AI,被“横扫记录”反噬?
编辑 | Jane
出品 | AI科技大本营
昨天,香侬科技发表论文《Glyce: Glyph-vectors for Chinese Character Representations》,提出基于中文字形的 NLP 模型——Glyce。香侬科技官方公开的论文解读中写道:
Glyce提出了基于中文字形的语义表示:把汉字当成一个图片,然后用卷积神经网络学习出语义,这样便可以充分利用汉字中的图形信息,增强了深度学习向量的语意表达能力。Glyce在总共13项、近乎所有中文自然语言处理任务上刷新了历史记录。
论文一经发表,便引起了大家的广泛关注和讨论,营长经多方搜集、参考很多网友的回答,整理了几个颇具争议性的问题:
“横扫记录”的 Glyce 与 BERT 相比较是否有意义?
一些其他论文介绍中附有“横扫 13 项中文 NLP 记录”的标题,吸引了读者的眼球,不由得将其与 BERT 进行对比。然而很多人细读后表示,Glyce 的一些设计优势,在实验效果上确有提升,记录也有刷新,但“横扫”言过其实了。根据论文给出的实验结果,有些任务并没有 BERT 达到的影响力。在命名实体识别任务中(采用 F1 作为最终评价指标,对比之前的最优模型 Lattice-LSTM),在 OneNotes、MSRA 和 Resume 三个数据集上分别超过 0.93、0.71 和 1.21 个百分点。
抛开实验效果,二者的本质也是不同的。论文发表后,香侬科技创始人李纪为对此问题进行了统一回复:
@李纪为@香侬科技:Glyce 与 BERT 本质上不太一样,是互补的。Glyce 可以认为是特征提取算法,BERT 是 pre-training,BERT 基于外部极大规模语料训练,而 Glyce 并没有用到外部语料。针对此论文中的工作,将 Glyce 与 BERT 进行对比是不公平的。
最好的结果一定会是 Glyce+BERT_pertrain,大家可以期待 Glyce 2.0。
随后,论文作者之一@吴炜也在知乎上对此问题进行了回答:

可见,没有必要将 Glyce 与 BERT 进行对比,更应先关注 Glyce 的工作本身,探讨其带来的意义、价值与反思。
论文中也提到了一些研究,关注在中文 NLP 中结合字形图像特征的方法,但并没有表现出持续的性能提升,甚至在一些研究中取得了负面效果,(Liu et al., 2017; Zhang and LeCun, 2017)、Dai and Cai, 2017)。但是,这种 idea 还是很有意思的,很多网友也表示”这篇论文真正将字形特征的思路通过实验得到 Work 的状态,还是很有价值的”。
但是谈到实验部分,很多人都对实验 Baseline 持质疑态度
@Nan Yang:这个是 1024 维的向量表示,而对于 Baseline,分词和 NER 50 维向量、词性标注是 64 维、Sentiment 是 256 维、Deppar 是 300 维、MT 是 512 维,还有几个懒得查了,一般来说在这些 Task 上维度增大好好调下都会更高,能好好做下 baseline 吗?
针对以上问题,张俊林老师也分享了他对这项工作的一些想法和意见,AI科技大本营经张俊林老师授权转载,欢迎大家一起交流学习!
以下是张俊林老师全文(略有修正):
今天(1 月 30 日)被 Glyce 刷屏了,刚开始我是下午在微信朋友圈看到的这个新闻“香侬科技提出中文字型的深度学习模型Glyce,横扫13项中文NLP记录”,看到标题心里还有点小激动,觉得 NLP 今年大进展真的是多啊!但是白天有事没来及细看,匆匆扫了一遍,晚上回家找来论文仔细读了一下,感想比较多,下面简单谈谈我的个人看法。
首先,使用字型作为特征引入 NLP 中这种思路还是挺有意思的,但直观感觉,这种信息可能只会对语义匹配类或者汉字发音计算类的任务有帮助,对分词、词性标注、句法与分类这种任务应该没太大作用。
其次,现在很多技术媒体出于吸引眼球等目的,有标题党倾向。动不动就“超过人类”、“横扫...记录”......虽然可以理解,但这对外行或者领域经验不足的年轻人来说,引导尤其不好。“横扫”这种词不能轻易拿来用,BERT 在很多任务上取得的效果是大幅度领先的,说“横扫”没人不服气,而 Glyce 每个任务的提升幅度有限,说“横扫”只会招黑。
第三,论文的立论多少缺乏说服力。论文的立论是:象形字中包含语义信息,所以从汉字图片中抽取象形字特征作为补充。但是,象形字本身占汉字的比例并没有想象中那么高。“现行汉字最多的是形声字,象形字只是很少的一部分,但它是构成其他汉字的基础。《说文解字》形声字占所收 9353 个汉字的 80% 以上,清代《康熙字典》形声字占 90%,形声字大量增加是汉字发展的主流”。比如,“蜘蛛”的 “蛛”和“珠宝”的“珠”,这两个字是形声字,形只占了一半,声占了另外一半,CNN 提出的特征能够区分那一部分是代表声,哪一部分是代表形吗?但从特征角度讲,两个字提出的特征应该是很相似的吧?难道从预测任务来说,比如语言模型,看到“蜘蛛”的 “蛛”,我们会觉得后面将出现“珠宝”的“珠”吗?这个概率应该很小。
对于文本分类任务,两篇不同领域的文章都包含很多形声字,所以在两篇领域相差很远的文章中会存在大量重叠的偏旁部首,比如一篇体育一篇娱乐,偏旁部首会对分类有帮助吗?这在直觉上很难接受。其它高层任务,如分词、词性和情感倾向等都面临这个问题。单从直观感觉来讲:写起来比较像的文字,它们可能只在单词级别的语义匹配或发音类的任务上有用,对其它任务看不出有什么必然的联系。所以总体感觉,论文立论不太符合直觉。
另外一种解释,这种方式对于 OOV 有帮助,但从大比例汉字其实是形声字的角度看,也没有特别必然的联系。而且,如果采取汉字单字字符输入的方式,哪怕是单字 Onehot 或者 Embedding,它本身对于 OOV 也是直接有帮助的,OOV 这个问题可能并不突出。如果对比对象是字符 ID方式的话,采取图形汉字作为输入,对于 OOV 能有多大作用,目前看不到特别明显的理由。可能需要专门设计实验来验证这一点。
第四,个人觉得这里面的实验设计需要改进。拿 BERT 来比较确实不是必要的,因为两者的目的不太一样;此外,Transformer 类特征抽取器做 NLP 任务的模型应该引入对比一下,毕竟这基本已经是很多 NLP 任务中公认最强的模型了。
最关键的一点是:如何证明在这么多任务中性能的提升真的是汉字图片信息带来的,而不是 Glyce-char 之上辅助优化目标产生的效果?如果是后者产生的效果,那么把这个损失函数放在常规模型的字符 Embedding 上,也可能产生类似不同任务的提升效果。个人感觉很大可能是一定比例的性能提升来自于这个辅助损失函数,它有助于优化单字 Embedding 的表达能力,而与字符是图形形式还是 ID 形式关系并无如此之大。建议做个对比实验:把模型中的 Glyce 去掉,然后给常规模型 Char 的 Embedding 也加上辅助损失函数,然后再和具有 Glyce 的比较。如果证明不是这个因素发挥作用,那么还能增加实验的说服力。
第五,当然还有其他一些值得讨论的地方。比如论文开始提到的“其他利用字型的工作之所以效果不好,是因为简体字经过简化,缺乏历史上的语义信息,所以一个创新点是引入其他字体”,实验并没有充分说明这一点。除了字符级语言模型外,其它实验并没有对这两者效果作对比,无法确定这个立论是否成立,除非大量任务上都证明多种字体效果好于单字体,这个立论才成立。而从目前版本的论文中看不出这点。再比如文中使用的“Tianzige(田字格)——CNN 架构,这个就是偏文艺化的说法了,为什么 pooling 后不能是 5 或者 6,而只能是 4 形成田字格呢?如果是 6 的话,跟田字格又有什么关系呢?这个架构的提出应该更严谨一些。
作为技术人员,我们都希望能有新技术、大突破,但是技术本身说服力够强才是基础。也希望技术媒体能够客观进行报道,AI 泡沫本来已经快破了,希望不要推波助澜进一步加快这个破灭过程,这样对所有人其实都不好。
作者 | 张俊林,中国中文信息学会理事,目前在新浪微博 AI Lab 担任资深算法专家。在此之前,张俊林曾经在阿里巴巴任资深技术专家,以及在百度和用友担任技术经理及技术总监等职务。同时他是技术书籍《这就是搜索引擎:核心技术详解》(该书荣获全国第十二届输出版优秀图书奖)、《大数据日知录:架构与算法》的作者。
更多好文:
放弃幻想,全面拥抱Transformer:NLP三大特征抽取器(CNN/RNN/TF)比较
写在最后
无论是做研究还是做应用都需要严谨的态度。作为专注传播、分享技术成果的我们,虽然有时候也有做的不够好的地方,但我们会常常反思,也欢迎大家多多指正,反馈意见。
(本文为 AI科技大本营整理文章,转载请微信联系 1092722531。)
推荐

推荐阅读
iPhone曝严重漏洞,用户接听FaceTime前或被“监听”!
熬夜写代码,不如换女装入GitHub获上千Star?
“百练”成钢:NumPy 100练
小学生手写Python程序解魔方!这是高手,这绝对是高手!
鏖战九载,Google 是否会因 Oracle 而弃用 Java?
小心!你的脸正在成为色情片主角
聊聊云计算:为什么构建网站时常会用到负载均衡
年度大戏!以太坊大神怒怼智能合约之父,尼克·萨博到底做错了啥?
嫁人当嫁程序员
相关文章:
android 入门之一【开发环境搭建】
这里的开发环境采用Eclipseandroid 开发插件,其它的开发环境不做介绍 一.安装JDK android 开发语言是基于Java的,所以要做android的开发必须要安装JDK,并且对JDK的版本有一定的要求必须是JDK5 以上的版本,JDK5以前的版本android不…
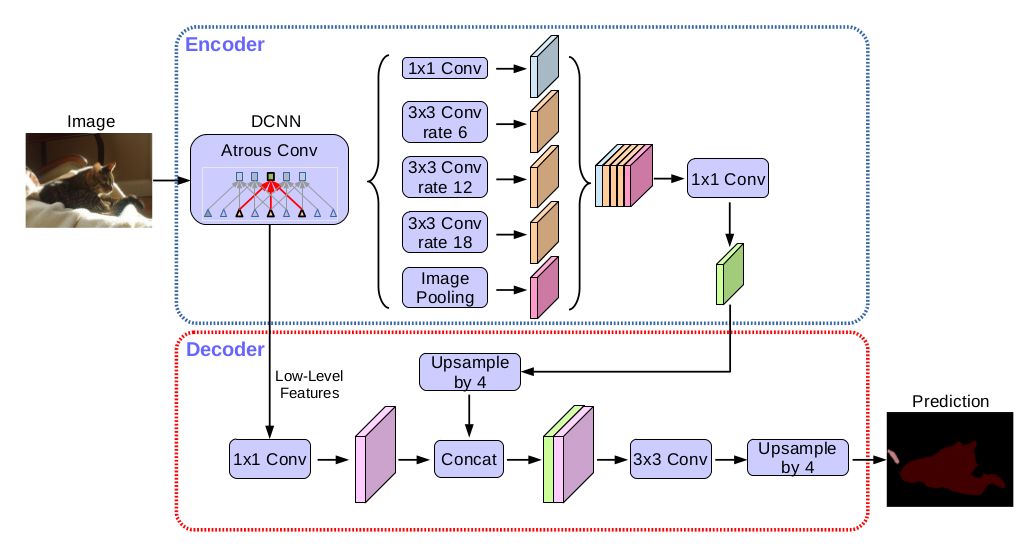
一块GPU就能训练语义分割网络,百度PaddlePaddle是如何优化的?
【引言】显存不足是训练语义分割网络常常遇见的问题,而显存是GPU计算中的稀缺资源。百度深度学习框架PaddlePaddle中的显存优化,不仅可以让研究人员在相同成本的计算设备上训练更大的模型,还可以在消费级别显卡上完成训练。在本篇文章中&…

【音频】Faad源码交叉编译
1、源码下载http://www.audiocoding.com/downloads.html2、解压后,进入目录执行如下命令aclocalautoheaderautomake --add-missingautoconf./configure --hostarm-fsl-linux-gnueabi CCarm-fsl-linux-gnueabi-gcc --prefix/home/faad/installmakemake install

springboot 整合redis 实现KeySpaceNotification 键空间通知
2019独角兽企业重金招聘Python工程师标准>>> 目录结构如下: application.properties配置文件(redis的配置): spring.redis.hostlocalhost spring.redis.pool.max-idle300 spring.redis.pool.max-wait3000 spring.redis…

黄聪:穿过主机访问虚拟机中的SQL服务 FOR VMware NAT
一般来说,大家都会在主机或者虚拟机中安装SQLIIS,但假如主机的IIS想利用虚拟机中的SQL服务怎么办呢? 以我的电脑为例子,主机系统:Windows 7 7600 RTM X64,安装IIS 7.5。虚拟机系统:Windows 2003…
【数据库】mysql报错 编码码1130 和错误码1146
1、错误编码1130 问题:1130-Hose‘172.16.12.129’is not allowed to connect to this MySQL server 原因:MySQL服务器没有创建,远程客户的账户信息 解决: 1.1 登录 :mysql -uroot 1.2 切换数据库:mysql>…

一键fxxk,代码修复神器拯救你
作者 | 一一出品 | AI科技大本营(ID:rgznai100)在成为一个合格的开发者之前,大多数人一般都经历过被命令行反复“fuck”蹂躏。当然,改代码改不动了,你的内心也是“无 fuck 可说”,尤其在检查半天之后发现这…
hive2.3.2安装使用
hive的安装简单一些,使用也比较简单,基础hadoop搭建好之后,只要初始化一些目录和数据库就好了 安装需要做几件事: 1.设立一个数据源作为元数据存储的地方,默认是derby内嵌数据库,不过不允许远程连接,所以换成mysql 2.配置java路径和classpath路径 下载地址: http://mirrors.shu…
Google经典面试题解析
作者 | Alex Golec译者 | 弯月责编 | 屠敏出品 | CSDN(ID:CSDNnews)在深入问题之前,有一个令人振奋的消息:我离开了Google!我激动地宣布,我已经加入了Reddit,并在纽约市担任项目经理…
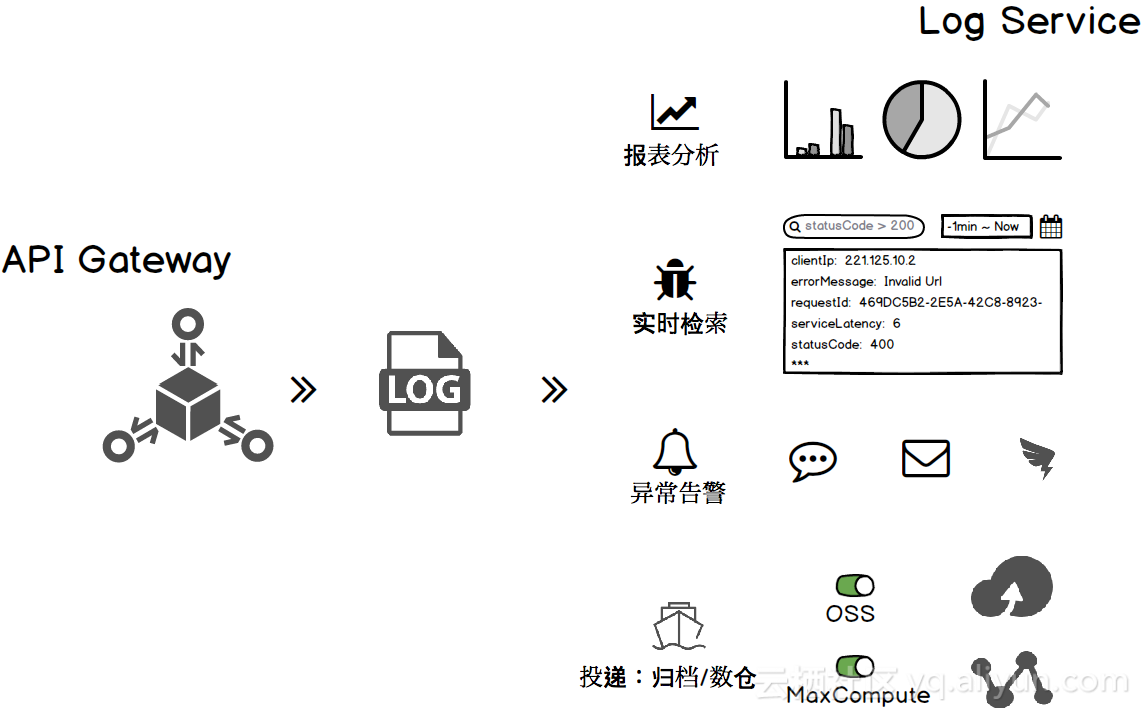
1分钟构建API网关日志解决方案
访问日志(Acccess Log)是由web服务生成的日志,每一次api请求都对应一条访问记录,内容包括调用者IP、请求的URL、响应延迟、返回状态码、请求和响应字节数等重要信息。 阿里云API网关提供API托管服务,在微服务聚合、前后…
ISQL*PLUS
1、有以下几种命令:环境:影响会话期间SQL语句的总体行为;格式化:格式化查询结果;文件处理:保存语句到脚本文件中,从脚本文件中运行语句;执行:从浏览器发送SQL语句到oracl…
【数据库】mysql 常用命令(一)
1、启动、停止mysql服务 1.0 sudo service mysql restart //测试有效 以下未测试 1.1 使用mysqld mysqld start mysqld stop 1.2 使用mysqld_safe启动、关闭MySQL服务 mysqld_safe 1.3 使用mysql.server启动、关闭MySQL服务 mysql.server stop …
15 个 JavaScript Web UI 库
新闻来源:speckboy.com几乎所有的富 Web 应用都基于一个或多个 Web UI 库或框架,这些 UI 库与框架极大地简化了开发进程,并带来一致,可靠,以及高度交互性的用户界面。本文介绍了 15 个非常强大的 JavaScript Web UI 库,…
【网络编程】MarioTCP
0、参考博客 《MarioTCP_一个可单机支持千万并发连接的TCP服务器 - JohanFong - CSDN博客》 http://blog.csdn.net/everlastinging/article/details/10894493 1、下载 sourceforge下载:https://sourceforge.net/projects/mariotcp/files/latest/download 2、安装…
Spring MVC-ContextLoaderListener和DispatcherServlet
2019独角兽企业重金招聘Python工程师标准>>> Spring MVC-ContextLoaderListener和DispatcherServlet 博客分类: spring java Tomcat或Jetty作为Servlet容器会为每一个Web应用构建一个ServletContext用于存放所有的Servlet, Filter, Listener。Spring MVC…
《中国人工智能ABC人才发展报告》发布,算法和应用类人才短缺
近日,百度云联手中国传媒大学、BOSS 直聘和百度指数发布了《中国人工智能 ABC 人才发展报告(2018版)》(以下简称“报告”)和百度云智学院2019 年人才认证体系。报告指出,从 2018 年的人才供需状况来看&…
博客域名改为http://bobli.cnblogs.com
本博客的域名已修改为:http://bobli.cnblogs.com/ 原来的地址还可以进入,希望搜索引擎快点更新过来。。。 感谢博客园管理员的帮助,效率非常之高!
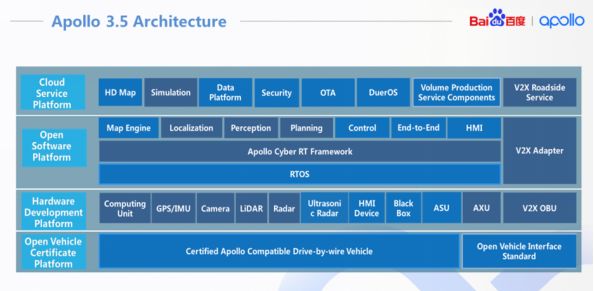
百度Apollo 3.5是如何设计Cyber RT计算框架的?
自百度Apollo自动驾驶平台开源以来,已快速迭代至 3.5 版本,代码行数超过 39 万行,合作伙伴超过 130 家,吸引了来自 97 个国家的超 15000 名开发者。无疑,Apollo 是目前世界范围内最活跃的自动驾驶开放平台之一。最新发…
Spark Streaming实践和优化
2019独角兽企业重金招聘Python工程师标准>>> Spark Streaming实践和优化 博客分类: spark 在流式计算领域,Spark Streaming和Storm时下应用最广泛的两个计算引擎。其中,Spark Streaming是Spark生态系统中的重要组成部分࿰…

Python | 一万多条拼车数据,看春运的迁徙图
作者 | 白苏,医疗健康领域产品经理一枚,Python&R爱好者来源 | InThirty编辑 | Jane今天是腊月二十八,你们都到家了吗?这篇文章,作者对北京、上海、广州、深圳、杭州等地 1万多条出行数据进行分析,得出了…
[转载] sql server 2000系统表解释
sql server 2000系统表解释汇总了几个比较有用的系统表,内容摘自联机帮助sysobjects---------------在数据库内创建的每个对象(约束、默认值、日志、规则、存储过程等)在表中占一行。只有在 tempdb 内,每个临时对象才在该表中占一…
【驱动】uboot环境变量分析
0、bootcmd 0.1 飞凌原设置 bootcmdif mmc rescan; then if run loadbootscript; then run bootscript; else if test ${bootdev} sd1; then echo update firmware.........;run update_from_sd;else echo mmc boot..........;if run loadimage; then run mmcboot; else run n…

python--属性魔法方法
转载于:https://www.cnblogs.com/Purp1e/p/8149773.html

利用三层交换机实现VLAN的通信实验报告
利用三层交换机实现VLAN的通信实验报告<?xml:namespace prefix o ns "urn:schemas-microsoft-com:office:office" />背景:要想实现VLAN之间的通讯,我们可以采用通过路由器实现VLAN间的通信 使用路由器实现VLAN间通信时,路由器与交换机…
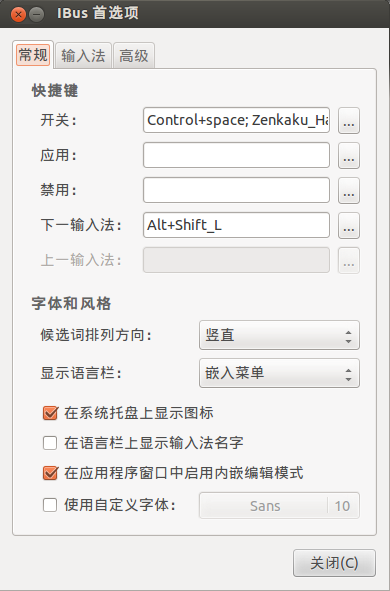
【Qt】Qt Creator中文输入设置
#【Qt】Qt Creator中文输入设置 一、ubuntu中文输入法的设置 1、在终端中输入: $ ibus-setup 弹出界面如图: 2、选择中文输入法 3、点击右上角设置–》选择系统设置–》选择语言支持 4、语言支持选择: 汉语(中国)…

为何Google将几十亿行源代码放在一个仓库?
作者 | Rachel Potvin,Josh Levenberg 译者 | 张建军 编辑 | apddd 【AI科技大本营导读】与大多数开发者的想象不同,Google只有一个代码仓库——全公司使用不同语言编写的超过10亿文件,近百TB源代码都存放在自行开发的版本管理系统Piper中&…
Java反射得到属性的值和设置属性的值
package com.whbs.bean; public class UserBean { private Integer id; private int age; private String name; private String address; public UserBean(){ System.out.println("实例化"); } public Integer getId() { return id; } public void setI…

ASP.NET 中的正则表达式
引言 Microsoft.NET Framework 对正则表达式的支持是一流的,甚至在 Microsoft ASP.NET 中也有依赖正则表达式语言的控件。本文介绍了深入学习正则表达式的基础知识和推荐内容。 本文主要面向对正则表达式知之甚少或没有使用经验,但却熟悉 ASP.NET、可借助…

如何用最强模型BERT做NLP迁移学习?
作者 | 台湾大学网红教授李宏毅的三名爱徒来源 | 井森堡,不定期更新机器学习技术文并附上质量佳且可读性高的代码。编辑 | Jane谷歌此前发布的NLP模型BERT,在知乎、Reddit上都引起了轰动。其模型效果极好,BERT论文的作者在论文里做的几个实验…