Python分析101位《创造营2020》小姐姐,谁才是你心中的颜值担当?
来源 | CDA 数据分析师
责编 | Carol
Show me data,用数据说话。
今天我们聊一聊《创造营2020》各个小姐姐,点击下方视频,先睹为快:
最近可以追的综艺真是太多了,特别是女团选秀节目。之前我们刚聊过《青春有你2》,现在隔壁鹅厂的《创造营2020》又火热开播了。除了数不清的漂亮小姐姐,导师团除了黄子韬、鹿晗,最新一期中吴亦凡更是作为特约教练登场,“归国三子”一下子就引爆了话题度。
《创造营2020》到底好看吗?
那么,《创造营2020》到底好看吗?先让我们看到豆瓣,目前已经有25129人打分,分数为6.6分。
对比起隔壁的《青你2》5.2分,创造营还略胜一筹,不过刚更新3期,还可以在观望一下。
总体评分分布
具体看到总体评分分布,其中11.8%的人给了5星,19.6%的人给了4星,其中打1星的最多占到39.8%。
其中给出1分2分算评分较差的,4分5分算比较好的推荐分数。我们分布看到这两部分评分的词云图。
在评分较低的观众看来,主要的吐槽点有关于"赛制"、"导师"、"剪辑"方面。直接表达"不好看"、"劝退"、"吊打"的评论也有不少。
在给出分数较高,推荐的观众看来,《创造营2020》的亮点在于"选手小姐姐"、"导师阵容"、"话题"。鹅厂的"财大气粗"、"燃烧的经费"也令人印象深刻。其次也有认为比《青你2》要更好看的。
教你用Python分析101位选手小姐姐
之前看到 菜鸟学Python 写了一篇「我用Python分析了《青春有你2》109位漂亮小姐姐,真香!」。
这次我们也受到了点启发,打算也用Python来盘一盘《创造营2020》的小姐姐们。
下面让我们来通过Python为大家介绍一下这101位美丽的小姐姐吧。
数据获取
数据预处理:数据合并和字段提取
数据可视化分析
1、数据获取
此次我们主要获取了以下部分的数据:
从腾讯的官方助力网站,来获取选手的姓名和照片信息
从维基百科获取选手的籍贯、年龄、身高、所在经济公司信息
调用百度智能云的AI人脸识别接口,输入选手照片,获取选手颜值等信息。
下面看到具体步骤和部分关键代码:
获取腾讯撑腰榜数据
我们获取数据的页面地址如下:
https://m.v.qq.com/activity/h5/303_index/index.html?ovscroll=0&autoplay=1&actityId=107015
这是一个动态js加载的网站,使用chrome浏览器简单的抓包分析,得到真实的数据传输接口,通过修改其中的pageSize参数即可得到所有的数据。
代码如下:
# 导入库
import pandas as pd
import requests
import jsondef get_tx_actors():"""功能:获取创造营2020撑腰榜数据。"""# 获取URLurl = 'https://zbaccess.video.qq.com/fcgi/getVoteActityRankList?raw=1&vappid=51902973&vsecret=14816bd3d3bb7c03d6fd123b47541a77d0c7ff859fb85f21&actityId=107015&pageSize=101&vplatform=3&listFlag=0&pageContext=&ver=1&_t=1589598410618&_=1589598410619'# 添加headersheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}# 发起请求response = requests.get(url, headers=headers)# 解析数据json_data = json.loads(response.text)# 提取选手信息player_infos = json_data['data']['itemList']# 提取详细信息names = [i['itemInfo'].get('name') for i in player_infos]rank_num = [i['rankInfo'].get('rank') for i in player_infos]images = [i['itemInfo']['mapData'].get('poster_pic') for i in player_infos]# 保存信息df = pd.DataFrame({'names': names,'rank_num': rank_num,'images': images})return df通过以上程序,获取到101位选手的姓名、排名和照片信息,并将选手的照片保存到本地。获取数据如下所示:
df1.head() 获取维基百科数据
此处使用selenium获取,需要电脑可以登录外网,代码较为简单,暂时省略。
这里主要获取了选手的籍贯、年龄、身高、所在经济公司信息,如下所示:
df2.head()调用百度AI接口获取颜值数据
百度AI人脸详细的识别文档地址如下:
https://ai.baidu.com/ai-doc/FACE/yk37c1u4t
首先需要在官网申请个人的token信息,然后下面的程序中,get_face_score函数首先构造请求URL,然后构造请求的params表单数据,包括base64编码的图片信息,图片类型和想要获取的人脸信息。通过POST方法获取返回的json数据,返回的json数据里就包含着我们需要的颜值得分和年龄估计等信息,具体代码如下:
def get_file_content(file_path):"""功能:使用base64转换路径编码"""with open(file_path, 'rb') as fp:content = base64.b64encode(fp.read())return content.decode('utf-8')def get_face_score(file_path):"""功能:调用api,实现一个百度的颜值分析器"""# 调用函数,获取image_codeimage_code = get_file_content(file_path=file_path)# 请求base_urlrequest_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"# 表单数据params = {'image':'{}'.format(image_code),'image_type': 'BASE64','face_field': 'age,gender,beauty'}# 调用函数,获取tokenmy_access_token = "官网获取的个人的token信息"# 获取access_tokenaccess_token = my_access_token# 构建请求URLrequest_url = request_url + "?access_token=" + access_token# 请求头headers = {'content-type': 'json'}# 发起请求response = requests.post(request_url, data=params, headers=headers)if response:print(response.json())age = response.json()['result']['face_list'][0]['age']gender = response.json()['result']['face_list'][0]['gender']['type']gender_prob = response.json()['result']['face_list'][0]['gender']['probability']beauty = response.json()['result']['face_list'][0]['beauty']all_results = [age, gender, gender_prob, beauty]return all_results通过以上程序,获取到101位选手通过百度AI预测的年龄、性别、性别预测概率、颜值等信息。
df3.head() 2、内容预处理
此处我们主要对以上获取的数据集进行整理和清洗,清洗后的数据如下所示:
df.head() 3、数据可视化
获取和整理数据之后,接下来我们使用数据可视化库pyecharts进行以下的数据可视化分析。
选手的年龄分布
首先在年龄上,选手最小年龄是18岁,最大年龄是25岁。我们对年龄进行了分箱,具体分析发现20-22岁的选手最多,占比达到35.87%。其次是22-24岁,占比29.35%,紧随其后是18-20岁,占比28.26%。最后是24-26岁,仅占比6.52%。看来想要出道真的需要趁早啊!
代码如下:
# 分箱
age_bins = [18,20,22,24,26]
age_labels = ['18-20', '20-22', '22-24', '24-26']
age_cut = pd.cut(df.age, bins=age_bins, labels=age_labels)
age_cut = age_cut.value_counts()# 产生数据对
data_pair = [list(z) for z in zip(age_cut.index.tolist(), age_cut.values.tolist())]# 绘制饼图
# {a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add('', data_pair=data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='选手年龄分布'), legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.render()
选手的真实年龄和百度AI预测对比
我们将百度AI预测的年龄和真实年龄进行了对比,可以看出模型预测的方差较小,由计算可知平均预测的绝对误差在1.67岁,预测结果还是比较准确的。
代码如下:
# 产生数据
x1_line2 = df.names.values.tolist()
y1_line2 = df.age.values.tolist()
y2_line2 = df.pred_age.values.tolist()# 绘制折线图
line2 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))
line2.add_xaxis(x1_line2)
line2.add_yaxis('真实年龄', y1_line2)
line2.add_yaxis('预测年龄', y2_line2)
line2.set_global_opts(title_opts=opts.TitleOpts('选手的真实年龄和百度AI预测对比'), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate='30')),yaxis_opts=opts.AxisOpts(min_=15, max_=30),)
line2.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
line2.render()选手的身高分布
通过上图可以看出,选手的身高基本符合正态分布。身高方面小姐姐们都在160以上,最高的是175cm,令人意外的是身高167cm的最多,共有34名。看来女团对身高的要求还挺高的。
选手籍贯分布
那么小姐姐们都来自哪些地区呢?
这里我们只是关注了国内的情况,马来西亚和俄罗斯等其他国家,并不在我们的统计范围内。经过分析整理可以发现,来自四川的人数是最多的,看来四川当之无愧是个盛产美女之地,然后是广东和湖南。
代码如下:
city_num = df.region.value_counts()# 数据对
data_pair2 = [list(z) for z in zip(city_num.index.tolist(), city_num.values.tolist())]# 绘制地图
map1 = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))
map1.add('', data_pair2, maptype='china')
map1.set_global_opts(title_opts=opts.TitleOpts(title='选手的籍贯分布'), visualmap_opts=opts.VisualMapOpts(max_=9))
map1.render()选手所在经济公司分布
同时再看到选手的经济公司。可以看到,其中丝芭传媒推出的选手人数位居第一,最多共有7人,丝芭传媒是中国大型女子偶像团体SNH48的运营公司,值得注意的是它在青春有你2中选送的选手数量也是最多的。
代码如下:
company_num = df.company.value_counts(ascending=False) # 柱形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(company_num.index.tolist())
bar1.add_yaxis('', company_num.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='选手所在经济公司分布'), visualmap_opts=opts.VisualMapOpts(max_=7),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate='60')),)
bar1.render()
选手的颜值分布
最后再看到大家最最关系的颜值问题啦,这次我们还调用百度智能云的AI人脸识别接口,输入选手照片,获取选手颜值等信息。
通过AI接口,可以看到由百度AI预测的颜值最低为57分,最高为89分,我们对颜值进行了分箱操作,其中55-60对应低,60-70对应中,70-80对应较高,80以上对应高。可以计算,较高和高占比76%,小姐姐们的颜值都是非常高的。
其中百度AI预测颜值最高的小姐姐是谁呢?她就是崔文美秀,很灵动清秀的一位小姐姐呢。
谁是你心中《创造营2020》中的颜值担当呢?在留言区告诉我们吧!
推荐阅读
又一年5.20,用Python助力程序员脱单大攻略(视频版)
我佛了!用KNN实现验证码识别,又 Get 到一招!
潘石屹 Python 考试成绩 99 分,网友:还有一分怕你骄傲
平安科技王健宗:所有 AI 前沿技术,都可以在联邦学习中大展身手!
踢翻这碗狗粮:程序员花 7 个月敲出 eBay,只因女票喜欢糖果盒!
在 520 这天,竟然有人把 Docker讲清楚了? | 原力计划
斗地主吗?能学区块链那种! | 原力计划
你点的每个“在看”,我都认真当成了AI
相关文章:

体验Remix——安卓电脑
第一次听说Android-X86 以前玩唱吧的时候接触过PC上的安卓模拟器,不过这个只是一个软件,效果毕竟不好,想要把电脑变成安卓手机,还差远了。 然后,前段时间一直纠结要不要换个手机,我现在的华为小6已经跟我…

重置 microsoft visual studio窗口
“工具”->“导入导出设置”—>“重置所有设置”,在这个向导中可以重置编译环境的!转载于:https://www.cnblogs.com/qiantuwuliang/archive/2011/05/31/2064825.html
排序算法总结之堆排序
一,堆排序介绍 堆是一个优先级队列,对于大顶堆而言,堆顶元素的权值最大。将 待排序的数组 建堆,然后不断地删除堆顶元素,就实现了排序。关于堆,参考:数据结构--堆的实现之深入分析 下面的堆排序…

Hessian通信案例(java)
个人博客: 戳我,戳我 前言 由于工作的原因,接触到了hessain,项目需要做hessain和xml之间的报文转换。但是对于hessian是个什么东西一头雾水。于是接下来的时间了解了hessain协议的序列化规则以及hessian协议进行通信的方式。这篇文章是在完成了这个模块…

VDI序曲二十一 APP-V 4.6 SP1服务器端部署
APP-V是微软应用程序虚拟化除RemoteApp以外非常棒的另一种应用程序虚拟化,此应用程序虚拟化是把搭开应用程序消耗的资源放在前端,应用程序虚拟化主要解决的还是软件兼容性问题和保护软件资产问题,同时让用户无需安装就可以绿色使用的手段&…
绝悟之后再超神,腾讯30篇论文入选AI顶会ACL
作者 | 马超责编 | Carol出品| AI科技大本营(ID:rgznai100)封图 | CSDN 付费下载于东方 IC近日,国际计算语言学协会年会ACL在官网(https://www.aclweb.org)公布了2020年度的论文收录名单,其中腾讯共有30篇论文入选&…
mac中用命令行运行mysql
1,安装mysql 在mysql的官方网站下载 mysql 5.5.23 http://www.mysql.com/downloads/mysql/,根据我的机器的配置情况选择了64bit版本。 2,命令行中启动mysql 安装的位置在/usr/local/mysql 于是做了一个别名: $alias mysql/usr/loc…

Hessian源码分析(java)
个人博客: 戳我,戳我 先扯一扯 前一篇博文Hessian通信案例(java)简单实现了Java版的Hessian客户端和服务端的通信,总体看来,实现起来比较简单,整个基于Hessian的远程调用过程也显得很方便。但是知其然还要知其所以然&…
必读!53个Python经典面试题详解
作者 | Chris翻译 | 苏本如,编辑 | 夕颜题图 | 视觉中国出品 | AI科技大本营(ID:rgznai100)本文列出53个Python面试问题,并且提供了答案,供数科学家和软件工程师们参考。不久前,我作为“数据科学家”开始担…
Microsoft Web 平台安装程序 (Web PI) Microsoft Web Platform Installer
Microsoft Web 平台安装程序 3.0 (Web PI) 是一款免费的工具,使用它可以获得 Microsoft Web 平台的最新组件(包括 Internet Information Services (IIS)、SQL Server Express、.NET Framework 和 Visual Web Developer)。Web PI 的内置Window…
Linux Shell 脚本限制ssh最大用户登录数
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://dgd2010.blog.51cto.com/1539422/1670233 我撰写本文原来的意图是想把“复制SSH渠道”和"copy SSH Session"这样的功能从远程s…

hessiancpp编译和使用(C++版)
个人博客:戳我,戳我 许下的承诺 前两篇博客Hessian通信案例(java)和Hessian源码分析(java)介绍了Java版的hessian的使用以及源码分析。当时也说过打算写一下C版的hessian的使用和源码分析,现在就是兑现承诺的时候了。其实我项目中实际用到的…
美国AI博士一针见血:Python这样学最容易成为高手!
我见过市面上很多的 Python 讲解教程和书籍,他们大都这样讲 Python 的:先从 Python 的发展历史开始,介绍 Python 的基本语法规则,Python 的 list, dict, tuple 等数据结构,然后再介绍字符串处理和正则表达式࿰…
win7操作系统在哪显示隐藏文件夹
win7操作系统在哪显示隐藏文件夹 打开计算机--组织--文件夹和搜索选项--查看--把 “隐藏受保护的操作系统文件”前面的钩去掉,选中“显示隐藏的文件、文件夹和驱动器”--确定
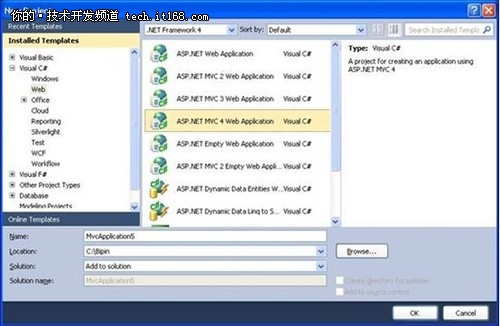
ASP.NET MVC4中调用WEB API的四个方法
当今的软件开发中,设计软件的服务并将其通过网络对外发布,让各种客户端去使用服务已经是十分普遍的做法。就.NET而言,目前提供了Remoting,WebService和WCF服务,这都能开发出功能十分强大的服务。然而,越来越多的互联网…
使用docker制作hexo镜像
个人博客:戳我,戳我 背景 这段时间一直在折腾我的博客,由于之前出现过一次电脑硬盘完全挂掉的情况,为了避免重新搭建博客系统,一直打算搞一个方便点的环境,能进行多机迁移之类的。正好,Docker完…
3D目标检测深度学习方法数据预处理综述
作者 | 蒋天元来源 | 3D视觉工坊(ID: QYong_2014)这一篇的内容主要要讲一点在深度学习的3D目标检测网络中,我们都采用了哪些数据预处理的方法,主要讲两个方面的知识,第一个是representation,第二个数据预处…

NTLM协议认证
第一篇blog,发现这是个记录学习过程的好地方。从基础的开始吧。 NTLM: 基本知识telnet的一种验证身份方式,即Windows NT LAN Manager (NTLM); NTLM 是为没有加入到域中的计算机(如独立服务器和工作组)提供的…
新盒模型移动端的排版
这里采用的是新盒模型来进行排版: <div class"mytest"> <header></header> <section></section> <footer></footer> </div> 在CSS样式里添加如下样式 html,body{ height: 100%; } .mytest{ …
微信跳一跳高分辅助踩坑
旧博文,搬到 csdn 原文:http://rebootcat.com/2018/01/08/wechat_jump_hack/ 最近挺火的微信跳一跳 最近新版微信的『跳一跳』小程序着实火了一把,也把小程序这个概念再次推波助澜了一波,看来以后小程序这个入口会有大作为。 张小…
“编程能力差,90%的人会输在这点上!”谷歌开发:其实都是在瞎努力
这是一个很难让人心平气和的年代。疫情之下,很多人的都在面临着:失业、降薪、找不到工作、随时被裁等风险。但是:有心的人早已上路超车,做个人能力的升级——提高自己的不可替代性。李开复曾提出过“五秒钟准则”:一项…
64位win7安装IIS7时不能浏览asp的问题
64位win7高级家庭版安装IIS7,安装完成后只能浏览静态页,找了很多的教程都没有解决,最后在一个博客里看到说64位系统下ASP是不支持的ODB读取ACC的数据库的,因此需要开启32位应用程序的支持。 方法是: Internet 信息服务…
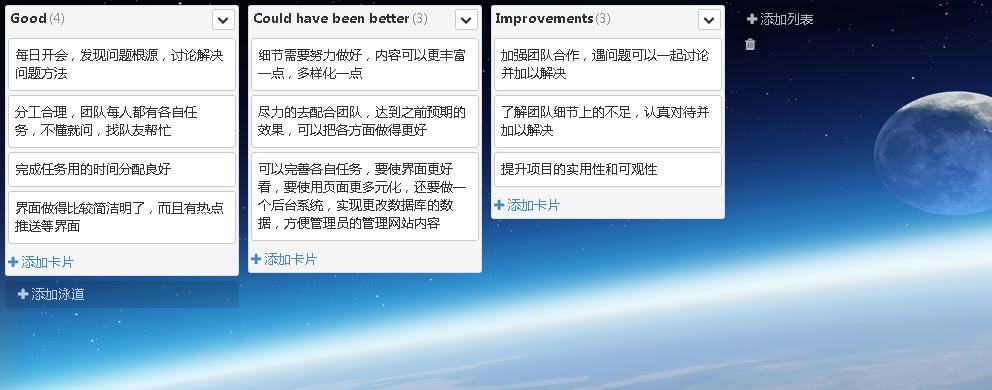
0525 项目回顾7.0
一、sprint总结 当谈到团队,我开始真的不知道团队是怎么样的,怎么样进行工作的,要该怎么出力团队的关系,有时候会涉及到个人问题,是不是该考虑进来,但是很多时候是不能的,每一个人作为团队的一份…
辩证看待 iostat
旧博文,搬到 csdn 原文:http://rebootcat.com/2018/01/16/using-iostat-dialectically/ 前言 经常做系统分析会接触到很多有用的工具,比如 iostat,它是用来分析磁盘性能、系统 I/O 的利器。 本文将重点介绍 iostat 命令的使用,并…
搞机器学习,Python和R哪个更合适?
【编者按】如果你正想构建一个机器学习项目,但却纠结于如何选择编程语言,这篇文章将是你所需要的。这篇文章不仅帮助你理解Python和R这两种语言的区别,还有助于你了解各个语言多方面的优势。作者 | Manav Jain译者 | Joe,编辑 | 夕…
Java安装方法
第1章 Java简介及开发环境搭建 实验1 JDK的下载、安装与配置 【实验目的】 (1)熟悉JDK工具包的下载及安装过程。 (2)掌握JAVA_HOME、CLASSPATH及Path的设置内容。 (3)掌握Java程序运行原理及Javac、Java命…

Hash函数的安全性
我们为了保证消息的完整性,引进了散列函数,那么散列函数会对安全正造成什么影响呢?这是需要好好研究一番的问题。 三个概念: 1.如果y<>x,且h(x)h(y),则…
一键安装python3环境
旧博文,搬到 csdn 原文:http://rebootcat.com/2018/04/15/python3_in_a_box/ 一键安装python3环境 由于现在逐步转移到 python3 进行开发,但是很多机器并没有预装 python3 环境,所以需要安装。 所以分享一个我常用的,…
认知智能再突破,阿里 18 篇论文入选 AI 顶会 KDD
作者 | 马超责编 | 屠敏头图 | CSDN 下载自东方 IC出品 | CSDN(ID:CSDNnews)近日,国际知识发现与数据挖掘协会KDD在官网(https://www.kdd.org/kdd2020)公布其2020年度的论文收录结果,笔者看到阿里共有18篇论文入选&…
python采集cpu信息
旧博文,搬到 csdn 原文:http://rebootcat.com/2018/05/20/analyze_cpu/ python脚本采集cpu 经常要做一些 linux 系统上的性能分析或者采集 cpu/mem/bandwidth 上报到监控系统。 分享一个我平常常用到的 cpu 采集脚本,原理是分析 /proc/stat…