Python在计算内存时值得注意的几个问题
作者 | 豌豆花下猫
来源 | python猫(ID:python_cat)
我之前的一篇文章,带大家揭晓了 Python 在给内置对象分配内存时的 5 个奇怪而有趣的小秘密。文中使用了sys.getsizeof()来计算内存,但是用这个方法计算时,可能会出现意料不到的问题。
文档中关于这个方法的介绍有两层意思:
该方法用于获取一个对象的字节大小(bytes)
它只计算直接占用的内存,而不计算对象内所引用对象的内存
也就是说,getsizeof() 并不是计算实际对象的字节大小,而是计算“占位对象”的大小。如果你想计算所有属性以及属性的属性的大小,getsizeof() 只会停留在第一层,这对于存在引用的对象,计算时就不准确。
例如列表 [1,2],getsizeof() 不会把列表内两个元素的实际大小算上,而只是计算了对它们的引用。举一个形象的例子,我们把列表想象成一个箱子,把它存储的对象想象成一个个球,现在箱子里有两张纸条,写上了球 1 和球 2 的地址(球不在箱子里),getsizeof() 只是把整个箱子称重(含纸条),而没有根据纸条上地址,找到两个球一起称重。
计算的是什么?
我们先来看看列表对象的情况:
如图所示,单独计算 a 和 b 列表的结果是 36 和 48,然后把它们作为 c 列表的子元素时,该列表的计算结果却仅仅才 36。(PS:我用的是 32 位解释器)
如果不使用引用方式,而是直接把子列表写进去,例如 “d = [[1,2],[1,2,3,4,5]]”,这样计算 d 列表的结果也还是 36,因为子列表是独立的对象,在 d 列表中存储的是它们的 id。
也就是说:getsizeof() 方法在计算列表大小时,其结果跟元素个数相关,但跟元素本身的大小无关。
下面再看看字典的例子:
明显可以看出,三个字典实际占用的全部内存不可能相等,但是 getsizeof() 方法给出的结果却相同,这意味着它只关心键的数量,而不关心实际的键值对是什么内容,情况跟列表相似。
“浅计算”与其它问题
有个概念叫“浅拷贝”,指的是 copy() 方法只拷贝引用对象的内存地址,而非实际的引用对象。类比于这个概念,我们可以认为 getsizeof() 是一种“浅计算”。
“浅计算”不关心真实的对象,所以其计算结果只是一个假象。这是一个值得注意的问题,但是注意到这点还不够,我们还可以发散地思考如下的问题:
“浅计算”方法的底层实现是怎样的?
为什么 getsizeof() 会采用“浅计算”的方法?
关于第一个问题,getsizeof(x) 方法实际会调用 x 对象的__sizeof__() 魔术方法,对于内置对象来说,这个方法是通过 CPython 解释器实现的。
我查到这篇文章《Python中对象的内存使用(一)》,它分析了 CPython 源码,最终定位到的核心代码是这一段:
/*longobject.c*/static Py_ssize_t
int___sizeof___impl(PyObject *self)
{Py_ssize_t res;res = offsetof(PyLongObject, ob_digit) + Py_ABS(Py_SIZE(self))*sizeof(digit);return res;
}我看不懂这段代码,但是可以知道的是,它在计算 Python 对象的大小时,只跟该对象的结构体的属性相关,而没有进一步作“深度计算”。
对于 CPython 的这种实现,我们可以注意到两个层面上的区别:
字节增大:int 类型在 C 语言中只占到 4 个字节,但是在 Python 中,int 其实是被封装成了一个对象,所以在计算其大小时,会包含对象结构体的大小。在 32 位解释器中,getsizeof(1) 的结果是 14 个字节,比数字本身的 4 字节增大了。
字节减少:对于相对复杂的对象,例如列表和字典,这套计算机制由于没有累加内部元素的占用量,就会出现比真实占用内存小的结果。
由此,我有一个不成熟的猜测:基于“一切皆是对象”的设计原则,int 及其它基础的 C 数据类型在 Python 中被套上了一层“壳”,所以需要一个方法来计算它们的大小,也即是 getsizeof()。
官方文档中说“All built-in objects will return correct results” [1],指的应该是数字、字符串和布尔值之类的简单对象。但是不包括列表、元组和字典等在内部存在引用关系的类型。
为什么不推广到所有内置类型上呢?我未查到这方面的解释,若有知情的同学,烦请告知。
“深计算”与其它问题
与“浅计算”相对应,我们可以定义出一种“深计算”。对于前面的两个例子,“深计算”应该遍历每个内部元素以及可能的子元素,累加计算它们的字节,最后算出总的内存大小。
那么,我们应该注意的问题有:
是否存在“深计算”的方法/实现方案?
实现“深计算”时应该注意什么?
Stackoverflow 网站上有个年代久远的问题“How do I determine the size of an object in Python?” [2],实际上问的就是如何实现“深计算”的问题。
有不同的开发者贡献了两个项目:pympler 和 pysize :第一个项目已发布在 Pypi 上,可以“pip install pympler”安装;第二个项目烂尾了,作者也没发布到 Pypi 上(注:Pypi 上已有个 pysize 库,是用来做格式转化的,不要混淆),但是可以在 Github 上获取到其源码。
对于前面的两个例子,我们可以拿这两个项目分别测试一下:
单看数值的话,pympler 似乎确实比 getsizeof() 合理多了。
再看看 pysize,直接看测试结果是(获取其源码过程略):
64
118
190
206
300281
30281可以看出,它比 pympler 计算的结果略小。就两个项目的完整度、使用量与社区贡献者规模来看,pympler 的结果似乎更为可信。
那么,它们分别是怎么实现的呢?那微小的差异是怎么导致的?从它们的实现方案中,我们可以学习到什么呢?
pysize 项目很简单,只有一个核心方法:
def get_size(obj, seen=None):"""Recursively finds size of objects in bytes"""size = sys.getsizeof(obj)if seen is None:seen = set()obj_id = id(obj)if obj_id in seen:return 0# Important mark as seen *before* entering recursion to gracefully handle# self-referential objectsseen.add(obj_id)if hasattr(obj, '__dict__'):for cls in obj.__class__.__mro__:if '__dict__' in cls.__dict__:d = cls.__dict__['__dict__']if inspect.isgetsetdescriptor(d) or inspect.ismemberdescriptor(d):size += get_size(obj.__dict__, seen)breakif isinstance(obj, dict):size += sum((get_size(v, seen) for v in obj.values()))size += sum((get_size(k, seen) for k in obj.keys()))elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)):size += sum((get_size(i, seen) for i in obj))if hasattr(obj, '__slots__'): # can have __slots__ with __dict__size += sum(get_size(getattr(obj, s), seen) for s in obj.__slots__ if hasattr(obj, s))return size除去判断__dict__和 __slots__属性的部分(针对类对象),它主要是对字典类型及可迭代对象(除字符串、bytes、bytearray)作递归的计算,逻辑并不复杂。
以 [1,2] 这个列表为例,它先用 sys.getsizeof() 算出 36 字节,再计算内部的两个元素得 14*2=28 字节,最后相加得到 64 字节。
相比之下,pympler 所考虑的内容要多很多,入口在这:
def asizeof(self, *objs, **opts):'''Return the combined size of the given objects(with modified options, see method **set**).'''if opts:self.set(**opts)self.exclude_refs(*objs) # skip refs to objsreturn sum(self._sizer(o, 0, 0, None) for o in objs)它可以接受多个参数,再用 sum() 方法合并。所以核心的计算方法其实是 _sizer()。但代码很复杂,绕来绕去像一座迷宫:
def _sizer(self, obj, pid, deep, sized): # MCCABE 19'''Size an object, recursively.'''s, f, i = 0, 0, id(obj)if i not in self._seen:self._seen[i] = 1elif deep or self._seen[i]:# skip obj if seen before# or if ref of a given objself._seen.again(i)if sized:s = sized(s, f, name=self._nameof(obj))self.exclude_objs(s)return s # zeroelse: # deep == seen[i] == 0self._seen.again(i)try:k, rs = _objkey(obj), []if k in self._excl_d:self._excl_d[k] += 1else:v = _typedefs.get(k, None)if not v: # new typedef_typedefs[k] = v = _typedef(obj, derive=self._derive_,frames=self._frames_,infer=self._infer_)if (v.both or self._code_) and v.kind is not self._ign_d:# 猫注:这里计算 flat sizes = f = v.flat(obj, self._mask) # flat sizeif self._profile:# profile based on *flat* sizeself._prof(k).update(obj, s)# recurse, but not for nested modulesif v.refs and deep < self._limit_ \and not (deep and ismodule(obj)):# add sizes of referentsz, d = self._sizer, deep + 1if sized and deep < self._detail_:# use named referentsself.exclude_objs(rs)for o in v.refs(obj, True):if isinstance(o, _NamedRef):r = z(o.ref, i, d, sized)r.name = o.nameelse:r = z(o, i, d, sized)r.name = self._nameof(o)rs.append(r)s += r.sizeelse: # just size and accumulatefor o in v.refs(obj, False):# 猫注:这里递归计算 item sizes += z(o, i, d, None)# deepest recursion reachedif self._depth < d:self._depth = dif self._stats_ and s > self._above_ > 0:# rank based on *total* sizeself._rank(k, obj, s, deep, pid)except RuntimeError: # XXX RecursionLimitExceeded:self._missed += 1if not deep:self._total += s # accumulateif sized:s = sized(s, f, name=self._nameof(obj), refs=rs)self.exclude_objs(s)return s它的核心逻辑是把每个对象的 size 分为两部分:flat size 和 item size。
计算 flat size 的逻辑在:
def flat(self, obj, mask=0):'''Return the aligned flat size.'''s = self.baseif self.leng and self.item > 0: # include itemss += self.leng(obj) * self.item# workaround sys.getsizeof (and numpy?) bug ... some# types are incorrectly sized in some Python versions# (note, isinstance(obj, ()) == False)# 猫注:不可 sys.getsizeof 的,则用上面逻辑,可以的,则用下面逻辑if not isinstance(obj, _getsizeof_excls):s = _getsizeof(obj, s)if mask: # aligns = (s + mask) & ~maskreturn s这里出现的 mask 是为了作字节对齐,默认值是 7,该计算公式表示按 8 个字节对齐。对于 [1,2] 列表,会算出 (36+7)&~7=40 字节。同理,对于单个的 item,比如列表中的数字 1,sys.getsizeof(1) 等于 14,而 pympler 会算成对齐的数值 16,所以汇总起来是 40+16+16=72 字节。这就解释了为什么 pympler 算的结果比 pysize 大。
字节对齐一般由具体的编译器实现,而且不同的编译器还会有不同的策略,理论上 Python 不应关心这么底层的细节,内置的 getsizeof() 方法就没有考虑字节对齐。
在不考虑其它 edge cases 的情况下,可以认为 pympler 是在 getsizeof() 的基础上,既考虑了遍历取引用对象的 size,又考虑到了实际存储时的字节对齐问题,所以它会显得更加贴近现实。
 小结
小结
getsizeof() 方法的问题是显而易见的,我创造了一个“浅计算”概念给它。这个概念借鉴自 copy() 方法的“浅拷贝”,同时对应于 deepcopy() “深拷贝”,我们还能推理出一个“深计算”。
前面展示了两个试图实现“深计算”的项目(pysize+pympler),两者在浅计算的基础上,深入地求解引用对象的大小。pympler 项目的完整度较高,代码中有很多细节上的设计,比如字节对齐。
Python 官方团队当然也知道 getsizeof() 方法的局限性,他们甚至在文档中加了一个链接 [3],指向了一份实现深计算的示例代码。那份代码比 pysize 还要简单(没有考虑类对象的情况)。
未来 Python 中是否会出现深计算的方法,假设命名为 getdeepsizeof() 呢?这不得而知了。
本文的目的是加深对 getsizeof() 方法的理解,区分浅计算与深计算,分析两个深计算项目的实现思路,指出几个值得注意的问题。
相关链接
Python 内存分配时的小秘密:https://dwz.cn/AoSdCZfo
Python中对象的内存使用(一):https://dwz.cn/SXGtXklz
[1] https://dwz.cn/yxg72lyS
[2] https://dwz.cn/5m83JStN
[3] https://code.activestate.com/recipes/577504
作者简介:豌豆花下猫,生于广东毕业于武大,现为苏漂程序员,有一些极客思维,也有一些人文情怀,有一些温度,还有一些态度。
【end】
◆
精彩推荐
◆
在这次疫情防控中,无感人体测温系统发挥了怎样的作用?它的技术原理是什么?无感人体测温系统的应用场景中有哪些关键技术与落地困难?高精准的无感人体测温系统的核心技术武器是什么?对于开发者们来说,大家应该了解哪些技术?
本周四晚八点,澎思科技智能安防行业解决方案副总监带来的直播《疫情防控天网:云端边下的全栈AI技术与应用》。扫描二维码或者点击阅读原文即刻报名。
推荐阅读
机器会成为神吗?
6个步骤,告诉你如何用树莓派和机器学习DIY一个车牌识别器!(附详细分析)
微信回应钉钉健康码无法访问;谷歌取消年度I/O开发者大会;微软公布Visual Studio最新路线图
什么是CD管道?一文告诉你如何借助Kubernetes、Ansible和Jenkins创建CD管道!
智能合约初探:概念与演变
血亏 1.5 亿元!微盟耗时 145 个小时弥补删库
你点的每个“在看”,我都认真当成了AI
相关文章:

HDU 1816, POJ 2723 Get Luffy Out(2-sat)
HDU 1816, POJ 2723 Get Luffy Out 题目链接 题意:N串钥匙。每串2把,仅仅能选一把。然后有n个大门,每一个门有两个锁,开了一个就能通过,问选一些钥匙,最多能通过多少个门 思路:二分通…
AI战“疫“之路:揭秘高精准无感测温系统的全栈AI 技术
在这个全民抗疫的特殊时期,今年的春节返潮来得比往年迟了许多。如今不少企业结束了远程办公,开始陆续复工,一时间,无论是重点防控的机场、火车站,还是学校、企业、社区等密集型场所,都安排了密集的防疫驻扎…

关于text段、data段和bss段
根据APUE,程序分为下面的段:.text, data (initialized), bss, stack, heap。 data/bss/text: text段在内存中被映射为只读,但.data和.bss是可写的。 bss是英文Block Started by Symbol的简称,通常是指用来存放程序中未初始化的全局…
091023 T GIX4 项目中的 智能部署 和 智能客户端
先说一下ClickOnce的使用方法:先给一个要发布的工程设置安全和签名。然后发布到iis中。当用户访问该iis目录下的.application文件时,就会自动安装整个应用程序。 再说一下我们目前的应用程序。相对还是比较复杂的,分为框架部分和特定应用程序部分。其中的…
STL学习系列九:Map和multimap容器
1.map/multimap的简介 map是标准的关联式容器,一个map是一个键值对序列,即(key,value)对。它提供基于key的快速检索能力。map中key值是唯一的。集合中的元素按一定的顺序排列。元素插入过程是按排序规则插入,所以不能指定插入位置。map的具体…
人工智能改变未来教育的5大方式!
作者 | Zohaib翻译 | 天道酬勤,编辑 | Carol出品 | AI科技大本营(ID:rgznai100)科技正在改变着我们的生活、工作和娱乐方式,教育领域也不例外。 人工智能将像大多数其他领域一样全面改变教育领域,这取决于当…

程序在内存中运行的奥秘
简介当丰富多彩的应用程序在计算机上运行,为你每天的工作和生活带来便利时,你是否知道它们是如何在计算机中工作呢?本文用形象的图表与生动的解释,揭示了程序在计算机中运行的奥秘。 内存管理是操作系统的核心功能,无论…
微软虚拟化解决方案课件
微软虚拟化解决方案课件转载于:https://blog.51cto.com/yangzhiguo/231577

【Python 第8课】while
2019独角兽企业重金招聘Python工程师标准>>> 先介绍一个新东西:注释。python里,以“#”开头的文字都不会被认为是可执行的代码。 print “hello world”和 print "hello world" #输出一行字是同样的效果。但后者可以帮助开发者更…
2019年度CSDN博客之星TOP10榜单揭晓,你上榜了吗?
培根说,『读书造成充实的人,会议造成未能觉悟的人,写作造成正确的人』。在短信短视频快速迭代的快时代,更深度的思考、更正确的实践,更成体系的写作与分享,尤显可贵。这里,每一篇博文都是开发者…

objdump查看目标文件构成
objdump objdump是用查看目标文件或者可执行的目标文件的构成的GCC工具 反汇编 #objdump -d cpuid2 对于其中的反汇编代码 左边是机器指令的字节,右边是反汇编结果。显然,所有的符号都被替换成地址了, 注意没有加$的数表示内存地址&#…

jQuery--AJAX传递xml
程序代码$.ajax({ url:Accept.jsp, type:post, //数据发送方式 dataType: xml, //注意这里是xml哦 ,不是html ( html比较简单,所以我拿xml做下例子,解释下 )data:text$("#name").val()&datenewDate(), //要传递的数据 timeout: 2000, …
ActionDescriptor 的认识
ActionDescriptor的作用是对Action方法的元数据的描述,通过ActionDescriptor我们可以获取到action方法的相关的名称,所属控制器,方法的参数列表,应用到方法上的特性以及一些筛选器;ActionDescriptor是由ControllerDescriptor类中的FindAction方法进行创建; ActionDescriptor类也…

readelf和ldd分析elf文件
1. elf 文件格式 linux系统中,gcc编译器编译出的object文件、可执行文件都属于elf文件。 elf文件由三个部分组成:elf header、program headers|section headers、sections|program segments。 如果是executable文件,则section部分是不需要的…
号称3个月发布最强量子计算机,卖口罩的霍尼韦尔凭什么?
作者 | Just出品 | AI科技大本营新冠疫情的发生,霍尼韦尔这家口罩品牌引入众人眼帘。但实际上,口罩业务只是这家企业的一小块副业,它能做的业务十分多元。3月4日,霍尼韦尔宣布在量子计算领域取得突破,将提升量子计算机…
一位老工程师前辈的忠告
诸位,咱当工程师也是十余年了,不算有出息,环顾四周,也没有看见几个有出息的!回顾工程师生涯,感慨万千,愿意讲几句掏心窝子的话,也算给咱们师弟师妹们提个醒,希望他们比咱…
一站式学习Wireshark
https://community.emc.com/message/818739#818739 转载于:https://blog.51cto.com/jackprivate/1725190
objdump与readelf
objdump和readelf都可以用来查看二进制文件的一些内部信息. 区别在于objdump 借助BFD而更加通用一些, 可以应付不同文件格式, readelf则并不借助BFD, 而是直接读取ELF格式文件的信息, 按readelf手册页上所说, 得到的信息也略细致一些. 几个功能对比. 1. 反汇编代码 查看源代…

接口学习笔记(2009.11.24)
了解接口,主要是为了一道经典面试题:接口与抽象类的区别,对接口的理解却很少,现在学习一下。 接口只包含方法、属性、事件或索引器的签名。成员的实现是在实现接口的类或结构中完成的。 Interfacenamespace study1124{ interfa…
“一网打尽”Deepfake等换脸图像,微软提出升级版鉴别技术Face X-Ray
作者 | Just出品 | AI科技大本营(ID:rgznai100)Deepfake换脸图像的泛滥给人类社会带来了巨大的挑战。虽然研究者们为检测换脸图片提出了多种AI鉴别算法,但随着换脸算法的不断改造升级,鉴别算法很难跟上换脸算法的变化。微软亚洲研…

双边滤波算法的简易实现bilateralFilter
没怎么看过双边滤波的具体思路,动手写一写,看看能不能突破一下。 最后,感觉算法还是要分开 水平 与 垂直 方向进行分别处理,才能把速度提上去。 没耐性写下去了,发上来,给大伙做个参考好了。 先上几张效果图…
赔偿谷歌1.8亿美元!前Uber自动驾驶主管被告到破产
整理 | Just出品 | AI科技大本营(ID:rgznai100)两年前的Google自动驾驶部门与Uber自动驾驶技术纠纷案以和解结束后再起波澜。据路透社等外媒报道,Uber自动驾驶部门前主管安东尼莱万多夫斯基(Anthony Levandowski)周三申…

.data和.text段合并
a.c #include <stdio.h> extern int share;int main(void) { int a100;swap(&a,&share);} b.c int share1;void swap(int *a,int *b){*a^*b^*a^*b;} 编译 #gcc -c a.c b.c 链接 #ld a.o b.o -e main -o ab 查看 #objdump -h 文件 VMA即虚拟地址 size即…
用QQ提问的技巧,用了之后可以提高效率,呵呵。
有些Tx喜欢用QQ向好友提些问题,但是却没有掌握提问的技巧,自己没有及时得到答案也浪费了对方的时间。这里抛砖引玉,说一下我的看法和体会。大家一起讨论。我们讨论问题,不讨论人。 一、 把QQ当成了电话(不适合的做法&a…
Android重绘ListView高度
Android重绘ListView高度 经常会有这样需求,需要ListView默认将所有的条目显示出来,这就需要外层使用ScrollView,ScrollView里面放置一个重绘高度的ListView,类似下面这样 工具类 package ……;import android.view.View; import …

C语言数据类型所占空间大小
C语言数据类型所占空间大小 /** datasize.c -- print the size of common data items* This runs with any Linux kernel (not any Unix, because of <linux/types.h>)** Copyright (C) 2001 Alessandro Rubini and Jonathan Corbet* Copyright (C) 2001 OReilly & A…
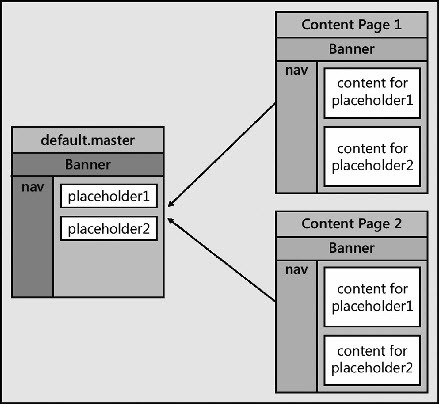
SharePoint基础之六- SharePoint基础架构中涉及的ASP.NET架构
ASP.NET框架代表着在IIS和ISAPI编程模型之上的一个重要的生产力层. 如果你熟悉ASP.NET开发的话, 你就会知道它为你的应用程序逻辑编写托管代码提供了便利, 比如说C#, VB.NET, 并且允许你在由Microsoft Visual Studio提供的面向生产力的可视化编辑器中工作. ASP.NET框架还提供了…
Javascript函数之深入浅出递归思想,附案例与代码!
作者 | 浮世万千吾爱有三责编 | Carol来源 | CSDN 博客递归函数的理解1、生活中的递归“递归”在生活中的一个典例就是“问路”。如图小哥哥进入电影院后找不到自己的座位,问身边的小姐姐“这是第几排”,小姐姐也不清楚便依次向前询问,问至第…
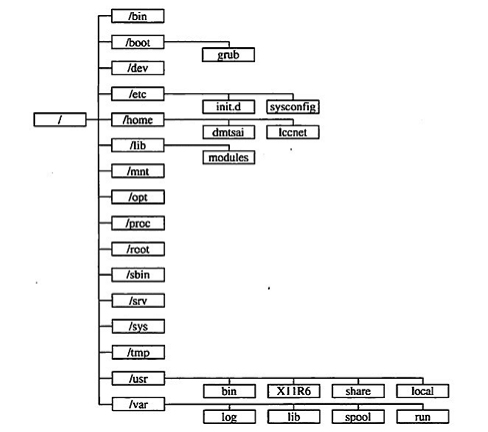
Linux指令--文件和目录属性
对于每一个Linux学习者来说,了解Linux文件系统的目录结构,是学好Linux的至关重要的一步.,深入了解linux文件目录结构的标准和每个目录的详细功能,对于我们用好linux系统只管重要,下面我们就开始了解一下linux目录结构的…

Linux内存寻址
一.内存地址分类以及MMU介绍 对于程序员来说,可以简单的把内存地址理解为一种访问存储单元的内容的一种方式。而对于80x86系列微处理器来说,我们需要区分三种地址: (1)逻辑地址 这种地址通常使用在机器语言里用于指…