如何优雅地使用pdpipe与Pandas构建管道?
作者 | Tirthajyoti Sarkar
译者 | 清儿爸
编辑 | 夕颜
出品 | AI科技大本营(ID: rgznai100)
【导读】Pandas 是 Python 生态系统中的一个了不起的库,用于数据分析和机器学习。它在 Excel/CSV 文件和 SQL 表所在的数据世界与 Scikit-learn 或 TensorFlow 施展魔力的建模世界之间架起了完美的桥梁。
数据科学流通常是一系列的步骤:数据集必须经过清理、缩放和验证,之后才能被强大的机器学习算法使用。
当然,这些任务可以通过 Pandas 等包提供的许多单步函数或方法来完成,但更为优雅的方式是使用管道。在几乎所有的情况下,通过自动执行重复性任务,管道可以减少出错的机会,并能够节省时间。
在数据科学领域中,具有管道特性的软件包有 R 语言的 dplyr 和 Python 生态系统中的 Scikit-learn。
要了解它们在机器学习工作流中的应用,你可以读这篇很棒的文章:
https://www.kdnuggets.com/2017/12/managing-machine-learning-workflows-scikit-learn-pipelines-part-1.html
Pandas 还提供了 `.pipe` 方法,可用于类似的用户定义函数。但是,在本文中,我们将讨论的是非常棒的小库,叫 pdpipe,它专门解决了 Pandas DataFrame 的管道问题。
使用 Pandas 的流水线
Jupyter Notebook 的示例可以在我的 Github 仓库中找到:
https://github.com/tirthajyoti/Machine-Learning-with-Python/blob/master/Pandas%20and%20Numpy/pdpipe-example.ipynb。
让我们看看如果使用这个库来构建有用的管道。
数据集
为了演示,我将使用美国房价的数据集,可从 Kaggle 下载:
https://www.kaggle.com/vedavyasv/usa-housing
我们可以在 Pandas 中加载数据集,并显示其汇总的统计信息,如下所示:
但是,数据集中还有一个“Address”字段,其中包含了文本数据。
添加大小限定符列
在这个演示中,我们在数据集中添加了一个列来限定房屋的大小,代码如下所示:
经过此步骤之后,数据集如下所示:
最简单的管道:一次操作
我们从最简单的管道开始,它只包含一次操作(不必担心,我们很快就会增加复杂性的)。
让我们假设机器学习团队和领域专家说他们认为我们可以安全地忽略用于建模的数据 `Avg. Area House Age` 。因此,我们将从数据集中删除这一列。
对于这个任务,我们使用 pdpipe 中的 `ColDrop` 来创建一个管道对象 `drop_age`,并将 DataFrame 传递给这个管道。
import pdpipe as pdpdrop_age = pdp.ColDrop(‘Avg. Area House Age’)df2 = drop_age(df)正如预期的那样,生成的 DataFrame 如下所示:
只需添加管道链级
只有当我们能够进行多个阶段时,管道才是有用和实用的。在 pdpipe 中有多种方法可以实现这一点。但是,最简单、最直观的方法是使用 + 运算符。这就像手工连接管道一样!
比方说,除了删除 `age` 列之外,我们还希望对 `House size` 的列进行独热编码,以便可以轻松地在数据集上运行分类或回归算法。
pipeline = pdp.ColDrop(‘Avg. Area House Age’)
pipeline+= pdp.OneHotEncode(‘House_size’)
df3 = pipeline(df)
因此,我们首先使用 `ColDrop` 方法创建了一个管道对象来删除 `Avg. Area House Age` 列。此后,我们只需使用常用的 Python 的 `+=` 语法将 `OneHotEncode` 方法添加到这个管道对象中即可。
生成的 DataFrame 如下所示。请注意,附加的指示列 `House_size_Medium` 和 `House_size_Small` 是由独热编码创建的。
根据行值删除某些行
接下来,我们可能希望根据行值来删除它们。具体来说,我们可能希望删除房价低于 25 万的所有数据。我们有 `ApplybyCol` 的方法来讲删除用户蒂尼的函数应用到 DataFrame,还有一个方法 `ValDrop` 根据特定值来删除某些行。我们可以轻松地将这些方法链接到管道,以便能够有选择地删除行(我们仍在向现有的管道对象中添加内容,该对象已经完成了列删除和独热编码的其他工作)。
def price_tag(x): if x>250000: return 'keep' else: return 'drop'pipeline+=pdp.ApplyByCols('Price',price_tag,'Price_tag',drop=False)pipeline+=pdp.ValDrop(['drop'],'Price_tag')pipeline+= pdp.ColDrop('Price_tag')第一个方法是通过应用用户定义的函数 `price_tag()`,根据 `Price` 列中的值来对行进行标记。
第二种方法是,在 `Price_tag` 中查找字符串 `drop`,并删除那些匹配的行。最后,第三个方法就是删除 `Price_tag` 标签列,清理 DataFrame。毕竟,这个 `Price_tag`列只是临时需要的,用于标记特定的行,在达到目的后就应该将其删除。
所有这些都是通过简单地链接同一管道上的各个阶段来完成的!
现在,我们可以回顾一下,看看我们的管道从一开始对 DataFrame 都做了什么工作:
删除特定的列。
独热编码,用于建模的分类数据列。
根据用户定义函数对数据进行标记。
根据标记删除行。
删除临时标记列。
所有这些,使用的是以下五行代码:
pipeline = pdp.ColDrop('Avg. Area House Age')pipeline+= pdp.OneHotEncode('House_size')pipeline+=pdp.ApplyByCols('Price',price_tag,'Price_tag',drop=False)pipeline+=pdp.ValDrop(['drop'],'Price_tag')pipeline+= pdp.ColDrop('Price_tag')
df5 = pipeline(df)最近版本更新:直接删除行!
我与包作者 Shay Palachy 进行了精彩的讨论,他告诉我,该包的最新版本可以用 lambda 函数,仅用一行代码即可完成行的删除(满足给定的条件),如下所示:
pdp.RowDrop({‘Price’: lambda x: x <= 250000})
Scikit-learn 与 NLTK
还有许多更有用、更直观的 DataFrame 操作方法可用于 DataFrame 操作。但是,我们只是想说明,即使是 Scikit-learn 和 NLTK 包中的一些操作,也包含在 pdpipe 中,用于创建非常出色的管道。
Scikit-learn 的缩放估算器
建立机器学习模型最常见的任务之一是数据的缩放。Scikit-learn 提供了集中不同类型的缩放,例如,最小最大缩放,或者基于标准化的缩放(其中,数据集的平均值被减去,然后除以标准差)。
我们可以在管道中直接链接这些缩放操作。下面的代码段演示了这种用法:
pipeline_scale = pdp.Scale('StandardScaler',exclude_columns=['House_size_Medium','House_size_Small'])df6 = pipeline_scale(df5)本文中,我们应用了 Scikit-learn 包中的 `StandardScaler` 估算器来转换数据以进行聚类或神经网络拟合。我们可以选择性地排除那些无需缩放的列,就像我们在本文中对指示列 `House_size_Medium` 和 `House_size_Small` 所做的那样。
瞧!我们得到了缩放后的 DataFrame:
NLTK 的词法分析器
我们注意到,DataFrame 中的 Address 字段现在几乎毫无用处。但是,如果我们可以从这些字符串中提取邮政编码或州名,它们可能对某种形式的可视化或机器学习任务有用。
为此,我们可以使用 Word Tokenizer(单词标记器)来实现这一目的。NTLK 是一个流行而强大的 Python 库,用于文本挖掘和自然语言处理,并提供了一系列的标记器方法。在本文示例中,我们客户使用一个这样的标记器来拆分 Address 字段中的文本,并从中提取州名。我们注意到,州名就是地址字符串中的倒数第二个单词。因此,下面的链式管道就可以帮我们完成这项工作:
def extract_state(token): return str(token[-2])
pipeline_tokenize=pdp.TokenizeWords('Address')pipeline_state = pdp.ApplyByCols('Address',extract_state,result_columns='State')
pipeline_state_extract = pipeline_tokenize + pipeline_state
df7 = pipeline_state_extract(df6生成的 DataFrame 如下所示:
总结
如果我们对本文这个演示中显示的所有操作进行总结,则如下所示:
所有这些操作都可以在类似类型的数据集上频繁使用,并在数据集准备好进入下一级建模之前,能有一组简单的顺序代码块作为预处理操作来执行,将是非常棒的。
流水线是实现统一的顺序代码块集的关键。Pandas 是机器学习和数据科学团队中用于这类数据预处理任务的最广泛使用的 Python 库,而 pdpipe 则提供了一种简单而强大的方法,可以使用 Pandas 类型操作构建管道,可以直接应用于 Pandas DataFrame 对象。
你可以自己探索这个库,为你的特定数据科学任务构建更强大的管道。
原文链接:
https://towardsdatascience.com/https-medium-com-tirthajyoti-build-pipelines-with-pandas-using-pdpipe-cade6128cd31
(*本文为AI科技大本营翻译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
2020年,由 CSDN 主办的「Python开发者日」活动(Python Day)正式启动。我们将与 PyCon 官方授权的 PyCon中国社区合作,联手顶尖企业、行业与技术专家,通过精彩的技术干货内容、有趣多元化的活动等诸多体验,共同为中国 IT 技术开发者搭建专业、开放的技术交流与成长的家园。未来,我们和中国万千开发者一起分享技术、践行技术,铸就中国原创技术力量。
【Python Day——北京站】现已正式启动,「新春早鸟票」火热开抢!2020年,我们还将在全国多个城市举办巡回活动,敬请期待!
活动咨询,可扫描下方二维码加入官方交流群~
CSDN「Python Day」咨询群 ????
来~一起聊聊Python
如果群满100人,无法自动进入,可添加会议小助手微信:婷婷,151 0101 4297(电话同微信)
推荐阅读
伯克利新无监督强化学习方法:减少混沌所产生的突现行为
机器推理文本+视觉,跨模态预训练新进展
中国搜索 20 年:易守难攻、刚需不减!
年终没有奖
以太坊 2.0 前途光明!
你点的每个“在看”,我都认真当成了AI
相关文章:

第 十 天 : 添 加 硬 盘 和 分 区 挂 载 等
小Q:狼若回头,必有缘由,不是报恩,就是***; 事不三思必有败,人能百忍则无忧。今天的进度虽然慢了,但是学习状态还是一如往常,只不过今天遇到了不少新的知识点,需要好好想想…
从4个月到7天,Netflix开源Python框架Metaflow有何提升性能的魔法?
作者 | Rupert Thomas译者 | 凯隐编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】Metaflow 是由 Netflix 开发,用在数据科学领域的 Python框架,于 2019 年 12 月正式对外开源。据介绍,Metaflow 解决…
SOA标准发展混乱 国内业务缺少经验
近年来,SOA已经成为国际及我国信息技术领域的重大热点之一。从2005年至今,SOA逐渐成为影响中国IT系统构建的主导思想。从2006年开始,SOA的建设方法已在我国部分行业信息化项目中开始得以越来越广泛的应用。 但热潮背后, SOA概念在…

跨平台PHP调试器设计及使用方法——界面设计和实现
一个优秀的交互设计往往会影响一个产品的命运。在设计这款调试器时,我一直在构思这款调试器该长什么样子。简单、好用是我设计的原则,于是在《跨平台PHP调试器设计及使用方法——立项》一文中,我给出了一个Demo。之后实现的效果也与之变化并不…
AJAX安全-Session做Token
个人思路,请大神看到了指点 个人理解token是防止扫号机或者恶意注册、恶意发表灌水,有些JS写的token算法,也会被抓出来被利用,个人感觉还是用会过期的Session做token更好,服务器存储,加载到客户端页面&…
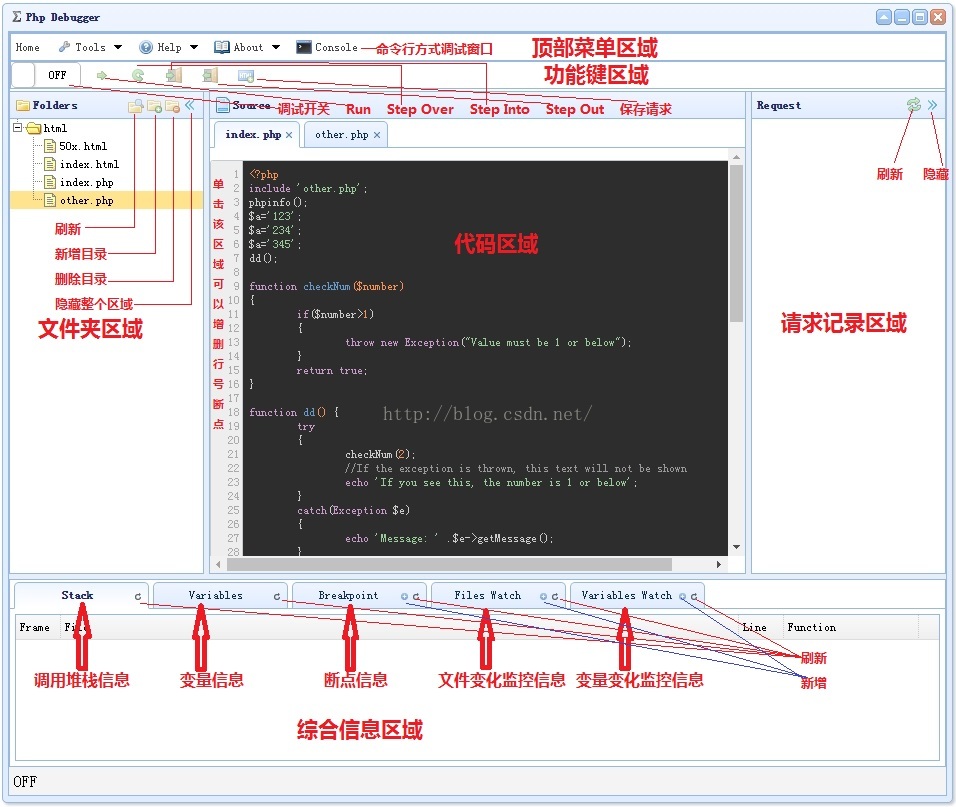
跨平台PHP调试器设计及使用方法——使用
经过之前六篇博文的分析和介绍,大家应该对这套调试器有个初步的认识。本文我将讲解它的使用方法。(转载请指明出于breaksoftware的csdn博客) 上图是该软件界面的布局,我们之后的讲解也将围绕着这些功能展开。 文件夹管理 在查看一…
管理7k+工作流,月运行超10000万次,Lyft开源的Flyte平台意味着什么?
作者 | Allyson Gale译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】Flyte 平台可以更容易的创建并发,可伸缩和可维护的工作流,从而进行机器学习和数据处理。Flyte 已有三年多的训练模型和数据处理经…
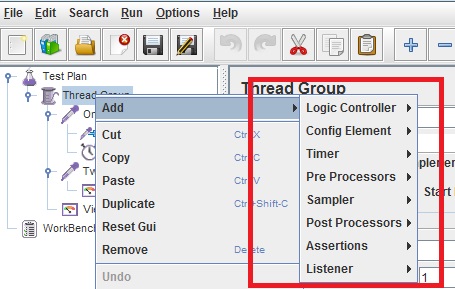
Jmeter组件执行顺序与作用域
一、Jmeter重要组件: 1)配置元件---Config Element: 用于初始化默认值和变量,以便后续采样器使用。配置元件大其作用域的初始阶段处理,配置元件仅对其所在的测试树分支有效,如,在同一个作用域…

跨平台PHP调试器设计及使用方法——拾遗
之前七篇博文讲解了跨平台PHP调试器从立项到实现的整个过程,并讲解了其使用方法。但是它们并不能全部涵盖所有重要内容,所以新开一片博文,用来讲述其中一些杂项。(转载请指明出于breaksoftware的csdn博客) 触发调试的…
召唤超参调优开源新神器:集XGBoost、TensorFlow、PyTorch、MXNet等十大模块于一身...
整理 | 凯隐编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】Optuna是一款为机器学习任务设计的自动超参数优化软件框架,是一款按运行定义(define-by-run) 原则设计的优化软件,允许用户动态地调整搜索空间&#…
Linux下的Silverlight:Moonlight 1.0 Beta 1发布了
Moonlight是微软Silverlight的一个开源实现,其目标平台是Linux与Unix/X11系统。自从2007年9月开始,Moonlight就在Mono项目下进行了开发,它是由Novell发起并资助的。现在,Moonlight 1.0 Beta 1已经向公众发布了。 Novell和Mono宣布…
在visual studio 2010中调用ffmpeg
转自:http://blog.sina.com.cn/s/blog_4178f4bf01018wqh.html 最近几天一直在折腾ffmpeg,在网上也查了许多资料,费了不少劲,现在在这里和大家分享一下。 一、准备工作本来是想自己在windows下编译ffmpeg生成lib、dll等库文件的&am…
无线路由器与无线AP的区别
摆脱线缆的羁绊,手捧一杯香醇的咖啡在家中的任何角落都可以无拘无束和网友谈天说地──这就是无线的魅力!在无线网络迅猛发展的今天,无线局域网(Wireless Local-Area Network,简称WLAN)已经成为许多SOHO家庭…
Simple Dynamic Strings(SDS)源码解析和使用说明一
SDS是Redis源码中一个独立的字符串管理库。它是由Redis作者Antirez设计和维护的。一开始,SDS只是Antirez为日常开发而实现的一套字符串库,它被使用在Redis、Disque和Hiredis等作者维护的项目中。但是作者觉得这块功能还是比较独立的,应该让其…
“不会Linux,到底有多危险?”骨灰级成程序员:基本等于自废武功!
说起程序员的必备技能,我想大家都可以说很多,比如:算法、数据结构、数学、编程语言等等。对于程序员来讲,这些底层能力固然重要,但是,工具同样也是如此,比如常被大家所忽视的:Linux。…

“Uncaught TypeError: string is not a function”
http://www.cnblogs.com/haitao-fan/archive/2013/11/08/3414678.html 今天在js中写了一个方法叫做search(),然后点击按钮的时候提示: “Uncaught TypeError: string is not a function” 百思不得其解啊,我的js木有问题啊啊.... 后来才发现酱…

关于Nikon Ai AF 28mm F1.4D遮光罩的问题
-- 好不容易找到百变妖,确实比较妖!!遮光罩不好找,原厂推荐的HK-7基本属于古董中的古董。 爬文很久,终于找到一篇国外的介绍,说可以用HK-4代替,比HK-7效果更好,而且可以用85mm 1.4D-…
Simple Dynamic Strings(SDS)源码解析和使用说明二
在《Simple Dynamic Strings(SDS)源码解析和使用说明一》文中,我们分析了SDS库中数据的基本结构和创建、释放等方法。本文将介绍其一些其他方法及实现。(转载请指明出于breaksoftware的csdn博客) 字符串连接 SDS库提供下面两种方法进行字符串…
亚马逊机器学习服务:深入研究AWS SageMaker
作者 | Manish Manalath译者 | Shawn编辑 | Carol出品 | AI科技大本营(ID: rgznai100) 机器学习是一个从数据中发现模式的强大概念。但是,如果您尝试过从零开始构建机器模型,那么您一定知道设计一个可扩展的机器学习工作流是多大的…
Java Timer 定时器的使用
一、延时执行首先,我们定义一个类,给它取个名字叫TimeTask,我们的定时任务,就在这个类的main函数里执行。 代码如下:package test;import java.util.Timer;public class TimeTaskTest { public static void main(Str…

Redis源码解析——前言
今天开启Redis源码的阅读之旅。对于一些没有接触过开源代码分析的同学来说,可能这是一件很麻烦的事。但是我总觉得做一件事,不管有多大多难,我们首先要在战略上蔑视它,但是要在战术上重视它。除了一些高大上的技术,我们…

asp.net客户端脚本验证小技巧
通用的客户端脚本验证 Code//验证客户端function checkclient() { var list document.all; for(var i0 ;i<list.length; i) { var h list[i].hint; if(h ! null && h ! "") { if(list[i].isdrop"…
5个可以帮助你提高工作效率的新AI工具
作者 | Kyrylo Lyzanets译者 | 火火酱编辑 | Carol出品 | AI科技大本营(ID: rgznai100) 毫无意义的新闻、故事和活动会占用你每天多少的工作时间?假如你是一名需要高绩效的高管或专业人士,如果在工作中可以不分心,那你…
Centos6.5更换163源 epel源
想必大家都遇到过,安装新的centos系统,使用yum去安装软件的时候,要么找不到,要么慢的让人发疯。网上其实办法很多,直接更换163源就ok,但是基本所有的文章都是直接wget下163的源,但是不知道为什么…
图模型+Bert香不香?完全基于注意力机制的图表征学习模型Graph-Bert
作者 | Jiawei Zhang、Haopeng Zhang、Congying Xia、Li Sun译者 | 凯隐编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】本文提出了一种全新的图神经网络 Graph-Bert,仅仅基于 Attention 机制而不依赖任何类卷积或聚合操作…
闭关纪要17.Google app engine的简单应用
在上面用了十一篇博客的文章详细的介绍了,Step1账户登录系统之后,从现在开始,继续写闭关纪要,因为Step1账户登录系统也是闭关工作的一部分,因此保留序号,这篇纪要在上次的闭关纪要5.WML,UTF-8,BOM,签名及其…

Redis源码解析——内存管理
在《Redis源码解析——源码工程结构》一文中,我们介绍了Redis可能会根据环境或用户指定选择不同的内存管理库。在linux系统中,Redis默认使用jemalloc库。当然用户可以指定使用tcmalloc或者libc的原生内存管理库。本文介绍的内容是在这些库的基础上&#…
poj_2479 动态规划
题目大意 给定一列数,从中选择两个不相交的连续子段,求这两个连续子段和的最大值。 题目分析 典型的M子段和的问题,使用动态规划的方法来解决。 f[i][j] 表示将A[1...i] 划分为j个不相交连续子串,且A[j]属于第i个子串,…

Redis源码解析——字典结构
C语言中有标准的字典库,我们可以通过pair(key,value)的形式存储数据。但是C语言中没有这种的库,于是就需要自己实现。本文讲解的就是Redis源码中的字典库的实现方法。(转载请指明出于breaksoftware的csdn博客) 一般情况下…
十步,教你把Python运行速度提升 30%
作者 | Martin Heinz译者 | 陆离编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】一直以来,诟病 Python语言的人经常说,他们不想使用的一个原因是 Python 的速度太慢了。不管使用哪一种编程语言,程序…