nginx源码分析--内存对齐处理
1.nginx内存对齐主要是做2件事情:
1) 内存池的内存地址对齐;
2) 长度按照2的幂取整.因为前面结构体已经是对齐了,如果后面的内存池每一小块不是2的幂,那么后面的就不能对齐
2.通用内存对齐理论
内存对齐:数据项只能存储在地址是数据项大小的整数倍的内存位置上
例如int类型占用4个字节,地址只能在0,4,8等位置上。
数据的对齐(alignment)
指数据的地址和由硬件条件决定的内存块大小之间的关系。一个变量的地址是它大小的倍数的时候,这就叫做自然对齐(naturally aligned)。例如,对于一个32bit的变量,如果它的地址是4的倍数,-- 就是说,如果地址的低两位是0,那么这就是自然对齐了。所以,如果一个类型的大小是2n个字节,那么它的地址中,至少低n位是0。对齐的规则是由硬件引起的。一些体系的计算机在数据对齐这方面有着很严格的要求。在一些系统上,一个不对齐的数据的载入可能会引起进程的陷入。在另外一些系统,对不对齐的数据的访问是安全的,但却会引起性能的下降。在编写可移植的代码的时候,对齐的问题是必须避免的,所有的类型都该自然对齐。
预对齐内存的分配
在大多数情况下,编译器和C库透明地帮你处理对齐问题。POSIX 标明了通过malloc( ), calloc( ), 和realloc( ) 返回的地址对于任何的C类型来说都是对齐的。在Linux中,这些函数返回的地址在32位系统是以8字节为边界对齐,在64位系统是以16字节为边界对齐的。有时候,对于更大的边界,例如页面,程序员需要动态的对齐。虽然动机是多种多样的,但最常见的是直接块I/O的缓存的对齐或者其它的软件对硬件的交互,因此,POSIX 1003.1d提供一个叫做posix_memalign( )的函数
2.1对较小结构体进行机器字对齐--避免多次读
对于现代计算机硬件来说,内存只能通过特定的对齐地址(比如按照机器字)进行访问。举个例子来说,比如在64位的机器上,不管我们是要读取第0个字节还是要读取第1个字节,在硬件上传输的信号都是一样的。因为它都会把地址0到地址7,这8个字节全部读到CPU,只是当我们是需要读取第0个字节时,丢掉后面7个字节,当我们是需要读取第1个字节,丢掉第1个和后面6个字节。
当我们要读取的字节刚好落在两个机器字内时,就出现两次访问内存的情况,同时通过一些逻辑计算才能得到最终的结果。
因此,为了更好的提升性能,我们须尽量将结构体做到机器字(或倍数)对齐,而结构体中一些频繁访问的字段也尽量安排在机器字对齐的位置。
操作系统的默认对齐系数
每个操作系统都有自己的默认内存对齐系数,如果是新版本的操作系统,默认对齐系数一般都是8,因为操作系统定义的最大类型存储单元就是8个字节,例如 long long,不存在超过8个字节的类型(例如int是4,char是1,long在32位编译时是4,64位编译时是8)。当操作系统的默认对齐系数与第一节所讲的内存对齐的理论产生冲突时,以操作系统的对齐系数为基准。
编译器是按照什么样的原则进行对齐的。首先有3个重要的概念:自身对齐值,指定对齐值和有效对齐值。
自身对齐值:即数据类型的自身的对齐值。例如char型的数据,其自身对齐值为1字节;short型的数据,其自身对齐值为2字节;int,float,long类型,其自身对齐值为4字节;double类型,其自身对齐值为4字节;而struct和class类型的数据其自身对齐值为其成员变量中自身对齐值最大的那个值。
指定对齐值:#pragma pack (value)时指定的对齐值value
有效对齐值:上述两个对齐值中最小的那个。
我们一般说的对齐在N上,都是指有效对齐在N上。
2.2对较大结构体进行CACHE LINE对齐--避免占用过多CACHE LINE
我们知道,CACHE与内存交换的最小单位为CACHE LINE,一个CACHE LINE大小以64字节为例。当我们的结构体大小没有与64字节对齐时,一个结构体可能就要占用比原本需要更多的CACHE LINE。比如,把一个内存中没有64字节长的结构体缓存到CACHE时,即使该结构体本身长度或许没有还没有64字节,但由于其前后搭占在两条CACHE LINE上,那么对其进行淘汰时就会淘汰出去两条CACHE LINE。
这还不是最严重的问题,非CACHE LINE对齐结构体在SMP机器上容易引发名为错误共享的CACHE问题。
#include <stdio.h>struct xx{char b;long long a;int c;char d;
};int main()
{struct xx bb;printf("&a = %p\n", &bb.a);printf("&b = %p\n", &bb.b);printf("&c = %p\n", &bb.c);printf("&d = %p\n", &bb.d);printf("sizeof(xx) = %d\n", sizeof(struct xx));return 0;
}

例如假设没有内存对齐,结构体xx的变量位置会出现如下情况:
struct xx{
char b; //0xffbff5e8
int a; //0xffbff5e9
int c; //0xffbff5ed
char d; //0xffbff5f1
};
操作系统先读取0xffbff5e8-0xffbff5ef的内存,然后在读取0xffbff5f0-0xffbff5f8的内存,为了获得值c,就需要将两组内存合并,进行整合,这样严重降低了内存的访问效率。

VC和GCC默认的都是4字节对齐,编程中可以使用#pragma pack(n)指定对齐模数。出现以上差异的原因在于,VC和GCC中对于double类型的对齐方式不同。
Win32平台下的微软VC编译器在默认情况下采用如下的对齐规则: 任何基本数据类型T的对齐模数就是T的大小,即sizeof(T)。比如对于double类型(8字节),就要求该类型数据的地址总是8的倍数,而char类型数据(1字节)则可以从任何一个地址开始。
Linux下的GCC奉行的是另外一套规则:任何2字节大小(包括单字节吗?)的数据类型(比如short)的对齐模数是2,而其它所有超过2字节的数据类型(比如long,double)都以4为对齐模数。
复杂类型(如结构)的默认对齐方式是它最长的成员的对齐方式,这样在成员是复杂类型时,可以最小化长度。
struct{char a;double b;}
在VC中,因为结构中存在double和char,按照最长数据类型对齐,char只占1B,但是加上后面的double所占空间超过8B,所以char独占8B;而double占8B,一共16Byte。
在GCC中,double长度超过4字节,按照4字节对齐,原理同上,不过char占4字节,double占两个4字节,一共12Byte。
3.Nginx中的内存处理
ngx_alloc.c部分代码
ngx_uint_t ngx_cacheline_size;#if (NGX_HAVE_POSIX_MEMALIGN)void *
ngx_memalign(size_t alignment, size_t size, ngx_log_t *log)
{void *p;int err;err = posix_memalign(&p, alignment, size);if (err) {ngx_log_error(NGX_LOG_EMERG, log, err,"posix_memalign(%uz, %uz) failed", alignment, size);p = NULL;}ngx_log_debug3(NGX_LOG_DEBUG_ALLOC, log, 0,"posix_memalign: %p:%uz @%uz", p, size, alignment);return p;
}#elif (NGX_HAVE_MEMALIGN)void *
ngx_memalign(size_t alignment, size_t size, ngx_log_t *log)
{void *p;p = memalign(alignment, size);if (p == NULL) {ngx_log_error(NGX_LOG_EMERG, log, ngx_errno,"memalign(%uz, %uz) failed", alignment, size);}ngx_log_debug3(NGX_LOG_DEBUG_ALLOC, log, 0,"memalign: %p:%uz @%uz", p, size, alignment);return p;
}#endif
ngx_cpuinfo.c

得到ngx_cacheline_size = 64;
ngx_config.h
#ifndef NGX_ALIGNMENT
#define NGX_ALIGNMENT sizeof(unsigned long) /* platform word */
#endif#define ngx_align(d, a) (((d) + (a - 1)) & ~(a - 1))
#define ngx_align_ptr(p, a) \(u_char *) (((uintptr_t) (p) + ((uintptr_t) a - 1)) & ~((uintptr_t) a - 1))sizeof(unsigned long)=4
先分析 (((d) + (a - 1)) & ~(a - 1))表达式
两个参数d和a,d代表数据,a代表对其单位。假设a是8,那么用二进制表示就是1000,a-1就是0111. d + a-1之后在第四位可能进位一次(如果d的前三位不为000,则会进位。反之,则不会),~(a-1)是1111...1000,&之后的结过就自然在4位上对其了。注意二进制中第四位的单位是8,也就是以8为单位对其。
理解表达式 ~(a - 1)注意,其中a为2的幂,设右数第n位为非零位,则a-1为右数的n-1位均为1, 则有~(a-1)为最后的n-1位全为0;
显然可得一个数和2的幂进行 减一取反再按位与操作,即为该数减去(其与a求余的值)
这种计算地址或者长度对齐,取整的宏还是很有用的。cpu访问对齐的数据较快,不对齐的的int之类的,有可能区要多次内存访问才能取到值。
向上取整倍数,ngx_align内存对齐的宏,对于a,传入CPU的二级cache的line大小,通过ngx_cpuinf函数,可以获得ngx_cacheline_size的大小,一般intel为64或128
计算宏ngx_align(1, 64)=64,只要输入d<64,则结果总是64,如果输入d=65,则结果为128,以此类推。
进行内存池管理的时候,对于小于64字节的内存,给分配64字节,使之总是cpu二级缓存读写行的大小倍数,从而有利cpu二级缓存取速度和效率。
ngx_cpuinfo函数实际是调用了汇编代码,获取cpu二级缓存大小!
//==================================================
上面式子,当a等于2的幂的时候,比如,4,8,16等值时,
d加上(a-1) 之后的值肯定要比最小的a的倍数要大的。因为a为2的幂,所以(a - 1) 刚好后面几位都是连续的1,取反之后再相与一下之后,就把小于a的余数部分丢掉了。 不过如果a不是2的幂,比如a=3, d=1 ,那么推算一下,上面的计算就不成立了。
这种计算地址或者长度对齐,取整的宏还是很有用的。cpu访问对齐的数据跟快把,不对齐的的int之类的,有可能区要多次内存访问才能取到值出来。 写个简单的字符串内存池,AllocateString时打算把所有的字符串放到一个连续的内存块上,觉得还是把长度取整一下比较好。这样后续的对字符串的memcpy就是内存字对齐,更好吧。
//=================================================
ngx_palloc.c部分代码
ngx_align_ptr的调用
void *
ngx_palloc(ngx_pool_t *pool, size_t size)
{u_char *m;ngx_pool_t *p;if (size <= pool->max) {p = pool->current;do {m = ngx_align_ptr(p->d.last, NGX_ALIGNMENT);if ((size_t) (p->d.end - m) >= size) {p->d.last = m + size;return m;}p = p->d.next;} while (p);return ngx_palloc_block(pool, size);}return ngx_palloc_large(pool, size);
}ngx_memalign的调用
static void *
ngx_palloc_block(ngx_pool_t *pool, size_t size)
{u_char *m;size_t psize;ngx_pool_t *p, *new, *current;psize = (size_t) (pool->d.end - (u_char *) pool);m = ngx_memalign(NGX_POOL_ALIGNMENT, psize, pool->log);if (m == NULL) {return NULL;}new = (ngx_pool_t *) m;new->d.end = m + psize;new->d.next = NULL;new->d.failed = 0;m += sizeof(ngx_pool_data_t);m = ngx_align_ptr(m, NGX_ALIGNMENT);new->d.last = m + size;current = pool->current;for (p = current; p->d.next; p = p->d.next) {if (p->d.failed++ > 4) {current = p->d.next;}}p->d.next = new;pool->current = current ? current : new;return m;
}ngx_http.c
ngx_align的调用
hash.bucket_size = ngx_align(64, ngx_cacheline_size);4.Nginx内存对齐使用举例
64=2的6次方

5.编译器对齐值
Visualstudio2012

参考《linux系统编程》好累啊,我翻译的<Linux system programming> 第八章 二 ;《Linux System Programming》中文版
Cache line
从CPU角度看内存访问对齐
如何高效的访问内存
相关文章:

七喜携手AMD,摆脱英特尔“潜规则”
七喜携手AMD,摆脱英特尔“潜规则”<?xml:namespace prefix o ns "urn:schemas-microsoft-com:office:office" />最近,在PC市场随着七喜董事副总裁毛骏飙揭发英特尔制定的潜规则,“游戏规则都是英特尔制定的,全…
半小时训练亿级规模知识图谱,亚马逊AI开源知识图谱嵌入表示框架DGL-KE
出品 | AI科技大本营(ID:rgznai100) 知识图谱 (Knowledge Graph)作为一个重要的技术,在近几年里被广泛运用在了信息检索,自然语言处理,以及推荐系统等各种领域。学习知识图谱的嵌入表示 &#x…
数组的各类排序
1 package sort;2 3 /**4 * 数组的各种排序操作5 * Created by liuwei on 16/3/6.6 */7 public class MSort {8 9 /**10 * 直接插入排序11 * 外层一个循环,从第2个元素开始(下标为1),遍历后面的所有元素12 * 内层一个循环,从当前位置position i 开始,每次…
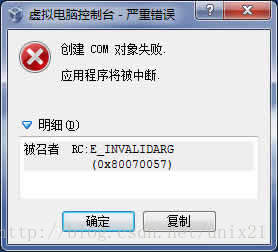
Virtualbox安装使用注意
1.VirtualBox升级到4.3以后不能打开 提示创建 COM 对象失败 应用程序将被中断 解决方案:右键VirtualBox的桌面快捷方式,选择属性,选到兼容性选项卡,勾选“以兼容模式运行这个程序”,下拉框选择Windows Server 2008 …
机器学习项目模板:ML项目的6个基本步骤
来源 | DeepHub IMBA每个机器学习项目都有自己独特的形式。对于每个项目,都可以遵循一组预定义的步骤。尽管没有严格的流程,但是可以提出一个通用模板。准备问题不仅是机器学习,任何项目的第一步都是简单地定义当前的问题。您首先需要了解背景…
ib_logfile 在数据库中有何作用?
ib_logfile 在数据库中有何作用? ib_logfile0/ib_logfile1 文件在数据库中起什么作用? 如果被删除,对数据库有何影响? ----->>>>>>>>>>> 回复 #1 mugua_xinli 的帖子 用于存放InnoDB引擎的事…
Podfile 常见语法
source URL : 指定镜像仓库的源 platform : ios, 6.0 : 指定所支持系统和最低版本 inhibit_all_warnings! :屏蔽所有warning workspace 项目空间名: 指定项目空间名 xcodeproj 工程文件名:指定xcodeproj工程文件名 …
今天学完了ccna
通过10天的学习,终于学完了NA,但是会不会呢?还是个未知数,再就也一知半解的。觉得基础知识太差了,可是看书,又觉得太长了,太多了,晚上老是停电 白天啥也看不进去。热。还是静不下心&…
攀登数据科学家和数据工程师之间的隔墙
来源 | 数据派 THU机器学习的教育和研究重点往往集中在数据科学过程的模型构建、训练、测试和优化等方面。要使这些模型投入使用,需要一套工程专长和组织结构,对于其中的标准尚不存在。有一个架构可以指导数据科学和工程团队相互协作,从而将机…

js变量以及其作用域详解
2019独角兽企业重金招聘Python工程师标准>>> 一、变量的类型 Javascript和Java、C这些语言不同,它是一种无类型、弱检测的语言。它对变量的定义并不需要声明变量类型,我们只要通过赋值的形式,可以将各种类型的数据赋值给同一个变…

在A*寻路中使用二叉堆
在A*寻路中使用二叉堆 作者:Patrick Lester(2003年4月11日更新) 译者:Panic 2005年3月28日 译者序: 这一篇文章,是“A* Pathfinding for Beginners.”,也就是我翻译的另一篇文章A*寻路初探…
“Hey Siri” 背后的黑科技大揭秘!
作者 | Vishant Batta译者 | 苏本如,责编 | 伍杏玲出品 | CSDN(ID:CSDNnews)以下是译文: 如今苹果手机可随时检测并回答“Hey Siri”命令,有人可能会想,它是不是在随时记录我们的日常生活对话呢…
[ASP.NET4之旅]Circular file references are not allowed
将ASP.NET 2.0的项目升级到ASP.NET 4后,用VS2010编译站点,某些控件出现编译错误“Circular file references are not allowed”,比如: <% Control Language"C#"ClassName"NewsRight"%>解决方法…
IOS-XMPP
一、即时通讯技术简介 即时通讯技术(IM -- Instant Messaging)支持用户在线实时交谈。如果要发送一条信息,用户需要打开一个小窗口,以便让用户及其朋友在其中输入信息并让交谈双方都看到交谈的内容有许多的IM系统,如AO…
libcurl使用
官网:http://curl.haxx.se/libcurl/c/libcurl-tutorial.html #curl-config --libs 得到 -lcurl #cc libcurl_test.c -o libcurl_test -lcurl 所有的例子:http://curl.haxx.se/libcurl/c/example.html 例子: /***********************…
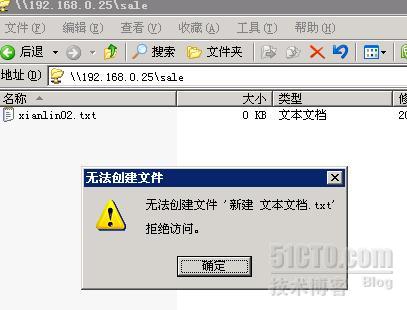
RH5.4下samba共享配置实例(3)
一、基于用户名的访问控制实例: 王乾大哥写的比较详细了,我是跟着他的教程学习的,按照他的教程走一边; 要求如下: 1、创建一个公共的交换文件夹,所有人都可以写入删除,但不能删除修改其他人的文…

《评人工智能如何走向新阶段》后记(再续21)
346.中国抗疫十大黑科技(以人工智能为主力的黑科技) 摘自数邦客(2020.3.30发布) 负压救护车 人工智能机器人:如送餐机器人、消毒机器人、服务型机器人,及机器人呼叫等呼吸道病毒核配检测试剂盒…
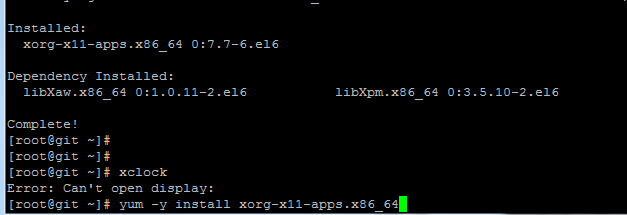
nagios npc安装后状态为off的解决方法
1、检查ndo2db的进程是不是二个 nagios 16825 0.0 0.1 6784 396 ? Ss 19:05 0:00 /usr/local/nagios/bin/ndo2db -c /usr/l nagios 17032 0.0 0.3 6784 1268 ? S 19:09 0:00 /usr/local/nagios/bin/ndo2db -c 2、检查nagios.log日志看…

C语言extern关键字定义外部变量--Redis源码extern使用
在Redis2.8中有networking.c,这个文件没有networking.h networking.c首先引入redis.h这个头文件 #include "redis.h" 在redis.c一开始就声明了全局变量 /* Global vars */ struct redisServer server; networking.c的createClient函数 redisClient *cr…
深度学习面试必备的25个问题
作者 | Tomer Amit译者 | 弯月,编辑 | 屠敏出品 | CSDN(ID:CSDNnews)在本文中,我将分享有关深度学习的25个问题,希望能够帮助你为面试做好准备。1.为什么必须在神经网络中引入非线性?答…
一分钟了解阿里云产品:先知计划
一、 概述 阿里云发布了各种各样的产品,今天让我们一起来了解下阿里云先知计划吧。 什么是先知计划呢? 先知计划是一个帮助企业建立私有应急响应中心的平台(帮助企业收集漏洞信息)。企业加入先知计划后,可…
C语言的HashTable简单实现
原文地址:http://blog.csdn.net/zmxiangde_88/article/details/8025541 HashTable是在实际应用中很重要的一个结构,下面讨论一个简单的实现,虽然简单,但是该有的部分都还是有的。 一,访问接口 创建一个hashtable. h…
GitHub标星2000+,如何用30天啃完TensorFlow2.0?
作者 | 梁云1991来源 | Python与算法之美(ID:Python_Ai_Road)天下苦tensorflow久矣!尽管tensorflow2.0宣称已经为改善用户体验做出了巨大的改进,really easy to use,但大家学得并不轻松。tensorflow2.0官方文档和tenso…
【Struts2学习笔记(1)】Struts2中Action名称的搜索顺序和多个Action共享一个视图--全局result配置...
一、Action名称的搜索顺序 1.获得请求路径的URI,比如url是:http://server/struts2/path1/path2/path3/test.action 2.首先寻找namespace为/path1/path2/path3的package,假设不存在这个package则运行步骤3;假…
大话卷积神经网络CNN,小白也能看懂的深度学习算法教程,全程干货建议收藏!...
来源 | 程序员管小亮本文创作的主要目的,是对时下最火最流行的深度学习算法的基础知识做一个简介,作者看过许多教程,感觉对小白不是特别友好,尤其是在踩过好多坑之后,于是便有了写这篇文章的想法。由于文章较长&#x…

频繁分配释放内存导致的性能问题的分析--brk和mmap的实现
现象1 压力测试过程中,发现被测对象性能不够理想,具体表现为: 进程的系统态CPU消耗20,用户态CPU消耗10,系统idle大约70 2 用ps -o majflt,minflt -C program命令查看,发现majflt每秒增量为0&…
Linux 服务器日志文件查找技巧精粹
用来在日志文件里搜索特定活动事件的工具不下几十种,本文将介绍搜索日志文件时应该采取的策略。然后,通过几个具体示例介绍一些使用grep命令手动搜索日志文件的办法。接下来,我们将看到 logwatch工具和logsurfer工具的用法。最后,…
程序猿面试什么最重要?
程序猿面试一直是社区乐于讨论的热门话题。我自己从06年实习以来。先后经历了4家软件公司。所有是外企。当中有世界500强的通信企业,有从事期权期货交易的欧洲中等规模的金融公司,也有为大型汽车制造商开发Android智能汽车的新兴公司。跨入IT行业以来。我…
open的O_DIRECT选项
http://blog.chinaunix.net/uid-223060-id-2127385.html http://blog.csdn.net/hhtang/article/details/6605951 查看磁盘分区: #df -h #tune2fs -l /dev/mapper/VolGroup-lv_root 或者 #dumpe2fs /dev/mapper/VolGroup-lv_root|grep -i "block size"…