堆状态分析的利器——valgrind的DHAT
在《堆问题分析的利器——valgrind的massif》一文中,我们介绍了如何使用massif查看和分析堆分配/释放的问题。但是除了申请和释放,堆空间还有其他问题,比如堆空间的使用率、使用周期等。通过分析这些问题,我们可以对程序代码进行优化以提高性能。本文介绍的工具DHAT——dynamic heap analysis tool就是分析这些问题的利器。(转载请指明出于breaksoftware的csdn博客)
不同于massif是在程序结束时产生报告,DHAT是在程序运行时实时输出信息的。
我们继续以《堆问题分析的利器——valgrind的massif》文中末尾的代码为例
#include <stdlib.h>void* create(unsigned int size) {return malloc(size);
}void create_destory(unsigned int size) {void *p = create(size);free(p);
}int main(void) {const int loop = 4;char* a[loop];unsigned int kilo = 1024;for (int i = 0; i < loop; i++) {const unsigned int create_size = 10 * kilo;create(create_size);const unsigned int malloc_size = 10 * kilo;a[i] = malloc(malloc_size);const unsigned int create_destory_size = 100 * kilo;create_destory(create_destory_size);}for (int i = 0; i < loop; i++) {free(a[i]);}return 0;
}
第19行通过create方法申请了10K堆空间,一共申请了4次。整个代码周期它们都没释放,所以存在着内存泄漏。
第22行通过malloc方法申请了10K堆空间,一共申请了4次。在第29行,通过free方法释放了这些空间,没有造成内存泄漏。
第25行通过create_destory方法申请并使用了100K的空间,所以也没有内存泄漏。
我们使用下面指令分析编译后的结果
valgrind --tool=exp-dhat ./test得出的结果如下
==9121== ======== ORDERED BY decreasing "max-bytes-live": top 10 allocators ========
==9121==
==9121== -------------------- 1 of 10 --------------------
==9121== max-live: 102,400 in 1 blocks
==9121== tot-alloc: 409,600 in 4 blocks (avg size 102400.00)
==9121== deaths: 4, at avg age 35 (0.02% of prog lifetime)
==9121== acc-ratios: 0.00 rd, 0.00 wr (0 b-read, 0 b-written)
==9121== at 0x4C2DECF: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==9121== by 0x10870F: create (test.c:4)
==9121== by 0x108726: create_destory (test.c:8)
==9121== by 0x10882C: main (test.c:25)
==9121==
==9121== -------------------- 2 of 10 --------------------
==9121== max-live: 40,960 in 4 blocks
==9121== tot-alloc: 40,960 in 4 blocks (avg size 10240.00)
==9121== deaths: none (none of these blocks were freed)
==9121== acc-ratios: 0.00 rd, 0.00 wr (0 b-read, 0 b-written)
==9121== at 0x4C2DECF: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==9121== by 0x10870F: create (test.c:4)
==9121== by 0x1087EE: main (test.c:19)
==9121==
==9121== -------------------- 3 of 10 --------------------
==9121== max-live: 40,960 in 4 blocks
==9121== tot-alloc: 40,960 in 4 blocks (avg size 10240.00)
==9121== deaths: 4, at avg age 454 (0.32% of prog lifetime)
==9121== acc-ratios: 0.00 rd, 0.00 wr (0 b-read, 0 b-written)
==9121== at 0x4C2DECF: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==9121== by 0x108808: main (test.c:22)
==9121==
==9121==
==9121==
==9121== ==============================================================
第4到11行显示了create_destory方法导致堆变化的信息。
第4行意思是分配的最大一个区块大小是100K。
第5行意思是一共分配了4个区块,一共400K,平均每个区块100K。
第6行意思是释放了4次堆上空间,平均生命周期是35,占程序运行时间的0.02%。
第7行意思是这些区块被读写了0次,读写的空间也是0。
第8到11行是调用堆栈。
类似的我们可以解读14到20行(代码第19行的create)、23到28行(代码第22行的malloc)的信息。
我们注意下第16行信息,其意思是create方法申请的堆没有一次释放,所以释放的空间大小是0。这对我们动态分析程序执行比较有意义,可以借此检查相应代码是否发生了内存泄漏。
再注意下第6行和第25行,可以看到create_destory和main中直接malloc申请的堆的生命周期分别占比是0.02%和0.32%。这也是符合我们代码的设计的,因为create_destory方法申请的空间立即被释放掉了,所以它们的生命周期短点。而main中第22行malloc的空间存在一段时间之后才在第29行被释放掉,所以它们的生命周期长点。这个信息也非常有意义。因为一个函数申请的堆频繁被快速释放,其表现就是它们的生命周期变短,那么此时使用堆是否合适,或者说这种频繁释放堆空间的行为是否合适?
最后我们注意下第7,17和26行,它们显示这些堆被读写的情况。这个信息也非常重要。因为通过读写情况可以分析出堆空间的特点,比如是读多还是写多,这在多线程编程下,可能可以优化堆中存储的结构或者管理这段堆的锁粒度。还可以通过读写情况分析出这个堆空间是否存在不被使用的情况,从而可以优化掉对应的代码。或者通过对堆数据写入的多少,来分析申请这么大的空间是否合适。
现在我们开始以观察到的现象来分析和优化代码。
频繁申请和释放堆
现象如下
==10111== -------------------- 1 of 10 --------------------
==10111== max-live: 1,024 in 1 blocks
==10111== tot-alloc: 4,096 in 4 blocks (avg size 1024.00)
==10111== deaths: 4, at avg age 170 (0.12% of prog lifetime)
==10111== acc-ratios: 0.00 rd, 1.06 wr (0 b-read, 4,352 b-written)
==10111== at 0x4C2DECF: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==10111== by 0x108703: main (test.c:8)
这段信息显示:一共申请的4个堆空间生命周期只占比0.12%——非常低。被申请的空间只被写入,从来没被读取过。堆空间的使用率(当前只有写操作)也不高,只有1.06次写入(4352/4096)。我们看下代码
#include <stdlib.h>
#include <string.h>int main(void) {const int loop_count = 4;const unsigned int kilo = 1024;for (int i = 0; i < loop_count; i++) {char* buf = malloc(kilo);memset(buf, 'a', kilo);free(buf);}return 0;
}
第8行申请的堆,在第9行被使用后,立即被第10行释放掉。频繁申请和释放堆会造成内存碎片等问题,所以一般我们都是希望堆的使用率是是比较高的。发现和定位问题后,我们可以做如下改动
#include <stdlib.h>
#include <string.h>int main(void) {const int loop_count = 4;const unsigned int kilo = 1024;char* buf = malloc(kilo);for (int i = 0; i < loop_count; i++) {memset(buf, 'a', kilo);}free(buf);return 0;
}
得到如下分析结果
==10119== max-live: 1,024 in 1 blocks
==10119== tot-alloc: 1,024 in 1 blocks (avg size 1024.00)
==10119== deaths: 1, at avg age 602 (0.43% of prog lifetime)
==10119== acc-ratios: 0.00 rd, 4.25 wr (0 b-read, 4,352 b-written)
==10119== at 0x4C2DECF: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==10119== by 0x1086FA: main (test.c:7)
可以发现堆的生命周期提高到了0.43%,使用率提高到了4.25。
使用堆是否合理
上面例子也没必要使用堆,我们可以把其变成栈上空间,这样执行效率更高。
#include <stdlib.h>
#include <string.h>int main(void) {const int loop_count = 4;const unsigned int kilo = 1024;char buf[kilo];for (int i = 0; i < loop_count; i++) {memset(buf, 'a', kilo);}return 0;
}是否有没有使用的堆
没有使用的堆是指:堆空间被申请出来,但是没有对其进行过读写操作。我们看个现象
==10309== -------------------- 1 of 10 --------------------
==10309== max-live: 1,024 in 1 blocks
==10309== tot-alloc: 1,024 in 1 blocks (avg size 1024.00)
==10309== deaths: 1, at avg age 664 (0.47% of prog lifetime)
==10309== acc-ratios: 0.00 rd, 4.25 wr (0 b-read, 4,352 b-written)
==10309== at 0x4C2DECF: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==10309== by 0x1086FA: main (test.c:7)
==10309== -------------------- 2 of 10 --------------------
==10309== max-live: 1,024 in 1 blocks
==10309== tot-alloc: 1,024 in 1 blocks (avg size 1024.00)
==10309== deaths: 1, at avg age 602 (0.43% of prog lifetime)
==10309== acc-ratios: 0.00 rd, 0.00 wr (0 b-read, 0 b-written)
==10309== at 0x4C2DECF: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==10309== by 0x108709: main (test.c:8)
第5行显示这个堆被写入过,第12行显示这个堆从来没有被读写过。这样我们就需要怀疑test.c的第8行申请的空间是否必要。看下代码,可以发现这个堆的确没必要申请。
#include <stdlib.h>
#include <string.h>int main(void) {const int loop_count = 4;const unsigned int kilo = 1024;char* buf = malloc(kilo);char* unused = malloc(kilo);for (int i = 0; i < loop_count; i++) {memset(buf, 'a', kilo);}free(unused);free(buf);return 0;
}
申请的大小是否合理
有时候,我们并不是那么节约。比如一个只需要1K的空间,我们可能申请了10K。但是这个单纯的靠梳理代码可能比较难以发现。我们看个分析结果
==10571== -------------------- 1 of 10 --------------------
==10571== max-live: 1,024 in 1 blocks
==10571== tot-alloc: 1,024 in 1 blocks (avg size 1024.00)
==10571== deaths: 1, at avg age 134 (0.09% of prog lifetime)
==10571== acc-ratios: 0.00 rd, 0.00 wr (0 b-read, 8 b-written)
==10571== at 0x4C2DECF: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==10571== by 0x1086AA: main (test.c:7)
==10571==
==10571== Aggregated access counts by offset:
==10571==
==10571== [ 0] 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0
==10571== [ 16] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
==10571== [ 32] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
==10571== [ 48] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 从第9行开始,显示的是该堆每个字节被访问的次数。我们看到只有前8个字节被访问了1次。但是剩余的其他字节都没有被访问过。于是我们看下代码
#include <stdlib.h>
#include <string.h>int main(void) {const int loop_count = 8;const unsigned int kilo = 1024;char* buf = malloc(kilo);for (int i = 0; i < loop_count; i++) {buf[i] = 'a' + i;}free(buf);return 0;
}
可以看到,第8到10行的确只操作了前8个字节。所以我们没必要申请1K的空间。
相关文章:

cisco2950交换机密码恢复
在实际工作中可能会忘记交换机密码,导致不能对交换机进行配置的情况。cisco提供了密码恢复的方法。以下是关于交换机密码恢复说明:如果忘记密码,这时我们如果要配置交换机就必须在启动时绕过config.text的配置【密码保存在config.text中】然后…
程序员SQL都不会?能干啥?资深研发:别再瞎努力了!
国外有人曾做过调查显示:“SQL的使用人数仅次于JavaScript”。更有统计,世界上一流的互联网公司中,排名前 20 的有 80% 都是 MySQL 的忠实用户。为什么这项技术仍有这么多人在用?又为什么值得我们学习?1、无论你是前端…
OC管理文件方法
1、常见的NSFileManager文件方法 -(NSData *)contentsAtPath:path //从一个文件读取数据 -(BOOL)createFileAtPath: path contents:(NSData *)data attributes:attr //向一个文件写入数据 -(BOOL)removeItemAtPath:path error:err //删除一个文件 -(BOOL)moveItemAtPa…

堆状态分析的利器——gperftools的Heap Profiler
在《内存泄漏分析的利器——gperftools的Heap Checker》一文中,我们介绍了如何使用gperftools分析内存泄漏。本文将介绍其另一个强大的工具——Heap Profiler去分析堆的变化过程。(转载请指明出于breaksoftware的csdn博客) 我们使用类似于《堆…

亲戚称呼关系表
直系血亲父系曾曾祖父--曾祖父--祖父--父亲曾曾祖母--曾祖母--祖母--父亲母系曾曾外祖父--曾外祖父--外祖父--母亲曾曾外祖母--曾外祖母--外祖母--母亲儿子:夫妻间男性的第一子代。女儿:夫妻间女性的第一子代。孙:夫妻间的第二子代࿰…
技术驰援抗疫一线, Python 线上峰会免费学!
截至截止2月9号24时,新型冠状病毒在全国已确诊42714例,疑似病例已达21675例。而专家所说的“拐点”始终未至,受疫的影响,各大公司开启远程办公模式,将返回工作场所办公的时间一延再延。在抗疫前线,中国医疗…
ZeroMq实现跨线程通信
ZeroMq实现跨线程通信 之前在技术崇拜的技术经理指导下阅读了ZeroMq的基础代码,现在就将阅读的心得与成果记录一下,并重新模仿实现了一下经理的异步队列。 1、对外接口 //主要接口(1)void *ymq_attach (void *ctx_, int oid, voi…
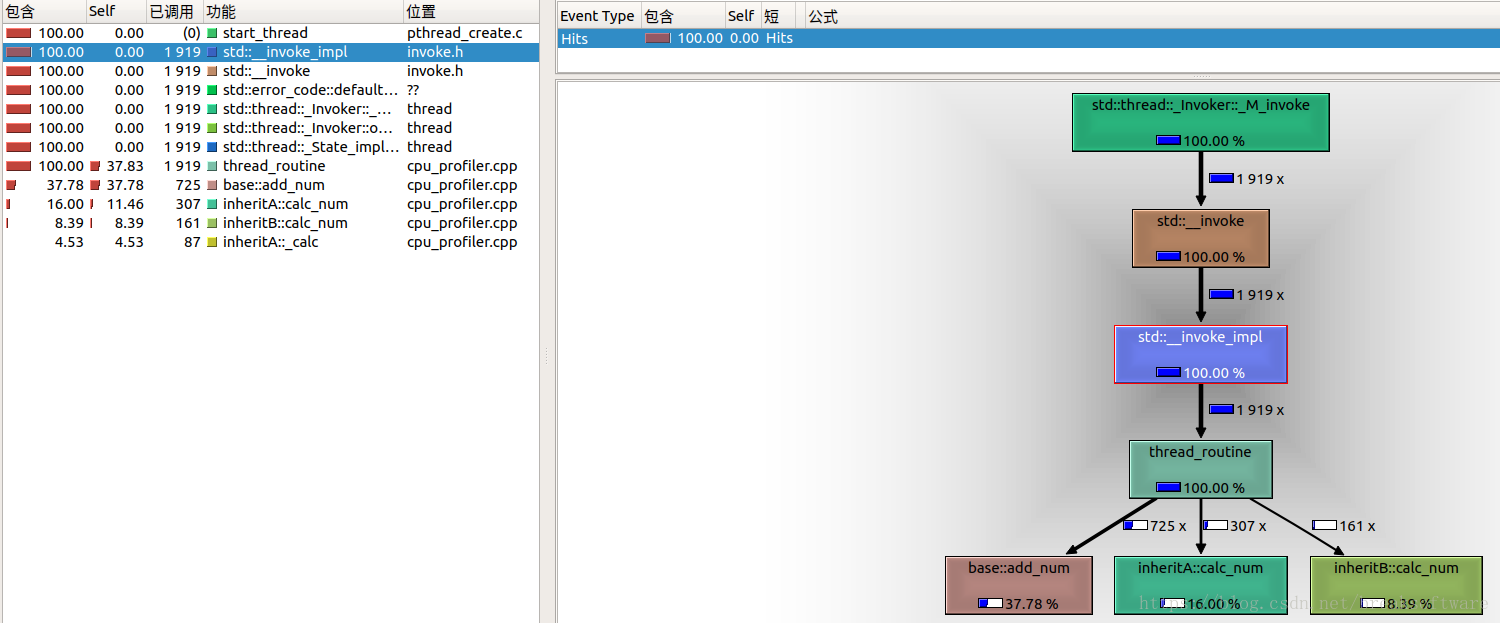
动态执行流程分析和性能瓶颈分析的利器——gperftools的Cpu Profiler
在《动态执行流程分析和性能瓶颈分析的利器——valgrind的callgrind》中,我们领略了valgrind对流程和性能瓶颈分析的强大能力。本文将介绍拥有相似能力的gperftools的Cpu Profiler。(转载请指明出于breaksoftware的csdn博客) 我们依然以callg…

C语言内存管理内幕(二)----半自动内存管理策略
2019独角兽企业重金招聘Python工程师标准>>> C语言内存管理内幕(二)----半自动内存管理策略 转载于:https://my.oschina.net/hengcai001/blog/466
无人机巡逻喊话、疫情排查、送药消毒,抗疫战中机器人化身钢铁战士!
整理 | 夕颜责编 | Carol出品 | CSDN(ID:CSDNnews)这场抗疫战争似乎格外漫长,但回头细数一下才发现,自疫情爆发以来,也不过半月之久。在接下来的几个半月中,抗疫战仍将继续,各方力量也要绷紧神经…
jQuery EasyUI 表单插件 - Datebox 日期框
为什么80%的码农都做不了架构师?>>> 扩展自 $.fn.combo.defaults。通过 $.fn.datebox.defaults 重写默认的 defaults。 日期框(datebox)把可编辑的文本框和下拉日历面板结合起来,用户可以从下拉日历面板中选择日期。在…
互斥量、读写锁长占时分析的利器——valgrind的DRD
在进行多线程编程时,我们可能会存在同时操作(读、写)同一份内存的可能性。为了保证数据的正确性,我们往往会使用互斥量、读写锁等同步方法。(转载请指明出于breaksoftware的csdn博客) 互斥量的用法如下 pth…
一次性同步修改多台linux服务器的密码
如何一次性修改多台linux服务器的密码,这是个问题,我给大家提供一个脚本,是前一段我刚刚写的,希望能对大家有所帮助一 , 需求:linux环境下运行,需要tcl和expect支持原理说明:利用expect的摸拟交互的功能&…
麻省理工学院的新系统TextFooler, 可以欺骗Google的自然语言处理系统及Google Home的音频...
来源 | news.mit编译 | 武明利责编 | Carol出品 | AI科技大本营(ID:rgznai100)两年前,Google的AI还不太成熟。一段时间以来,有一部分计算机科学研究一直致力于更好地理解机器学习模型如何处理这些“对抗性”攻击,这些攻…
Oracle VS DB2 数据类型
Oracle VS DB2 本文转自:http://www.bitscn.com/oracle/install/200604/16541.html首先,通过下表介绍ORACLE与DB2/400数据类型之间的对应关系,是一对多的关系,具体采用哪种对应关系,应具体问题具体分析。 OracleDB2/40…
死锁问题分析的利器——valgrind的DRD和Helgrind
在《DllMain中不当操作导致死锁问题的分析--死锁介绍》一文中,我们介绍了死锁产生的原因。一般来说,如果我们对线程同步技术掌握不牢,或者同步方案混乱,极容易导致死锁。本文我们将介绍如何使用valgrind排查死锁问题。(…
疫情可视化,基于知识图谱的AI“战疫”平台如何做?
来源 | DataExa渊亭科技武汉封城半个月,疫情依然严峻。但与17年前的SARS相比,我国在此次疫情防控工作中展现出了更高的医疗救治水平、更快的防疫反应速度、更透明的信息披露机制、更迅速的数据报送机制。在这场没有硝烟的战役中,社会各界团结…
mysql乐观锁总结和实践
2019独角兽企业重金招聘Python工程师标准>>> 上一篇文章《MySQL悲观锁总结和实践》谈到了MySQL悲观锁,但是悲观锁并不是适用于任何场景,它也有它存在的一些不足,因为悲观锁大多数情况下依靠数据库的锁机制实现,以保证操…
数据竞争(data race)问题分析的利器——valgrind的Helgrind
数据竞争(data race)是指在非线程安全的情况下,多线程对同一个地址空间进行写操作。一般来说,我们都会通过线程同步方法来保证数据的安全,比如采用互斥量或者读写锁。但是由于某些笔误或者设计的缺陷,还是存…
sql charindex函数
CHARINDEX函数返回字符或者字符串在另一个字符串中的起始位置。CHARINDEX函数调用方法如下: CHARINDEX ( expression1 , expression2 [ , start_location ] ) Expression1是要到expression2中寻找的字符中,start_location是CHARINDEX函数开始在expressi…
170亿参数加持,微软发布史上最大Transformer模型
来源 | 微软译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)Turing Natural Language Generation(T-NLG)是微软提供的一个有170亿参数的语言模型,在许多NLP任务上均优于目前的SOTA技术。我们向学者演示了该模型…
iOS 开发 OC编程 数组冒泡排序.图书管理
// // main.m // oc -5 数组 // // Created by dllo on 15/10/28. // Copyright (c) 2015年 dllo. All rights reserved. // #import <Foundation/Foundation.h> #import "Student.h" #import "Book.h" int main(int argc, const char * argv[])…
C#中使用Monitor类、Lock和Mutex类来同步多线程的执行(转)
C#中使用Monitor类、Lock和Mutex类来同步多线程的执行 在多线程中,为了使数据保持一致性必须要对数据或是访问数据的函数加锁,在数据库中这是很常见的,但是在程序中由于大部分都是单线程的程序,所以没有加锁的必要,但是…
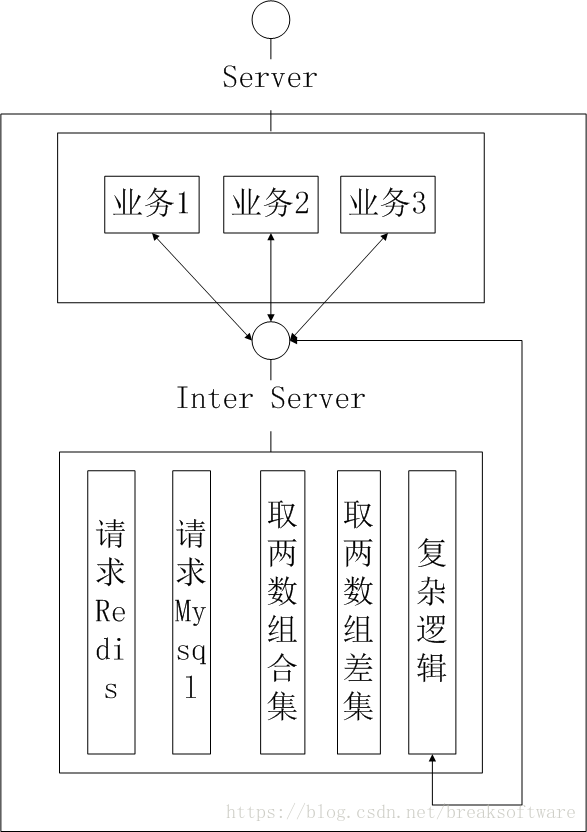
从0开始搭建编程框架——思考
需求来源于问题。(转载请指明出于breaksoftware的csdn博客) 之前有个人做前端开发的同学在群里问“C语言能做什么?能写网页么?”,然后大家就开始基于这个问题展开争辩。有的认为是“不能,从来没听说过C语言…
2月15日Python线上峰会免费学!6场精华分享,用代码“抗”疫
截至截止2月12号09时43分,新型冠状病毒在全国已确诊44726例,疑似病例已达21675例。而专家所说的“拐点”始终未至,受疫的影响,各大公司开启远程办公模式,将返回工作场所办公的时间一延再延。在抗疫前线,中国…

C#语言 数组
转载于:https://www.cnblogs.com/a849788087/p/4947939.html
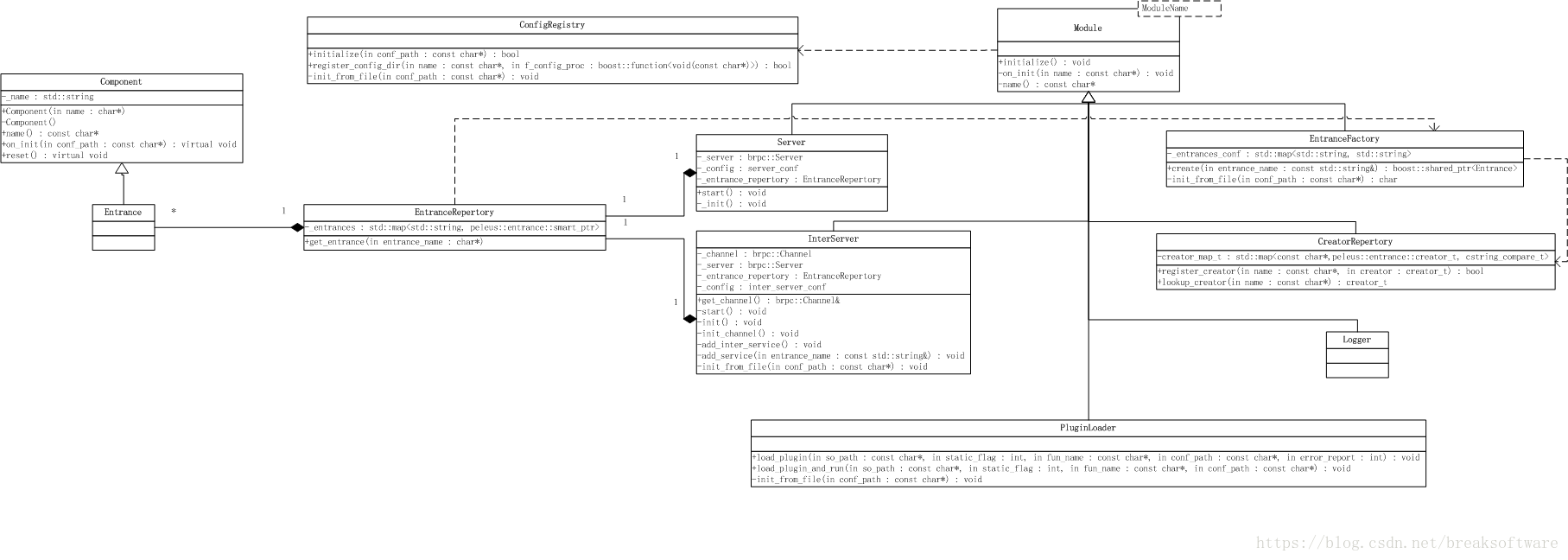
从0开始搭建编程框架——主框架和源码
一个良好的结构是“对修改关闭,对扩展开放”的。(转载请指明出于breaksoftware的csdn博客) 这个过程就像搭建积木。框架本身需要有足够的向内扩展能力以使自身有进化能力,其次要有足够的外向扩展能力以使其可以方便定制业务。一般…
中文版开源!这或许是最经典的Python编程教材
整理 | AI科技大本营(ID:rgznai100)想入门Python,但一直没找到合适的参考书籍?《Think Python》是很多Python初学者的不二入门教材,受到广泛好评。该书原作者是美国Olin工程学院的教授Allen B. Downey,目前…
[流水账]毕业?工作?
离正常毕业时间还有1年多, 没想到这么早就开始感受到毕业的气息了. 前几天收到去参加IBM中国研究院校友座谈会的邀请, 因为有事没过去, 今天又接到了校友蒋师兄的电话来了解我的个人情况. 接到电话时蒋师兄先核对了一下信息, 然后要我介绍一下自己, 我做事一向比较谨慎, 对涉及…
Java并发编程-信号量
Semaphore 直译是信号量,它的功能比较好理解,就是通过构造函数设定一个数量的许可,然后通过 acquire 方法获得许可,release 方法释放许可。它还有 tryAcquire 和 acquireUninterruptibly 方法,可以根据自己的需要选择。…