浅谈无缓存I/O操作和标准I/O文件操作区别 (转载)
系统调用,英文名system call,每个操作系统都在内核里有一些内建的函数库,这些函数可以用来完成一些系统系统调用把应用程序的请求传给内核,调用相应的的内核函数完成所需的处理,将处理结果返回给应用程序,如果没有系统调用和内核函数,用户将不能编写大型应用程序,及别的功能,这些函数集合起来就叫做程序接口或应用编程接口(Application Programming Interface,API),我们要在这个系统上编写各种应用程序,就是通过这个API接口来调用系统内核里面的函数。如果没有系统调用,那么应用程序就失去内核的支持。
现在,再聊不带缓存的I/O操作:
1:不带缓存,不是直接对磁盘文件进行读取操作,像read()和write()函数,它们都属于系统调用,只不过在用户层没有缓存,所以叫做无缓存IO,但对于内核来说,还是进行了缓存,只是用户层看不到罢了。如果这一点看不懂,请看第二点;
2:带不带缓存是相对来说的,如果你要写入数据到文件上时(就是写入磁盘上),内核先将数据写入到内核中所设的缓冲储存器,假如这个缓冲储存器的长度是100个字节,你调用系统函:
ssize_t write (int fd,const void * buf,size_t count);
写操作时,设每次写入长度count=10个字节,那么你几要调用10次这个函数才能把这个缓冲区写满,此时数据还是在缓冲区,并没有写入到磁盘,缓冲区满时才进行实际上的IO操作,把数据写入到磁盘上,所以上面说的“不带缓存""不是没有缓存而是没有直写进磁盘就是这个意思
那么,既然不带缓存的操作实际在内核是有缓存器的,那带缓存的IO操作又是怎么回事呢?
带缓存IO也叫标准IO,符合ANSI C 的标准IO处理,不依赖系统内核,所以移植性强,我们使用标准IO操作很多时候是为了减少对read()和write()的系统调用次数,带缓存IO其实就是在用户层再建立一个缓存区,这个缓存区的分配和优化长度等细节都是标准IO库代你处理好了,不用去操心,还是用上面那个例子说明这个操作过程:
上面说要写数据到文件上,内核缓存(注意这个不是用户层缓存区)区长度是100字节,我们调用不带缓存的IO函数write()就要调用10次,这样系统效率低,现在我们在用户层建立另一个缓存区(用户层缓存区或者叫流缓存),假设流缓存的长度是50字节,我们用标准C库函数的fwrite()将数据写入到这个流缓存区里面,流缓存区满50字节后在进入内核缓存区,此时再调用系统函数write()将数据写入到文件(实质是磁盘)上,看到这里,你用该明白一点,标准IO操作fwrite()最后还是要掉用无缓存IO操作write,这里进行了两次调用fwrite()写100字节也就是进行两次系统调用write()。
如果看到这里还没有一点眉目的话,那就比较麻烦了,希望下面两条总结能够帮上忙:
无缓存IO操作数据流向路径:数据——内核缓存区——磁盘
标准IO操作数据流向路径:数据——流缓存区——内核缓存区——磁盘
下面是一个网友的见解,以供参考:
不带缓存的I/O对文件描述符操作,下面带缓存的I/O是针对流的。
标准I/O库就是带缓存的I/O,它由ANSI C标准说明。当然,标准I/O最终都会调用上面的I/O例程。标准I/O库代替用户处理很多细节,比如缓存分配、以优化长度执行I/O等。
标准I/O提供缓存的目的就是减少调用read和write的次数,它对每个I/O流自动进行缓存管理(标准I/O函数通常调用malloc来分配缓存)。它提供了三种类型的缓存:
1) 全缓存。当填满标准I/O缓存后才执行I/O操作。磁盘上的文件通常是全缓存的。
2) 行缓存。当输入输出遇到新行符或缓存满时,才由标准I/O库执行实际I/O操作。stdin、stdout通常是行缓存的。
3) 无缓存。相当于read、write了。stderr通常是无缓存的,因为它必须尽快输出。
一般而言,由系统选择缓存的长度,并自动分配。标准I/O库在关闭流的时候自动释放缓存。
在标准I / O库中,一个效率不高的不足之处是需要复制的数据量。当使用每次一行函数fgets和fputs时,通常需要复制两次数据:一次是在内核和标准I / O缓存之间(当调用read和write时),第二次是在标准I / O缓存(通常系统分配和管理)和用户程序中的行缓存(fgets的参数就需要一个用户行缓存指针)之间。
不管上面讲的到底懂没懂,记住一点:
使用标准I / O例程的一个优点是无需考虑缓存及最佳I / O长度的选择,并且它并不比直接调用read、write慢多少。
带缓存的文件操作是标准C 库的实现,第一次调用带缓存的文件操作函数时标准库会自动分配内存并且读出一段固定大小的内容存储在缓存中。所以以后每次的读写操作并不是针对硬盘上的文件直接进行的,而是针对内存中的缓存的。何时从硬盘中读取文件或者向硬盘中写入文件有标准库的机制控制。不带缓存的文件操作通常都是系统提供的系统调用,更加低级,直接从硬盘中读取和写入文件,由于 IO瓶颈的原因,速度并不如意,而且原子操作需要程序员自己保证,但使用得当的话效率并不差。另外标准库中的带缓存文件IO 是调用系统提供的不带缓存IO实现的。
这里为了说明标准I/O的工作原理,借用了glibc中标准I/O实现的细节,所以代码多是不可移植的.
1. buffered I/O, 即标准I/O
首先,要明确,unbuffered I/O只是相对于buffered I/O,即标准I/O来说的。而不是说unbuffered I/O读写磁盘时不用缓冲。实际上,内核是存在高速缓冲区来进行。真正的磁盘读写的,不过这里要讨论的buffer跟内核中的缓冲区无关.
buffered I/O的目的是什么呢?很简单,buffered I/O的目的就是为了提高效率.请明确一个关系,那就是:
buffered I/O库函数(fread, fwrite等,用户空间) <----call--->
buffered I/O库函数都是调用相关的unbuffered I/O系统调用来实现的,他们并不直接读写磁盘.那么,效率的提高从何而来呢?
注意到,buffered I/O中都是库函数,而unbuffered I/O中为系统调用,使用库函数的效率是高于使用系统调用的.buffered I/O就是通过尽可能的少使用系统调用来提高效率的.它的基本方法是,在用户进程空间维护一块缓冲区,第一次读(库函数)的时候用read(系统调用)多从内核读出一些数据,下次在要读(库函数)数据的时候,先从该缓冲区读,而不用进行再次read(系统调用)了.同样,写的时候,先将数据写入(库函数)一个缓冲区,多次以后,在集中进行一次write(系统调用),写入内核空间.
buffered I/O中的fgets, puts, fread, fwrite等和unbufferedI/O中的read,write等就是调用和被调用的关系
下面是一个利用buffered I/O读取数据的例子:
- #include <stdlib.h>
- #include <stdio.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- int main(void)
- {
- char buf[5];
- FILE *myfile = stdin;
- fgets(buf, 5, myfile);
- fputs(buf, myfile);
- return 0;
- }
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main(void)
{char buf[5];FILE *myfile = stdin;fgets(buf, 5, myfile);fputs(buf, myfile);return 0;
}要弄清楚这些问题,就要看看FILE是如何定义和运作的了.(特别说明,在平时写程序时,不用也不要关心FILE是如何定义和运作的,最好不要直接操作它,这里使用它,只是为了说明buffered IO)
下面的这个是glibc给出的FILE的定义,它是实现相关的,别的平台定义方式不同.
- struct _IO_FILE {
- int _flags;
- #define _IO_file_flags _flags
- char* _IO_read_ptr;
- char* _IO_read_end;
- char* _IO_read_base;
- char* _IO_write_base;
- char* _IO_write_ptr;
- char* _IO_write_end;
- char* _IO_buf_base;
- char* _IO_buf_end;
- char *_IO_save_base;
- char *_IO_backup_base;
- char *_IO_save_end;
- struct _IO_marker *_markers;
- struct _IO_FILE *_chain;
- int _fileno;
- };
struct _IO_FILE {int _flags; #define _IO_file_flags _flagschar* _IO_read_ptr;char* _IO_read_end;char* _IO_read_base;char* _IO_write_base;char* _IO_write_ptr;char* _IO_write_end;char* _IO_buf_base;char* _IO_buf_end;char *_IO_save_base;char *_IO_backup_base;char *_IO_save_end;struct _IO_marker *_markers;struct _IO_FILE *_chain;int _fileno;
};1.char* _IO_read_ptr; char* _IO_read_end; char* _IO_read_base;
2.char* _IO_write_base; char* _IO_write_ptr; char* _IO_write_end;
3.char* _IO_buf_base; char* _IO_buf_end;
其中
_IO_read_base 指向"读缓冲区"
_IO_read_end
_IO_read_end - _IO_read_base "读缓冲区"的长度
_IO_write_base 指向"写缓冲区"
_IO_write_end 指向"写缓冲区"的末尾
_IO_write_end - _IO_write_base "写缓冲区"的长度
_IO_buf_base
_IO_buf_end
_IO_buf_end - _IO_buf_base "缓冲区"的长度
上面的定义貌似给出了3个缓冲区,实际上上面的_IO_read_base,_IO_write_base, _IO_buf_base都指向了同一个缓冲区.这个缓冲区跟上面程序中的char buf[5];没有任何关系.
他们在第一次buffered I/O操作时由库函数自动申请空间,最后由相应库函数负责释放.(再次声明,这里只是glibc的实现,别的实现可能会不同,后面就不再强调了)
请看下面的程序(这里给的是stdin,行缓冲的例子):
- #include <stdlib.h>
- #include <stdio.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- int main(void)
- {
- char buf[5];
- FILE *myfile =stdin;
- printf("before reading\n");
- printf("read buffer base %p\n", myfile->_IO_read_base);
- printf("read buffer length %d\n", myfile->_IO_read_end - myfile->_IO_read_base);
- printf("write buffer base %p\n", myfile->_IO_write_base);
- printf("write buffer length %d\n", myfile->_IO_write_end - myfile->_IO_write_base);
- printf("buf buffer base %p\n", myfile->_IO_buf_base);
- printf("buf buffer length %d\n", myfile->_IO_buf_end - myfile->_IO_buf_base);
- printf("\n");
- fgets(buf, 5, myfile);
- fputs(buf, myfile);
- printf("\n");
- printf("after reading\n");
- printf("read buffer base %p\n", myfile->_IO_read_base);
- printf("read buffer length %d\n", myfile->_IO_read_end - myfile->_IO_read_base);
- printf("write buffer base %p\n", myfile->_IO_write_base);
- printf("write buffer length %d\n", myfile->_IO_write_end - myfile->_IO_write_base);
- printf("buf buffer base %p\n", myfile->_IO_buf_base);
- printf("buf buffer length %d\n", myfile->_IO_buf_end - myfile->_IO_buf_base);
- return 0;
- }
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main(void)
{char buf[5];FILE *myfile =stdin;printf("before reading\n");printf("read buffer base %p\n", myfile->_IO_read_base);printf("read buffer length %d\n", myfile->_IO_read_end - myfile->_IO_read_base);printf("write buffer base %p\n", myfile->_IO_write_base);printf("write buffer length %d\n", myfile->_IO_write_end - myfile->_IO_write_base);printf("buf buffer base %p\n", myfile->_IO_buf_base);printf("buf buffer length %d\n", myfile->_IO_buf_end - myfile->_IO_buf_base);printf("\n");fgets(buf, 5, myfile);fputs(buf, myfile);printf("\n");printf("after reading\n");printf("read buffer base %p\n", myfile->_IO_read_base);printf("read buffer length %d\n", myfile->_IO_read_end - myfile->_IO_read_base);printf("write buffer base %p\n", myfile->_IO_write_base);printf("write buffer length %d\n", myfile->_IO_write_end - myfile->_IO_write_base);printf("buf buffer base %p\n", myfile->_IO_buf_base);printf("buf buffer length %d\n", myfile->_IO_buf_end - myfile->_IO_buf_base);return 0;
}上面的例子只是说明了buffered I/O缓冲区的存在,下面从全缓冲,行缓冲和无缓冲3个方面看一下buffered I/O是如何工作的.
1.1. 全缓冲
下面是APUE上的原话:
全缓冲"在填满标准I/O缓冲区后才进行实际的I/O操作.对于驻留在磁盘上的文件通常是由标准I/O库实施全缓冲的"书中这里"实际的I/O操作"实际上容易引起误导,这里并不是读写磁盘,而应该是进行read或write的系统调用
下面两个例子会说明这个问题
- #include <stdlib.h>
- #include <stdio.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- int main(void)
- {
- char buf[5];
- char *cur;
- FILE *myfile;
- myfile = fopen("bbb.txt", "r");
- printf("before reading, myfile->_IO_read_ptr: %d\n", myfile->_IO_read_ptr - myfile->_IO_read_base);
- fgets(buf, 5, myfile); //仅仅读4个字符
- cur = myfile->_IO_read_base;
- while (cur < myfile->_IO_read_end) //实际上读满了这个缓冲区
- {
- printf("%c",*cur);
- cur++;
- }
- printf("\nafter reading, myfile->_IO_read_ptr: %d\n", myfile->_IO_read_ptr - myfile->_IO_read_base);
- return 0;
- }
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main(void)
{char buf[5];char *cur;FILE *myfile;myfile = fopen("bbb.txt", "r");printf("before reading, myfile->_IO_read_ptr: %d\n", myfile->_IO_read_ptr - myfile->_IO_read_base);fgets(buf, 5, myfile); //仅仅读4个字符cur = myfile->_IO_read_base;while (cur < myfile->_IO_read_end) //实际上读满了这个缓冲区{printf("%c",*cur);cur++;}printf("\nafter reading, myfile->_IO_read_ptr: %d\n", myfile->_IO_read_ptr - myfile->_IO_read_base);return 0;
}上例中,fgets(buf, 5, myfile); 仅仅读4个字符,但是,缓冲区已被写满,但是_IO_read_ptr却向前移动了5位,下次再次调用读操作时,只要要读的位数不超过myfile->_IO_read_end - myfile->_IO_read_ptr那么就不需要再次调用系统调用read,只要将数据从myfile的缓冲区拷贝到buf即可(从myfile->_IO_read_ptr开始拷贝)
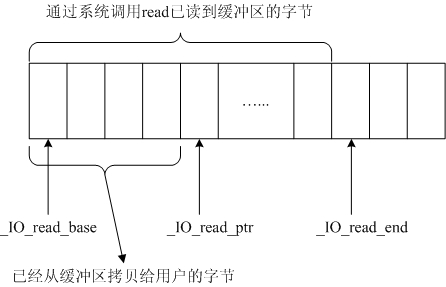
全缓冲读的时候:
_IO_read_base始终指向缓冲区的开始
_IO_read_end始终指向已从内核读入缓冲区的字符的下一个(对全缓冲来说,buffered I/O读每次都试图都将缓冲区读满)
_IO_read_ptr始终指向缓冲区中已被用户读走的字符的下一个
(_IO_read_end < (_IO_buf_base-_IO_buf_end)) && (_IO_read_ptr == _IO_read_end)时则已经到达文件末尾,其中_IO_buf_base-_IO_buf_end是缓冲区的长度
一般大体的工作情景为:
第一次fgets(或其他的)时,标准I/O会调用read将缓冲区充满,下一次fgets不调用read而是直接从该缓冲区中拷贝数据,直到缓冲区的中剩余的数据不够时,再次调用read.在这个过程中,_IO_read_ptr就是用来记录缓冲区中哪些数据是已读的,哪些数据是未读的
- #include <stdlib.h>
- #include <stdio.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- int main(void)
- {
- char buf[2048]={0};
- int i;
- FILE *myfile;
- myfile = fopen("aaa.txt", "r+");
- i= 0;
- while (i<2048)
- {
- fwrite(buf+i, 1, 512, myfile);
- i +=512;
- //注释掉这句则可以写入aaa.txt
- myfile->_IO_write_ptr = myfile->_IO_write_base;
- printf("%p write buffer base\n", myfile->_IO_write_base);
- printf("%p buf buffer base \n", myfile->_IO_buf_base);
- printf("%p read buffer base \n", myfile->_IO_read_base);
- printf("%p write buffer ptr \n", myfile->_IO_write_ptr);
- printf("\n");
- }
- return 0;
- }
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main(void)
{char buf[2048]={0};int i;FILE *myfile;myfile = fopen("aaa.txt", "r+");i= 0;while (i<2048){fwrite(buf+i, 1, 512, myfile);i +=512;//注释掉这句则可以写入aaa.txtmyfile->_IO_write_ptr = myfile->_IO_write_base;printf("%p write buffer base\n", myfile->_IO_write_base);printf("%p buf buffer base \n", myfile->_IO_buf_base);printf("%p read buffer base \n", myfile->_IO_read_base);printf("%p write buffer ptr \n", myfile->_IO_write_ptr);printf("\n");}return 0;
}全缓冲时,只有当标准I/O自动flush(比如当缓冲区已满时)或者手工调用fflush时,标准I/O才会调用一次write系统调用.例子中,fwrite(buf+i, 1, 512, myfile);这一句只是将buf+i接下来的512个字节写入缓冲区,由于缓冲区未满,标准I/O并未调用write.此时,myfile->_IO_write_ptr = myfile->_IO_write_base;会导致标准I/O认为没有数据写入缓冲区,所以永远不会调用write,这样aaa.txt文件得不到写入.注释掉myfile->_IO_write_ptr = myfile->_IO_write_base;前后,看看效果.
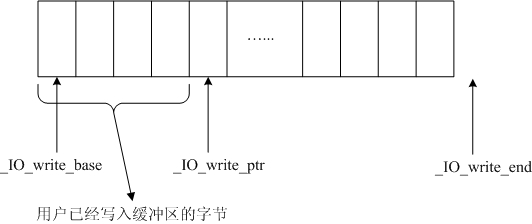
全缓冲写的时候:
_IO_write_base始终指向缓冲区的开始
_IO_write_end全缓冲的时候,始终指向缓冲区的最后一个字符的下一个
(对全缓冲来说,buffered I/O写总是试图在缓冲区写满之后,再系统调用write)
_IO_write_ptr始终指向缓冲区中已被用户写入的字符的下一个
flush的时候,将_IO_write_base和_IO_write_ptr之间的字符通过系统调用write写入内核
1.2. 行缓冲
下面是APUE上的原话:
行缓冲"当输入输出中遇到换行符时,标准I/O库执行I/O操作. "书中这里"执行O操作"也容易引起误导,这里不是读写磁盘,而应该是进行read或write的系统调用
下面两个例子会说明这个问题
第一个例子可以用来说明下面这篇帖子的问题
http://bbs.chinaunix.net/viewthread.php?tid=954547
- #include <stdlib.h>
- #include <stdio.h>
- int main(void)
- {
- char buf[5];
- char buf2[10];
- fgets(buf, 5, stdin); //第一次输入时,超过5个字符
- puts(stdin->_IO_read_ptr);//本句说明整行会被一次全部读入缓冲区,而非仅仅上面需要的个字符
- stdin->_IO_read_ptr = stdin->_IO_read_end; //标准I/O会认为缓冲区已空,再次调用read,注释掉,再看看效果
- printf("\n");
- puts(buf);
- fgets(buf2, 10, stdin);
- puts(buf2);
- return 0;
- }
#include <stdlib.h>
#include <stdio.h>int main(void)
{char buf[5];char buf2[10];fgets(buf, 5, stdin); //第一次输入时,超过5个字符puts(stdin->_IO_read_ptr);//本句说明整行会被一次全部读入缓冲区,而非仅仅上面需要的个字符stdin->_IO_read_ptr = stdin->_IO_read_end; //标准I/O会认为缓冲区已空,再次调用read,注释掉,再看看效果printf("\n");puts(buf);fgets(buf2, 10, stdin);puts(buf2);return 0;
}
行缓冲读的时候,
_IO_read_base始终指向缓冲区的开始
_IO_read_end始终指向已从内核读入缓冲区的字符的下一个
_IO_read_ptr始终指向缓冲区中已被用户读走的字符的下一个
(_IO_read_end < (_IO_buf_base-_IO_buf_end)) && (_IO_read_ptr == _IO_read_end)时则已经到达文件末尾
其中_IO_buf_base-_IO_buf_end是缓冲区的长度
- #include <stdlib.h>
- #include <stdio.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- char buf[5]={'1','2', '3', '4', '5'}; //最后一个不要是\n,是\n的话,标准I/O会自动flush的,这是行缓冲跟全缓冲的重要区别
- void writeLog(FILE *ftmp)
- {
- fprintf(ftmp, "%p write buffer base\n", stdout->_IO_write_base);
- fprintf(ftmp, "%p buf buffer base \n", stdout->_IO_buf_base);
- fprintf(ftmp, "%p read buffer base \n", stdout->_IO_read_base);
- fprintf(ftmp, "%p write buffer ptr \n", stdout->_IO_write_ptr);
- fprintf(ftmp, "\n");
- }
- int main(void)
- {
- int i;
- FILE *ftmp;
- ftmp = fopen("ccc.txt", "w");
- i= 0;
- while (i<4)
- {
- fwrite(buf, 1, 5, stdout);
- i++;
- *stdout->_IO_write_ptr++ = '\n';//可以单独把这句打开,看看效果
- //getchar();//getchar()会将标准I/O将缓冲区输出
- //打开下面的注释,你就会发现屏幕上什么输出也没有
- //stdout->_IO_write_ptr = stdout->_IO_write_base;
- writeLog(ftmp); //这个只是为了查看缓冲区指针的变化
- }
- return 0;
- }
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>char buf[5]={'1','2', '3', '4', '5'}; //最后一个不要是\n,是\n的话,标准I/O会自动flush的,这是行缓冲跟全缓冲的重要区别void writeLog(FILE *ftmp)
{fprintf(ftmp, "%p write buffer base\n", stdout->_IO_write_base);fprintf(ftmp, "%p buf buffer base \n", stdout->_IO_buf_base);fprintf(ftmp, "%p read buffer base \n", stdout->_IO_read_base);fprintf(ftmp, "%p write buffer ptr \n", stdout->_IO_write_ptr);fprintf(ftmp, "\n");
}int main(void)
{int i;FILE *ftmp;ftmp = fopen("ccc.txt", "w");i= 0;while (i<4){fwrite(buf, 1, 5, stdout);i++;*stdout->_IO_write_ptr++ = '\n';//可以单独把这句打开,看看效果//getchar();//getchar()会将标准I/O将缓冲区输出//打开下面的注释,你就会发现屏幕上什么输出也没有//stdout->_IO_write_ptr = stdout->_IO_write_base;writeLog(ftmp); //这个只是为了查看缓冲区指针的变化 }return 0;
}上面这个是关于行缓冲写的例子.
stdout->_IO_write_ptr = stdout->_IO_write_base;会使得标准I/O认为缓冲区是空的,从而没有任何输出.可以将上面程序中的注释分别去掉,看看运行结果
行缓冲时,下面3个条件之一会导致缓冲区立即被flush
1. 缓冲区已满
2. 遇到一个换行符;比如将上面例子中buf[4]改为'\n'时
3. 再次要求从内核中得到数据时;比如上面的程序加上getchar()会导致马上输出
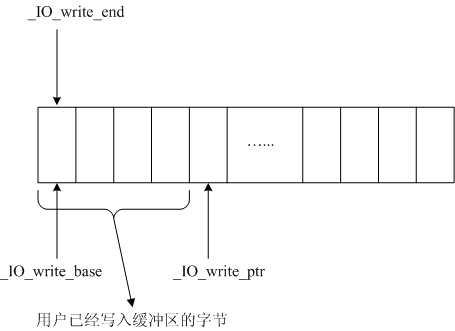
行缓冲写的时候:
_IO_write_base始终指向缓冲区的开始
_IO_write_end始终指向缓冲区的开始
_IO_write_ptr始终指向缓冲区中已被用户写入的字符的下一个
flush的时候,将_IO_write_base和_IO_write_ptr之间的字符通过系统调用write写入内核
1.3. 无缓冲
无缓冲时,标准I/O不对字符进行缓冲存储.典型代表是stderr,这里的无缓冲,并不是指缓冲区大小为0,其实,还是有缓冲的,大小为1
- #include <stdlib.h>
- #include <stdio.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- int main(void)
- {
- fputs("stderr", stderr);
- printf("%d\n", stderr->_IO_buf_end - stderr->_IO_buf_base);
- return 0;
- }
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main(void)
{fputs("stderr", stderr);printf("%d\n", stderr->_IO_buf_end - stderr->_IO_buf_base);return 0;
}1.4 feof的问题
CU上已经有无数的帖子在探讨feof了,这里从缓冲区的角度去考察一下.对于一个空文件,为什么要先读一下,才能用feof判断出该文件到了结尾了呢?
- #include <stdlib.h>
- #include <stdio.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- int main(void)
- {
- char buf[5];
- char buf2[10];
- fgets(buf, sizeof(buf), stdin);//输入要于4个,少于13个字符才能看出效果
- puts(buf);
- //交替注释下面两行
- //stdin->_IO_read_end = stdin->_IO_read_ptr+1;
- stdin->_IO_read_end = stdin->_IO_read_ptr + sizeof(buf2)-1;
- fgets(buf2, sizeof(buf2), stdin);
- puts(buf2);
- if (feof(stdin))
- printf("input end\n");
- return 0;
- }
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main(void)
{char buf[5];char buf2[10];fgets(buf, sizeof(buf), stdin);//输入要于4个,少于13个字符才能看出效果puts(buf);//交替注释下面两行//stdin->_IO_read_end = stdin->_IO_read_ptr+1;stdin->_IO_read_end = stdin->_IO_read_ptr + sizeof(buf2)-1;fgets(buf2, sizeof(buf2), stdin);puts(buf2);if (feof(stdin))printf("input end\n");return 0;
}1.5. 其他说明
很多新手有一个误解,就是fgets, fputs代表行缓冲,fread, fwrite代表全缓冲 fgetc, fputc代表无缓冲等等.其实不是这样的,是什么样的缓冲跟使用那个函数没有关系,而跟你读写什么类型的文件有关系.上面的例子中多次在全缓冲中使用fgets, fputs,而在行缓冲中使用fread, fwrite
下面的是引至APUE的,实际上ISO C要求:
1.当且仅当标准输入和标准输出并不涉及交互式设备时,他们才是全缓冲的
2.标准错误输出决不是全缓冲的.
很多系统默认使用下列类型的标准:
1.标准错误输出是不带缓冲的.
2.如若是涉及终端设备的其他流,则他们是行缓冲的;否则是全缓冲的.
转自:http://blog.csdn.net/cowbane/article/details/6630298
原文:
浅谈无缓存I/O操作和标准I/O文件操作区别
相关文章:

Android之ListActivity(一):布局与数据绑定
Android中的列表,当然也可以用ListView来完成所需要的功能,用法是一样的。 废话不说,来关键的。 LiveActivity本身继承了关于List操作的众多接口,我们可以方便的重写这些操作中需要的方法来实现自己需要的功能。 如果要用ListActi…
用于单图像超分辨率的对偶回归网络,达到最新SOTA | CVPR 2020
作者 | Yong Guo, Jian Chen等译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)通过学习从低分辨率(LR)图像到高分辨率(HR)图像之间的非线性映射函数,深度神经网络在图像超分辨率(SR&a…
老生常谈,joomla wordpress drupal,你该选择哪个CMS?
本人从事Joomla建站多年,给客户建站都是用Joomla,所以我会极力推荐你选择Joomla? No No No,这样未免太Hard sale了。 虽然这是一个会经常被提到的问题,网上也有不少优秀的答案,但我还是想把自己的想法跟大家…

利用TCMalloc替换Nginx和Redis默认glibc库的malloc内存分配
TCMalloc的全称为Thread-Caching Malloc,是谷歌开发的开源工具google-perftools中的一个成员。与标准的glibc库的Malloc相比,TCMalloc库在内存分配效率和速度上要高很多,这在很大程度上提高了服务器在高并发情况下的性能,从而降低…

Silverlight Analytics Framework(开源分析框架)
Silverlight Analytics Framework是由微软官方推出的WPF/Silverlight扩展Web分析框架.该框架与10余家第三方分析服务结合,使应用可以跟踪程序如何使用的详细情况,为用户提供诸如可用性和视频质量等细节分析。用户可以了解到这些应用软件的使用细节&#…
Python炫技操作:条件语句的七种写法
作者 | 写代码的明哥来源 | Python编程时光有的人说 Python 入门容易,但是精通难的语言,这点我非常赞同。Python 语言里有许多(而且是越来越多)的高级特性,是 Python 发烧友们非常喜欢的。在这些人的眼里,能…
puppet(1.7-2.1)
puppet配置模块(一)模块是puppet的最大单元,模块里面有类,类下面有资源。同步文件、远程执行命令、cron等叫做资源,都是通过模块来实现的。下面我们来定义一个模块:在服务端上做如下操作:mkdir /etc/puppet/modules/te…
ldconfig动态链接库管理以及修改ld.so.conf.d
将"/usr/local/lib"加入配置文件重 执行命令: #echo "/usr/local/lib" >> /etc/ld.so.conf 然后再直接执行: #ldconfig /etc/ld.so.conf.d/* 或/etc/ld.so.conf和ldconfig. /etc/ld.so.conf.d/*目录下的文件和/etc/ld.so.co…
深度残差收缩网络:借助注意力机制实现特征的软阈值化
作者 | 哈尔滨工业大学(威海)讲师 赵明航本文解读了一种新的深度注意力算法,即深度残差收缩网络(Deep Residual Shrinkage Network)。从功能上讲,深度残差收缩网络是一种面向强噪声或者高度冗余数据的特征学…
如何在同一台电脑上多个账户同时登陆MSN
一般情况下,在一台电脑上只能启动一个msn进程,所以当想多个账户在同一台电脑上同时登陆时,就无法实现了。我们可以使用MSNShell来实现多个账户的同时登陆。MSNShell下载地址:http://www.msnshell.netMSNShell系统要求:…
LINUX动态链接库的创建与使用
大家都知道,在 WINDOWS系统中有很多的动态链接库(以.DLL为后缀的文件,DLL即Dynamic Link Library)。这种动态链接库,和静态函数库不同,它里面的函数并不是执行程序本身的一部分,而是根据执行程序需要按需装入ÿ…
多模态商品推荐与认知智能背后的数学
在数据挖掘领域,KDD CUP是最有影响力、最高水平的国际顶级赛事,堪称大数据的“奥运会”。阿里巴巴作为KDD CUP 2020的主办方为参赛团队准备了两大赛题,第一道是关于“电商场景的多模态商品推荐”,下面就这一道题目从认知智能与数学…
Asp.net MVC2.0系列文章-运行Web MVC2.0 Demo
安装VS2010 首先安装VS2010,安装过程请参考文章:http://www.cnblogs.com/ywqu/archive/2010/01/27/1657450.html。创建第一个MVC2.0程序 新建一个asp.net MVC2.0网站程序,如下图:提示是否新建单元测试工程,选择创建Uni…
one pragmatical sqlhelper
namespace ConsoleApplication2 {using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Data;using System.Data.SqlClient;using System.Configuration;public class SqlHelper{/// <summary>/// 连接字符串/// </summa…
LINUX动态链接库高级应用
在《 LINUX下动态链接库的创建与应用》 一文中,我介绍了LINUX动态链接库的基本知识.其要点是:用户根据实际情况需要,利用dlopen,dlsym,dlclose等动态链接库操作函 数,装入指定的动态链接库中指定的函数,然后加以执行.程序中使用很少的动态函数时,这样的做法尚可.如果程序需要调…
林轩田机器学习基石课程学习笔记1 -- The Learning Problem
来源 | AI 算法与图像处理 主要内容What is Machine LearningApplications of Machine LearningComponents of Machine LearningMachine Learning and Other FieldsWhat is Machine Learning什么是“学习”?学习就是人类通过观察、积累经验,掌握某项技能…

裸创,你敢吗?
呵呵
ecshop修改注册、增加手机
1.去掉“用户名”注册 a.去掉提交 user_passport.dwt页面去掉 <input name"username" type"text" size"30" id"username" οnblur"is_registered(this.value);" class"input_login" />提交 b.去掉js表单验证…
使用NetBeans IDE开发C程序
使用NetBeans IDE开发C程序 在windows下开发调试linux环境的代码,同时还可以拷贝到Linux环境。 其实是NetBeans可以连接到远程Linux服务器,使用其中的GNU编译环境。 1.打开NetBeans,新建C/C项目: 下一步: 如果之前配置…
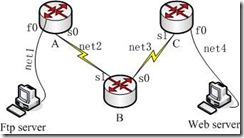
实验七 访问列表配置
实验七 访问列表配置 预备知识: ACL指令的放置顺序是很重要的。 当路由器在决定是否转发或者阻止数据报的时候,Cisco的IOS软件,按照ACL中指令的顺序依次检查数据报是否满足某一个指令条件。 当检测到某个指令条件满足的时候,就不会…
京东商城背后的AI技术能力揭秘 - 基于关键词自动生成摘要
来源 | 京东智联云开发者过去几十年间,人类的计算能力获得了巨大提升;随着数据不断积累,算法日益先进,我们已经步入了人工智能时代。确实,人工智能概念很难理解,技术更是了不起,背后的数据和算法…
CSS哲学伪命题
标题党。这篇文章断断续续的修改过好几次,也没有满意,本来是想总结一下我这些零散的 CSS 知识结构,可能由于知识体系不全面,总是没能把知识点串联成一个通顺的内容。贴出来权当大家一起讨论下“前世今生”。文章后续可能会不定时更…
Linux TCP/IP协议栈笔记
数据包的接收作者:kendoKernel:2.6.12一、从网卡说起这并非是一个网卡驱动分析的专门文档,只是对网卡处理数据包的流程进行一个重点的分析。这里以Intel的e100驱动为例进行分析。大多数网卡都是一个PCI设备,PCI设备都包含了一个标…
技术大佬的肺腑之言:“不要为了 AI 而 AI”! | 刷新 CTO
扫描上方二维码直达精彩回顾整理 | 伍杏玲出品 | CSDN(ID:CSDNnews)据 CSDN 最新数据统计显示,在 CSDN 3000万的注册开发者中,689 万开发者有阅读、撰写与研究 AI 技术的行为,聚焦 AI 学习及应用的开发者人…

Silverlight中使用CompositionInitializer宿主MEF
MEF可以在传统应用程序中使用(包括桌面的Winform、控制台程序和Web的ASP.NET),也可以在RIA的Silverlight中使用。在Silverlight中只是宿主的方式有所不同,实际上在Silverlight中也可以像传统应用程序中是方式去宿主,ME…

Verilog与SystemVerilog编程陷阱:怎样避免101个常犯的编码错误
这篇是计算机类的优质预售推荐>>>>《Verilog与SystemVerilog编程陷阱:怎样避免101个常犯的编码错误》 编辑推荐 纠错式学习,从“陷阱”中学习编程,加深对语言本身的理解。逆向式学习,从错误中学习避免错误的方法。让读…
Linux网卡驱动程序编写
Linux网卡驱动程序编写 [摘自 LinuxAID] 工作需要写了我们公司一块网卡的Linux驱动程序。经历一个从无到有的过程,深感技术交流的重要。Linux作为挑战微软垄断的强有力武器,日益受到大家的喜爱。真希望她能在中国迅速成长。把程序文档贴出来࿰…
旷视提双边分支网络BBN:攻坚长尾分布的现实世界任务 | CVPR 2020 Oral
作者 | 旷视研究院出品 | AI科技大本营(ID:rgznai100)导读:本文是旷视 CVPR 2020 论文系列解读文章,也是 CVPR 2020 Oral展示论文之一,它揭示了再平衡方法解决长尾问题的本质及不足:虽然增强了分类器性能&a…
kissy core
http://code.google.com/p/kissy/转载于:https://www.cnblogs.com/pinnasky/archive/2010/07/07/1772646.html
VIM多窗口编辑
vim提供多窗口编辑的功能,可以简化复合的编辑任务。vim的多窗口并不是说在终端上启动多个vim实例。启动多窗口编辑 vim的多窗口是动态的,可以开始编辑时就打开多窗口,也可以工作时随时增加新窗口,或者删除一个窗口。$ …