赠书 | 熵的实际应用,赌场和金融圈最著名的一个数学公式
本文选自湛庐文化策划出版图书《模型思维》。
作者斯科特·佩奇,超过100万用户的“模型思维课”主讲人。密歇根大学复杂性研究中心“掌门人”。圣塔菲研究所外聘研究员。曾出版《多样性红利》一书。
斯科特·佩奇以对社会科学多样性和复杂性的研究和建模面闻名。具体研究方向包括路径依赖,文化、集体智慧、适应和社会生活的计算模型。斯科特·佩奇于2011年当选美国艺术与科学学院院士,获得2002年的IGERT奖、2001—2006年的生物复杂性项目SLUCE奖和2013年的古根海姆奖。
想要获得这本书,在评论区留言,分享本文读后感,将从中选出3条优质评论送出《思维模型》一本。
活动截止时间12月18日晚8点。
说明:本次活动仅限微信公众平台
信息是不确定性的解。
——克劳德·香农(Claude Shannon)
在本章中,我们讨论熵。熵是对不确定性的一个正式测度。利用熵,我们可以证明不确定性、信息内容与惊喜之间的等价性。低熵对应于低不确定性,同时揭示的信息很少。如果某个结果发生在低熵系统中,例如太阳从东方升起,我们并不会感到惊讶。而在高熵系统中,比如在抽奖时抽中了某个数字,结果是不确定的,并且实现的结果能够揭示信息。在这个过程中,我们经历了惊喜。
利用熵,可以比较不同的现象。我们可以判断新西兰的选举结果是不是比联合国对谴责某个国家的方案的投票结果更不确定,还可以将股票价格的不确定性与体育赛事结果的不确定性进行比较,也可以利用熵的概念来区分四类结果:均衡、周期性、复杂性和随机性。我们可以将看似随机的复杂模式和真正的随机性区分开来,并且可以分辨出哪些现象看起来像是有一定模式的,但事实上是随机的。
我们还可以使用熵来表征分布。在没有控制或调节力量的情况下,一些群体可能会向最大熵漂移。给定特定的约束条件,例如不变的均值或方差,就可以解出最大熵分布。最大熵分布的结果还可以用来证明某些分布比其他分布更优,从而能够对我们在建模时的选择起到指导作用。
本章分为五个部分。
在第一部分中,我们讨论对信息熵(informationentropy)的直观认识,然后给出信息熵的正式定义。在第二部分中,我们描述了关于熵的公理基础。在第三部分中,我们讨论如何使用熵来区分均衡、周期性、随机性和复杂性。在第四部分中,我们研究了会在给定约束条件下产生最大熵的系统。最后,我们探讨了这样一个问题:为什么在有的时候,我们更喜欢复杂性而不是均衡。
信息熵
熵是用来度量与结果的概率分布相关的不确定性的。因此,它也可以衡量意外。熵与方差不同,方差度量一个数值集合或数值分布的离散程度。不确定性与离散程度有关,但是两者并不是一回事。在具有高不确定性的分布中,许多结果的概率都是有意义的,这些结果并不一定有数值,具有高离散度的分布则只是具有一些极端的数值。
通过比较具有最大熵的分布与具有最大方差的分布,可以将这种区别鲜明地呈现出来。给定取值范围为从 1 到 8 的整数的若干结果,能够使最大化熵的分布对每个结果赋予相同的权重。而能够使方案最大化的分布则是以 1/2 的概率取值 1、以 1/2 的概率取值 8(图 12-1)。
熵是在概率分布上定义的。因此它可以应用于非数值数据分布,例如森林中鸟儿的种类或不同口味果酱的市场份额。熵在数学上等于概率与它们的对数之和的相反数。这个数学公式听起来似乎很复杂,但是事实并非如此。
我们先从信息熵这种特殊情况开始讨论。对于信息熵,可以把它理解为根据随机抛硬币的结果来衡量不确定性的一种方法。假设每个家庭都只有两个孩子,男孩和女孩的可能性相同。某个家庭的孩子们的性别列表(按出生顺序排列)相当于抛两次硬币。因此,结果分布的信息熵为 2,因为它对应于两个随机事件。其信息内容也等于 2,因为我们只要提出两个“是或否”问题要求他们回答,就可以掌握结果。
与此类似,在有三个孩子的家庭中,性别列表相当于抛 3 次硬币。要了解这样的家庭的孩子的性别,也只需要提出三个“是或否”问题。同样的逻辑适用于任何数量的儿童。在一般情况下,要了解N 个孩子的性别,只需要提出N 个“是或否”问题。
这里需要注意的是,这N个问题区分出了种可能的出生顺序。这种数学关系是理解熵测度的关键所在:N 个二元随机事件会产生
个可能的结果序列,并且,与之等价,我们可以通过提出N 个“是或否”问题知悉结果序列。这也意味着,信息熵将不确定性水平(和信息内容)N 分配给了2N 个结果上的一个等可能分布。
于是,挑战变成了如何用数学公式刻画这种关系。每个结果序列的概率均为
。要将这个数值转换为 N,需要一个相当复杂的数学公式。我们可以将这个公式推广到任意概率的情形下。如果某个结果序列出现的概率为
,就分配一个不确定性
,它近似于识别该序列所需要提出的“是或否”问题的数量。为了计算出一个分布的信息熵,我们只需求得所有结果(或者像在前面那个例子中那样的结果序列)需要提出的问题的期望数量的平均值。
乍一看,这个数学公式带来的混淆似乎比它所能澄清的还要多。通过举例说明,应该能够使这个公式更加直观。想象一下这种情况:第一胎是女孩的家庭不再生任何孩子,而第一胎是男孩的家庭则还要再生两个孩子。从而,所有家庭中将有一半家庭只有一个女孩。而另一半家庭则等可能地分别属于如下四个结果之一:三个男孩;两个男孩与一个女孩;一个男孩与两个女孩;一个男孩一个女孩与一个男孩。这四种结果中的每一种出现的概率均为 1/8。
信息熵等于我们想了解一个家庭的子女排列状况时必须提出的“是或否”问题的期望数量。我们首先会问,第一个孩子是不是女孩,回答“是”的概率为 1/2。如果是这个答案,那么就不需要继续问下去了。因此有一半的时间,我们只需问一个问题。我们可以把这写成。
如果答案是否定的,那么我们还必须再提出两个问题,于是总共要问三个问题。这四种情况中的每一种都以 1/8 的概率出现,因此每种情况对信息熵的贡献为1/8×3,我们对每种情况可以写出。
从而,信息熵等于 2,即上述五项的总和。虽然这里使用的对数和负号可能会让有些人觉得困扰,但是直观含义仍然是非常清楚的:信息熵就对应着“是或否”问题的期望数量。
如果我们不得不提出很多问题,那么分布就是不确定的。而知道了结果,也就揭示了信息。
熵的公理基础
为了得到熵的一般表达式,我们采用公理化的方法。数学家克劳德·香农对他给出的这种测度施加了四个条件。前三个条件很容易理解,它必定是连续的和对称的,而且在所有结果以相同的概率发生时最大化,同时在某些结果上等于零。第四个条件可分解性则要求在具有m 个子类别的n 个类别上定义的概率分布的熵,等于各类别上的分布的熵与每个子类别的熵的总和。香农证明,有一类熵测度是唯一满足这些公理的测度。虽然这里的分布的乘积是一个不那么直观的自然假设。例如,在结果是两个独立事件的乘积的情况下,这意味着联合事件的信息内容是每个事件单独发生时的信息内容的总和。
正如夏普利值的公理基础一样,这些公理对存在性的贡献大于它们本身的合理性。聪明的数学家总是可以构造出能唯一定义一个函数的公理。香农的前两个公理很难质疑。有的人可能吹毛求疵地指责,将已知分布的不确定性设置为零过于任意了,但这只是一个适当的基准,另一种可能性是将已知分布的不确定性指定为 1。可分解性虽然解释起来不是很容易,但是也很难去挑战它。两个组合随机事件的不确定性理应等于每个事件的不确定性之和。总的来说,这些公理不仅仅是可辩护的,事实上,它们是难以辩驳的。
利用熵区分结果类别
我们现在阐明,如何利用熵测度来对经验数据进行分类,并在计算机科学家、数学家斯蒂芬·沃尔弗拉姆(Stephen Wolfram)给出的四大类别的框架下建模:均衡、周期性,随机性和复杂性。在沃尔弗拉姆的这个分类中,放在桌子上的铅笔处于均衡状态,绕太阳运转的行星处于循环当中,抛硬币的结果序列是随机的,纽约证券交易所的股票价格也是近似随机的(我们在下一章中将会说明原因)。最后,一个人大脑中的神经元发放则是复杂的:它们既不会随意发放,也不会以某个固定的模式发放。图 12-2 以图形方式呈现了这四个类别。
平衡结果没有不确定性,因此其熵等于零。周期性过程具有不随时间变化的低熵。当然,完全随机过程具有最大的熵。复杂性具有中等程度的熵,因为复杂性位于有序性和随机性之间。虽然熵在两种极端情况下能够为我们给出明确的答案:均衡和随机性;但是这并不适用于周期性和复杂性的结果。在这些情况下,通常还必须善用我们的判断力。
为了对时间序列数据进行分类,我们需要先计算出不同长度的子序列中的信息熵。假设,有个人会把他每天戴的帽子的类型一一记录下来。假设他只在两种帽子之间进行选择,一种是贝雷帽,记为B,另一种是浅顶软呢帽,记为F。这样过了一年,他对帽子的选择生成了一个有 365 个事件的时间序列。我们先计算长度为 1 的子序列的熵,也就是说,先计算戴每种类型帽子的概率的熵。假设他喜欢这两种类型的帽子的程度相同,那么长度为 1 的子序列的熵等于 1。因此,我们可以先把均衡排除掉,因为他会改变他的选择,但是其他三种类别中的任何一种都是可能的。
为了确定类别,我们接下来计算长度为 2 到 6 的子序列的熵。如果所有都具有最大的熵,那么我们可以将简单的周期性排除掉。假设当我们考虑更长的序列时,熵会缓慢增加,直到达到最大值 8 为止。换句话说,无论子序列有多长,熵都不会超过 8。熵为 8 相当于 256 个结果的等可能分布,这不可能是一个简单的循环。熵为 8 更可能代表具有特定结构和模式的复杂过程序列。我们不能确定地说,这个时间序列是复杂的。一种可能的情况是,这个人试图做到随机化,但是却失败了。
最大熵和分布假设
在很多情况下,我们建模时都必须把不确定性包括进来;因而作为建模者,必须对有关的分布做出假设。这里的原则是,我们要尽量避免做出任意特殊假设(ad hoc assumption)。也许,我们对产生分布的过程已经有了一些了解。如果是这样,通常可以运用逻辑 - 结构 - 功能方法,推导出该过程产生的统计结构。
例如,假设我们想要对一个房地产拍卖中的所有拍卖对象的总价值的分布做出一个假设。总价值等于各个项目的价值总和。因此,我们可以根据中心极限定理假设这是一个正态分布。对于一栋房子的可能价值,我们也可以假设一个正态分布,因为房屋的价值取决于它的多个性质:卧室的数量、浴室的数量和占地大小等。
对于艺术珍品或稀有手稿的可能价值,正态分布却可能没有意义。在这些情况下,我们对决定它们价值的过程几乎一无所知。一种方法是假设一个具有最大不确定性的分布,即最大熵分布。
最大熵分布的形状取决于各种约束条件。正如我们已经看到的,如果假设了一个最小值和一个最大值,那么均匀分布会使熵最大化。教科书和学术期刊中的许多社会科学模型都假设均匀分布,我们可能会质疑这个假设,因为均匀分布在现实世界中确实很少出现。然而,无差别原则(principle ofindifference)可以证明假设均匀分布的合理性。如果只知道范围或可能集,那么就应当予以无差别的对待。
在某些情况下,我们可能知道分布的均值,也知道所有值都必定是正数。给定这些约束条件,最大熵分布必定具有长尾,因为我们要将分布置于更多的值上,从而必须使少数高值结果与许多低值结果保持平衡。不难证明,熵最大化分布是一个指数分布。因此,如果我们正在构建一个模型,需要假设网站点击量或市场份额的分布形式,那么在没有可用数据的情况下,指数分布是一种自然的假设。
如果我们确定了均值和方差(并且允许出现负值),那么最大熵分布则是正态分布。这里的逻辑与前一种情况类似。为了创造更多的不确定性,我们创造了一些极端值,在这里,可以平衡正值和负值,而不用改变均值。但是,这样做会增大方差,因此我们必须在均值附近添加更多值,从而创造出钟形曲线。
我们可以在逻辑 - 结构 - 功能框架内解释这些最大熵分布。如果我们认为在给定的社会、生物或物理环境中,某个微观层面的过程能够最大化熵,那么我们应该期待上面这些分布中的某一个会出现。或者也可以假设一个微观过程,并能够证明熵在增加。如果是这样,上述分布中的某一个也会涌现出来。
我们也可以将这些结果解释为探索性的。我们可能会遇到一些指数分布或正态分布的数据。虽然没有“义务”去追问某种潜在的行为是否会在一定约束条件下使熵增加,但这样做确实可以帮助我们获得一些新的洞见。在本书前面的章节中,我们利用中心极限定理解释了物种的高度、重量和长度为什么会服从正态分布。
在这里,我们再给出一个不同的、基于模型的解释:如果一种突变能够最大化熵(以便探索最好的生态位),并且假设平均规模和总离散度是固定的,那么规模的分布将是会正态的。关键不在于这种最大熵方法是不是提供了一个更好的解释,而在于给定约束下最大化熵必定会导致正态分布。因此,当我们看到正态分布时,它可能是最大化熵的结果。
熵的实证含义和规范含义
前面我们已经讨论了,熵如何衡量不确定性、信息和惊喜,如何与测量离散度的方差不同,以及如何有助于我们对不同类别的结果进行分类和比较。在本书第 13 章和第 14 章中研究随机游走和路径依赖时,还会利用熵来识别随机性并测量路径依赖的程度。事实上,我们可以将熵测度用于任何实际应用,可以用它来衡量对金融市场的干预是增加了还是减少了不确定性,可以检验选举、体育赛事或博彩中的结果到底是不是随机的。
在这些应用中,熵都是作为一个实证的衡量标准来使用的。它告诉我们世界是什么样的,而不是世界应该是什么样。一个系统中的熵的本质,不能简单地说好,也不能简单地说不好。我们想要多少熵,取决于具体情况。在制定税法时,我们可能需要一种均衡行为模型,并不希望有随机性。在规划城市时,我们可能会希望看到复杂性,均衡或者周期性都会显得过于平淡。
我们希望一个城市充满生机活力,为偶然的相遇和互动提供无限机会。在这种情况下,更多的熵会更好,但是又不能太多。我们不喜欢随机性,随机性会使计划变得非常困难,并可能导致我们的认知能力崩溃。最理想的情况是,世界会产生适度的复杂性,以保证我们生活在一个有趣的时代。
建筑师克里斯托弗·亚历山大(Christopher Alexander)证明,诸如强中心、厚边界和非独立这类的几何属性,能够生成复杂的生活建筑、社区和城市。亚历山大渴望城市和生活空间中的复杂性。中央银行的规划者可能不太喜欢复杂性,在金融市场中,他们可能更喜欢可预测的均衡结果。不过幸运的是,使用模型,我们既可以探索复杂性,也可以讨论均衡的可能性。
*本文已获得湛庐文化转载许可,拒绝二次转载。
好书推荐
你有好书,我来推荐!
书籍方向:AI、大数据、物联网等技术方向。
合作联系人:1092722531(微信)
相关文章:

Java传输对象模式
传输对象模式(Transfer Object Pattern)用于从客户端向服务器一次性传递带有多个属性的数据。传输对象也被称为数值对象。传输对象是一个具有 getter/setter 方法的简单的 POJO 类,它是可序列化的,所以它可以通过网络传输。它没有…
图片下方出现几像素的空白间隙
1、如何定义高度很小的容器? 在IE6下无法定义小高度的容器,是因为有一个默认的行高。 列举2种解决方案:overflow:hidden | line-height:0 2、图片下方出现几像素的空白间隙? 这个也有多种解决方案,如将img定义为displa…
Python3中Pillow(PIL)介绍
PIL全称为Python Imaging Library,是Python中的免费开源图像处理库。PIL的最新版本为1.1.7,于2009年9月发布,支持Python的最高版本到2.7。原始的PIL开发于2011年停止。随后,一个名为Pillow的后续项目fork了PIL的repository并增加了…
GitHub有望在中国开设子公司?
作者 | Financial Times译者 | 弯月,编辑 | 郭芮出品 | CSDN(ID:CSDNnews)作为世界上最大的软件开发平台,GitHub 自去年被微软以 75 亿美元收购后,一直颇受外界的争议。虽然在交易完成后,GitHub…
OC指示符assign、atomic、nonatomic、copy、retain、strong、week的解释
在使用property定义property时可以在property与类型之间用括号添加一些额外的指示符,常用的指示符有assign、atomic、nonatomic、copy、retain、strong、week、等。详情如下: assign: 简单赋值,不更改索引计数(Referen…
项目沟通管理计划
沟通计划包括决定项目涉及人的信息和沟通需求:谁需要什么信息;什么时候需要;怎么获得。虽然所有的项目都需要沟通项目信息,但信息需求和传播方式差别很大。确认涉及人的信息需求和决定满足需求的适当方式是项目获得成功的重要因素…
PyTorch中torchvision介绍
TorchVision包包含流行的数据集、模型架构和用于计算机视觉的图像转换,它是PyTorch项目的一部分。TorchVison最新发布版本为v0.11.1,发布较频繁,它的license为BSD-3-Clause。它的源码位于: https://github.com/pytorch/vision T…
百度ERNIE登顶GLUE榜单,得分首破90大关
出品 | AI科技大本营(ID:rgznai100)12月10日,百度ERNIE在自然语言处理领域权威数据集GLUE中登顶榜首,以9个任务平均得分首次突破90大关刷新该榜单历史,其表现超越微软MT-DNN-SMART, 谷歌T5、ALBERT等一众顶级预训练模…
Java 重写(Override)与重载(Overload)
TestDog.java /* * 重写(Override) * 重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写! * 重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现…

Oracle常用查看表结构命令
2019独角兽企业重金招聘Python工程师标准>>> select user from dual; //查看当前的用户名 select table_name from all_tables; //所有用户的表 select table_name from dba_tables; //包括系统表 select table_name from dba_tables where owner用户名 user_tabl…
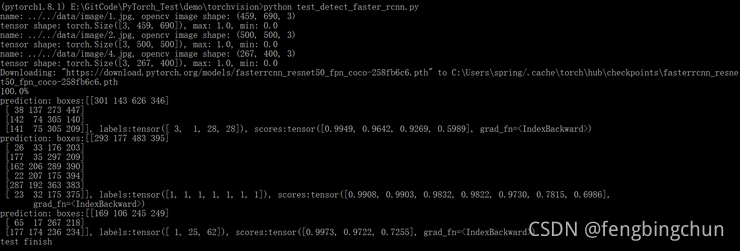
TorchVision中使用FasterRCNN+ResNet50+FPN进行目标检测
TorchVision中给出了使用ResNet-50-FPN主干(backbone)构建Faster R-CNN的pretrained模型,模型存放位置为https://download.pytorch.org/models/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth,可通过fasterrcnn_resnet50_fpn函数下载,此函数实现…

iOS-UIButton防止重复点击(三种办法)
目录 使用场景方法一 设置enabled或userInteractionEnabled属性方法二 借助cancelPreviousPerformRequestsWithTarget:selector:object实现方法三 通过runtime交换方法实现注意事项一 使用场景 在实际应用场景中,有几个业务场景需要控制UIButton响应事件的时间间隔。…
华为诺亚方舟开源预训练模型“哪吒”,4项任务均达到SOTA
出品 | AI科技大本营(ID:rgznai100)BERT之后,新的预训练语言模型XLnet、RoBERTa、ERNIE不断推出,这次,华为诺亚方舟实验室开源了基于BERT的中文预训练语言模型NEZHA(哪吒),寓意模型能…
音量调节助手(转)
源:音量调节助手 软件名称:音量调节助手 软件功能:通过键盘快捷键快速调节系统主音量 软件版本:V2014 软件作者:易几网络 操作系统:所有WINDOWS版本 开发工具:DELPHI XE …
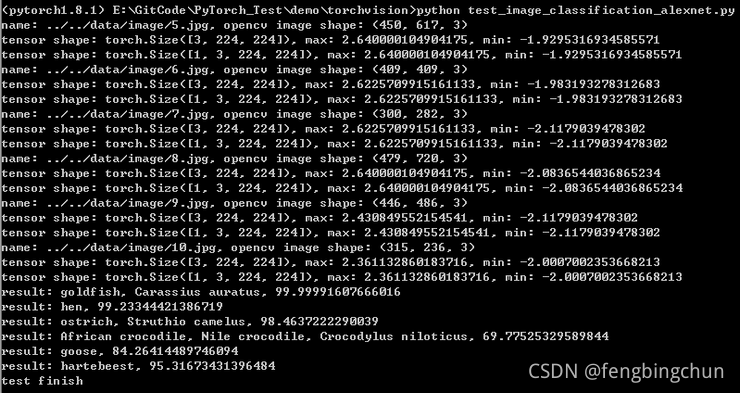
TorchVision中通过AlexNet网络进行图像分类
TorchVision中给出了AlexNet的pretrained模型,模型存放位置为https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth ,可通过models.alexnet函数下载,此函数实现在torchvision/models/alexnet.py中,下载后在Ubuntu上存放…
西湖龙井也上链?是的,以后你喝什么茶我都知道!
什么?区块链还可以帮忙法律取证?是的!就是这么牛13!区块链存证第一案12月9日,据《新华每日电讯》报道,杭州互联网法院用区块链提升审判效率。报道提到一个案例。2018年4月,杭州一家公司…
Java Enumeration接口
import java.util.Vector; import java.util.Enumeration; /* * Enumeration接口中定义了一些方法,通过这些方法可以枚举(一次获得一个)对象集合中的元素。 * 这种传统接口已被迭代器取代,虽然Enumeration 还未被遗弃࿰…
Windows Azure Pack与SCVMM标签解析分享
我在SCVMM上做了好CentOS6.5的VM模板镜像,自己部署也是成功的,现在配置WAP的VM云虚拟机角色配置,在SCVMM上我打好了CentOS6.5的标签,可是在创建虚拟机角色配置中,选择的CentOS却无法找到硬盘,这是怎么回事呢…

Linux下C++中可使用的3种Hook方法
Hook即钩子,截获API调用的技术,是将执行流程重定向到你自己的代码,类似于hack。如使程序运行时调用你自己实现的malloc函数代替调用系统库中的malloc函数。这里介绍下Linux下C中可使用的3中Hook方法: 1. GNU C库允许你通过指定适当…
Java Properties 类
Properties 继承于 Hashtable.表示一个持久的属性集.属性列表中每个键及其对应值都是一个字符串。 Properties 类被许多Java类使用。例如,在获取环境变量时它就作为System.getProperties()方法的返回值。 Properties 定义如下实例变量.这个变量持有一个Properties对…
国产数据库年终大盘点
作者 | 马超 编辑 | 胡巍巍出品 | CSDN(ID:CSDNnews)去“IOE”这个概念,最早由王坚院士在刚刚加入阿里时提出,其目标是将IBM 的小型机、Oracle数据库、EMC存储设备从阿里的IT体系中去除,代之以自主研发的系…

解密FFmpeg播放track mode控制
上一篇文章(http://www.cnblogs.com/yangdanny/p/4421130.html)我们解决了在FFmpeg下如何处理H264和AAC的扩展数据,根据解出的NALU长度恢复了H264的起始码和AAC的ADTS头,这样一般来说播放是没有问题。本篇文章来谈谈如何实现基于FFmpeg的track mode控制&…
UIButton防止按钮和手势的暴力点击
首先理解下几个概念 1、IMP:它是指向一个方法具体实现的指针,每一个方法都有一个对应的IMP,当你发起一个消息之后,最终它会执行的那段代码,就是由IMP这个函数指针指向了这个方法实现的 2、SEL:方法名称的描…
使用Windows7上的VS Code打开远程机Ubuntu上的文件操作步骤
之前在https://blog.csdn.net/fengbingchun/article/details/118991855 中介绍过在Windows10通过VS Code打开Ubuntu 16.04上的文件或文件夹的操作步骤。Windows7上的操作与Windows10有所不同,这里记录下。 Visual Studio Code Remote - SSH扩展允许你在任何远程机器…
微众银行殷磊:AI+卫星,从上帝视角洞察资产管理|BDTC 2019
出品 | AI科技大本营(ID:rgznai100)12月5日-7日,2019中国大数据技术大会(BDTC)于北京隆重举办,大会已成功举办十二届,是大数据领域极具影响力的行业盛会。本届大会汇聚了学术界、企业界上千位知…
【二分答案】【最短路】bzoj1614 [Usaco2007 Jan]Telephone Lines架设电话线
对于二分出的答案x而言,验证答案等价于将所有边权>x的边赋成1,否则赋成0,然后判断从1到n的最短路是否<K。 #include<cstdio> #include<cstring> #include<queue> using namespace std; #define N 1001 #define M 100…
Python3中装饰器@typing.overload的使用
typing.py的源码在:https://github.com/python/cpython/blob/main/Lib/typing.py 。此模块为类型提示(Type Hints)提供运行时支持。这里介绍下typing.overload的使用,从python 3.5版本开始将Typing作为标准库引入。 python3中增加了Function Annotation(…
19年NAACL纪实:自然语言处理的实用性见解 | CSDN博文精选
作者 | Nikita Zhiltsov翻译 | 王威力校对 | 李海明本文为你概述处理不同NLP问题时的具有卓越性能的方法、技术和框架等。计算语言:人类语言技术学会北美分会2019年年会(North American Chapter of the Association for Computational Linguistics: Huma…
高并发场景下数据库的常见问题及解决方案
一、分库分表 (1)为什么要分库分表 随着系统访问量的增加,QPS越来越高,数据库磁盘容量不断增加,一般数据库服务器的QPS在800-1200的时候性能最佳,当超过2000的时候sql就会变得很慢并且很容易被请求打死&a…
典型用户 persona
persona 典型用户 1、姓名:王涛 2、年龄:22 3、收入:基本无收入 4、代表用户在市场上的比例和重要性:王涛为铁道学生。本软件的用户主要是学生和老师,尤其是广大的铁大学子,所以此典型用户的重要性不言而喻…