降低预测过程计算成本,这些NLP模型压缩方法要知道
编译 | 凯隐
出品 | AI科技大本营(ID:rgznai100)
近年来,基于谷歌Transformer的语言模型在神经机器翻译,自然语言推理和其他自然语言理解任务上取得了长足进展。
通过多种语言模型的平均损失进行自我监督预训练,使得在大范围的语料库上训练的模型可以在许多任务中提高下游性能。然而,大量的参数和计算量仍然是阻碍BERT和其衍生模型部署的难点。
值得庆幸的是,在过去的两年里,我们已经看到了各种各样的技术,可以缩短模型在进行实际预测时消耗的时间。因此,这篇文章主要着眼于在基本模型预训练后可以用于降低预测过程计算成本的方法,主要包含以下方法:
数值精度约简:通过降低计算过程中使用的浮点数精度(浮点约简)和量化,来加速计算。
计算融合:在计算图中选择节点并进行合并的技巧。
网络修剪: 识别和删除网络中不重要的部分。
知识提炼: 训练更小的,效率更高的模型来模仿表现力更强,同时计算成本更高的大模型。
模块替换:通过替换部分模块来降低模型的深度和复杂度。
数值精度约简
数值精度约简可能是为模型带来预测加速最通用的方法。在过去几年GPU对16位浮点操作的支持性很差,这意味着降低权重和激活值的精度往往不会带来加速,甚至造成减速。英伟达(Nvidia)Volta和图灵张量核架构的引入在一定程度上解决了这个问题,让GPU能够更好的实现高效的16位浮点精度运算。
1、浮点数的表示
浮点类型数据主要存储三种类型的数值信息:符号,指数,分数。传统的32位浮点表示法分别用8位和23位来表示指数和分数(剩下一位应该表示正负),而传统的16位表示法(用于NVIDIA硬件的格式)将32位表示法中的指数和分数部分大致减半。相对于GPU而言,TPU(张量处理单元)则使用一种称为bfloat16的变体,它可以选择将一些位从分数移动到指数,即牺牲一定的精度来换取表示更大范围的值的能力。
三种不同的浮点数表示方法
Transformer网络的大部分结构都可以直接转换为16位浮点数的权重和激活值,且不会带来计算准确率的下降。而网络的一小部分,特别是softmax操作部分必须保留为32位浮点精度。这是因为大量的小数值(我们的logits)累积起来就可能成为错误的来源。由于这样做同时使用了16位和32位精度的浮点数值,因此这种方法通常称为“混合精度”。
低精度的数值表示主要可以从两方面实现加速:
(1)机器自带的半精度指令(速度更快)
(2)更大的batch size(得益于更紧凑的表示)
NVIDIA已经发布了一套相当广泛的与浮点精度降低相关的基准测试——实际上,这种方法可以使速度提高3倍。
链接:https://github.com/NVIDIA/DeepLearningExamples
2、整型量化
32位浮点到8位整数型值的量化也能实现加速,但需要更细节的实现。特别的,为了确保8位整型的计算结果与32位浮点计算结果尽可能相同,还需要在训练后对输入进行校准。
如果已经知道网络激活值可能所占用的范围,可以将该范围划分为256个离散块,并将每个块分配给一个整数。只要存储了比例因子和占用的范围,就可以使用整数近似来进行矩阵乘法,并将乘法输出恢复为浮点值。
两种不同的整型量化方法
一种简单的整型量化方法,如上图右侧,首先选择一个范围和偏移量,这样就不会将校准后的输入浮点激活值激活映射到unit8值(-128,127)两端的整数。但这种做法在适应两端极值的同时牺牲了一些精度。如上图左侧,为了解决这个问题,TensorRT之类的框架会选择合适的scale和offset值,以最小化模型的32位浮点版本和8位整型版本的输出激活值之间的KL差异。这使我们能够以合理的方式在取值范围和计算精度之间权衡取舍。由于KL散度可以被看作激活值在不同编码(不同精度可以看做不同编码)下的信息损失的度量,因此是一种自然合理的度量方式。
关于如何使用英伟达TensorRT来将8位整型量化应用到个人模型的更多详细细节,可以参考一下链接:
https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html
https://github.com/tensorflow/tensorrt
3、网络层融合与计算图优化
除了浮点数约简和整型量化外,操作融合提供了一个实用的,通用的选择来实现更高效的预测。操作融合的基本原理是将计算流程中若干层所执行的操作进行合并,以避免对全局设备存储器的冗余访问,进而提高执行效率。通过将多个计算操作合并到一个内核中,可以加速内存读写速度。
操作合并示例
如上图,我们可以将添加的skip连接与层规范化操作(LN)的比例(scale)和偏差(bias)合并在一起。
软件优化允许我们重构一些矩阵乘法操作以更好地进行计算并行话。如下图,我们可以将self-attention层的查询向量(Query)、键向量(Key)和值向量(Value)的计算投影合并到一个矩阵乘法中。
对自注意力层进行优化示意图
遗憾的是,从这类计算流程图优化中很少看到关于加速幅度的详细信息,但这种改进仍然是有效的,大约有10%的吞吐量提升。
网络修剪
除了纯粹的软件层面优化,还有其他许多方法可用来修剪网络结构,删除对最终模型贡献小的权重。许多剪枝方法(如Fan等人提出的"Reducing Transformer Depth on Command With Structured Dropout")需要在训练前对网络进行修改,以生成足够稀疏的模型,并在训练后进行剪枝。剪枝文献中的其他论文聚焦于在没有具体预测目标的情况下,模型所学习的连接模型如何才能更加稀疏。(例如Gorden等人提出的"Compressing BERT: Studying the Effects of Weight Pruning on Transfer Learning")
虽然这些方法本身都很有意义(而且结构化的删除部分层的方法在实际应用中有重要前景),但更有趣的是一种能以特定方式应用并且仍然能获得性能提升的方法。这类方法基于一个公认事实来对模型进行修剪,即解决特定任务只需要模型的一部分。
为了获得经验上的模型性能提升而进行修剪需要结构化的稀疏性。简单地将单个权值归零并不足以获得性能提升,因为我们没有实际的方法来利用这种稀疏性。因此,我们必须设法砍掉网络中的大部分结构,以获得实际的性能提升。
注意力头剪枝
在文献"Are Sixteen Heads Really Better than One?"中,作者通过迭代的方法从BERT模型中逐步去除注意力头(attention head)。他们使用了一种基于梯度检测的方法(对下游任务进行梯度估计)来估计每个注意力头的重要性,并通过绘制性能--去除的注意力头所占百分比函数来测试模型对注意力头剪枝的鲁棒性。
如下图,在实践中,作者发现20 - 40%的注意力头可以修剪,且对模型准确性的影响可以忽略不计。
基于门控的模型修剪
在J.S. McCarley,Rishav Chakravarti和Avirup Sil合著的《Structured Pruning of a BERT-based Question Answering Model》一书中,坐着探索了一种更通用的模型剪枝方法。不仅关注注意力头,还对每一层的输入以及每一BERT层的前馈层的激活值进行了门控。
他们探索了一些距离度量机制,从而有选择的对网络进行修剪,这包括Michel等人提出的重要措施。但最终确定了一个L0正则化项(添加到损失函数中),并且该项可以在超参调优时进行设置(作为超参数之一),来提高模型的稀疏性。为了使这个L0正则化项可微,他们使用了一个类似于在变分自动编码器中使用的重参数化技巧。
在他们的实验中他们发现通过正则化项进行稀疏惩罚,并通过参数调优得到的结果优于“Are 16 Heads Really Better than 1”使用的基于重要性的估计方法,并且他们发现可以另外删除近50%的前馈激活值,且在基准任务上对最终性能影响微乎其微。
为了获得更多提升,作者还使用了知识蒸馏技术。
知识蒸馏
1、发展历史
知识蒸馏首先由Geoffrey Hinton, Oriol Vinyals, 和 Jeff Dean 在2015年的工作"Distilling the Knowledge in a Neural Network"中提出。知识蒸馏主要通过损失修正的方法,将教师模型中包含的知识迁移到学生模型中。
首先,假设我们可以访问大量未标记的样本。如果我们相信教师模型的预测结果是足够准确的,但是教师模型在实际应用中部署使用太麻烦或计算成本太昂贵,我们可以使用教师模型来预测未标记样本池中的目标类,并将这些目标作为监督样本用于学生模型的训练。如果不是生成与最大可能性类相对应的硬目标,而是生成所有可能类的概率分布,那么学生模型将获得更多的信息丰富的监督样本。
直观来讲,学生模型的一些预测错误比其他错误更加合理,如下图,将哈士奇误认为勺子是荒谬的,但是将哈士奇误认为雪橇犬则是合理的。即设置的损失函数应该反映错误的严重程度。通过惩罚教师模型预测结果和学生模型预测之间的差异(即鼓励二者预测结果相同),学生网络可以从教师网络给出的预测中学习更多有意义的信息。在语音识别任务中,教师网络的大部分网络性能可以通过仅约3%的训练数据来重现。
有证据表明高参数量可能对样本的有效学习至关重要,而且,就相同时间而言,以一个固定的复杂度训练大型模型可能比训练一个等价的紧凑模型效果更好。因此有效地把教师模型学到的知识传递给被压缩的学生模型是很有前途的。
2、相似模型的知识迁移
在上面讨论文章"Structured Pruning of a BERT-based Question Answering Model"中,通过知识蒸馏将未修剪的教师模型中包含的知识传递给修剪过的学生模型。在自然问题数据集上,教师模型在长答案和短答案问题上的F1分数分别为70.3和58.8。随着大约50%的注意力头和前馈激活值的削减,F1分说分别下降到67.8和55.5,即大约有2.5的下降。但如果用蒸馏损失来代替超参调优过程中的交叉熵损失,那么性能将恢复1.5到2个点,达到69.3和58.4。
不同的模型压缩方法带来的性能损失对比
由Victor Sanh,Lysandre starter,Julien Chaumond和Thomas Wolf提出的“DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter”,在一个语言建模任务的二级预训练步骤中,从基本BERT模型向一个6层的BERT压缩后的学生模型执行知识蒸馏。学生模型(以任务不可知的方式训练)在GLUE基准测试上保持了97%的模型性能,同时减少了60%的预测时间。
在文章“TinyBERT: Distilling BERT for Natural Language Understanding”中,作者采用了从BERT模型到一个4层,隐藏神经元个数为312的学生模型的知识蒸馏与迁移。他们在预训练和调参时都进行了迁移,得到的模型在GLUE基准测试上的达到了BERT-base性能的96%,且模型相对于BERT-base缩小了7.5倍,预测推断速度提高了近10倍。
在文章"Patient Knowledge Distillation for BERT Model Compression"中,作者将知识蒸馏损失函数应用于12层BERT教师模型以及6层学生模型,这在大约5/6的GLUE任务中得到了精度提升(相对于仅将知识蒸馏应用于模型本身)。
3、不同结构模型的知识迁移
在目前讨论的论文中,教师模型和学生模型具有相同的基本架构,学生模型通常使用教师模型的权重来进行初始化。然而,即使在教师和学生模型结构差异很大的情况下,也可以应用知识蒸馏损失来让二者的预测结果相近,从而将教师模型学习到的知识迁移到学生模型。
在文章"Training Compact Models for Low Resource Entity Tagging using Pre-trained Language Models"中,作者首先在命名实体识别任务上训练了一个BERT教师模型(参数量约330M),然后将其迁移到一个更紧凑更高效的CNN-LSTM学生模型上(参数量约3M),这样做使得他们在CPU硬件上以最小的精度损失实现了高达2个数量级的速度提升。
在文章"Distilling Transformers into Simple Neural Networks with Unlabeled Transfer Data"中,作者将BERT-Base和BERT-Large迁移到一个双向LSTM学生模型上,使得学生模型在4种分类任务(Ag News, IMDB, Elec, and DBPedia)上都能达到和教师模型相同的准确度,且参数量削减为13M。他们还发现蒸馏使得样本效率大大提高,每个任务只需要用大约500个带标签的样本进行训练,就能让学生模型达到和教师模型相同的水平(提供足够的未标记样本进行测试)。
在文章"Distilling Task-Specific Knowledge from BERT into Simple Neural Networks"中,作者Lin报告了在使用参数小于1M的单层BiLSTM执行各种句子配对任务(QQP、MNLI等)时的类似结果。
在文章"Attentive Student Meets Multi-Task Teacher: Improved Knowledge Distillation for Pretrained Models"中,作者将多任务学习与知识蒸馏相结合,将Transformer教师模型通过注意力机制迁移到deep LSTM学生模型上。文章指出,从知识蒸馏中得到的提升与多任务学习框架带来的泛化提升是一样的,并且预测速度是纯粹知识精馏的30倍,是TinyBERT的7倍。
知识蒸馏是最近很流行的方法,原因很明显——它很可能成为许多基于Transformer的语言模型应对逐渐增加的参数量的有效方法。如果我们想要尽可能地利用GPU,那么我们就需要通过知识蒸馏这样的方法来保持高预测速度。
模块替换
将要介绍的最后一篇论文有两个特点,一是采用了一种更新颖的模型压缩方法,二是与下面展示的现代艺术作品一起发表:
“BERT-of-Theseus:Compressing BERT by Progressive Module Replacing”是由Canwen Xu等提出的工作,不同于之前的工作仅训练一个单独的学生模型来最小化知识蒸馏损失,BERT-of-Theseus在调试阶段随机地用一个新的模块(后继模块)来替换原来的模块(前继模块),且在每个训练批次都随机替换。
BERT-of-Theseus是思想实验“Ship of Theseus”的一个版本,该实验探究的是一艘船经过一点一点的修复和升级后,是否仍然是原来的物体。BERT-of-Theseus将这种逐步替换思想应用到模型压缩的思想中。
后继模块通常是前继模块的廉价版本——在本例中,单个变压器层替换了一个由2个变压器层组成的块。与知识蒸馏不同,这里没有使用损失来鼓励后续模块模仿它们的前辈,而只是通过简单的让继任模块和前任模块可以互换使用,使得继任者学习模仿前任的行为。
这种隐式模仿行为的一个优点是,我们不再需要选择如何重量各种知识蒸馏损失目标模型的损失,不同于知识蒸馏使用的L0正则化损失 ,不存在二次训练的步骤,与下游整合压缩并发执行。最后,渐进式模块替换方法也适用于整个模型结构,且它在设计中没有利用Transformer模型的任何特定特性,因此泛化能力更强。
作者用线性学习率变化策略进行了实验,发现随着时间的推移,线性增加的模块替换率比恒定的替换率效果更好。
为了测试这种方法的鲁棒性,作者在将BERT-base应用到GLUE基准测试时使用了Theseus压缩,并且轻松地超过了其他几个基于知识蒸馏的方法,这些方法在将原始模型压缩到50%的大小时,常常落后于BERT-base不到1个点。
渐进式模块替换很有吸引力的部分原因是它提供了一种新的训练方法,可以用其他方法进行试验来增加模型吞吐量,而这些方法通常需要对scratch进行重新训练。对于独立的研究人员和较小的公司来说,从头开始重新培训transformer模型通常是很困难的,因此很难利用那些提出了提高模型效率的有用想法但没有发布预先培训过的模型的论文(即没有开源的论文)。
论文地址:
https://arxiv.org/pdf/2002.11985.pdf
相关链接地址:
http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
推荐阅读
那个分分钟处理 10 亿节点图计算的 Plato,现在怎么样了?
看似毫不相干,哲学与机器学习竟有如此大的交集
黑客用上机器学习你慌不慌?这 7 种窃取数据的新手段快来认识一下
“谷歌杀手”发明者,科学天才 Wolfram
数据库激荡 40 年,深入解析 PostgreSQL、NewSQL 演进历程
5分钟!就能学会以太坊 JSON API 基础知识
你点的每个“在看”,我都认真当成了AI
相关文章:

政府要尽快对应用商店出台管理办法
前两天联想的开发者大会,我和联想的CTO贺志强先生联合接受了一个视频访谈,贺先生谈到联想的乐园软件商店,组织大量的人力对于软件进行检测,以保证软件是合格产品,不会给用户一路带来侵害,对于联想这种负责态…
antlr-2.7.6.jar的作用
项目中没有添加antlr-2.7.6.jar,hibernate不会执行hql语句 并且会报NoClassDefFoundError: antlr/ANTLRException错误
junit集成Hamcrest测试集合中某个属性是否包含特定值
junit已经集成Hamcrest但是还是需要引用hamcrest-library,不然只有基本方法,高级的没有 <dependency> <groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test<…
腾讯第100个开源项目:微信开源推理加速工具TurboTransformers
出品 | AI科技大本营(ID:rgznai100)4月24日,腾讯正式宣布开源Transformer推理加速工具TurboTransformers。该工具面向自然语言处理领域中Transformers相关模型丰富的线上预测场景,在微信、腾讯云、QQ看点等产品的线上服务中已经广…

程序员:提高编程效率的技巧
本文写给那些认为在项目上所花时间和效率成正比的程序员。我要说的是,事实并非如此。虽然你需要在电脑前敲键盘输入东西,但这只和编程沾上一点边。那么,程序员该如何利用时间呢? 俗话说,磨刀不误砍柴工,拿出…

Qunee for HTML5 V2.5新版本发布
为什么80%的码农都做不了架构师?>>> Qunee for HTMl5 V2.5 beta2版本正式发布,此次版本内核改动较大,采用了新的2D渲染引擎,增加了延迟绘制功能,大幅改善画布的浏览体验,此外重构了鼠标键盘以及触控交互监听处理,增加右键框选功能,改善了多点触控交互,增…
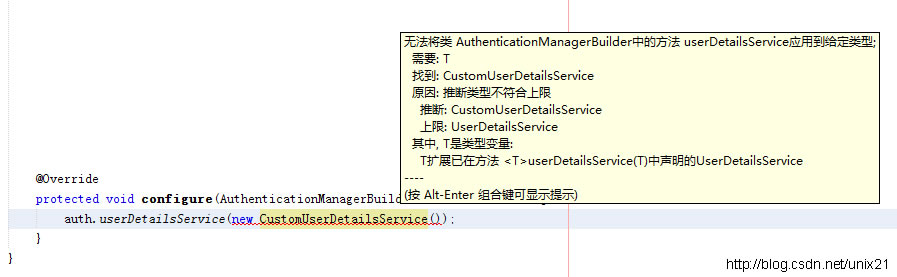
泛型推断类型不符合上限
程序报错推断类型不符合上限 springsecurity需要自定义用户服务 代码 Overrideprotected void configure(AuthenticationManagerBuilder auth) throws Exception {auth.userDetailsService(new CustomUserDetailsService());}public class CustomUserDetailsService implemen…
如何通过深度学习,完成计算机视觉中的所有工作?
Mask-RCNN做对象检测和实例分割作者 | George Seif译者 | 天道酬勤,责编 | Carol出品 | AI科技大本营(ID:rgznai100)Mask-RCNN做对象检测和实例分割:https://miro.medium.com/max/1200/1*s9raSe9mLeSSuxE3API-ZA.gif你想做计算机视…
Windows PowerShell 2.0语言之字面类型系统
PowerShell语言允许通过一个字面类型(type Literals)来访问类型,它是用括号抬起的类型名,返回.NET底层的System.Type对象实例,如: PS C:\> [System.Int32]IsPublic IsSerial Name …
建立名称server
一、实验的目的:实现DNSserver功能,提供正向、反向解析二、实验环境装有Linux的Windows系统IP为192.168.6.3的虚拟机三、实验目的建立gr.org域的主名称server。解析:名称 IP 用途ns.gr.org 192.168.…
Java的JSON操作存储List到Redis
使用jackson和json-lib都可以 <dependency> <groupId>org.codehaus.jackson</groupId><artifactId>jackson-mapper-asl</artifactId><version>1.9.13</version></dependency><dependency><groupId>net.sf.json-li…
关注基于云的下一代应用开发
接受经济和信息化的视频专访专访的主页地址为:http://www.enicn.com/article/2010-08-20/0R064b52010.shtml我的其他视频,请参考土豆空间,地址为http://www.tudou.com/home/larryvmw。
确认了!MySQL 狠甩 Oracle 稳居 Top1!
01几乎所有程序员都会用到的 MySQL稳居 Top 1科技长河,顺之者昌,错失者亡。在2019年,CSDN面向具备超强计算力的数字化世界,我们进行了「大数据技术应用现状分析」,并发布了《2019-2020 年中国开发者调查报告》。发现&a…
[AWK]使用AWK进行分割字符串以及截取字符串
如何split当前的字符串,用$0,例如: cat num.2012032911 | awk {print $2} | awk {split($0,b,".");print b[2]} | cut -c 3- 获取第二列,例如第二列是com.sb3456.you那么在split当前的这个字符串获得sb3456,最后截取sb3…

SpringMVC集成Tiles布局引擎框架
Tiles布局框架, http://tiles.apache.org/ Spring已经对Tiles进行了集成。页头页尾公共模板页要靠这个,不然重复代码太多。 <dependency><groupId>org.apache.tiles</groupId><artifactId>tiles-servlet</artifactId><…

VC 文件操作(文件查找,打开/保存,读/写,复制/删除/重命名)
右击项目->属性->字符集:使用多字节字符集。这样可以使用char到CString的转化。char sRead[20] ""; CString strtest sRead; 大气象 //文件查找/*CString strFileTitle;CFileFind finder;BOOL bWorking finder.FindFile(_T("C:\*.sys"…
程序员会懂的冷笑话:各大编程语言的内心独白
作者 | Anupam Chugh译者 | 弯月,责编 | 夕颜出品 | CSDN(ID:CSDNnews)软件工程领域鱼龙混杂。有些人乐不思蜀,而有些人则饱受打击。然而,构建软件的工作让每个人倍感压力,这点毋庸置疑。在本文…
swift集成alamofire的简单封装
import UIKit import Alamofire enum MethodType{ case GET case POST } class NetworkTool: NSObject { class func request(type : MethodType ,urlString : String , paramters: [String :Any]? nil,finishedCallback : escaping (_ result : Any) -> ()) { //判断是什…
Go后台项目架构思考与重构 | 深度长文
作者 | 腾讯云后台工程师黄雷编辑 | 唐小引来源 | CSDN(ID:CSDNnews)引言本文首先介绍了架构的重要性,随后从一个实际项目的重构过程作为主线,逐步引出主流的架构设计思想以及其所解决的实际问题是什么。通过阅读本文&…
前途到底是网络工程还是程序设计
本人89年年底生的,现在快满21了,大二的时候过的国家网络工程师考试,并不是cisco的网络支持工程师,大三也就是现在,在学校花销太大,想自己赚点钱,于是在学校招聘会上应聘了一家通信公司ÿ…
FAIL - Deployed application at context path / but context failed to start
IDE报错:FAIL - Deployed application at context path / but context failed to start 编译通过,这个错误原因是很多地方被误用,导致Spring运行时不能解析某些Class导致, 例如:ModelAndView用错 public ModelAndView…

项目ITP(五) spring4.0 整合 Quartz 实现任务调度
2014-05-16 22:51 by Jeff Li 前言 系列文章:[传送门] 项目需求: 二维码推送到一体机上,给学生签到扫描用。然后须要的是 上课前20分钟 。幸好在帮带我的学长做 p2p 的时候。接触过。自然 quartz 是首选。所以我就配置了下,搞了个…

Spring security防止跨站请求伪造(CSRF防护)
因为使用了spring security 安全性框架 所以spring security 会自动拦截站点所有状态变化的请求(非GET,HEAD,OPTIONS和TRACE的请求),防止跨站请求伪造(CSRF防护),即防止其他网站或是程序POST等请求本站点。…
从Ops到NoOps,阿里文娱智能运维的关键:自动化应用容量管理
作者| 阿里文娱高级开发工程师 金呈编辑 | 夕颜来源 | CSDN(ID:CSDNnews)概述1. 背景随着业务形态发展,更多的生产力集中到业务创新,这背后要求研发能力的不断升级。阿里文娱持续倾向用更加高效、稳定、低成本的方式支…

JAVA目录树(全功能),Java+ajax实现
我自己要的功能全实现了 一:双击选中项进行编辑 二:右键菜单功能(新增,删除,修改,自定义颜色什么的) 三:选中项进行拖动事件 四:输入项进入搜索(并自动选中结果项) 2011.03.14更新功能 …
SiteMesh介绍
1. SiteMesh简介 SiteMesh是由一个基于Web页面布局、装饰以及与现存Web应用整合的框架。它能帮助我们在由大量页面构成的项目中创建一致的页面布局和外观,如一致的导航条,一致的banner,一致的版权等等。它不仅仅能处理动态的内容,…
商汤提基于贪心超网络的One-Shot NAS,达到最新SOTA | CVPR 2020
出品 | AI科技大本营(ID:rgznai100)导读:在CVPR 2020上,商汤移动智能事业群-3DAR-身份认证与视频感知组提出了基于贪心超网络的One-Shot NAS方法,显著提升了超网络直接在大规模数据集上的搜索训练效率,并在…
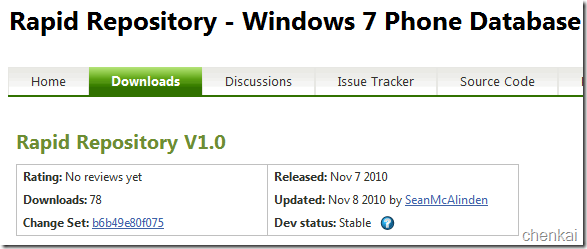
多样化实现Windows phone 7本地数据访问5——深入Rapid Repository
上一篇多样化实现Windows Phone 7本地数据访问<4>——Rapid Repository 中初步的介绍Repid Repository作为Windows phone 7数据库存储原理Repid具有特点以及数据CRUD基本操作.Rapid Repository 是一个基于WP7开源的数据库. 上周联系Rapid 数据库的作者Sean McAlinden.有…
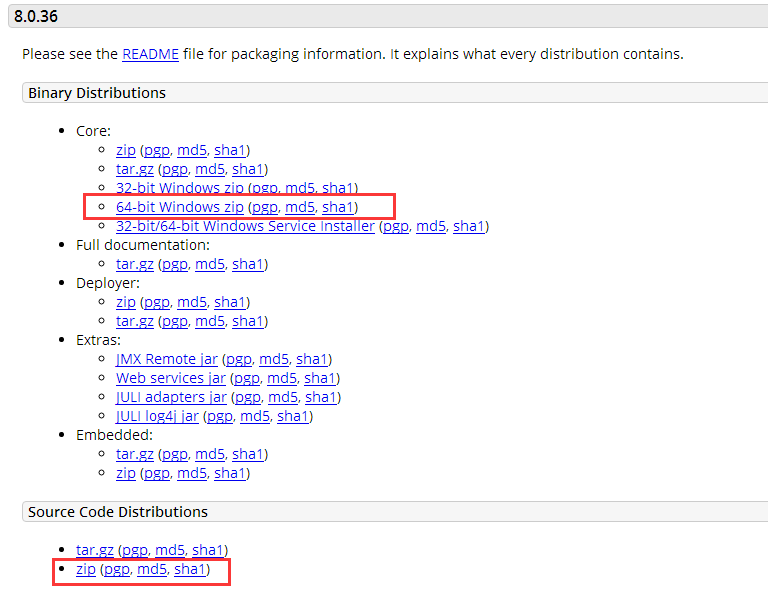
调试Tomcat源码
需要调试Tomcat源码其实很简单, 1.保持你的Tomcat安装文件和源码是版本一致 http://tomcat.apache.org/download-80.cgi 下载安装版和源码2个版本 2.建立Java自由格式项目 先在IDE里配置好Tomcat,这个不复杂。 然后新建一个项目,这个需要…

开源 免费 java CMS - FreeCMS1.9 全文检索
项目地址:http://code.google.com/p/freecms/ 全文检索 从FreeCMS 1.7開始支持 仅仅有创建过索引的对象才干被lucene类标签查询到。 信息类数据会在信息更新、审核、删除、还原操作时自己主动进行全文检索处理。1. 创建索引 从左側管理菜单点击创建索引进入。 您能够…