Python开发(基础):字符串
字符串常用方法说明
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# class str(basestring):
# """
# str(object='') -> string
#
# Return a nice string representation of the object.
# If the argument is a string, the return value is the same object.
# """
#
# def capitalize(self): # real signature unknown; restored from __doc__
# """
# 首字母大写
# S.capitalize() -> string
#
# Return a copy of the string S with only its first character
# capitalized.
# """
# return ""
#
str_capitalize = 'welcome'
print str_capitalize.capitalize()
#输出:Welcome
# def center(self, width, fillchar=None): # real signature unknown; restored from __doc__
# """
# 原字符串居中显示,两边可选择填充字符
# S.center(width[, fillchar]) -> string
#
# Return S centered in a string of length width. Padding is
# done using the specified fill character (default is a space)
# """
# return ""
str_center = 'hello'
print str_center.center(20,'*')
#输出:*******hello********
# def count(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
# """
# 字符串中某个子字符串出现的次数
# S.count(sub[, start[, end]]) -> int
#
# Return the number of non-overlapping occurrences of substring sub in
# string S[start:end]. Optional arguments start and end are interpreted
# as in slice notation.
# """
# return 0
#
str_count = 'helikdk;a'
print str_count.count('k')
#输出:2
# def decode(self, encoding=None, errors=None): # real signature unknown; restored from __doc__
# """
# 字符串解码
# S.decode([encoding[,errors]]) -> object
#
# Decodes S using the codec registered for encoding. encoding defaults
# to the default encoding. errors may be given to set a different error
# handling scheme. Default is 'strict' meaning that encoding errors raise
# a UnicodeDecodeError. Other possible values are 'ignore' and 'replace'
# as well as any other name registered with codecs.register_error that is
# able to handle UnicodeDecodeErrors.
# """
# return object()
#
# def encode(self, encoding=None, errors=None): # real signature unknown; restored from __doc__
# """
# 字符串编码
# S.encode([encoding[,errors]]) -> object
#
# Encodes S using the codec registered for encoding. encoding defaults
# to the default encoding. errors may be given to set a different error
# handling scheme. Default is 'strict' meaning that encoding errors raise
# a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
# 'xmlcharrefreplace' as well as any other name registered with
# codecs.register_error that is able to handle UnicodeEncodeErrors.
# """
# return object()
#
# def endswith(self, suffix, start=None, end=None): # real signature unknown; restored from __doc__
# """
# 判断字符串是否以什么结尾
# S.endswith(suffix[, start[, end]]) -> bool
#
# Return True if S ends with the specified suffix, False otherwise.
# With optional start, test S beginning at that position.
# With optional end, stop comparing S at that position.
# suffix can also be a tuple of strings to try.
# """
# return False
#
# def expandtabs(self, tabsize=None): # real signature unknown; restored from __doc__
# """
# 将字符串中的tab键替换成空格(默认是8个空格),也可自己指定
# S.expandtabs([tabsize]) -> string
#
# Return a copy of S where all tab characters are expanded using spaces.
# If tabsize is not given, a tab size of 8 characters is assumed.
# """
# return ""
#
str_expandtabs = 'hello\talex'
print str_expandtabs
print str_expandtabs.expandtabs(20)
#输出:hello alex
# hello alex
# def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
# """
# 查找字符串中子字符串第一次出现的位置(下标从0开始),也可指定从某个位置开始查找,或结束查找,
# 如果找不到就返回-1
# S.find(sub [,start [,end]]) -> int
#
# Return the lowest index in S where substring sub is found,
# such that sub is contained within S[start:end]. Optional
# arguments start and end are interpreted as in slice notation.
#
# Return -1 on failure.
# """
# return 0
#
str_find = 'kdlafjdklkdla'
print str_find.find('la',4)
#输出:11
# def format(self, *args, **kwargs): # known special case of str.format
# """
# 通过通配符来格式化字符串
# S.format(*args, **kwargs) -> string
#
# Return a formatted version of S, using substitutions from args and kwargs.
# The substitutions are identified by braces ('{' and '}').
# """
# pass
#
str_format = 'hell {0},age {1}'
print str_format.format('alex',19)
#输出:hell alex,age 19
# def index(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
# """
# 查找字符串中子字符串第一次出现的位置(下标从0开始),也可指定从某个位置开始查找,或结束查找,找不到会报错,功能同find类似
# S.index(sub [,start [,end]]) -> int
#
# Like S.find() but raise ValueError when the substring is not found.
# """
# return 0
str_index = 'kd;fjdkl;sfjkd;akd'
print str_index.index('fj')
#输出:3
# def isalnum(self): # real signature unknown; restored from __doc__
# """
# 判断字符串是否全部是字母和数字
# S.isalnum() -> bool
#
# Return True if all characters in S are alphanumeric
# and there is at least one character in S, False otherwise.
# """
# return False
#
str_isalnum = 'dafdfdk;j123'
print str_isalnum.isalnum()
#输出:False
# def isalpha(self): # real signature unknown; restored from __doc__
# """
# 判断字符串是否全部是字母
# S.isalpha() -> bool
#
# Return True if all characters in S are alphabetic
# and there is at least one character in S, False otherwise.
# """
# return False
#
# def isdigit(self): # real signature unknown; restored from __doc__
# """
# 判断字符串是否全部是字母和数字
# S.isdigit() -> bool
#
# Return True if all characters in S are digits
# and there is at least one character in S, False otherwise.
# """
# return False
#
# def islower(self): # real signature unknown; restored from __doc__
# """
# 判断是否全小写
# S.islower() -> bool
#
# Return True if all cased characters in S are lowercase and there is
# at least one cased character in S, False otherwise.
# """
# return False
#
# def isspace(self): # real signature unknown; restored from __doc__
# """
# 判断字符串是否为空(包括空格)
# S.isspace() -> bool
#
# Return True if all characters in S are whitespace
# and there is at least one character in S, False otherwise.
# """
# return False
#
# def istitle(self): # real signature unknown; restored from __doc__
# """# 判断是否标题(即:首字母大写,其他全部小写)
# S.istitle() -> bool
#
# Return True if S is a titlecased string and there is at least one
# character in S, i.e. uppercase characters may only follow uncased
# characters and lowercase characters only cased ones. Return False
# otherwise.
# """
# return False
#
# def isupper(self): # real signature unknown; restored from __doc__
# """
# 判断是否全大写
# S.isupper() -> bool
#
# Return True if all cased characters in S are uppercase and there is
# at least one cased character in S, False otherwise.
# """
# return False
#
# def join(self, iterable): # real signature unknown; restored from __doc__
# """
# 将list、元组等通过一个字符或字符串连接成一个字符串
# S.join(iterable) -> string
#
# Return a string which is the concatenation of the strings in the
# iterable. The separator between elements is S.
# """
# return ""
#
li = ['alex','age']
print '.'.join(li)
#输出:alex.age
# def ljust(self, width, fillchar=None): # real signature unknown; restored from __doc__
# """
# 左对齐,右边填充所给的字符
# S.ljust(width[, fillchar]) -> string
#
# Return S left-justified in a string of length width. Padding is
# done using the specified fill character (default is a space).
# """
# return ""
#
str_ljust = ' hello,where are you from ? ]'
print str_ljust.ljust(40,'*')
print str_ljust.ljust(50,"*")
#输出:
# hello,where are you from ? ]*******
# hello,where are you from ? ]*****************
# def lower(self): # real signature unknown; restored from __doc__
# """
# 将字符串转换为小写
# S.lower() -> string
#
# Return a copy of the string S converted to lowercase.
# """
# return ""
#
# def lstrip(self, chars=None): # real signature unknown; restored from __doc__
# """
# 去掉字符串左边的空格
# S.lstrip([chars]) -> string or unicode
#
# Return a copy of the string S with leading whitespace removed.
# If chars is given and not None, remove characters in chars instead.
# If chars is unicode, S will be converted to unicode before stripping
# """
# return ""
#
print ' dkla; fda; '.lstrip()
# def partition(self, sep): # real signature unknown; restored from __doc__
# """
# 根据的所级字符(或字符串),将原字符串拆分成三个部分组成一个元组,如果所给字符在字符串中找不到,返回的元祖由两个空字符串和原字符串本身组成
# S.partition(sep) -> (head, sep, tail)
#
# Search for the separator sep in S, and return the part before it,
# the separator itself, and the part after it. If the separator is not
# found, return S and two empty strings.
# """
# pass
#
str_partition = 'headseptail'
print str_partition.partition('sep')
#输出:('head', 'sep', 'tail')
# def replace(self, old, new, count=None): # real signature unknown; restored from __doc__
# """
# 替换字符串中的某个部份,可经指定替换几次
# S.replace(old, new[, count]) -> string
#
# Return a copy of string S with all occurrences of substring
# old replaced by new. If the optional argument count is
# given, only the first count occurrences are replaced.
# """
# return ""
#
# def rfind(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
# """
# 字符串中查找某个字符第一次出现的位置,从右边开始,用法同find(默认从左边开始)
# S.rfind(sub [,start [,end]]) -> int
#
# Return the highest index in S where substring sub is found,
# such that sub is contained within S[start:end]. Optional
# arguments start and end are interpreted as in slice notation.
#
# Return -1 on failure.
# """
# return 0
#
print 'dklfkd;fjdklsa'.rfind('dk')
#输出:9
# def rindex(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
# """
# 字符串中查找某个字符第一次出现的位置,从右边开始,用法同index(默认从左边开始)
# S.rindex(sub [,start [,end]]) -> int
#
# Like S.rfind() but raise ValueError when the substring is not found.
# """
# return 0
#
# def rjust(self, width, fillchar=None): # real signature unknown; restored from __doc__
# """
# 右对齐,左边填充所给的字符
# S.rjust(width[, fillchar]) -> string
#
# Return S right-justified in a string of length width. Padding is
# done using the specified fill character (default is a space)
# """
# return ""
#
print ' kfdls;k kldjklfdlk '.rjust(50,'*')
#输出:************************ kfdls;k kldjklfdlk
# def rpartition(self, sep): # real signature unknown; restored from __doc__
# """
# 用法同partition ,只是从右边开始
# S.rpartition(sep) -> (head, sep, tail)
#
# Search for the separator sep in S, starting at the end of S, and return
# the part before it, the separator itself, and the part after it. If the
# separator is not found, return two empty strings and S.
# """
# pass
#
# def rsplit(self, sep=None, maxsplit=None): # real signature unknown; restored from __doc__
# """
# 用法同split
# S.rsplit([sep [,maxsplit]]) -> list of strings
#
# Return a list of the words in the string S, using sep as the
# delimiter string, starting at the end of the string and working
# to the front. If maxsplit is given, at most maxsplit splits are
# done. If sep is not specified or is None, any whitespace string
# is a separator.
# """
# return []
s_rsplit = 'dkls;jfkdlak;jkdls;af'
print s_rsplit.rsplit(';')
#输出:['dkls', 'jfkdlak', 'jkdls', 'af']
# def rstrip(self, chars=None): # real signature unknown; restored from __doc__
# """
# 去掉字符串右边的空格
# S.rstrip([chars]) -> string or unicode
#
# Return a copy of the string S with trailing whitespace removed.
# If chars is given and not None, remove characters in chars instead.
# If chars is unicode, S will be converted to unicode before stripping
# """
# return ""
#
# def split(self, sep=None, maxsplit=None): # real signature unknown; restored from __doc__
# """
# 要据所给字符串字符串拆分成一个list
# S.split([sep [,maxsplit]]) -> list of strings
#
# Return a list of the words in the string S, using sep as the
# delimiter string. If maxsplit is given, at most maxsplit
# splits are done. If sep is not specified or is None, any
# whitespace string is a separator and empty strings are removed
# from the result.
# """
# return []
#
# def splitlines(self, keepends=False): # real signature unknown; restored from __doc__
# """
# S.splitlines(keepends=False) -> list of strings
#
# Return a list of the lines in S, breaking at line boundaries.
# Line breaks are not included in the resulting list unless keepends
# is given and true.
# """
# return []
#
# def startswith(self, prefix, start=None, end=None): # real signature unknown; restored from __doc__
# """
# 判断所给字符串是否以所给字符(或字符串)开头
# S.startswith(prefix[, start[, end]]) -> bool
#
# Return True if S starts with the specified prefix, False otherwise.
# With optional start, test S beginning at that position.
# With optional end, stop comparing S at that position.
# prefix can also be a tuple of strings to try.
# """
# return False
#
# def strip(self, chars=None): # real signature unknown; restored from __doc__
# """
# 去掉字符串左右两边的窗格
# S.strip([chars]) -> string or unicode
#
# Return a copy of the string S with leading and trailing
# whitespace removed.
# If chars is given and not None, remove characters in chars instead.
# If chars is unicode, S will be converted to unicode before stripping
# """
# return ""
#
print ' dksl klds '.strip()
#输出:dksl klds
# def swapcase(self): # real signature unknown; restored from __doc__
# """
# 大小写转换,大写变小写,小写变大写
# S.swapcase() -> string
#
# Return a copy of the string S with uppercase characters
# converted to lowercase and vice versa.
# """
# return ""
#
print 'AkdlNkdlKDKLda;'.swapcase()
#输出:aKDLnKDLkdklDA;
# def title(self): # real signature unknown; restored from __doc__
# """
# 字符串首字母大写,其他全部转为小写
# S.title() -> string
#
# Return a titlecased version of S, i.e. words start with uppercase
# characters, all remaining cased characters have lowercase.
# """
# return ""
#
print 'kdlsaKDlk'.title()
#输出:Kdlsakdlk
# def translate(self, table, deletechars=None): # real signature unknown; restored from __doc__
# """
# S.translate(table [,deletechars]) -> string
#
# Return a copy of the string S, where all characters occurring
# in the optional argument deletechars are removed, and the
# remaining characters have been mapped through the given
# translation table, which must be a string of length 256 or None.
# If the table argument is None, no translation is applied and
# the operation simply removes the characters in deletechars.
# """
# return ""
#
# def upper(self): # real signature unknown; restored from __doc__
# """
# 字符串全部转为大写
# S.upper() -> string
#
# Return a copy of the string S converted to uppercase.
# """
# return ""
#
# def zfill(self, width): # real signature unknown; restored from __doc__
# """
# 根据所给宽度,将字符串左边不够的位置上填充0
# S.zfill(width) -> string
#
# Pad a numeric string S with zeros on the left, to fill a field
# of the specified width. The string S is never truncated.
# """
# return ""
print '1000'.zfill(8)
#输出:00001000
# def _formatter_field_name_split(self, *args, **kwargs): # real signature unknown
# pass
#
# def _formatter_parser(self, *args, **kwargs): # real signature unknown
# pass
#
# def __add__(self, y): # real signature unknown; restored from __doc__
# """ x.__add__(y) <==> x+y """
# pass
#
# def __contains__(self, y): # real signature unknown; restored from __doc__
# """ x.__contains__(y) <==> y in x """
# pass
#
# def __eq__(self, y): # real signature unknown; restored from __doc__
# """ x.__eq__(y) <==> x==y """
# pass
#
# def __format__(self, format_spec): # real signature unknown; restored from __doc__
# """
# S.__format__(format_spec) -> string
#
# Return a formatted version of S as described by format_spec.
# """
# return ""
#
# def __getattribute__(self, name): # real signature unknown; restored from __doc__
# """ x.__getattribute__('name') <==> x.name """
# pass
#
# def __getitem__(self, y): # real signature unknown; restored from __doc__
# """ x.__getitem__(y) <==> x[y] """
# pass
#
# def __getnewargs__(self, *args, **kwargs): # real signature unknown
# pass
#
# def __getslice__(self, i, j): # real signature unknown; restored from __doc__
# """
# x.__getslice__(i, j) <==> x[i:j]
#
# Use of negative indices is not supported.
# """
# pass
#
# def __ge__(self, y): # real signature unknown; restored from __doc__
# """ x.__ge__(y) <==> x>=y """
# pass
#
# def __gt__(self, y): # real signature unknown; restored from __doc__
# """ x.__gt__(y) <==> x>y """
# pass
#
# def __hash__(self): # real signature unknown; restored from __doc__
# """ x.__hash__() <==> hash(x) """
# pass
#
# def __init__(self, string=''): # known special case of str.__init__
# """
# str(object='') -> string
#
# Return a nice string representation of the object.
# If the argument is a string, the return value is the same object.
# # (copied from class doc)
# """
# pass
#
# def __len__(self): # real signature unknown; restored from __doc__
# """ x.__len__() <==> len(x) """
# pass
#
# def __le__(self, y): # real signature unknown; restored from __doc__
# """ x.__le__(y) <==> x<=y """
# pass
#
# def __lt__(self, y): # real signature unknown; restored from __doc__
# """ x.__lt__(y) <==> x<y """
# pass
#
# def __mod__(self, y): # real signature unknown; restored from __doc__
# """ x.__mod__(y) <==> x%y """
# pass
#
# def __mul__(self, n): # real signature unknown; restored from __doc__
# """ x.__mul__(n) <==> x*n """
# pass
#
# @staticmethod # known case of __new__
# def __new__(S, *more): # real signature unknown; restored from __doc__
# """ T.__new__(S, ...) -> a new object with type S, a subtype of T """
# pass
#
# def __ne__(self, y): # real signature unknown; restored from __doc__
# """ x.__ne__(y) <==> x!=y """
# pass
#
# def __repr__(self): # real signature unknown; restored from __doc__
# """ x.__repr__() <==> repr(x) """
# pass
#
# def __rmod__(self, y): # real signature unknown; restored from __doc__
# """ x.__rmod__(y) <==> y%x """
# pass
#
# def __rmul__(self, n): # real signature unknown; restored from __doc__
# """ x.__rmul__(n) <==> n*x """
# pass
#
# def __sizeof__(self): # real signature unknown; restored from __doc__
# """ S.__sizeof__() -> size of S in memory, in bytes """
# pass
#
# def __str__(self): # real signature unknown; restored from __doc__
# """ x.__str__() <==> str(x) """
# pass
#
#
# bytes = str
相关文章:

Linux与Windows文件共享命令 rz,sz
一般来说,linux服务器大多是通过ssh客户端来进行远程的登陆和管理的,使用ssh登陆linux主机以后,如何能够快速的和本地机器进行文件的交互呢,也就是上传和下载文件到服务器和本地; 与ssh有关的两个命令可以提供很方便的…

Python爬虫小偏方:如何用robots.txt快速抓取网站?
作者 | 王平,一个IT老码农,写Python十年有余,喜欢分享通过爬虫技术挣钱和Python开发经验。来源 | 猿人学Python在我抓取网站遇到瓶颈,想剑走偏锋去解决时,常常会先去看下该网站的robots.txt文件,有时会给你…

八百客与51CTO结了梁子?
转载于:https://blog.51cto.com/simon/171348

特斯拉“撞死”机器人,是炒作还是事故?
作者 | 若名出品 | AI科技大本营科幻片里机器人大战的剧情可能离人类还很遥远,但设想一下,现实中机器人不受控制的打起架来...1 月 6 日,一辆处于自动驾驶模式的特斯拉 Model S “撞死”了一辆掉队 Promobot 的机器人。本次撞击事件发生在当地…

网页解析:如何获得网页源码中嵌套的标签。
一:前言:网页源码中有很多嵌套的标签 例如div标签嵌套如:bUTP<DIV>finally<div>aurora</div>126.com</div><div class\"Cited1\">ggff</div> 我们的网页解析工作中有时候需要解嵌套。通俗的讲…

36.intellij idea 如何一键清除所有断点
转自:https://www.cnblogs.com/austinspark-jessylu/p/7799212.html 1.在idea左下方找到"View Breakpoints"按钮,点击打开. 2.点击"Java Line Breakpoints"前方的全选框,取消全选. 3.点击上方"-"即"Remove"按钮,即可取消所…
Ruby与vim
介绍一点vim下使用Ruby的技巧。 1. vim命令行模式下输入 !ruby % 可以直接运行Ruby程序,并返回到vim编辑 2. vim Ruby关键字及自定义变量补全 拷贝附录中的ruby-macros.vim至机器某处,然后修改~/.vimrc,添加一行: source ROOT(…

NLP技术落地为何这么难?里面有哪些坑?
AI 很火,但是 AI 的门槛也很高,普通的开发者想要搭上这波 AI 红利依然困难。近期,人工智能公司推出了新一代智能 Bot 开放平台,它整合了小i机器人 Chatting Bot、FAQ Bot、Discovery Bot 三大核心能力,为企业和开发者提…
开源工具之valgrind
首先对源文件进行编译:Preparing your programCompile your program with -g to include debugging information so that Memchecks error messages include exact line numbers.-O0 a good idea if you can tolerate the slowdown-O1 line number in error message…
存储过程定义语法
CREATE PROCEDURE addTicket(in vipsql VARCHAR(255),in ordersql VARCHAR(255),in detailkey varchar(255),in detailsql VARCHAR(255)) comment 挂单(售药窗口) BEGIN DECLARE CONTINUE HANDLER FOR SQLEXCEPTION ,NOT FOUND rollback; start transac…
.NET : 针对Oracle的LOB数据访问
参考资料:来自Oracle官方网站 在 .NET 中使用 Oracle 数据库事务作者:Jason Price http://www.oracle.com/technology/global/cn/pub/articles/price_dbtrans_dotnet.html 在 .NET 中使用大对象作者:Jason Price http://www.oracle.com/techn…
MySQL数据类型--------浮点类型实战
1. 背景 * MySQL支持的浮点类型中有单精度类型(float), 双精度类型(double),和高精度类型(decimal),在数字货币类型中推荐使用高精度类型(decimal)来进行应用. * MySQL浮点型和定点型可以用类型名称后加(M,D)来表示&am…
山寨上网本溃败的两点教训
不是马后炮。08年11月份,笔者写过一篇《上网本难以复制山寨机的辉煌》(以下简称《辉煌》),从消费取向和价格两个方面着手,分析认为山寨上网本市场有限,难以复制山寨手机的市场奇迹。现在看来,笔…
分享一个expect的脚本
分享一个expect的脚本,可以用于Linux机器之间远程执行命令: #!/usr/bin/expect -fset ipaddress [lindex $argv 0] set user [lindex $argv 1] set passwd [lindex $argv 2] set cmd [lindex $argv 3] set timeout [lindex $argv 4]spawn -noecho ssh $u…

今晚直播 | 深入浅出理解A3C强化学习
强化学习是一种比较传统的人工智能手段,在近年来随着深度学习的发展,强化学习和深度学习逐渐结合在了一起。这种结合使得很多原来无法想象的工作有了可能,最令我们瞩目的莫过于AlphaGo战胜李世石,以及OpenAI团队的机器人可以在团战…
正则表达式口诀及教程(推荐)
正则其实也势利,削尖头来把钱揣; (指开始符号^和结尾符号$)特殊符号认不了,弄个倒杠来引路; (指\. \*等特殊符号)倒杠后面跟小w, 数字字母来表示; ࿰…
ssh其他机器的Expect脚本
ssh登陆其他机器的Expect脚本 #!/usr/bin/expect -fset user [lindex $argv 0] set ipaddr [lindex $argv 1] set passwd [lindex $argv 2]spawn ssh -l $user $ipaddrexpect "password:" send "$passwd\r" interact或者: #!/usr/bin/expect -f…

今晚8点直播 | 深入浅出理解A3C强化学习
强化学习是一种比较传统的人工智能手段,在近年来随着深度学习的发展,强化学习和深度学习逐渐结合在了一起。这种结合使得很多原来无法想象的工作有了可能,最令我们瞩目的莫过于AlphaGo战胜李世石,以及OpenAI团队的机器人可以在团战…
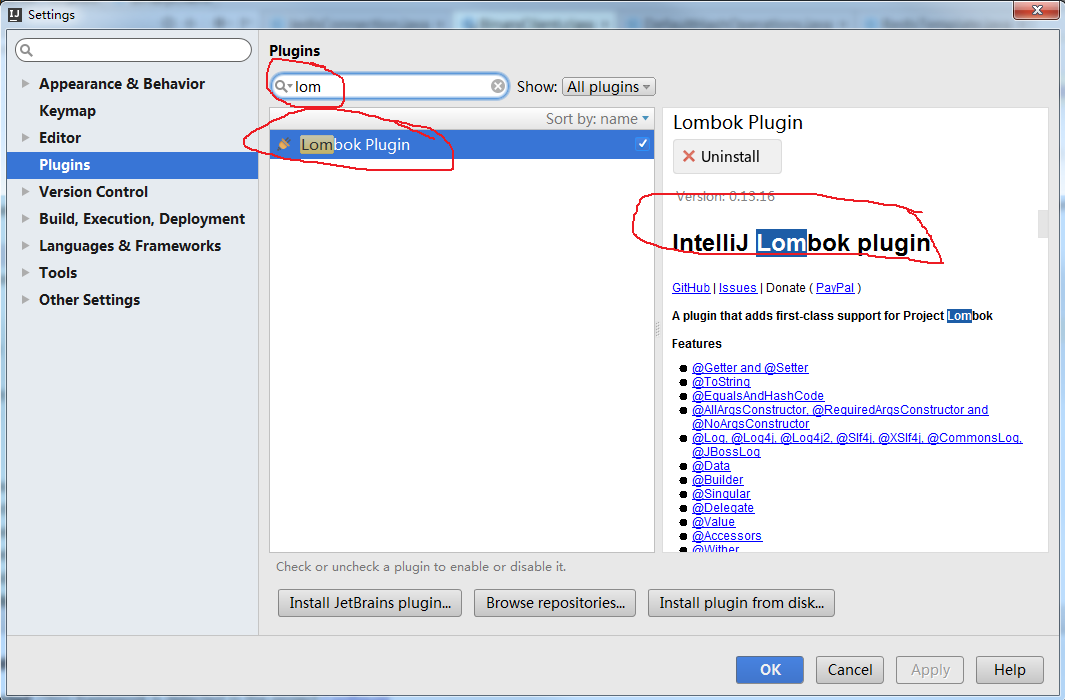
40.lombok在IntelliJ IDEA下的使用
转自:https://www.cnblogs.com/yjmyzz/p/lombok-with-intellij-idea.html lombok是一款可以精减java代码、提升开发人员生产效率的辅助工具,利用注解在编译期自动生成setter/getter/toString()/constructor之类的代码。代码越少,意味着出bug的…
C++之Boost使用
1. Get & Build & Install Boost download boost from http://www.boost.org/ 进入boost目录,使用命令: ./bootstrap.sh --prefixpath/to/installation ./b2 install 如此之后: leave Boost binaries in the lib/ subdirectory…

这就是芬兰:先让全国1%的人学起AI!
译者 | 大鱼责编 | 琥珀出品 | AI科技大本营【AI科技大本营导语】全球最大的手机制造商诺基亚、著名游戏《愤怒的小鸟》的开发商 Rovio,这两大曾名噪一时的科技公司都来自同一个国家——芬兰。很多人会问:在如此激烈的竞争环境下,为什么如此小…
Linux 裸设备基础知识(转)
1、裸设备定义:一块没有分区的硬盘,称为原始设备(RAW DEVICE)或者是一个分区,但是没有用EXT3,OCFS等文件系统格式化,称为原始分区(RAW PARTITION)以上两者都是裸设备 2、裸设备的绑定有文件系统的分区是采用mount的方式挂载到某一个挂载点的…

吴恩达与LG握手合作!
图片来自LG官网作者 | 琥珀出品 | AI科技大本营在近日举办的 CES 大会上,人工智能领域知名科学家、Landing.ai 创始人兼 CEO 吴恩达(Andrew Ng)与 LG(LG Electronics)总裁兼 CTO IP. Park 在拉斯维加斯签署了战略合作伙…

linux上安装mysql,tomcat,jdk
Linux 上安装 1 安装jdk 检测是否安装了jdk 运行 java –version若有 需要将其卸载a) 查看安装哪些jdk rmp –qa |grep java b) 先卸载openjdk 1.7 c) 在卸载openjdk 1.6 使用rpm –e - -nodeps 卸载的包 安装jdka) 上传jdk到linux 使用Xftp5…
现代人的无知什么样
以前没有知识的人就是无知! 但现在变了!一个博士却不会用他的知识挣钱养家糊口算不算无知,一个人大学毕业却不会学习算不算无知,一个经理在自己的电脑上找不到自己存的东西算不算无知,有知识却不会表达的人算不算无知…
zz Expect的安装
转载一篇靠谱的文章,按照文章所述方法一次成功。只不过我的expect二进制文件最后实在tcl的bin目录下,而不是expect的bin目录下,这个令我有些疑惑,whatever,不算什么大问题,注意一下就好了。A. Tcl 安装 主页…
分享一个ssh打通的脚本
分享一个ssh打通的脚本,经过测试可用。目前只能单向打通,且要求本地用户名为admin(写入代码,可简单修改)。本身只是个人使用,故通用性、异常情况考虑不多,大家可以做个参考。 补充一点,Important Tip&…

从云计算到AI:NetApp的数据网络转型之道
毫无疑问,在 AI、大数据、云计算等新技术潮流的冲击下,各行业企业的数字化转型进程日益加速,社会正在进入一个全新的数据融合时代。这一过程中,人们一方面对技术予以高期待,期望给行业进行业务重构,但另一方…
侧方位停车技巧
侧方位停车技巧 侧方位停车相对来说是比较容易的,只要掌握要领就能够正确地倒入车位中。具体要领如下: 第一步先打右转向灯,挂倒档,保持车辆平稳、缓慢地倒车;第二步回头看桩,当右后车门三角窗中部与1号桩&…

微信是把“杀猪刀”,还改变了我的表情包
整理 | Jane出品 | Python大本营1 月 9 日上午,一年一度的微信公开课 PRO 在广州举行,会上发布了《2018微信年度数据报告》。报告的第一部分是 2018 年微信用户活跃数、发送消息与音视频通话数据;第二部分根据微信用户画像,针对不…