详解 | 推荐系统的工程实现

作者 | gongyouliu
来源 | 大数据工程师
01 写在前面
本篇文章作者会结合多年推荐系统开发的实践经验粗略介绍推荐系统的工程实现,简要说明要将推荐系统很好地落地到产品中需要考虑哪些问题及相应的思路、策略和建议,其中有大量关于设计哲学的思考,希望对从事推荐算法工作或准备入行推荐系统的读者有所帮助。
本篇文章主要从整体上来介绍推荐系统工程实现,以后发布的系列文章会逐步介绍工程实现的各个细节实现原理与策略。为了描述方便,本文主要基于视频推荐来讲解,作者这几年也一直在从事视频推荐系统开发的工作,其他行业的推荐系统工程实现思路类似。
02 推荐系统与大数据
推荐系统是帮助人们解决信息获取问题的有效工具,对互联网产品而也用户数和信息总量通常都是巨大的,每天收集到的用户在产品上的交互行为也是海量的,这些大量的数据收集处理就涉及到大数据相关技术,所以推荐系统与大数据有天然的联系,要落地推荐系统往往需要企业具备一套完善的大数据分析平台。
推荐系统与大数据平台的依赖关系如下图。大数据平台包含数据中心和计算中心两大抽象,数据中心为推荐系统提供数据存储,包括训练推荐模型需要的数据,依赖的其他数据,以及推荐结果,而计算中心提供算力支持,支撑数据预处理、模型训练、模型推断(即基于学习到的模型,为每个用户推荐)等。
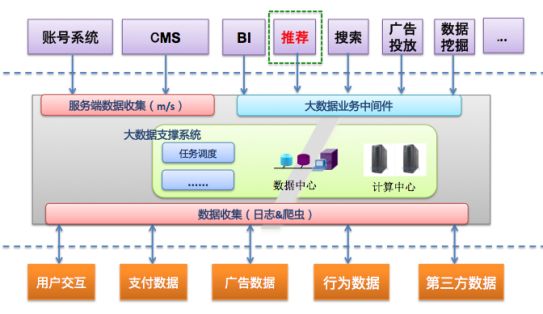
推荐系统在整个大数据平台的定位
大数据与人工智能具有千丝万缕的关系,互联网公司一般会构建自己的大数据与人工智能团队,构建大数据基础平台,基于大数据平台构建上层业务,包括商业智能(BI),推荐系统及其他人工智能业务,下图是典型的基于开源技术的视频互联网公司大数据与人工智能业务及相关的底层大数据支撑技术。
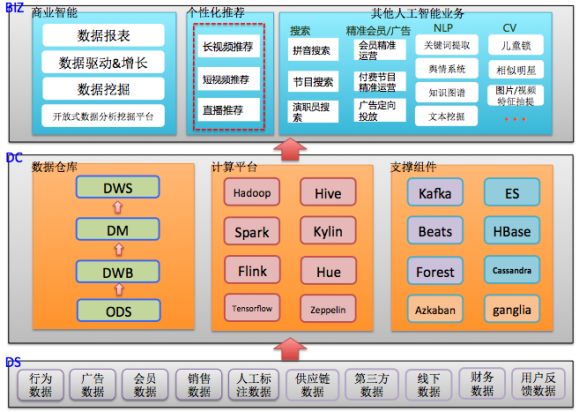
大数据支撑下的人工智能技术体系(DS:数据源,DC:大数据中心,BIZ:上层业务)
在产品中整合推荐系统是一个系统工程,怎么让推荐系统在产品中产生价值,真正帮助到用户,提升用户体验的同时为平台方提供更大的收益是一件有挑战的事情,整个推荐系统的业务流可以用下图来说明,它是一个不断迭代优化的过程,是一个闭环系统。
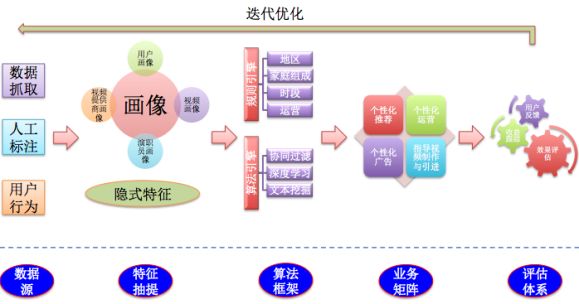
有了上面这些介绍,相信读者对大数据与推荐系统的关系有了一个比较清楚的了解,下面会着重讲解推荐系统工程实现相关的知识。
03 推荐系统业务流及核心模块
先介绍一下构建一套完善的推荐系统涉及到的主要业务流程及核心模块,具体流程如下图,下面分别介绍各个模块:
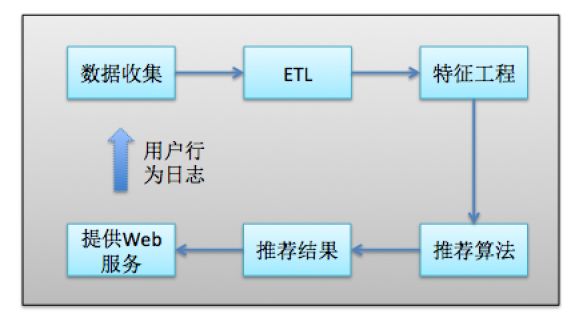
数据收集模块
构建推荐模型需要收集很多数据,包括用户行为数据,用户相关数据及推荐“标的物”相关数据。如果将推荐系统比喻为厨师做菜,那么这些数据是构建推荐算法模型的原材料。巧妇难为无米之炊,要构建好的推荐算法收集到足够多的有价值的数据是非常关键和重要的。
ETL模块
收集到的原始数据一般是非结构化的,ETL模块的主要目的是从收集到的原始数据中提取关键字段(拿视频行业来说,用户id,时间,播放的节目,播放时长,播放路径等都是关键字段),将数据转化为结构化的数据存储到数据仓库中。同时根据一定的规则或策略过滤掉脏数据,保证数据质量的高标准。在互联网公司中,用户行为数据跟用户规模呈正比,所以当用户规模很大时数据量非常大,一般采用HDFS、Hive、HBase等大数据分布式存储系统来存储数据。
用户相关数据及推荐“标的物”相关数据一般是结构化的数据,一般是通过后台管理模块将数据存储到MySQL、ProgreSQL等关系型数据库中。
特征工程模块
推荐系统采用各种机器学习算法来学习用户偏好,并基于用户偏好来为用户推荐“标的物”,而这些推荐算法用于训练的数据是可以“被数学所描述”的,一般是向量的形式,其中向量的每一个分量/维度就是一个特征,所以特征工程的目的就是将推荐算法需要的,以及上述ETL后的数据转换为推荐算法可以学习的特征。
当然,不是所有推荐算法都需要特征工程,比如,如果要做排行榜相关的热门推荐,只需要对数据做统计排序处理就可以了。最常用的基于物品的推荐和基于用户的推荐也只用到用户id,标的物id,用户对标的物的评分三个维度,也谈不上特征工程。像logistic回归等复杂一些的机器学习算法需要做特征工程,一般基于模型的推荐算法都需要特征工程。
特征工程是一个比较复杂的过程,要做好需要很多技巧、智慧、行业知识、经验等,在这篇文章中作者不作详细介绍。
推荐算法模块
推荐算法模块是整个推荐系统的核心之一,该模块的核心是根据具体业务及可利用的所有数据设计一套精准、易于工程实现、可以处理大规模数据的(分布式)机器学习算法,进而可以预测用户的兴趣偏好。这里一般涉及到模型训练、预测两个核心操作。下面用一个图简单描述这两个过程,这也是机器学习的通用流程。
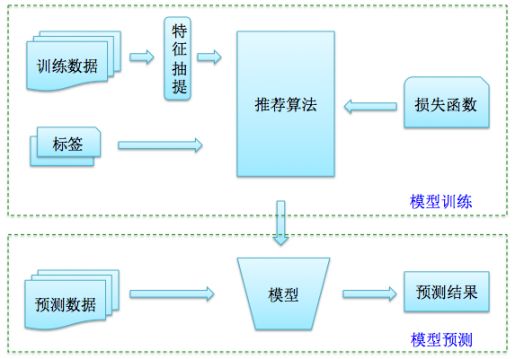
好的推荐工程实现,希望尽量将这两个过程解耦合,做到通用,方便用到各种推荐业务中,后面在推荐系统架构设计一节中会详细讲解具体的设计思路和哲学。
推荐结果存储模块
作者在最开始做推荐系统时由于没有经验,开始将推荐结果存储在Mysql中,当时遇到最大的问题是每天更新用户的推荐时,需要先找到用户存储的位置,再做替换,操作复杂,并且当用户规模大时,高并发读写,大数据量存储,Mysql也扛不住,现在最好的方式是采用CouchBase,Redis等可以横向扩容的数据库,可以完全避开MySQL的缺点。
在计算机工程中有“空间换时间”的说法,对于推荐系统来说,就是先计算好每个用户的推荐,将推荐结果存储下来,通过预先将推荐结果存下来,可以更快的为用户提供推荐服务,提升用户体验。由于推荐系统会为每个用户生成推荐结果,并且每天都会(基本全量)更新用户的推荐结果,一般采用NoSql数据库来存储,并且要求数据库可拓展,高可用,支持大规模并发读写。
推荐结果一般不是直接在模型推断阶段直接写入推荐存储数据库,较好的方式是通过一个数据管道(如kafka)来解耦,让整个系统更加模块化,易于维护拓展。
Web服务模块
该模块是推荐系统直接服务用户的模块,该模块的主要作用是当用户在UI上触达推荐系统时,触发推荐接口,为用户提供个性化推荐,该模块的稳定性、响应时长直接影响到用户体验。跟上面的推荐存储模块类似,Web服务模块也需要支持高并发访问、水平可拓展、亚秒级(一般200ms之内)响应延迟。
下图是作者公司相似影片推荐算法的一个简化版业务流向图,供大家与上面的模块对照参考:
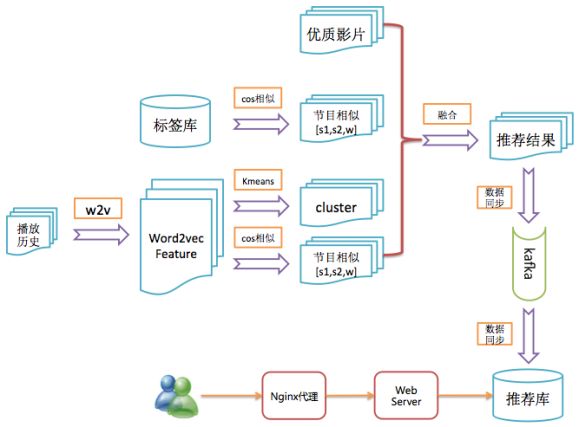
相似影片业务流
04 推荐系统支撑模块
推荐系统想要很好的稳定的发挥价值,需要一些支撑业务来辅助,这些支撑业务虽然不是推荐系统的核心模块,但却是推荐业务稳定运行必不可少的部分,主要包括如下4大支撑模块,下面分别简述各个模块的作用和价值。
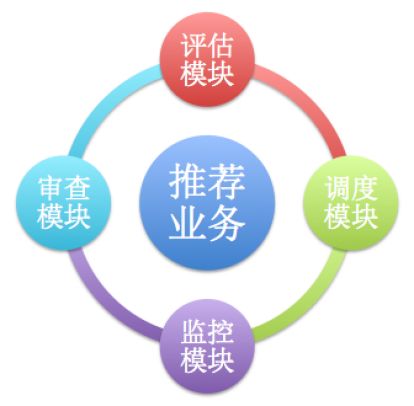
推荐系统核心支撑模块
评估模块
推荐评估模块的主要作用是评估整个推荐系统的质量及价值产出。一般来说可以从两个维度来评估。
离线评估:主要是评估训练好的推荐模型的“质量”,模型在上线服务之前需要评估该模型的准确度,一般是将训练数据分为训练集和测试集,训练集用于训练模型,而测试集用来评估模型的预测误差。
在线评估:模型上线提供推荐服务过程中来评估一些真实的转化指标,比如转化率、购买率、点击率、播放时长等。线上评估一般会结合AB测试,先放一部分量,如果效果达到期望再逐步拓展到所有用户,避免模型线上效果不好严重影响用户体验和收益指标等。
调度模块
一个推荐业务要产生价值,所有依赖的任务都要正常运行。推荐业务可以抽象为有向无环图(第六节推荐系统架构设计会讲到将推荐业务抽象为有向无环图),因此需要按照该有向图的依赖关系依次执行每个任务,这些任务的依赖关系就需要借助合适的调度系统(比如Azkaban)来实现,早期我们采用Crontab来调度,当任务量多的时候就不那么方便了,Crontab也无法很好解决任务依赖关系。
监控模块
监控模块解决的是当推荐业务(依赖的)任务由于各种原因调度失败时可以及时告警,通过邮件或者短信通知运维或者业务的维护者,及时发现问题,或者可以在后台自动拉起服务。同时可以对服务的各种其他状态做监控,比如文件大小、状态变量的值、日期时间等与业务正常执行相关的状态变量,不正常时及时发现问题。
审查模块
审查模块是对推荐系统结果数据格式的正确性、有效性进行检查,避免错误产生,一般的处理策略是根据业务定义一些审查用例(类似测试用例),在推荐任务执行前或者执行阶段对运算过程做check,发现问题及时告警。举两个例子,如果你的DAU是100w,每天大约要为这么多用户生成个性化推荐结果,但是由于一些开发错误,只计算了20w用户的个性化推荐,从监控是无法发现问题的,如果增加推荐的用户数量跟DAU的比例控制在1附近这个审查项,就可以避免出现问题;在推荐结果插入数据库过程中,开发人员升级了新的算法,不小心将数据格式写错(如Json格式不合法),如果不加审查,会导致最终插入的数据格式错误,导致接口返回错误或者挂掉,对用户体验有极大负面影响。
05 推荐系统范式
推荐系统的目的是为用户推荐可能喜欢的标的物,这个过程涉及到用户、标的物两个重要要素,我们可以根据这两个要素的不同组合产生不同的推荐形态,即所谓的不同“范式(paradigm)”(数学专业的同学不难理解范式,如果不好理解可以将范式看成具备某种相似性质的对象的集合),根据我自己构建推荐系统的经验可以将推荐系统总结为如下5种范式,这5中范式可以应用到产品的各种推荐场景中,后面会拿视频APP举例说明具体的应用场景。
范式1:完全个性化范式:为每个用户提供个性化的内容,每个用户推荐结果都不同;
常见的猜你喜欢就是这类推荐,可以用于进入首页的综合类猜你喜欢推荐,进入各个频道(如电影)页的猜你喜欢推荐。下图是电视猫首页兴趣推荐,就是为每个用户提供不一样的个性化推荐;
范式2:群组个性化范式:首先将用户分组(根据用户的兴趣,将兴趣相似的归为一组),每组用户提供一个个性化的推荐列表,同一组的用户推荐列表一样,不同组的用户推荐列表不一样;
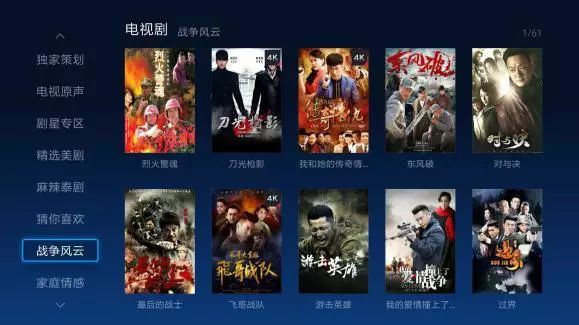
这里举一个在作者公司利用范式2做推荐的例子,我们在频道页三级列表中,会根据用户的兴趣对列表做个性化重排序,让与用户更匹配的节目放到前面,提升节目转化,但是在实现时,为了节省存储空间,先对用户聚类,同一类用户兴趣相似,对这一类用户,列表的排序是一样的,但是不同类的用户的列表是完全不一样的。见下图的战争风云tab,右边展示的节目集合总量不变,只是在不同组的用户看到的排序不一样,排序是根据与用户的兴趣匹配度高低来降序排列的。
范式3:非个性化范式:为所有用户提供完全一样的推荐;
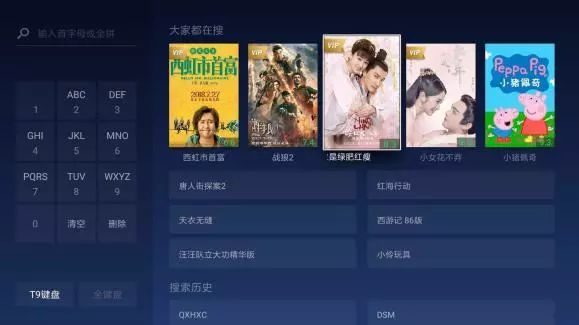
比如各类排行榜业务,既可以作为首页上的一个独立的推荐模块,方便用户发现新热内容,也可以作为猜你喜欢推荐新用户冷启动的默认推荐,下图是搜索模块当用户未输入搜索关键词时给出的热门内容,也是采用该范式的例子;
范式4:标的物关联标的物范式:为每个标的物关联一组标的物,作为用户在访问标的物详情页时的推荐,每个用户都是相同的标的物;
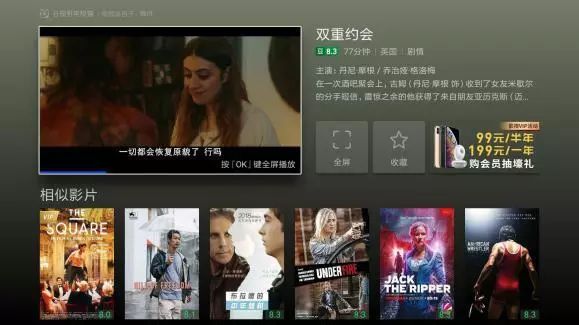
当用户浏览一个电影时,可以通过关联相似的电影,为用户提供更多的选择空间(下图就是电视猫电影详情页关联的相似影片);还可以当用户播放一个节目退出时,推荐用户可能还喜欢的其他节目;针对短视频,可以将相似节目做成连播推荐列表,用户播放当前节目直接连播相似节目,提升节目分发和用户体验;
范式5:笛卡尔积范式:每个用户跟每个标的物的组合产生的推荐都不相同,不同用户在同一个视频的详情页看到的推荐结果都不一样;
该范式跟4类似,只不过不同用户在同一个节目得到的关联节目不一样,会结合用户的兴趣,给出更匹配用户兴趣的关联节目;
由于每个用户跟每个标的物的组合推荐结果都不一样,往往用户数和标的物的数量都是巨大的,没有足够的资源事先将所有的组合的推荐结果先计算存储下来,一般是在用户触发推荐时实时计算推荐结果呈现给用户,计算过程也要尽量简单,在亚秒级就可以算完,比如利用用户的播放历史,过滤掉用户已经看过的关联节目;
下面给一个简单的图示来说明这5种范式,让读者有一个直观形象的理解。
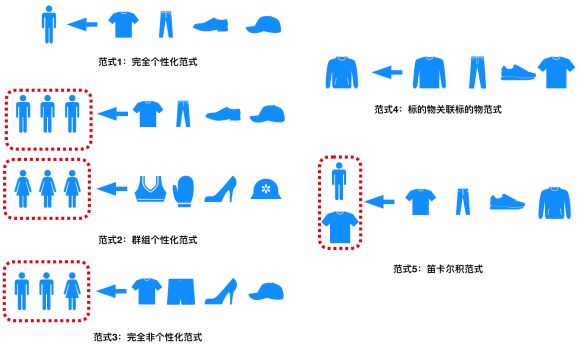
推荐算法的5种范式
总之,推荐系统不是孤立存在的对象,它一定是要整合到具体的业务中,在合适的产品交互流程中触达用户,通过用户触发推荐行为。所以,推荐系统要应用到产品中需要嵌入到用户使用产品的各个流程(页面)中。当用户访问首页时,可以通过综合推荐(范式1)来给用户提供个性化推荐内容,当用户访问详情页,可以通过相似影片(范式4)提供相似标的物推荐,当用户进入搜索页尚未输入搜索内容时,可以通过热门推荐给用户推送新热节目(范式3)。这样处处都有推荐,才会使产品显得更加智能。所有这些产品形态基本都可以用上面介绍的5种范式来概括。
06 推荐系统架构设计
作者在早期构建推荐系统时由于经验不足,而业务又比较多,当时的策略是每个算法工程师负责几个推荐业务(一个推荐业务对应一个推荐产品形态),由于每个人只对自己的业务负责,所以开发基本是独立的,每个人只关注自己的算法实现,虽然用到的算法是一样的,但前期在开发过程中没有将通用的模块抽象出来,每个开发人员从ETL、算法训练、预测到插入数据库都是独立的,并且每个人在实现过程中整合了自己的一些优化逻辑,一竿子插到底,导致资源(计算资源,存储资源,人力资源)利用率不高,开发效率低下。经过几年的摸索,作者在团队内部构建了一套通用的算法组件Doraemon框架(就像机器猫的小口袋,有很多工具供大家方便构建推荐业务),尽量做到资源的节省,大大提升了开发效率。开发过程的蜕变,可以用下面的图示简单说明,从中读者也可以对Doraemon架构落地前后的推荐业务开发变化有个大致的了解。
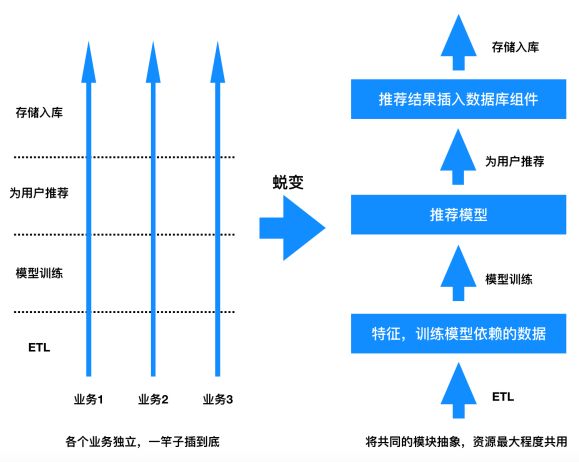
Doraemon框架前后开发方式对比
作者构建Doraemon框架的初衷是希望构建推荐业务就像搭积木一样(见下图),可以快速构建一套算法体系,快速上线业务。算法或者处理逻辑就像一块一块的积木,而算法依赖的数据(及数据结构)就是不同积木之间是否可以衔接的“接口”。

构建推荐业务就像搭积木一样简单(图片来源于网络)
本着上面朴素的思想,下面作者详细说说构建这套体系的思路和策略。
为了支撑更多类型的推荐业务,减少系统的耦合,便于发现和追踪问题,节省人力成本,方便算法快速上线和迭代,需要设计比较好的推荐系统架构,而好的推荐系统架构应该具备6大原则:通用性,模块化,组件化,一致性,可拓展性,抽象性。下面分别对上述6大原则做简要说明,阐述清楚它们的目标和意义。
通用性:所谓通用,就是该架构具备包容的能力,业务上的任何推荐产品都可以用这一套架构来涵盖和实现。
模块化:模块化的目的在于将一个业务按照其功能做拆分,分成相互独立的模块,以便于每个模块只包含与其功能相关的内容,模块之间通过一致性的协议调用。将一个大的系统模块化之后,每个模块都可以被高度复用。模块化的目的是为了重用,模块化后可以方便重复使用和插拨到不同平台,不同推荐业务逻辑中。
组件化:组件化就是基于可重用的目的,将一个大的软件系统拆分成多个独立的组件,主要目的就是减少耦合。一个独立的组件可以是一个软件包、web服务、web资源或者是封装了一些函数的模块。这样,独立出来的组件可以单独维护和升级而不会影响到其他的组件。组件化的目的是为了解耦,把系统拆分成多个组件,分离组件边界和责任,便于独立升级和维护,组件可插拔,通过组件的拼接和增减提供更丰富的能力。
组件化和模块化比较类似,目标分别是为了更好的解耦和重用,就像搭积木一样构建复杂系统。
一致性:指模块的数据输入输出采用统一的数据交互协议,做到整个系统一致。
可拓展性:系统具备支撑大数据量,大并发的能力,并且容易在该系统中增添新的模块,提供更丰富的能力,让业务更加完备自治。
抽象性:将相似的操作和流程抽象为统一的操作,主要目的是简化系统设计,让系统更加简洁通用。针对推荐系统采用数学上的概念抽象如下:
操作/算法抽象:我们先对数据处理或者算法做一个抽象,将利用输入数据通过“操作”得到输出的的过程抽象为“算子”,按照这个抽象,ETL、机器学习训练模型、机器学习推断都是算子。其中输入输出可以是数据或者模型。
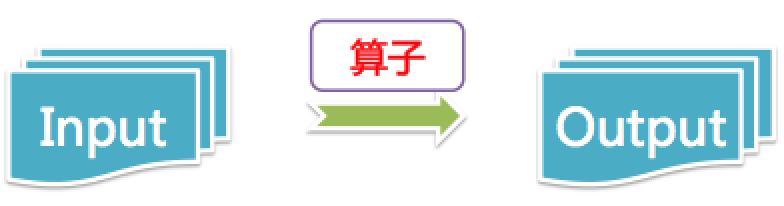
算法或者操作的算子抽象
业务抽象:任何一个推荐业务可以抽象为由数据/模型为节点,算子为边的“有向无环图”。下图是深度学习的算法处理流程,整个算法实现就是一个有向无环图。
下图是我们做的一个利用深度学习做电影猜你喜欢的推荐业务流程,整个流程是由各个算子通过依赖关系链接起来的,就像一个有向无环图。
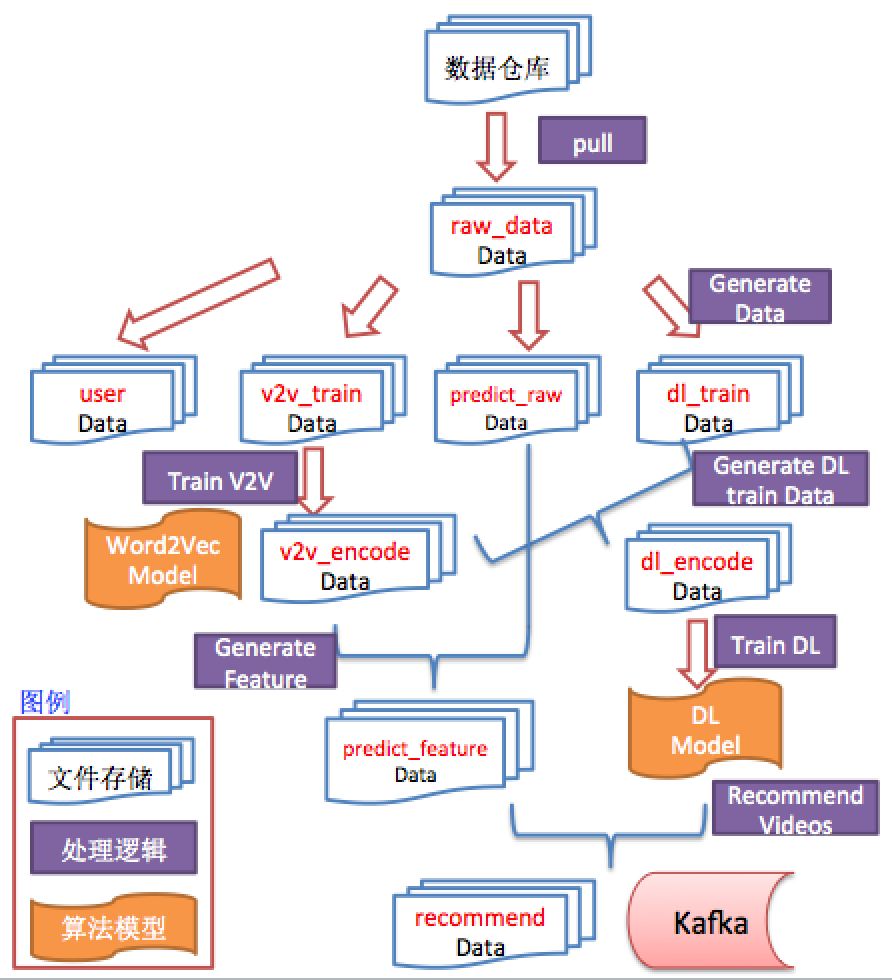
推荐业务的有向无环图抽象
根据Doraemon系统的设计哲学及上面描述的推荐系统的核心模块,结合业内,一般将推荐系统分为召回(将用户可能会喜欢的标的物取出来)和排序(将取出的标的物按照用户喜好程度降序排列,最喜欢的排在前面)两个过程,推荐系统可以根据如下方式进行设计。
基础组件:业务枚举类型、常量、路径处理、配置文件解析等。
数据读入组件:包括从HDFS、数据仓库、HBase、Mysql等相关数据库读取数据的操作,将这些操作封装成通用操作,方便所有业务线统一调用;
数据流出组件:类似数据读入组件,将推荐结果插入最终存储(如Redis,CouchBase等)的操作封装成算子,我们一般是将推荐结果流入Kafka,利用Kafka作为数据管道,最终再从Kafka将数据插入推荐存储服务器;
算法组件:这个是整个推荐系统的核心。在工程实现过程中,我们将推荐系统中涉及到的算子抽象为3个接口, AlgParameters(算子依赖的参数集合)、 Algorithm/AlgorithmEx (具体的算法实现,如果算法依赖模型,采用AlgorithmEx,比如利用模型做推断)、Model(算法训练后的模型,包括模型的导入、导出等接口)。所有的算子实现实现上面3个接口的抽象方法。下图给出了这3个接口包含的具体方法以及Spark mllib中的矩阵分解基于该抽象的实现。
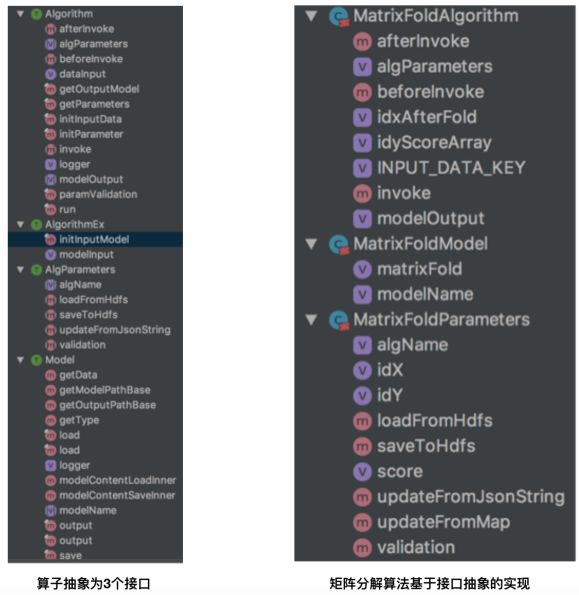
在我们的业务实践中,发现上述抽象很合理,基本推荐业务涉及到的所有算子(ETL、模型训练、模型推荐、排序框架、数据过滤,具体业务逻辑等)都可以采用该方式很好的抽象。
评估组件:主要是包括算法训练过程的离线评估等;
其他支撑组件:比如AB测试等,都可以整合到Doraemon框架中;
这里要特别说一下数据(模型),数据作为算子的输入输出,一定要定义严格的范式(具备固定的数据结构,比如矩阵分解训练依赖的数据有三列,一列用户id,一列物品id,一列用户对物品的评分),Spark的DataFrame可以很好的支撑各种数据类型。数据格式定义好后,在算子读入或者输出时,可以对类型做校验,可以很好的避免很多由于业务开发疏忽导致的问题。这有点类似强类型编程语言,在编译过程(类似算子)可以检查出类型错误。
我们将上面的6类组件封装成一个Doraemon的lib库,供具体的推荐业务使用。
基于大数据的数据中心和计算中心的抽象,我们将所有推荐业务中涉及到的数据和算子分别放入数据仓库和算子仓库,开发推荐业务时根据推荐算法的业务流程从这两个仓库中拿出对应的“积木”来组装业务,参考下图。
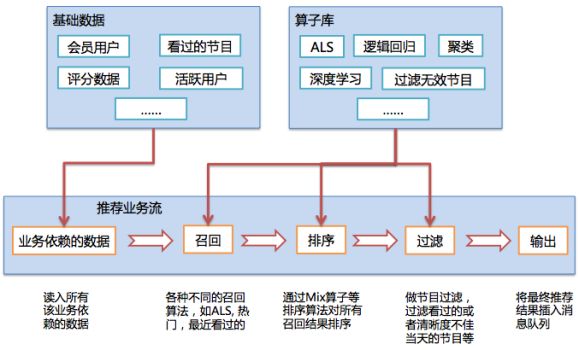
基于Doraemon框架的算法组件化开发方式
基于上面的设计原则,推荐业务可以抽象为“数据流”和“算子流”两个流的相互交织,利用Doraemon框架构建一个完善的推荐业务流程如下图。
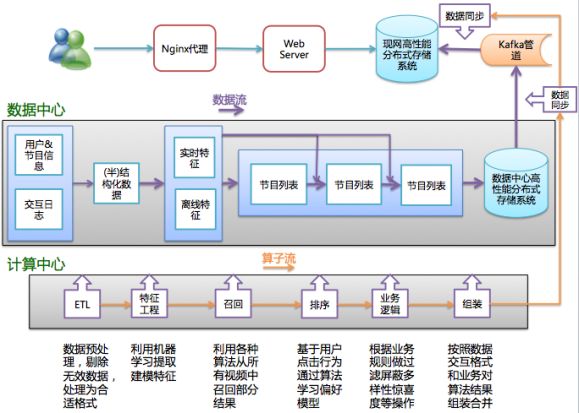
基于Doraemon框架开发的推荐业务,数据流与算子流相互交织,非常清晰
另外,如果公司做产品线的拓展,比如今日头条拓展新产品抖音、西瓜视频、火山小视频等,可以基于上面所提到的“推荐算法的范式”实现很多推荐业务(比如猜你喜欢、相似影片、热门推荐等),将这些业务封装到一个DoraemonBiz.jar的jar包,这样这些能力可以直接平移到新的产品线,赋能新业务。这种操作就是二次封装,具有极大的威力,下面给一个形象的图示来说明这种二次赋能的逻辑,让大家更好理解这种思想。
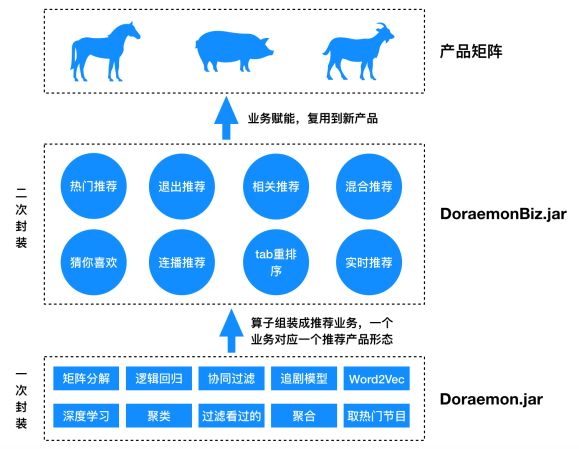
通过二次封装,构建推荐业务单元,赋能到新产品矩阵
从上面的介绍,相信大家已经感受到了Doraemn框架的威力了,有了这套框架,我们可以高效的开发算法了,如果有新的技术突破,我们可以将这些新算法实现并封装到Doraemon框架中,不断拓展Doraemon的能力,让Doraemon成长为具备更多技能(算子)的巨人!
07 推荐系统工程实现的设计哲学
要为推荐系统设计一套好用高效的工程框架并不容易,往往需要踩过很多坑,通过多年经验的积累才能深刻领悟。前面在“推荐系统架构设计”一节已经说了很多构建Doraemon框架的设计原则,本节试图从整个推荐业务工程实现的角度给出一些可供参考的设计哲学,以便大家可以更好的将推荐系统落地到业务中。
什么是好的推荐系统工程实现?
个人认为好的工程实现需要满足如下几个原则:
01.别人很容易理解你的逻辑;
02.按照业务流/数据流来组织代码结构;
03.便于debug;
04.保证数据存储、代码模块、业务逻辑的一致性;
设计好的推荐系统工程架构的原则?
01.尽量将逻辑拆解为独立的小单元;
02.代码单元的输入输出定义清晰;
03.设置合适的交互出入口;
04.确定通用一致的数据交互格式;
05.数据存储、业务功能点、代码单元保持一一对应;
怎么设计好的推荐系统工程架构?
01.确定思考问题的主线:数据流or 业务流;
02.画出业务流或者数据流的架构图;
03.确定核心功能模块;
04.根据核心功能模块组织代码目录结构,数据存储结构;
05.定义清晰明确的数据格式;
下图是作者团队开发的深度学习猜你喜欢推荐系统(基于Tensorflow开发)的业务流程图,对应的代码组织结构和对应的数据在本地文件系统中的存储结构,基本按照上述设计原则来做,看起来很清晰,方便理解和问题排查。
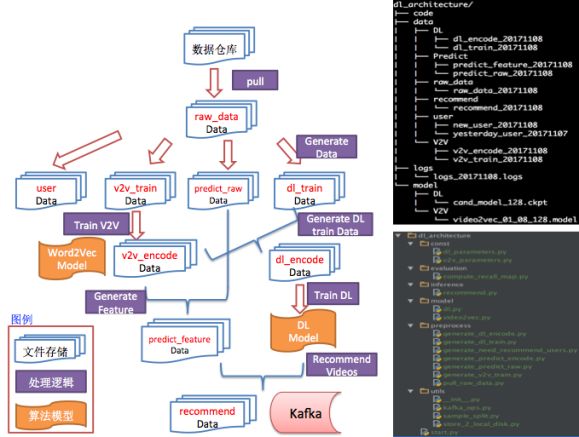
业务流,数据存储,代码工程结构保持对应
08 近实时个性化推荐
推荐系统在实际业务实现时一般是T+1推荐(每天更新一次推荐,今天利用昨天之前的数据计算用户的推荐结果),随着移动互联网的深入发展,特别是今日头条和快手等新闻,短视频APP的流行,越来越多的公司将T+1和实时策略相结合(比如采用流行的lambda架构,下图是一个采用lambda架构的推荐架构图,供参考)将推荐系统做到了近实时推荐,根据用户的兴趣变化实时为用户提供个性化推荐。像新闻、短视频这类满足用户碎片化时间需求的产品,做到实时个性化可以极大提升用户体验,这样可以更好地满足用户需求,提升用户在产品的停留时间。这里我们只是简单的介绍了一下实时个性化推荐,我在后续的系列文章中会详细讲解实时推荐系统。
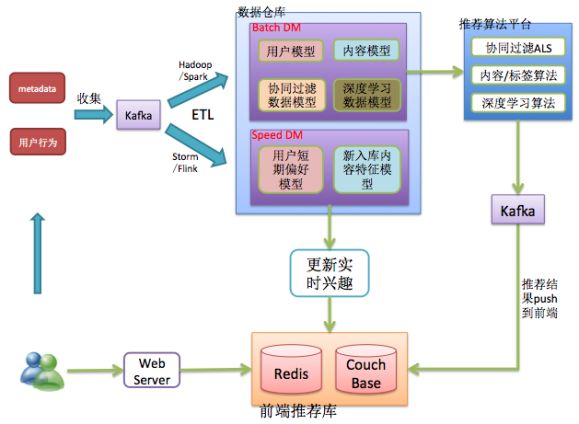
推荐系统的lambda架构
09 推荐系统业务落地需要关注的问题
推荐系统要想很好的落地产生价值,除了算法实现、核心模块和支撑模块构建外,还有很多方面需要考虑,下面简单描述一下其他需要考虑的点,这些点都是非常重要的,深入理解这些问题,对真正发挥出推荐系统的价值有非常大的帮助。
二八定律:你的产品可能包含很多推荐模块,但是在投入精力迭代优化过程中,需要将核心精力放到用户触点多的产品(位置好,更容易曝光给用户的推荐产品)上,因为这些产品形态占整个推荐价值产出的绝大部分。这个道理看起来谁都懂,但在实际工作中一直坚守这个原则,还是很难的;
牛逼的算法与工程可实现性易用性之间的平衡:刚从事推荐算法开发的工程师会觉得算法的价值是巨大的,一个牛逼的算法可以让产品一飞冲天。殊不知很多在顶级会议上发表的绝大多数“高大上”的算法遇到工业级海量数据大规模的分布式计算难以在工程上落地。好的推荐算法一定要是易于工程实现,跟公司当前的技术架构、人员能力、可用资源是匹配的;
推荐系统冷启动:冷启动是推荐系统非常重要的一块,特别是对新产品,这块设计策略好不好直接影响用户体验,冷启动有很多实现方案,作者以后会单独介绍冷启动的实现策略;
推荐系统的解释:给用户提供一个推荐理由有时会达到事半功倍的效果,能够提升用户体验,促进用户的点击购买。推荐理由又是很难做的,主要是因为现在很多推荐算法(特别是深度学习算法)可解释性不强,给你做出了推荐可能很精准,但是整个系统无法给你解释为什么给你推荐。拿推荐系统给你推荐了电影A来说明,我们可以从其他的途径来做解释, 比如“因为你喜欢B”(电影B跟A有一定的相似性),“今天是国庆节,为你推荐A”,“今天是雨天,为你推荐A”,“跟你兴趣相似的人都喜欢A”等等,只要可以挖掘出用户的行为,场景(时间,空间,上下文等),跟推荐的电影的某种联系,这种联系都可以作为推荐解释的理由,不必拘泥于一定要从推荐算法原理中寻找解释;
推荐系统UI设计和交互逻辑:好的产品UI和交互逻辑有时比好的算法更管用,推荐算法工程师一定要有这种意识,平时在做推荐系统时,也要往这方面多思考,当前的UI及交互是否合理,是否还有更好的方式,多参考或者咨询一下设计师的思路想法,多体验一下竞品,往往你会有新的收获。我不是这方面的专家,这里只给大家举一个电视猫产品的例子(见下图), 好的UI交互可以极大提升用户体验和点击。
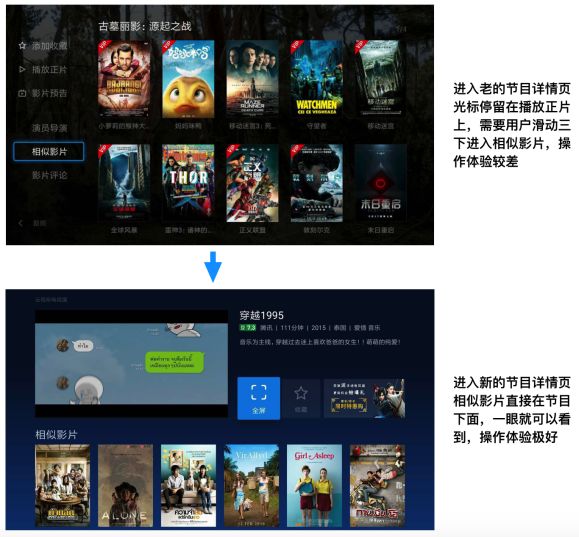
好的UI和交互的价值甚至比好的算法大很多
推荐系统的价值度量: 让推荐系统发挥价值, 首先要度量出推荐系统的价值,我们需要将推荐系统的价值量化出来,只有量化出推荐系统的价值,推荐工程师的价值才能够被公司认可,老板才愿意在推荐系统上投入资源。这里我简单说一下推荐系统的价值产出方式(拿视频推荐举例说明)。
(1)推荐系统可以提升用户体验和留存,让用户更快更便捷找到想看的电影,减少找片时间:可以统计出推荐产生的播放量,总播放时长,人均播放时长,这些数值指标跟大盘的平均指标对比,可以体现推荐系统的优势,推荐系统的这些指标在大盘的占比也可以衡量推荐系统所占的分量;
(2)推荐系统可以创造收益:通过精准推荐会员节目,用户通过推荐的会员节目购买会员可以产生会员收益;在推荐的节目上做贴片广告,用户播放推荐的节目让广告曝光,可以产生广告收益;这两块收益需要量化出来,体现出推荐系统支撑商业变现的能力;
10 推荐系统的技术选型
根据第二节推荐系统与大数据的描述,推荐业务落地依赖大数据技术, 推荐系统的中间过程和结果的存储需要依赖数据库,推荐系统接口实现需要依赖web服务器。这些方面需要的软件和技术在前面基本都有简单介绍,也都有开源的软件供选择,对创业公司来说,没有资源和人力去自研相关技术,选择合适的开源技术是最好最有效的方案。
本节详细描述一下推荐系统算法开发所依赖的机器学习软件选型,方便大家在工程实践中参考选择。
由于推荐系统落地强依赖于大数据相关技术,而最流行的开源大数据技术基于Hadoop生态系统,所以推荐算法技术选型要围绕大数据生态系统来发展,可以无缝的将大数据和人工智能结合起来。
基于大数据生态系统有很多机器学习软件可以用来开发推荐系统,比如Apache旗下的工具SparkMLlib、Flink-ML、Mahout、Storm、SystemML。以及可以运行在Hadoop生态系统上的DeepLearning4J(Java深度学习软件),TonY(TensorflowonYARN,LinkedIn开源的),CaffeOnSpark(雅虎开源的),BigDL(基于Spark上的深度学习,Intel开源的)等。
随着人工智能第三次浪潮的到来,以Tensorflow,Pytorch,MXNet等为代表的深度学习工具得到工业界的大量采用,Tensorflow上有关于推荐系统、排序框架的模块和源代码,可供学习参考,通过简单修改可以直接用于推荐业务中。
另外像xgboost,scikit-learn,H2O,gensim等框架也是非常流行实用的框架,可以用于实际工程项目中。
国内也有很多开源的机器学习框架,腾讯开源的Angel(基于参数服务器的分布式机器学习平台,可以直接运行在yarn上),百度开源的PaddlePaddle(深度学框架),阿里开源的Euler(图深度学习框架),X-DeepLearning(深度学习框架),也值得大家学习参考。
作者所在公司主要采用SparkMllib,Tensorflow,gensim等框架来实现推荐系统算法的开发。
至于开发语言,Hadoop生态圈基本采用Java/Scala,深度学习生态圈基本采用Python(Tensorflow、Pytorch都采用python作为用户使用软件的开发语言,但它们的底层还是用C++开发的),所以采用Java/Scala,Python作为开发语言有很多开源框架可供选择,相关的生态系统也很完善。
随着大数据、云计算、深度学习驱动的人工智能浪潮的发展,越来越多的顶级科技公司开源出很多好用有价值的机器学习软件工具,可以直接用于工程中,也算是创业公司的福音。
11 推荐系统的未来发展
随着移动互联网、物联网的发展,5G技术的商用,未来推荐系统一定是互联网公司产品的标配技术和标准解决方案,推荐系统会被越来越多的公司采用,用户也会越来越依赖推荐系统来做出选择。
在工程实现上,推荐系统会越来越采用实时推荐技术来更快的响应用户的兴趣(需求)变化,给用户强感知,提升用户体验,增加公司收益。
个人觉得未来会有专门的开源的推荐引擎出现,并且是提供一站式服务,让搭建推荐系统成本越来越低。同时随着人工智能的发展,越来越多的云计算公司会提供推荐系统的PAAS或者SAS服务(现在就有很多创业公司提供推荐服务,只不过还做的不够完善),创业公司可以直接购买推荐系统云服务,让搭建推荐系统不再是技术壁垒,到那时推荐系统的价值将会大放异彩!到那时,不是每个创业公司都需要推荐算法开发工程师了,只要你理解推荐算法原理,知道怎么将推荐系统引进产品中创造价值,就可以直接采购推荐云服务。就像李开复博士最新的畅销书《AI未来》中所说的,很多工作会被AI取代,所以推荐算法工程师也要有危机意识,要不断培养对业务的敏感度,对业务的理解,短期是无法被机器取代的,到时候说不定可以做一个推荐算法商业策略师。
12 结语
本文是作者多年推荐系统学习、实践经验的总结,希望能够帮助到即将入行推荐系统开发的读者或者推荐系统开发人员,让大家少走弯路。
(*本文为AI科技大本营转载文章,转载请联系原作者)
推荐阅读:
Google又逆天:语音输入离线实时输出文字,仅占80MB!然而……
西工大开源拥挤人群数据集生成工具,大幅提升算法精度 | CVPR 2019
R和Python谁更好?这此让你「鱼与熊掌」兼得
10行Python,搭建一个游戏AI | 视频教程
Node.js 与 JavaScript 基金会正式合并,JS 喜提新主场
云计算时代运维的出路在哪?
30岁的万维网活不长了! 蒂姆·伯纳斯·李要借去中心化亲手杀死它, 你再也不用担心...
互联网裁员潮亲历者:那些阵痛、挣扎与去向
没有一个人,能躲过程序员的诱惑!

❤点击“阅读原文”,查看历史精彩文章。
相关文章:

【linux】Valgrind工具集详解(六):使用Valgrind gdbserver和GDB调试程序
一、概述 在Valgrind下运行的程序不是由CPU直接执行的。相反,它运行在Valgrind提供的合成CPU上。这就是调试器在Valgrind上运行时无法调试程序的原因。 二、快速入门 在使用Memcheck工具时使用GDB调试程序,启动方式如下: 1、valgrind --vgdb = yes --vgdb-error = 0 可执…
C++模式学习------工厂模式
工厂模式属于创建型模式,大致可以分为简单工厂模式、抽象工厂模式。 简单工厂模式,它的主要特点是需要在工厂类中做判断,从而创造相应的产品。 1 enum PTYPE2 {3 ProdA 0,4 ProdB 15 };6 7 class ProductBase8 {9 public: 10 v…

JavaScript中正则表达式学习(一)
2019独角兽企业重金招聘Python工程师标准>>> 1.判断是不是手机号码(实际判断是不是11位数字,可以用\d来匹配数字) 表单部分代码: <form name"form1" > <lable>请输入:</lable>…

深度 | 推荐系统评估
作者 | gongyouliu 来源 | 大数据工程师作者在上篇文章《推荐系统的工程实现》中提到推荐系统要很好地落地到业务中,需要搭建支撑模块,其中效果评估模块就是其中非常重要的一个。本篇文章作者来详细说明怎么评估(Evaluating)推荐系统的效果,…
【linux】Valgrind工具集详解(七):Memcheck(内存错误检测器)
一、概述 Memcheck是一个内存错误检测器。它可以检测C和C ++程序中常见的以下问题: 1、非法内存:如越界、释放后继续访问; 2、使用未初始化的值; 3、释放内存错误:如double-free(同一内存上执行了两次free)、或者 malloc、new、new[] 与 free、delete、delete[]错配使用…
Kafka系列三 java API操作
使用java API操作kafka 1.pom.xml <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.x…
用自己的×××身换来男朋友的健康
MASKDIY BLOG开通作 他把她当成孩子一样宠着,不让她工作,更不让她做一点点家务。他对她说:我就是要让你幸福,一点苦也不让你尝,等你快乐的长到二十岁,我就娶你,继续宠你养你一辈子。 他是一…

R和Python谁更好?这次让你「鱼与熊掌」兼得
作者 | Parul Pandey译者 | 大鱼责编 | Jane出品 | Python大本营(公众号id:pythonnews)如果你从事在数据科学领域,提到编程语言,一定能马上想到 R 语言和 Python语言(以下分别简称 R、Python)。…
大学实习就要来了,买个性价比高的笔记本应付一下
人才市场历来有着“金三银四”、“金九银十”招聘高峰期之说。“金九银十”指的是每年9、10月份,各大企业为第二年拓宽事务许多吸纳人才,一起应届高校毕业生找作业,供需两旺。而“金三银四”则是职场人拿到了奖金,看清了得失&…
【linux】Valgrind工具集详解(八):Memcheck命令行参数详解
【linux】Valgrind工具集详解(五):命令行详解中不够全,在此专门针对Memcheck工具中的命令行参数做一次详细的解释。 Memcheck命令行选项 –leak-check=<no|summary|yes|full> [default: summary] 程序执行完毕后,搜索内存泄漏。默认值为summary,只统计发生了多少…
PHP 5.3 中不建议使用的(部分)函数列表
2019独角兽企业重金招聘Python工程师标准>>> PHP 5.3.0 introduces two new error levels: E_DEPRECATED and E_USER_DEPRECATED. The E_DEPRECATED error level is used to indicate that a function or feature has been deprecated. The E_USER_DEPRECATED level…
【linux】Valgrind工具集详解(九):Memcheck检查的内容和方法
一、值的有效性 1、什么是值的有效性? 英文原文是Valid-value (V) bits,直译过来就是有效值(V)位。 我将它理解为值的有效性,就是判断在内存或CPU的物理地址中存储的数据是否有效,比如在内存中变量(int i)代表的物理位置(不是地址),没有初始化,就去使用它,是否合…

微软亚研院提出用于语义分割的结构化知识蒸馏 | CVPR 2019
作者 | CV君来源 | 我爱计算机视觉今天跟大家分享一篇关于语义分割的论文,刚刚上传到arXiv的CVPR 2019接收论文《Structured Knowledge Distillation for Semantic Segmentation》,通讯作者单位为微软亚洲研究院。作者信息:作者分别来自澳大利…

Elam的git笔记:(二)git的安装与基本操作介绍
Giti安装 下载地址下载:https://git-scm.com/download/win自动下载64位,如果是32位系统,取消下载后自行下载对应版本双击安装,自选项可根据自身需求自由选择 习惯于cmd的同学可以选择第二个安装完成后在桌面右键,选择G…
创新驱动未来,浪潮持续深耕信息安全市场
2010年,我国信息安全行业在快速发展中涌现出众多优秀的安全厂商,以创新的产品及技术推动中国信息安全产业做大做强。其中,浪潮创造性地开发出了英信安全服务器,加上此前推出的浪潮服务器安全加固系统()&…

Pig变飞机?AI为什么这么蠢 | Adversarial Attack
整理 | Jane责编 | Jane出品 | AI科技大本营(公众号id:rgznai100)【编者按】这篇文章的起意有两点:一是由刚刚过去的 315 打假日,智能语音机器人在过去一年拨出的超 40 亿电话,联想到前一段时间引起大家热烈…
【linux】Valgrind工具集详解(十):SGCheck(检查栈和全局数组溢出)
一、概述 SGCheck是一种用于检查栈中和全局数组溢出的工具。它的工作原理是使用一种启发式方法,该方法源于对可能的堆栈形式和全局数组访问的观察。 栈中的数据:例如函数内声明数组int a[10],而不是malloc分配的,malloc分配的内存是在堆中。 SGCheck和Memcheck是互补的:它…
shell脚本之 if,case,for的用法
目录一.条件选择:if语句二.条件判断:case语句三.for循环 一.条件选择:if语句 单分支if 判断条件;then 条件为真的分支代码fi 例子:判断一个数字是否等于10 #!/bin/bashread -p 输入一个数字 numif [ $num -eq 10 ];thenecho 该数字…
RAC 修改 DB 实例名 步骤
在我之前的2篇Blog 里提到了RAC ASM实例名和 DB实例名的问题。 RAC 中 ASM 实例名 与 节点的对应关系 http://blog.csdn.net/tianlesoftware/archive/2011/03/23/6272244.aspx RAC 修改 ASM实例名 的步骤 http://blog.csdn.net/tianlesoftware/archive/2011/03/25/6275827.asp…
【linux】Valgrind工具集详解(十二):DHAT:动态堆分析器
一、概述 DHAT动态堆分析器。Massif(堆分析器)是在程序结束后输出分析结果,而DHAT是实时输出结果,所以叫做动态堆分析器。Massif只记录堆内存的申请和释放,DHAT还会分析堆空间的使用率、使用周期等信息。 DHAT的功能:它首先记录在堆上分配的块,通过分析每次内存访问时所…

微软(中国)CTO韦青:人工智能是拿来用的,不是拿来炒的
随着近几年全球各大科技巨头纷纷入场人工智能领域,催生了一大批技术的发展和落地:AI 医疗、智能翻译、图像识别、智能社交机器人、无人驾驶……这些技术的背后都离不开“深度学习”。但与此同时,越来越多弱点的凸显,也引起了公众对…
概念被滥用 你真的了解云计算吗?
在Amazon、Google和IBM这些公司推出云计算的概念之后,其他一些公司也开始跟进了。但遗憾的是,其中一部分只是打着云计算的旗号,实际所做的却不值得称为云。 云计算的概念越来越流行,但这个概念也有被人滥用的趋势。Amazon、Google…

近万个Python开源项目中精选Top34!
作者 | Mybridge编译 | 仲培艺出品 | CSDN(ID:CSDNNews)【导语】踏着人工智能、区块链的东风,近年来一路“横冲直撞”的 Python 在实现了从小众语言到主流的完美转身后,一头扎进了 2019,依旧没有透出丝毫停…
【linux】Valgrind工具集详解(十三):Helgrind(线程错误检测器)
一、概述 Helgrind用于检测C、C ++和Fortran程序中使用符合POSIX标准的线程函数造成的同步错误。 POSIX中关于线程的主要抽象描述有:共享公共地址空间的一组线程、线程创建、线程连接、线程退出、互斥(锁)、条件变量(线程间事件通知)、读写器锁、自旋锁、信号量和线程等…
vivado烧写bin文件到flash 中
点击 bitstream setting ,将 bin_file 勾上,点击 OK。 2)点击 generate bitstream ,生成 bit 文件和 bin 文件 3)点击 open hardware manager,连接板子。 4)选中芯片,右键如下操作。…
如何使dropship第三方销售是基于发货数量,而不是基于LIV发票校验的数量
不好意思,我何慕雄这两天说drop ship第三方销售已经是说烂了,但是,还是要得继续说,毕竟这个问题也是挺复杂的。 什么是第三方销售呢?第三方销售是指客户向我们下销售订单,而我们没有货,但是根据…

图神经网络综述:方法及应用 | Deep Reading
整理 | 耿玉霞,浙江大学直博生。研究方向:知识图谱,零样本学习,自然语言处理等。来源 | 开放知识图谱(公众号id:OpenKG-CN)责编 | Jane近日,清华刘知远老师组在 arXiv 上发表了一篇关…
【linux】top命令详解
1、参数详解 $ top -helpprocps-ng version 3.3.9 Usage:top -hv | -bcHiOSs -d secs -n max -u|U user -p pid(s) -o field -w [cols]-b:打印所有程序 -c:以命令行的形式显示程序名 -d:设置刷新间隔时间 -h:显示帮助 -H…
关于近期的总结
北京的黄金三月,应去年的计划,年初换工作,这是回来之后找工作的第四个周,目前收到offer一份,在昨天之前我还深深的觉得自己真的是失败,菜的不行,去年一年的努力都努力到哪里去了,越想…

让QQ按时上下班
朋友在临近的一所幼儿园当头儿,说最近发现有小老师在上班期间用QQ聊天,影响孩子的看护,问我有没有办法限制她们在上班期间聊天,顺便看看他们上班期间都在干什么,我说试试吧,估计得花钱。 说干就干ÿ…