从这篇YouTube论文,剖析强化学习在工业级场景推荐系统中的应用

作者 | 吴海波
转载自知乎用户吴海波
【导读】本文作者根据两篇工业界背景的论文解答了 RL 在推荐场景需要解决的问题与困难,以及入门需要学习得相关知识点。
2 个月前,业界开始流传 youtube 成功将 RL 应用在了推荐场景,并且演讲者在视频中说是 youtube 近几年来取得的最显著的线上收益。
放出了两篇论文:Top-K Off-Policy Correction for a REINFORCE Recommender System和Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology。本文不想做论文讲解,已经有同学做的不错了:wd1900.github.io/2019/0(http://wd1900.github.io/2019/06/23/Top-K-Off-Policy-Correction-for-a-REINFORCE-Recommender-System-on-Youtube/)。
个人建议两篇论文都仔细读读,TopK 的篇幅较短,重点突出,比较容易理解,但细节上 SlateQ 这篇更多,对比着看更容易理解。而且,特别有意思的是,这两篇论文都说有效果,但是用的方法却不同,一个是 off-policy,一个是 value-base ,用 on-policy。很像大公司要做,把主流的几种路线让不同的组都做一遍,谁效果好谁上。个人更喜欢第二篇一些,会有更多的公式细节和工程实践的方案。
很多做个性化推荐的同学,并没有很多强化学习的背景,而 RL 又是一门体系繁杂的学科,和推荐中常用的 supervised learning 有一些区别,入门相对会困难一些。本文将尝试根据这两篇有工业界背景的论文,来解答下 RL 在推荐场景解决什么问题,又会遇到什么困难,我们入门需要学习一些哪些相关的知识点。本文针对有一定机器学习背景,但对 RL 领域并不熟悉的童鞋。
本文的重点如下:
目前推荐的问题是什么
RL在推荐场景的挑战及解决方案
常见的套路是哪些
推荐系统目前的问题
目前主流的个性化推荐技术的问题,突出的大概有以下几点:
优化的目标都是 short term reward,比如点击率、观看时长,很难对long term reward 建模。
最主要的是预测用户的兴趣,但模型都是基于 logged feedback 训练,样本和特征极度稀疏,大量的物料没有充分展示过,同时还是有大量的新物料和新用户涌入,存在大量的 bias。另外,用户的兴趣变化剧烈,行为多样性,存在很多 Noise。
pigeon-hole:在短期目标下,容易不停的给用户推荐已有的偏好。在另一面,当新用户或者无行为用户来的时候,会更倾向于用大爆款去承接。
RL应用在推荐的挑战
extremely large action space:many millions of items to recommend.如果要考虑真实场景是给用户看一屏的物料,则更夸张,是一个排列组合问题。
由于是动态环境,无法确认给用户看一个没有看过的物料,用户的反馈会是什么,所以无法有效模拟,训练难度增加。
本质上都要预估 user latent state,但存在大量的 unobersever 样本和noise,预估很困难,这个问题在 RL 和其他场景中共存。
long term reward 难以建模,且 long/short term reward。tradeoff due to user state estimate error。
旅程开始
熟悉一个新领域,最有效率的做法是和熟悉的领域做结合。接下来,让我们先简单看下 RL 的基本知识点,然后从 label、objective、optimization、evaluation 来切入吧。
RL的基本知识
有一些基本的 RL 知识,我们得先了解一下,首先是场景的四元组结构:
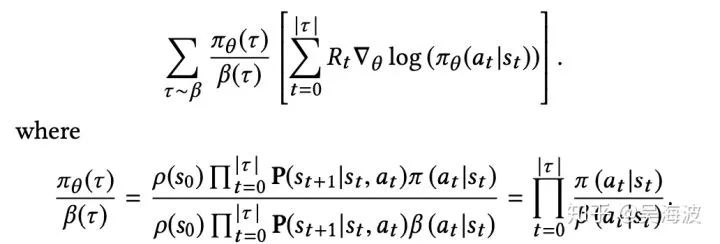
RL 最大的特点是和环境的交互,是一种 trial-error 的过程,通常我们会用 MDP 来描述整个过程,结合推荐场景,四元组数学定义如下:
• S: a continuous state space describing the user states;• A: a discrete action space, containing items available for recommendation;• P : S × A × S → R is the state transition probability;• R : S × A → R is the reward function, where r(s, a) is the immediate reward obtained by performing action a at user state s;
RL在推荐场景的Label特点
众所周知,RL 是典型的需要海量数据的场景,比如著名的 AlphaGo 采用了左右互博的方式来弥补训练数据不足的问题。但是在推荐场景,用户和系统的交互是动态的,即无法模拟。举个例子,你不知道把一个没有推荐过的商品 a 给用户,用户会有什么反馈。
老生常谈Bias
好在推荐场景的样本收集成本低,量级比较大,但问题是存在较为严重的 Bias 。即只有被系统展示过的物料才有反馈,而且,还会有源源不断的新物料和用户加入。很多公司会采用 EE 的方式去解决,有些童鞋表示 EE 是天问,这个点不能说错,更多的是太从技术角度考虑问题了。
EE 要解决是的生态问题,必然是要和业务形态结合在一起,比如知乎的内容自荐(虽然效果是呵呵的)。这个点估计我们公司是 EE 应用的很成功的一个了,前阵子居然在供应商口中听到了准确的 EE 描述,震惊于我们的业务同学平时都和他们聊什么。
off-policy vs on-policy
论文[1]则采取 off-policy 的方式来缓解。off-policy 的特点是,使用了两个policy,一个是用户 behavior 的 β,代表产生用户行为 Trajectory:(s0,A0,s1, · · · )的策略,另一个是系统决策的 π,代表系统是如何在面对用户 a 在状态 s 下选择某个 action 的。
RL 中还有 on-policy 的方法,和 off-policy 的区别在于更新 Q 值的时候是沿用既定策略还是用新策略。更好的解释参考这里:zhihu.com/question/5715
importance weight
off-policy 的好处是一定程度上带了 exploration,但也带来了问题:
In particular, the fact that we collect data with a periodicity of several hours and compute many policy parameter updates before deploying a new version of the policy in production implies that the set of trajectories we employ to estimate the policy gradient is generated by a different policy.
Moreover, we learn from batched feedback collected by other recommenders as well, which follow drastically different policies.
A naive policy gradient estimator is no longer unbiased as the gradient in Equation (2) requires sampling trajectories from the updated policy πθ while the trajectories we collected were drawn from a combination of historical policies β.
常见的是引入 importance weighting 来解决。看下公式
从公式看,和标准的 objective 比,多了一个因子,因为这个因子是连乘和 rnn 的问题类似,梯度容易爆炸或消失。论文中用了一个近似解,并有人证明了是 ok 的。
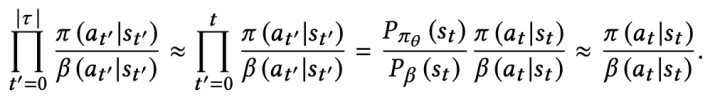
RL在推荐场景的Objective特点
在前文中,我们提到,现有的推荐技术,大多是在优化短期目标,比如点击率、停留时长等,用户的反馈是实时的。用户的反馈时长越长,越难优化,比如成交 gmv 就比 ctr 难。
同时也说明,RL 可能在这种场景更有优势。看下 objective 的形式表达:
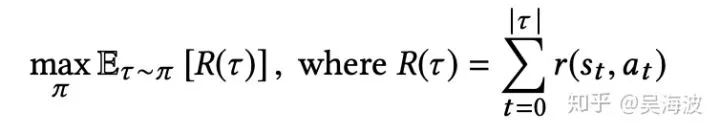
可以发现,最大的特点是前面有个累加符号。这也意味着,RL 可以支持和用户多轮交互,也可以优化长期目标。这个特点,也是最吸引做个性化推荐的同学,大家想象下自已在使用一些个性化产品的时候,是不是天然就在做多轮交互。
轮到 Bellman 公式上场了,先看下核心思想:
The value of your starting point is the reward you expect to get from being there, plus the value of wherever you land next.
看下公式,注意它包含了时间,有助于理解。
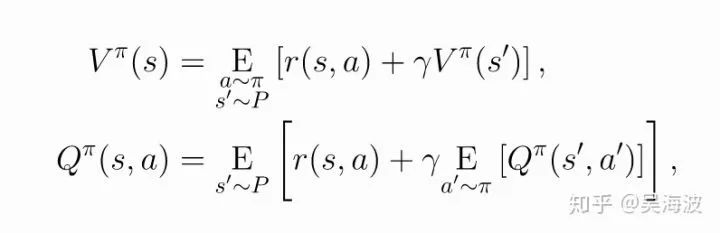
在论文[2]中,有更多关于 bellman 在 loss 中推导的细节。由于论文[1]采用的 policy-gradient 的优化策略,我们需要得到 loss 的梯度:
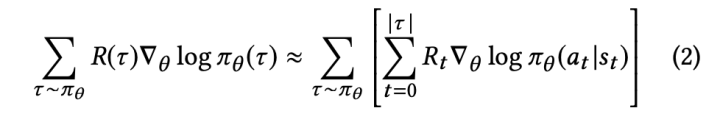
加入 importance weighting 和一些 correction 后,
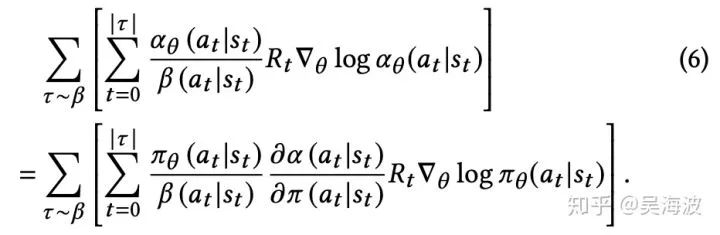
更多细节可以去参考论文。
optimization 和 evaluation
通常,RL 可以分成两种,value-base 和 policy-base,虽然不是完全以optimial的角度看,但两种套路的优化方法有较大的区别。其中 value-base 虽然直观容易理解,但一直被质疑不能稳定的收敛。
they are known to be prone to instability with function approximation。
而 policy-base 则有较好的收敛性质,所以在很多推荐场景的 RL 应用,大部分会选择 policy-base。当然现在也很有很多二者融合的策略,比如 A3C、DDPG 这种,也是比较流行的。
怎么训练 β 和 π
π 的训练是比较常规的,有意思的是 β 的学习。用户的 behavior 是很难建模的,我们还是用 nn 的方式去学一个出来,这里有一个单独的分支去预估 β,和 π 是一个网络,但是它的梯度不回传,如下图:
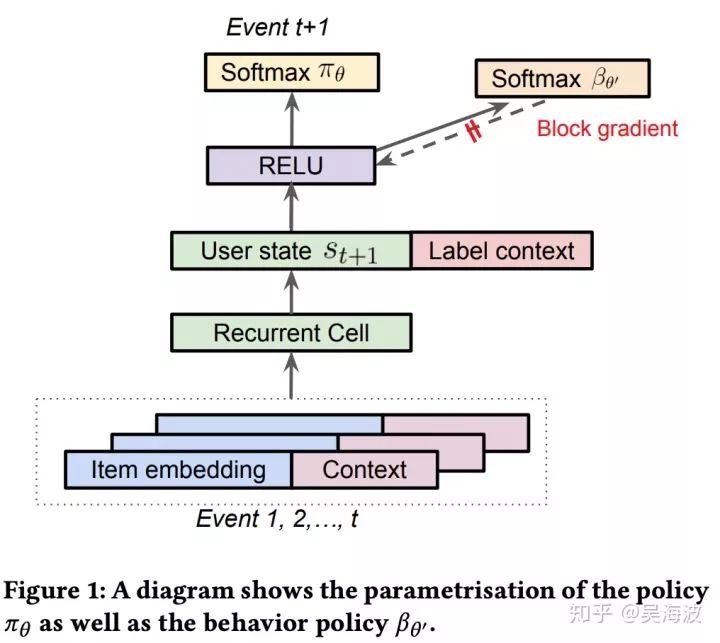
这样就不会干扰 π 。二者的区别如下:
(1) While the main policy πθ is effectively trained using a weighted softmax to take into account of long term reward, the behavior policy head βθ′ is trained using only the state-action pairs;
(2) While the main policy head πθ is trained using only items on the trajectory with non-zero reward 3, the behavior policy βθ′ is trained using all of the items on the trajectory to avoid introducing bias in the β estimate.
为何要把 evaluation 拿出来讲呢?通常,我们线下看 AUC,线上直接看 abtest 的效果。本来我比较期待论文中关于长期目标的设计,不过论文[1]作者的方式还是比较简单,可借鉴的不多:
The immediate reward r is designed to reflect different user activities; videos that are recommended but not clicked receive zero reward. The long term reward R is aggregated over a time horizon of 4–10 hours.
论文[2]中没有细讲。
两篇论文中还有很大的篇幅来讲 Simulation 下的结果,[1]的目的是为了证明作者提出的 correction 和 topK 的作用,做解释性分析挺好的,[2]做了下算法对比,并且验证了对 user choice model 鲁棒,但我觉得对实践帮助不大。
One more thing:TopK在解决什么问题?
listwise 的问题
主流的个性化推荐应用,都是一次性给用户看一屏的物料,即给出的是一个列表。而目前主流的个性化技术,以 ctr 预估为例,主要集中在预估单个物料的ctr,和真实场景有一定的 gap 。当然,了解过 learning to rank 的同学,早就听过 pointwise、pairwise、listwise,其中 listwise 就是在解决这个问题。
通常,listwise 的 loss 并不容易优化,复杂度较高。据我所知,真正在实践中应用是不多的。RL在推荐场景,也会遇到相同的问题。但直接做 list 推荐是不现实的,假设我们一次推荐 K 个物料,总共有 N 个物料,那么我们能选择的action 就是一个排列组合问题,C_N_K * K!个,当 N 是百万级时,量级非常夸张。
这种情况下,如果不做些假设,问题基本就没有可能在现实中求解了。
youtube 的两篇论文,都将问题从 listwise(他们叫slatewise)转化成了itemwise 。但这个 itemwise 和我们常规理解的 pointwise 的个性化技术还是有区别的。在于这个 wise 是 reward 上的表达,同时要引申出 user choice model 。
user choice model
pointwise 的方法只考虑单个 item 的概率,论文中提出的 itemwise,虽然也是认为最后的 reward 只和每个被选中的 item 有关,且 item 直接不互相影响,但它有对 user choice 做假设。比如论文[2]还做了更详细的假设,将目标函数的优化变成一个多项式内可解的问题:

这两个假设也蛮合理的,SC 是指用户一次指选择一个 item,RTDS 是指reward 只和当前选择的 item 有关。
有不少研究是专门针对 user choice model 的,一般在经济学中比较多。推荐中常见的有 cascade model 和 mutilnomial logit model,比如 cascade model,会认为用户选择某个 item 的概率是 p,那么在一个 list 下滑的过程中,点击了第 j 个 item 的概率是 (1-p(i))^j * p(j).
论文[1]中最后的 objective 中有一个因子,表达了 user choice 的假设:
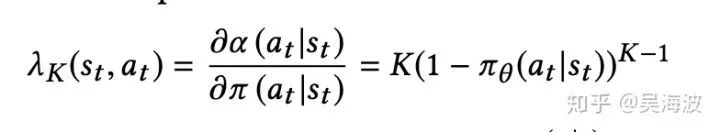
简单理解就是,用 π 当做用户每次选择的概率,那上面就是 K-1 不选择 a 概率的连乘。而论文[2]中,RL 模型和现有的监督模型是融合在一起的,直接用 pCTR 模型预估的 pctr 来当这个 user choice 的概率。
最后
这篇写的有点长,但就算如此,看了本文也很难让大家一下子就熟悉了 RL,希望能起到抛砖引玉的作用吧。从实践角度讲,比较可惜的是 long term reward 的建模、tensorflow 在训练大规模 RL 应用时的问题讲的很少。最后,不知道 youtube 有没有在 mutil-task 上深入实践过,论文[2]中也提到它在 long term 上能做一些事情,和 RL 的对比是怎么样的。
参考
[1] Top-K Off-Policy Correction for a REINFORCE Recommender System
[2] Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology*
[3] slideslive.com/38917655
[4] zhuanlan.zhihu.com/p/72
[5] 强化学习中on-policy 与off-policy有什么区别?zhihu.com/question/5715
[6] wd1900.github.io/2019/0
原文链接:
https://zhuanlan.zhihu.com/p/77494496
(*本文为 AI 科技大本营转载文章,转载请联系原作者)
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

AI ProCon 大会优惠票限时抢购中,三人拼团,每人立减600元!识别海报二维码,即刻购票~

推荐阅读
可惜了,你们只看到“双马会”大型尬聊
60+业内技术专家,9大核心技术专题,AI ProCon倒计时一周!
小团队如何玩转物联网开发?
一文看懂机器学习中的常用损失函数
DeepMind提图像生成的递归神经网络DRAW,158行Python代码复现
KDD 2019高维稀疏数据上的深度学习Workshop论文汇总
5G 改变社会的真相在这里!
程序员如何解决并发冲突的难题?

你点的每个“在看”,我都认真当成了喜欢
相关文章:

java中两个Integer类型的值相比较的问题
转载自: https://www.cnblogs.com/xh0102/p/5280032.html 两个Integer类型整数进行比较时,一定要先用intValue()方法将其转换为int数之后再进行比较,因为直接使用比较两个Integer会出现问题。 总结: 当给Integer直接赋值时&#x…

C#共享内存实例 附源码
原文 C#共享内存实例 附源码 网上有C#共享内存类,不过功能太简单了,并且写内存每次都从开头写。故对此进行了改进,并做了个小例子,供需要的人参考。 主要改进点: 通过利用共享内存的一部分空间(以下称为“数据信息区”…

C++11中weak_ptr的使用
在C中,动态内存的管理是通过一对运算符来完成的:new,在动态内存中为对象分配空间并返回一个指向该对象的指针,可以选择对对象进行初始化;delete,接受一个动态对象的指针,销毁该对象,…
经典不过时,回顾DeepCompression神经网络压缩
作者 | 薰风初入弦转载自知乎导读:本文作者为我们详细讲述了 ICLR 2016 的最佳论文 Deep Compression 中介绍的神经网络压缩方法。神经网络压缩一直是一个重要的研究方向,而目前业界最认可的压缩方法莫过于 ICLR 2016 的最佳论文 Deep Compression&#…
区块链技术特点之去中心化特性
想知道更多关于区块链技术知识,请百度【链客区块链技术问答社区】 链客,有问必答!! 由于区块链技术去中心化的特性,其在我们生活中的很多重要领域(如金融、管理)等方面具有重要的意义。例如&…

Android APK反编译
转自:http://blog.csdn.net/ithomer/article/details/6727581 一、Apk反编译得到Java源代码 下载上述反编译工具包,打开apk2java目录下的dex2jar-0.0.9.9文件夹,内含apk反编译成java源码工具,以及源码查看工具。 apk反编译工具dex…

Java泛型进阶 - 如何取出泛型类型参数
在JDK5引入了泛型特性之后,她迅速地成为Java编程中不可或缺的元素。然而,就跟泛型乍一看似乎非常容易一样,许多开发者也非常容易就迷失在这项特性里。多数Java开发者都会注意到Java编译器的类型擦除实现方式,Type Erasure会导致关…
C++11中override的使用
override是C11中的一个继承控制关键字。override确保在派生类中声明的重载函数跟基类的虚函数有相同的声明。 override明确地表示一个函数是对基类中一个虚函数的重载。更重要的是,它会检查基类虚函数和派生类中重载函数的签名不匹配问题。如果签名不匹配ÿ…
平头哥发布一站式芯片设计平台“无剑”,芯片设计成本降低50%
导读:8 月 29 日,在上海举行的世界人工智能大会上,阿里巴巴旗下半导体公司平头哥发布 SoC 芯片平台“无剑”。无剑是面向 AIoT 时代的一站式芯片设计平台,提供集芯片架构、基础软件、算法与开发工具于一体的整体解决方案ÿ…

Windows XP下,JDK环境变量配置
2019独角兽企业重金招聘Python工程师标准>>> 1.安装JDK,安装过程中可以自定义安装目录等信息,例如我们选择安装目录为D:\java\jdk1.5.0_08; 2.安装完成后,右击“我的电脑”,点击“属性”; 3.选择…
Markdown语法简介
Markdown是一种方便记忆、书写的纯文本标记语言,用户可以使用这些标记符号以最小的输入代价生成极富表现力的文档。它目标是实现易读易写。Markdown的语法全由一些符号所组成。Markdown语法的目标是成为一种适用于网络的书写语言。 Markdown优点:纯文本…
吴恩达:AI未来将呈现四大发展趋势
作者 | 夕颜出品 | AI科技大本营(ID:rgznai100)导读:8 月 30 日,世界人工智能大会精彩继续。在今天的全球工业智能峰会上,Landing.AI 创始人及首席执行官吴恩达来到现场,做了题为《人工智能是新电力》的演讲…
嵌入式课程安排 嵌入式培训课程大纲参考
嵌入式是一门综合性的学科,现在学习嵌入式开发不是单纯局限于单片机或者Linux,嵌入式课程中包含着非常多的内容。以粤嵌嵌入式课程进行参考,看看我们要学习嵌入式的话,要掌握哪些必备的技能。嵌入式课程安排包含:1、入…
Linux网站架构系列之Apache----进阶篇
本篇博文为Linux网站架构系列之apache的第二篇,我将带大家一起学习apache的编译参数,目录结构和配置文件等方面的知识,实现对apache服务的进一步掌握,并使之能更好的应用到生产实战中去。一、编译参数在上篇的apache部署中&#x…

仅用10天设计的JavaScript,凭什么成为程序员最受欢迎的编程语言?
导语:在这个世纪之交诞生的 JavaScript,没人想到会发展为当今世界上最流行的语言之一。它不够成熟,不够严肃,甚至连名字都是模仿的 Java。那么,JavaScript 的成功是依靠运气和完美时机的侥幸吗?其实不然——…
C++11中= delete;的使用
C11中,对于deleted函数,编译器会对其禁用,从而避免某些非法的函数调用或者类型转换,从而提高代码的安全性。 对于 C 的类,如果程序员没有为其定义特殊成员函数,那么在需要用到某个特殊成员函数的时候&…
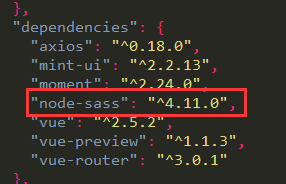
vue 使用scss
使用vue-cli模板创建的项目中,使用scss步骤 1. cmd命令: cnpm install sass-loader --save-devcnpm install node-sass --sava-dev2.查看package.json文件中是否已自动添加以下信息 3. 转载于:https://www.cnblogs.com/duanzhenzhen/p/10453495.html
EBS form日历可选范围设置(calendar.setup )介绍
Calendar是Template提供给我们的standard object.可以使我们方便的为日期型字段提供日期的选择列表.form中设置日历方法:1. 为日期型字段指定LOV(ENABLE_LIST_LAMP)2. 在字段的KEY–LISTVAL事件中编写代码:Calendar.showCalendar Package包含如下几个Procedure:1. Calendar.sho…
人工智能对地球环境科学的推进
一项德国耶拿[1]和汉堡[2]科学家在《自然》杂志发起的研究表明,人工智能可以有效地推进我们对于地球气候系统的理解。特别是在当前深度学习的潜力还未被完全开发的情况下。在人工智能的帮助下一些复杂的动态环境,如飓风,森林火灾,…
从概念到应用,终于有人把数据挖掘讲明白了
作者:陈封能(Pang-Ning Tan)、迈克尔斯坦巴赫(Michael Steinbach)等来源 | 大数据(ID: hzdashuju)【导语】数据采集和存储技术的迅速发展,加之数据生成与传播的便捷性&am…
C++11中default的使用
在C11中,对于defaulted函数,编译器会为其自动生成默认的函数定义体,从而获得更高的代码执行效率,也可免除程序员手动定义该函数的工作量。 C的类有四类特殊成员函数,它们分别是:默认构造函数、析构函数、拷…
Android开发:setAlpha()方法和常用RGB颜色表----颜色, r g b分量数值(int), 16进制表示 一一对应...
杂家前文Android颜色对照表只有颜色和十六进制,有时候需要设置r g b分量的int值,如paint.setARGB(255, 127, 255, 212);就需要自己计算下分量的各个值。这里提供一个带有r g b分量的int型的颜色表。注意paint.setAlpha()及paint.setARGB(&…
【redis】c/c++操作redis(对于hiredis的封装)
前言 最近一直在学习redis,通过c/cpp来执行redis命令,使用的是hiredis客户端来实现的。 先简单贴一下代码 头文件 #include <vector> #include <string> #include <hiredis/hiredis.h> typedef enum en_redisResultType {redis_reply_…

OpenCV代码提取:transpose函数的实现
OpenCV中的transpose函数实现图像转置,公式为:目前fbc_cv库中也实现了transpose函数,支持多通道,uchar和float两种数据类型,经测试,与OpenCV3.1结果完全一致。实现代码transpose.hpp:// fbc_cv …
只给测试集不给训练集,要怎么做自己的物体检测器?
9 月5 日,下周四,大家期待已久的由《动手学深度学习》作者,亚马逊首席科学家亲自带领的「深度学习实训营」就要在北京开营了。今天,李沐已经把这次深度学习实训营白天的教学内容和代码上传到 Gituhub 和 D2L.ai 网站了,…
MYSQL忘记登录密码
1、关闭Mysql: 如果 MySQL 正在运行,首先杀之 killall -TERM mysqld 2、另外的方法启动 MySQL :bin/safe_mysqld --skip-grant-tables 3、可以不需要密码就进入 MySQL 了。 然后就是 >use mysql>update user set passwordpassword(&qu…

OpenCV代码提取:flip函数的实现
OpenCV中实现图像翻转的函数flip,公式为:目前fbc_cv库中也实现了flip函数,支持多通道,uchar和float两种数据类型,经测试,与OpenCV3.1结果完全一致。实现代码flip.hpp:// fbc_cv is free softwar…
NLP这两年:15个预训练模型对比分析与剖析
作者 | JayLou来源 | 知乎前言在之前写过的《NLP的游戏规则从此改写?从word2vec, ELMo到BERT》一文中,介绍了从word2vec到ELMo再到BERT的发展路径。而在BERT出现之后的这大半年的时间里,模型预训练的方法又被Google、Facebook、微软、百度、O…
大三下学期第一周总结
本周以是开学第一周了,在生活方面,生活琐事确实变多了起来。每天上课,看着老师熟悉的面庞,如履春风。感觉学习没有那么多的陌生恐惧。学习是一方面,身体锻炼不能落下。一周至少保证三小时及其以上的运动。身体是革命的…
AD rodc扩展报错
AD rodc扩展报错AD RODC抢夺FSMO五大角色后,架构扩展报错,解决办法参考链接:http://support.microsoft.com/kb/949257/en-us