我佛了!用KNN实现验证码识别,又 Get 到一招!
作者| 李秋键
责编| Carol
出品| AI科技大本营(ID:rgznai100)
头图 | CSDN付费下载自视觉中国
验证码使我们生活中最为常见的防治爬虫和机器人登录攻击的手段,一般的验证码主要由数字和字母组成,故我们可以设想:我们是否可以根据文本识别训练模型进行识别验证码呢?当然可以,今天我们就将利用KNN实现验证码的识别。
关于KNN基本常识如下:
KNN算法我们主要要考虑三个重要的要素,对于固定的训练集,只要这三点确定了,算法的预测方式也就决定了。这三个最终的要素是k值的选取,距离度量的方式和分类决策规则。
对于k值的选择,没有一个固定的经验,一般根据样本的分布,选择一个较小的值,可以通过交叉验证选择一个合适的k值。
选择较小的k值,就相当于用较小的领域中的训练实例进行预测,训练误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是泛化误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
选择较大的k值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少泛化误差,但缺点是训练误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
一个极端是k等于样本数m,则完全没有分类,此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单。
效果图如下:
实验前的准备
首先我们使用的python版本是3.6.5所用到的库有cv2库用来图像处理;
Numpy库用来矩阵运算;
训练的数据集如下所示:
训练模型的搭建
1、获取切割字符轮廓:
我们定义ws和valid_contours数组,用来存放图片宽度和训练数据集中的图片。如果分割错误的话需要重新分割。主要根据字符数量判断是否切割错误,如果切割出有4个字符。说明没啥问题:
代码如下:
#定义函数get_rect_box,目的在于获得切割图片字符位置和宽度
def get_rect_box(contours):print("获取字符轮廓。。。")#定义ws和valid_contours数组,用来存放图片宽度和训练数据集中的图片。如果分割错误的话需要重新分割ws = []valid_contours = []for contour in contours:#画矩形用来框住单个字符,x,y,w,h四个参数分别是该框子的x,y坐标和长宽。因x, y, w, h = cv2.boundingRect(contour)if w < 7:continuevalid_contours.append(contour)ws.append(w)
#w_min是二值化白色区域最小宽度,目的用来分割。w_min = min(ws)
# w_max是最大宽度w_max = max(ws)result = []#如果切割出有4个字符。说明没啥问题if len(valid_contours) == 4:for contour in valid_contours:x, y, w, h = cv2.boundingRect(contour)box = np.int0([[x,y], [x+w,y], [x+w,y+h], [x,y+h]])result.append(box)# 如果切割出有3个字符。参照文章,中间分割elif len(valid_contours) == 3:for contour in valid_contours:x, y, w, h = cv2.boundingRect(contour)if w == w_max:box_left = np.int0([[x,y], [x+w/2,y], [x+w/2,y+h], [x,y+h]])box_right = np.int0([[x+w/2,y], [x+w,y], [x+w,y+h], [x+w/2,y+h]])result.append(box_left)result.append(box_right)else:box = np.int0([[x,y], [x+w,y], [x+w,y+h], [x,y+h]])result.append(box)# 如果切割出有3个字符。参照文章,将包含了3个字符的轮廓在水平方向上三等分elif len(valid_contours) == 2:for contour in valid_contours:x, y, w, h = cv2.boundingRect(contour)if w == w_max and w_max >= w_min * 2:box_left = np.int0([[x,y], [x+w/3,y], [x+w/3,y+h], [x,y+h]])box_mid = np.int0([[x+w/3,y], [x+w*2/3,y], [x+w*2/3,y+h], [x+w/3,y+h]])box_right = np.int0([[x+w*2/3,y], [x+w,y], [x+w,y+h], [x+w*2/3,y+h]])result.append(box_left)result.append(box_mid)result.append(box_right)elif w_max < w_min * 2:box_left = np.int0([[x,y], [x+w/2,y], [x+w/2,y+h], [x,y+h]])box_right = np.int0([[x+w/2,y], [x+w,y], [x+w,y+h], [x+w/2,y+h]])result.append(box_left)result.append(box_right)else:box = np.int0([[x,y], [x+w,y], [x+w,y+h], [x,y+h]])result.append(box)# 如果切割出有3个字符。参照文章,对轮廓在水平方向上做4等分elif len(valid_contours) == 1:contour = valid_contours[0]x, y, w, h = cv2.boundingRect(contour)box0 = np.int0([[x,y], [x+w/4,y], [x+w/4,y+h], [x,y+h]])box1 = np.int0([[x+w/4,y], [x+w*2/4,y], [x+w*2/4,y+h], [x+w/4,y+h]])box2 = np.int0([[x+w*2/4,y], [x+w*3/4,y], [x+w*3/4,y+h], [x+w*2/4,y+h]])box3 = np.int0([[x+w*3/4,y], [x+w,y], [x+w,y+h], [x+w*3/4,y+h]])result.extend([box0, box1, box2, box3])elif len(valid_contours) > 4:for contour in valid_contours:x, y, w, h = cv2.boundingRect(contour)box = np.int0([[x,y], [x+w,y], [x+w,y+h], [x,y+h]])result.append(box)result = sorted(result, key=lambda x: x[0][0])return result2、数据集图像处理:
在读取数据集后,我们需要对图片数据集进行二值化和降噪处理,以获得更为合适的训练数据。
其中代码如下:
def process_im(im):rows, cols, ch = im.shape#转为灰度图im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)#二值化,就是黑白图。字符变成白色的,背景为黑色ret, im_inv = cv2.threshold(im_gray,127,255,cv2.THRESH_BINARY_INV)#应用高斯模糊对图片进行降噪。高斯模糊的本质是用高斯核和图像做卷积。就是去除一些斑斑点点的。因为二值化难免不够完美,去燥使得二值化结果更好kernel = 1/16*np.array([[1,2,1], [2,4,2], [1,2,1]])im_blur = cv2.filter2D(im_inv,-1,kernel)#再进行一次二值化。ret, im_res = cv2.threshold(im_blur,127,255,cv2.THRESH_BINARY)return im_res3、切割字符:
在得到字符位置后,我们对图片进行切割和保存
部分代码如下:
#借助第一个函数获得待切割位置和长宽后就可以切割了
def split_code(filepath):#获取图片名filename = filepath.split("/")[-1]#图片名即为标签filename_ts = filename.split(".")[0]im = cv2.imread(filepath)im_res = process_im(im)im2, contours, hierarchy = cv2.findContours(im_res, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#这里就是用的第一个函数,获得待切割位置和长宽boxes = get_rect_box(contours)
#如果没有区分出四个字符,就不切割这个图片if len(boxes) != 4:print(filepath)
# 如果区分出了四个字符,说明切割正确,就可以切割这个图片。将切割后的图片保存在char文件夹下for box in boxes:cv2.drawContours(im, [box], 0, (0,0,255),2)roi = im_res[box[0][1]:box[3][1], box[0][0]:box[1][0]]roistd = cv2.resize(roi, (30, 30))timestamp = int(time.time() * 1e6)filename = "{}.jpg".format(timestamp)filepath = os.path.join("char", filename)cv2.imwrite(filepath, roistd)#cv2.imshow("image", im)#cv2.waitKey(0)#cv2.destroyAllWindows()
# split all captacha codes in training set
#调用上面的split_code进行切割即可。
def split_all():files = os.listdir(TRAIN_DIR)for filename in files:filename_ts = filename.split(".")[0]patt = "label/{}_*".format(filename_ts)saved_chars = glob.glob(patt)if len(saved_chars) == 4:print("{} done".format(filepath))continuefilepath = os.path.join(TRAIN_DIR, filename)split_code(filepath)4、标注字符:
通过已经标注好的数据集字符读取标签,然后存储标签,以方便和图片达到对应。字符数据集如下:
代码如下:
#用来标注单个字符图片,在label文件夹下,很明显可以看到_后面的就是标签。比如图片里是数字6,_后面就是6def label_data():files = os.listdir("char")for filename in files:filename_ts = filename.split(".")[0]patt = "label/{}_*".format(filename_ts)saved_num = len(glob.glob(patt))if saved_num == 1:print("{} done".format(patt))continuefilepath = os.path.join("char", filename)im = cv2.imread(filepath)cv2.imshow("image", im)key = cv2.waitKey(0)if key == 27:sys.exit()if key == 13:continuechar = chr(key)filename_ts = filename.split(".")[0]outfile = "{}_{}.jpg".format(filename_ts, char)outpath = os.path.join("label", outfile)cv2.imwrite(outpath, im)#和标注字符图反过来,我们需要让电脑知道这个字符叫啥名字,即让电脑知道_后面的就是他字符的名字def analyze_label():print("识别数据标签中。。。")files = os.listdir("label")label_count = {}for filename in files:label = filename.split(".")[0].split("_")[1]label_count.setdefault(label, 0)label_count[label] += 1print(label_count)5、KNN模型训练:
KNN算法我们直接使用OpenCV自带的KNN函数即可。通过读取数据集和标签,加载模型训练即可。代码如下:
#训练模型,用的是k相邻算法def get_code(im):#将读取图片和标签print("读取数据集和标签中。。。。")[samples, label_ids, id_label_map] = load_data()#k相邻算法print("初始化中...")model = cv2.ml.KNearest_create()#开始训练print("训练模型中,请等待!")model.train(samples, cv2.ml.ROW_SAMPLE, label_ids)#处理图片。即二值化和降噪im_res = process_im(im)#提取轮廓im2, contours, hierarchy = cv2.findContours(im_res, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)#获取各切割区域位置和长宽boxes = get_rect_box(contours)#判断有没有识别出4个字符,如果没有识别出来,就不往下运行,直接结束了if len(boxes) != 4:print("cannot get code")result = []#如果正确分割出了4个字符,下面调用训练好的模型进行识别。for box in boxes:#获取字符长宽roi = im_res[box[0][1]:box[3][1], box[0][0]:box[1][0]]#重新设长宽。roistd = cv2.resize(roi, (30, 30))#将图片转成像素矩阵sample = roistd.reshape((1, 900)).astype(np.float32)#调用训练好的模型识别ret, results, neighbours, distances = model.findNearest(sample, k = 3)#获取对应标签idlabel_id = int(results[0,0])#根据id得到识别出的结果label = id_label_map[label_id]#存放识别结果result.append(label)return result模型调用
if __name__ == "__main__":file=os.listdir("test")filepath="test/"+file[4]im = cv2.imread(filepath)preds = get_code(im)preds="识别结果为:"+preds[0]+preds[1]+preds[2]+preds[3]print(preds)canny0 = imimg_PIL = Image.fromarray(cv2.cvtColor(canny0, cv2.COLOR_BGR2RGB))myfont = ImageFont.truetype(r'simfang.ttf', 18)draw = ImageDraw.Draw(img_PIL)draw.text((20, 5), str(preds), font=myfont, fill=(255, 23, 140))img_OpenCV = cv2.cvtColor(np.asarray(img_PIL), cv2.COLOR_RGB2BGR)cv2.imshow("frame", img_OpenCV)key = cv2.waitKey(0)print(filepath)
到这里,我们整体的程序就搭建完成,下面为我们程序的运行结果:
源码地址:
链接:https://pan.baidu.com/s/1Ir5QNjUZaeTW26T8Gb3txQ
提取码:9eqa
作者简介:
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等等。
推荐阅读
潘石屹 Python 考试成绩 99 分,网友:还有一分怕你骄傲
Go远超Python,机器学习人才极度稀缺,全球16,655位程序员告诉你这些真相
深度学习基础总结,无一句废话(附完整思维导图)
第一个"国产"Apache 顶级项目 Kylin,了解一下!| 原力计划
华为 5G、阿里检测病毒算法、腾讯 AI 一分钟诊断,国内抗疫科技大阅兵!
对不起,我把APP也给爬了
超级账本Hyperledger Fabric中的Protobuf到底是什么?
你点的每个“在看”,我都认真当成了AI
相关文章:

JVM中的垃圾收集器
2019独角兽企业重金招聘Python工程师标准>>> Serial收集器: 一种新生代的单线程收集器,采用复制算法回收。当它进行垃圾收集时,其他用户的所有线程都将暂停。 Serial Old收集器:Serial的老年代版本,采用的是标记-清除算…

linux系统用户,组和权限的管理
PS: {最近一直在做毕业设计,前面博客也记录过我的一些过程。其中需要在Ubuntu上搭建一个FTP服务器,此处我选择Vsftpd,但是在我对vsftpd的配置文件vsftpd.conf设置正确后(对于上传,下载等设置肯定没问题&am…
520 情人节 :属于Python 程序员的脱单攻略大合集(视频版)
作者| Python 编程时光责编| Carol情人节年年有,但今年的 5.20 要比以往的更有意义。2020.05.20 ,爱你爱你我爱你,如果再卡个时间(13:14),那就是 爱你爱你我爱你一生一世。为了能过上这个这个百年难遇的情人…

使用Word2010灵活掌握文档结构
使用Microsoft Word应用程序组织和编写文档时,可能会出现反复调整文档结构的情况,而通过一系列的剪切、复制、粘贴操作来解决问题,可能会让您觉得很麻烦,有没有更好的解决办法呢?其实,通过使用Word 2010中全…
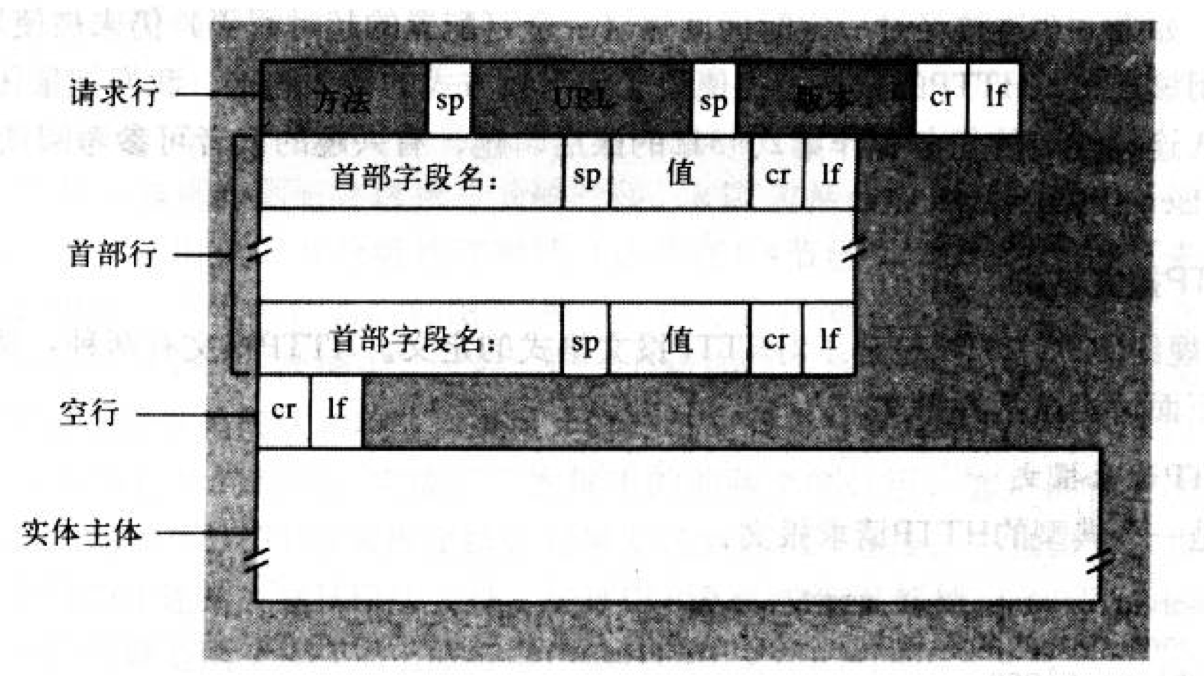
深入Jetty源码之HTTP协议
在计算机网络中,如果两台机器要通信,他们首先要定义通信数据的格式,这样在服务器收到客户端的请求消息时,它才能正确的解析请求的内容,然后根据请求内容处理逻辑,并将相应消息传递会客户端;此时…
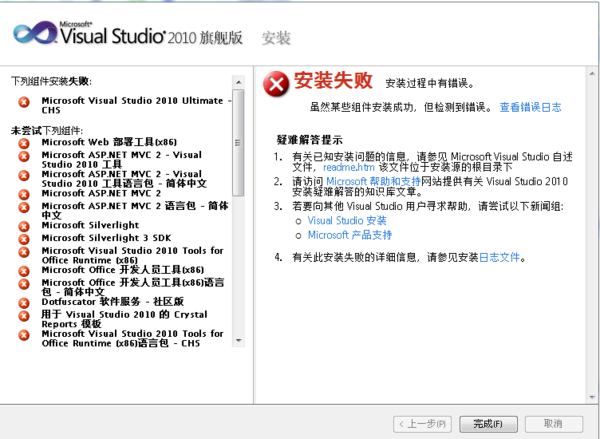
64位win7安装vs2010出现“组件安装失败...”等问题的解决方法
如题,公司发了新电脑,安装的是64位win7 ,我原来的本本安装的是32位的win7,当时安装vs2010的时候并没有那么多事,这次安装却真是让我蛋疼至极。 先后下了3个vs的安装包,中文版的,有专业版的,有旗…

不同网段路由配置
PC1 ip 192.168.1.1PC2 ip 192.168.4.1路由0 f0/0 192.168.1.254 f0/1 192.168.2.1路由1 f0/0 192.168.3.1f0/1 192.168.2.2路由2 f0/0 192.168.4.254 f0/1 192.168.3.2路由器0Router>enRouter#conf tRouter(config)#no ip domain-lookupRouter(config)#line console 0…
黑科技:绕过眼睛植入幻觉,科学家成功在盲人脑海中呈现指定图像!
来源 | 学术头条(ID:SciTouTiao)头图 | CSDN付费下载自视觉中国对于全球 5000 多万盲人来说,重见光明是一个遥不可及的梦想。而为了与盲人朋友进行交互,我们发明了盲文,用各种凸起的字符集合来表达各种意思。但这种通过…
Solr 4.x定时、实时增量索引 - 修改、删除和新增索引
2019独角兽企业重金招聘Python工程师标准>>> 一、开始增量索引前的准备工作。 1、认识data-config.xml中相关属性 <!-- transformer 格式转化:HTMLStripTransforme表示 索引中将忽略HTML标签 ---> <!-- query: 查询数据库表符合记录数据 …

关于Blocking IO, Non-Blocking IO 和 Asynchronous I/O的理解
文章写得很详细很清楚了,对我的理解帮助很大。 转载自:http://www.cnblogs.com/whyandinside/archive/2012/03/04/2379234.html。 概括来说,一个IO操作可以分为两个部分:发出请求、结果完成。如果从发出请求到结果返回ÿ…
还在苦恼机器学习和线性回归?这篇总结拿走不谢 | 原力计划
作者 | 听星的朗瑞责编 | 王晓曼出品 | CSDN博客题图 | 东方IC什么是机器学习?机器学习是一种实现人工智能的方法,从数据中寻找规律、建立关系,根据建立的关系去解决问题,从数据中进行经验学习,实现自我优化与升级。维…
网页设计和用户界面设计
摘要:这是两个现在网页设计领域使用频率非常高的词。在大多数情况下,它们被相互替代。这个领域内外的很多人都认为这是两个意义基本一样的词。但是它们真的可以互相混淆么?这是两个现在网页设计领域使用频率非常高的词。在大多数情况下&#…

使用VisualStudio2010连接CodePlex进行代码管理
摘要:CodePlex是微软的开源工程网站,涉及诸多微软最新技术的开源工程,同时你也可以建立并向世界展示自己的开源工程。同SourceForge、GoogleCode相比CodePlex有其自身的优势,特别是对做.Net开发的朋友来说,由于CodePle…
计算程序运行时间(time_t, clock_t)
转载自:http://blog.chinaunix.net/uid-23208702-id-75182.html 计算程序运行时间(time_t, clock_t)-whyliyi-ChinaUnix博客 我们有时需要得到程序的运行时间,但我们也要知道,根本不可能精确测量某一个程序运行的确切…
又一年5.20,用Python助力程序员脱单大攻略(视频版)
作者 | 写代码的明哥来源 | Python编程时光(ID: Cool-Python)情人节年年有,但今年的 5.20 要比以往的更有意义。2020.05.20 ,爱你爱你我爱你,如果再卡个时间(13:14),那就是 爱你爱你…
pthred()多线程计算派
实验一:计算π问题描述实验提供了两种计算方法,一种使用积分方法,另一种采用随机数方法。本报告中采用积分方法。计算公式:程序流程图:(图1)函数流程图(图2)一组实验数据,计算规模:500,000,000性…
使用最小堆优化Dijkstra算法
OJ5.2很简单,使用priority_queue实现了最小堆竟然都过了OJ……每次遇到relax的问题时都简单粗暴地重新push进一个节点…… 然而正确的实现应该是下面这样的吧,关键在于swap堆中元素时使用pos数组存储改变位置后的编号为k的节点对应在堆中的位置。下面这种…
C语言编程技巧-signal(信号机制)
http://blog.sina.com.cn/s/blog_6a1837e90100v1vc.html

第一课:网络参考模型OSI
网络参考模型OSI(一):模型提出目的:开放系统互连。使各个厂商的设备可以很好的互连、互通、互操作。(二):各层功能(1):物理层:负责链路上bit流的传输。(bit流显著的特点是,不支持格式或者结构)。…
在线直播 | 是事实还是贩卖焦虑?IT行业也偏爱“小鲜肉”
几年前曾看过这样一篇报道:Java 之父求职被嫌年纪大,硅谷公司现在喜欢“小鲜肉”,不爱“老古董”。Java之父 James Gosling 在 Facebook 上发表了他所遭遇的年龄歧视:我曾在面试的时候被 HR 告知,“通常我们不招你这种…

eclipse 代码中突然出现特殊字符
在写代码的时候,不知道点到了 eclipse 的哪个属性,代码中就出现了一些特殊字符,也不能删除。 请问,在 eclipse 中该怎么设置,才能将这些字符去掉。 如下图所示: 解决方法: 选择Window->Preferences->…

如何优化数据中心虚拟机布局
当前已经有很多组织将服务器虚拟化技术引入到生产中,这么做是有道理的,特别是在当前经济并不景气的情况下,因为服务器虚拟化技术可以在服务器硬件,机架空间,电力消耗和制冷方面为组织节省开支。 但为了实现服务器虚…
回归——同步更新github.io
回归 已经有好长时间没写博客了,可能我比较懒,不太乐于分享,我觉得这个是一个很不好的习惯。但我坚信:Sharing changes the world! 最近搭建了自己的个人独立博客,基于Github Pages的,所以打算以后同步更…
支持量子机器学习,王海峰发布最新百度飞桨全景图
出品 | AI科技大本营(ID:rgznai100)刚刚,WAVE SUMMIT 2020深度学习开发者峰会上,百度CTO王海峰开场即披露了一组飞桨数据:飞桨累计开发者数量已超过190万,服务企业数量达8.4万家,发布模型数量已…

NPOI读写Excel
1、整个Excel表格叫做工作表:WorkBook(工作薄),包含的叫页(工作表):Sheet;行:Row;单元格Cell。 2、NPOI是POI的C#版本,NPOI的行和列的index都是从…

我的vim捣鼓之路
2016-06-13 更新 绑定独立博客到域名rebootcat.com 2016-06-12 更新文中的几个链接错误,google search报错 前言 从大二的时候就开始接触Linux了,从而也接触了vi,对的,当时对这些还不太了解,不知道还有个vim,真的觉得…
代码写对了还挂了?程序媛小姐姐从 LRU Cache 带你看面试的本质
来源 | 码农田小齐责编 | Carol 前言在讲这道题之前,我想先聊聊「技术面试究竟是在考什么」这个问题。技术面试究竟在考什么在人人都知道刷题的今天,面试官也都知道大家会刷题准备面试,代码大家都会写,那面试为什么还在考这些题&…
广船国际股份有限公司OA项目
2003年的老案例: 背景 广船国际股份有限公司是由原中国船舶工业总公司属下国有企业广州造船厂在1993年改组、在上海和香港同期上市的股份有限公司,公司享有自营进出口权。 广船国际于2002年3月通过评标后选定采用iOffice.net信息管理平台作为信息化建设…

注册表----修改Win7登录界面
在进行操作前,需要准备好背景图片。对背景图片的要求有三点: (1)图片必须是JPG格式; (2)必须将图片命名为backgroundDefault; (3)图片的体积必须小于256KB。 按下【WinR】…
定义自己的rm command
rm 是一个很危险的命令,别人一直说,我并没有在意,直到有一天一个不小心,忘记当前目录的位置,手贱的使用了rm命令,结果花了半天也没有把那些重要资料给恢复过来。所以还是有必要给自己定义一个不那么危险的r…