QQ卖手办,用AI分析用户评论

作者 | 徐汉彬
指导 | 宋彦
编辑 | Jane
出品 | AI科技大本营
徐汉彬,腾讯鹅漫前台研发团队 Leader,T3-3 级工程师,负责鹅漫U品和 AMS 平台(高峰期 PV 超过 13 亿)的研发工作,在 Web 研发、活动运营服务领域有丰富的经验和积累。
宋彦博士,腾讯AI Lab骨干科学家,T4专家研究员。前微软小冰创始团队成员。发表AI领域顶级会议和期刊论文50余篇,多次担任NLP顶级会议(ACL、NAACL、EACL、EMNLP、COLING等)程序委员会委员。主导了腾讯2018智能春联及AI Lab大规模中文词向量的构建工作。
前言
深度学习(深度神经网络)作为机器学习的一个重要分支,推动了很多领域的研究和应用,其中包括文本处理领域的情感分类问题。由于可以对文本进行更有效地编码及表达,基于深度学习的情感分类对比传统的浅层机器学习和统计学方法,可以取得更高的分类准确率。当前,情感分析在互联网业务中已经具有比较广泛的应用场景,成为了一个重要的业务支持能力。
文本情感分析的发展与挑战
1.情感分析的发展
情感分析(Sentiment Analysis),也称为情感分类,属于自然语言处理(Natural Language Processing,NLP)领域的一个分支任务,分析一个文本所呈现的信息是正面、负面或者中性,也有一些研究会区分得更细,例如在正负极性中再进行分级,区分不同情感强度。
在 2000 年之前,互联网没有那么发达,积累的文本数据不多,因此,这个问题被研究得较少。2000 年以后,随着互联网大潮的推进,文本信息快速积累,文本情感分析的研究也开始快速增加。早期主要是针对英文文本信息,比较有代表性的,是 Pang, Lee and Vaithyanathan (2002) 的研究,第一次采用了 Naive Bayes(朴素贝叶斯), Maximum Entropy(最大熵)和SVM(Support Vector Machine, 支持向量机)等方法对电影评论数据进行了情感分类,将之分为正面或者负面。2000-2010 年期间,情感分析主要基于传统的统计和浅层机器学习,由于这些方法不是本文阐述的重点,因此,本文就不再展开介绍。
2010 年以后,随着深度学习的崛起和发展,情感分析开始采用基于深度学习的方法,并且相对于传统的机器学习方法取得了更好的识别准确率。
2.中文文本情感分析的难点
由于汉语博大精深,从传统方法的角度来看,中文文本的情感分析有多个难点:
(1)分词不准确:中文句子由单个汉字组成,通常第一个要解决的问题,就是如何“分词”。但是,由于汉字组合的歧义性,分词的准确率一直难以达到完美的效果,而不准确的分词结果会直接影响最终分析的结果。
(2)缺乏标准完整的情感词库:与中文相比,英文目前有相对比较完整的情感词库,对每个词语标注了比较全面的情感类型、情感强度等。但是,中文目前比较缺乏这样的情感词库。同时考虑到语言的持续发展的特性,往往持续不断地产生新的词语和表达方式,例如,“陈独秀,坐下”,“666”,它们原本都不是情感词,在当今的互联网环境下被赋予了情感极性,需要被情感词库收录。
(3)否定词问题:例如,“我不是很喜欢这个商品”和“我很喜欢这个商品”,如果基于情感词的分析,它们的核心情感词都是“喜欢”,但是整个句子却表达了相反的情感。这种否定词表达的组合非常丰富,即使我们将分词和情感词库的问题彻底解决好,针对否定词否定范围的分析也会是一个难点。
(4)不同场景和领域的难题:部分中性的非情感词在特定业务场景下可能具有情感倾向。例如,如下图的一条评论“(手机)蓝屏,充不了电”,蓝屏是一个中性名词,但是,如果该词在手机或者电脑的购买评价中如果,它其实表达了“负面”的情感,而在某些其他场景下还有可能呈现出正面的情感。因此,即使我们可以编撰一个完整的“中文情感词典”,也无法解决此类场景和领域带来的问题。

上述挑战广泛存在于传统的机器学习与深度学习方法中。但是,在深度学习中,有一些问题可以得到一定程度的改善。
中文分词概述
一般情况下,中文文本的情感分类通常依赖于分析句子中词语的表达和构成,因此需要先对句子进行分词处理。不同于英文句子中天然存在空格,单词之间存在明确的界限,中文词语之间的界限并不明晰,良好的分词结果往往是进行中文语言处理的先决条件。
中文分词一般有两个难点,其一是“歧义消解”,因为中文博大精深的表达方式,中文的语句在不同的分词方式下,可以表达截然不同的意思。有趣地是,正因如此,相当一部分学者持有一种观点,认为中文并不能算作一种逻辑表达严谨的语言。其二是“新词识别”,由于语言的持续发展,新的词汇被不断创造出来,从而极大影响分词结果,尤其是针对某个领域内的效果。下文从是否使用词典的角度简单介绍传统的两类中文分词方法。
1.基于词典的分词方法
基于词典的分词方法,需要先构建和维护一套中文词典,然后通过词典匹配的方式,完成句子的分词,基于词典的分词方法有速度快、效率高、能更好地控制词典和切分规则等特性,因此被工业界广泛作为基线工具采用。基于词典的分词方法包含多种算法。比较早被提出的有“正向最大匹配算法”(Forward Maximum Matching,MM),FMM 算法从句子的左边到右边依次匹配,从而完成分词任务。但是,人们在应用中发现 FMM 算法会产生大量分词错误,后来又提出了“逆向最大匹配算法”(Reverse Maximum Matching,RMM),从句子右边往左边依次匹配词典完成分词任务。从应用的效果看,RMM 的匹配算法表现,要略为优于 MM 的匹配算法表现。
一个典型的分词案例“结婚的和尚未结婚的”:
FMM:结婚/的/和尚/未/结婚/的 (分词有误的)
RMM:结婚/的/和/尚未/结婚/的 (分词正确的)
为了进一步提升分词匹配的准确率,研究者后来又提出了出了同时兼顾 FMM 和 RMM 分词结果的“双向最大匹配算法” (Bi-directctional Matching,BM ),以及兼顾了词的出现频率的“最佳匹配法”(Optimum Matching,OM)。
2.基于统计的分词方法
基于统计的分词方法,往往又被称作“无词典分词”法。因为中文文本由汉字组成,词一般是几个汉字的稳定组合,因此在一定的上下文环境下,相邻的几个字出现的次数越多,它就越有可能成为“词”。基于这个规则可以通过算法构建出隐式的“词典”(模型),从而基于它完成分词操作。该类型的方法包括基于互信息或条件熵为基础的无监督学习方法,以及 N 元文法(N-gram)、隐马尔可夫模型(Hiden Markov Model,HMM)、最大熵模型(Maximum Entropy,ME)、条件随机场模型(Conditional Random Fields,CRF)等基于监督学习的模型。这些模型往往作用于单个汉字,需要一定规模的语料支持模型的训练,其中监督学习的方法通过薛念文在 2003 年第一届 SIGHAN Bakeoff 上发表的论文所展现出的结果开始持续引起业内关注。效果上,这些模型往往很善于发现未登录词,可以通过对大量汉字之间关系的建模有效“学习”到新的词语,是对基于词典方法的有益补充。然而它在实际的工业应用中也存在一定的问题,例如分词效率,切分结果一致性差等。
基于多层 LSTM 的中文情感分类模型原理
在前述分词过程完成后,就可以进行情感分类了。我们的情感分类模型是一个基于深度学习(多层 LSTM)的有监督学习分类任务,输入是一段已经分好词的中文文本,输出是这段文本正面和负面的概率分布。整个项目的流程分为数据准备、模型搭建、模型训练和结果校验四个步骤,具体内容会在下文中详细展开。由于本文模型依赖于已切分的中文文本,对于想要动手实现代码的读者,如果没有分词工具,我们建议读者使用网上开源的工具。
1.数据准备
我们基于 40 多万条真实的鹅漫用户评论数据建立了语料库,为了让正面和负面的学习样本尽可能均衡,我们实际抽样了其中的 7 万条评论数据作为学习样本。一般情况下,对于机器学习的分类任务,我们建议将学习样本比例按照分类规划为 1:1,以此更好地训练无偏差的模型。
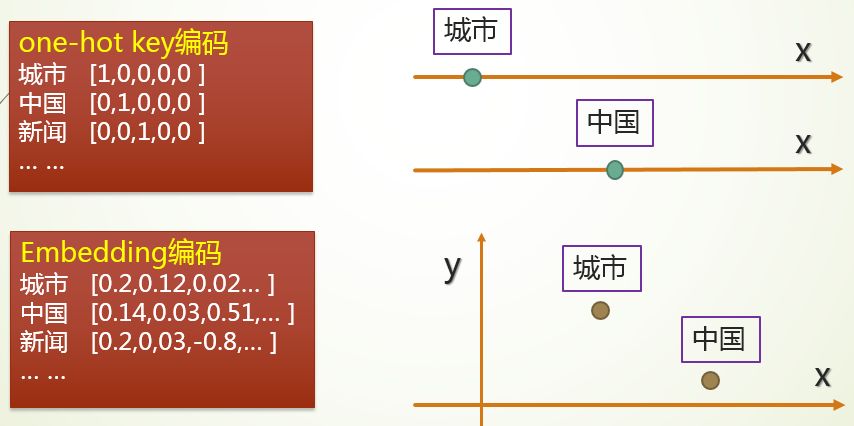
模型的输入是一段已经分词的中文文本,但它无法直接被模型识别,因此我们要将它转换成一种能被模型识别的数学表达。最直接的方式是将这些文本中的词语用“One-Hot Key”进行编码。One-Hot Key是一种比较简单的编码方式,假设我们一共只有5个词,则可以简单地编码为如下图所示:

在一般的深度学习任务中,非连续数值型特征基本采用了上述编码方式。但是,One-Hot Key 的编码方式通常会造成内存占用过大的问题。我们基于 40 多万条用户评论分词后获得超过 38000 个不同的词,使用 One-Hot Key 方式会造成极大的内存开销。下图是对 40 多万条评论分词后的部分结果:

因此,我们的模型引入了词向量(Word Embeddings)来解决这个问题,每一个词以多维向量方式编码。我们在模型中将词向量编码维度配置为 128 维,对比 One-Hot Key 编码的 38000 多维,无论是在内存占用还是计算开销都更节省机器资源。作为对比,One-Hot key 可以粗略地被理解为用一条线表示 1 个词,线上只有一个位置是 1,其它点都是 0,而词向量则是用多个维度表示 1 个词。
这里给大家安利一个很好的资源,由腾讯AI Lab去年10月发布的大规模中文词向量,可以对超过800万词进行高质量的词向量映射,从而有效提升后续任务的性能。
https://ai.tencent.com/ailab/nlp/embedding.html
假设我们将词向量设置为 2 维,它的表达则可以用二维平面图画出来,如下图所示:
2.模型搭建
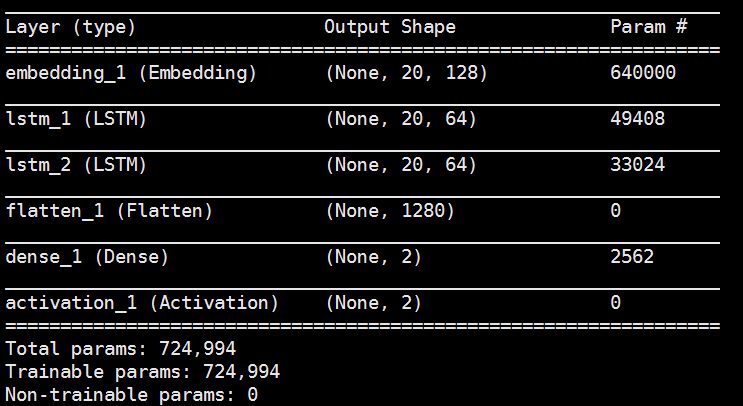
本项目的代码采用了 Keras 实现,底层框架是 Google 开源的 TensorFlow。整个模型包含 6 层,核心层包括 Embedding 输入层、中间层(LSTM)、输出层(Softmax)。模型中的 Flatten 和 Dense 层用于做数据维度变换,将上一层输出数据变换为相应的输出格式,最终的输出是一个二维数组,用于表达输入文本是正面或者负面的概率分布,格式形如 [0.8, 0.2]。
Keras的模型核心代码和参数如下:
EMBEDDING_SIZE = 128
HIDDEN_LAYER_SIZE = 64
model = Sequential()
model.add(layers.embeddings.Embedding(words_num, EMBEDDING_SIZE, input_length=input_data_X_size))
model.add(layers.LSTM(HIDDEN_LAYER_SIZE, dropout=0.1, return_sequences=True))
model.add(layers.LSTM(64, return_sequences=True))
model.add(layers.Flatten())
model.add(layers.Dense(2))
model.add(layers.Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
model.fit(X, Y, epochs=1, batch_size=64, validation_split=0.05, verbos
模型架构如下图:
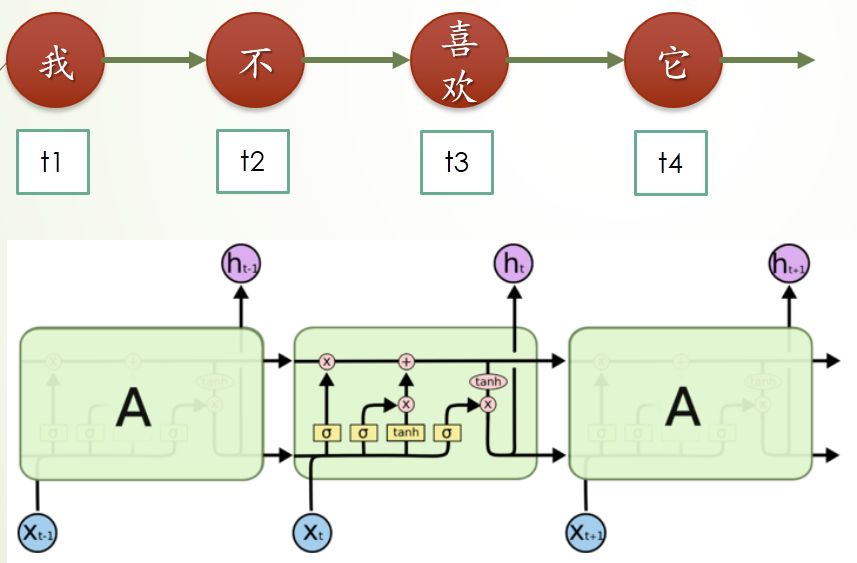
该模型的核心层采用 LSTM (Long short-term memory,长短记忆模型),LSTM 是 RNN (Recurrent neural network,循环神经网络)的一种实现形式,具有“记忆时序”的特点,可以学习到数据上下文之间的关联关系。例如,在含有前置否定词的句子“我喜欢”和“我不是很喜欢”中,虽然“喜欢”这个词表达了正面的情感含义,但是句子前面出现的否定词却更重要,否定词会使语句表达的情感截然相反。LSTM 可以通过上下文学习到这种组合规律,从而提高分类准确率。
模型其他几个层的含义本文也简单列出:
Flatten(压平层),在本模型中负责将 2 阶张量压缩为 1 阶级张量(20*64 = 1280):

Dense(全连接层),通常用于做维度变换,在本模型中将 1280 维变为 2 维。

Activation(激活函数),本模型采用 Softmax,它负责将数值约束到 0-1 之间,并且以概率分布的方式输出。
3.模型训练
由于我们的模型架构比较简单,模型的训练耗时不高,在一台 8 核 CPU + 8G 内存的机器上完成一轮 7 万多个评论样本的训练只需 3 分钟左右。训练得到的模型在测试集上可以获得大约 96% 的情感分类准确率,而基于传统机器学习方法的准确率通常只有 75-90%。值得注意的是,本模型并不是一个可以识别任意文本的通用模型,因为我们构建的学习样本基本上只覆盖鹅漫用户评论语料范围内的词,超出语料范围的分类准确率可能会显著降低。
测试集情感分类的部分结果(数值代表该评论是正面情感的概率):

文本表述中含有否定词的识别场景:

关于部分“中性词”在某些业务情景下拥有情感倾向的问题,利用本文的模型可以较好地处理,因为本文的模型可以通过学习得到所有词(包括情感词和一般词)的情感倾向。
例如,下图中的“坑爹”一词,在模型中已经被明显地识别为“负面”情感词(0.002 表示该词属于正面情感的概率仅有千分之二),而“666”则被识别为正面情感词(概率系数大于 0.5 则属于正面情感)。

业务应用场景与扩展展望
1.业务应用场景
在鹅漫U品业务场景中,用户完成商品购买后通常会对商品进行评论,一般情况下,我们的客服和商家会对差评评论进行一定处理和回复。但是,真实的用户评论数据中存在一种特殊的好评,我们称之为“假好评”,用户评论表述的内容是差评,可能由于页面点击失误或者其他原因却在评论分类上选择了“好评”,从而导致这种评论没有被正确归类,因此,客服和商家同学没办法处理到这类评论。从鹅漫的评论数据看,这类“假好评”的比例大概占据全部评论数据的 3%。考虑到鹅漫业务每天产生巨量评论,如果依靠人工甄别的处理方式将非常费时费力,通过自动情感分类的则可以有效解决该问题。
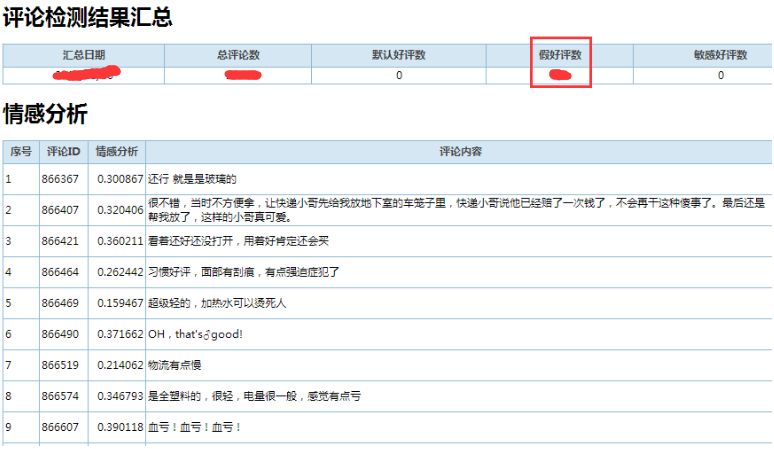
鹅漫另外一个业务场景是自动提取“深度好评”:我们直接通过全量数据扫描获取正面情感系数高,并且评论字数较多的评论文本,将它们作为商品的“深度好评”。这类评论通常对产品的体验和描述较为详尽,适合放在商品页面更显眼的位置,能有效提升浏览用户对商品的了解。同时,自动提取评论也能一定程度上减轻商品运营人员撰写运营文案的工作量,尤其是在商品数量较多的情况下。反之亦如此,如果我们提取负面情感系数较高且字数较多的评论,则可以获得“深度差评”,它可以作为商品运营人员了解用户负面反馈的一种有效渠道。
例如下图的“弹幕”评论,就是我们自动提取的“好评”:
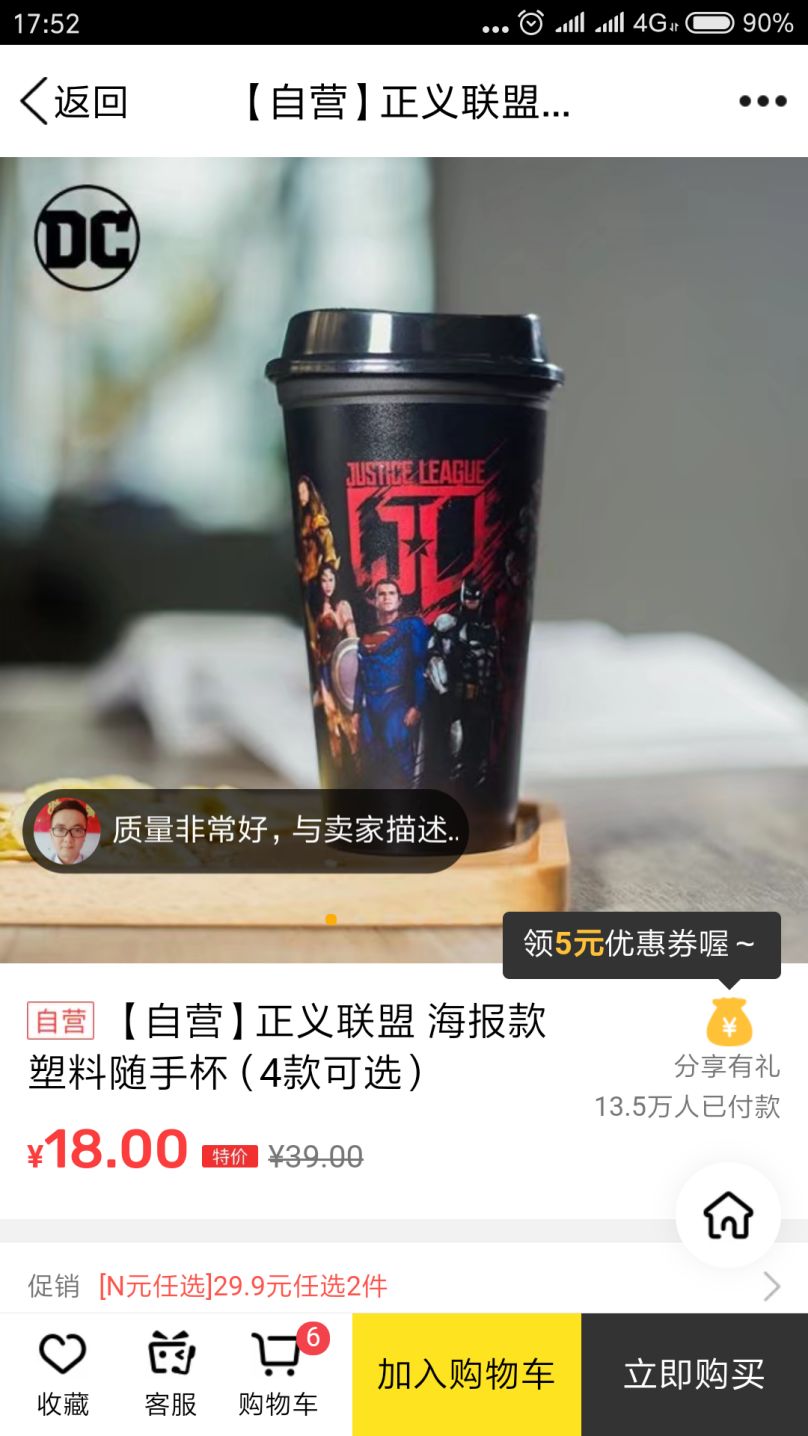
值得提出的是,目前,鹅漫也在使用腾讯 AI Lab 提供的通用版情感分类接口,它的模型不依赖于分词,直接以字为单元进行建模和训练,情感分类的准确率非常高,适用范围更广。我们通过联合使用两个不同模型的分类结果完成更高质量的情感分析。
2.未来扩展方向
我们从海量的文本评论中,归类出了正面和负面情感的文本数据,在此基础上如果再通过针对商品不同方面(aspect)的评论的建模乃至句法依存分析(dependency parsing),进一步提炼文本的关键信息,就可以获得用户的关键表达意见。从中我们可以获得比较全面的商品评价信息,提炼出商品被大量用户正面评价和负面评价的主要观点,最终可以为运营人员和商家提供商品改进意见和运营决策指导。实现真正意义上的基于商品的舆情分析(opinion summary),提炼出用户的真实反馈和观点。
下图以“我们一直喜欢美丽的手办”为例,通过词法依存分析,获得了词与词之间的关系,进而分析出用户在评论中倾诉情绪的核心对象。在下图的评论中,用户对“手办”表达了正面的情感。
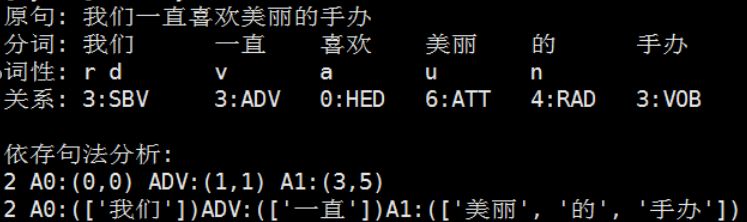
词法关系的含义:
SBV,主谓关系
ADV,修饰(状语)
HED,核心
ATT,修饰(定语)
RAD,右附加关系
VOB,直接宾语
结语
在互联网海量信息和数据面前,人的力量非常有限并且成本高昂,例如,鹅漫U品评论情感分类和提取的两项业务需求,就是面向海量文本信息处理的典型任务,如果通过人工完成,执行效率极为低下。深度学习模型使我们良好地满足了业务诉求。虽然深度学习并非完美,但是它所提供的执行效率和帮助是显著的,并在一定的业务场景下成为辅助解决业务问题的新选择和新工具。
参考
Google 开源的 TensorFlow:
https://tensorflow.google.cn/
对 TensorFlow 的二次封装框架 Keras:
https://keras.io/
(*本文为AI科技大本营投稿文章,转载请联系微信1092722531。)
公开课预告
◆
全双工语音
◆
本期课程中,微软小冰全球首席架构师及研发总监周力博士将介绍微软小冰在全双工语音对话方面的最新成果,及其在智能硬件上的应用和未来将面临的更多技术产品挑战。

推荐阅读
华为波兰销售总监被捕;苹果将推三款新 iPhone;ofo 用冻结款还债 | 极客头条
Spring中的9种设计模式汇总
《请不要回应外星人2019》
一图看尽全生态, 2018区块链产业云图重磅发布!
最全NLP语料资源集合及其构建现状
买不到回家的票,都是“抢票加速包”惹的祸?
这个用Python编写的PDF神器你值得拥有!
刚刚!程序员集体荣获2个冠军,这份2018 IT报告还说这些!
相关文章:

使用svn时碰到的一个的问题
做技术的人,需要有完美主义,很多问题,如果当时不能彻底解决,往往会留下更大的麻烦。这个字符编码的问题,当时碰到的时候没有主义,以后遇到的时候也是抱着躲避的鸵鸟主义的态度,今天认真对待了一…
远程为服务器安装Windows 2008 Server
命苦,老早就定好10.1期间要把服务器重新安装一次,今天反正也没有事情,来尝试下远程安装,因为以后的MOSS公司要远程的管理和使用 先登录到远程控制卡的管理地址 然后输入用户名和密码,以下是登录成功后的界面 然后在左侧的功能树中选择“介质”…
Spring装配Bean---使用xml配置
声明Bean Spring配置文件的根元素是<beans>. 在<beans>元素内,你可以放所有的Spring配置信息,包括<bean>元素的声明. 除了Beans命名空间,Spring的核心框架总共自带了10个命名空间配置: 命名空间用途 aop 为声…

Ruby DSL介绍及其在测试数据构造中的使用(1)
什么是DSL?英文全称Domain Specific Language,中文解释为领域专用语言。顾名思义,DSL是针对某个特定领域而开发的语言。像我们平时接触到的C/C,Java,Python/Ruby,都属于通用语言,可以为各个领域…

2017年度最受欢迎开源中国项目:roncoo-pay投票评选
2019独角兽企业重金招聘Python工程师标准>>> roncoo-pay项目正在参加 2017年度最受欢迎中国开源软件评选,请大家投上宝贵的一票,支持roncoo-pay更好的发展,为大家带来更多好用的支付功能! 2017年度最受欢迎中国开源软件…
编程小问题系列(2)——为什么WPF里MediaElement等视频控件不起作用
为什么WPF里MediaElement等视频控件不起作用?非常可能的原因是因为没有安装Microsoft Windows Media Player 10或者10以上的播放器,MSDN文档里就写有下面一句话:Both and are used to present audio, video, and video with audio content. B…

国行版HomePod售价2799元,本周五发售
(图片源自苹果中国官网截图)整理 | 一一出品 | AI科技大本营去年 12 月,苹果表示将于今年年初在中国销售其 HomePod 智能音箱。1 月 14 日,苹果公司正式宣布,HomePod 将于 1 月 18 日(本周五)在…

维基百科联手谷歌翻译,结果“惨不忍睹”!
作者 | 琥珀出品 | AI科技大本营作为前沿科技新闻报道的一线工作者,我们经常会碰到各种陌生难懂、语言不通的词句。这直接导致我们在引用和查找信息时,往往辅助以维基百科和谷歌翻译为代表的两大信息引擎,其重要性不言而喻。然而,…

Ruby DSL介绍及其在测试数据构造中的使用(2)
在(1)中介绍了DSL和普通的函数定义之间的区别。在(1)的最后提到,DSL分为内部DSL和外部DSL,我们再看一遍他们的定义:1. External DSLs 用不同于host语言的语言来编写,通过编译和解释器来翻译成host语言 2. Internal DSLs 将host语言…
批量编译fla文件
jsfl太神奇了不过内存不高的机器还是少编译一点,会同时打开你选择的文件夹下的所有fla文件,然后一个一个自动编译。Compile flas.jsfl//----------------------------------Start--------------------------------//Brent Arnolds kick butt batch folde…
字符串转换成utf-8编码
a、将字符串转换成utf-8编码的字节,并输出,然后将该字节在转换成utf-8编码字符串,在输出 b、将字符串转换后才能gbk编码的字节,并输出,然后将该字节在转换成gbk编码字符串,在输出 123456789101112def main(…

50万奖金+京东数科offer,JDD-2018全球总决赛冠军诞生
(JDD 大赛总决赛选手与导师、评委合影)整理 | 一一出品 | AI科技大本营1 月 13 日,JDD-2018 京东数字科技全球探索者大赛全球总决赛落下帷幕。在经过 24 小时极限挑战和 2 小时商业路演的较量后,来自以色列赛区的团队“Cheese&…
三星笔记本FN功能键操作大全
Samsung 的快捷键都很简单,提供的都是最常用的功能,但新出的X系列和P系列机的FN快捷键差异很大,例如X10和P25。现在介绍FN快捷键以巧的X10为主,补充说明P25。FN上方向键/下方向键:增加/减低亮度FN左方向键/右方向键:增…
[翻译] Ruby Golf
原文地址:http://rubysource.com/ruby-golf/ Ruby golf is the art of writing code that uses as few characters as possible. The idea originates in the world of Perl (where it is, unsurprisingly, known as Perl Golf). As a language, Perl is well suite…

AI删库,程序员背锅?
作者 | 一一出品 | AI科技大本营又一代码清库的惨案发生了,不过这次要背锅是 AI。近日,美国最大点评网站 Yelp 的工程师训练的神经网络闯祸了。他们训练了一个用来消除 bug 的神经网络,万万没想到,该网络删除一切,从根…

OpenStack Keystone架构一:Keystone基础
一 什么是keystone keystone是OpenStack的身份服务,暂且可以理解为一个与权限有关的组件。 二 为何要有keystone Keystone项目的主要目的是为访问openstack的各个组件(nova,cinder,glance...)提供一个统一的验证方式,具体的&#…
用gdb调试mpi程序的一些心得
Linux下MPI (Message Passage Interface) 的程序不太好调试,在windows下vs2005以上的IDE有集成的简便MPI调试工具,没有用过,有兴趣的可以试验一下。下面总结了一些最近在用MPI和c语言写程序时的调试经验(Ubuntu环境,c语…

开源如何占领软件世界?
作者 | Mike Volpimavolpi译者 | 风车云马编辑 | 一一出品 | AI科技大本营5 年前,投资商对开源这种商业模式的可行性持有怀疑态度。他们普遍认为,红帽(redhat)公司犹如雪花飘零——在软件世界里开源公司不可能占据举足轻重的地位。…
软件工程概论——课堂测试1
设计思想:1.用1个页面,实现课程录入,提交后直接返回课程界面。2.应用html表单属性进行数据的提交。3.用servlet进行写入数据库和验证输入。 源代码: <% page language"java" import"java.util.*" contentT…

过程即奖励(The Journey is the Reward)
今天读完了《乔布斯传》。翻着这本书最后的影集,乔布斯传奇一生的一幕幕仿佛在眼前展开。从第一张照片中特里独行、桀骜不驯的年轻人,到最后一张照片中阳光下慈祥微笑的老者,看到的仿佛不是乔布斯的照片,而是自己的一位人生挚友。…
BREW 计费模式概览
计费模式也就是收入模型是商业模式的基础。BDS分发系统中不但提供了与运营商计费系统的接口,而且直接提供了BREW 计费服务。 BREW分发系统与运营商计费系统的集成,一般就是与运营商的综合营帐系统的集成,需要融合于网元层,资源层&…

程序员崩溃了,年终奖怎么说黄就黄
作者 | 胡巍巍转载自程序人生(ID:coder_life)往年王者荣耀年终奖200个月100万(虽然辟谣是假的)、华为年终奖24个月100万,都让我等平民羡煞不已。还有在BAT发生的(朋友圈)真人真事↓这是年终奖的…
改变IT世界的11大Apache开源技术
据国外媒体报道,转眼之间,Apache软件基金会已经成立10年之久了,11月份,Apache基金会的成员将会为其举行一次大型的庆祝。虽然Apache软件基金会是一个开源的组织,但是Apache却创造了对现代互联网来说很重要的技术。下面…

nginx常用技术
作者:NetSeek http://www.linuxtone.org (IT运维专家网|集群架构|性能调优)欢迎转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明.首发时间: 2008-11-25 更新时间:2009-1-14目 录一、 Nginx 基础知识二、 Nginx 安装及调试三、 Ngi…

2011到过的地方
火车上读《南方周末》,看到记者把自己2011去过的地方在地图上标记,带着标记的世界地图,显得特别而好看,于是很想自己也做一份。找了一些网站,做的图片,差强人意吧。2011到过的地方:这个图不算漂…

2亿简历遭泄漏,到底谁的锅?
作者 | 仲培艺转载自CSDN(ID:CSDNnews)前面刚有 AWS 开战 MongoDB,双方“隔空互呛”,这厢又曝出 2 亿简历信息泄露——MongoDB 的这场开年似乎“充实”得过分了些。长期以来,作为“最受欢迎的 NoSQL 数据库…
Could not apply the stored configuration for monitors 解决办法
Could not apply the stored configuration for monitors 解决办法: $ sudo rm -rf ~/.config/monitors.xml 重启电脑即可 本文转自linux博客51CTO博客,原文链接http://blog.51cto.com/yangzhiming/1225802如需转载请自行联系原作者 yangzhimingg

20行Python代码给微信头像戴帽子
作者 | Leauky,北理工硕士在读,非CS专业的Python爱好者。朋友圈里微信官方要求戴圣诞帽的活动曾经火爆一时,有些会玩的小伙伴都悄咪咪地用美图秀秀一类的 app 给自己头像 p 一顶,然后可高兴地表示“哎呀好神奇hhhh”,呆…
2012关于钱的Tips
对于目前的我来说,死工资是唯一的财富积累手段,而且工资本身还不足够满足所有的物质和精神需求。以此为前提,对钱的来龙去脉有一个了解、把控是极其有必要的。 2011钱的规划基本为零,一年下来惊恐的发现,似乎自己没攒多…
在 Azure 中管理 Windows 虚拟机的可用性
了解如何设置和管理多个虚拟机,以确保 Azure 中 Windows 应用程序的高可用性。 也可以管理 Linux 虚拟机的可用性。 Note Azure 具有用于创建和处理资源的两个不同的部署模型:Resource Manager 和经典。 这篇文章介绍了如何使用这两种模型,但…