Python文本预处理:步骤、使用工具及示例

作者 | Data Monster
译者 | Linstancy
编辑 | 一一
出品 | AI科技大本营(ID:rgznai100)
本文将讨论文本预处理的基本步骤,旨在将文本信息从人类语言转换为机器可读格式以便用于后续处理。此外,本文还将进一步讨论文本预处理过程所需要的工具。
当拿到一个文本后,首先从文本正则化(text normalization) 处理开始。常见的文本正则化步骤包括:
将文本中出现的所有字母转换为小写或大写
将文本中的数字转换为单词或删除这些数字
删除文本中出现的标点符号、重音符号以及其他变音符号
删除文本中的空白区域
扩展文本中出现的缩写
删除文本中出现的终止词、稀疏词和特定词
文本规范化(text canonicalization)
下面将详细描述上述文本正则化步骤。
将文本中出现的字母转化为小写
示例1:将字母转化为小写
Python 实现代码:
input_str = ”The 5 biggest countries by population in 2017 are China, India, United States, Indonesia, and Brazil.”
input_str = input_str.lower()
print(input_str)
输出:
the 5 biggest countries by population in 2017 are china, india, united states, indonesia, and brazil.
删除文本中出现的数字
如果文本中的数字与文本分析无关的话,那就删除这些数字。通常,正则化表达式可以帮助你实现这一过程。
示例2:删除数字
Python 实现代码:
import re
input_str = ’Box A contains 3 red and 5 white balls, while Box B contains 4 red and 2 blue balls.’
result = re.sub(r’\d+’, ‘’, input_str)
print(result)
输出:
Box A contains red and white balls, while Box B contains red and blue balls.
删除文本中出现的标点
以下示例代码演示如何删除文本中的标点符号,如 [!”#$%&’()*+,-./:;<=>?@[\]^_`{|}~] 等符号。
示例3:删除标点
Python 实现代码:
import string
input_str = “This &is [an] example? {of} string. with.? punctuation!!!!” # Sample string
result = input_str.translate(string.maketrans(“”,””), string.punctuation)
print(result)
输出:
This is an example of string with punctuation
删除文本中出现的空格
可以通过 strip()函数移除文本前后出现的空格。
示例4:删除空格
Python 实现代码:
input_str = “ \t a string example\t “
input_str = input_str.strip()
input_str
输出:
‘a string example’
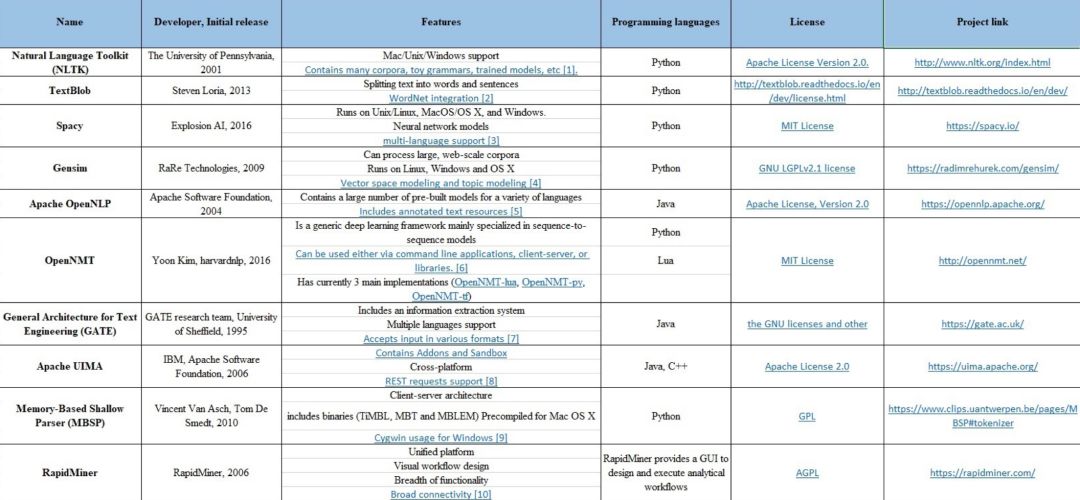
符号化(Tokenization)
符号化是将给定的文本拆分成每个带标记的小模块的过程,其中单词、数字、标点及其他符号等都可视为是一种标记。在下表中(Tokenization sheet),罗列出用于实现符号化过程的一些常用工具。
删除文本中出现的终止词
终止词(Stop words) 指的是“a”,“a”,“on”,“is”,“all”等语言中最常见的词。这些词语没什么特别或重要意义,通常可以从文本中删除。一般使用 Natural Language Toolkit(NLTK) 来删除这些终止词,这是一套专门用于符号和自然语言处理统计的开源库。
示例7:删除终止词
实现代码:
input_str = “NLTK is a leading platform for building Python programs to work with human language data.”
stop_words = set(stopwords.words(‘english’))
from nltk.tokenize import word_tokenize
tokens = word_tokenize(input_str)
result = [i for i in tokens if not i in stop_words]
print (result)
输出:
[‘NLTK’, ‘leading’, ‘platform’, ‘building’, ‘Python’, ‘programs’, ‘work’, ‘human’, ‘language’, ‘data’, ‘.’]
此外,scikit-learn 也提供了一个用于处理终止词的工具:
from sklearn.feature_extraction.stop_words import ENGLISH_STOP_WORDS
同样,spaCy 也有一个类似的处理工具:
from spacy.lang.en.stop_words import STOP_WORDS
删除文本中出现的稀疏词和特定词
在某些情况下,有必要删除文本中出现的一些稀疏术语或特定词。考虑到任何单词都可以被认为是一组终止词,因此可以通过终止词删除工具来实现这一目标。
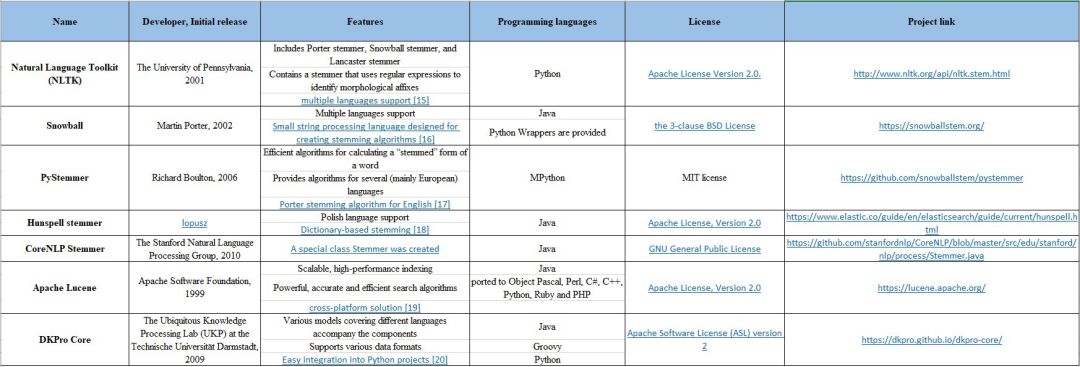
词干提取(Stemming)
词干提取是一个将词语简化为词干、词根或词形的过程(如 books-book,looked-look)。当前主流的两种算法是 Porter stemming 算法(删除单词中删除常见的形态和拐点结尾) 和 Lancaster stemming 算法。
示例 8:使用 NLYK 实现词干提取
实现代码:
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
stemmer= PorterStemmer()
input_str=”There are several types of stemming algorithms.”
input_str=word_tokenize(input_str)
for word in input_str:
print(stemmer.stem(word))
输出:
There are sever type of stem algorithm.
词形还原(Lemmatization)
词形还原的目的,如词干过程,是将单词的不同形式还原到一个常见的基础形式。与词干提取过程相反,词形还原并不是简单地对单词进行切断或变形,而是通过使用词汇知识库来获得正确的单词形式。
当前常用的词形还原工具库包括: NLTK(WordNet Lemmatizer),spaCy,TextBlob,Pattern,gensim,Stanford CoreNLP,基于内存的浅层解析器(MBSP),Apache OpenNLP,Apache Lucene,文本工程通用架构(GATE),Illinois Lemmatizer 和 DKPro Core。
示例 9:使用 NLYK 实现词形还原
实现代码:
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
lemmatizer=WordNetLemmatizer()
input_str=”been had done languages cities mice”
input_str=word_tokenize(input_str)
for word in input_str:
print(lemmatizer.lemmatize(word))
输出:
be have do language city mouse
词性标注(POS)
词性标注旨在基于词语的定义和上下文意义,为给定文本中的每个单词(如名词、动词、形容词和其他单词) 分配词性。当前有许多包含 POS 标记器的工具,包括 NLTK,spaCy,TextBlob,Pattern,Stanford CoreNLP,基于内存的浅层分析器(MBSP),Apache OpenNLP,Apache Lucene,文本工程通用架构(GATE),FreeLing,Illinois Part of Speech Tagger 和 DKPro Core。
示例 10:使用 TextBlob 实现词性标注
实现代码:
input_str=”Parts of speech examples: an article, to write, interesting, easily, and, of”
from textblob import TextBlob
result = TextBlob(input_str)
print(result.tags)
输出:
[(‘Parts’, u’NNS’), (‘of’, u’IN’), (‘speech’, u’NN’), (‘examples’, u’NNS’), (‘an’, u’DT’), (‘article’, u’NN’), (‘to’, u’TO’), (‘write’, u’VB’), (‘interesting’, u’VBG’), (‘easily’, u’RB’), (‘and’, u’CC’), (‘of’, u’IN’)]
词语分块(浅解析)
词语分块是一种识别句子中的组成部分(如名词、动词、形容词等),并将它们链接到具有不连续语法意义的高阶单元(如名词组或短语、动词组等) 的自然语言过程。常用的词语分块工具包括:NLTK,TreeTagger chunker,Apache OpenNLP,文本工程通用架构(GATE),FreeLing。
示例 11:使用 NLYK 实现词语分块
第一步需要确定每个单词的词性。
实现代码:
input_str=”A black television and a white stove were bought for the new apartment of John.”
from textblob import TextBlob
result = TextBlob(input_str)
print(result.tags)
输出:
[(‘A’, u’DT’), (‘black’, u’JJ’), (‘television’, u’NN’), (‘and’, u’CC’), (‘a’, u’DT’), (‘white’, u’JJ’), (‘stove’, u’NN’), (‘were’, u’VBD’), (‘bought’, u’VBN’), (‘for’, u’IN’), (‘the’, u’DT’), (‘new’, u’JJ’), (‘apartment’, u’NN’), (‘of’, u’IN’), (‘John’, u’NNP’)]
第二部就是进行词语分块
实现代码:
reg_exp = “NP: {<DT>?<JJ>*<NN>}”
rp = nltk.RegexpParser(reg_exp)
result = rp.parse(result.tags)
print(result)
输出:
(S (NP A/DT black/JJ television/NN) and/CC (NP a/DT white/JJ stove/NN) were/VBD bought/VBN for/IN (NP the/DT new/JJ apartment/NN)
of/IN John/NNP)
也可以通过 result.draw() 函数绘制句子树结构图,如下图所示。

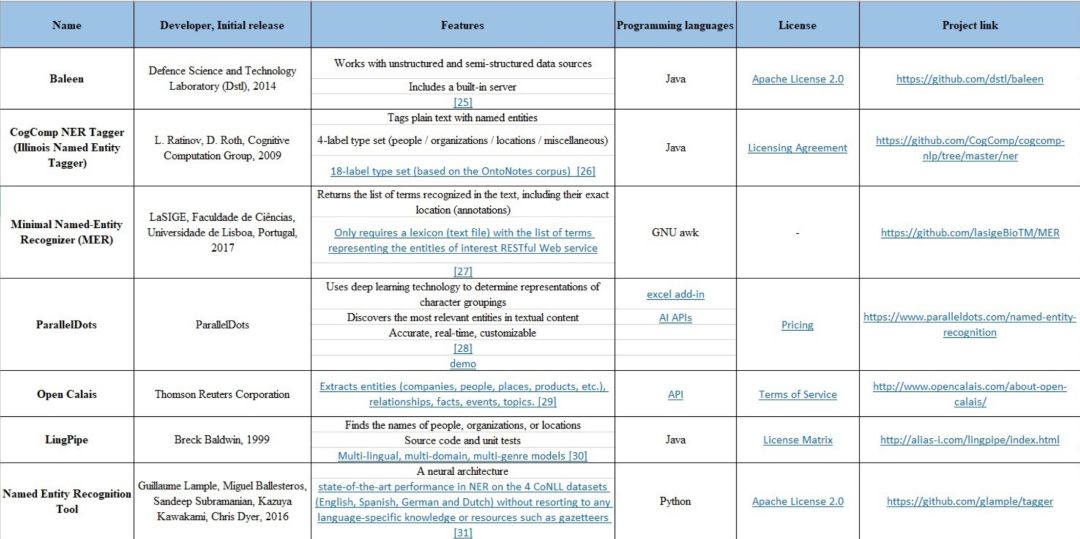
命名实体识别(Named Entity Recognition)
命名实体识别(NER) 旨在从文本中找到命名实体,并将它们划分到事先预定义的类别(人员、地点、组织、时间等)。
常见的命名实体识别工具如下表所示,包括:NLTK,spaCy,文本工程通用架构(GATE) -- ANNIE,Apache OpenNLP,Stanford CoreNLP,DKPro核心,MITIE,Watson NLP,TextRazor,FreeLing 等。
示例 12:使用 TextBlob 实现词性标注
实现代码:
from nltk import word_tokenize, pos_tag, ne_chunk
input_str = “Bill works for Apple so he went to Boston for a conference.”
print ne_chunk(pos_tag(word_tokenize(input_str)))
输出:
(S (PERSON Bill/NNP) works/VBZ for/IN Apple/NNP so/IN he/PRP went/VBD to/TO (GPE Boston/NNP) for/IN a/DT conference/NN ./.)
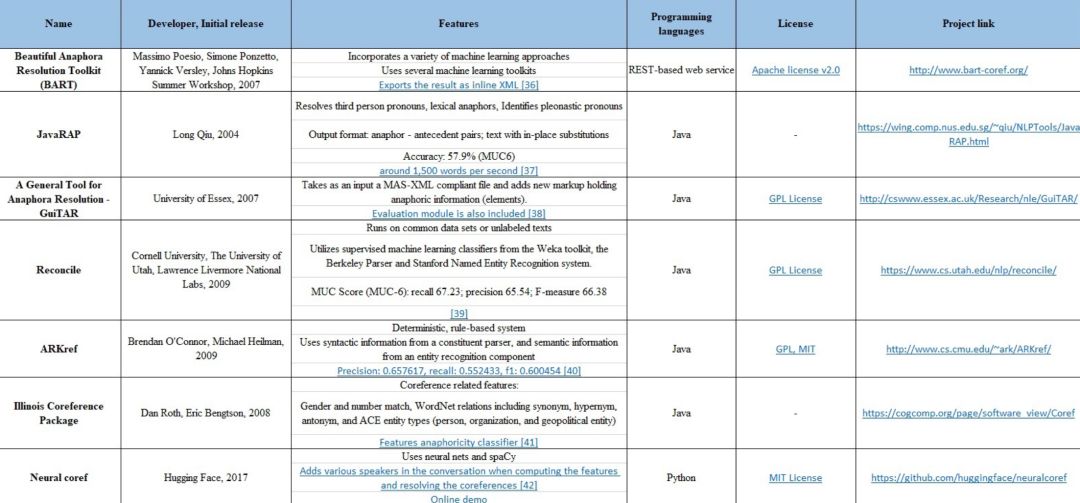
共指解析 Coreference resolution(回指分辨率 anaphora resolution)
代词和其他引用表达应该与正确的个体联系起来。Coreference resolution 在文本中指的是引用真实世界中的同一个实体。如在句子 “安德鲁说他会买车”中,代词“他”指的是同一个人,即“安德鲁”。常用的 Coreference resolution 工具如下表所示,包括 Stanford CoreNLP,spaCy,Open Calais,Apache OpenNLP 等。
搭配提取(Collocation extraction)
搭配提取过程并不是单独、偶然发生的,它是与单词组合一同发生的过程。该过程的示例包括“打破规则 break the rules”,“空闲时间 free time”,“得出结论 draw a conclusion”,“记住 keep in mind”,“准备好 get ready”等。
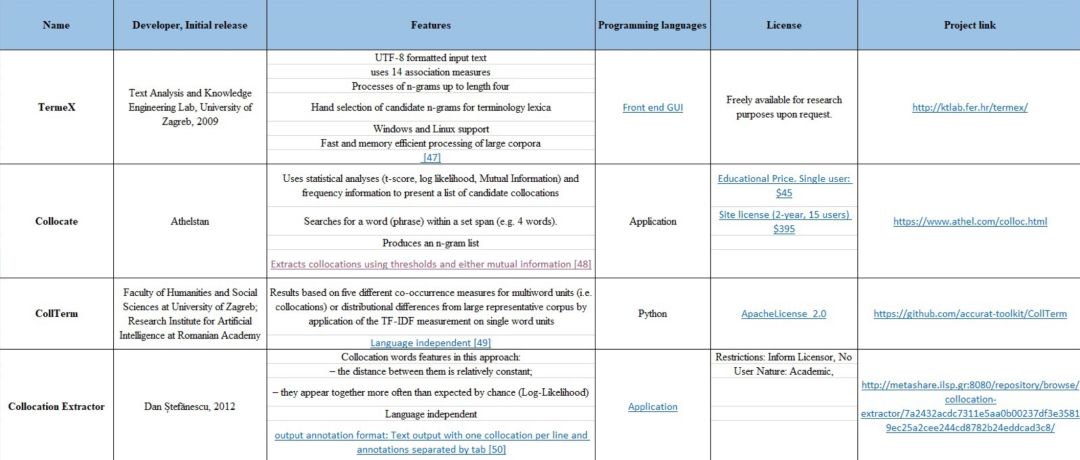
示例 13:使用 ICE 实现搭配提取
实现代码:
input=[“he and Chazz duel with all keys on the line.”]
from ICE import CollocationExtractor
extractor = CollocationExtractor.with_collocation_pipeline(“T1” , bing_key = “Temp”,pos_check = False)
print(extractor.get_collocations_of_length(input, length = 3))
输出:
[“on the line”]
关系提取(Relationship extraction)
关系提取过程是指从非结构化的数据源 (如原始文本)获取结构化的文本信息。严格来说,它确定了命名实体(如人、组织、地点的实体) 之间的关系(如配偶、就业等关系)。例如,从“昨天与 Mark 和 Emily 结婚”这句话中,我们可以提取到的信息是 Mark 是 Emily 的丈夫。
总结
本文讨论文本预处理及其主要步骤,包括正则化、符号化、词干化、词形还原、词语分块、词性标注、命名实体识别、共指解析、搭配提取和关系提取。还通过一些表格罗列出常见的文本预处理工具及所对应的示例。在完成这些预处理工作后,得到的结果可以用于更复杂的 NLP 任务,如机器翻译、自然语言生成等任务。
原文链接:https://medium.com/@datamonsters/text-preprocessing-in-python-steps-tools-and-examples-bf025f872908
(本文为 AI科技大本营翻译文章,转载请联系原作者)
征稿
推荐阅读
PDF翻译神器,再也不担心读不懂英文Paper了
Facebook增强版LASER开源:零样本迁移学习,支持93种语言
啥是佩奇排名算法
网络爬虫的法律边界
Caicloud 开源 Nirvana:让 API 从对框架的依赖中涅槃重生
程序员有话说 | 那个拒绝加班的程序员后来怎么样了
告别摩拜
6大改进:盘点以太坊的2018冒险之旅
不难!月薪 50K大牛,悉心整理程序员必备技能!

相关文章:

读《杜拉拉升职记》有感
读杜拉拉升职记有感1.一定要在核心部门任职,防止被边缘化2.劳心者治人,劳力者治于人干了活还受气怎么办?1.把每一个阶段的主要任务和安排的都做成清晰简明的表格,发给我的老板,告诉他如果有反对意见,在某某…

linux驱动:TI+DM8127+GPIO(二)之驱动
二、【GPIO驱动框架》驱动driver】 重要结构体 gpio_chip:管理一组GPIO gpio_desc:描述每个GPIO gpio_bank:封装了gpio_chip加入GPIO控制的属性 1、驱动注册到platform中 Arch/arm/plat-omap/gpio.c中 static int __init omap_gpio_drv…

菜鸟的DUBBO进击之路(八):配置抽离导致${jdbc.url}被当成字符串处理
为什么80%的码农都做不了架构师?>>> 导致这个问题的原因有很多,基于我查到的资料做个记录 第一:xmlns:context"http://www.springframework.org/schema/context" xsi:schemaLocation"http://www.springframework.org/schema/…
用VS2005打开方案出现“此安装不支持该项目类型”
当在用VS2005打开已有项目时常会出现“此安装不支持该项目类型”。 出现此原因是因为已有项目是在打了VS 2005 SP1补丁后编写的,所以在没有打补丁的.net中会出现此种情况 下面就补丁下载:VS80sp1-KB926604-X86-CHS.exeWebApplicationProjectSetup.msi
linux驱动:TI+DM8127+GPIO(三)之omap_hwmod中添加GPIO资源
三、【GPIO驱动框架》向omap_hwmod中添加GPIO资源】 ***将GPIO硬件信息添加到注册到omap_hwmod_list列表中 Arch/arm/plat-omap/include/plat/ti81xx.h中 #define TI814X_GPIO3_BASE 0x481AE000 Arch/arm/plat-omap/gpio.c中 输入输出控制寄存器偏移地址 #define OMAP4…
用Redis存储Tomcat集群的Session(转载)
本文转自http://blog.csdn.net/chszs/article/details/42610365 感谢作者 前段时间,我花了不少时间来寻求一种方法,把新开发的代码推送到到生产系统中部署,生产系统要能够零宕机、对使用用户零影响。 我的设想是使用集群来搞定,通…

微信的Bug差点让我被老板炒鱿鱼!
作者 | 屠敏转载自CSDN(ID:CSDNnews)1 月 24 日上午 10:30 左右,10 亿用户量的国民应用微信疑似出现大 Bug。据网友反馈,自己一直使用的微信号突然显示被删除,登也登不上。对此,不少人的银行卡一…

vPower系列1: vMotion-没有vMotion,虚拟化只是玩具
vPower今天开讲,第一篇vMotion。vMotion是虚拟化可以支撑核心应用的重要前提,没有vMotion,虚拟化只是玩具,只能应用在实验环境和开发环境。为什么这么说呢?为什么会有vMotion?vMotion解决了虚拟平台上的什么…
linux驱动:TI+DM8127+GPIO(四)之设备
四、【GPIO驱动框架》设备device】 arch/arm/mach-omap2/gpio.c中 1、static int __init omap2_gpio_init(void) { returnomap_hwmod_for_each_by_class("gpio", omap2_gpio_dev_init, NULL); } archarm/mach-omap2/omap_hwmod.c 中 2、int omap_hwmod_for_each…
简单的TableViewCell高度自适应(只有Label,仅当参考思路)
在iOS开发中或多或少的都会碰到TableViewCell高度自适应,那么今天这篇文章就简单的介绍一下如何给tableViewCell自适应高度 #ViewController copy interface ViewController ()<UITableViewDelegate, UITableViewDataSource>{UITableView *_tableView; }property (nonato…

Google发布新的问答语料库,专攻篇章级的NLU问题
译者 | Linstancy整理 | Jane出品 | AI科技大本营(ID:rgznai100)开放域的问答(QA)是自然语言理解(NLU)中的一项基本任务,旨在模拟人是如何通过阅读和理解完整的文档,从而寻找信息、发…

AjaxControltoolkit(工具包)安装步骤说明
本来打算做一个系统搜索中Ajax AutoComplete自动提示的效果,想尝试一下以前用AjaxControlToolkit中控件,在官网上下载一个AjaxControlToolkit2.0版本我尽然忘了如何安装.很是汗了一把. 看来人都是有惰性的,哪怕自己认为以前比较熟练自信的东西 如果时间一长不做回顾还是不行的 …
linux驱动:TI+DM8127+GPIO(五)之plarform
五、【GPIO驱动框架》平台platform】 (一)设备找驱动 1、drivers/base/platform.c中 int platform_device_register(structplatform_device *pdev) { device_initialize(&pdev->dev); returnplatform_device_add(pdev); } 2、int platform_…

2:0!谷歌 AI “AlphaStar“ 虐杀职业星际玩家
作者 | 若名出品 | AI科技大本营(ID:rgznai100)刚刚,在更复杂的《星际争霸 II》游戏中,DeepMind AI 以总比分 2:0 分别战胜两位职业人类选手。这或许是自 2017 年 AlphaGo 在围棋上战胜人类后,再次让人类刷新 AI 认知的…
插件化知识梳理(7) 类的动态加载入门
一、前言 在 插件化知识梳理(6) - Small 源码分析之 Hook 原理 这一章的学习完成之后,下一步我们将进入插件化加载的精髓,动态加载类的学习,在此之前,我们需要先准备一些关于类加载的知识。 Android当中,支持动态加载的…
redhat中使用securecrt 中文乱码解决办法
具体解决方法是: 1,修改远程linux机器的配置 vim /etc/sysconfig/i18n 把LANG改成支持UTF-8的字符集 如:LANG”zh_CN.UTF-8″ 或者是 LANG”en_US.UTF-8″ 2,然后再改Secure CRT的设置,选项->会话选项->外观->字符编码-&…
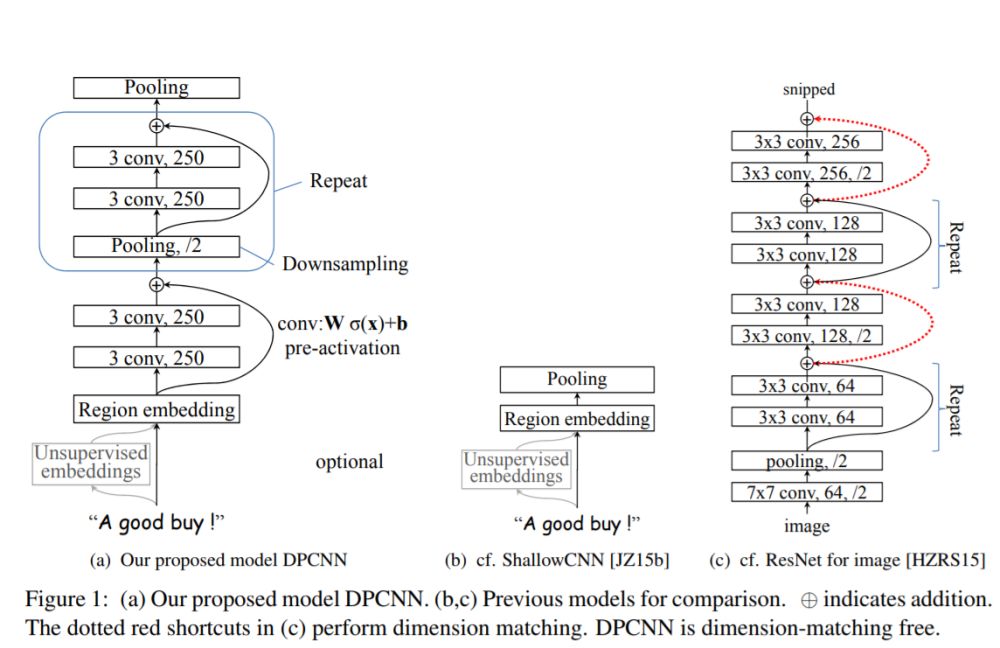
知否?知否?一文看懂深度文本分类之DPCNN原理与代码
【导读】ACL2017年中,腾讯AI-lab提出了Deep Pyramid Convolutional Neural Networks for Text Categorization(DPCNN)。论文中提出了一种基于word-level级别的网络-DPCNN,由于上一篇文章介绍的TextCNN 不能通过卷积获得文本的长距离依赖关系,…

linux驱动:设备-总线-驱动(以TI+DM8127中GPIO为例)
一:说明:这次学习设备-总线-驱动是以TIDM8127的GPIO为例 1、GPIO资源注册到omap_hwmod链表中 2、初始化GPIO 3、将GPIO注册到plarform层 4、将GPIO注册到device层 二、流程图 1、GPIO资源注册到omap_hwmod链表中 2、初始化GPIO 3、将GPIO注册到pla…
生活总是在推着你一步一步往前走
上早班的时候,无意间看到了关于高考这个字眼。对于我的高考已经过去五年了,但回想起来记忆依旧是那么深刻。记得五年前的那个日子,阳光明媚,空气中到处都是一股夏天的气息,我妈和我哥早早的从家里搭车到县城࿰…
急!!!求从字符串中提取形如: div([MC0010000000006],此若干个字符或数字,0) 的正则表达式...
如题, 形如: div([MC0010000000006],此处有若干个字符或数字, 此处只有一个字符) 静坐等待.
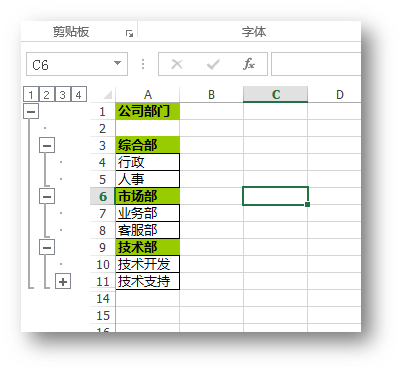
C# 如何创建Excel多级分组
在Excel中如果能够将具有多级明细的数据进行分组显示,可以清晰地展示数据表格的整体结构,使整个文档具有一定层次感。根据需要设置显示或者隐藏分类数据下的详细信息,在便于数据查看、管理的同时也使文档更具美观性。那么,在C#中如…
苹果裁员逾200人,拿无人驾驶“开刀”
整理 | 琥珀出品 | AI科技大本营1 月 14日,据美国媒体 CNBC 援引知情人士消息报道称,本周,苹果泰坦项目(Project Titan)的 200 多名员工遭到解雇。据悉,泰坦项目是苹果未公开的自动驾驶汽车项目。一名苹果发…

linux驱动:i2c驱动(一)
I2C系统框架:I2C核心层、I2C总线驱动、I2C设备驱动 -------------------------------------------------------------------------------- 【I2C核心层】 代码在driver/i2c/i2c-core.c中 【I2C总线驱动】也叫I2C适配器驱动 1、每个适配器视为一个字符设备文件 …
关于SQLServer2005的学习笔记——XML的处理
在 SQLServer2005 中对 XML 的处理功能显然增强了很多,提供了 query(),value(),exist(),modify(),nodes() 等函数。关于 xml ,难以理解的不是 SQLServer 提供的函数,而是对 xml 本身的理解,看似很简单的文件格式,处理起…

2019最新实战!给程序员的7节深度学习必修课,最好还会Python!
整理 | 琥珀出品 | AI科技大本营从 2017 年开始,fast.ai 创始人、数据科学家 Jeremy Howard 以每年一迭代的方式更新“针对编程者的深度学习课程”(Practical Deep Learning For Coders)。这场免费的课程可以教大家如何搭建最前沿的模型、了解…
linux驱动:i2c驱动(二)
3、驱动源码分析 IPNC_RDK_V3.8.0.1/Source/ti_tools/ipnc_psp_arago/kernel/sound/soc/codecs/tlv320aic3x.c 3.1 注册模块 module_init(aic3x_modinit); 3.2 在初始化函数中添加i2c驱动 static int __init aic3x_modinit(void) { intret 0; #if defined(CONFIG_I2C) ||…
01 使用AFN3 0上传图片时间慢的问题
##iOS中修改图片的大小:修改分辨率和裁剪 ###第一步:裁剪图片 // 裁剪// 要裁剪的图片区域,按照原图的像素大小来,超过原图大小的边自动适配CGSize size CGSizeMake(1000, 1000);UIImage *img [self imageWithImageSimple:image scaledToS…
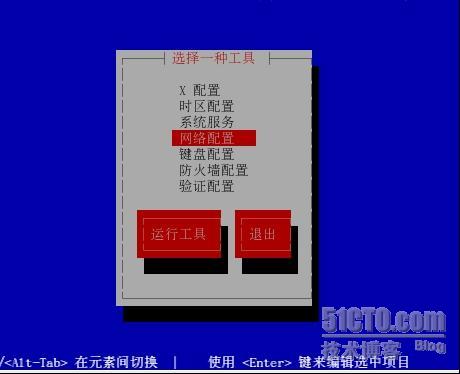
配置telnet
配置telnet<?xml:namespace prefix o ns "urn:schemas-microsoft-com:office:office" />允许root账号能够登录telnet,但是拒绝某一台主机登录且只允许在9:00-14:00 14:00-18:00能够访问࿰…
04 pod setup 慢的问题
解决方式一: 可以直接从别人的电脑中拷贝解决方式二转载于:https://juejin.im/post/5a3c5a985188257d391d3a39

linux驱动:i2c驱动(三)流程图之注册设备
一、设备注册过程 1、将i2c设备信息保存到i2c_board_info结构体中; 2、在注册i2c_board_info时(i2c_register_board_info)将它加入一个全局列表__i2c_board_list中, 3、在注册I2c adapter适配器驱动后,再从全局列表…