打通语言理论和统计NLP,Transformers/GNNs架构能做到吗?
作者 | Chaitanya K. Joshi
译者 | 苏本如,责编 | 夕颜
来源 | CSDN(ID:CSDNnews)
我的工程师朋友经常问我:图深度学习听起来很棒,但是有没有实际应用呢?
虽然图神经网络被用于Pinterest、阿里巴巴和推特的推荐系统,但一个更巧妙的成功案例是Transformer架构,它在NLP(Natural Language Processing ,自然语言处理)世界掀起了一场风暴。
在这篇文章中,我尝试在图神经网络(GNNs)和Transformers之间建立一种联系。我将讨论NLP和GNN社区对于模型架构背后的直觉,用方程和图形建立两者之间的联系,并讨论两者如何合作来共同进步。
让我们从模型架构的目的——表示学习(representation learning)开始。
NLP的表示学习
在较高的层次上,所有的神经网络结构都将输入数据的“表示”构建为嵌入向量,并对有关数据的有用统计和语义信息进行编码。这些潜在的或隐藏的“表示”可以用于执行一些有用的操作,例如对图像进行分类或翻译句子。神经网络通过接收反馈(通常是通过误差/损失函数)来学习构建更好的“表示”。
对于自然语言处理(NLP),通常递归神经网络(RNNs)以顺序的方式构建句子中每个单词的“表示”,即一次一个单词。直观地说,我们可以把一个RNN层想象成一个传送带,上面的文字从左到右进行递归处理。最后,我们得到了句子中每个单词的一个隐藏的特征,我们将其传递给下一个RNN层或用于我们选择的NLP任务。
如果你想回顾一下RNNs和NLP的表示学习,我强烈推荐Chris Olah的博客。
Transformers 最初是为机器翻译而引入的,现在已经逐渐取代了主流NLP中的RNNs。该架构采用了一种全新的表示学习方法:完全不需要使用递归,Transformers使用一种注意力机制(attention mechanism)来构建每个单词的特征,以确定句子中所有其他单词对前述单词的重要性。了解了这一点,单词的更新特征就是所有单词特征的线性变换的和,并根据其重要性进行加权。
在2017年的时候,这种想法听起来非常激进,因为NLP社区已经习惯了使用RNN处理文本的顺序式方式(即一次一个单词)。它的名字可能也起到了推波助澜的作用。
详解Transformer
让我们通过将前一段翻译成数学符号和向量的语言来发展关于架构的直觉。我们将句子S中第i个单词的隐藏特征h从从第 ℓ 层更新到第 ℓ+1层,如下所示:
例如:
这里的:
其中j∈S表示句子中的词集,、
、
是可学习的线性权重(分别表示注意力计算的Query、Key和Value)。
对于句子中的每个单词,注意力机制是并行执行的,以一个单词一个单词地方式获得更新后的特征,这是RNNs上的Transformer的另一个优点:它逐词逐词地更新特征。
我们可以通过以下管道(pipeline)来更好地理解注意力机制:
考虑到单词的特征 和其他词集的特征,通过向量点积计算每对(i,j)的注意力权重,然后对所有j的注意力权重执行softmax运算。最后。我们得到单词i的最新特征。句子中的每个单词都会并行地通过相同的管道来更新其特征。
多头注意力机制
让这个简单的向量点积注意力机制发挥作用是很棘手的。因为错误的可学习权重的随机初始化会使训练过程变得不稳定。
我们可以通过并行执行多个注意力“头”并将结果串联起来(让每个“头”现在都有独立的可学习权重)来解决这个问题:
式中,是第k个注意力头的可学习的权重,
是降维投影,以匹配跨层的
和
的维度。
多个头部允许注意力机制从本质上“对冲赌注”,可以从上一层观察前一层隐藏特征的不同转换或不同的方面。我们稍后会详细讨论。
规模大小问题
Transformer架构的一个关键问题是,经过注意力机制之后的单词特征可能具有不同的规模和大小。这可能是由于在对一些单词的其他单词特征进行求和的时候,这些单词具有非常尖锐或非常分散的注意力权重。此外,在单个特征向量条目层面上,将多个注意力头拼接在一起,每个注意力头的输出值可以在不同的尺度上,从而导致最终向量
的值具有很宽的动态值范围。
按照传统的机器学习(ML)的经验,这时候向pipeline中添加一个归一化层似乎是合理的。
Transformer通过使用LayerNorm克服了第二个问题,LayerNorm在特征级别进行规一化并学习仿射变换。此外,通过特征维度的平方根来调整向量点积注意力有助于解决第一个问题。
最后,Transformer的作者提出了另一个控制尺度问题的“技巧”:一个具有特殊结构的基于位置排列的2层MLP。在多头注意力之后,他们通过一个可学习的权重将投射到一个(荒谬的)更高的维度,在那里它经历了ReLU非线性后,再被投射回其原始维度,然后再进行另一次归一化:
老实说,我不确定这个过于参数化的前馈子层背后的确切直觉是什么。我想LayerNorm和scaled dot products并没有完全解决前面提到的问题,所以大的MLP可以说是一种独立地重新缩放特征向量的hack方法。根据Jannes Muenchmeyer的说法,前馈子层确保了Transformer是一个万能逼近器。因此,投影到一个非常高的维度空间,经历一次ReLU非线性,然后重新投射到原始维度,使模型能够比在隐藏层中保持相同维度时可以“表示”更多的功能。
Transformer层的最终结构图看起来是这样的:
Transformer架构也非常适合深度学习网络,这使得NLP社区在模型参数和扩展数据方面都能够进行扩展。
每个多头注意力子层和前馈子层的输入和输出之间的残差连接是堆叠Transformer层的关键(但为了清晰起见,在图中省略了)。
使用GNNs构建图的表示
现在,我们暂时先不讨论NLP。
图神经网络(GNNs)或图卷积神经网络(GCNs)构建图数据中节点和边的表示。它们通过邻域聚合(或消息传递)来实现这一点,每个节点从其邻域收集特征,以更新其对周围的局部图结构的表示。堆叠几个GNN层使得模型能够在整个图中传播每个节点的特征--从它的邻居传播到邻居的邻居,依此类推。
以这个表情符号社交网络为例: GNN产生的节点特征可以用于预测任务,例如:识别最有影响力的成员或提出潜在的联系。
在其最基本的形式中,GNNs通过对第ℓ层节点(比如说)自身特征的非线性变换,在每个相邻节点j∈N(i)的特征的集合中加入节点自身特征的非线性变换,从而更新第ℓ层节点i的隐藏特征h:
在这里,,是GNN层的可学习权重矩阵,σ是一个类似于ReLU的非线性变换函数。在本示例中, = {
}。
邻域节点j∈N(i)上的求和可以用其他输入大小不变的聚合函数来代替,例如简单的mean/max或更强大的函数,比如基于注意力机制的加权求和函数。
这听起来耳熟吗?
也许一个pipeline(管道)将有助于实现连接:
如果我们将多个并行的邻域头进行聚合,并用注意力机制(即加权和)代替邻域j上的求和,加上归一化和前馈MLP,看,我们就得到了一个图Transformer!
句子是全连通的词图
为了使连接更加明确,可以将一个句子看作一个完全连通的图,其中每个单词都与其他每个单词相连。现在,我们可以使用GNN为图(句子)中的每个节点(单词)构建特性,然后我们可以使用它执行NLP任务。
广义地说,这就是Transformers正在做的: 它们是具有以多头注意力作为邻域聚合函数的GNNs。而标准的GNNs从其局部邻域节点j∈N(i)聚合特征,NLP的Transformer将整个句子S视为局部邻域,在每一层聚合来自每个单词j∈S的特征。
重要的是,各种特定于问题的技巧,-- 例如位置编码、因果/屏蔽聚合、学习速率调度器和广泛的预训练 -- 对Transformers 的成功至关重要,但在GNN社区中很少出现。同时,从GNN的角度来看,Transformers可以启发我们摆脱架构中的许多华而不实的东西。
我们学到了什么?
句子都是全连通图吗?
既然我们已经在Transformer和GNNs之间建立了联系,让我来谈谈一些想法。
首先,全连通图是NLP的最佳输入格式吗?
在统计NLP和ML(机器学习)流行之前,像Noam Chomsky这样的语言学家专注于发展语言结构的形式化理论,例如语法树/图。树形长短期记忆网络(Tree LSTMs)模型已经被尝试过了,但是否有可能Transformers/GNNs是可以将语言理论和统计NLP这两个世界结合在一起的更好的架构?例如,MILA(蒙特利尔学习算法研究所和斯坦福大学最近的一项研究探索了使用语法树增强预训练的Transformer,如Sachan等人在2020年提出的基于Transformer的双向编码器表示( BERT)。
图片来源: 维基百科
长期依赖性
全连通图的另一个问题是,它们使得学习单词之间的长期依赖关系变得困难。原因很简单,这是因为图的边数量和节点的数量成平方量级关系,即在一个有着n个单词的句子中,Transformer/GNN将在对单词的量级上进行计算。对于非常大的n来说,这个计算规模大到无法控制。
NLP社区对长序列和依赖关系问题的看法很有趣:使注意力机制在输入大小方面变得稀疏或自适应,在每一层中添加递归或压缩,以及使用局部敏感哈希来获得有效的注意力,这些都是可能使得Transformers变得更好的新想法。
看到来自GNN社区的想法加入其中是一件很有趣的事,例如用于句子图稀疏化的二分法(BP- Binary Partitioning)似乎是另一种令人兴奋的方法。BP-Transformers递归地将句子分为两部分,直到它们能够从句子标记中构造出一个分层二叉树。这种结构化的归纳偏置有助于模型以内存级效率的方式处理较长的文本序列。
资料来源:Ye等人,2019年
Transformers正在学习“神经语法吗” ?
在一些有关Transformers学习的文章中,基本假设是Transformers对句子中的所有词对进行注意力计算,以确定哪些词对是最有趣的,也就是能让“Transformer”学习一些类似于特定任务语法的东西。在多头注意力中,不同的头也可以“观察”不同的句法属性。
用图的术语来说,通过在全图上使用GNN,我们能从GNN在每一层执行邻域聚合的方式恢复最重要的边以及它们可能包含的内容吗?我还不太相信这个观点。
资料来源:Clark等人, 2019
为什么是多头注意力?为什么是注意力?
我更赞同多头机制的优化观点,即拥有多个注意力头可以改进学习,并克服糟糕的随机初始化。例如,这些论文表明,Transformer头可以在训练后被“修剪”或移除,而不会对性能产生显著影响。
多头邻域聚合机制在GNNs中也被证明是有效的,例如,GAT使用相同的多头注意力,MoNet使用多个高斯核来聚合特征。虽然这些是为了稳定注意力机制而发明的,但这些多头技巧会成为挤出额外模型性能的标准吗?
相反,具有简单聚合函数(如sum或max)的GNN不需要多个聚合头来进行稳定的训练。如果我们不必计算句子中每个词对之间的配对兼容性,那对Transformers来说不是很好吗?
Transformers能从完全摆脱注意力中获益吗?Yann Dauphin和合作者的最近工作提出了一种替代的ConvNet的架构。Transformers也可能最终会做一些类似的事情。
资料来源:Wu等人,2019年
为什么Transformers的训练这么难?
阅读最新的Transformer论文让我觉得,训练这些模型需要一些类似于黑魔法的东西来确定最佳学习速率调度器、热身策略和衰减设置。这可能只是因为模型太过庞大,而NLP的研究任务又太具有挑战性了。
但是最近的结果表明,这也可能是因为归一化的具体排列和架构内的残差连接所导致的。
我很喜欢阅读最新的@DeepMind Transformer论文,但是训练这些模型为什么需要它样的黑魔法呢?”对于基于单词的语言模型(LM),我们使用了16,000个warmup-step和500,000个decay-step,并牺牲了9000个goat。”
https://t.co/dP49GTa4zepic.twitter.com/1K3Fx4s3M8
- Chaitanya K.Joshi(@chaitjo)于2020年2月17日
我知道自己过分激动了,但这让我提出疑问:我们真的需要多头的昂贵的配对的注意力,过分参数化的MLP子层,和复杂的学习速度调度器吗?
我们真的需要如此之大的模型吗?对于手头的任务来说,具有良好的归纳偏差的体系结构不应该更容易训练吗?
原文链接:
https://thegradient.pub/transformers-are-graph-neural-networks/
更多精彩推荐
神经网络其实和人一样懒惰,喜欢走捷径?
自拍卡通化,拯救动画师,StyleGAN再次玩出新花样
干货!高频手撕算法合集来了
Azure Arc 正式商用、Power Platform+GitHub 世纪牵手,一文看懂 Ignite 2020
起底 ARM:留给中国队的时间不多了
相关文章:

艰辛的面向对象
为什么80%的码农都做不了架构师?>>> 所有的操作系统都不是面向对象的。 所有的操作系统都是基于函数的。ANDROID框架里面的好多类也是基于函数的。很多都是静态的方法。这个框架包括两个部分:一是JAVA部分,一是本地类。本地类不…

计算机网络第一课
1.IPv4与IPv6的区别是什么?在windows 7以上系统中,在设置本地IP地址的时候经常会看到同事含有IPV4协议项与IPV6协议项,并不同于以往windows xp系统中仅有TCP/IP协议项,不少朋友都觉得比较奇怪,询问编辑IPv4与IPv6的区别…
常用函数集农历函数
常用函数集农历函数原来是vb代码,重新整理为VB.NET版的,并在VS2003中编译通过Imports System.MathPublic Class UCnCalendarPrivate Structure SolarHolidayStructDim Month As IntegerDim Day As IntegerDim Recess As IntegerDim HolidayName As Strin…
微软发布代码智能新基准数据集CodeXGLUE,多角度衡量模型优劣
来源 | 微软研究院AI头条编者按:代码智能(code intelligence)目的是让计算机具备理解和生成代码的能力,并利用编程语言知识和上下文进行推理,支持代码检索、补全、翻译、纠错、问答等场景。以深度学习为代表的人工智能…

Spring从菜鸟到高手(四)(上)使用JdbcTemplate类实现用户登陆验证、批量更新
标签:Spring java JdbcTemplate Spring从菜鸟到高手 绝缘材料原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://tonyaction.blog.51cto.com/227462/42042看了我前面几篇文章的朋…
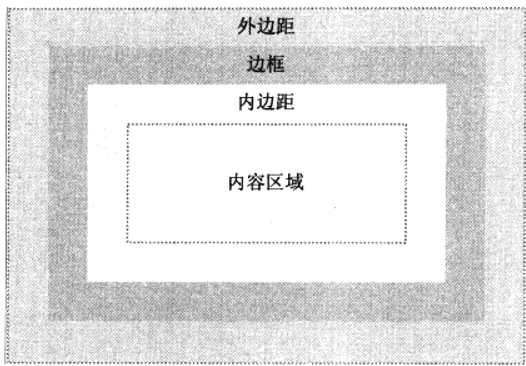
CSS盒模型及边距问题
盒模型是CSS的基石之一,页面的每一个元素都被看作一个矩形框,分别由外边距,边框,内边距,内容组成, 在CSS中,width和height的值指的是内容的宽高,增加外边距,边框…
区分C语言中getch、getche、fgetc、getc、getchar、fgets、gets
首先,这两个函数不是C标准库中的函数, int getch(void) //从标准输入读入一个字符,当你用键盘输入的时候,屏幕不显示你所输入的字符。也就是,不带回显。 int getche(void) //从标准输入读入一个字符&…
无限想象空间,用Python玩转3D人体姿态估计
前言姿态估计,一直是近几年的研究热点。它就是根据画面,捕捉人体的运动姿态,比如 2D 姿态估计:再比如 3D 姿态估计:看着好玩,那这玩应有啥用呢?自动驾驶,大家应该都不陌生࿰…
Mac中将delete键定义为删除键
在Mac中,delete键实际是退格键(Backspace),fndelete才是删除键。这也是从Windows转到Mac时不习惯的地方之一。 通过安装DoubleCommand软件可以解决这个问题。安装后,在System Preferences中找到DoubleCommand找打开在E…
CHIL-SQL-MIN() 函数
MIN() 函数 MIN 函数返回一列中的最小值。NULL 值不包括在计算中。 SQL MIN() 语法 SELECT MIN(column_name) FROM table_name 注释:MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值。 SQL MIN() 实例 我们拥有下面这个 "Orders&quo…
Google排名第一的语言,引数十万人关注:搞定它,技术大牛都甘拜下风
毋庸置疑,Python越来越被认可为程序员新时代的风口语言。无论是刚入门的程序员,还是年薪百万的 BATJ 的大牛都无可否认:Python的应用能力是成为一名码农大神的必要项。 所以,很多程序员把Python当做第一语言来学习。 但对于Python…
CSS滤镜详解
CSS滤镜详解 简介〓 设置文字透明层次,模糊效果,给文字加光晕等这些本来要靠图片才能处理的效果,现在CSS可以既简单又快速的把它实现了……接着往下看就知道了。 〓正文〓 语法:STYLE"filter:filtername(fparameter1, fpa…
php实现单链表
<?php //单链表的存储结构 class Node{ public $data;//数据域 public $next;//指针域 指向下一个结点 function __construct(){ $this->data null; $this->next null; } } //单链表数据类型 class LinkList{ public $data; public $next; function _…
2017-2-23 C#基础 中间变量
用中间变量做这个题 1、“请输入年份:”(1-9999) “请输入月份:”(1-12) “请输入日期:”(要判断大小月,判断闰年) 判断输入的时间日期是否正确 2、计算输入的…
HTA的简单应用
HTA简介:HTA是HTML Application的缩写(HTML应用程序),是软件开发的新概念,直接将HTML保存成HTA的格式,就是一个独立的应用软件,与VB、C等程序语言所设计的软件没什么差别。下面是一个HTA的例子&…
300亿美元,AMD为什么要买Xilinx?
作者 | Just来源 | CSDN(ID:CSDNnews)自2015年5月,Intel(英特尔)以167亿美元收购FPGA生产商Altera后,半导体行业接连传出大整合。上个月,NVIDIA(英伟达)宣布以400亿美元收购芯片设计公司Arm&…
PIM-SSM简介
源特定组播(SSM:Source Specific Multicast)是一种区别于传统组播的新的业务模型,它使用组播组地址和组播源地址同时来标识一个组播会话,而不是向传统的组播服务那样只使用组播组地址来标识一个组播会话。SSM保留了传统PIM-SM模式中的主机显示…

MyBatis开发入门二:一对多连表查询
1. 步骤: (1). 加包(2). 编写db.properties;编写conf.xml,将db.properties加入到conf.xml;引入别名(3). 建立实体类(4). 编写sql操作对应的***Mapper.xml文件(5). 将sql操作对应的***Mapper.xml文件注册到conf.xml文件中(6). 编写…
ASP.NET里的事务处理
出自: http://blog.csdn.net/ycl111/ 事务是一组组合成逻辑工作单元的数据库操作,虽然系统中可能会出错,但事务将控制和维护每个数据库的一致性和完整性。如果在事务过程中没有遇到错误,事务中的所有修改都将永久成为数据库的一部…
JAVA的正则表达式语法
Java 正则表达式表达式意义:1.字符x 字符 x。例如a表示字符a\\ 反斜线字符。在书写时要写为\\\\。(注意:因为java在第一次解析时,把\\\\解析成正则表达式\\,在第二次解析时再解析为\,所以凡是不是1.1列举到的转义…
应届生失业率或继续上升?别怕,这份秋招指南请收好!
受疫情影响,今年的就业形势基本上没跑了:“各行各业,大小企业,全面缩招!”据国家统计局7月份的最新数据显示:20-24岁大专及以上人员(主要为新毕业大学生)失业率比去年同期高 3.3 个百…
微信小程序把玩(三十五)Video API
原文:微信小程序把玩(三十五)Video API电脑端不能测试拍摄功能只能测试选择视频功能,好像只支持mp4格式,值得注意的是成功之后返回的临时文件路径是个列表tempFilePaths而不是tempFilePath文档写的有点问题。 主要属性:…
使用.NET发送邮件
出自: http://blog.csdn.net/ycl111/如果你曾经使用过ASP来发送邮件,你大概会使用CDONTS,但是在.NET里,发送邮件的功能已经封装进 .NET Framework的System.Web.Mail的命名空间里了,使用这个命名空间下类,就可以很容易…
采摘工人月薪十万却无人应聘,英澳农场求助 AI
作者 | 神经小兮来源 | HyperAI超神经金秋时节,本是收获的季节,但是英国、澳大利亚等地的果农却愁容满面。眼看着日渐成熟的瓜果就要烂在地里,却还招不到采摘工人。缺人,成为果农们眼下急需解决的问题。虽然大型联合收割机早已普及…
好记性不如烂笔杆-android学习笔记二 Acitvity lifecycle 生命周期
7,//Acitvity lifecycle 生命周期/***1,一个Activity就是一个类,并且这个类要继承Activity*2,复写onCreate方法*3,每个Activity需要在Androidmanifest.xml文件中配置*4,为Activity添加控件*/ 1 public class Activity …

hdu5740
考验代码能力的题目,感觉网络流一要求输出方案我就写的丑 http://www.cnblogs.com/duoxiao/p/5777632.html 官方题解写的很详细 因为如果一个点染色确定后,整个图的染色也就确定了; 对于两个点u和v, 令它们之间的最短路是dis(u,v), 那么交换它…
xml操作类(转载)
作者:未知 请与本人联系 <%Class XMLDOMDocument Private fNode,fANode Private fErrInfo,fFileName,fOpen Dim XmlDom 返回节点的缩进字串 Private Property Get TabStr(byVal Node) TabStr"" If Node Is Nothing Then Exit Property …

对HDS AMS 2000+巡检案例
1. 使用工具:笔记本,网线一根, 2. 使用软件:vmware虚拟机(安装XP P2系统,最好为P3),HSNM2-1152-W-CLI-P01.exe(AMS 200管理软件),jre…
用Python实现坦克大战游戏 | 干货贴
作者 | 李秋键出品 | AI科技大本营(rgznai100)《坦克大战》是1985年日本南梦宫Namco游戏公司在任天堂FC平台上,推出的一款多方位平面射击游戏。游戏以坦克战斗及保卫基地为主题,属于策略型联机类。同时也是FC平台上少有的内建关卡…
SPU、SKU、ARPU是什么,我来记录一下我的理解
在电商系统里经常会提到“商品”、“单品”、“SPU”、“SKU”这几个词,那么这几个词到底是什么意思呢?既然不知道是什么,那么我们就查一下:SPU Standard Product Unit (标准化产品单元),SKUst…