读完ACL 2019录取的30篇知识图谱论文,我发现了这5点趋势

作者 | Michael Galkin
译者 | Freesia
编辑 | 夕颜
出品 | AI科技大本营(ID: rgznai100)
【导读】近年来,自然语言处理领域中广泛应用的知识图谱(KGs)正在不断地吸引人们的目光,此次 ACL 2019 中的有关于知识图谱的论文也比比皆是,因此本文作者在参加 ACL 2019 后将有关于知识图谱的论文进行了整理并予以简要介绍,广大技术人员们可以借此了解知识图谱在自然语言处理领域的最新发展情况。
大家好啊, ACL 2019 刚刚结束,我整个星期都在美丽的佛罗伦萨参加各种会议、tutorial、workshop!在这篇文章中,我想回顾一下知识是如何缓缓但坚定地融入到 NLP 社区中的。

ACL 2019 声势浩大 — 论文提交数为 2900 篇,660 篇被录用,3000 多名注册与会者,约 400 名与会者参加了四个 workshop(好吧,workshop 比一些国际 CS 会议更大)。Mihail Eric 撰写了一篇关于 ACL 总体趋势的文章。大会除了如 Bertology、Transformers 和 Machine Translation等热门话题外,还出现了如对抗性学习、自然语言生成和知识图谱(KGs)等新趋势。我个人很高兴看到了 KGs 在顶尖级人工智能领域的强劲势头:660 份被录用的论文中约有30 份是关于知识图谱的,占了 5% 的份额( ACL 一直不都是典型 AI 人的好去处吗?)因此,我在本周内会列举一些以 KGs 为代表的人工智能的主要应用领域,还有一系列前途无量的论文。由于会议规模浩大,如果我错过了什么,请告知我,以便于我在列表中添加。
知识图谱的人机对话系统
人机对话系统传统上分为任务型和聊天型。任务型帮助用户完成某项任务,如在餐厅预订桌子或在车内场景中帮助驾驶员(如果你想熟悉典型的基于 KG 的对话系统,请阅读我以前的文章)。聊天型主要是小型聊天,具备互动娱乐性质。最近深度学习在没有特定的 pipeline 的端到端对话系统(尤其是聊天系统)成就斐然,你可能有所耳闻。然而,越来越明显的是,这两种类型的系统都必须配备一些知识,任务型系统需要任务领域的知识;聊天型需要的更多是常识性知识。
对这项技术的预期,ACL 候任主席周明本人表达得再清楚不过了——他在欢迎辞中强调了将知识图谱、推理和上下文结合到对话系统中的重要性。我还要补充一点,KGs 能够提高 agent 答案的可解释性。因此,如果候任主席就 KGs 来讨论对话系统,那么这一领域就大有所为了是吧?这正是我们在 Fraunhofer Iais Dresden 和 Smart Data Analytics 研究组所做的工作,既推动了产业应用的发展,又拓宽了基于 KG 的对话平台的研究视野,请原谅我对这一主题的偏见。
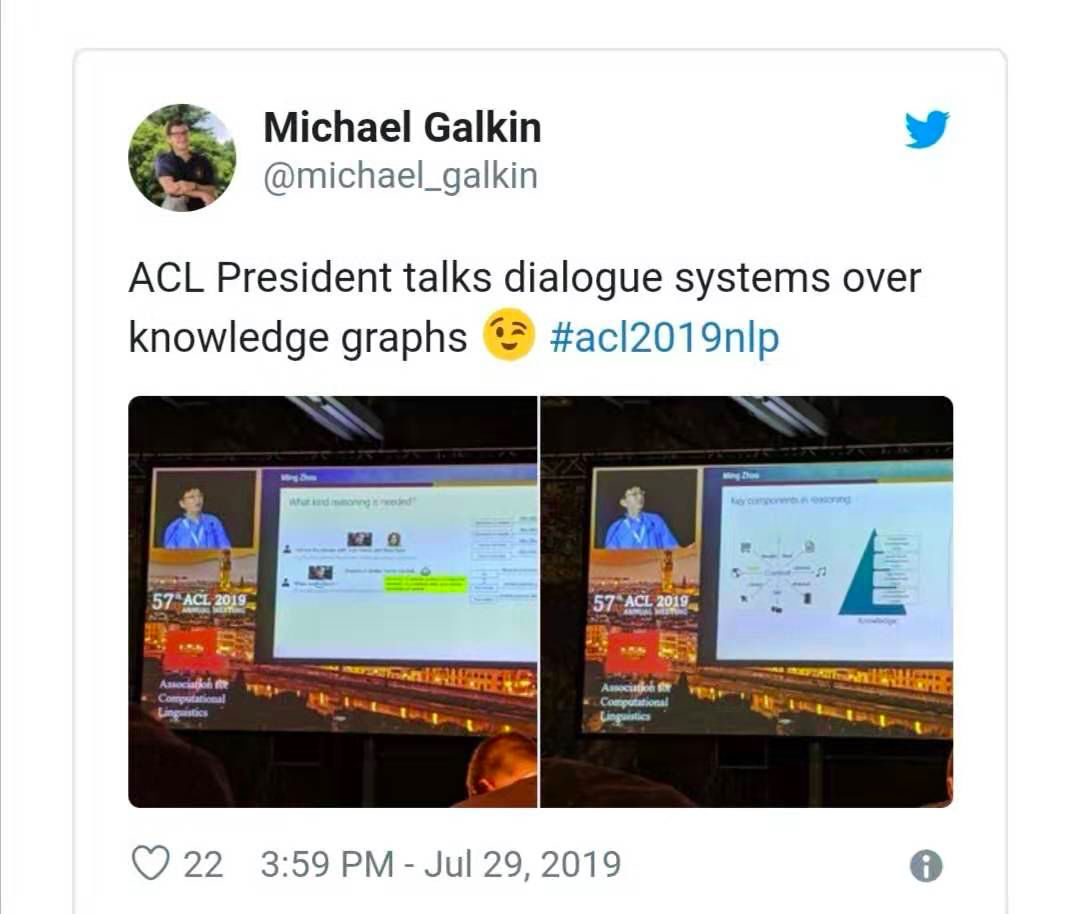
知识图谱的春天?
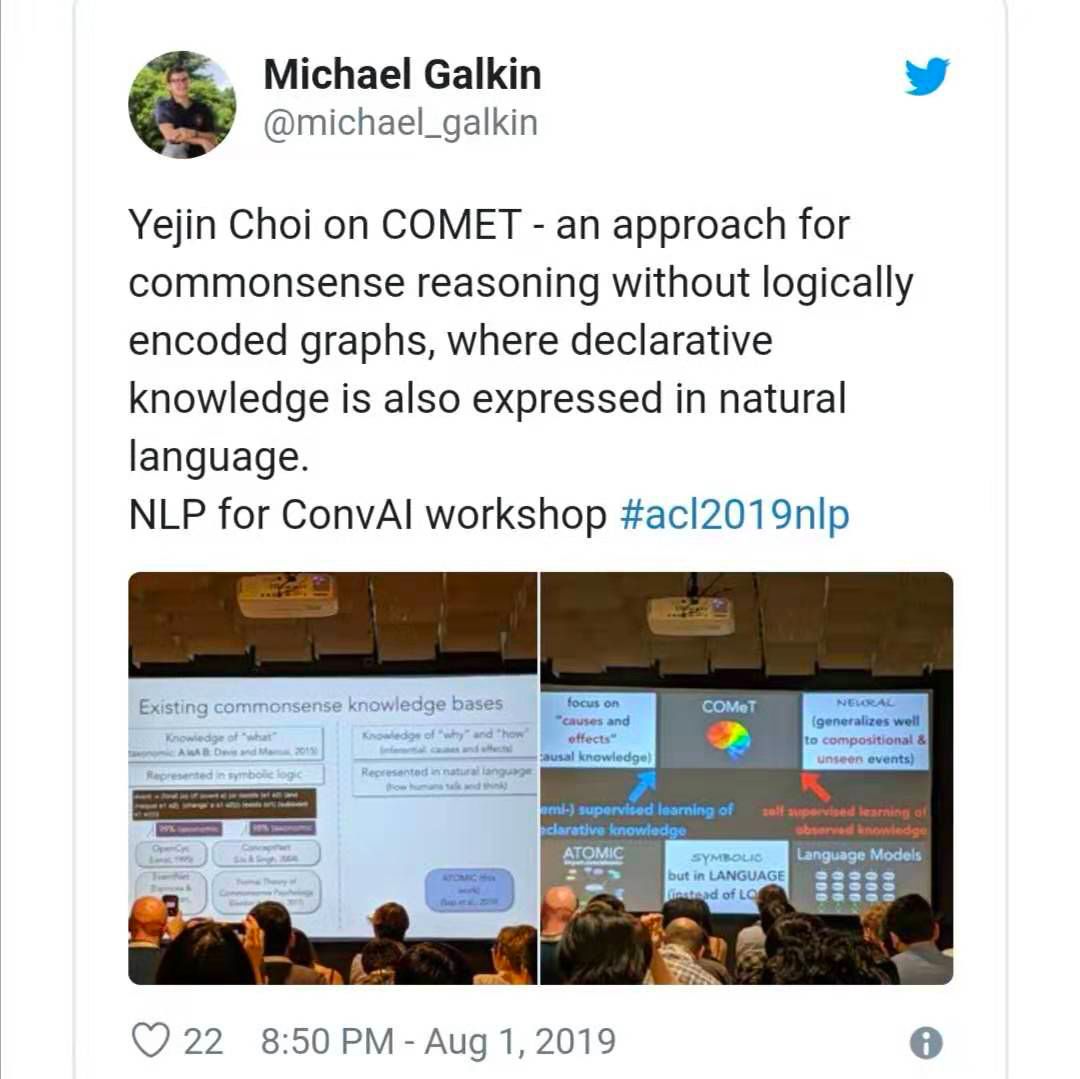
AI 会话的 NLP workshop 中讨论了更多细节,会上来自华盛顿大学的 Yejin Choi 提出了一种将常识知识整合到对话中的方法(技术细节见下文)。
来自亚马逊的 Ruhi Sarikaya 确信 Alexa 在一定程度上仍然需要在 pipeline 模式上,采用组织化来源( 如图谱)的知识提取方式。
来自 MS Research 的 Jianfeng Gao 表示小冰需要使用结构化的知识与用户进行对话(小冰仍然保持着最长的 conversation-step 序列的记录)
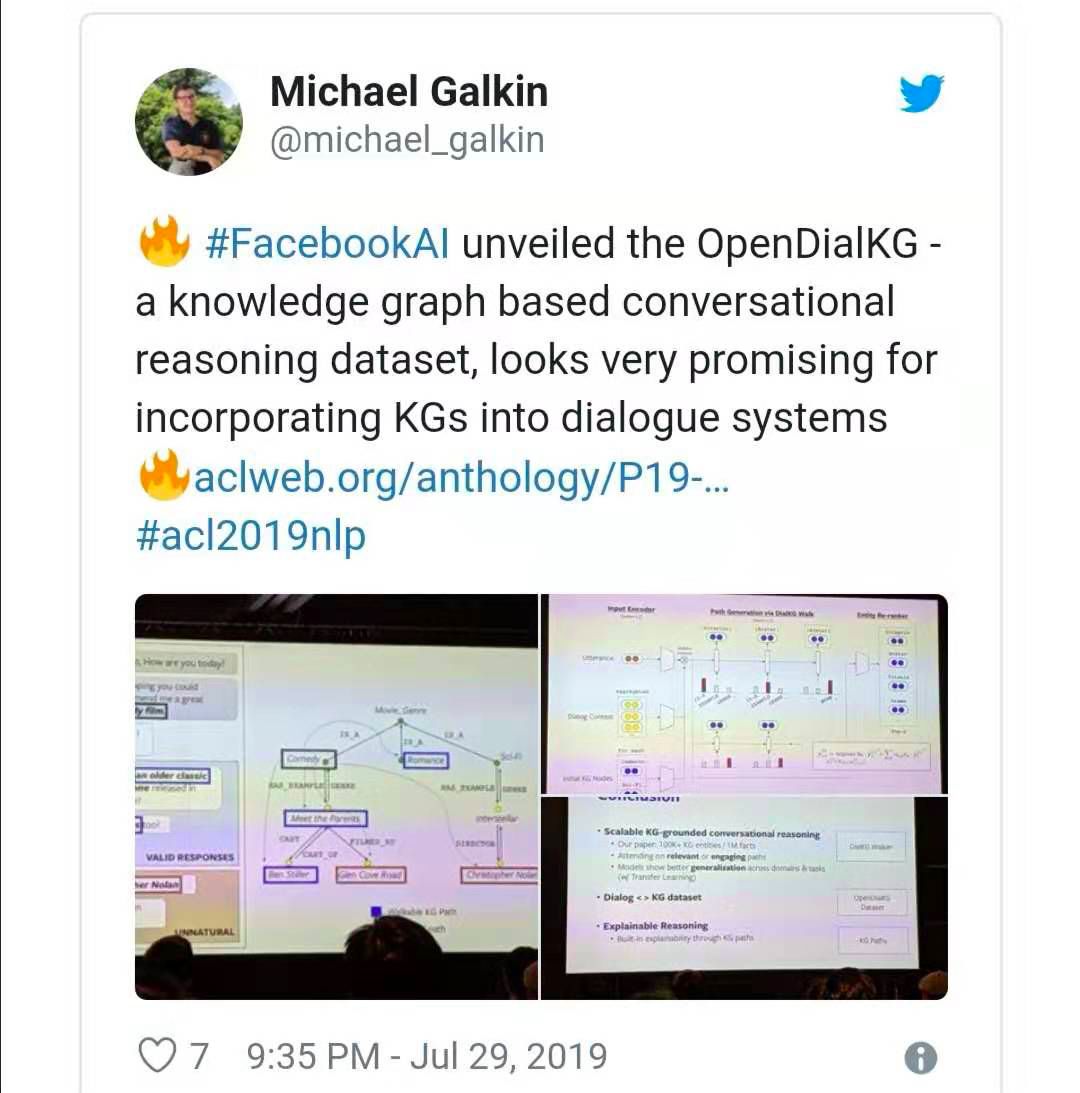
来自 Facebook AI 的 Moon et al., 2019 展示了 OpenDialKG — 一个开放式对话系统 — 其并行语料库带有 15000 注释对话,基于1百万 triples,10 万字符实体和 1358 个关系的 Freebase 子集 91000 turns。这是构建基于 KG 的对话系统的伟大一步,我希望 Facebook 的例子能够激励到其他人!此外,作者还提出了一种新奇的 DialKG Walk 架构,该架构以 E2E 方式利用知识图谱,并采用基于注意的图谱路径解码器。
我唯一担心的就是 selected graph — Freebase,自从 2014 年就正式下线了,长期以来一直无人支持,或许现在是大家转向 Wikidata 的时候了?
知识图谱的自然语言生成事实
从结构化数据中产生连贯的自然语言话语也是一个热门的新兴话题。虽然纯神经 E2E NLG 模型试图解决产出文本无聊的问题,但是从结构化数据中生成的 NLG 在表达自然语言的内在结构方面挑战重重。同样,知识图谱也很难用言语描述。输入一个 triple 三元组,例如 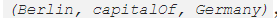 生成一箩筐不同的句子,但是输入一个连贯的三元组,例如
生成一箩筐不同的句子,但是输入一个连贯的三元组,例如 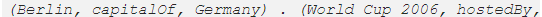
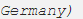 时,哪个产出更合理:“柏林是 2006 年世界杯主办国德国的首都” 还是 “柏林是 2006 年世界杯举办国的首都”?
时,哪个产出更合理:“柏林是 2006 年世界杯主办国德国的首都” 还是 “柏林是 2006 年世界杯举办国的首都”?
令人惊讶的是,ACL 可以提供相当多 KGs 的话语 triples。
首先,我想提下由 IBM Research 组织的讲故事 workshop(链接:https://sites.google.com/view/acl-19-nlg/slides),该 workshop 提出了许多挑战的同时也提到了可能解决 triples 三元组言语问题的方法。
Logan et al.的一篇很棒的论文及海报演讲(链接:https://www.aclweb.org/anthology/P19-1598)提议将 OpenAIGPT 等语言模型与知识图谱嵌入结合使用。作者还介绍了一个新的数据集, Linked WikiText-2,训练部分由超过 41000 个实体和 15000 个关系组成,且带有 Wikidata 的 注释。
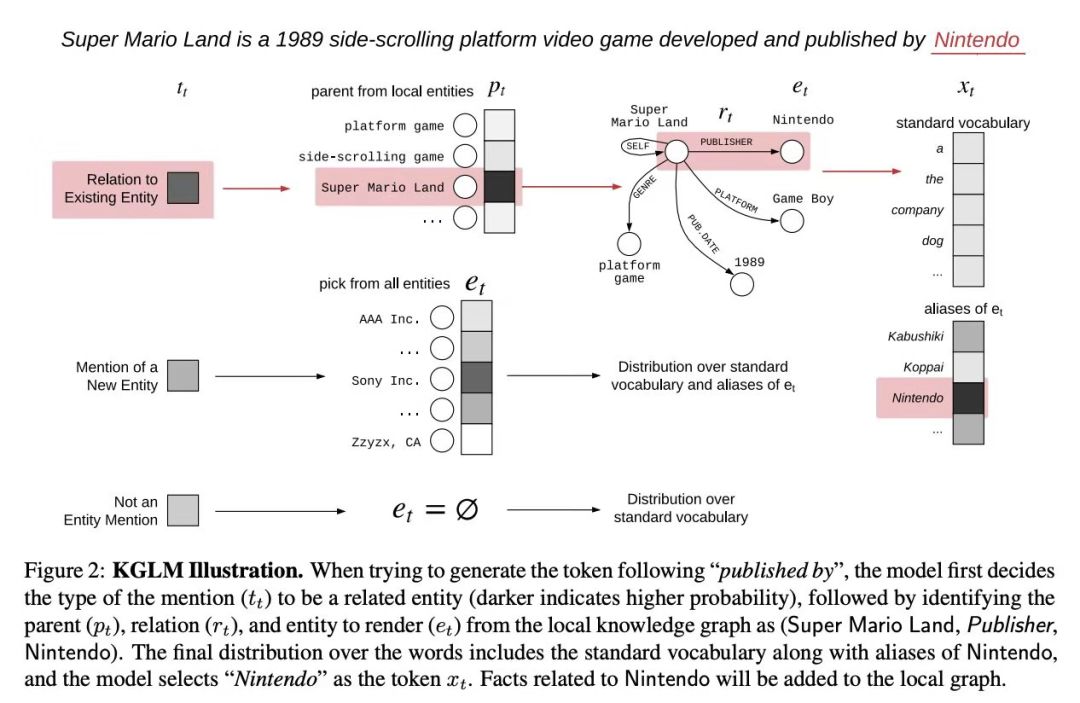
图源: Logan et al.
Moryossef 等人(https://arxiv.org/abs/1904.03396)提出了 Chimera ,尽管并非源自 ACL 2019,但同样是来自 NAACL 2019 的相关作品, — 一个 NLG 用于 triples 的 two-fold 模型。首先,给定一组三元组,它们生成文本图谱,保留给定三元组的语意合成特性,对它们排序,最后用复制机制运行一个典型的神经机器翻译(NMT)系统来生成文本句子。评估基于 WebNLG dataset,该数据集还使用了 Wikidata 实体和谓词 IDs 。
知识图谱的复杂问答
作为一项理解任务,问答是跟进 BERT 等大型模型进展的最流行的基准之一。
“知识图谱问答(KGQA)旨在为用户提供一个界面,让他们自己的语言进行提问,通过问询 KG 可以获得简明的答案。”
我要引用我的同事 Chakraborty 等人最近发表的一项关于 KGQA 的全面研究—— https://arxiv.org/pdf/1907.09361.pdf 。在 QA 任务中,KGs 向用户提供可解释的结果(实际上是可能是在目标图谱中找到的图谱模式)。此外,他们还可以进行复杂的推理,而阅读理解系统还不能做到这一点。ACL2019 带来了许多你想了解的最先进的研究。
Saha 等人的复杂序列问答 CSQA 数据集 (带有 Wikidata IDs)主要为一些针对 KGs 的最复杂的问题,包括聚合(“哪一民族的守护神的数量与希尔德加德·宾根的同行人数大致相同?“)核实(“伊朗的 Shamsi 和 Samatice 是姊妹镇吗?”)甚至是实体和关系的指代消解对话。无记忆的简单问题的训练表现很差,现在看来需要某种形式语言或语法来执行逻辑操作和聚合。本文作者介绍了一种集合交集、知识图谱嵌入查找等多种操作的语法,通过强化学习,推导出一个逻辑程序,能够在对话环境中回答这些复杂的问题。

图源:Saha et al.
? Weber 等人(https://arxiv.org/pdf/1906.06187.pdf)继续致力于 Neural Prolog— 一种结合符号推理和规则学习方法的可区别逻辑方法,可以直接应用于自然语言文本,而无需将其转换为逻辑形式,并使用 Prolog-style 的推理来回答逻辑查询。因此,一方面,框架是基于模糊逻辑(也是我的罪恶小九九)和预先训练的句子嵌入模型。在我看来,神经逻辑方法在社会中被低估了,当研究开始真正进行可解释性之战时,我希望这个领域能有更多的吸引力,因为这篇论文和上面的论文都提出了一个有关于如何推断出具体答案的理智而又可说明的机制。
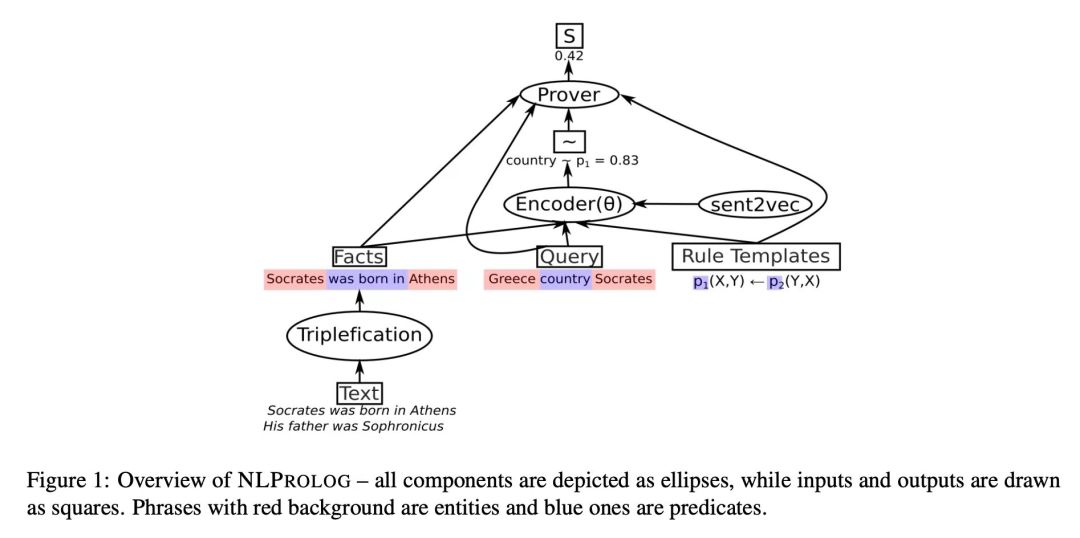
图源:Weber et al.
对于处理更简单的 KGQA 数据集,Xiong 等人(https://www.aclweb.org/anthology/P19-1417)提出一种针对不完整知识图谱的方法,需要执行一些链接预测,Sydorova 等人(https://www.aclweb.org/anthology/P19-1488)在 TextKBQA 任务中取得了很好的效果,有两个知识来源——一个图表和一个文本段落。Yang 等人采用了另一种方法,用 KGs(本例中的 WordNet 和 Nell )丰富 BERT 式阅读理解模型。截至 2019 年 3 月,他们的 KT-NET 在 SQuAD 1.1 和 ReCoRD 上超过了纯 MRC 系统,这表明这是一种有希望的研究方法。
基于理解的问答系统仍然处于火爆状态,因为他们有好几个口头陈述和广告会议专门为他们准备,所以我非常肯定也会有关于这个领域的详细报告。简言之,新的数据集(如 WikiHop 或HotpotQA)是针对整个 Wikipedia 文章的多个问答,你需要将多篇文章中的知识结合起来回答问题。CommonSenseQA 包含来自搜索引擎日志的真实问题,因此系统需要某种常识性推理。为了区分有意义的案例和完全的胡说八道,你需要进行对抗性训练,Zhu (https://www.aclweb.org/anthology/P19-1415) 和 Wu (https://www.aclweb.org/anthology/P19-1616) 等人也有类似论文,他们证明了对抗性训练是有效的。
最后,为了克服通常较小的训练数据集,Alberti 等人(https://www.aclweb.org/anthology/P19-1620)为那些能够生成 50 万个额外问题来训练系统并实现 +2 到 +3 F1 增长的问题引入一个解释性数据扩充模式。
知识图谱的 NER 和关系联结
ACL2019 的信息提取轨道是最受欢迎和关注的轨道之一!KGs 在命名实体识别、实体链接、关系提取和关系联结中显示出了切实的好处。我对神经方法特别感兴趣,它允许从文本源构建知识图谱。引入了许多新的数据集(带有 Wikidata ID )和方法。
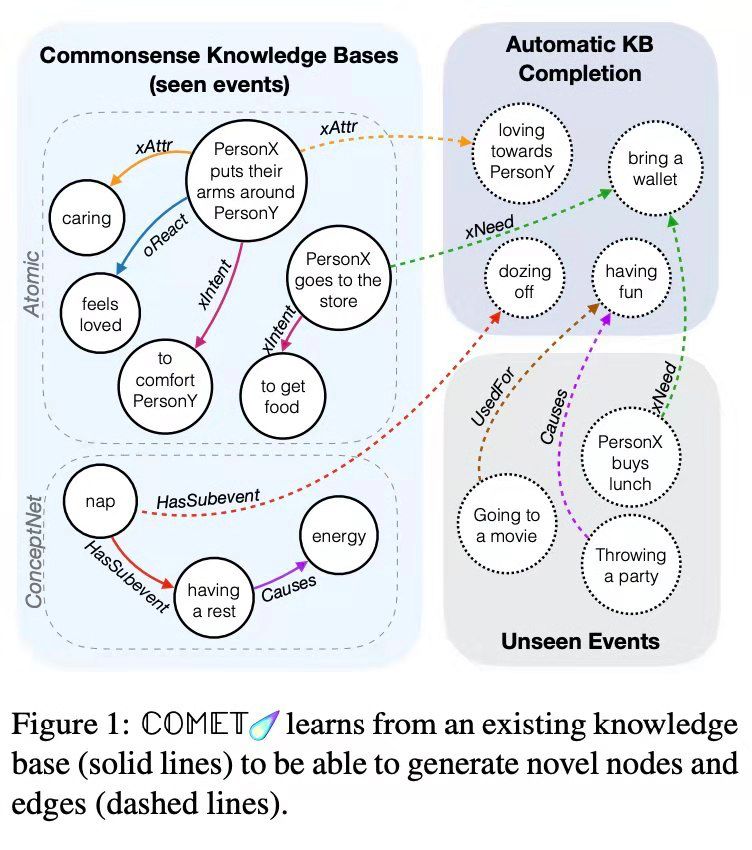
图源: Bosselut et al.
?Bosselut 等人的论文(https://www.aclweb.org/anthology/P19-1470)介绍了 Comet —— 一种用于常识性转换的架构 —— 其中语言模型(如 GPT-2)与 seed knowledge 图谱(如 Atomic)相结合。用图谱中的 seed tuples 元组支持 COMET 能够了解它的结构和关系。另一方面,为生成新的节点和边并添加到 seed tuples 中,语言模型采用了图示法。更酷的是,可以用自然文本元组来表示一个图 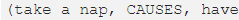
 。在和 Wikidata一样大的 smth 上尝试这种架构非常有趣。
。在和 Wikidata一样大的 smth 上尝试这种架构非常有趣。
用于关系提取的新数据集和基线模型——鼓舞人心的是它们基于 Wikidata 实体和 predicates 。Yao 和 Ye 等人(https://arxiv.org/pdf/1906.06127.pdf)提出一个庞大的 DocRED 数据集,它由 6 个实体类型、96 个关系、250 万个实体(没有 Wikidata IDs)、102000 个文档中的 828000 句组成。Trisedya 等人(https://www.aclweb.org/anthology/P19-1023)提出一个由255000 个文本 triples 、280000 个实体和 158 个谓词函数组成的 WIKI 数据集,该数据集的任务是用给定的自然语言句子构建知识图,并为该数据集建立基线模型。此外,Chen 等人(https://www.aclweb.org/anthology/P19-1278)介绍一个由 426000 triples、112000 个实体、188 个关系组成的关系相似性数据集。
为进一步进行研究信息提取,Zhu 等人(https://www.aclweb.org/anthology/P19-1128)利用graph attention nets 进行关系链接,结果令人印象深刻。他们将句子中实体和关系的组合建模为图形,并使用能够识别 multi-hop 关系的 GNNs。SOTA 的表现有很大的优势。
Soares 等人(https://www.aclweb.org/anthology/P19-1279)的作品描述了一种关系学习的新方法——预训练一个像 BERT 一样的大型模型,并通过它的编码器传递句子,以获得一个关系的抽象概念,然后对一个特定的模式(如 Wikidata, TACRED 或 DBpedia)进行微调,以获得具有相应 ID 的实际谓词。这确实有用——通常 KG-based IE 是为特定的本体定制的,所以当你有很多任务时——也有很多本体。在这里,作者从任一模式中分离出一个关系,并允许提取一个非常通用的关系。这种方法显示出准确性得到了极大的提高,特别是在 zero- 和 few-shots 任务中,因此你可以在训练数据相当有限的情况下使用它。
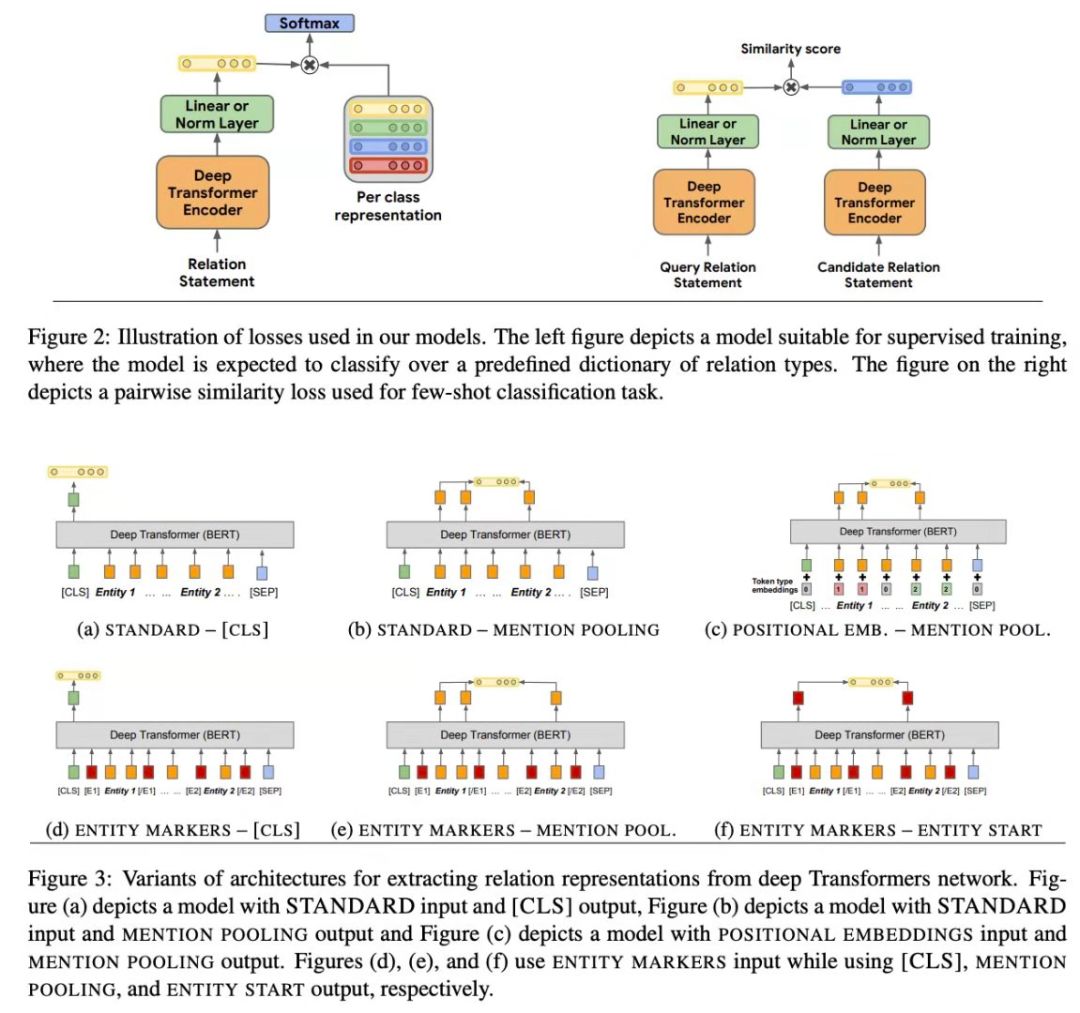
图源: Soares et al.
对于实体联结,Logeswaran 等人(https://www.aclweb.org/anthology/P19-1335)打算采用类似 BERT 的预训练阅读理解模型以推广一些未知域的未知实体。因此,他们提出了一个 domain-adaptive 的预训练策略和一个未知域的 zero-shot 和实体联结的新任务。现在,数据集由 Wikia 文章组成,但我认为,在应用知识图谱框架时,不应有太多的问题,因为这些图谱包含多种语言标签和同义词,或良好界定的特定域的本体。
Hosseini 等人(https://www.mitpressjournals.org/doi/pdf/10.1162/tacl_a_00250)在他们的文章中研究了一个问题,即直接从自然语言文本中提取一个关系图,并在评估数据集方面取得了一些成果。Shaw等人(https://www.aclweb.org/anthology/P19-1010)解决了类似问题,他们应用graph nets(GNNS 近日确实特别火)获取了带有实体的逻辑模式。
Wu 等人(https://www.aclweb.org/anthology/P19-1616)研究了 KGs 中的关系表示,提出了一种基于现有 KG embeddings,能够推广到 unseed 关系的 Representation Adapter 模型。作者还将 SimpleQuestion (SQ) 数据集调整为 SimpleQuestions-Balance (SQB),这样一来 train/test 拆分中已知谓词和未知谓词的分布更加平衡。
谈到命名实体识别(NER),我概述一下 Lopez 等人(https://arxiv.org/pdf/1906.02505.pdf)的文章“双曲空间中的细粒度实体类型”。他们使用了一系列可能的实体类型(转换为具有后续图形网表示的图形),提及了他们构建了一个双曲线嵌入空间,能够推断提及的上下文并在很大程度上专门化实体类型。例如,如果有一句话“阿加莎·克里斯蒂在……中出版了一系列小说”,那么阿加莎·克里斯蒂将不仅被定义为一个人类,而且还能识别出她作家的身份。实际上,在 UltraFine 数据集上训练的框架可以细化到三个级别!在 OntoNotes 上,结果与 SOTA 相当。
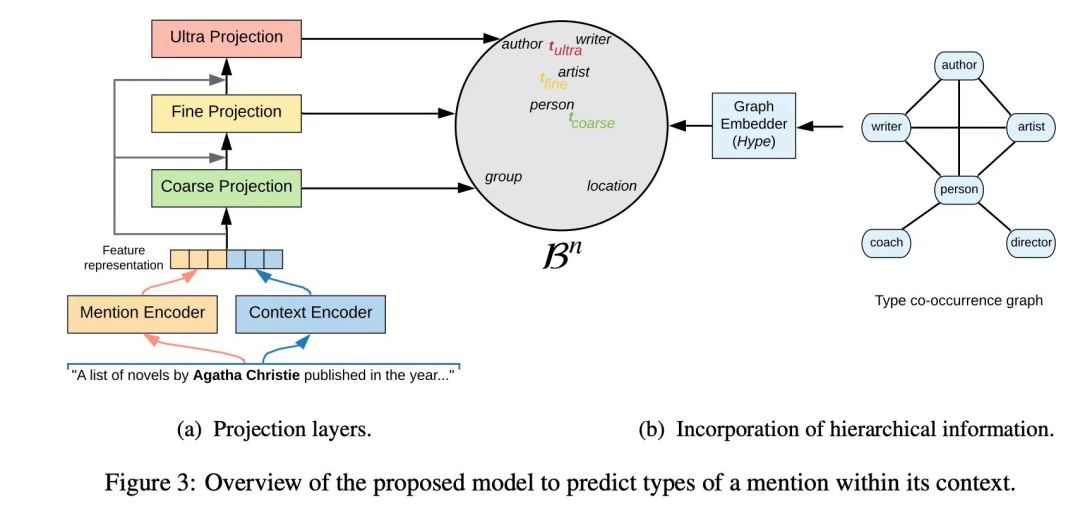
图源: Lopez et al.
KG 嵌入 & Graph Representations
也许有人会认为 NLP 会议不是学习 graph representation 的最佳场所,但你瞧,有一堆很有见地的论文试图在结构和语义上对知识图谱进行编码!
Nathani 等人(https://www.aclweb.org/anthology/P19-1466)介绍了一种基于图注意力网络(GAT)的知识图嵌入方法,该方法考虑了注意机制中的节点和边缘特征。作者采用了一种 multi-head 注意的体系结构,并着重研究了学习关系表示。对四个数据集(除了WN18RR和FB15K-237作者采用NELL-995和亲属关系)进行基准测试,可以显著提高 SOTA 的性能。实际上,这种方法比在 acl 当天介绍的下面的方法要好得多。
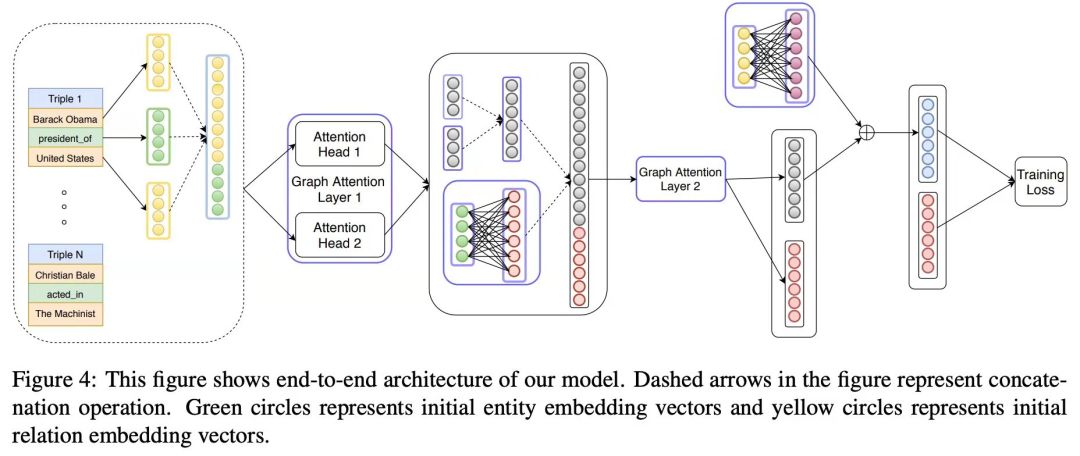
图源: Nathani et al.
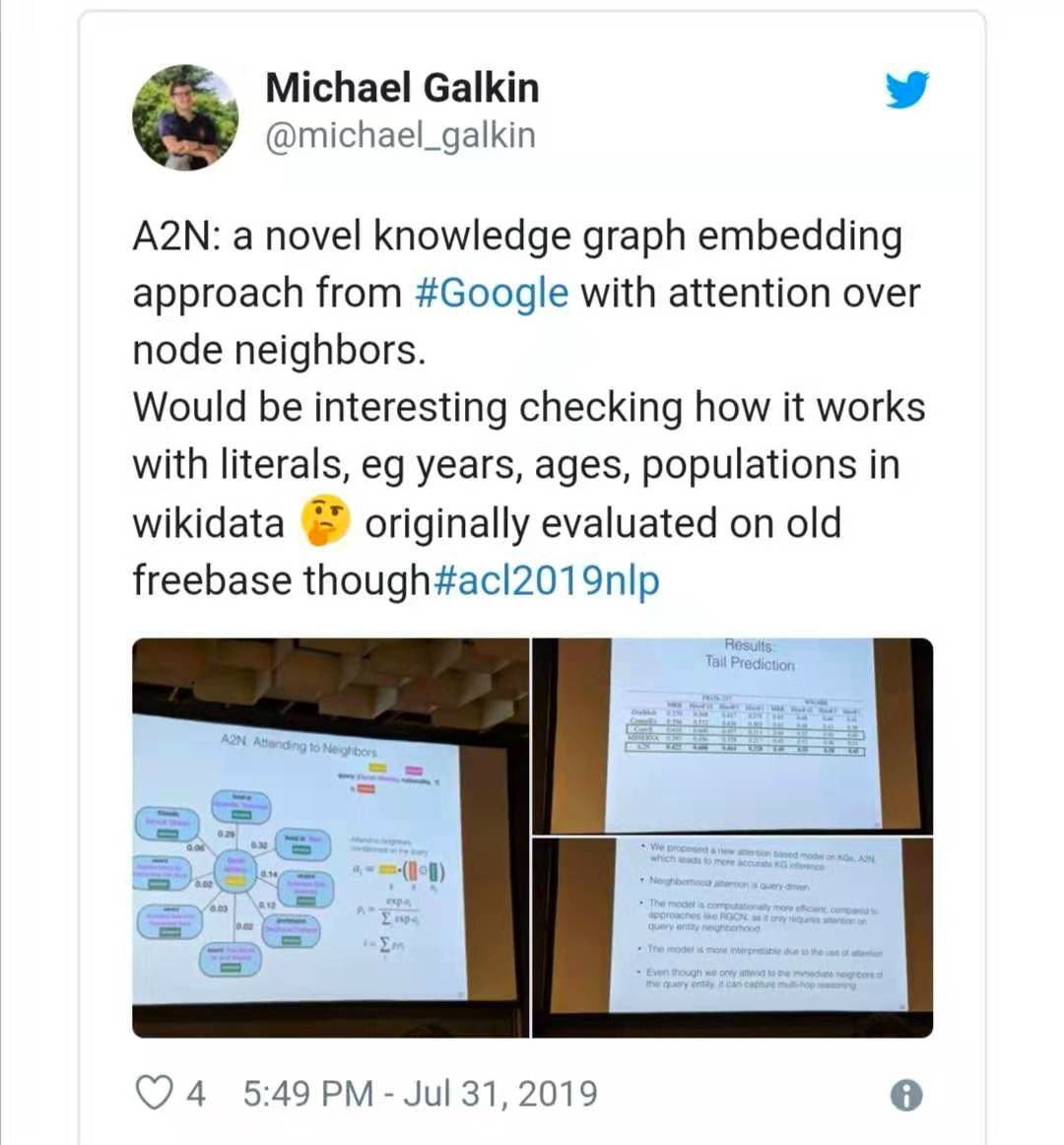
Bansal 等人(https://www.aclweb.org/anthology/P19-1431)提出了一种面向邻域的知识图嵌入技术。聚集来自邻域的消息可以更好地表示作者在评估中显示的 multi-hop 关系。在关系预测基准中,A2N 的表现优于 ConvE 。但是,与上面的方法相比,Hits@N 和 MRR A2N 的效果稍差。我鼓励作者比较一下训练时间和记忆消耗!
**高能数学警告**? Xu 和 Li 的的文章 (https://www.aclweb.org/anthology/P19-1026)与前两篇论文相比有点突出,因为他们使用二面体群在 KG 嵌入中建模关系。本文中的数学知识十分高能(要挑战自己啊 ?),因此简而言之,二面体群允许对谓词的非交换合成建模,例如 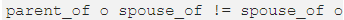
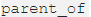 中 o 表示矩阵乘法。此外,该方法能够对谓词之间的对称关系和逆关系进行建模(就像已经在高级 OWL 本体中一样)。虽然传统基准测试的性能与 conva 相当,因为它们主要由 Abelian compositions 组成,但作者构建了一个大量使用非 Abelian compositions 的族数据集。也就是说,这篇论文确实值得一看,但要准备好数学知识储备。** 高能数学警告结束**
中 o 表示矩阵乘法。此外,该方法能够对谓词之间的对称关系和逆关系进行建模(就像已经在高级 OWL 本体中一样)。虽然传统基准测试的性能与 conva 相当,因为它们主要由 Abelian compositions 组成,但作者构建了一个大量使用非 Abelian compositions 的族数据集。也就是说,这篇论文确实值得一看,但要准备好数学知识储备。** 高能数学警告结束**
Kutuzov 等人(https://www.aclweb.org/anthology/P19-1325)描述一个构建图形嵌入的框架,在该框架中,它们不是基于向量的距离函数,而是优化基于图形的度量(如最短路径),并插入定制的节点相似性函数(如 leacock chodorow )。在提高推理速度的同时,该方法不能充分利用节点特征和边缘特征,而这些特征被认为是未来的研究方向。亲爱的作者们,我们一起期待吧!
Stadelmeier 和 Pado (https://www.aclweb.org/anthology/W19-4816)提出了一个上下文路径模型(CPM),旨在在传统的 KG 嵌入方法基础上提供一个可解释层。作者建议使用两个优化分数——路径的校正分数,triple 和路径之间的相关性分数,即正确信号的强度。
Wang 等人(https://arxiv.org/pdf/1810.07180.pdf)在他们的文章 “关于评估 Knowledge Base Completion 的嵌入模型” 中,说明了 KG 嵌入评估中的一个反复出现的问题——它们的预测在逻辑上是一致的吗?例如,在图中,我们可能有 “Roger can’t be friends with David.罗杰不能和大卫交朋友”(实例级)或“Humans can’t be made of Wood.人类不可能由木头制成。”(类级)之类的规则,这意味着 KG 嵌入应该考虑并减少出现此类语句的可能性。他们发现现在大多数的 KG 嵌入模型都可以将非零概率值赋给相当不实际的 triples 三元组。
总结
显然,越来越多的人对在各种 NLP 领域中广泛应用的知识图感兴趣。KGs 上的新数据集和任务出现的频率也越来越高,太棒了!看看这个项目(http://www.acl2019.org/EN/program.xhtml)已经可以完全把闲聊记录下来了。
插图选自对应的论文,其他照片由本人拍摄。
我们下次会议见!
原文链接:
https://medium.com/@mgalkin/knowledge-graphs-in-natural-language-processing-acl-2019-7a14eb20fce8
(*本文为 AI科技大本营编译文章,转载请联系微信 1092722531)
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

大会5折优惠票倒计时 1 天! 团购还享立减优惠,倒计时 1 天!此外,伯克利大学名师精髓课程移师北京。《动手学深度学习》作者、亚马逊首席科学家李沐线下亲授「深度学习实训营」,免费GPU资源,现场还将限量赠送价值85元的配套书籍一本,先到先得。原价1099元,限时专享CSDN 独家福利价199元!识别海报二维码,即刻购票~

推荐阅读
2019 AI ProCon日程出炉:Amazon首席科学家李沐亲授「深度学习」
玩嗨的2亿快手“老铁”和幕后的极致视觉算法
与旷视、商汤等上百家企业同台竞技?AI Top 30+案例评选等你来秀
从不温不火到炙手可热:语音识别技术简史
入门大爆炸式发展的深度学习,你先要了解这6个著名框架
用Python的算法工程师们,编码问题搞透彻了吗?
Python冷知识,不一样的技巧带给你不一样的乐趣
我是如何通过开源项目月入 10 万的?
撬动百亿台设备,让物联网“造”起来!
程序员离无人值班有多远?

你点的每个“在看”,我都认真当成了喜欢
相关文章:

力扣(LeetCode)933
题目地址:https://leetcode-cn.com/probl...题目描述:写一个 RecentCounter 类来计算最近的请求。 它只有一个方法:ping(int t),其中 t 代表以毫秒为单位的某个时间。 返回从 3000 毫秒前到现在的 ping 数。 任何处于 [t - 3000, …
2013年10月1日C#随机数
最近开始接触C跟C#,总是有人说女生本来就不适合做程序,就连今天都听到有人这样跟我讲,不过呢没有关系,我相信男生不一定比女生厉害多少,就好像我身边就有一位男生就总是觉得我的程序比他好一点就是理所当然的ÿ…
C/C++中inline/static inline/extern inline的区别及使用
引入内联函数的目的是为了解决程序中函数调用的效率问题,也是用内联函数取代带参宏定义(函数传参比宏更加方便易用)inline关键字用来定义一个类的内联函数。在类体中和类体外定义成员函数是有区别的:在类体中定义的成员函数为内联…

RISC-V架构上的Debian和Fedora现状
RISC-V仍然是开源/Linux用户非常感兴趣的,因为它是免版税且完全开放的CPU架构。部分原因是由于缺乏经济实惠的RISC-V硬件,限制了开发人员在这种架构上的更多工作,Linux发行版支持的RISC-V状态各不相同,但近年来至少有所改善。在上…

字节跳动李航:自学机器学习,研究AI三十载,他说AI发展或进入平缓期
作者 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】一阵凉风吹过人工智能,让这个曾是燥热的领域逐渐冷却下来,留下的是扎实地在做研究的人、机构、企业。先后在 NEC 公司中央研究所、微软亚洲研究院、华为诺亚方舟实验室从事和…

PC上安装MAC X Lion
PC上安装MACXLion网上关于如何在PC下安装MAC的文章已近不少了,但对于一些初学者在实践当中会遇到各种问题,以下视频资料为大家展示两种虚拟机安装MacOS。1.VmwareWorkstation在虚拟机中安装首先将插件装好(在远景上下载)ÿ…
C++中static_cast/const_cast/dynamic_cast/reinterpret_cast的区别和使用
C风格的强制转换较简单,如将float a转换为int b,则可以这样:b (int)a,或者bint(a)。 C类型转换分为隐式类型转换和显示类型转换。 隐式类型转换又称为标准转换,包括以下几种情况: (1)、算术转换&#x…
行为型模式:命令模式
LieBrother原文: 行为型模式:命令模式 十一大行为型模式之三:命令模式。 简介 姓名 :命令模式 英文名 :Command Pattern 价值观 :军令如山 个人介绍 : Encapsulate a request as an object,ther…

与旷视、商汤等上百家企业同台竞技?AI Top 30+案例评选等你来秀!
人工智能历经百年发展,如今迎来发展的黄金时期。目前,AI 技术已涵盖自然语言处理、模式识别、图像识别、数据挖掘、机器学习等领域的研究,在汽车、金融、教育、医疗、安防、零售、家居、文娱、工业等行业获得了令人印象深刻的成果。在各行业宣…

在CSS中定义a:link、a:visited、a:hover、a:active顺序
摘自:http://www.qianyunlai.com/post-2.html以前用CSS一直没有遇到过这个问题,在最近给一个本科同学做的项目里面。出现一些问题,搜索引擎查了一些网站和资料,发现很多人问到这个问题,给出的结果我试了试,…
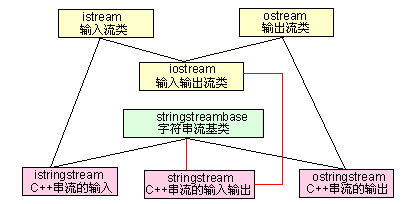
C++中istream的使用
在项目中会经常用到读取一些配置数据,这些数据根据实际需要有可能会调整,如果将这些数据直接嵌入进代码中会非常不便,需要经常调整代码。将这些数据写入配置文件中然后在读入,如果需要调整,只需修改配置文件࿰…

手把手教你用Python模拟登录淘宝
作者 | 猪哥66来源 | 裸睡的猪(ID:IT--Pig)最近想爬取淘宝的一些商品,但是发现如果要使用搜索等一些功能时基本都需要登录,所以就想出一篇模拟登录淘宝的文章!看了下网上有很多关于模拟登录淘宝,但是基本都…
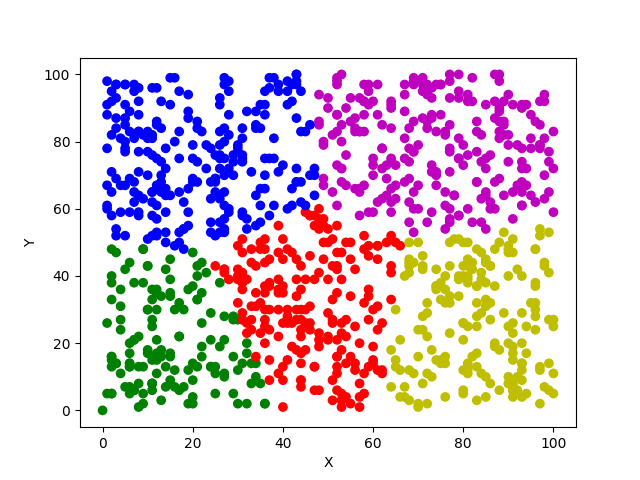
Python之机器学习K-means算法实现
一、前言: 今天在宿舍弄了一个下午的代码,总算还好,把这个东西算是熟悉了,还不算是力竭,只算是知道了怎么回事。今天就给大家分享一下我的代码。代码可以运行,运行的Python环境是Python3.6以上的版本&#…
C++中模板的使用
模板(Template)指C程序设计语言中的函数模板与类模板,是一种参数化类型机制。模板是C泛型编程中不可缺少的一部分。C templates enable you to define a family of functions or classes that can operate on different types of information.模板就是实现代码重用机…

php面试问答
结合实际PHP面试,汇总自己遇到的问题,以及网上其他人遇到的问题,尝试提供简洁准确的答案包含MySQL、Redis、Web、安全、网络协议、PHP、服务器、业务设计、线上故障、个人简历、自我介绍、离职原因、职业规划、准备问题等部分 GitHub: https:…

图解LSTM与GRU单元的各个公式和区别
作者 | Che_Hongshu来源 | AI蜗牛车 (ID: AI_For_Car)因为自己LSTM和GRU学的时间相隔很远,并且当时学的也有点小小的蒙圈,也因为最近一直在用lstm,gru等等,所以今天没事好好缕了一下,接下来跟着我一起区分并…
iphone越狱神器
前阵子刚刚换了iphone5,老婆的4就留给我了。一到手就决定越狱,无意中发现了一款越狱神器:爱思助手http://www.i4.cn/ 确实很好用转载于:https://blog.51cto.com/shanks/1306423
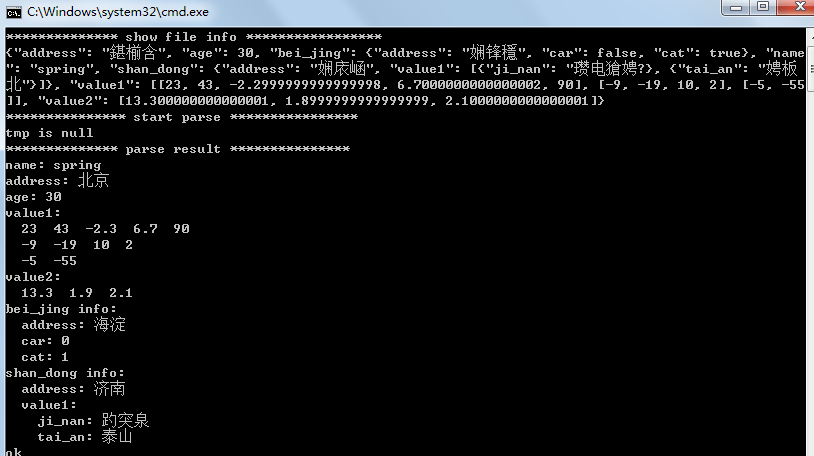
json11库的使用
JSON(JavaScript Object Notation)是一种轻量级的文本数据交换格式,易于让人阅读。同时也易于机器解析和生成。尽管JSON是Javascript的一个子集,但JSON是独立于语言的文本格式,并且采用了类似于C语言家族的一些习惯。JSON解析器和JSON库支持许…
覆盖10亿设备,月活2亿,快应用要取代App?
作者 | 伍杏玲 来源 | CSDN(ID:CSDNnews) 2017 年 1 月 9 日,微信小程序横空出世,紧接着支付宝小程序、百度智能小程序、今日头条小程序、12 大厂商联盟的快应用等布局小程序。自此,小程序迅速改变国内移…
跨域的四种方式
本文主要是关于跨域的几种方式,关于什么是跨域这里就不多说了,写这个也是为了记住一些知识点的。 一. jsonp jsonp的跨域方式很容易理解,页面的的每一个script标签浏览器都会发送get请求获取对应的文本资源,获取到了之后ÿ…

使用模式创建一个面向服务的组件中间件
引言 在本文中,您将了解面向服务的组件中间件在用于资源有限的语音设备时,在设计阶段所应用的模式。它涵盖了项目的问题上下文,并被看成是一组决定因素,是对相关体系结构远景的一个简要概括。您还会得到一份描述,其中介…
OpenCV代码提取:遍历指定目录下指定文件的实现
OpenCV 3.1之前的版本,在contrib目录下有提供遍历文件的函数,用起来比较方便。但是在最新的OpenCV 3.1版本给去除掉了。为了以后使用方便,这里将OpenCV 2.4.9中相关的函数给提取了出来,适合在Windows 64bits上使用。directory.hpp…

姚班三兄弟3万块创业八年,旷视终冲刺港股
作者 | 余洋洋 杨健楷编辑 | 张丽娟来源 | CV智识(ID:CVAI2019)旷视此次 IPO 或将成为整个 AI 行业的信号,不只是“ 四小龙”的另外三家——商汤、依图、云从,整个 AI 行业的创业公司都将受到影响。8月25日晚,AI 独角兽…

Java类加载器详解
Java虚拟机中的类加载有三大步骤:,链接,初始化.其中加载是指查找字节流(也就是由Java编译器生成的class文件)并据此创建类的过程,这中间我们需要借助类加载器来查找字节流. Java虚拟…
linux svn客户端的使用
一下内容转载于:http://blog.chinaunix.net/space.php?uid22976768&doblog&id1640924。这个总结的很好~ windows下的TortoiseSVN是资源管理器的一个插件,以覆盖图标表示文件状态,几乎所以命令都有图形界面支持,比较好用&…
C++中vector的使用
向量std::vector是一种对象实体,能够容纳许多各种类型相同的元素,包括用户自定义的类,因此又被称为序列容器。与string相同,vector同属于STL(Standard Template Library)中的一种自定义的数据类型,可以广义上认为是数组…

说出来你可能不信,现在酒厂都在招算法工程师
导语:虽然夏日已过,但人们喝啤酒的热情还在持续高涨。不过随着大众的追求和理念提升,对于啤酒的要求也越来越高,比如逐渐兴起的精酿之风,都在印证人们在啤酒的口感和风味上,拥有更加「苛刻」的要求。那么这…

「前端面试题系列7」Javascript 中的事件机制(从原生到框架)
前言 这是前端面试题系列的第 7 篇,你可能错过了前面的篇章,可以在这里找到: 理解函数的柯里化ES6 中箭头函数的用法this 的原理以及用法伪类与伪元素的区别及实战如何实现一个圣杯布局?今日头条 面试题和思路解析最近,…
安装Ecshop首页出现报错:Only variables should be passed by referen
出现下面这就话: Strict Standards: Only variables should be passed by reference in D:\wamp\ecshop\includes\cls_template.php on line 406 第406行:$tag_sel array_shift(explode( , $tag)); 解决办法 1 5.3以上版本的问题,应该也和配…
KDD 2019高维稀疏数据上的深度学习Workshop论文汇总
作者 | 深度传送门来源 | 深度传送门【导读】本文是“深度推荐系统”专栏的第九篇文章,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文简要总结一下阿里妈妈在 KDD 2019 上组织的第一届面向高维稀疏数据的深度学习实…