四大指标超现有模型!少样本的无监督图像翻译效果逆天| 技术头条

作者 | Ming-yu Liu, Xun Huang, Arun Mallya, Tero Karras, Timo Aila, Jaakko Lehtinen
译者 | linstancy
编辑 | Rachel
出品 | AI 科技大本营(ID:rgznai100)
【导读】在已有的图像翻译研究中,模型需要使用大量的多类别图像数据,在一定程度上限制了模型的具体应用。本文提出了一种基于少样本目标类别图像的图像翻译模型,该模型在翻译准确度、内容保留程度、图像真实度和分布匹配度四个指标上都超越了现有模型的效果。

摘要
无监督的图像翻译方法通过在不同的非结构化图像数据集上进行学习,将指定类别的图像转换为另一类别的图像。现有方法虽然取得了一定进展,但在模型训练期间需要大量的源类别和目标类别的图像,限制了这类方法的实际应用。
本文通过将一个新的神经网络架构和对抗学习相结合,提出了一种少样本的无监督图像翻译算法。该模型能够使用少量样本图像,针对新出现的图像类别进行图片生成。作者将该模型与几种现有方法进行了比较,结果表明,这种基于少样本的无监督图像翻译算法非常有效。该论文的代码已开源,相关项目地址如下:
https://nvlabs.github.io/FUNIT
简介
人类非常擅长通过学习、类比推理等方法,将现有的知识泛化推广到一些未见过的问题上。例如,即使对于没见过老虎的人来说,当看到一只站立的老虎,他也能根据对其他动物的观察经验,联想到老虎躺着的样子。近来无监督的图像翻译研究在不同图像类别间的翻译中取得了长足的进步,但现有方法依然很难依据先验知识和少量新类别的样本图像,对图像进行泛化。
当前的图像翻译方法需要大量各类别的图像用于翻译模型的训练。针对这些问题,本研究提出一种少样本无监督图像翻译框架 (Few-shot UNsupervised Image-to-image Translation, FUNIT),旨在只利用少量的目标类图像,通过学习到的图像翻译模型,将源图像类别图像范围为到目标类别的图像。
该模型的假设如下:人类基于少样本的生成能力来源于过去的视觉知识,且在之前看过的不同种类的物体越多,该泛化生成能力越强。基于此,本研究使用了一个包含多种类别图像的数据集训练 FUNIT 模型,用来模拟过去所学习的多类别视觉知识。模型的目标为,只利用目标类别的少量样本图像,实现从源类别到目标类别的图像翻译任务。
研究假设,通过在训练中学习从少量新类别图像中提取该图像类别的外观模式,模型能够学习一个通用的外观模式提取器,并将该模式应用于未见过的类别图像实现图像翻译。本文的实验数据证明,训练集类别数的增加对于少样本图像翻译模型的性能提升是有帮助的。
本文模型结构基于对抗生成网络(Generative Adversarial Networks, GAN)。作者将 GAN 和新的网络架构耦合,获得了较好的实验效果。通过在不同数据集上的实验将模型与几种基线方法进行对比分析,作者对模型的效果进行了验证,发现在各种性能指标上 FUNIT 框架的表现都更好。
方法
本文所提出的 FUNIT 框架旨在基于少量的目标类别图像,将源类别图像映射为一些模型未学习过的目标类别的图像。具体来说,在模型训练阶段,本文所使用的图像来自一组图像类别的数据集合 (如各种动物类别的图像集),称之为源类别,用于训练多层级无监督的图像翻译模型 FUNIT。
这里,本文假设在不同类别间不存在处于同一姿态的动物的图像。在测试时,本文使用少量取自类别的图像样本,称之为目标类别,这一类别在模型训练时未使用。模型利用这些少量的目标类别图像样本,能够实现从源类别到目标类别的图像翻译本文提出的模型主要包括两部分:一个少样本图像翻译器 G 和一个多任务对抗判别器 D 。
少样本图像翻译器 G
少样本图像翻译器 G 由一个内容编码器 Ex,一个类编码器 Ey 和一个解码器 Fx 构成。其中内容编码器由多个 2D 卷积层和多个残差块(residual blocks)组成,用于将输入的内容图像 x 映射为内容潜在编码 zx ,其中 zx 是一个空间特征映射。类编码器包含多个 2D 卷积层并对卷积结果取均值。
而解码器是由多个采用自适应实例正则化方法 (AdaIN) 的残差块和多个卷积层结构组成。对于每个样本,AdaIN 方法对每个通道的样本激活值进行正则化,以获得其零均值和单元方差,之后通过一个仿射变换来缩放激活值。
如下图1所示,该仿射变换具有空间不变性,因此仅可以用于得到全局的外观特征信息。内容编码器能够提取到不随类别改变的隐层表征信息,而类别编码器学习特定类别的隐层表征。文本通过 AdaIN 层将类编码馈送到解码器,并使用类别图像来控制所生成的图像全局外观,使用内容图像决定图像的局部结构。
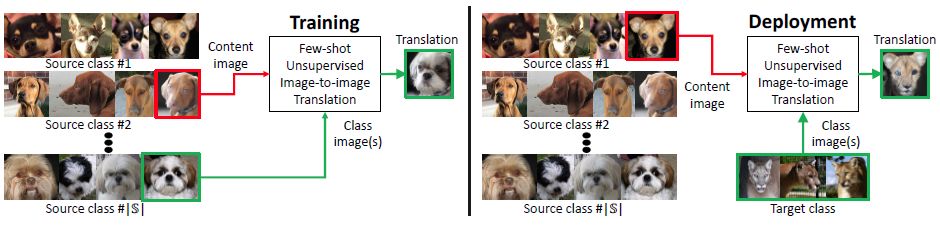
图1 训练:训练集数据由各种不同类别图像构成 (源类别),用于训练一个图像翻译模型。部署:展示了所提出的模型基于少量目标类别图像进行图像翻译的表现。 FUNIT 中生成器的输入由两部分构成:1) 内容图像;2) 目标类别图像集。旨在通过输入与目标类相似的图像来实现少样本图像翻译。
不同于现有的图像翻译研究中使用的条件图像生成器,这里 G 同时采用一张内容图像 x 和 K 个目标类别图像作为输入,并生成输出图像。假定内容图像属于类别 cx,而每个 K 类图像属于类别 cy。另外, K 是个很小的数字,且 cx 与 cy 属于不同类别。如下图2所示。
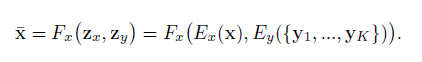
图2 仿射变换表达式
G 将一张输入的内容图像映射到属于类别 cy 的输出图像,二者在图像结构上有一定的相似度。以 S 和 T 分别代表源图像和目标图像集,在训练期间从两个集合中随机抽取图像供 G 学习,在测试期间 G 从目标集中抽取一些未见过的类别图像,并将源图像集数据类别映射到目标类图像上。
多任务对抗判别器 D
判别器 D 的训练是同时在几种对抗二分类任务上进行的,其用于判别输入图像是源类别的真实图像还是生成的目标类别图像。由于这里存在 S 个源图像类别,因此 D 将对应生成 S 个输出。当更新 D 时,根据输出的结果,相应地惩罚 D。当更新 G 时,只有当输出结果为假时才选择惩罚 D。经验上来说,通过这种方法处理后的判别器 D 能够在 S 多分类任务上表现得更好。
此外,FUNIT 框架所采用的损失函数如图3所示:由 GAN 模型损失、内容图像重构损失和特征匹配损失构成。
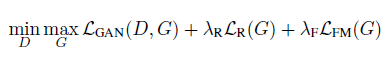
图3 FUNIT 框架的损失函数表达式
GAN 模型损失的计算如图4:
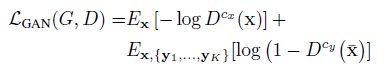
图4 GAN 模型的损失表达式
重构损失的数学表达式如图5:
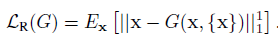
图5 重构损失表达式
而图像特征匹配损失旨在最小化目标类图像特征与翻译输出结果图像之间特征匹配度,如图6:
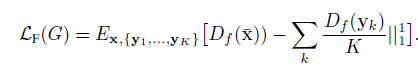
图6 特征匹配损失表达式
实验
实验部分使用如下四种数据集:
动物面孔数据集:从 ImageNet 数据集中抽取149种卡通动物类别,共含117574张图像。
鸟类数据集数据集:包含48527张攻击555种北美鸟类图像数据。
花卉数据集:102类共8189张包含花的图像。
事务数据集:来自256种共31395张食物图像数据。
基准方法分别使用的是 StarGAN-Fair-K 、 StarGAN-Fair-K 、 CycleGAN-Unfair-K 、 UNIT-Unfair-K 和 MUNIT-Unfair-K 五种,分别通过 翻译准确率(translation accuracy)、内容保留程度(content preservation)、图像真实度(photorealism) 和 分布匹配度(Distribution matching)四种指标来评估各种方法的性能。
总体结果 FUNIT 与基准方法在不同数据集的实验结果如下图7所示。
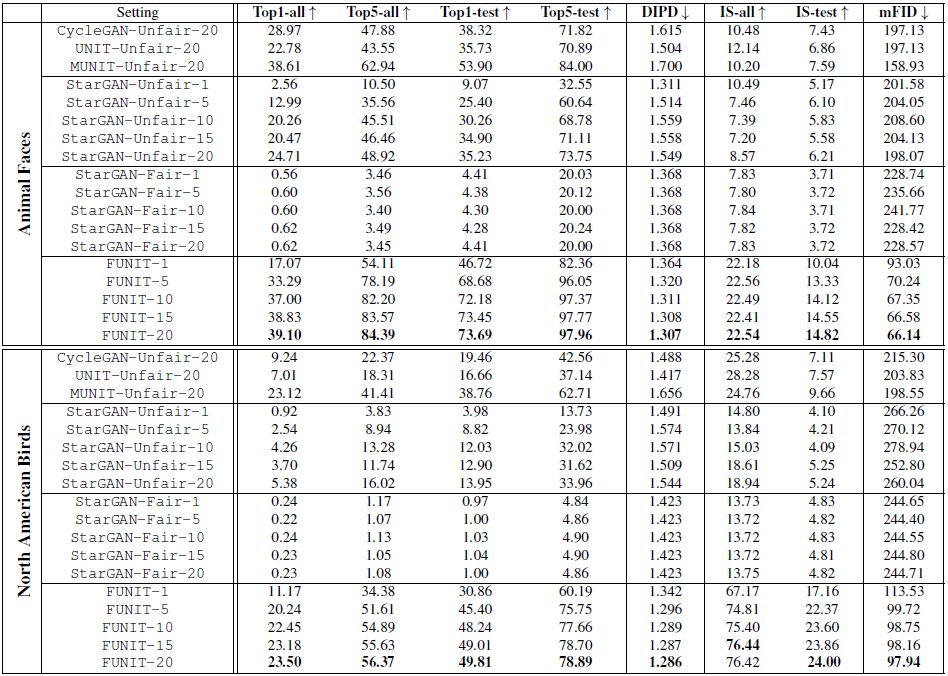
图7 各方法的性能对比
可以看到,FUNIT 框架在少样本无监督图像翻译任务上所有的性能指标都超过了所有基准方法的表现:在 Animal Faces 数据集的 1-shot 和 5-shot 设置上分别达到82.36和96.05 的 Top-5 测试精度,在 North American Birds 数据集上分别达到60.19和75.75的 Top-5 测试精度。图8对 FUNIT-5 模型在少样本图像翻译任务上的结果进行了可视化。

图8 FUNIT-5 模型的少样本无监督图像翻译结果的可视化展示。从上到下,分别采用是动物面孔、鸟类、花卉和食物数据集样本。
可以看到 FUNIT 模型能够成功地实现从源图像到新类别图像的翻译。此外,在图9还提供了一些可视化的对比结果。

图9 少样本图像翻译性能的结果对比
用户研究 本文在 Amazon Mechanical Turk (AMT) 平台上通过人类评估法来进一步验证了图像翻译结果的可信度和真实度,结果如图10 所示。
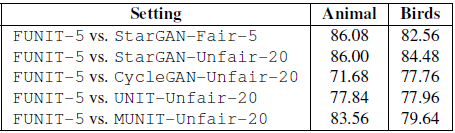
图10 用户偏好得分结果
用户偏好得分评估结果表明,相比于其他方法,FUNIT-5 模型的翻译结果与目标类图像的相似度更高,可靠性更强。
训练集源类别数量 下图11展示了在动物数据集上,当类别数量发生变化时,FUNIT-5 模型的性能表现变化。这里只展示了类别数从69到119以间隔10变化时模型的表现。
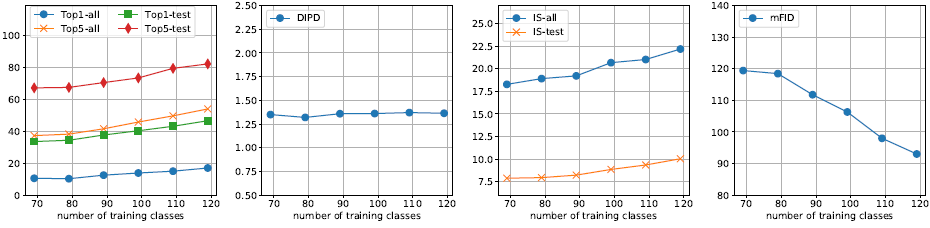
图11 少样本图像翻译性能 vs 动物面孔数据集目标类别数
可以看到,FUNIT 模型的翻译性能与目标类别数呈正相关关系,即类别数越多,翻译性能越好。此外,研究中还进行了参数分析 (parameter analysis)、消融实验 (ablation study)、隐层插值 (latent interpolation)、失败样本分析 (failure cases) 等评估,具体信息可以查阅原论文的说明。
总结
本文介绍了首个少样本无监督图像翻译框架 FUNIT,该模型利用少量的目标类别图像,实现了从源类别图像到目标图像的翻译,并展示了该框架的性能与目标类别数的关系。FUNIT 由三部分构成:1) 内容编码器:用于学习类别不变编码;2) 类编码器:用于学习特定类别编码;以及 3) 解码器。
总的来说,FUNIT 框架能够实现非常出色的图像翻译,但当目标类别与源图像有显著差异时,也会存在一些失败的情况。在失败样本中,FUNIT 方法仅对源图像的颜色进行了变更,而改变图像的其他外观特征,这也是未来研究的方向。
论文链接:
https://arxiv.org/abs/1905.01723
(*本文由AI科技大本营编译,转载请联系微信1092722531)
◆
CTA核心技术及应用峰会
◆
5月25-27日,由中国IT社区CSDN与数字经济人才发展中心联合主办的第一届CTA核心技术及应用峰会将在杭州国际博览中心隆重召开,峰会将围绕人工智能领域,邀请技术领航者,与开发者共同探讨机器学习和知识图谱的前沿研究及应用。
更多重磅嘉宾请识别海报二维码查看。目前会议8折预售票抢购中,点击阅读原文即刻抢购。添加小助手微信15101014297,备注“CTA”,了解票务以及会务详情。

推荐阅读
肖仰华:知识图谱落地,不止于“实现”
人工智能的浪潮中,知识图谱何去何从?
推荐一个牛逼的生物信息Python库——Dash Bio
漫画:什么是LRU算法?
一顿操作猛如虎!云原生应用为何如此优秀?
增长88%! 2019福布斯全球区块链50强榜单, 你未必看懂这3个细节
数据库不适合上容器云?| 技术头条
互联网行业人才格局大换血,BAT 已换位?
补偿100万?Oracle裁900+程序员,新方案已出!

点击阅读原文,了解「CTA核心技术及应用峰会」
相关文章:

【摄像头】镜头焦距
【摄像头】低照度和光圈 1、简介 在镜头上有两个非常重要的参数,一个是光圈、一个是焦距。 如果在镜头上只标注有一个数字的就是定焦头,比如:50mm,就表示这是一只焦距为50mm的定焦头。 如果在镜头上标注有两个数字的就是变焦头,比如:18-55mm,就表示这只镜头焦距覆盖…

(转)C语言字节对齐
图片可以在下面的博客中看到. 转自:http://blog.csdn.net/bigloomy/article/details/6633008 可能有不少读者会问,字节对齐有必要拿出来单独写一篇博客嘛?我觉得是很有必要,但是它却是被很多人所忽视的一个重点。那么我们使用字节对齐的作用…
赌5毛钱,你解不出这道Google面试题
作者 | Kevin Ghadyani 译者 | 清儿爸 编辑 | Rachel 出品 | AI科技大本营(ID:rgznai100) 为了更了解其他人对软件工程的看法,我开始疯狂在 YouTube 上追 TechLead 的视频。在接下来的几天里,我为他在 Google 工作时…
【摄像头】摄像头IRCUT滤光片
1、IRCUT组成原理 IRCUT由两层滤光片组成,一片红外截止或吸收滤光片和一片全透光谱滤光片。 白天是红外截止滤光片工作,晚上是全透滤光片工作: 白天摄像头可以接收到人眼无法识别的红外线,会导致图像与肉眼所见有偏差,…

修改Java-source版本
2019独角兽企业重金招聘Python工程师标准>>> pom.xml添加以下:<plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin><plugin>&l…

HDU 2519 新生晚会【求组合数】
Problem Description开学了,杭电又迎来了好多新生。ACMer想为新生准备一个节目。来报名要表演节目的人很多,多达N个,但是只需要从这N个人中选M个就够了,一共有多少种选择方法?Input数据的第一行包括一个正整数T&#x…

【摄像头】宽动态范围
1、什么是动态范围 简单的来说,就是摄像机拍摄的同一个画面内,能正常显示细节的最亮和最暗物体的亮度值所包含的那个区间。动态范围越大,过亮或过暗的物体在同一个画面中都能正常显示的程度也就越大。 根据百度百科,当在强光源(日光、灯具或反光等)照射下的高亮度区域及…
mysql format函数对数字类型转化的坑
原值param 1234.5678 format(param, 2) (不建议) 结果,字符串类型,123,4.57 会导致你图表char 生成失败,直接变0 convert(param, decimal(12,2))(建议) 结果, 数值类型 1234.57 cast(p…

打造AI产教融合共赢生态,微软亚洲研究院扩大开放了这些资源
2019年5月10日,由教育部国际合作与交流司、科学技术司指导,教育部中外人文交流中心主办, 微软亚洲研究院承办,信息技术新工科产学研联盟特别协办的“中国高校人工智能人才国际培养计划”2019国际人工智能专家论坛暨2019微软新一代…
Microsoft.NET框架程序设计--20 CLR寄宿、应用程序域、反射
应用程序域是CLR提供的一种旨在减少内存使用、提高系统系能的新型机制。而反射使得我们可以很容易使用自己活着第三方的类型来增强应用程序的功能,从而帮助我们设计出可动态扩展的应用程序。 1.元数据:.NET框架的基石 元数据描述了一个类型的字段和方法。…
上手!深度学习最常见的26个模型练习项目汇总
作者:沧笙踏歌转载自AI部落联盟(id:AI_Tribe)今天更新关于常见深度学习模型适合练手的项目。这些项目大部分是我之前整理的,基本上都看过,大概俩特点:代码不长,一般50-200行代码&…

【EMC】电磁兼容性相关名词解释、基础知识
一、名词解释 1、EMC EMC(Electro Magnetic Compatibility)直译是“电磁兼容性”。意指设备所产生的电磁能量既不对其它设备产生干扰,也不受其他设备的电磁能量干扰的能力。 2、EMI——攻击力 EMI(Electro Magnetic Interference)直译为&…
定时任务 Cron表达式
Cron表达式是一个表示时间周期的字符串。 分为6或7个域,每一个域代表一个含义。 验证工具: http://cron.qqe2.com/Cron有如下两种语法格式: 格式1:秒分时天(月)月天(星期)年格式2&a…
C语言字符计算器
这又是以前的一篇文章,觉得有纪念价值。就发过来了。 去年暑假自己下了C语言实战105例,看了几个基础的,其中有一个是关于字符计算器的 我看起来蛮简单的,不过自己做起来我觉得还是做得少了,懵懵懂懂的。 现在想起那个觉…
一文看尽目标检测:从YOLO v1到v3的进化之路
本文转载自:http://www.mamicode.com/info-detail-2314392.html导语:如今基于深度学习的目标检测已经逐渐成为自动驾驶、视频监控、机械加工、智能机器人等领域的核心技术,而现存的大多数精度高的目标检测算法,速度较慢࿰…
【EMC】EMC屏蔽设计
1、屏蔽设计的基本原则: 蔽体结构简洁,尽可能减少不必要的孔洞,尽可能不要增加额外的缝隙;避免开细长孔,通风孔尽量采用圆孔并阵列排放。屏蔽和散热有矛盾时尽可能开小孔,多开孔,避免开大孔&am…
js控制表格隔行变色
只是加载时候隔行变一个颜色,鼠标滑动上去时候没有变化 <table width"800" border"0" cellpadding"0" cellspacing"0"> <tr><td>不变色</td></tr><tbody id"goaler"><tr…

jQuery实例——仿京东仿淘宝列表导航菜单
以前看着京东,淘宝的导航做的真好,真想哪一天自己也能做出来这么漂亮功能全的导航菜单。今天弄了一下午终于自制成功,主要使用jQuery和CSS,实现功能基本和京东一样。 功能介绍: 1、鼠标停留导航; 2、根据子…
【Ubuntu】使用过的ubuntu工具记录
1、UnixBench UnixBench性能测试,和windows的鲁大师差不多。 2、smartctl 测试磁盘性能 sudo apt install smartmontools 3、cpufrequtils cpu频率查看、设置工具集:cpufreq-inf、cpufreq-set sudo apt install cpufrequtils 4、stress cpu满负荷…
解救被困传销女演员 助人减肥找老婆 蚂蚁森林又现神功能
近日,一篇《女演员被传销组织拘禁30多天 竟因蚂蚁森林幸运逃离》的报道引发了全网热议。网友纷纷表示:蚂蚁森林功能强大,不仅能帮人减肥、找老婆,还能在关键时刻保命! 珍惜偷你能量的好友 因为关键时刻能保命 据北京晨…

“智能+”时代,看见别人看不见的才是赢家
当科技、商业和社会均发生天翻地覆的变革,我们可以确定的是,“智能”时代的浪潮已掀起波澜。这将是智慧无处不在的时代,曾经无法解决的问题,都将在科技的发展下找到答案;这也是技术普惠万物的时代,创新型应…
CSS a控制超链接文字样式
超链接的代码<a href"http://www.divcss5.com/" target"_blank" title"关于div css的网站">DIVCSS</a>解析如下:href 后跟被链接地址目标网站地址这里是http://www.divcss5.com/target _blank -- 在新窗口中打开链接 _pa…

3分钟快速实现:9种经典排序算法的可视化
作者 | 爱笑的眼睛 来源 | 恋习Python(ID:sldata2017)最近在某网站上看到一个视频,是关于排序算法的可视化的,看着挺有意思的,也特别喜感。▼6分钟演示15种排序算法不知道作者是怎么做的,但是突然很想自己…
【Qt】Qt再学习(一):Application Example
1、QCommandLineParser 命令行解析类 常用接口 QApplication app(argc, argv);QCommandLineParser parser;parser.setApplicationDescription(QCoreApplication::applicationName());parser.addHelpOption(
沃森世界研讨会前瞻:AI服务 了解客户情绪
科技讯10月19日消息,据国外媒体报道,“沃森世界”研讨会(World of Watson)将于10月24日至27日在拉斯维加斯曼德勒湾举办,与会者将能够了解沃森目前的进展,并深入了解将来沃森将从事的一些令人兴奋的事情。10月14日一整日的会谈中&…
《人月神话》——外科手术队伍——笔记!
本章讨论了一个问题“如何在有意义的时间进度内创建大型的系统?” 软件经理测试出来的数据显示“经验和实际的表现没有相互的联系”。 *需要协作沟通的人员的数量影响着开发成本,因为成本的主要组成部分是相互的沟通和交流,以及更正沟…
直接上手!不容错过的Visual Studio Code十大扩展组件
作者 | David Neal译者 | 谭开朗,责编 | 屠敏转载自CSDN(ID:CSDNnews)各大平台与各种语言的开发人员都在使用Visual Studio Code,我对此感到惊讶。Stack Overflow发布的2019年开发者调查结果显示,VS Code占…
【Qt】Qt再学习(二):Bars Example(Q3DBars)
1、简介 Bars example显示了如何使用Q3DBars制作3D条形图,以及如何结合使用小部件来调整几种可调节的质量。该示例显示了如何: 使用Q3DBars和一些小部件创建应用程序 使用QBar3DSeries和QBarDataProxy将数据设置为图形 使用控件调整一些图形和系列属性…
记录错误信息的行数
1.try catch 记录错误信息的时候,如果报错了,我们只能粗略估算是什么错误,但如果能够具体知道是哪行错误的话,对错误的分析就能够快速定位问题。 2.只需要记录到错误的行号,就能快速定位问题。 3.ex.stackTrace 就可以…

android中PreferencesActivity的使用(一)
在使用android手机的时候,尤其是在操作软件设置时,我们经常见到这样的界面: 这是怎么来实现的的呢?其实android已经提供了相应的类和方法,当进行简单数据存储时(比如:软件配置参数)a…