为什么深度神经网络这么难训练?| 赠书
导读:本文内容节选自《深入浅出神经网络与深度学习》一书,由Michael Nielsen所著,他是实验媒体研究工作室的联合创始人,曾是 YC Research 的 Research Fellow。。
本书深入了讲解神经网络和深度学习技术,侧重于阐释深度学习的核心概念。作者以技术原理为导向,辅以贯穿全书的 MNIST 手写数字识别项目示例,介绍神经网络架构、反向传播算法、过拟合解决方案、卷积神经网络等内容,以及如何利用这些知识改进深度学习项目。学完本书后,读者将能够通过编写 Python 代码来解决复杂的模式识别问题。
了解关于深度学习的更多干货知识,关注AI科技大本营并评论分享你对本文的学习心得或深度学习的见解,我们将从中选出5条优质评论,各送出《深入浅出神经网络与深度学习》一本。活动截止时间为8月29日晚8点。
假设你是工程师,接到一项任务:从头开始设计计算机。某天,你正在工作室设计逻辑电路,例如构建与门、或门等。这时,老板带着坏消息进来了:客户刚刚提了一个奇怪的设计需求——整个计算机的电路深度限于两层,如图5-1所示。
你惊呆了,跟老板说道:“他们疯了吧!”
老板说:“我也觉得他们疯了,但是客户至上,只能设法满足他们。”
实际上,客户提出的需求并不过分。假设你能使用某种特殊的逻辑对任意多的输入执行AND运算,还能使用多输入的与非门对多个输入执行AND运算和NOT运算。由这类特殊的逻辑门构建出来的双层深度电路就可以计算任何函数。
理论上成立并不代表这是一个好的想法。在实际解决电路设计问题或其他大多数算法问题时,通常要考虑如何解决子问题,然后逐步集成这些子问题的解。换言之,要通过多层抽象来得到最终解。
假设设计一个逻辑电路来对两个数做乘法,我们希望基于计算两个数之和的子电路来构建该逻辑电路。计算两个数之和的子电路是构建在用于两位相加的子子电路上的。电路大致如图5-2所示。
最终的电路至少包含3层。实际上,这个电路很可能超过3层,因为可以将子任务分解成更小的单元,但基本思想就是这样。
可见深度电路让设计过程变得更简单,但对于设计本身帮助并不大。其实用数学可以证明,对于某些函数计算,浅层电路所需的电路单元要比深度电路多得多。例如20世纪80年代初的一些著名的论文已经提出,通过浅层电路计算比特集合的奇偶性需要指数级的逻辑门。然而,如果使用更深的电路,那么可以使用规模很小的电路来计算奇偶性:仅仅需要计算比特对的奇偶性,然后使用这些结果来计算比特对的对的奇偶性,以此类推,从而得出整体的奇偶性。这样一来,深度电路就能在本质上超过浅层电路了。
前文一直将神经网络看作疯狂的客户,几乎讲到的所有神经网络都只包含一层隐藏神经元(另外还有输入层和输出层),如图5-3所示。
这些简单的神经网络已经非常有用了,前面使用这样的神经网络识别手写数字,准确率高达98%!而且,凭直觉来看,拥有更多隐藏层的神经网络会更强大,如图5-4所示。
这样的神经网络可以使用中间层构建出多层抽象,正如在布尔电路中所做的那样。如果进行视觉模式识别,那么第1层的神经元可能学会识别边;第2层的神经元可以在此基础上学会识别更加复杂的形状,例如三角形或矩形;第3层将能够识别更加复杂的形状,以此类推。有了这些多层抽象,深度神经网络似乎可以学习解决复杂的模式识别问题。正如电路示例所体现的那样,理论研究表明深度神经网络本质上比浅层神经网络更强大。
如何训练深度神经网络呢?本章尝试使用我们熟悉的学习算法——基于反向传播的随机梯度下降,来训练深度神经网络。但是,这会产生问题,因为我们的深度神经网络并不比浅层神经网络的性能强多少。
这似乎与前面的讨论相悖,就此退缩吗?当然不,下面深入探究使得深度神经网络训练困难的原因。仔细研究便会发现,在深度神经网络中,不同层的学习速度差异很大。后面的层正常学习时,前面的层常常会在训练中停滞不前,基本上学不到什么。这种停滞并不是因为运气不佳,而是有着更根本的原因,并且这些原因和基于梯度的学习技术相关。
随着更加深入地理解这个问题,也会发现相反的情形:前面的层可能学习得很好,但是后面的层停滞不前。实际上,我们发现在深度神经网络中使用基于梯度下降的学习算法本身存在不稳定性。这种不稳定性使得前面或后面的层的学习过程阻滞。
这的确是个坏消息,但真正理解了这些难点后,就能掌握高效训练深度神经网络的关键所在。而且这些发现也是第6章的预备知识,届时会介绍如何使用深度学习解决图像识别问题。
梯度消失问题
在训练深度神经网络时,究竟哪里出了问题?
为了回答这个问题,首先回顾一下使用单一隐藏层的神经网络示例。这里仍以MNIST数字分类问题作为研究和试验的对象。
你也可以使用自己的计算机训练神经网络。如果想同步跟随这些步骤,需要用到NumPy,可以使用如下命令复制所有代码:
git clone https://github.com/mnielsen/neural-networks-and-deep-learning.git
如果你不使用Git,可以直接在随书下载的压缩包里找到数据和代码。
进入src子目录,在Python shell中加载MNIST数据:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
初始化神经网络:
>>> import network2
>>> net = network2.Network([784, 30, 10])
该神经网络有784个输入神经元,对应输入图片的28×28 = 784个像素点。我们设置隐藏神经元为30个,输出神经元为10个,对应10个MNIST数字(0~9)。
训练30轮,小批量样本大小为10,学习率,正则化参数
。训练时也会在validation_data上监控分类准确率:
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)
最终的分类准确率为96.48%(也可能不同,每次运行实际上都会有一点点偏差),这和前面的结果相似。
接下来增加另外一个隐藏层,它也包含30个神经元,并使用相同的超参数进行训练:
>>> net = network2.Network([784, 30, 30, 10])
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)
分类准确率稍有提升,到了96.90%,这说明增加深度有效果,那就再增加一个隐藏层,它同样有30个神经元:
>>> net = network2.Network([784, 30, 30, 30, 10])
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)
结果分类准确率不仅没有提升,反而下降到了96.57%,这与最初的浅层神经网络相差无几。尝试再增加一层:
>>> net = network2.Network([784, 30, 30, 30, 30, 10])
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)
分类准确率继续下降,变为96.53%。虽然这从统计角度看算不上显著下降,但释放出了不好的信号。
这种现象非常奇怪。根据常理判断,额外的隐藏层能让神经网络学到更加复杂的分类函数,然后在分类时表现得更好。按理说不应该变差,有了额外的神经元层,再糟糕也不过是没有作用,然而情况并非如此。
这究竟是为什么呢?理论上,额外的隐藏层的确能够起作用,然而学习算法没有找到正确的权重和偏置。下面研究学习算法本身出了什么问题,以及如何改进。
为了直观理解这个问题,可以将神经网络的学习过程可视化。图5-5展示了[784,30,30,10]神经网络的一部分——两个隐藏层,每层各有30个神经元。图中每个神经元都有一个条形统计图,表示在神经网络学习时该神经元改变的速度,长条代表权重和偏置变化迅速,反之则代表变化缓慢。确切地说,这些条代表每个神经元上的,即代价关于神经元偏置的变化速率。第2章讲过,这个梯度量不仅控制着学习过程中偏置改变的速度,也控制着输入到神经元的权重的改变速度。遗忘了这些细节也不要紧,这里只需要记住这些条表示每个神经元权重和偏置在神经网络学习时的变化速率。
简单起见,图5-5只展示了每个隐藏层最上方的6个神经元。之所以没有展示输入神经元,是因为它们没有需要学习的权重或偏置;之所以没有展示输出神经元,是因为这里进行的是层与层的比较,而比较神经元数量相同的两层更为合理。神经网络初始化后立即得到了训练前期的结果,如图5-5所示。
该神经网络是随机初始化的,因此神经元的学习速度其实相差较大,而且隐藏层2上的条基本上要比隐藏层1上的条长,所以隐藏层2的神经元学习得更快。这仅仅是一个巧合吗?这能否说明第2个隐藏层的神经元一般会比第1个隐藏层的神经元学习得更快呢?
借助以上定义,在和图5-5相同的配置下,,这样就解开了之前的疑惑:第2个隐藏层的神经元确实比第1个隐藏层的学得快。
如果添加更多隐藏层,会如何呢?如果有3个隐藏层,比如一个[784,30,30,30,10]神经网络,那么对应的学习速度分别是0.012、0.060和0.283,其中前面两个隐藏层的学习速度还是慢于最后的隐藏层。假设再增加一个包含30个神经元的隐藏层,那么对应的学习速度分别是0.003、0.017、0.070和0.285。还是相同的模式:前面的隐藏层比后面的隐藏层学习得更慢。
这就是训练开始时的学习速度,即刚刚初始化之后的情况。那么随着训练的推进,学习速度会发生怎样的变化呢?以只有两个隐藏层的神经网络为例,其学习速度的变化如图5-6所示。
这些结果产生自对1000幅训练图像应用梯度下降算法,训练了500轮。这与通常的训练方式不同,没有使用小批量方式,仅仅使用了1000幅训练图像,而不是全部的50 000幅图像。这并不是什么新尝试,也不是敷衍了事,而显示了使用小批量随机梯度下降会让结果包含更多噪声(尽管在平均噪声时结果很相似)。可以使用确定好的参数对结果进行平滑处理,以便看清楚真实情况。
如图5-6所示,两个隐藏层一开始速度便不同,二者的学习速度在触底前迅速下降。此外,第1层的学习速度比第2层慢得多。
更复杂的神经网络情况如何呢?下面进行类似的试验,但这次神经网络有3个隐藏层([784,30,30,30,10]),如图5-7所示。
同样,前面的隐藏层比后面的隐藏层学习得更慢。最后一个试验用到4个隐藏层([784,30,30,30,30,10]),看看情况如何,如图5-8所示。
同样的情况出现了,前面的隐藏层慢于后面的隐藏层。其中隐藏层1的学习速度跟隐藏层4的差了两个数量级,即前者是后者的1/100,难怪之前训练这些神经网络时出现了问题。
这就有了重要发现:至少在某些深度神经网络中,梯度在隐藏层反向传播时倾向于变小。这意味着前面的隐藏层中的神经元比后面的隐藏层中的神经元学习得更慢。本节只研究了一个神经网络,其实多数神经网络存在这个现象,即梯度消失问题。
为何会出现梯度消失问题呢?如何避免它呢?在训练深度神经网络时如何处理这个问题呢?实际上,这个问题并非不可避免,然而替代方法并不完美,也会出现问题:前面的层中的梯度会变得非常大!这被称为梯度爆炸问题,它不比梯度消失问题容易处理。一般而言,深度神经网络中的梯度是不稳定的,在前面的层中可能消失,可能“爆炸”。这种不稳定性是基于梯度学习的深度神经网络存在的根本问题,也就是需要理解的地方。如果可能,应该采取恰当的措施解决该问题。
关于梯度消失(或不稳定),一种观点是确定这真的成问题。暂时换一个话题,假设要最小化一元函数,如果其导数
很小,这难道不是一个好消息吗?是否意味着已经接近极值点了?同样,深度神经网络中前面隐藏层的小梯度是否表示不用费力调整权重和偏置了?
当然,实际情况并非如此。想想随机初始化神经网络中的权重和偏置。对于任意任务,单单使用随机初始化的值难以获得良好结果。具体而言,考虑MNIST问题中神经网络第1层的权重,随机初始化意味着第1层丢失了输入图像的几乎所有信息。即使后面的层能得到充分的训练,这些层也会因为没有充足的信息而难以识别输入图像。因此,第1层不进行学习是行不通的。如果继续训练深度神经网络,就需要弄清楚如何解决梯度消失问题。
梯度消失的原因
为了弄清楚梯度消失问题出现的原因,看一个极简单的深度神经网络:每层都只有单一神经元。图5-9展示了有3个隐藏层的神经网络。
表达式结构如下:每个神经元都有项,每个权重都有
项,此外还有一个
项,它表示最终的代价函数。注意,这里将表达式中的每一项置于对应的位置,所以神经网络本身就是对表达式的解读。
你可以不深究这个表达式,直接跳到下文讨论为何出现梯度消失的内容。这样做不会影响理解,因为实际上该表达式只是反向传播的特例。不过,对于该表达式为何正确,了解一下也很有趣(可能还会给你有益的启示)。
假设对偏置做了微调
,这会导致神经网络中其余元素发生一系列变化。首先会使得第1个隐藏神经元输出产生
的变化,进而导致第2个隐藏神经元的带权输入产生
的变化,第2个隐藏神经元输出随之产生
的变化,以此类推,最终输出的代价会产生
的变化。这里有:
5.2.1 为何出现梯度消失
梯度的完整表达式如下:
除了最后一项,该表达式几乎就是一系列的乘积。为了理解每一项,先看看sigmoid函数的导数的图像,如图5-11所示。
该导数在时达到峰值。如果使用标准方法来初始化神经网络中的权重,那么会用到一个均值为0、标准差为1的高斯分布,因此所有权重通常会满足
。基于这些信息,可知有
。另外,在对所有这些项计算乘积后,最终结果肯定会呈指数级下降:项越多,乘积下降得越快。梯度消失的原因初见端倪。
更具体一点,比较和稍后面一个偏置的梯度,例如
。当然,还未明确给出
的表达式,但计算方式是和
相同的。二者的对比如图5-12所示。
这两个表达式有很多项相同,但多了两项。由于这些项都小于
,因此
会是
的
或者更小,这其实就是梯度消失的根本原因。
当然,以上并非梯度消失问题的严谨证明,而是一个不太正式的论断,可能还有别的一些原因。我们尤其想知道权重在训练中是否会增长,如果会,项
是否不再满足这个条件。实际上,如果项变得很大——超过1——那么梯度消失问题将不会出现。当然,这时梯度会在反向传播中呈指数级增长,即出现了梯度爆炸问题。
5.2.2 梯度爆炸问题
下面分析梯度爆炸的原因。举的例子可能不那么自然:固定神经网络中的参数,以确保发生梯度爆炸。即使不太自然,这个例子也能说明梯度爆炸确实会发生(而非假设)。
5.2.3 梯度不稳定问题
根本问题其实不是梯度消失问题或梯度爆炸问题,而是前面的层上的梯度来自后面的层上项的乘积。当层过多时,神经网络就会变得不稳定。让所有层的学习速度都近乎相同的唯一方式是所有这些项的乘积达到一种平衡。如果没有某种机制或者更加本质的保证来达到平衡,那么神经网络就很容易不稳定。简而言之,根本问题是神经网络受限于梯度不稳定问题。因此,如果使用基于梯度的标准学习算法,那么不同的层会以不同的速度学习。
练 习
在关于梯度消失问题的讨论中,我们采用了这个结论。假设使用一个不同的激活函数,其导数值更大,这有助于避免梯度不稳定问题吗?
5.2.4 梯度消失问题普遍存在
如前所述,在神经网络中,前面的层可能会出现梯度消失或梯度爆炸。实际上,在使用sigmoid神经元时,通常发生的是梯度消失,原因见表达式。为了避免梯度消失问题,需要满足
。也许你认为如果
很大就行了,实际上更复杂。原因在于
项同样依赖
:
,其中
是输入激活值,所以在让
变大时,需要保持
不变小。这会是很大的限制,因为
变大的话,也会使得
变得非常大。看看
的图像,就会发现它出现在
的两翼外,取到很小的值。为了避免出现这种情况,唯一的方法是让输入激活值落在相当小的范围内(这个量化的解释见下面第一个问题)。这种情况偶尔会出现,但通常不会发生,所以梯度消失问题更常见。
问 题
考虑乘积。假设有
,请完成如下证明。
(1) 证明这种情况只在时才会出现。
(2) 假设,考虑满足
的输入激活值
的集合。请证明:满足上述条件的集合跨了一个不超过如下宽度的区间。
(3) 证明以上表达式在时取最大值(约为0.45)。所以,即使每个条件都满足,仍有
一个小的输入激活值区间,以此避免梯度消失问题。
恒等神经元:考虑一个只有单一输入的神经元,对应的权重为
,偏置为
,输出上的权重为
。请证明:通过合理选择权重和偏置,可以确保
,其中
。
这样的神经元可用作恒等神经元,即输出和输入相同(按权重因子成比例缩放)。提示:可以重写,假设
很小,以及对
使用泰勒级数展开。
复杂神经网络中的梯度不稳定
前面研究了简单的神经网络,其中每个隐藏层只包含一个神经元。那么,每个隐藏层包含很多神经元的深度神经网络又如何呢?图5-13展示了一个复杂的深度神经网络。
实际上,在这样的神经网络中,同样的情况也会发生。在介绍反向传播时,本书提到了在一个共L层的神经网络中,第l层的梯度是:
其中是一个对角矩阵,它的每个元素是第l层的带权输入
,
是不同层的权重矩阵,
是每个输出激活值的偏导数向量。
相比单一神经元的情况,这是更复杂的表达式,但仔细看的话,会发现本质上形式还是很相似的,主要区别是包含了更多形如的对。而且,矩阵
在对角线上的值很小,不会超过
。由于权重矩阵
不是太大,因此每个额外的项
会令梯度向量更小,导致梯度消失。更普遍的是,在乘积中大量的项会导致梯度不稳定,类似于前面的例子。在实践中,往往发现sigmoid神经网络中前面的层的梯度指数级地消失,所以这些层的学习速度就会变得很慢。这种减速并非偶然现象,也是由所采用的训练方法决定的。
深度学习的其他障碍
本章着重研究了深度学习的障碍——梯度消失,以及更常见的梯度不稳定。实际上,尽管梯度不稳定是深度学习面临的根本问题,但并非唯一的障碍。当前的研究侧重于更好地理解训练深度神经网络时遇到的挑战,这里不会给出详尽的总结,而会列出一些论文,带你一窥当前的研究方向。
2010年,Xavier Glorot和Yoshua Bengio提出,使用sigmoid函数训练深度神经网络会出现问题。他们声称sigmoid函数会导致训练早期最终层的激活函数在0附近饱和,进而导致学习缓慢。他们也给出了sigmoid函数的一些替代选择,以消除饱和对性能的影响。
2013年,Ilya Sutskever、James Martens、George Dahl和Geoffrey Hinton研究了深度学习使用随机权重初始化和基于动量(momentum)的SGD方法。在这两种情形下,好的选择能让深度神经网络的训练效果显著不同。
以上例子表明,“什么使得训练深度神经网络非常困难”这个问题相当复杂。本章着重研究了基于梯度的学习算法的不稳定性。结果表明,激活函数的选择、权重的初始化,甚至学习算法的实现方式都是影响因素。当然,神经网络的架构和其他超参数也很重要。因此,有太多因素会影响神经网络的训练难度,理解所有这些因素仍是当前的研究重点。尽管这听起来有点悲观,但第6章将介绍的一些方法在一定程度上能解决和规避这些问题。
赠书活动
想要了解关于深度学习的更多干货知识,关注AI科技大本营并在评论区分享你对本文的学习心得或深度学习的见解,我们将从中选出5条优质评论,各送出《深入浅出神经网络与深度学习》一本。
▼ 扫码或点击阅读原文获取本书详情 ▼
相关文章:

dhcp 搭建
自带rpm包安装:# mount /dev/cdrom /media 挂载 # cd /media/Server/ 进入目录 # rpm -ivh dhcp-3.0.5-18.el5.i386.rpm 安装DHCP # cp /usr/share/doc/dhcp-3.0.5/dhcpd.conf.sample /etc/dhcpd.conf …
锦上添花DataGrid!
作者: cuike519的专栏 http://blog.csdn.net/cuike519/我们知道如果datagrid的宽度比较长那么使得我们很难分清楚行数据,也就是很容易 使我们看错行,我想如果当我们的鼠标移动到datagrid的行上,他可以清楚的显示给 我们就好了…
linux服务器优化1.0版
1.服务器修改IP vim /etc/sysconfig/network-scripts/ifcfg-eth12.修改dns服务器 vim /etc/resolv.conf 3.关闭selinux vim /etc/selinux/config 4.修改主机名iZ118z08 vim /etc/sysconfig/network5.禁用control-alt-delete vim /e…
给DataGrid添加确定删除的功能
给DataGrid添加确定删除的功能DataGrid的功能我想大家是知道的,我在实际的应用中遇到如下的问题,客户要求在删除之前做一次提示。类 似于windows。首先我们都知道DataGrid支持删除的功能,我们可以向DataGrid里面添加删除列就可以实现&#x…
操纵神经元构造后门,腾讯朱雀实验室披露AI模型新型攻击手法
近日,在第19届XCon安全焦点信息安全技术峰会上,腾讯朱雀实验室首度公开亮相。这个颇有神秘色彩的安全实验室专注于实战攻击技术研究和AI安全技术研究,以攻促防,守护腾讯业务及用户安全。会上,腾讯朱雀实验室高级安全研…
工程师进阶之路(四)
转载自 量子恒道官方博客 地址:http://blog.linezing.com 如何和“老板”沟通 我们是一线工程师的时候,和我们的直接技术管理者沟通是非常容易的。我们的技术架构、代码风格、系统扩展性、工程化全局考虑就是我们赢得信任和信赖的名片。但是随着我们的…
Hadoop API文档地址
经常需要查阅,做一下笔记 http://hadoop.apache.org/docs/ http://hadoop.apache.org/docs/current1/api/ http://hadoop.apache.org/docs/current2/api/

两个FTP对传文件
2019独角兽企业重金招聘Python工程师标准>>> #!/bin/bash ftp -n<<! open hostname user username password binary cd /FTP_A_Directory lcd /tmp/tmpSave prompt mget * close bye ! ftp -n<<! open hostname user username password binary cd /…
全国大学生数学建模竞赛中,哈工大被禁用MATLAB
整理 | 屠敏出品 | AI科技大本营(ID:rgznai100)AK47 VS “小米加步枪”同台竞技,最终会有什么样的结果?目前我们尚未可知,但是这样的“竞赛”却在真实上演中。近日,在全国大学生数学建模竞赛中&…
JDK NIO编程
我们首先需要澄清一个概念:NIO到底是什么的简称?有人称之为New I/O,因为它相对于之前的I/O类库是新增的,所以被称为New I/O,这是它的官方叫法。但是,由于之前老的I/O类库是阻塞I/O,New I/O类库的…
ASP.NET ViewState 初探
Susan Warren Microsoft Corporation 与刚接触 ASP.NET 页面的开发人员交谈时,他们通常向我提出的第一个问题就是:“那个 ViewState 到底是什么?”他们的语气中流露出的那种感觉,就象我来到一家异国情调的餐馆,侍者端…
[emuch.net]MatrixComputations(1-6)
matrixComputation转载于:https://www.cnblogs.com/stoneresearch/archive/2012/06/24/4336678.html
身为面向对象编程、移动计算机之父的他,为何说“计算机革命还没真正到来”?...
作者 | 年素清责编 | 李雪敬出品 | 程序人生(ID:coder_life) 艾伦凯(艾伦 Kay)是近代计算机革命先驱之一,他最早提出了“面向对象编程”的概念,也是“Dynabook”(笔记本电脑的雏形)的最早阐述者…

动态表单构建器——建造者模式
在编写一个弹出框时,它可以包含确定按钮,取消按钮,标题栏,关闭按钮,最小化按钮,内容,最大化按钮等内容,但这些内容在不同的需求下又不是必须存在的,不同的需求需要对这些组件自由组合…

网页素材大宝库:50套非常精美的图标素材
图标对网页设计师来说是宝贵的财富,高质量的图标素材既能为设计师节省时间,又能有很不错的效果。网上的免费图标素材非常多,可以说是琳琅满目,那些充满分享精神的设计师们把素材共享出来,让更多的人可以使用他们的优秀…
AI 面试“泛滥”的时代,HR该如何甄别真假“AI”?
作者 | 无缺编辑 | 王晓曼出品 | AI科技大本营(ID:rgznai100)在互联网、物联网蓬勃发展的中国,AI在商业化领域的运用,大家并不陌生。但AI在人力资源领域的发展前景如何?这是一个复杂且相对陌生的话题,也没有…

C语言里面%2d 意思
看看下面的说明就知道啦:修饰符 格式说明 意义 int a1;int b1234;double c1.2345678;printf("%2d\n",a);printf("%2d\n",a);printf("%4d\n",a);printf("%2d\n",b);printf("%2d\n",b);printf("%4d\n",b…

DatagridView自动充满屏幕,并能指定某列宽度
1、要使datagridview正好充满屏幕,设置其AutoSizeColumnsMode属性为fill 2、 同时,我们想要某列宽点,某列窄点,在AutoSizeColumnsMode属性为fill的前提下,设置FillWeight 属性 FillWeight :获取或设置一个值…
在网页中动态的生成一个gif图片
作者: love.net 大家知道股票网站的K线图是动态生成的定时刷新PHP 就有动态生成图片的功能 那么怎样用asp.net在网页中动态的生成一个图片呢? 下面我要举的例子是动态的生成一个图片显示当前时间 namespace Wmj { using System; using System.Drawing; u…
11项重大发布!百度大脑语言与知识技术峰会全程高能
AI正在向更深层次进化,语言与知识技术的重要性愈加凸显。8月25日,以“掌握知识、理解语言、拥有智能”为主题的百度大脑语言与知识技术峰会重磅开启,百度CTO王海峰发表主旨演讲,解读百度语言与知识技术的发展历程与最新成果&#…
MySQL 5.5.35 单机多实例配置详解
一、前言 二、概述 三、环境准备 四、安装MySQL 5.5.35 五、新建支持多实例的配置文件(我这里配置的是四个实例) 六、初始化多实例数据库 七、提供管理脚本 mysqld_multi.server 八、整体备份方便后续迁移 九、管理MySQL多实例 十、登录MySQL多实例 十一…
ASP.NET超凡的代码控制
crystal译yesky 适应性 肯定的是,通常任何一个全新的技术,在市场渗透都会花费一些时间。微软正在开始让ASP和IIS平台通过行业验证,以便让其作为其它网络服务器之外可以供选择的平台 对于在其基本构架上的如此巨大的改变,是很难说服…
老码农:这是我见过最操蛋的代码,切勿模仿!
作为一名老码农,我的心这次凉透了!事情起因很简单:我在全国最大ZZ的同性组织某Hub上浏览时候,发现这样的一条信息:Python 超过 C、JS 薪酬排行第一(最大招聘网站Indeed.com数据)噗,9…
QTP时间格式的转换(YYYYMMDDHHMMSS)
之前查了好多资料都是这样写的: sendTime year(sendTime) & right( "00 " & month(sendTime),2) & right( "00 " & day(sendTime),2) & right( "00 " & hour(sendTime),2) &…
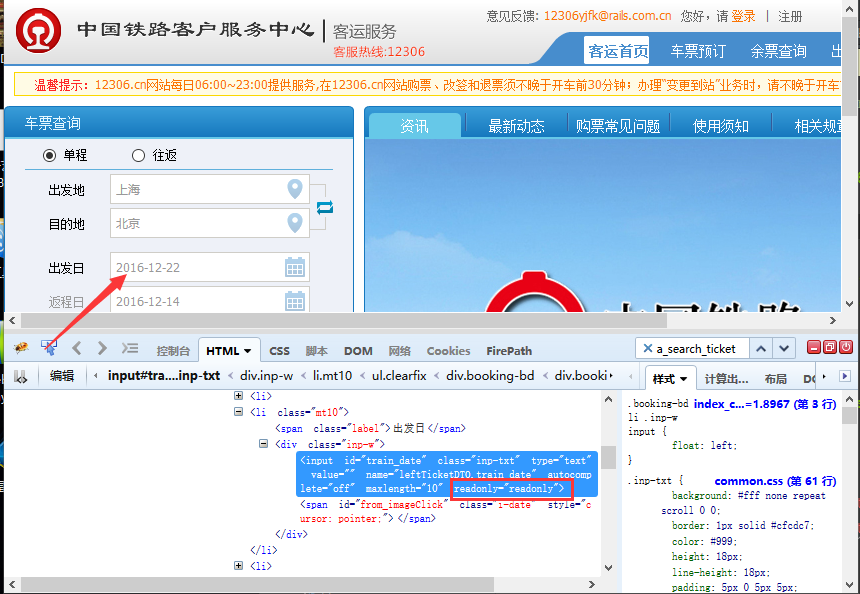
Selenium2+python自动化25-js处理日历控件(修改readonly属性)
前言 日历控件是web网站上经常会遇到的一个场景,有些输入框是可以直接输入日期的,有些不能,以我们经常抢票的12306网站为例,详细讲解如何解决日历控件为readonly属性的问题。 基本思路:先用js去掉readonly属性…
ASP.NET强大的性能
crystal译 yesky 一个程序,速度是一件非常令人渴望的东西。一旦代码开始工作,接下来你就得尽可能的让它运作的快些,再快些, 在ASP中你只有尽可能拧干你的代码,以至于不得不将他们移植到一个仅有很少一点性能的部件中。…
POJ-1753 Flip Game 枚举 状态压缩
刚开始做这题时总是在想应该用何种的策略来进行翻装,最后还是没有想出来~~~ 这题过的代码的思路是用在考虑到每个点被翻装的次数只有0次或者是1次,所以对于16个点就只有2^16中请况了。再运用位运算将状态压缩到一个32位…
“半真半假”DeepFake换脸也能精准识别?阿里安全提出全新检测方法
一段包含多个人脸的视频中,攻击者只对一个或者几个人的人脸进行伪造,这种“半真半假”的伪造情况能否被检测识别?近日,阿里安全图灵实验室宣布,其已成功打造出针对这种换脸视频的DeepFake检测技术,阐述该技…
python 定时任务
Python 定时任务 最近学习到了 python 中两种开启定时任务的方法,和大家分享一下心得。 sched.scheduler()threading.Timer()sched 定时任务 使用sched的套路如下: s sched.scheduler(time.time, time.sleep) s.enter(delay, priority, func1, (arg1, a…
思科AP与交换机端口的配置
思科AP与交换机端口的配置。 思科AP可以分IOS AP 和LAP。 1、IOS AP 中如果AP上需要创建多个SSID,连接的交换机端口则需要: switch(config-interfa)# sw mod trunk switch(config-interfa)# sw trunk allow vlan 1,x,x,x (SSID对应的VLAN) 另外注意&…