AI四巨头Google、DeepMind、Microsoft、Uber深度学习框架大比拼
编者按:Google、Uber、DeepMind和Microsoft这四大科技公司是当前将深度学习研究广泛应用于自身业务的典型代表,跻身全球深度学习研究水平最高的科技公司之列。GPipe、Horovod、TF Replicator和DeepSpeed分别是这四家公司开发应用的深度学习框架,它们结合了深度学习研究及其基础设施的前沿技术,以提高深度学习模型的训练效率。这四个深度学习框架各有什么特点和优势?本文将对此做一个基本介绍。
作者 | Jesus Rodriguez
译者 | 苏本如,编辑 | 夕颜
出品 | CSDN(ID:CSDNnews)
大规模深度学习训练是在现实世界中构建深度学习解决方案最具挑战性的方面之一。 正如俗语所说,你最大的优点可以成为你最大的缺点,这一点自然也适用于深度学习模型。整个深度学习空间在一定程度上取决于深度神经网络(DNN)跨越GPU拓扑的能力。然而,同样的扩展能力导致了计算密集型程序的创建,这给大多数组织带来了操作上的挑战。从训练到优化,深度学习项目的生命周期需要健壮的基础设施构建块,以便能够并行化和扩展计算工作负载。
尽管深度学习框架正在快速发展,但相应的基础架构模型仍处于初期阶段。在过去的几年里,技术巨头谷歌、微软、优步(Uber)、DeepMind和其他公司定期发布了各自的研究成果,以便在大型GPU等基础设施上实现深度学习模型的并行化。
分布式和并行化计算的原理与深度学习程序生命周期的几乎所有阶段都息息相关。训练一个深度学习模型可能是一个非常昂贵的任务,运行也是如此。显而易见的答案是,可以利用大型GPU网络来分配深度学习程序的工作负载,但这绝非易事。众所周知,并发和并行编程是非常复杂的,尤其在应用于大型神经网络时更是如此。大型科技公司每天都在面临这些挑战,因为它们必须为关键业务应用运行极其复杂的深层神经网络。
今天,我想回顾一下谷歌、微软、DeepMind、和优步(Uber)等科技巨头用于并行化大规模深度学习模型训练的一些顶级框架。具体来说,我们将讨论以下四个框架:
谷歌的 GPipe
优步的Horovod
DeepMind的TF-Replicator
微软的 DeepSpeed
谷歌的GPipe
GPipe专注于为深度学习项目提高训练工作量。从基础设施的角度来看,训练过程的复杂性是深度学习模型中经常被忽视的一个方面。训练数据集越来越大,也越来越复杂。例如,在医疗保健领域,遇到需要使用数百万高分辨率图像进行训练的模型已不罕见。因此,训练过程通常需要很长的时间才能完成,并且由于内存和CPU消耗而导致的成本也非常高。
将深度学习模型的并行性分为数据并行性和模型并行性,是一种研究深度学习模型并行性的有效方法。数据并行方法使用大量的机器集群来拆分输入数据。模型并行性尝试将模型移至加速器上,如GPU或TPU,它们具有加速模型训练的特殊硬件。在较高的层次上,几乎所有的训练数据集都可以按照一定的逻辑进行并行化,但在模型上却不是这样。例如,一些深度学习模型是由可以独立训练的并行分支组成的。在这种情况下,经典的策略是将计算划分为多个分区,并将不同的分区分配给不同的分支。然而,这种策略在连续堆叠层的深度学习模型中存在不足,这给高效并行计算带来了挑战。
GPipe采用一种称为管道的技术,将数据和模型并行性结合起来。从概念上讲,GPipe是一个分布式机器学习库,它使用同步随机梯度下降和管道并行性进行训练,适用于任何由多个连续层组成的深度神经网络(DNN)。GPipe将一个模型划分到不同的加速器上,并自动将一个小批量的训练实例分割成更小的微批量。该模型允许GPipe的加速器并行运行,以最大限度地提高了训练过程的可伸缩性。
下图说明了具有多个连续层的神经网络的GPipe模型在四个加速器之间的划分。Fk是第k个划分的复合正向计算函数。Bk是对应的反向传播函数。Bk既依赖于上层的Bk+1,也依赖于Fk的中间激活。在图片的上部中,我们可以看到网络的顺序特性如何导致资源利用不足的。图片的下部显示了GPipe方法,其中输入的小批量(mini-batch)被划分为更小的宏批量(macro-batch),这些宏批量(macro-batch)可以由加速器同时处理。
谷歌开源了GPipe的一种实现,作为TensorFlow项目的一部分。
开源地址:https://github.com/tensorflow/lingvo/blob/master/lingvo/core/gpipe.py
优步的 Horovod
Horovod是Uber的机器学习(ML)堆栈之一,它已经在社区中非常流行,并且已经被DeepMind和OpenAI等人工智能巨头的研究团队采用。从概念上讲,Horovod是一个用于大规模运行分布式深度学习训练工作的框架。
Horovod利用诸如OpenMPI之类的消息传递接口栈,来使训练作业能够在高度并行和分布式的基础设施上运行,而无需进行任何修改。通过以下四个简单的步骤即可在Horovod中运行分布式TensorFlow训练工作:
hvd.init()初始化Horovod。
config.gpu_options.visible_device_list = str(hvd.local_rank())为每个TensorFlow进程分配一个GPU。
opt=hvd.DistributedOptimizer(opt)使用Horovod优化器包装任何常规的TensorFlow优化器,该优化器使用ring-allreduce来处理平均梯度。
hvd.BroadcastGlobalVariablesHook(0)将变量从第一个进程广播到所有其他进程,以确保一致的初始化。
下面这个代码示例是一个基本的TensorFlow训练作业的模板,你可以从中看到上面的四个步骤:
1import tensorflow as tf2import horovod.tensorflow as hvd# Initialize Horovod3hvd.init()# Pin GPU to be used to process local rank (one GPU per process)4config = tf.ConfigProto()5config.gpu_options.visible_device_list = str(hvd.local_rank())# Build model…6loss = …7opt = tf.train.AdagradOptimizer(0.01)# Add Horovod Distributed Optimizer8opt = hvd.DistributedOptimizer(opt)# Add hook to broadcast variables from rank 0 to all other processes during9# initialization.
10hooks = [hvd.BroadcastGlobalVariablesHook(0)]# Make training operation
11train_op = opt.minimize(loss)# The MonitoredTrainingSession takes care of session initialization,
12# restoring from a checkpoint, saving to a checkpoint, and closing when done
13# or an error occurs.
14with tf.train.MonitoredTrainingSession(checkpoint_dir=“/tmp/train_logs”,
15 config=config,
16 hooks=hooks) as mon_sess:
17 while not mon_sess.should_stop():
18 # Perform synchronous training.
19 mon_sess.run(train_op)DeepMind的TF-Replicator
TF-Replicator专注于TensorFlow程序如何利用Tensor处理单元(TPU)有关的可伸缩性的另一个方面。TPU被认为是最先进的人工智能芯片之一,它为机器学习工作负载提供了本机可扩展性。然而,在TensorFlow程序中使用TPU需要专门的API,这会给不熟悉底层硬件模型的数据科学家们带来可移植性问题和采用障碍。DeepMind的TF Replicator通过提供一个更简单、对开发人员更友好的编程模型来利用TensorFlow程序中的TPU,从而解决了这一难题。
TF-Replicator的魔力依赖于一种“图内复制(in-graph replication)”模型,其中每个设备的计算被复制到同一张TensorFlow图中。设备之间的通信是通过连接设备对应子图中的节点来实现的。为了达到这种级别的并行化,TF-Replicator利用TensorFlow的图重写模型在图中的设备之间插入本机通信。当呈现一个TensorFlow图时,TF Replicator首先独立地为每个设备构建计算,并在用户指定跨设备计算的地方留下占位符。一旦构建了所有设备的子图,TF Replicator就会用实际的跨设备计算替换占位符来连接它们。
从编程模型的角度来看,使用TF-Replicator编写的代码看起来类似于为单个设备编写的本机TensorFlow代码。用户只需定义:(1)一个公开数据集的输入函数,和(2)一个定义其模型逻辑的阶跃函数(例如,梯度下降的单个阶跃)。下面的代码片段展示了一个简单的TF-Replicator程序:
1# Deploying a model with TpuReplicator.2repl = tf_replicator.TpuReplicator(3num_workers=1, num_tpu_cores_per_worker=84)5with repl.context():6model = resnet_model()7base_optimizer = tf.train.AdamOptimizer()8optimizer = repl.wrap_optimizer(base_optimizer)# ... code to define replica input_fn and step_fn.per_replica_loss = repl.run(step_fn, input_fn)9train_op = tf.reduce_mean(per_replica_loss)with tf.train.MonitoredSession() as session:
10repl.init(session)
11for i in xrange(num_train_steps):
12session.run(train_op)
13repl.shutdown(session)为了优化不同设备之间的通信,TF-Replicator利用了最先进的MPI接口。在一些实验中,DeepMind能够在一个TPUv3 pod的512个核心上,以2048的batch size批量训练著名的BigGAN模型。目前,TF-Replicator是DeepMind公司的TPU的主要编程接口。
微软的DeepSpeed
微软的DeepSpeed是一个新的开源框架,专注于优化大型深度学习模型的训练。当前版本包含了ZeRO的第一个实现以及其他优化方法。从编程的角度来看,DeepSpeed是在PyTorch之上构建的,它提供了一个简单的API,允许工程师只需几行代码就可以利用并行化技术来进行训练。DeepSpeed抽象了大规模训练的所有困难方面,例如并行化、混合精度、梯度累积和检查点,使得开发人员可以专注于模型的构建。
从功能角度来看,DeepSpeed在以下四个关键方面表现出色:
规模:DeepSpeed可以为运行高达1,000亿个参数的模型提供系统支持,这和其他训练优化框架相比,提高了10倍。
速度:在最初的测试中,DeepSpeed表现出的吞吐量比其他库高出4-5倍。
成本:可以使用DeepSpeed进行训练的模型,其成本比其他替代方案少三倍。
可用性:DeepSpeed不需要重构PyTorch模型,仅需几行代码即可使用。
将深度学习模型的训练并行化是一项非常复杂的工作,超出了大多数机器学习团队的专业知识。利用谷歌、微软、优步或DeepMind等科技公司创建的框架和架构,肯定可以简化这些工作。
在不久的将来,我们希望看到这些框架的一些版本包含在主流深度学习堆栈中,以加速核心深度学习社区准入的民主化。
原文链接:
https://towardsdatascience.com/the-frameworks-that-google-deepmind-microsoft-and-uber-use-to-train-deep-learning-models-at-scale-30be6295725
欢迎所有开发者扫描下方二维码填写《开发者与AI大调研》,只需2分钟,便可收获价值299元的「AI开发者万人大会」在线直播门票!
推荐阅读
GitHub标星2000+,如何用30天啃完TensorFlow2.0?
斩获GitHub 2000+ Star,阿里云开源的Alink机器学习平台如何跑赢双11数据“博弈”?
百年 IBM 终于 All In 人工智能和混合云!
微软为一人收购一公司?破解索尼程序、写黑客小说,看他彪悍的程序人生!
机器学习项目模板:ML项目的6个基本步骤
BM、微软、苹果、谷歌、三星……这些区块链中的科技巨头原来已经做了这么多事!
你点的每个“在看”,我都认真当成了AI
相关文章:

转《刘润的数字化家庭》
数字家庭也是我的一大梦想,感谢刘润让我的想法更加丰富和具体。。。 转载自刘润的博客,原文地址:http://blog.run2me.com/runliu/archive/2010/06/12/37082.aspx 1 of 22 (大图):用数字化的技术,…

自己写的内存池Slabs
看memcached的源码写的,虽然很粗糙,但是基本思想还是有的,自娱自乐,后期不断改进。 #include <stdio.h> #include <stdlib.h> #include <string.h>struct st{void * start;void * end;char ptr[10]; }; struct …
Eclispse Che(2):启动Che服务,进入IDE界面
本文的原文连接是: http://blog.csdn.net/freewebsys/article/details/50888878 未经博主允许不得转载。 博主地址是:http://blog.csdn.net/freewebsys 1,关于Docker 上次使用Che的时候没有成功创建Project。 其实主要问题就是docker的网络问题。 使用…

使用strace和ltrace跟踪程序调用
ltrace能够跟踪进程的库函数调用,它会显现出哪个库函数被调用,而strace则是跟踪程序的每个系统调用.1.系统调用的输出对比程序代码:#include <stdio.h> main(){char str[] "Abcde";printf("\n string %s length %d \n",str,str_length(…

NeHe OpenGL第三十三课:TGA文件
NeHe OpenGL第三十三课:TGA文件 加载压缩和未压缩的TGA文件: 在这一课里,你将学会如何加载压缩和为压缩的TGA文件,由于它使用RLE压缩,所以非常的简单,你能很快地熟悉它的。 我见过很多人在游戏开发论坛或其它地方询问…

阿里自动驾驶新突破!达摩院自研ISP图像处理器大幅提升安全性
阿里巴巴达摩院在自动驾驶领域取得新突破!4月8日,据记者了解,达摩院已经自主研发出用于车载摄像头的ISP处理器,保障自动驾驶车辆在夜间拥有更好的“视力”,“看”得更清晰,从而大幅提升自动驾驶安全性, 而背…

3月14号作业
<!DOCTYPE html> <html> <head lang"en"><meta charset"UTF-8"><title></title> </head> <body> <br/> <br/> <img src"51job表单_03.gif"</br> <br/> <br/>…

NeHe OpenGL第三十五课:播放AVI
NeHe OpenGL第三十五课:播放AVI 在OpenGL中播放AVI: 在OpenGL中如何播放AVI呢?利用Windows的API把每一帧作为纹理绑定到OpenGL中,虽然很慢,但它的效果不错。你可以试试。 首先我得说我非常喜欢这一章节.Jonathan de Blok使我产生…

为什么TCP的TIME_WAIT状态要保持2MSL?
TIMEWAIT状态也称为 2MSL等待状态。每个具体TCP实现必须选择一个报文段最大生存时间MSL(Maximum Segment Lifetime)。它是任何报文段被丢弃前在网络内的最长时间。我们知道这个时间是有限的,因为TCP报文段以IP数据报在网络内传输,而IP数据报则有限制其生…
深度 | 一文读懂“情感计算”在零售中的应用发展
作者 | 黄程韦博士、刘刚、包飞博士、杨现博士、孙皓博士、沈艺博士来源 | 苏宁零售技术研究院零售商需要不断通过创新服务来提高顾客的购物体验,而情感计算在该领域具有独特优势。它在零售行业的应用,主要集中在提升购物体验的服务中。在这个科技逐步改…

mysql基于replication实现最简单的M-S主从复制
2019独角兽企业重金招聘Python工程师标准>>> 什么是replication Replication可以实现数据从一台数据库服务器(master)复制到一到多台数据库服务器。 默认情况下,属于异步复制,因此无需维持长连接。 通过配置࿰…
Linux下高并发socket最大连接数所受的各种限制
修改最大打开文件数 # ulimit -n 修改最大进程数 # ulimit -u ------------------------------------------------------ Linux下高并发socket最大连接数所受的各种限制 转自:http://blog.csdn.net/guowake/article/details/6615728 1、修改用户进程可打开…
linux安全问答(1)
一、如何限制对系统资源的过度使用? (1)、编辑/etc/security/limits.conf文件,在其中加入或改变下面这些内容: * hard core 0 //禁止创建core文件 * hard rss 5000 //表示除root用户之外,其他用户都只能最多…
快速搭建对话机器人,就用这一招!
作者 | Milvus.io 责编 | 胡巍巍问答系统是自然语言处理领域一个很经典的问题,它用于回答人们以自然语言形式提出的问题,有着广泛的应用。其经典应用场景包括:智能语音交互、在线客服、知识获取、情感类聊天等。常见的分类有:生成…
目前流行的源程序版本管理软件和项目管理软件都有哪些?各有什么优缺点?...
目前流行的源程序版本管理软件和项目管理软件:Microsoft TFS,Github,SVN,Coding 各自的优缺点: Microsoft TFS:优点:任务版上能将需求、项目进度一览无余,对于小团队而言,…
孙鑫mfc学习笔记第十四课
第十四课网络的相关知识,网络程序的编写,Socket是连接应用程序与网络驱动程序的桥梁,Socket在应用程序中创建,通过bind与驱动程序建立关系。此后,应用程序送给Socket的数据,由Socket交给驱动程序向网络上发…

Linux环境编译安装Mysql以及补装innodb引擎方法
mysql安装 5.6以后可能会收费,所以选择5.1以下从台湾中山大学镜像下载 1.首先要安装C编译环境 # yum install gcc-c 2.下载解压 # wget http://mysql.cdpa.nsysu.edu.tw/Downloads/MySQL-5.1/mysql-5.1.73.tar.gz# tar zxvf mysql-5.1.73.tar.gz# cd mysql-5…
Python 炫技操作:合并字典的七种方法
来源 | Python编程时光(ID: Cool-Python)Python 语言里有许多(而且是越来越多)的高级特性,是 Python 发烧友们非常喜欢的。在这些人的眼里,能够写出那些一般开发者看不懂的高级特性,就是高手&am…

shell脚本编程基础(1)及RAID阵列
shell脚本:Linux从底层到上层的系统架构:硬件-->内核-->库(lib)-->shell-->用户。shell既是一种命令语言,也是程序设计语言(shell脚本),作为一种命令语言,它提供了用户与内核的交互…
freemarker基本语法及实例
EG.一个对象BOOK 1.输出 ${book.name} 空值判断:${book.name?if_exists }, ${book.name?default(‘xxx’)}//默认值xxx ${ book.name!"xxx"}//默认值xxx 日期格式:${book.date?string(yyyy-MM-dd)} 数字格式:${boo…
前百度主任架构师创业,两年融资千万美元,他说AI新药研发将迎来黄金十年...
「AI技术生态论」 人物访谈栏目是CSDN发起的百万人学AI倡议下的重要组成部分。通过对AI生态专家、创业者、行业KOL的访谈,反映其对于行业的思考、未来趋势的判断、技术的实践,以及成长的经历。2020年,CSDN将对1000人物进行访谈,形…
Linux环境安装卸载JDK以及安装Tomcat和发布Java的web程序
Linux环境:CentOS7.2 一.安装JDK 安装好的CentOS会自带OpenJdk,最好还是先卸载系统自带的JDK,然后自己重新去Oracle网站下载最新的JDK安装。 1.卸载系统自带的JDK 查看java信息 # java -version 查看JDK # rpm -qa | grep java 或者 还…
(转)详解css3弹性盒模型(Flexbox)
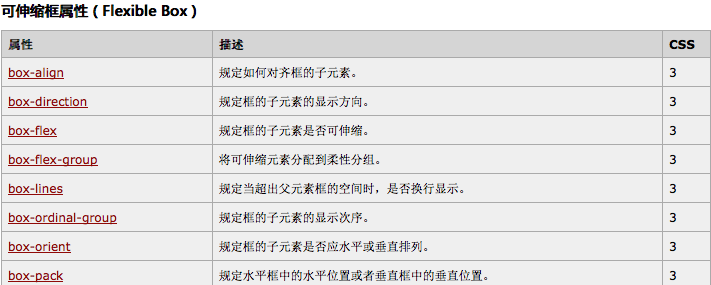
今天刚学了css3的弹性盒模型,这是一个可以让你告别浮动、完美实现垂直水平居中的新特性。 Flexbox是布局模块,而不是一个简单的属性,它包含父元素和子元素的属性。 Flexbox布局的主体思想是似的元素可以改变大小以适应可用空间,当…
Java开发环境的搭建以及使用eclipse创建项目
一、Java 开发环境的搭建 这里主要说windows环境下怎么配置Java环境。如果是Linux环境参考本博客另一篇文章即可: Linux环境安装卸载JDK 1.首先安装JDK java的SDK简称JDK。 去官网下载最新的JDK即可: http://www.oracle.com/technetwork/java/javase…
MMIT冠军方案 | 用于行为识别的时间交错网络,商汤公开视频理解代码库
作者 | 商汤出品 | AI科技大本营(ID:rgznai100)本文主要介绍三个部分:一个高效的SOTA视频特征提取网络TIN,发表于AAAI2020ICCV19 MMIT多标签视频理解竞赛冠军方案,基于TIN和SlowFast一个基于PyTorch,包含大…
MySQL的主从服务器配置
MySQL的主从服务器配置常见开源数据库有:MySQL,PostgreSQL,SQLite等,商业性质的:Oracle,Sql Server,DB2,Sybase,Infomix其中,Oracle的版本有Oracle 11g,Oracl…
Anaconda中安装Orange3脚本-完整版
2019独角兽企业重金招聘Python工程师标准>>> #Anaconda中安装Orange3脚本,完整版。包括插件的安装,在脚本中一次完成。 sudo apt-get update sudo apt-get -y install git python-pip python-virtualenv python-qt4-dev python3-pyqt4 libqt…
使用eclipse创建Struts2项目
eclipse版本: Kepler Service Release 1 http://www.eclipse.org/downloads/ struts版本:2.3.16 http://struts.apache.org/ 1.新建web项目 打开Eclipse,新建一个web项目"Struts2" 项目名字 勾选 web.xml选项 建好的…
8、进程通信-匿名管道
匿名管道 一个单向,未命名的管道,通常用来在一个父进程和一个子进程间传输数据。只能实现本地机器上两个进程间的通信,而不能实现跨网络的通信。 BOOL CreatePipe( PHANDLE hReadPipe, // read handle PHANDLE hWriteP…
Enhanced-RCNN: 一种高效的比较句子相似性的方法 |WWW 2020
作者 | 彭爽出品 | AI科技大本营(ID:rgznai100)国际顶级会议WWW2020将于4月20日至24日举行。始于1994年的WWW会议,主要讨论有关Web的发展,其相关技术的标准化以及这些技术对社会和文化的影响,每年有大批的学者、研究人…