Tensorflow框架是如何支持分布式训练的?

参加 2019 Python开发者日,请扫码咨询 ↑↑↑
作者 | 杨旭东
转载自知乎《算法工程师的自我修养》专栏
Methods that scale with computation are the future of AI.
—Rich Sutton, 强化学习之父
大数据时代的互联网应用产生了大量的数据,这些数据就好比是石油,里面蕴含了大量知识等待被挖掘。深度学习就是挖掘数据中隐藏知识的利器,在许多领域都取得了非常成功的应用。然而,大量的数据使得模型的训练变得复杂,使用多台设备分布式训练成了必备的选择。
Tensorflow是目前比较流行的深度学习框架,本文着重介绍tensorflow框架是如何支持分布式训练的。
分布式训练策略
模型并行
所谓模型并行指的是将模型部署到很多设备上(设备可能分布在不同机器上,下同)运行,比如多个机器的GPUs。当神经网络模型很大时,由于显存限制,它是难以完整地跑在单个GPU上,这个时候就需要把模型分割成更小的部分,不同部分跑在不同的设备上,例如将网络不同的层运行在不同的设备上。
由于模型分割开的各个部分之间有相互依赖关系,因此计算效率不高。所以在模型大小不算太大的情况下一般不使用模型并行。
在tensorflow的术语中,模型并行称之为"in-graph replication"。
数据并行
数据并行在多个设备上放置相同的模型,各个设备采用不同的训练样本对模型训练。每个Worker拥有模型的完整副本并且进行各自单独的训练。
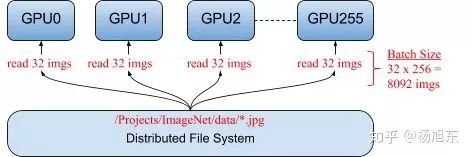
图1. 数据并行示例
相比较模型并行,数据并行方式能够支持更大的训练规模,提供更好的扩展性,因此数据并行是深度学习最常采用的分布式训练策略。
在tensorflow的术语中,数据并行称之为"between-graph replication"。
分布式并行模式
深度学习模型的训练是一个迭代的过程,如图2所示。在每一轮迭代中,前向传播算法会根据当前参数的取值计算出在一小部分训练数据上的预测值,然后反向传播算法再根据损失函数计算参数的梯度并更新参数。在并行化地训练深度学习模型时,不同设备(GPU或CPU)可以在不同训练数据上运行这个迭代的过程,而不同并行模式的区别在于不同的参数更新方式。
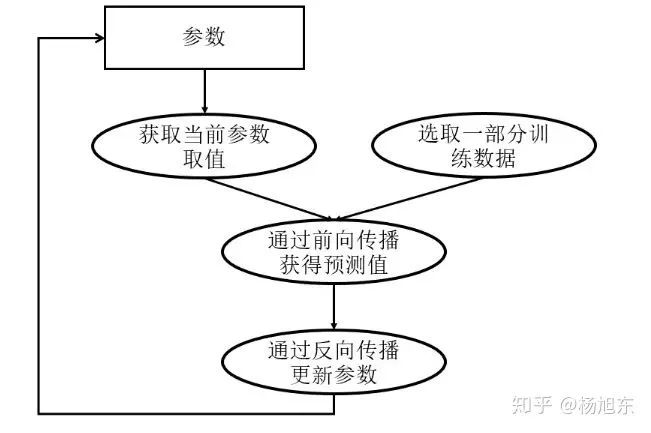
图2. 深度学习模型训练流程图
数据并行可以是同步的(synchronous),也可以是异步的(asynchronous)。
异步训练
异步训练中,各个设备完成一个mini-batch训练之后,不需要等待其它节点,直接去更新模型的参数。从下图中可以看到,在每一轮迭代时,不同设备会读取参数最新的取值,但因为不同设备读取参数取值的时间不一样,所以得到的值也有可能不一样。根据当前参数的取值和随机获取的一小部分训练数据,不同设备各自运行反向传播的过程并独立地更新参数。可以简单地认为异步模式就是单机模式复制了多份,每一份使用不同的训练数据进行训练。
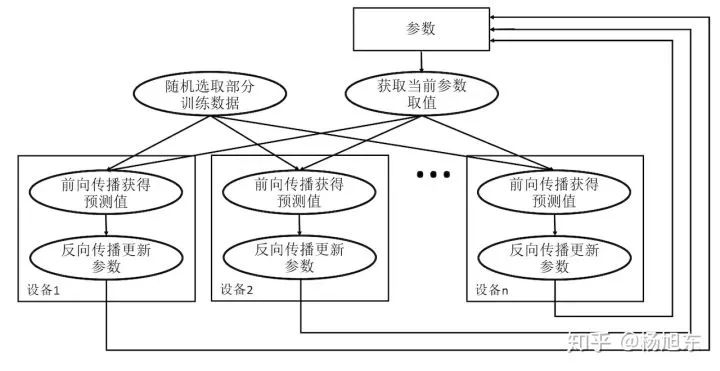
图3. 异步模式深度学习模型训练流程图
异步训练总体会训练速度会快很多,但是异步训练的一个很严重的问题是梯度失效问题(stale gradients),刚开始所有设备采用相同的参数来训练,但是异步情况下,某个设备完成一步训练后,可能发现模型参数已经被其它设备更新过了,此时这个设备计算出的梯度就过期了。由于梯度失效问题,异步训练可能陷入次优解(sub-optimal training performance)。图4中给出了一个具体的样例来说明异步模式的问题。其中黑色曲线展示了模型的损失函数,黑色小球表示了在t0时刻参数所对应的损失函数的大小。假设两个设备d0和d1在时间t0同时读取了参数的取值,那么设备d0和d1计算出来的梯度都会将小黑球向左移动。假设在时间t1设备d0已经完成了反向传播的计算并更新了参数,修改后的参数处于图4中小灰球的位置。然而这时的设备d1并不知道参数已经被更新了,所以在时间t2时,设备d1会继续将小球向左移动,使得小球的位置达到图4中小白球的地方。从图4中可以看到,当参数被调整到小白球的位置时,将无法达到最优点。
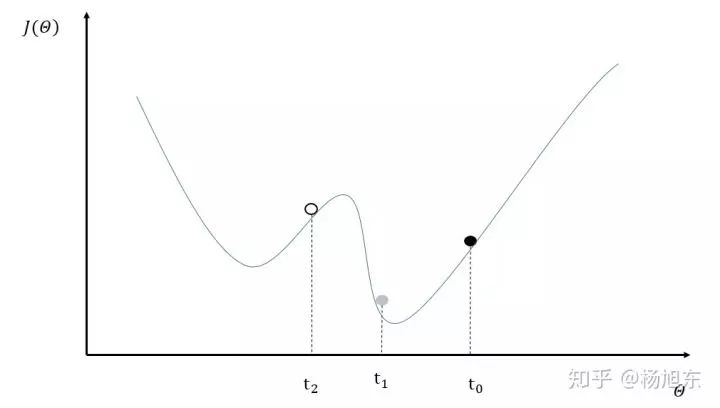
图4. 异步模式训练深度学习模型存在的问题示意图
在tensorflow中异步训练是默认的并行训练模式。
同步训练
所谓同步指的是所有的设备都是采用相同的模型参数来训练,等待所有设备的mini-batch训练完成后,收集它们的梯度后执行模型的一次参数更新。在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。单个设备不会单独对参数进行更新,而会等待所有设备都完成反向传播之后再统一更新参数 。
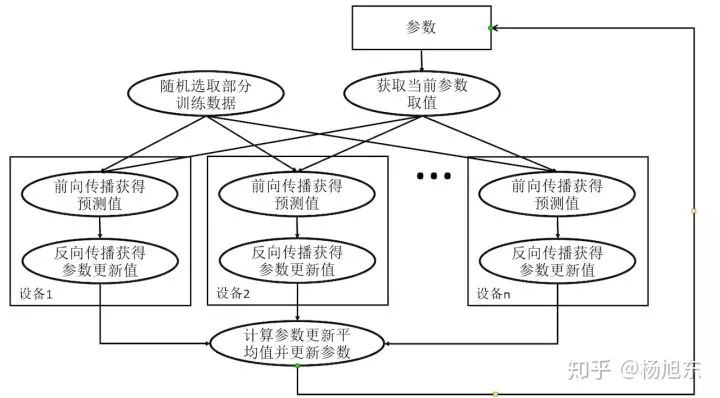
图5. 同步模式深度学习模型训练流程图
同步模式相当于通过聚合多个设备上的mini-batch形成一个更大的batch来训练模型,相对于异步模式,在同步模型下根据并行的worker数量线性增加学习速率会取得不错的效果。如果使用tensorflow estimator接口来分布式训练模型的话,在同步模式下需要适当减少训练步数(相对于采用异步模式来说),否则需要花费较长的训练时间。Tensorflow estimator接口唯一支持的停止训练的条件就全局训练步数达到指定的max_steps。
Tensorflow提供了tf.train.SyncReplicasOptimizer类用于执行同步训练。通过使用SyncReplicasOptimzer,你可以很方便的构造一个同步训练的分布式任务。把异步训练改造成同步训练只需要两步:
在原来的Optimizer上封装SyncReplicasOptimizer,将参数更新改为同步模式;
optimizer = tf.train.SyncReplicasOptimizer(optimizer, replicas_to_aggregate=num_workers)在MonitoredTrainingSession或者EstimatorSpec的hook中增加sync_replicas_hook:
sync_replicas_hook = optimizer.make_session_run_hook(is_chief, num_tokens=0)
小结
下图可以一目了然地看出同步训练与异步训练之间的区别。
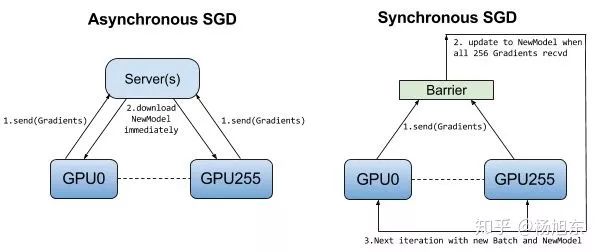
图6. 异步训练模式与同步训练模式的对比
同步训练看起来很不错,但是实际上需要各个设备的计算能力要均衡,而且要求集群的通信也要均衡,类似于木桶效应,一个拖油瓶会严重拖慢训练进度,所以同步训练方式相对来说训练速度会慢一些。
虽然异步模式理论上存在缺陷,但因为训练深度学习模型时使用的随机梯度下降本身就是梯度下降的一个近似解法,而且即使是梯度下降也无法保证达到全局最优值。在实际应用中,在相同时间内使用异步模式训练的模型不一定比同步模式差。所以这两种训练模式在实践中都有非常广泛的应用。
分布式训练架构
Parameter Server架构
Parameter server架构(PS架构)是深度学习最常采用的分布式训练架构。在PS架构中,集群中的节点被分为两类:parameter server和worker。其中parameter server存放模型的参数,而worker负责计算参数的梯度。在每个迭代过程,worker从parameter sever中获得参数,然后将计算的梯度返回给parameter server,parameter server聚合从worker传回的梯度,然后更新参数,并将新的参数广播给worker。
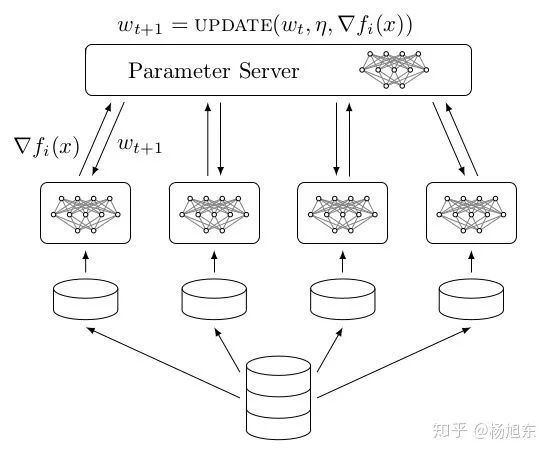
图7. Parameter Server架构
Ring AllReduce架构
PS架构中,当worker数量较多时,ps节点的网络带宽将成为系统的瓶颈。
Ring AllReduce架构中各个设备都是worker,没有中心节点来聚合所有worker计算的梯度。Ring AllReduce算法将 device 放置在一个逻辑环路(logical ring)中。每个 device 从上行的device 接收数据,并向下行的 deivce 发送数据,因此可以充分利用每个 device 的上下行带宽。
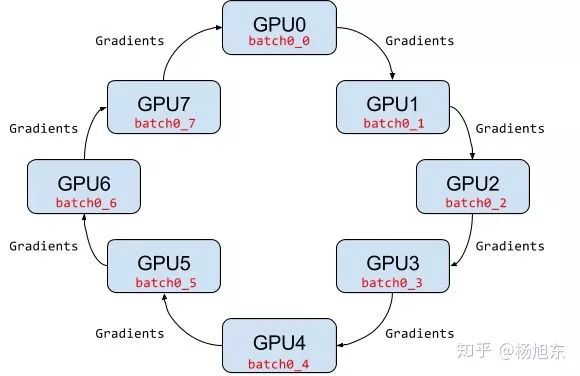
图8. Ring AllReduce架构示例
使用 Ring Allreduce 算法进行某个稠密梯度的平均值的基本过程如下:
将每个设备上的梯度 tensor 切分成长度大致相等的 num_devices 个分片;
ScatterReduce 阶段:通过 num_devices - 1 轮通信和相加,在每个 device 上都计算出一个 tensor 分片的和;
AllGather 阶段:通过 num_devices - 1 轮通信和覆盖,将上个阶段计算出的每个 tensor 分片的和广播到其他 device;
在每个设备上合并分片,得到梯度和,然后除以 num_devices,得到平均梯度;
以 4 个 device上的梯度求和过程为例:
ScatterReduce 阶段:
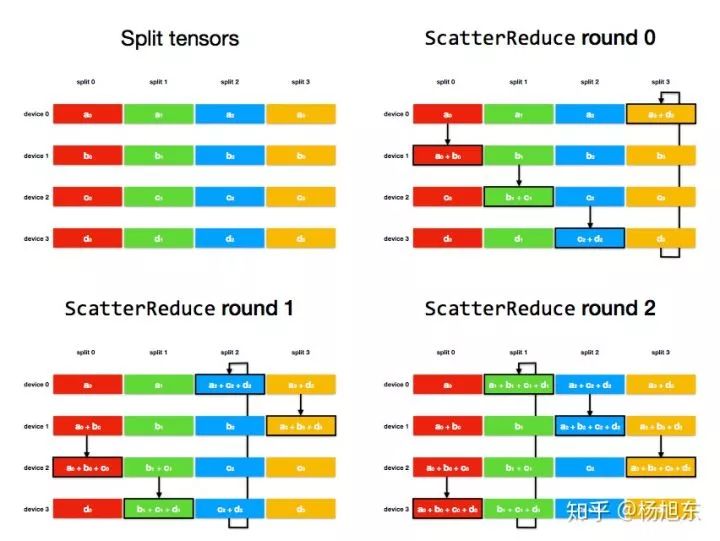
图9. Ring-AllReduce算法的ScatterReduce阶段
经过 num_devices - 1 轮后,每个 device 上都有一个 tensor 分片进得到了这个分片各个 device 上的和。
AllGather 阶段:
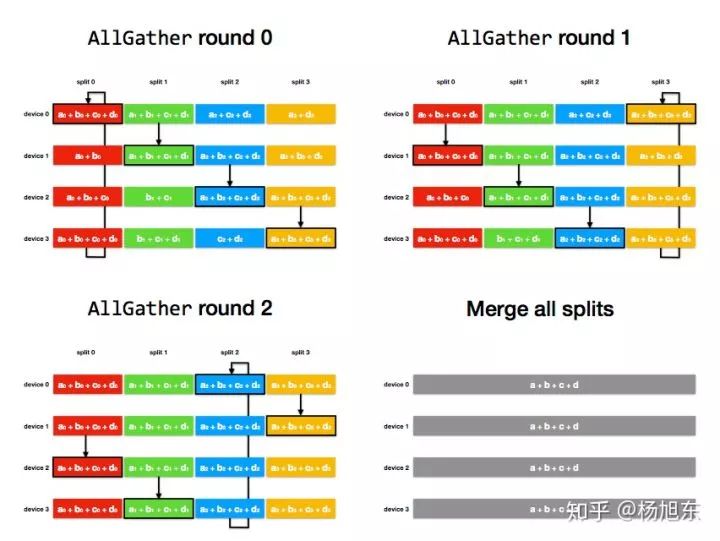
图10. Ring-AllReduce算法的AllGather阶段
经过 num_devices - 1 轮后,每个 device 上都每个 tensor 分片都得到了这个分片各个 device 上的和;
由上例可以看出,通信数据量的上限不会随分布式规模变大而变大,一次 Ring Allreduce 中总的通信数据量是:
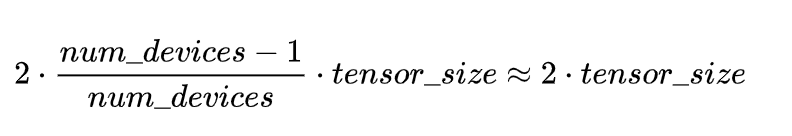
相比PS架构,Ring Allreduce架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。Ring Allreduce的训练速度基本上线性正比于GPUs数目(worker数)。
2017年2月百度在PaddlePaddle平台上首次引入了ring-allreduce的架构,随后将其提交到tensorflow的contrib package中。同年8月,Uber为tensorflow平台开源了一个更加易用和高效的ring allreduce分布式训练库Horovod。最后,tensorflow官方终于也在1.11版本中支持了allreduce的分布式训练策略CollectiveAllReduceStrategy,其跟estimator配合使用非常方便,只需要构造tf.estimator.RunConfig对象时传入CollectiveAllReduceStrategy参数即可。
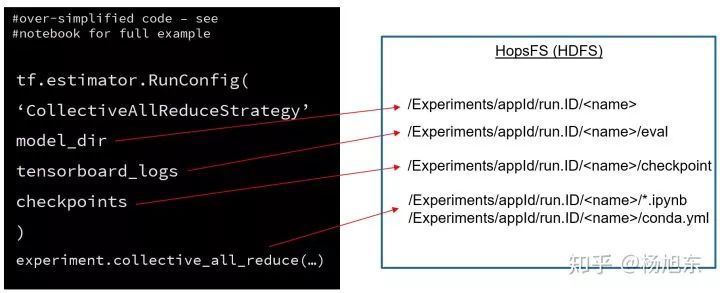
图11. 使用CollectiveAllReduceStrategy的伪代码
分布式tensorflow
推荐使用 TensorFlow Estimator API 来编写分布式训练代码,理由如下:
开发方便,比起low level的api开发起来更加容易
可以方便地和其他的高阶API结合使用,比如Dataset、FeatureColumns、Head等
模型函数model_fn的开发可以使用任意的low level函数,依然很灵活
单机和分布式代码一致,且不需要考虑底层的硬件设施
可以比较方便地和一些分布式调度框架(e.g. xlearning)结合使用
要让tensorflow分布式运行,首先我们需要定义一个由参与分布式计算的机器组成的集群,如下:
cluster = {'chief': ['host0:2222'],
'ps': ['host1:2222', 'host2:2222'],
'worker': ['host3:2222', 'host4:2222', 'host5:2222']}
集群中一般有多个worker,需要指定其中一个worker为主节点(cheif),chief节点会执行一些额外的工作,比如模型导出之类的。在PS分布式架构环境中,还需要定义ps节点。
要运行分布式Estimator模型,只需要设置好TF_CONFIG环境变量即可,可参考如下代码:
# Example of non-chief node:
os.environ['TF_CONFIG'] = json.dumps(
{'cluster': cluster,
'task': {'type': 'worker', 'index': 1}})
# Example of chief node:
os.environ['TF_CONFIG'] = json.dumps(
{'cluster': cluster,
'task': {'type': 'chief', 'index': 0}})
# Example of evaluator node (evaluator is not part of training cluster)
os.environ['TF_CONFIG'] = json.dumps(
{'cluster': cluster,
'task': {'type': 'evaluator', 'index': 0}})
定义好上述环境变量后,调用tf.estimator.train_and_evaluate即可开始分布式训练和评估,其他部分的代码跟开发单机的程序是一样的,
可以参考下面的资料:
基于Tensorflow高阶API构建大规模分布式深度学习模型系列: 开篇
基于Tensorflow高阶API构建大规模分布式深度学习模型系列: 基于Dataset API处理Input pipeline
基于Tensorflow高阶API构建大规模分布式深度学习模型系列: 自定义Estimator(以文本分类CNN模型为例)
基于Tensorflow高阶API构建大规模分布式深度学习模型系列: 特征工程 Feature Column
基于Tensorflow高阶API构建大规模分布式深度学习模型系列: CVR预估案例之ESMM模型
参考资料
Distributed TensorFlow
Goodbye Horovod, Hello CollectiveAllReduce
Overview: Distributed training using TensorFlow Estimator APIs
How to customize distributed training when using the TensorFlow Estimator API
原文链接:
https://zhuanlan.zhihu.com/p/56991108
(本文为 AI科技大本营转载文章,转载请联系原作者)
◆
征稿
◆

推荐阅读:
GitHub超全机器学习工程师成长路线图,开源两日收获3700+Star!
吴恩达最新斯坦福课程《深度学习》全部视频已送达,请签收!
用Python玩人脸合成,你也能有一张明星脸(附代码)
微软开源Python静态类型检查器:Pyright
雷军回应输 10 亿背后真相:世界正在青睐不务正业的人
微服务与单体架构:IT变革中企业及个体如何自处?
“别傻了,你不需要区块链!”
曝光!月薪5万的程序员面试题:73%人都做错,你敢试吗?

❤点击“阅读原文”,查看历史精彩文章。
相关文章:

【linux】SELinux工具:semanage的安装和使用
1、安装 在ubuntu14.04上安装 sudo apt-get install policycoreutils在CentOS7上安装 sudo yum -y install policycoreutils-python2、semanage命令行参数 $ semanage --help semanage用于配置SELinux策略的某些元素,而不需要对策略源进行修改或重新编译。 位置…
在阿里云Kubernetes容器服务上打造TensorFlow实验室
简介 Jupyter notebook是强大的数据分析工具,它能够帮助快速开发并且实现机器学习代码的共享,是数据科学团队用来做数据实验和组内合作的利器,也是机器学习初学者入门这一个领域的好起点。 而TensorFLow是深度学习和机器学习最流行的开源框架…
PagedGeometry 笔记03
1. 创建草 PagedGeometry *grass new PagedGeometry(mCamera,50); grass->addDetailLevel<GrassPage>(100); // 在100单位内绘草。 GrassLoader *grassLoader new GrassLoader(grass); grass->setPageLoader(grassLoader); grassLoader->setH…
【Qt中文手册】QSortFilterProxyModel
1、说明 QSortFilterProxyModel类继承自QAbstractProxyModel是一个代理类,存在于另一模型Model和视图View之间,将另一个模型排序或者过滤后在视图上显示。 2、简单示例 没有使用代理的项视图模型代码如下 QTreeView *treeView = new QTreeView; MyItemModel *model = new…
吴恩达的Landing.ai又迎来一位AI大牛
参加 2019 Python开发者日,请扫码咨询 ↑↑↑整理 | 琥珀出品 | AI科技大本营(ID:rgznai100)近日,吴恩达在Twitter发消息称,欢迎王冬岩加入Landing.ai,负责公司的客户对接及战略伙伴合作&#x…
synchronize
1。synchronize方法的产生与vcl的局限性有关,因为vcl控件在同一时刻只能被单线程访问,如果多个线程同时访问vcl,vcl会出现问题。所以问了安全地访问vcl,Tthread类提供了一个方法叫synchronize,他可以让线程中的方法在主线程中执行,所以我们可…
Google BBR拥塞控制算法背后的数学解释 | 深度
参加 2019 Python开发者日,请扫码咨询 ↑↑↑作者 | 赵亚转载自CSDN网站杭州待了一段时间,回到深圳过国庆假期,无奈温州皮鞋?厂老板过节要回温州和上海,不在深圳,也就没有见着,非常遗憾!国庆节…
【Linux】linux使用mplayer播放摄像头
1、安装mplayer 1.1 在ubuntu上安装mplayer sudo apt-get install mplayer1.2 在Centos7上安装mplayer 安装软件包: sudo yum localinstall http://download1.rpmfusion.org/free/el/rpmfusion-free-release-7.noarch.rpm安装mplayer: sudo yum ins…
leetCode刷题 2. 两数相加
原题链接: leetcode-cn.com/problems/ad… 题目描述 给定两个非空链表来表示两个非负整数。位数按照逆序方式存储,它们的每个节点只存储单个数字。将两数相加返回一个新的链表。 你可以假设除了数字 0 之外,这两个数字都不会以零开头。 示例&…
【Qt】pro 笔记
一、小技巧 1、获取pro文件所在目录的最后一级目录名 LASTDIR = $$relative_path($$_PRO_FILE_PWD_, $$_PRO_FILE_PWD_/..)2、获取变量的值 $$VAR:获取变量值; $${VAR}:获取变量值,{}的存在可以和后面的字符做隔离; $$(VAR):在执行qmake时,获取环境变量的值; $(VAR)…
7——ThinkPhp中的响应和重定向:
public function index3(){//响应数据:$data[title>"标题部分","content">"内容部分"];//return json($data);//return json($data,201);//return xml($data);//请求信息给模板:$this->assign(name,xiaoming222)…

GitHub超全机器学习工程师成长路线图,开源两日收获3700+Star!
参加 2019 Python开发者日,请扫码咨询 ↑↑↑ 大会议题以及更多详情请查看:https://pythondevdays2019.csdn.net/ 作者 | 琥珀 出品 | AI科技大本营(ID:rgznai100) 近日,一个在 GitHub 上开源即收获了 3700 Star 的项…
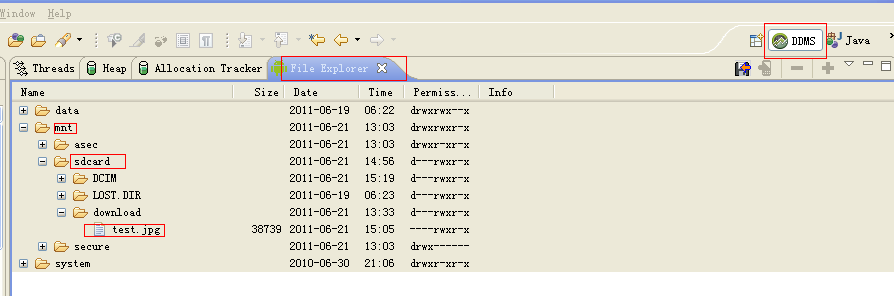
Android模拟器SD卡的使用
在Eclipse中,操作如下: 在设置了RUN的命令参数之后,RUN一个应用,然后使用DDMS的File Explorer工具导入导出文件。 打开DDMS工具:在Eclipse的Window->Open Perspective->Other...里面打开DDMS工具。 在DDMS的File…
受用一生的高效PyCharm使用技巧
参加 2019 Python开发者日,请扫码咨询 ↑↑↑作者 | Python编程时光转载自Python编程时光(ID:Python-Time)今天先从 PyCharm 入手,写一些可以明显改善开发效率的使用技巧,一旦学会,受用一生。以下代码演示是…
【Go】Go基础(一):Hello World!
1、 C格式hello.go package main import "fmt"func main(){fmt.Printf("Hello World!\n"); }2、编译 go build hello.go3、运行 执行go build编译后,会在当前目录下生成名为hello的可执行程序。 $ ./hello Hello World!4、Go格式的hello.g…
centos7上搭建http服务器以及设置目录访问
参考文献:http://www.jb51.net/article/137596.htm,原文摘抄如下,并根据具体需要作了相应的修改。 步骤: 1. 安装httpd服务 sudo yum install httpd Apache 的所有配置文件都位于 /etc/httpd/conf 和 /etc/httpd/conf.d 。网站…

一文看懂深度学习发展史和常见26个模型
参加 2019 Python开发者日,请扫码咨询 ↑↑↑来源 | AI部落联盟(ID:AI_Tribe)作者简介:沧笙踏歌,硕士毕业于北京大学,目前计算机科学与技术博士在读,主要研究自然语言处理和对话系统…

JBL无所不能与IPhone4、IPad2的完美盛宴
期待以久JBL白版终于到货了,由于水货的供电参数是110V~200V,行货是110~220V,所以本人选择了行货,因为水货的供电和国内的输入电压不符,时间用久了会影响小J寿命。经过测试后本人发现,用JBL无所不能连接IPho…
【Go】Go基础(二):学习网址汇总
Go语言中文网站 https://studygolang.com/ Go语言标准库文档 https://studygolang.com/pkgdoc 《The Way to Go》中文名《Go 入门指南》 https://github.com/Unknwon/the-way-to-go_ZH_CN https://github.com/Unknwon/the-way-to-go_ZH_CN/blob/master/eBook/directory.md…
堆和栈的主要区别由以下几点:
1、管理方式不同;2、空间大小不同;3、能否产生碎片不同;4、生长方向不同;5、分配方式不同;6、分配效率不同;管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制&a…
参与2011年7月13日举行的Azure国际猜拳锦标赛,赢取5,000美元大奖
你想要编写自己的“bot”角色并测试你的技能,在线同来自美国,加拿大,中国,德国,新西兰,瑞典和英国的Windows Azure开发者一教高下,并赢取5,000美元大奖吗?请先注册Azure国际猜拳锦标…
【Go】Go基础(三):基本结构和基本数据类型
1、Go程序源码结构 我们将一个Go程序的源码暂时称为一个项目 : 每个项目由若干个包组成; 每个包由同一个目录中的若干个go文件组成; 每个go文件中由若干函数、变量、常量等组成; 每个函数由流程控制语句、变量、常量、运算符和函…

2019如何学Python?这里有你需要的答案
点击上方↑↑↑蓝字关注我们~参加 2019 Python开发者日,请扫码咨询 ↑↑↑编辑 | Jane出品 | Python大本营(公众号id:pythonnews)根据 2018 年 Python 开发者大调查,Python 3 的渗透率已经快速增长至 84%,越…
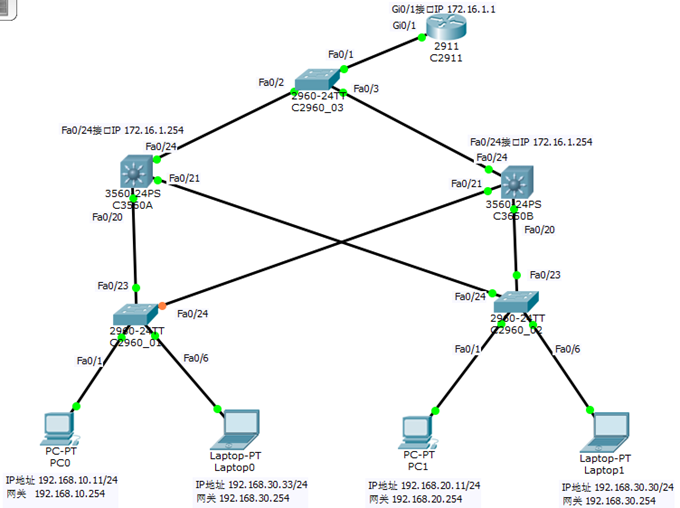
Cisco HSRP热备份路由器协议配置
HSRP热备份路由器协议: HSRP是 Hot Standby Routing Protocol(热备份路由协议)的缩写,它的作用是当核心路由器不能正常工作时, 备用路由器能够实现自动平滑的替换,以保证网络正常使用。该协议中含有多台路由…
FTP与TFTP的区别
文件传输协议(FTP)实际上就是传输文件的协议,它可以应用在任意两台主机之间,但是FTP不仅仅是一个协议,它同时也是一个程序。作为协议,FTP是被应用程序所使用的;而作为程序,用户需要通过手动方式来使用FTP并完成文件的传送。FTP允许执行对目录和文件的访问,并且可以完…
写给NLP研究者的编程指南
点击上方↑↑↑蓝字关注我们~参加 2019 Python开发者日,请扫码咨询 ↑↑↑作者 | 赤乐君,日本某大手研发部门的NLP工程师。关注关系抽取与知识图谱的相关研究。来源 | 赤乐君的知乎专栏最近AllenNLP在EMNLP2018上做了一个主题分享,名为“写给…
【数据库】sqlite3常用命令及SQL语句
【数据库】sqlite3数据库备份、导出方法汇总 一、准备工作 0、安装SQLite3 1)ubuntu命令安装(不是最新版本) sudo apt install sqlite32)源码安装(可以安装最新版本) 下载: https://www.sq…
资本主义社会是不存在人道的
对叙利亚人民感到无助而写点文章,虽然没有什么大的作用,也谈谈自己对于战争与和平的理解,战争与和平就相当于爱与恨一样,爱的热切,恨之入骨,虽然形容不当,人性的双面总是要拿来剖析一二的。 人类…
再谈javascript图片预加载经典技术
图片预加载技术的典型应用: 如lightbox方式展现照片,无疑需要提前获得大图的尺寸,这样才能居中定位,由于javascript无法获取img文件头数据,必须等待其加载完毕后才能获取真实的大小然后展示出来,所以lightb…
【Go】Go基础(四):流程控制(控制结构)
1、if-else结构 格式: if condition1 {// do something } else if condition2 {// do something else } else {// default }和C的不同,条件语句没有大括号; 新增的语法: if initialization; condition {// do something }例…