怎样用Python控制图片人物动起来?一文就能Get!
作者 | 李秋键
责编 | 李雪敬
头图 | CSDN 下载自视觉中国
出品 | AI科技大本营(ID:rgznai100)
引言:近段时间,一个让梦娜丽莎图像动起来的项目火遍了朋友圈。而今天我们就将实现让图片中的人物随着视频人物一起产生动作。
其中通过在静止图像中动画对象产生视频有无数的应用跨越的领域兴趣,包括电影制作、摄影和电子商务。更准确地说,是图像动画指将提取的视频外观结合起来自动合成视频的任务一种源图像与运动模式派生的视频。
近年来,深度生成模型作为一种有效的图像动画技术出现了视频重定向。特别是,可生成的对抗网络(GANS)和变分自动编码器(VAES)已被用于在视频中人类受试者之间转换面部表情或运动模式。
根据论文FirstOrder Motion Model for Image Animation可知,在姿态迁移的大任务当中,Monkey-Net首先尝试了通过自监督范式预测关键点来表征姿态信息,测试阶段估计驱动视频的姿态关键点完成迁移工作。在此基础上,FOMM使用了相邻关键点的局部仿射变换来模拟物体运动,还额外考虑了遮挡的部分,遮挡的部分可以使用image inpainting生成。
而今天我们就将借助论文所分享的源代码,构建模型创建自己需要的人物运动。具体流程如下。
实验前的准备
首先我们使用的python版本是3.6.5所用到的模块如下:
imageio模块用来控制图像的输入输出等。
Matplotlib模块用来绘图。
numpy模块用来处理矩阵运算。
Pillow库用来加载数据处理。
pytorch模块用来创建模型和模型训练等。
完整模块需求参见requirements.txt文件。
模型的加载和调用
通过定义命令行参数来达到加载模型,图片等目的。
(1)首先是训练模型的读取,包括模型加载方式:
def load_checkpoints(config_path, checkpoint_path, cpu=False):with open(config_path) as f:config = yaml.load(f)generator = OcclusionAwareGenerator(**config['model_params']['generator_params'],**config['model_params']['common_params'])if not cpu:generator.cuda()kp_detector = KPDetector(**config['model_params']['kp_detector_params'],**config['model_params']['common_params'])if not cpu:kp_detector.cuda()if cpu:checkpoint = torch.load(checkpoint_path, map_location=torch.device('cpu'))else:checkpoint = torch.load(checkpoint_path)generator.load_state_dict(checkpoint['generator'])kp_detector.load_state_dict(checkpoint['kp_detector'])if not cpu:generator = DataParallelWithCallback(generator)kp_detector = DataParallelWithCallback(kp_detector)generator.eval()kp_detector.eval()return generator, kp_detector
(2)然后是利用模型创建产生的虚拟图像,找到最佳的脸部特征:
def make_animation(source_image, driving_video, generator, kp_detector, relative=True, adapt_movement_scale=True, cpu=False):with torch.no_grad():predictions = []source = torch.tensor(source_image[np.newaxis].astype(np.float32)).permute(0, 3, 1, 2)if not cpu:source = source.cuda()driving = torch.tensor(np.array(driving_video)[np.newaxis].astype(np.float32)).permute(0, 4, 1, 2, 3)kp_source = kp_detector(source)kp_driving_initial = kp_detector(driving[:, :, 0])for frame_idx in tqdm(range(driving.shape[2])):driving_frame = driving[:, :, frame_idx]if not cpu:driving_frame = driving_frame.cuda()kp_driving = kp_detector(driving_frame)kp_norm = normalize_kp(kp_source=kp_source, kp_driving=kp_driving,kp_driving_initial=kp_driving_initial, use_relative_movement=relative,use_relative_jacobian=relative, adapt_movement_scale=adapt_movement_scale)out = generator(source, kp_source=kp_source, kp_driving=kp_norm) predictions.append(np.transpose(out['prediction'].data.cpu().numpy(), [0, 2, 3, 1])[0])return predictions
def find_best_frame(source, driving, cpu=False):import face_alignmentdef normalize_kp(kp):kp = kp - kp.mean(axis=0, keepdims=True)area = ConvexHull(kp[:, :2]).volumearea = np.sqrt(area)kp[:, :2] = kp[:, :2] / areareturn kpfa = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, flip_input=True,device='cpu' if cpu else 'cuda')kp_source = fa.get_landmarks(255 * source)[0]kp_source = normalize_kp(kp_source)norm = float('inf')frame_num = 0for i, image in tqdm(enumerate(driving)):kp_driving = fa.get_landmarks(255 * image)[0]kp_driving = normalize_kp(kp_driving)new_norm = (np.abs(kp_source - kp_driving) ** 2).sum()if new_norm < norm:norm = new_normframe_num = i
return frame_num
(3) 接着定义命令行调用参数加载图片、视频等方式:
parser = ArgumentParser()parser.add_argument("--config", required=True, help="path to config")parser.add_argument("--checkpoint", default='vox-cpk.pth.tar', help="path to checkpoint to restore")parser.add_argument("--source_image", default='sup-mat/source.png', help="path to source image")parser.add_argument("--driving_video", default='sup-mat/source.png', help="path to driving video")parser.add_argument("--result_video", default='result.mp4', help="path to output")parser.add_argument("--relative", dest="relative", action="store_true", help="use relative or absolute keypoint coordinates")parser.add_argument("--adapt_scale", dest="adapt_scale", action="store_true", help="adapt movement scale based on convex hull of keypoints")parser.add_argument("--find_best_frame", dest="find_best_frame", action="store_true", help="Generate from the frame that is the most alligned with source. (Only for faces, requires face_aligment lib)")parser.add_argument("--best_frame", dest="best_frame", type=int, default=None, help="Set frame to start from.")parser.add_argument("--cpu", dest="cpu", action="store_true", help="cpu mode.")parser.set_defaults(relative=False)parser.set_defaults(adapt_scale=False)opt = parser.parse_args()source_image = imageio.imread(opt.source_image)reader = imageio.get_reader(opt.driving_video)fps = reader.get_meta_data()['fps']driving_video = []try:for im in reader:driving_video.append(im)except RuntimeError:passreader.close()source_image = resize(source_image, (256, 256))[..., :3]driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video]generator, kp_detector = load_checkpoints(config_path=opt.config, checkpoint_path=opt.checkpoint, cpu=opt.cpu)if opt.find_best_frame or opt.best_frame is not None:i = opt.best_frame if opt.best_frame is not None else find_best_frame(source_image, driving_video, cpu=opt.cpu)print ("Best frame: " + str(i))driving_forward = driving_video[i:]driving_backward = driving_video[:(i+1)][::-1]predictions_forward = make_animation(source_image, driving_forward, generator, kp_detector, relative=opt.relative, adapt_movement_scale=opt.adapt_scale, cpu=opt.cpu)predictions_backward = make_animation(source_image, driving_backward, generator, kp_detector, relative=opt.relative, adapt_movement_scale=opt.adapt_scale, cpu=opt.cpu)predictions = predictions_backward[::-1] + predictions_forward[1:]else:predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=opt.relative, adapt_movement_scale=opt.adapt_scale, cpu=opt.cpu)
imageio.mimsave(opt.result_video, [img_as_ubyte(frame) for frame in predictions], fps=fps)模型的搭建
整个模型训练过程是图像重建的过程,输入是源图像和驱动图像,输出是保留源图像物体信息的含有驱动图像姿态的新图像,其中输入的两张图像来源于同一个视频,即同一个物体信息,那么整个训练过程就是驱动图像的重建过程。大体上来说分成两个模块,一个是motion estimation module,另一个是imagegeneration module。
(1)其中通过定义VGG19模型建立网络层作为perceptual损失。
其中手动输入数据进行预测需要设置更多的GUI按钮,其中代码如下:
class Vgg19(torch.nn.Module):"""Vgg19 network for perceptual loss. See Sec 3.3."""def __init__(self, requires_grad=False):super(Vgg19, self).__init__()vgg_pretrained_features = models.vgg19(pretrained=True).featuresself.slice1 = torch.nn.Sequential()self.slice2 = torch.nn.Sequential()self.slice3 = torch.nn.Sequential()self.slice4 = torch.nn.Sequential()self.slice5 = torch.nn.Sequential()for x in range(2):self.slice1.add_module(str(x), vgg_pretrained_features[x])for x in range(2, 7):self.slice2.add_module(str(x), vgg_pretrained_features[x])for x in range(7, 12):self.slice3.add_module(str(x), vgg_pretrained_features[x])for x in range(12, 21):self.slice4.add_module(str(x), vgg_pretrained_features[x])for x in range(21, 30):self.slice5.add_module(str(x), vgg_pretrained_features[x])self.mean = torch.nn.Parameter(data=torch.Tensor(np.array([0.485, 0.456, 0.406]).reshape((1, 3, 1, 1))),requires_grad=False)self.std = torch.nn.Parameter(data=torch.Tensor(np.array([0.229, 0.224, 0.225]).reshape((1, 3, 1, 1))),requires_grad=False)if not requires_grad:for param in self.parameters():param.requires_grad = Falsedef forward(self, X):X = (X - self.mean) / self.stdh_relu1 = self.slice1(X)h_relu2 = self.slice2(h_relu1)h_relu3 = self.slice3(h_relu2)h_relu4 = self.slice4(h_relu3)h_relu5 = self.slice5(h_relu4)out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]return out
(2)创建图像金字塔计算金字塔感知损失:
class ImagePyramide(torch.nn.Module):"""Create image pyramide for computing pyramide perceptual loss. See Sec 3.3"""def __init__(self, scales, num_channels):super(ImagePyramide, self).__init__()downs = {}for scale in scales:downs[str(scale).replace('.', '-')] = AntiAliasInterpolation2d(num_channels, scale)self.downs = nn.ModuleDict(downs)def forward(self, x):out_dict = {}for scale, down_module in self.downs.items():out_dict['prediction_' + str(scale).replace('-', '.')] = down_module(x)return out_dict
(3)等方差约束的随机tps变换
class Transform:"""Random tps transformation for equivariance constraints. See Sec 3.3"""def __init__(self, bs, **kwargs):noise = torch.normal(mean=0, std=kwargs['sigma_affine'] * torch.ones([bs, 2, 3]))self.theta = noise + torch.eye(2, 3).view(1, 2, 3)self.bs = bsif ('sigma_tps' in kwargs) and ('points_tps' in kwargs):self.tps = Trueself.control_points = make_coordinate_grid((kwargs['points_tps'], kwargs['points_tps']), type=noise.type())self.control_points = self.control_points.unsqueeze(0)self.control_params = torch.normal(mean=0,std=kwargs['sigma_tps'] * torch.ones([bs, 1, kwargs['points_tps'] ** 2]))else:self.tps = Falsedef transform_frame(self, frame):grid = make_coordinate_grid(frame.shape[2:], type=frame.type()).unsqueeze(0)grid = grid.view(1, frame.shape[2] * frame.shape[3], 2)grid = self.warp_coordinates(grid).view(self.bs, frame.shape[2], frame.shape[3], 2)return F.grid_sample(frame, grid, padding_mode="reflection")def warp_coordinates(self, coordinates):theta = self.theta.type(coordinates.type())theta = theta.unsqueeze(1)transformed = torch.matmul(theta[:, :, :, :2], coordinates.unsqueeze(-1)) + theta[:, :, :, 2:]transformed = transformed.squeeze(-1)if self.tps:control_points = self.control_points.type(coordinates.type())control_params = self.control_params.type(coordinates.type())distances = coordinates.view(coordinates.shape[0], -1, 1, 2) - control_points.view(1, 1, -1, 2)distances = torch.abs(distances).sum(-1)result = distances ** 2result = result * torch.log(distances + 1e-6)result = result * control_paramsresult = result.sum(dim=2).view(self.bs, coordinates.shape[1], 1)transformed = transformed + resultreturn transformeddef jacobian(self, coordinates):new_coordinates = self.warp_coordinates(coordinates)grad_x = grad(new_coordinates[..., 0].sum(), coordinates, create_graph=True)grad_y = grad(new_coordinates[..., 1].sum(), coordinates, create_graph=True)jacobian = torch.cat([grad_x[0].unsqueeze(-2), grad_y[0].unsqueeze(-2)], dim=-2)return jacobian (4)生成器的定义:生成器,给定的源图像和和关键点尝试转换图像根据运动轨迹引起要点。部分代码如下:
class OcclusionAwareGenerator(nn.Module):def __init__(self, num_channels, num_kp, block_expansion, max_features, num_down_blocks,num_bottleneck_blocks, estimate_occlusion_map=False, dense_motion_params=None, estimate_jacobian=False):super(OcclusionAwareGenerator, self).__init__()if dense_motion_params is not None:self.dense_motion_network = DenseMotionNetwork(num_kp=num_kp, num_channels=num_channels,estimate_occlusion_map=estimate_occlusion_map,**dense_motion_params)else:self.dense_motion_network = Noneself.first = SameBlock2d(num_channels, block_expansion, kernel_size=(7, 7), padding=(3, 3))down_blocks = []for i in range(num_down_blocks):in_features = min(max_features, block_expansion * (2 ** i))out_features = min(max_features, block_expansion * (2 ** (i + 1)))down_blocks.append(DownBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))self.down_blocks = nn.ModuleList(down_blocks)up_blocks = []for i in range(num_down_blocks):in_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i)))out_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i - 1)))up_blocks.append(UpBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))self.up_blocks = nn.ModuleList(up_blocks)self.bottleneck = torch.nn.Sequential()in_features = min(max_features, block_expansion * (2 ** num_down_blocks))for i in range(num_bottleneck_blocks):self.bottleneck.add_module('r' + str(i), ResBlock2d(in_features, kernel_size=(3, 3), padding=(1, 1)))self.final = nn.Conv2d(block_expansion, num_channels, kernel_size=(7, 7), padding=(3, 3))self.estimate_occlusion_map = estimate_occlusion_mapself.num_channels = num_channels
(5)判别器类似于Pix2PixGenerator。
def __init__(self, num_channels=3, block_expansion=64, num_blocks=4, max_features=512,sn=False, use_kp=False, num_kp=10, kp_variance=0.01, **kwargs):super(Discriminator, self).__init__()down_blocks = []for i in range(num_blocks):down_blocks.append(DownBlock2d(num_channels + num_kp * use_kp if i == 0 else min(max_features, block_expansion * (2 ** i)),min(max_features, block_expansion * (2 ** (i + 1))),norm=(i != 0), kernel_size=4, pool=(i != num_blocks - 1), sn=sn))self.down_blocks = nn.ModuleList(down_blocks)self.conv = nn.Conv2d(self.down_blocks[-1].conv.out_channels, out_channels=1, kernel_size=1)if sn:self.conv = nn.utils.spectral_norm(self.conv)self.use_kp = use_kpself.kp_variance = kp_variancedef forward(self, x, kp=None):feature_maps = []out = xif self.use_kp:heatmap = kp2gaussian(kp, x.shape[2:], self.kp_variance)out = torch.cat([out, heatmap], dim=1)for down_block in self.down_blocks:feature_maps.append(down_block(out))out = feature_maps[-1]prediction_map = self.conv(out)return feature_maps, prediction_map
最终通过以下代码调用模型训练“python demo.py--config config/vox-adv-256.yaml --driving_video path/to/driving/1.mp4--source_image path/to/source/7.jpg --checkpointpath/to/checkpoint/vox-adv-cpk.pth.tar --relative --adapt_scale”
效果如下:
完整代码:
https://pan.baidu.com/s/1nPE13oI1qOerN0ANQSH92g
提取码:e4kx
作者简介:
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等等
更多精彩推荐
微信群总有人发广告?用Python写一个自动化机器人消灭他
Cognitive Inference:认知推理下的常识知识库资源、常识推理测试评估与中文实践项目索引
滴滴AI Labs负责人叶杰平离职!CTO 张博接任
一年翻 3 倍,装机量 6 亿台的物联网操作系统又放大招!
谷歌软件工程师薪资百万,大厂薪资有多高?
相关文章:
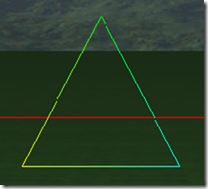
Directx11教程(61) tessellation学习(3)
现在我们看看在不同tess factor的情况下,三角形是如何细分的?(这儿三条边和内部tess factor值是一样的,而且partitioning("integer")) 下面8张图是三角形在tess factor 1到8的情况下的细分细节: 因为TS阶段是硬件自己做…

HTML語法大全
作者:闪吧標籤 , 屬性名稱 , 簡介 <! - - ... - -> 註解 <!> 跑馬燈 <marquee>...</marquee>普通捲動 <marquee behaviorslide>...</marquee>滑動 <marquee behaviorscroll>...</marquee>預設捲動 <marquee beh…
php相关书籍视频
虽然如今web领域,PHP JSP .NET 并驾齐驱,但PHP用的最广,原因不用我多说。 首先发一个PHP手册,方便查询,这个肯定是学PHP必备的。 下载地址:http://u.115.com/file/aq3e5sv9PHP100的视频教程,这个…
你究竟了解多少HTML代码
作者:十二 文章来源: 蓝色理想今天想学习一下基础知识,就看了一下HTML(4.0),发现自己对HTML掌握的太少了。很多代码都很陌生,根本就没见过,更别提用了。就拿<a></a>元素来举个例子。它的属性…
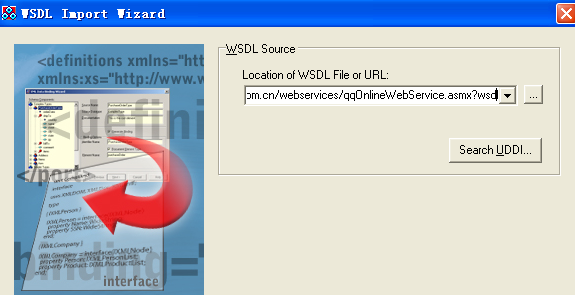
Delphi 调用webservice接口
一、使用向导 1.导入wsdl文件:file--new----other----webservice---WSDLimporter---输入wsdl地址 http://www.webxml.com.cn/webservices/qqOnlineWebService.asmx?wsdl 完成之后,即可导入wsdl文件。 注:结尾处的?wsdl不能少。 2…
都是程序员,凭什么他能站在鄙视链的顶端?
在写代码、改bug之中,有时候会陷入焦虑:明年我还要继续这样的生活吗?程序员群体中有一条无形的鄙视链,最直观的表现就是薪资差异。在最新的调查报告中,全国范围内,程序员年薪达到 50 万以上的,仅…
软件开发经验总结(一)细节决定软件的成败
最近在公司做开发的时候,需要开发一个自动备份的功能,于是我想到了SQL SERVER备份调度功能,于是打开SQL SERVER 备份调度界面,想照样画葫芦做一个,然后20分钟就把该功能做出来。30分钟过去了,我的界面依然还没有做完,原来打算很快做完的界面却总是离目标…
简明 HTML CSS 开发规范
作者:wjack 文章来源: 蓝色理想//总论本规范既是一个开发规范,也是一个脚本语言参考,本规范并不是一个一成不变的必须严格遵守的条文,特殊情况下要灵活运用,做一定的变通。但是,请大家千万不…
B 站神曲damedane:精髓在于换脸,五分钟就能学会
导读:AI 换脸技术层出不穷,但一代更比一代强。最近,一个发表在 NeurIPs 2019 的 AI 换脸模型 first order motion model 火了起来,其表情迁移效果胜过同领域其它方法。最近,这项技术在 B 站引起一波新潮流……来源 | H…

html select以数组的方式提交
2019独角兽企业重金招聘Python工程师标准>>> 1).select 以数组的方式提交 <form> <input type"hidden" name"app" value"wap_test"> <select name"attribute[颜色]"> &…
META的一些功用
作者:军军 文章来源:闪吧 META的一些功用 META标记用于描述不包含在标准HTML里的一些文档信息。基于这一基 础上又开发出一些其它的有用功能,下面我挑选几种功能和大家说一下: 1、如何让搜索引擎搜索到你的页面 …
Python爬虫并自制新闻网站,太好玩了
来源 | 凹凸数据(ID:alltodata)我们总是在爬啊爬,爬到了数据难道只是为了做一个词云吗?当然不!这次我就利用flask为大家呈现一道小菜。Flask是python中一个轻量级web框架,相对于其他web框架来说…
CPU值满resmgr:cpu quantum造成的Oracle等待事件解决办法
cpu quantum造成的Oracle等待事件解决办法 不少接触数据库的朋友有一个困扰已久的问题——resmgr:cpu quantum。已经遇过不少次这种CPU突然全绿的情况,通过隐含参数屏蔽了一下,方便研究。 刚好有人问我这个问题,就干脆翻文档写一篇文章给这位…
讲解用户角色切换
方法一:有root密码,可以使用su - root切换到root下,为了安全起见,不建议使用,因为如果切换到root下,被人修改了root密码,就真的完蛋了.......方法二:通过sudo给普通用户授权…
HTML教程-各窗口间相互操作(Frame Target)
文章来源: 山西之窗由Frames分出来的几个窗口的内容并不是静止不变的,往往一个窗口的内容随着另一个窗口的要求而不断变化,这就提高了Frames的利用价值。为了完成各窗口之间的相互操作,我们必须为每一个窗口起一个名字,…
[转载] 晓说——第3期:梦回青楼 爱与自由的温柔乡(上)
转载于:https://www.cnblogs.com/6DAN_HUST/archive/2012/08/20/2647811.html
10个 Python 工程师,9个不合格!
毋庸置疑,Python越来越被认可为程序员新时代的风口语言。 无论是刚入门的程序员,还是年薪百万的 BATJ 的大牛都无可否认:Python的应用能力是成为一名码农大神的必要项。 所以,很多程序员把Python当做第一语言来学习。 但对于Pytho…

驱动07.USB驱动程序
1 了解USB识别的过程 eg:在Windows系统下的一个现象:把手机的USB设备接到PC 1. 右下角弹出"发现android phone" 2. 跳出一个对话框,提示你安装驱动程序 问1. 既然还没有"驱动程序",为何能知道是"a…
豪气!华为放话:3年培养100万AI人才!网友神回应了
大家经常把BAT挂在嘴边,但是可能有些人还不知道,华为的体量早已超越了这三巨头,只是迟迟不肯上市。华为的创始人任正非曾说表:上不上市不重要,最重要的是要让中国华为的技术能够称霸全球!华为对技术的重视&…
InnoDB的启动,关闭,恢复
InnoDB存储引擎是MySQL的存储引擎之一,因此InnoDB存储引擎的启动和关闭更准确地是指在MySQL实例的启动过程中对InnoDB表存储引擎的处理过程。 参数innodb_fast_shutdown 在关闭时,参数innodb_fast_shutdown影响着表的存储引擎为InnoDB的行为。该参数可取…
微软推出提点神器动态ReLU,可能是最好的ReLU改进
作者 | Vincent 来源 | 晓飞的算法工程笔记 简介ReLU是深度学习中很重要的里程碑,简单但强大,能够极大地提升神经网络的性能。目前也有很多ReLU的改进版,比如Leaky ReLU和 PReLU,而这些改进版和原版的最终参数都是固定的。所以论…
监控 monit
官方说明文档 http://mmonit.com/monit/documentation/monit.html 实例 http://mmonit.com/wiki/Monit/ConfigurationExamples 下载最新软件包 wget http://mmonit.com/monit/dist/monit-5.4.tar.gz monit 介绍 monit是一个实用程序,用于在 Unix 系统上管理和监视…
框架窗口的尺寸设置
将窗口分割为几块,横向分用ROWS属性,纵向分用COLS属性,每一块的大小可以由这两个属性的值来实现。 <frameset cols#> 例:<frameset cols"100,200,300"> <frameset rows#> 例:<…
C语言双链表遍历,插入,删除
#include<stdio.h> #include<stdlib.h> #include <string.h> #define bzero(a, b) memset(a, 0, b)//windows平台下无bzero函数。 增加宏拓展移植性struct node{int data; //有效数据 struct node *pLast;//指向上一个节点的指针…
详解.NET的RAD功能
作者:中国计算机报Visual Studio.NET 拥有开发者建立一个成功而强大的中间层应用服务所需要的所有开发工具,利用这些工具,开发者可以: 1.保障消息传播和利用微软消息队列(MSMQ)跨平台的通讯; 2…
Java初学者如何自学和自己定位解决问题
注: OneCoder 即本人苦逼Coder 今天群里(Java Coder群:91513074)的朋友,问我该如何看帮助文档,或者说在遇到问题的时候如何解决。希望我能介绍一下我的方法。 这个OneCoder其实没有资格高谈阔论,只能说说个人的习惯和…
仅用 4 小时,吃透“百度太行”背后硬科技!
我们正处于一个 AI 生万物,万物生 AI 的时代,云与 AI 也如共同体,水乳相容不可分割。无论是企业还是政府机构、社会团体,上云已然成为一个不可抗的趋势,尤其是 AI 的发展,更是离不开强大、灵活、便捷的云计…
(转)java 中的try catch finally 语句中含有return语句的执行情况(总结版)
原处:http://blog.csdn.net/ns_code/article/details/17485221在这里看到了try catch finally块中含有return语句时程序执行的几种情况,但其实总结的并不全,而且分析的比较含糊。但有一点是可以肯定的,finally块中的内容会先于try…

希捷携全线企业级解决方案出席ODCC,Exos X18与Exos 2X14硬盘斩获两项大奖
2020年9月15日,数据存储与管理解决方案提供商希捷科技公司亮相2020开放数据中心(ODCC)峰会,并发表了以“数据新视界”为主题的演讲。希捷银河(Exos)18TB硬盘与希捷银河(Exos)2X14 MA…
动态装载和使用类型
作者:微软Reflection提供诸如Microsoft Visual Basic.NET和JScript语言编译器使用的底层结构来实施隐性后绑定。绑定是定位与某一特定类型相对应的声明的过程。当这个过程发生在运行的时候,而不是编译的时候,它被称为后绑定。Visual Basic.NE…