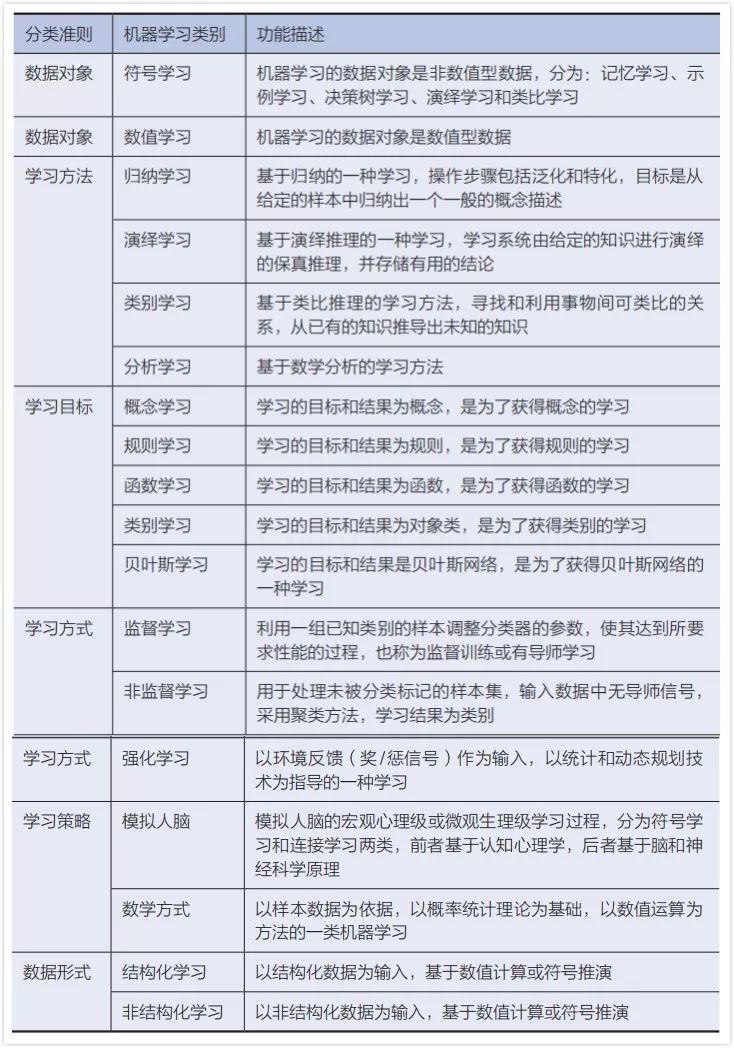
事实上,具体到每一个机器学习方法,根据上述不同的分类准则,可能会归属到一个或多个类别中。
非监督学习
在非监督学习(unsupervised learning)中,数据并不会被特别标识,学习模型是为了推断出数据的一些内在结构。非监督学习一般有两种思路:
(1)第一种思路是在指导Agent时不为其指定明确的分类,而是在成功时采用某种形式的激励制度。需要注意的是,这类训练通常会被置于决策问题的框架里,因为它的目标不是产生一个分类系统,而是做出最大回报的决定,这类学习往往被称为强化学习。
(2)第二种思路称之为聚合(clustering),这类学习类型的目标不是让效用函数最大化,而是找到训练数据中的近似点。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括关联规则挖掘、K-Means、EM等。
关联规则挖掘
顾名思义,关联规则挖掘就是从数据背后发现事物(务)之间可能存在的关联或者联系。比如数据挖掘领域著名的“啤酒-尿不湿”的故事(这个故事的真假不论)就是典型的关联规则挖掘发现的有趣现象。在关联规则挖掘场景下,一般用支持度和置信度两个阀值来度量关联规则的相关性(关联规则就是支持度和信任度分别满足用户给定阈值的规则)。所 谓 支 持 度(support), 指 的 是 同 时 包 含X、Y的 百 分 比, 即P(X, Y);所谓置信度(confidence)指的是包含X(条件)的事务中同时又包含Y(结果)的百分比,即条件概率P(Y|X),置信度表示了这条规则有多大程度上可信。
关联规则挖掘的一般步骤是:首先进行频繁项集挖掘,即从数据中找出所有的高频项目组(frequent itemsets,满足最小支持度或置信度的集合,一般找满足最小支持度的集合);然后进行关联规则挖掘,即从这些高频项目组中产生关联规则(association rules,既满足最小支持度又满足最小置信度的规则)。
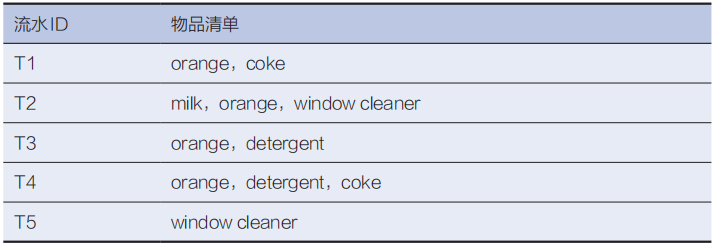
引用一个经典用例解释上述的若干概念,使用的数据集如表4-3所示,该数据集可以认为是超市的购物小票,第一列表示购物流水ID,第二列表示每个流水同时购买的物品。
表4-3 超市购物流水
计算示例1:计算“如果orange则coke的置信度”,即P(coke|orange),从上述的购物流水数据中可以发现,含有orange的交易有4个(分别是T1、T2、T3、T4),在这4个项目中仅有两条交易含有coke(T1、T4),因此
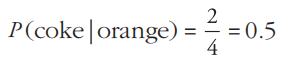
计算示例2:计算在所有的流水交易中“既有orange又有coke的支持度”,即P(orange, coke),从上述的购物流水数据中可以发现,总计有5条交易记录(T1、T2、T3、T4、T5),既有orange又有coke的记录有两条(T1、T4),因此
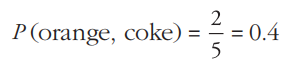
上述两个计算示例总结出的关联规则是:如果一个顾客购买了orange,则有50%的可能购买coke。而这样的情况(即买了orange会再买coke)会有40%的可能发生。
K-Means算法
K-Means算法是典型的基于距离的聚类算法,K-Means认为:
(1)两个对象的距离越近,其相似度就越大。
(2)相似度接近的若干对象组成一个聚集(也可称为“簇”)。
(3)K-Means的目标是从给定数据集中找到紧凑且独立的簇。
K-Means中的“K”指的就是在数据集中找出的聚集(“簇”)的个数,在K-Means算法中,此“K”的大小需要事先设定,K-Means的算法流程如下:
输入:数据集,K
输出:K个聚集
Step-1:从N个数据对象中任意选择K个对象作为初始聚类中心,记为
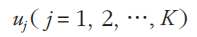
Step-2:根据每个聚类对象的均值(中心对象),计算每个对象与
这些中心对象的距离,并根据最小距离重新对相应对象进行划分,即
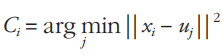
Step-3:重新计算每个(有变化)聚类的均值(中心对象),即
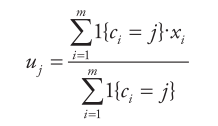
Step-4:循环Step-2到Step-3直到每个聚类不再发生变化(收敛)为止。
K-Means聚类算法的优点集中体现在(不限于):
(1)算法快速、简单。
(2)对大数据集有较高的计算效率并且可伸缩。
(3)时间复杂度近于线性,适合挖掘大规模数据集。K-Means聚类算法的时间复杂度是Q (N·K·T ),其中N代表数据集中对象的数量;T代表着算法迭代的次数;K代表着簇的数目;一般而言:K<<N且T<<N。
K-Means的缺陷集中体现在(不限于):
(1)在K-Means算法中,K是事先设定的,而K值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该被分成多少个类别才最合适。
(2)在K-Means算法中,初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择得不好,可能无法得到有效的聚类结果。
(3)K-Means算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。
监督学习
监督学习(supervised learning)是指:利用一组已知明确标识或结果的样本调整分类器的参数,使其达到所要求性能的过程,也称为有教(导)师学习。所谓“监督”或者“有教(导)师”指的是监督学习必须依赖一个已经标记的训练数据(训练集)作为监督学习的输入(学习素材)。训练集是由若干个训练实例组成,每个实例都是一个属性集合(通常为向量,代表对象的特征)和一个明确的标识(可以是离散的,也可以是连续的)组成。监督学习的过程就是建立预测模型的学习过程,将预测结果与训练集的实际结果进行比较,不断地调整预测模型,直到模型的预测结果达到一个预期的准确率。
根据训练集中的标识是连续的还是离散的,可以将监督学习分为两类:回归和分类。前者对应于训练集的标识是连续的情况,而后者适用于训练集的标识是离散的场景,离散的标识往往称为类标(label)。
回归
回归是研究一个随机变量Y或者一组随机变量Y ( y1, y2, …, yn )对一个属性变量X或者一组属性变量X (x1, x2, …, xn )的相依关系的统计分析方法,通常称X或者X (x1, x2, …, xn )为自变量,称Y或者Y ( y1, y2, …, yn )为因变量。当因变量和自变量的关系是线性时,则称为线性模型(这是最简单的一类数学模型)。当数学模型的函数形式是未知参数的线性函数时,称为线性回归模型;当函数形式是未知参数的非线性函数时,称为非线性回归模型。
回归分析的一般过程是通过因变量和自变量建立回归模型,并根据训练集求解模型的各个参数,然后评价回归模型是否能很好地拟合测试集实例,如果能够很好地拟合,则可以根据自变量进行因变量的预测,回归分析的主要步骤是:
(1)寻找h函数(即hypothesis)。
(2)构造J (W )函数(又称损失函数)。
(3)调整参数W使得J (W )函数最小。
1. 线性回归
线性回归模型假设自变量(也称输入特征)和因变量(也称目标值)满足线性关系。为了便于叙述,取自变量为X (x1, x2, …, xn ),因变量为Y,训练参数为W (w1, w2, …, wn )。
(1)目标数学模型函数定义为
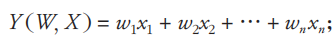
(2)基于最小二乘定义损失函数为
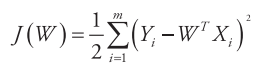
其中Xi和Yi分别表示训练集中第i个样本的自变量和因变量,m表示训练集的个数,前面乘上系数(1/2)是为了求导的时候,使常数系数消失。
(3)调整参数W使得J (W )最小,即
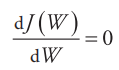
具体的方法有梯度下降法、最小二乘法等,下面先以梯度下降法介绍求解思路:对W取一个随机初始值,然后不断地迭代改变W的值使J减小,直到最终收敛(取得一个W值使得J (W )最小)。W的迭代更新规则如下
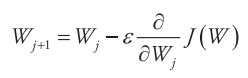
其中,ε称为学习率(Learning Rate),j表示W的迭代次数,将J (W )代入上式得到:
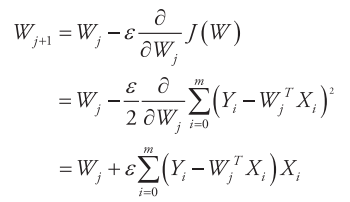
此更新规则称为最小均方LMS(least mean squares,LMS)更新策略,也称为Widrow-Hoff learning rule,从此更新公式可以看到,W的每一次迭代都考察训练集的所有样本,这种更新策略称为批量梯度下降(batch gradient descent)。还有一种更新策略是随机梯度下降(stochastic gradient descent),其基本思路是:每处理一个训练样本就更新一次W。相比较而言,由于batch gradient descent在每一步都考虑全部数据集,因而复杂度比较高;随机梯度下降会比较快地收敛。在实际情况中两种梯度下降得到的最优解J (W )一般都会接近真实的最小值,所以对于较大的数据集,一般采用效率较高的随机梯度下降法。
为了便于理解上述的计算流程,以一个具体的示例加以说明,示例设置如下。
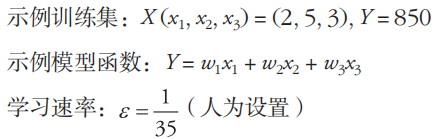
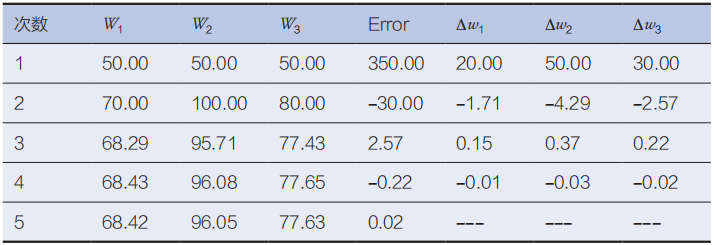
整个训练过程中各个参数变化如表4-4,为了便于阅读,将每次迭代W的变化罗列在表中,即表中的∆w1、∆w2、∆w3。
为了表示方便,表4-4中的数值均保留两位小数,并且仅显示了5步迭代的计算过程(假定0.02是可以接受的误差),从表4-4可见,经过5步迭代后可得到回归模型函数是
表4-4 简单迭代过程示意
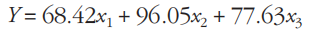
事实上,对于形如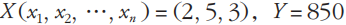 的样本,其模型或许是
的样本,其模型或许是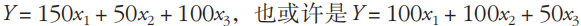 ,这意味着两点:
,这意味着两点:
(1)从回归的角度而言,结果可能并不唯一。
(2)回归结果未必是数据样本本来的模型。
对于后者,如果有更多的学习样本,或许会有利于结果更加逼近训练集背后的模型,这或许也是大数据时代,为什么要更热衷于“大”的数据,因为,唯有以更“大”的数据作为支撑,才有可能发掘数据背后的那个知识或模型。
刚才提及的更新策略是梯度下降法,需要多次迭代,相对比较费时而且不太直观。除了梯度下降法以外,还有最小二乘法更新策略。最小二乘法的计算思路是基于矩阵论,将权值的计算从梯度下降法的迭代改为矩阵计算,经过推导可以知道
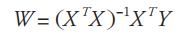
限于篇幅原因,此处不做具体的推导。无论是梯度下降法还是最小二乘法,其在拟合的过程中都是基于X (x1, x2, …, xn )中“每一个属性的重要性(权重)是一样”的这样假设,而这在实际场景中未必适用(往往会产生过拟合或者欠拟合的现象),针对这种情况就产生了加权的线性回归的思路,其本质是对各个元素进行规范化处理,对不同的输入特征赋予了不同的非负值权重,权重越大,对于代价函数的影响越大。
特 别 值 得 一 提 的 是: 上 述 提 到 的 线 性 回 归 模 型Y (W, X ) =
w1x1 + w2x2 + … + wn xn,所谓的线性是对参数W而言的,并非一定是输入X (x1, x2, …, xn )的线性函数,比如可以通过一系列的基函数ϕi (.)对输入
进行非线性变换,即
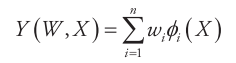
其中,ϕi (.)是基函数,可选择的基函数有多项式、高斯函数、Sigmoid函数等,简单介绍如下。
(1)多项式
多项式函数是由常数与自变量经过有限次乘法与加法运算得到的,定义如下
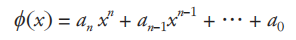
其中,ai (i = 0, 1, …, n)是常数,当n = 1时,多项式函数为一次函数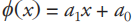 。
。
(2)高斯函数
高斯函数的形式如下
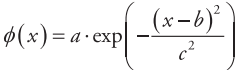
其中,a、b及c均是实常数,且a > 0。
(3)Sigmoid函数
Sigmoid函数是一个在生物学中常见的S函数,定义如下
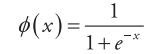
2. Logistic回归
Logistic回归一般用于分类问题,而其本质是线性回归模型,只是在回归的连续值结果上加了一层函数映射,将特征线性求和,然后使用g (z)作映射,将连续值映射到一个区间内,然后在该区间内取定一个阈值作为分类边界。根据映射函数g (z)的不同选择,其分类性能也不同,比如如果映射函数是Sigmoid函数时,其分类结果为0和1两类,而如果映射函数是双曲正弦sinh函数时,其分类结果则为1和-1两类。
以Sigmoid二值化(Sigmoid函数的特征是:当自变量趋于-∞,因变量趋近于0,而当自变量趋近于∞,因变量趋近于1)为例,为了便于后文的叙述,将Y (W, X )写作hW (X ),Logistic回归模型如下Logistic回归与多重线性回归实际上有很多相同之处,最大的区别就是他们的因变量不同,其他的基本都差不多。正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalized linear model)。Logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最为常用的就是二分类的Logistic回归。如果因变量是多分类的,则扩展为Softmax回归。Softmax回归模型是logistic模型在多分类问题上的推广,在Softmax回归中,类标签Y 可以取k (k > 2)个不同的值,其推导思路与Logistic回归相同,本文不再赘述。
分类
分类问题是机器学习研究中的一个重要问题,与回归问题类似,分类过程也是从训练集中建立因变量和自变量的映射过程。与回归问题不同的是,在分类问题中,因变量的取值是离散的,根据因变量的取值范围(个数)可将分类问题分为二分类问题(比如“好人”或者“坏人”)、三分类问题(比如“支持”、“中立”或者“反对”)及多分类问题。在分类问题中,因变量称为类标(label),而自变量称为属性(或者特征)。
根据分类采用的策略和思路的不同,分类算法包括(不限于):基于示例的分类方法(代表算法是KNN)、基于概率模型的分类方法(代表算法是朴素贝叶斯、最大期望算法EM)、基于线性模型的分类方法(代表算法是SVM)、基于决策模型的分类方法(代表算法包括:C4.5、AdaBoost、随机森林)等,下面简单介绍上述各种典型的分类算法的问题背景和算法思路。
1. KNN
K最近邻(k-nearest neighbor,KNN)分类算法是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的出发点是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。KNN算法则是从训练集中找到和新数据最接近的k条记录,然后根据他们的主要类别来决定新数据的类别。该算法涉及3个主要因素:训练集、距离或相似的度量、k的大小,算法的执行步骤如下:
输入:训练集(包括n个已经标注的记录(X, X ))、k、测试用例X (x1, x2, …, xn )
输出:测试用例的类标
Step-1:遍历训练集中的每个记录,计算每个记录属性特征Xi(i = 1, 2, …n)与测试用例X (x1, x2, …, xn )的距离,记为Di(i = 1, 2, …n);
Step-2:从Di (i = 1, 2, …n)中选择最小的k个记录(样本);
Step-3:统计这k个记录(样本)对应的类别出现的频率;
Step-4:返回出现频率最高的类别作为测试用例的预测类标。
KNN的思想很好理解,也容易实现。更重要的是:KNN算法不仅可以用于分类,还可以用于回归,具体思路是:通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(如权值与距离成反比),使得回归更加普适。但KNN算法的不足之处在于:
(1)每次分类都需要和训练集中所有的记录进行一次距离或相似度的计算,如果训练集很大,则计算负担很重。
(2)从上述记录流程中可以看出,如果k个近邻的类别属性各异,则就给分类带来了麻烦(需要其他策略支持)。
2.朴素贝叶斯
朴素贝叶斯分类是利用统计学中的贝叶斯定理来预测类成员的概率,即给定一个样本,计算该样本属于一个特定的类的概率,朴素贝叶斯分类基于的一个假设是:每个属性之间都是相互独立的,并且每个属性对分类问题产生的影响都是一样的。
贝叶斯定理由英国数学家贝叶斯(Thomas Bayes)发现,用来描述两个条件概率之间的关系,比如P (A|B)和P (B|A),其中P (A|B)表示事件B已经发生的前提下,事件A发生的概率,称为事件B发生下事件A的条件概率,其基本公式是
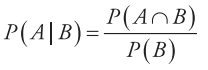
按照乘法法则
P (A∩B) = P (A) * P (B | A) = P (B) * P (A | B)
由上式可以推导得到

例,一座别墅在过去的20年里一共发生过2次被盗,别墅的主人有一条狗,狗平均每周晚上叫3次,在盗贼入侵时狗叫的概率被估计为0.9,问题是:在狗叫的时候发生入侵的概率是多少?
用贝叶斯的理论求解此问题,假设A事件为“狗在晚上叫”,B为“盗贼入侵”,则:
(1)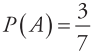 (计算根据:狗平均每周晚上叫3次)
(计算根据:狗平均每周晚上叫3次)
(2) (计算根据:过去20年发生过2次被盗)
(计算根据:过去20年发生过2次被盗)
(3) P (A|B)=0.9。(计算根据:B 事件发生时 A 事件发生的概率是 0.9)
基于上述数据,可以很容易地计算出A事件发生时B事件发生的概率P (B | A)是
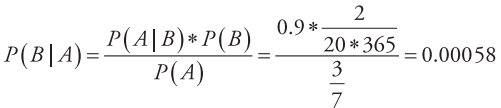
朴素贝叶斯分类的出发点是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。为了便于描述,将事件A表示为特征属性X (x1, x2, …, xn ),将事件B表示类标属性Y (y1, y2, …, ym ),则朴素贝叶斯分类问题可以描述为:
对于一个给定的测试样本的特征属性X (x1, x2, …, xn ),求其属于各个类标
yi(i = 1, 2, …, m)的概率P (yi | X )中的最大值,基于前面的定义可以知道
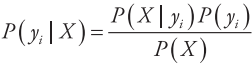
其中X表示特征属性(x1, x2, …, xn ),由于朴素贝叶斯是基于属性独立性的假设(前文已提及),故
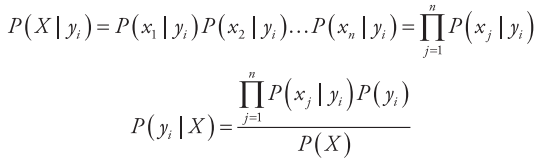
又由于P (X )是一个常数,因此只要比较分子的大小即可。朴素贝叶斯分类器的算法流程如下。
输入:训练集,测试用例X (x1, x2, …, xn)
输出:测试用例X (x1, x2, …, xn)的类标
Step-1:遍历训练集,统计各个类别下各个特征属性的条件概率估计,即P (xi | yi)(i = 1, 2, …, n; j = 1, 2, …, m)
Step-2:遍历训练集,根据上述公式,计算P (y1 | X ), P (y2 | X ), …,P (ym | X )
Step-3:如果P (yk | X ) = max{P (y1 | X ), P (y2| X), …, P (ym | X )},则测试用例的类标是yk。
为了更好地理解上述计算流程,以一个具体的实例说明。已知一个训练集如表4-5所示,特征属性有两个,分别是color和weight,其中,color的取值范围是{0, 1, 2, 3};weight的取值范围是{0, 1, 2, 3, 4}。类标属性有1个(sweet),取值范围是{yes, no}。
表4-5 训练集示意
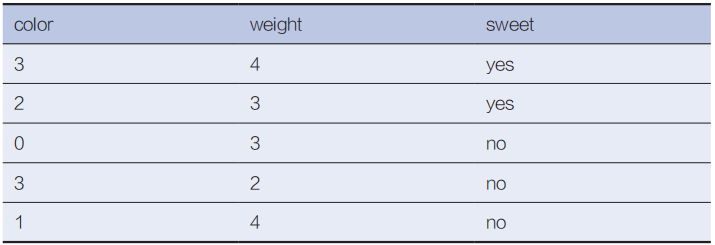
测试用例是(color = 3; weight = 4),求其类标。
遍历训练集,可以得到:
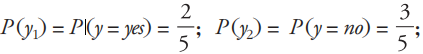
遍历训练集,可以得到:
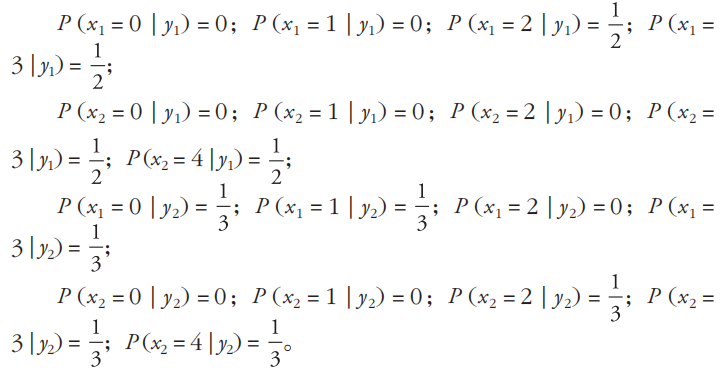
因为测试用例是(color = 3; weight = 4),所以
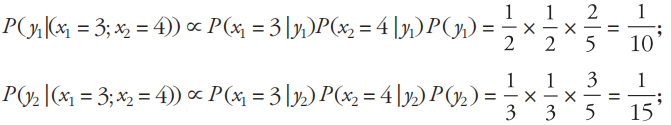
由于P (y1 | (x1 = 3;x2 = 4)) > P (y2 | (x1 = 3; x2 = 4)),故测试用例的类标是y1,即yes。
通过上述的计算实例可以发现,事实上,是没有必要把P (xi | yi)的所有可能均事先计算出来,而是根据测试用例的具体样本进行选择性的计算即可。理论上,朴素贝叶斯分类模型与其他分类方法相比具有最小的误差率,但其独立性假设在实际应用中往往是不成立的,这给朴素贝叶斯分类模型的正确分类带来了一定影响。针对这个缺点,也有一些改进的算法,此处不作罗列。
菜单升级啦,一键直通CSDN会员服务。你关心的开发问题,这里都有答案!
搜索:开发疑难/资源一键查找,搜遍CSDN全站
会员购买:专属VIP购买,免积分下载/免广告/获免费课程
下载APP:安装CSDN APP,CSDN资源随身带
个人中心:掌上CSDN个人助手,专属您的个人空间
2018 中国大数据技术大会
◆
BDTC 2018
◆
BDTC 2018中国大数据技术大会携主题“大数据新应用”再度强势来袭。现在购票即可获得中国科学院院士梅宏主编的《大数据导论》一书,数量有限哦~扫描下方二维码或点击【阅读原文】快速购票。

推荐阅读
孟岩对话元道:通证经济将在两个方向上闯出新路
AWS Lambda重大更新,跨越编程语言差异之门?
程序员婚恋现状大调查:有人三十岁没谈过恋爱,有人丁克万岁
C++20 要来了!
太嚣张了,会Python的人!
相关文章:

oracle1core,Oracle core06_latchlock
lock and latch在oracle中为了保护共享资源,使用了两种不同的锁机制lock和latch,这两种锁有明显不同点:1,lock和pin,采用的是队列的方式,先来先服务的策略,latch和mutex,采用的是抢占…

Foxmail6密码获取案例
Foxmail6密码获取案例 Simeon以前曾经写过一篇Foxmail5.0邮件账号以及密码获取的文章,对于Foxmail5.0中邮件账号密码获取相对较简单,可以通过星号密码查看器即可查看保留在Foxmail软件中的用户的密码,当然也还有其它的破解方式。但是在Foxmai…
新版CCNP中文版教材--ISCW
找了好久的新版CCNP中文教材,不过只有ISCW,希望能对想考NP的朋友有一点帮助![url]http://www.bibidu.com/fileview-696580.html[/url] 转载于:https://blog.51cto.com/xghe110/89352

杨超越的声音+高晓松的脸~如此酸爽的技术,你值得拥有!
作者 | 香港中文大学 Multimedia Laboratory译者 | linstancy整理 | Jane出品 | AI科技大本营什么是 Talking Face Generation 任务?简单来讲,给定音频或视频后,可以让任意一个人的面部特征与输入信息保持一致。比如在下面的 Demo 视频中&…
遍历数据键和值 php,php数组实例之获取当前数组键和值 each()
each()函数返回input_array的当前键/值对,并将指针推进一个位置。其形式如下:array each(array array)返回的数组包含四个键,键0和key包含键名,而键1和value包含相应的数据。如果执行each()前指针位于数组末尾,则返回f…
震后首游都江堰感怀
震后首游都江堰感怀题记:在地震刚刚过去2个月之时,来到都江堰参观有感——代腾飞 2008年7月12日 于都江堰千年水利都江堰地动山摇面不改但使沧容神尤在笑迎宾客八面来
安装linux和windows双系统
很多人一提到安装linux和windows双系统就会想到单独将磁盘划一个分区给linux,如果一块磁盘上已经安装了windows,并且所有分区都有数据,那就麻烦了,即使有了单独的分区,还需要安装grub,然后在grub中选择启动…

Office 365 系列之一:初识Office 365
最近项目越来越多,压力也是越来越大,而且到了年底了还要进行Office 365的考试,最近小编是在闲暇之余各种查看Office 365的资料,今天跟大家分享自己对 Office 365 的学习和理解,如有写得不对的地方还希望大家多 多指点哦…
oracle导出客户机使用us7a,导入 Oracle WORLD SAMPLE
Import WORLD SAMPLE C:\oraclexe\app\oracle\product\11.2.0\server\bin>imp system/oracle Import: Release 11.2.0.2.0 - Production on 星期五 10月 10 22:02:19 2014 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. 连接到: Oracle D…
AI做不了“真”3D图像?试试Google的新生成模型
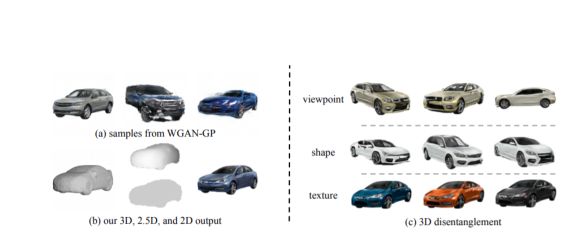
编译 | 若名出品 | AI科技大本营用 AI 生成逼真三维物体模型并不像人们以为的那么困难。近日,在 NeurIPS 2018 会议上接收的论文“ 视觉对象网络:图像生成与分离式的3D表示”中,麻省理工学院计算机科学与人工智能实验室(MIT CSAIL…
linux内核异常分析ecp,内核基于嵌入式Linux的PocketIX系统
lgms2008 于 2006-10-20 10:38:55发表:应用领域与前景目前PocketIX只是一个预览版,其正式版本不仅可以广泛应用于移动计算平台(PPC)、 家庭信息环境(机顶盒、数字电视)、 工业、商业控制(智能工控设备、POS/ATM机)等信息家电上,还可应用于与Internet相联…
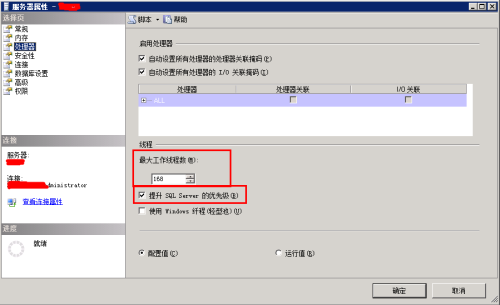
sharepoint性能优化
写几个配置,提高sharepoint性能的。主要思路是提高sql的查询能力,提高iis的硬件占用资源。 1、sql配置,管理器,点属性。配置最大工作线程数,勾选提升SQL server的优先级。配置后,重启sql服务,查…

倒计时1天,2018中国大数据技术大会报名通道即将关闭(附参会提醒)
2018 年12 月 6-8 日,由中国计算机学会主办,CCF大数据专家委员会承办,CSDN、中科天玑数据科技股份有限公司协办的 2018 中国大数据技术大会(BDTC),携主题“大数据新应用”再度强势来袭,直击大数…
DNN module.css文件不起作用的解决
DNN的模块会自动加载模块根目录下的module.css文件,但有时你加入了一个module.css文件,却发现加入的module.css文件没有被加载,这是为什么呢? 因为DNN的Cache机制和CSS加载机制,新加入的module.css没有立即被加载&…

搭建redis给mysql做缓存
安装redis的前提是lnmp或者lamp的环境已经搭建完成。 安装redis 1、安装redis(或可以选择yum安装) 123456789101112[rootredis ~]# wget -c -t 0 http://download.redis.io/releases/redis-2.8.19.tar.gz[rootredis ~]# mkdir /usr/local/redis[rootredi…

小米发力AI场景下的“快应用”,投百亿资源扶持开发者
近日,备受瞩目的2018 MIDC小米AIoT第二届开发者大会在京召开,雷军宣布AIloT是小米的核心战略,小米将和合作伙伴一起打造AIloT的美好明天。另外,大会还宣布了小米与宜家达成全球战略合作,宜家全系智能照明产品都将接入小…
arcgis 投影变换与坐标转换研究
arcgis 投影变换与坐标转换研究 1 ArcGIS中的投影方法 投影的方法可以使带某种坐标信息数据源进行向另一坐标系统做转换,并对源数据中的X和Y值进行修改。我们生产实践中一个典型的例子是利用该方法修正某些旧地图数据中X,Y值前加了带数和分带方法的数值。 字串9 操…
linux lvm 大小与硬盘大小关系,linux lvm扩容磁盘大小
关闭需要扩容的虚拟机,并通过管理虚拟机界面添加磁盘空间,本次调整50G注意,本次写入为增加容量的大小,并非增加完硬盘的大小硬盘添加后可以用fdisk -l 查看磁盘容量大小,可以看到硬盘增加了50G ,但是由于没…

无人驾驶汽车系统入门:基于VoxelNet的激光雷达点云车辆检测及ROS实现
作者 | 申泽邦(Adam Shan)兰州大学在读硕士研究生,主要研究方向无人驾驶,深度学习;兰大未来计算研究院无人车团队负责人,自动驾驶全栈工程师。之前我们提到使用SqueezeSeg进行了三维点云的分割,…
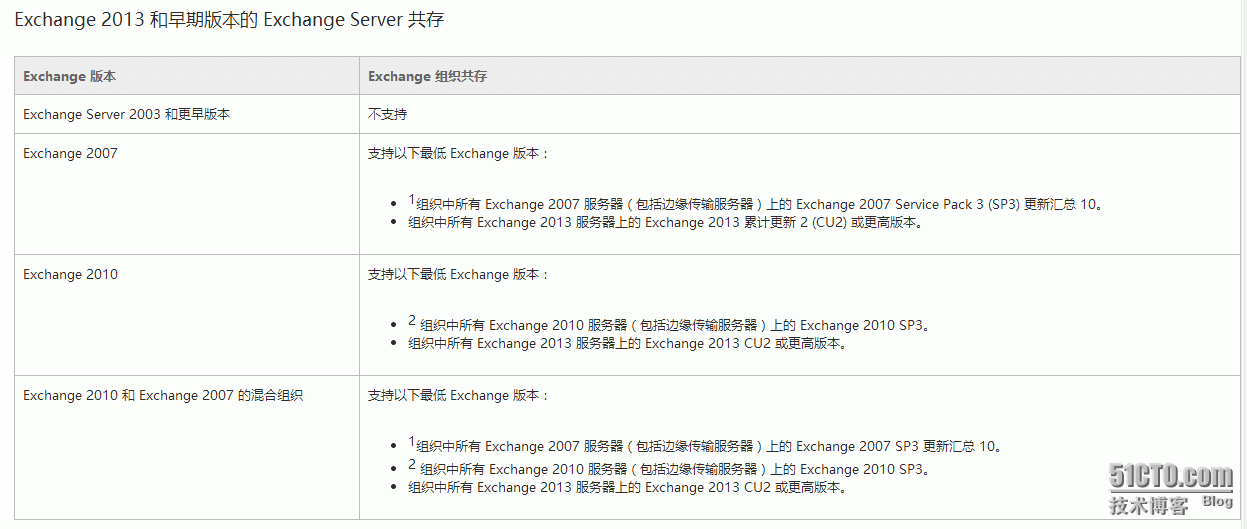
EX2010与EX2013共存迁移01-设计及说明
1.1共存条件说明 2013年之前发布的Exchange 2013版本是不支持共存的,只有在2013年4月2日发布的Exchange 2013 CU1版才支持共存,Exchange 2010必须为SP3版本才支持和2013共存及迁移,Exchange2003不支持和2013共存及迁移。下面是详细的共存说明…

linux ext4增加大小,如何修改 ext4 文件系统的大小
如何修改 ext4 文件系统的大小a. 扩大文件系统i启动到 Linux,umount 掉/dev/sdb1 和/dev/sdb2,若提示磁盘忙的话使用fuser 将正在使用磁盘的程序 kill 掉。(推荐使用另外的 Linux 启动盘来引导系统)ii使用 fdisk /dev/sdb 调整分区大小,进去之后,输入 p,记下要扩大分区起始位置…
Silverlight初级教程-开发工具
Silverlight初级教程 开发工具 在silverlight越来越流行的同时有很多的供应商开始筹划制作编辑和设计silverlight的工具。现在最常见的设计和开发工具是:Visual Studio 2008Visual Studio是微软整合的集成开发环境。截止此时Visual Studio 2008已经提供了编辑和预览…
201671010128 2017-11-12《Java程序设计》之图形程序设计
一、基本概念 Java的抽象窗口工具箱(Abstract Window Toolkit, AWT)包含在java.awt包中,它提供了许多用来设计GUI的组件类和容器类。AWT库处理用户界面元素的方法:把图形元素的创建和行为委托给本地GUI工具箱进行处理。应用AWT编写依赖于本地…
linux线程join的用法,join用法
Join用法- a 1显示第一个文件的不匹配行,- a 2为从第二个文件中显示不匹配行。n.m n为文件号,m为域号。1 . 3表示只显示文件1第三域,每个n,m必须用逗号分隔,如1 . 3,2 . 1。# cat name.txtM.Golls 12 Hi…
vss使用注意事项
连接方式 局域网方式连接 Internet 方式连接 在局域网方式连接时,需要输入自己的 vss 登陆帐号,账号可以通过管理器,自己在 vss 系统中注册; Internet 连接时默认使用的是 vss 中的 administrator 账号; 请大家都使用自…

沈向洋、黄学东等大咖助阵,IoT in Action微软深圳物联网大会即刻报名
每当海聊黑科技,总会有种恍然隔世的幻觉自动驾驶、无人配送、刷脸支付、智能翻译……物联网、人工智能、智能边缘等等新技术正在快速变得实用并普及怀疑论者还秉持观望,深怕技术布道之嫌而我们的现实中已经切实听见他们落地的声音因为“未来已经来临&…
centos6上以二进制方式安装mariadb5.5
准备mariadb-5.5.57-linux-x86_64.tar.gz二进制程序包 此包是经过编译的,也就是说我们要在特定的目录下安装; 步骤1、准备mysql用户 mkdir /app/data #此目录是存放mysql数据库、表的 useradd -r -m -d /app/data -s /sbin/nologin mysql #创建mysql用户…

“神人”or“闲人”?你的未来由AI与大数据决定
12 月 6 日,北京新云南皇冠假日酒店,由中国计算机学会主办,CCF 大数据专家委员会承办,CSDN、中科天玑数据科技股份有限公司协办的 2018 中国大数据技术大会(BDTC)首日议程圆满结束。本次大会为期三天&#…
linux 获取cpu id,linux获取cpu id和disk id
2013-04-19 15:17 57人阅读 评论(0)// 获得CPU IDpublic static final String CPU_ID_CMD "dmidecode -t 4 | grep ID |sort -u |awk -F: {print $2}";// 获得磁盘IDpublic static final String DISK_ID_CMD "fdisk -l |grep \"Disk identifier\" …

给gridview添加上下移动功能
给gridview添加上下移动功能存储过程代码:CREATE PROCEDURE [sp_trans_dept] now_id int,upside_id intASdeclare tmp_ordering int --临时变量declare sqlstr varchar(1000) --sql语句declare table_name varchar(500)declare column_name varchar(500)set t…