日均350000亿接入量,腾讯TubeMQ性能超过Kafka

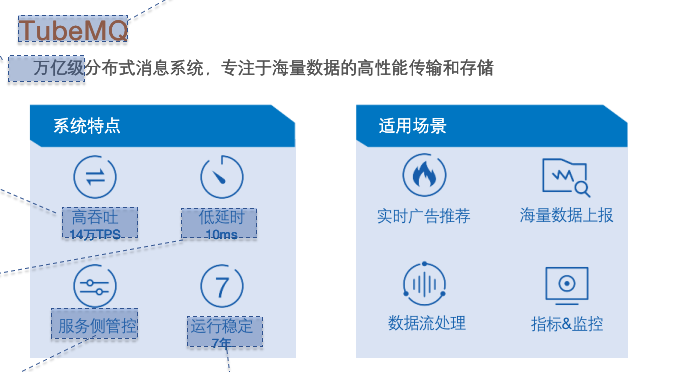
注:近期,腾讯开源了TubeMQ的相关代码及设计。项目推出后得到了广泛关注和对比讨论,在GitHub上已经获得了1.5k个Star。
GitHub:https://github.com/Tencent/TubeMQ
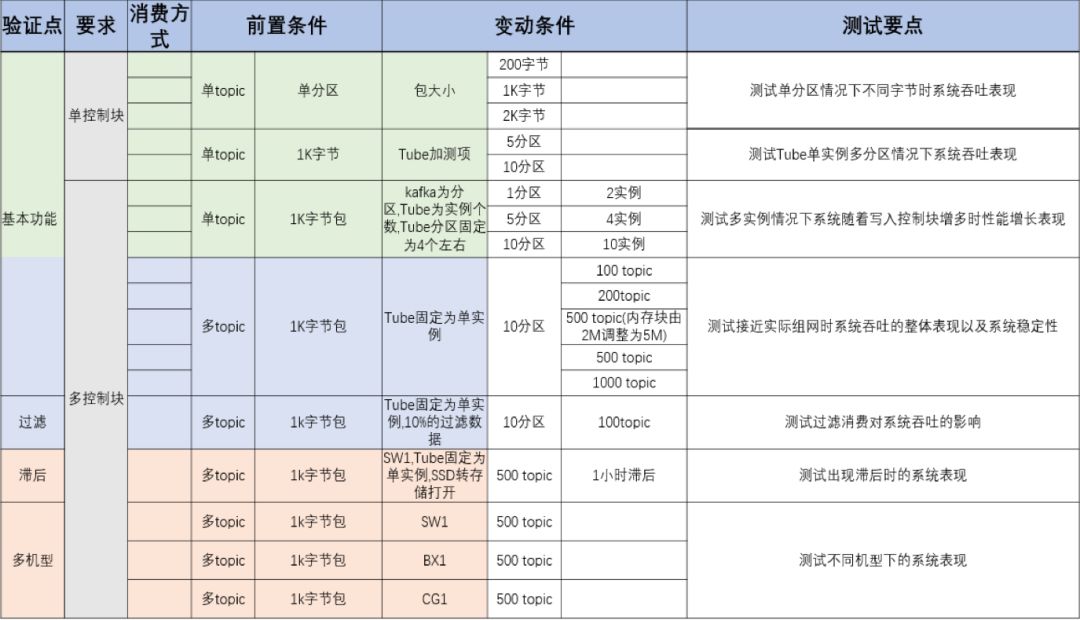
比较项 | TubeMQ | Kafka | Pulsar |
数据时延 | 非常低,10毫秒级 | 比较低,250毫秒级 | 非常低,10毫秒级 |
请求TPS | 高,单机14W+/s | 一般,单机10W+/s | 一般,单机10W+/s (大压力下不稳定) |
过滤消费 | 支持服务端过滤 | 客户端过滤,不支持服务端过滤 | 客户端过滤,不支持服务端过滤 |
数据副本同步策略 | 无,通过RAID10磁盘备份+低时延消费解决 | 多机异步备份 | 多机异步备份(高性能场景) |
数据可靠性 | 一般,单机故障未消费的数据存在丢失风险 | 一般,主机故障未同步的数据存在丢失风险 | 一般,主机故障未同步的数据存在丢失风险 |
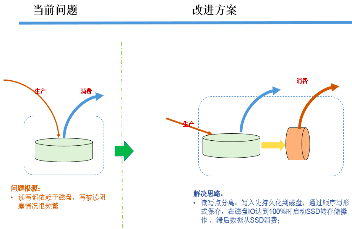
单机磁盘IO 100%时对外服务能力 | 高,特定机型下可以通过SSD转存储消费功能,维持约700M写入及超过1G的消费流量 | 低,滞后会读写受阻,甚至会停写 | 低,滞后会读写受阻,甚至会停写 |
系统稳定性 | 高,已线上运营7年,每天25万亿的数据量,已做到单集群400台Broker的线上运营规模 | 一般,性能随Topic数增多出现不稳定情况,没有超大数据运营规模场景 | 一般,高压下存在性能下降、服务受阻等情况 |
跨集群管控能力 | 有,实施中 | 无 | 无 |
配置可管理性 | 高,热备存储,中心化管理,API或页面操作 | 一般,基于zk配置管理,API或页面操作 | 一般,基于zk配置管理,API或页面操作 |
易用性 | 一般,只提供Java和C++的Lib,数据上报支持tcp、udp、http | 高,有很多配套插件使用 | 高,有很多配套插件使用 |
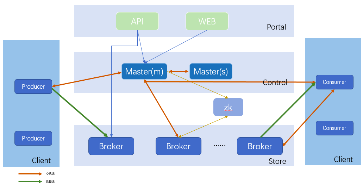
- 负责对外交互和运维操作的Portal部分,包括API和Web两块,API对接集群之外的管理系统,Web是在API基础上对日常运维功能做的页面封装;
- 负责集群控制的Control部分,该部分由1个或多个Master节点组成,Master HA通过Master节点间心跳保活、实时热备切换完成(这是大家使用TubeMQ的Lib时需要填写对应集群所有Master节点地址的原因),主Master负责管理整个集群的状态、资源调度、权限检查、元数据查询等;
- 负责实际数据存储的Store部分,该部分由相互之间独立的Broker节点组成,每个Broker节点对本节点内的Topic集合进行管理,包括Topic的增、删、改、查,Topic内的消息存储、消费、老化、分区扩容、数据消费的offset记录等,集群对外能力,包括Topic数目、吞吐量、容量等,通过水平扩展Broker节点来完成;
- 负责数据生产和消费的Client部分,该部分我们以Lib形式对外提供,大家用得最多的是消费端,相比之前,消费端现支持Push、Pull两种数据拉取模式,数据消费行为支持顺序和过滤消费两种。对于Pull消费模式,支持业务通过客户端重置精确offset以支持业务extractly-once消费,同时,消费端新推出跨集群切换免重启的BidConsumer客户端;
- 负责offset存储的zk部分,该部分功能已弱化到仅做offset的持久化存储,考虑到接下来的多节点副本功能该模块暂时保留。

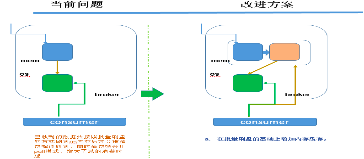
- 数据拉取模式支持Push、Pull:
数据消费行为支持顺序和过滤消费:
- 支持业务extractly-once消费:
(*本文为AI科技大本营整理文章,转载请微信联系1092722531)
◆
精彩推荐
◆
开幕倒计时16天|2019 中国大数据技术大会(BDTC)即将震撼来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读。6.6 折票限时特惠(立减1400元),学生票仅 599 元!

相关文章:

iOS应用版本更新(自动提醒用户)
在#import "AppDelegate.h" 文件中的application:(UIApplication )application didFinishLaunchingWithOptions:(NSDictionary )launchOptions 方法中调用检测结果 获得发布版本的Version 比较当前版本与新上线版本做比较 UIAlertView代理方法

Bash Shell脚本编程-变量知识
Shell:GUI CLI提供交互式接口:提高效率命令行展开:~ ,{}命令别名:alias命令历史:historyGlobbing:*,?,[],[^]命令补全:$PATH指定的目录下路径补全…

FFmpeg中可执行文件ffplay用法汇总
从https://ffbinaries.com/downloads 下载最新的4.1版本的windows 64位FFplay。目前linux下的只有3.2版本的。FFplay是一个由FFmpeg和SDL库组成的简单媒体播放器,它主要用作各种FFmpeg API的测试。 通过执行以下命令将FFplay信息重定位到ffplay_help.txt文件中便于…
用Go重构C语言系统,这个抗住春晚红包的百度转发引擎承接了万亿流量
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)11 月 20 日,百度的万亿流量转发引擎 BFE 登上了 GitHub Trending Top 3,今日 Star 已突破 270。事实上,这个曾经抗住 2019 年春晚抢红包的转发引擎早已于 2019 年夏在 G…
Swift3.0带来的变化汇总系列一——字符串与基本运算符中的变化
var string "Hello-Swift" //获取某个下标后一个下标对应的字符 char"e" //swift2.2 //var char string[startIndex.successor()] //swift3.0 var char string[string.index(after: startIndex)] //获取某个下标前一个下标对应的字符 char2 "t&qu…

vc+如何添加右键弹出菜单
2019独角兽企业重金招聘Python工程师标准>>> 一、创建新工程 二、编辑菜单资源 1、添加菜单 按“CtrlR”,双击“Menu”图标2、于菜单编辑器内编辑菜单四、添加代码(红色部分) void CCMenuView::OnUpdateShow(CCmdUI* pCmdU…
EMNLP 2019 | 大规模利用单语数据提升神经机器翻译
BDTC大会官网:https://t.csdnimg.cn/q4TY作者 | 吴郦军、夏应策来源 | 微软研究院AI头条(ID:MSRAsia)编者按:目前,目标语言端的无标注单语数据已被广泛应用于在机器翻译任务中。然而,目标语言端的无标注数据…

swift 3.0 json解析、字典转模型三种方案
swift3.0发布有一段时间了,发现很多朋友在swift3.0json解析上上遇到很多问题,我这边为大家提三种常见的json方案。 1.第一种是自带的字典转模型,自带的需要实现系统的setValue方法,然后自己还要实现dictToModel方法即可解析&…

海思3559A上编译GDB源码操作步骤及简单使用
1. 从http://ftp.gnu.org/gnu/gdb/ 下载最新稳定版8.3,即gdb-8.3.tar.gz,解压缩; 2. 在gdb-8.3目录下,创建一个build.sh脚本文件,内容如下: ./configure \--prefix"$PWD/install" \--targetaar…
Hibernate之继承映射
Hibernate的继承映射可以理解为两个持久化类之间的继承关系 例如老师和人之间的关系 持久化类 Person类 public class Person { private Integer id; privvate String name; private String sex; public Person (){} // 无参构造器 p…
AutoML未来可期,工程师的明天何去何从?
人工智能和机器学习建模专业技术人才紧缺,即使是高水平的人工智能专家,在大数据智能分析机器学习建模时,主要依靠人工经验,建模过程费时费力,缺少有效方法。为了解决这一突出问题,国内外出现了一种用机器学…
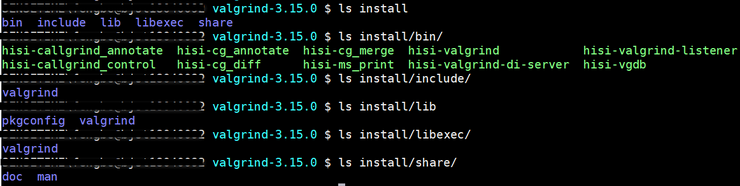
海思3559A上编译Valgrind源码操作步骤
注:按照以下步骤可以在海思板子上正常编译valgrind源码并生成valgrind可执行文件,但可能还不能在海思板子上正常使用。 1. 从http://valgrind.org/downloads/?srcwww.discoversdk.com 下载Valgrind 3.15.0即valgrind-3.15.0.tar.bz2; 2. 在valgrind-3…
Swift之SDWebImage第三方框架
在学习Swift过程中,最害怕的使用了OC的第三方框架 好不容易配置成功了,却出现了意外的Bug [UIImageView setImageWithURL:]: unrecognized selector sent to instance解决办法 第一次配置的时候,因为百度了教程,所以一次性成功…
文件分区格式化及挂载
创建一个5G的分区,文件系统为ext2,卷标为DATA,块大小为1024,预留管理空间为磁盘分区的8%;挂载至/backup目录,要求使用卷标进行挂载,且在挂载时启动此文件系统上的acl功能;在虚拟机创…
iOS开发swift版异步加载网络图片(带缓存和缺省图片)
iOS开发之swift版异步加载网络图片 与SDWebImage异步加载网络图片的功能相似,只是代码比较简单,功能没有SD的完善与强大,支持缺省添加图片,支持本地缓存。 异步加载图片的核心代码如下: func setZYHWebImage(url:NSStr…
2097352GB地图数据,AI技术酷炫渲染,《微软飞行模拟器》游戏即将上线
整理 | 若名出品 | AI科技大本营(ID:rgznai100)“只要是真实存在的地方,你都能抵达。”作为即将成为第一款将整个地球化作虚拟世界来供玩家玩的游戏,微软的《微软飞行模拟器》(Microsoft Flight Simulator)…

开源库nothings/stb的介绍及使用(图像方面)
GitHub上有个开源的stb库,Star数已过万,地址为https://github.com/nothings/stb,为何叫stb,是用的作者名字的缩写Sean T. Barrett。此库仅包含头文件,除stretchy_buffer.h外,其它所有文件以前缀stb开头&…
git stuff
git stuff trick git bash 无法标记复制解决办法 git bash窗口左上角图标点击,选择属性->选项->快速编辑模式 确定就ok了 Usual Commands 创建分支git branch branch-namegit push origin branch-name 删除分支git branch -r -d origin/branch-name 删除远程分支git push…

swift3.0之闭包
Swift 相比原先的 Objective-C 最重要的优点之一,就是对函数式编程提供了更好的支持。 Swift 提供了更多的语法和一些新特性来增强函数式编程的能力,本文就在这方面进行一些讨论。 Swift 概览 对编程语言有了一些经验的程序员,尤其是那些对多…

Linux下gdb attach的使用(调试已在运行的进程)
在Linux上,执行有多线程的程序时,当程序执行退出操作时有时会遇到卡死现象,如果程序模块多,代码量大,很难快速定位,此时可试试gdb attach方法。 测试代码main.cpp如下,这里为了使程序退出时产生…
一行Python代码能实现这么多丧心病狂的功能?(代码可复制)
最近看知乎上有一篇名为《一行 Python 能实现什么丧心病狂的功能?》(https://www.zhihu.com/question/37046157)的帖子,点进去发现一行Python代码可以做这么多丧心病狂的功能!整理了一下知乎上这篇文章的内容ÿ…
一步一步写算法(之图结构)
原文:一步一步写算法(之图结构) 【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 图是数据结构里面的重要一章。通过图,我们可以判断两个点之间是不是具有连通性…

FFmpeg中可执行文件ffprobe用法汇总
从https://ffbinaries.com/downloads 下载最新的4.1版本的Windows 64位FFprobe,FFprobe用于从多媒体流中获取相关信息或查看文件格式信息,并以可读的方式打印,FFprobe可以作为一个命令行程序单独使用。 通过执行以下命令将FFprobe信息重定位…

CocoaPods导入的库其头文件导入的方法
尽管CocoaPods使用十分方便,但其导入的第三方框架还是要经过几步操作,才能供项目使用; 第一步:导入库 1>-在终端进入项目的根目录; 2>-输入:touch Podfile,则项目文件夹会创建一个空的Podfile,这时,你可以将你想要导入的库写在里面.如: platform :ios, 6.0 pod RESid…
Google、微软、阿里、腾讯、百度这些大公司在GitHub上开源投入排名分析 | CSDN原力计划...
扫码参与CSDN“原力计划”作者 | 村中少年来源 | CSDN原力计划获奖作品现在有越来越多的公司都参与了开源,其背后有各自的目的所在,姑且不予讨论。本文是从多个方面分析各大公司在开源上的投入情况。由于全世界绝大多数的开源项目都有发布到Github上&…
jquery源码解析:each,makeArray,merge,grep,map详解
jQuery的工具方法,其实就是静态方法,源码里面就是通过extend方法,把这些工具方法添加给jQuery构造函数的。 jQuery.extend({ ...... each: function( obj, callback, args ) { //$.each(arr , function(i,value){}),第三个参数用于…

swift实现提示框第三方库:MBProgressHUD
GitHud的下载地址是:https://github.com/jdg/MBProgressHUD/ 下载完成后,将MBProgressHUD.h和MBProgressHUD.m拖入已经新建好的Swift项目。因为使用的swift语言,所以拖入项目的时候会提示是否新建一个桥接objective-c与swift的文件ÿ…
这段Python代码让程序员赚300W,公司已确认!网友:神操作!
Python到底还能给人多少惊喜?笔者最近看到了这两天关于Python最热门的话题,关于《地产大佬潘石屹学Python的原因》,结果被这个回答惊到了:来源:知乎 https://www.zhihu.com/question/355880221笔者翻了翻那些回答&…
FFmpeg中可执行文件ffmpeg用法汇总
从https://ffbinaries.com/downloads 下载最新的4.1版本的Windows 64位FFmpeg,FFmpeg是一个快速的音频/视频转换工具,FFmpeg可以作为一个命令行程序单独使用。 通过执行以下命令将FFmpeg信息重定位到ffmpeg_help.txt文件中便于查看,其内容如…
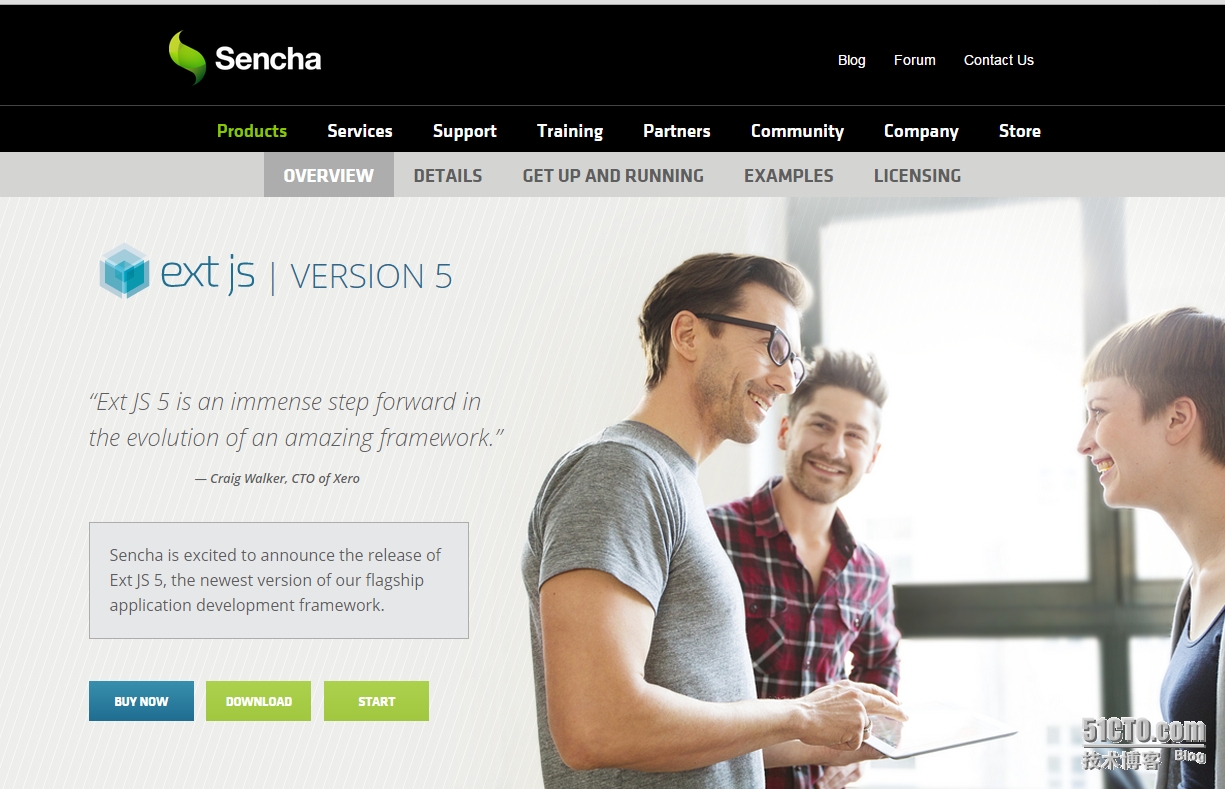
下载Ext JS 5.1 gpl版本的方法
先进入官网:http://www.sencha.com然后在导航的Products中选择Sencha Ext JS,会看到以下页面:这时候不要单击Download按钮,而是要单击导航中的DETAILS,页面切换后,就可在底部看到GPL版本的下载按钮了&#…