DataGrid基于Access的快速分页法
DataGrid基于Access的快速分页法
撰文/ 黎波
DataGrid是一个功能非常强大的ASP.NET Web服务器端控件,它除了能够方便地按各种方式格式化显示表格中的数据,还可以对表格中的数据进行动态的排序、编辑和分页。使Web开发人员从繁琐的代码中解放。实现DataGrid的分页功能一直是很多初学ASP.NET的人感到棘手的问题,特别是自定义分页功能,实现方法多种多样,非常灵活。本文将向大家介绍一种DataGird控件在Access数据库下的快速分页法,帮助初学者掌握DataGrid的分页技术。
目前的分页方法
DataGrid内建的分页方法是使用诸如“SELECT * FROM <TABLE>”的SQL语句从数据库表中取出所有的记录到DataSet中,DataGrid控件绑定到该DataSet之后,它的自动分页功能会帮你从该DataSet中筛选出当前分页的数据并显示出来,其他没有用的数据将被丢弃。
还有一种方法是使用自定义分页功能,先将DataGrid的AllowCustomPaging属性设置为True,再利用DataAdapter的Fill方法将数据的筛选工作提前到填充DataSet时,而不是让DataGrid帮你筛选:
public int Fill ( DataSet dataSet, //要填充的 DataSet。 int startRecord, //从其开始的从零开始的记录号。 int maxRecords, //要检索的最大记录数。 string srcTable //用于表映射的源表的名称。 ); |
该方法首先将来自查询处的结果填充到DataSet中,再将不需要显示的数据丢弃。当然,自定义分页功能需要完成的事情还不止这些,本文将在后面详细介绍。
以上两种方法的工作原理都是先从数据库中取出所有的记录,然后筛选出有用的数据显示出来。可见,两种方法的效率基本上是一致的,因为它们在数据访问阶段并没有采取有效的措施来减少Access对磁盘的访问次数。对于小数量的记录,这种开销可能是比较小的,如果针对大量数据的分页,开销将会非常巨大,从而导致分页的速度非常的慢。换句话说,就算每个DataGrid分页面要显示的数据只是一个拥有几万条记录的数据库表的其中10条,每次DataGrid进行分页时还是要从该表中取出所有的记录。
很多人已经意识到了这个问题,并提出了解决方法:用自定义分页,每次只从数据库中取出要显示的数据。这样,我们需要在SQL语句上下功夫了。由于Access不支持真正的存储过程,在编写分页算法上就没有SQL Server那么自由了。SQL Server可以在存储过程中利用临时表来实现高效率的分页算法,受到了广泛的采用。而对于Access,我们必须想办法在一条SQL语句内实现最高效的算法。
用一条SQL语句取得某段数据的方法有好几种。算法不同,效率也就不同。我经过粗略的测试,发现效率最差的SQL语句执行时耗费的时间大概是效率最高的SQL语句的3倍!而且这个数值会随着记录总数的增加而增加。下面将介绍其中两条常用的SQL语句。
为了方便接下来的讨论,我们先约定如下:
变量 | 说明 | 变量 | 说明 |
@PageSize | 每页显示的记录总数 | @MiddleIndex | 中间页的索引 |
@PageCount | 分页总数 | @LastIndex | 最后一页的索引 |
@RecordCount | 数据表的记录总数 | @TableName | 数据库表名称 |
@PageIndex | 当前页的索引 | @PrimaryKey | 主键字段名称 |
@FirstIndex | 第一页的索引 | @QueryFields | 要查询的字段集 |
变量 | 定义 |
@PageCount | (int)Math.Ceiling((double)@RecordCount / @PageSize) |
@FirstIndex | 0 |
@LastIndex | @PageCount – 1 |
@MiddleIndex | (int)Math.Ceiling((double)@PageCount / 2) – 1 |
先让我们看看效率最差的SQL语句:
SELECT TOP @PageSize * FROM @TableName WHERE @PrimaryKey NOT IN ( SELECT TOP @PageSize*@PageIndex @PrimaryKey FROM @TableName ORDER BY @PrimaryKey ASC ) ORDER BY @PrimaryKey ASC |
这条SQL语句慢就慢在NOT IN这里,主SELECT语句遍历的每个@PrimaryKey的值都要跟子SELECT语句的结果集中的每一个@PrimaryKey的值进行比较,这样时间复杂度非常大。这里不得不提醒一下大家,平时编写SQL语句时应该尽量避免使用NOT IN语句,因为它往往会增加整个SQL语句的时间复杂度。
另一种是使用了两个TOP和三个ORDER BY的SQL语句,如下所示:
SELECT * FROM ( SELECT TOP @PageSize * FROM ( SELECT TOP @PageSize*(@PageIndex+1) * FROM @TableName ORDER BY @PrimaryKey ASC ) TableA ORDER BY @PrimaryKey DESC ) TableB ORDER BY @PrimaryKey ASC |
这条SQL语句空间复杂度比较大。如果要显示的分页面刚好是最后一页,那么它的效率比直接SELECT出所有的记录还要低。因此,对于分页算法,我们还应该具体情况具体分析,不能一概而论。下面将简单介绍一下相关概念,如果您对主键和索引非常熟悉,可以直接跳过。
有关主键和索引的概念
在 ACCESS中,一个表的主键(PRIMARY KEY,又称主索引)必然是唯一索引(UNIQUE INDEX),它的值是不会重复的。除此之外,索引依据索引列的值进行排序,每个索引记录包含着一个指向它所引用的数据行的指针,这对ORDER BY的执行非常有帮助。我们可以利用主键这两个特点来实现对某条记录的定位,从而快速地取出某个分页上要显示的记录。
举个例子,假设主键字段为INTEGER型,在数据库表中,记录的索引已经按主键字段的值升序排好(默认情况下),那么主键字段值为“11”的记录的索引,肯定刚好在值为“12”的记录的索引前面(假设数据库表中存在主键的值为“12”的记录)。如果主键字段不具备UNIQUE约束,数据库表中将有可能存在两个或两个以上主键字段的值为“11”的记录,这样就无法确定这些记录之间的前后位置了。
下面就让我们看看如何利用主键来进行数据的分段查询吧。
快速分页法的原理
其实该分页法是从其他方法衍生而来的。本人对原来的方法认真地分析,发现通过优化和改进可以非常有效地提高它的效率。原算法本身效率很高,但缺乏对具体问题的具体分析。同一个分页算法,可能在取第一页的数据时效率非常高,但是在取最后一页的数据时可能反而效率更低。
经过分析,我们可以把分页算法的效率状态分为四种情况:
(1)@PageIndex <= @FirstIndex
(2)@FirstIndex < @PageIndex <= @MiddleIndex
(3)@MiddleIndex < @PageIndex < @LastIndex
(4)@PageIndex >= @LastIndex
状态(1)和(4)分别表示第一页和最后一页。它们属于特殊情况,我们不必对其使用特殊算法,直接用TOP就可以解决了,不然会把问题复杂化,反而降低了效率。对于剩下的两种状态,如果分页总数为偶数,我们可以看作是从数据库表中删掉第一页和最后一页的记录,再把剩下的按前后位置平分为两部分,即前面的一部分,也就是状态(2),后面的为另一部分,也就是状态(3);如果分页总数为奇数,则属于中间页面的记录归于前面的部分。这四种状态分别对应着四组SQL语句,每组SQL语句由升序和降序两条SQL语句组成。
下面是一个数据库表,左边第一列是虚拟的,不属于该数据库表结构的一部分,它表示相应记录所在的分页索引。该表将用于接下来的SQL语句的举例中:
PageIndex | ItemId | ProductId | Price |
0 | 001 | 0011 | $12 |
002 | 0011 | $13 | |
1 | 003 | 0012 | $13 |
004 | 0012 | $11 | |
2 | 005 | 0013 | $14 |
006 | 0013 | $12 | |
3 | 007 | 0011 | $13 |
008 | 0012 | $15 | |
4 | 009 | 0013 | $12 |
010 | 0013 | $11 |
由表可得:@PageSize = 2,@RecordCount = 10,@PageCount = 5
升序的SQL语句
(1)@PageIndex <= @FirstIndex
取第一页的数据是再简单不过了,我们只要用TOP @PageSize就可以取出第一页要显示的记录了。
SELECT TOP @PageSize @QueryFields FROM @TableName WHERE @Condition ORDER BY @PrimaryKey ASC |
(2)@FirstIndex < @PageIndex <= @MiddleIndex
把取数据表前半部分记录和取后半部分记录的SQL语句分开写,可以有效地改善性能。后面我再详细解释这个原因。现在看看取前半部分记录的SQL语句。先取出当前页之前的所有记录的主键值,再从中选出最大值,然后取出主键值大于该最大值的前@PageSize条记录。这里@PrimaryKey的数据类型可以不是INTEGER类型,CHAR、VARCHAR等其他类型照样可以。
SELECT TOP @PageSize @QueryFields FROM @TableName WHERE @PrimaryKey > ( SELECT MAX(@PrimaryKey) FROM ( SELECT TOP @PageSize*@PageIndex @PrimaryKey FROM @TableName WHERE @Condition ORDER BY @PrimaryKey ASC ) TableA ) WHERE @Condition ORDER BY @PrimaryKey ASC |
例如:@PageIndex=1,红-->黄-->蓝

(3)@MiddleIndex < @PageIndex < @LastIndex
接下来看看取数据库表中后半部分记录的SQL语句。该语句跟前面的语句算法的原理是一样的,只是方法稍微不同。先取出当前页之后的所有记录的主键值,再从中选出最小值,然后取出主键值小于该最小值的前@PageSize条记录。
SELECT * FROM ( SELECT TOP @PageSize @QueryFields FROM @TableName WHERE @PrimaryKey < ( SELECT MIN(@PrimaryKey) FROM ( SELECT TOP (@RecordCount-@PageSize*(@PageIndex+1)) @PrimaryKey FROM @TableName WHERE @Condition ORDER BY @PrimaryKey DESC ) TableA ) WHERE @Condition ORDER BY @PrimaryKey DESC ) TableB ORDER BY @PrimaryKey ASC |
之所以把取数据表前半部分记录和取后半部分记录的SQL语句分开写,是因为使用取前半部分记录的SQL语句时,当前页前面的记录数目随页数递增,而我们还要从这些记录中取出它们的主键字段的值再从中选出最大值。这样一来,分页速度将随着页数的增加而减慢。因此我没有这样做,而是在当前页索引大于中间页索引时(@MiddleIndex < @PageIndex)选用了分页速度随着页数的增加而加快的算法。由此可见,假设把所有分页面划分为前面、中间和后面三部分,则最前面和最后面的分页速度最快,最中间的分页速度最慢。
例如:@PageIndex=3,红 --> 黄 --> 蓝

(4)@PageIndex >= @LastIndex
取最后一页的记录可以简单地使用类似状态(1)的做法:
SELECT * FROM ( SELECT TOP @PageSize @QueryFields FROM @TableName WHERE @Condition ORDER BY @PrimaryKey DESC ) TableA ORDER BY @PrimaryKey ASC |
不过,这样产生的最后一页不一定是实际意义上的最后一页。因为最后一页的记录数未必刚好跟@PageSize相等,而上面的SQL语句是直接取得倒数的@PageSize条记录。如果想要精确地取得最后一页的记录,应该在先计算出该页的记录数,作为TOP语句的条件:
SELECT * FROM ( SELECT TOP (@RecordCount-@PageSize*@LastIndex) @QueryFields FROM @TableName WHERE @Condition ORDER BY @PrimaryKey DESC ) TableA ORDER BY @PrimaryKey ASC |
降序的SQL语句
降序的SQL语句跟升序的大同小异,这里就不在罗嗦了J
(1)@PageIndex <= @FirstIndex
SELECT TOP @PageSize @QueryFields FROM @TableName WHERE @Condition ORDER BY @PrimaryKey DESC |
(2)@FirstIndex < @PageIndex <= @MiddleIndex
SELECT TOP @PageSize @QueryFields FROM @TableName WHERE @PrimaryKey < ( SELECT MIN(@PrimaryKey) FROM ( SELECT TOP @PageSize*@PageIndex @PrimaryKey FROM @TableName WHERE @Condition ORDER BY @PrimaryKey DESC ) TableA ) WHERE @Condition ORDER BY @PrimaryKey DESC |
(3)@MiddleIndex < @PageIndex < @LastIndex
SELECT * FROM ( SELECT TOP @PageSize @QueryFields FROM @TableName WHERE @PrimaryKey > ( SELECT MAX(@PrimaryKey) FROM ( SELECT TOP (@RecordCount-@PageSize*(@PageIndex+1)) @PrimaryKey FROM @TableName WHERE @Condition ORDER BY @PrimaryKey ASC ) TableA ) WHERE @Condition ORDER BY @PrimaryKey ASC ) TableB ORDER BY @PrimaryKey DESC |
(4)@PageIndex >= @LastIndex
SELECT * FROM ( SELECT TOP (@RecordCount-@PageSize*@LastIndex) @QueryFields FROM @TableName WHERE @Condition ORDER BY @PrimaryKey ASC ) TableA ORDER BY @PrimaryKey DESC |
如何动态产生上述的SQL语句?
看了上面的SQL语句之后,相信大家已经基本明白该分页法的原理了。下面,我们将要设计一个动态生成SQL语句的类FastPaging。该类有一个公有静态方法,它根据您给出的条件动态生成SQL语句,作为方法的返回值。
// 产生根据指定字段排序并分页查询的 SELECT 语句。 public static String Paging( int pageSize, //每页要显示的记录的数目。 int pageIndex, //要显示的页的索引。 int recordCount, //数据表中的记录总数。 String tableName, //要查询的数据表。 String queryFields, //要查询的字段。 String primaryKey, //主键字段。 bool ascending, //是否为升序排列。 String condition //查询的筛选条件。 ) { StringBuilder sb = new StringBuilder(); int pageCount = GetPageCount(recordCount,pageSize); //分页的总数 int middleIndex = GetMidPageIndex(pageCount); //中间页的索引 int firstIndex = 0; //第一页的索引 int lastIndex = pageCount - 1; //最后一页的索引 if (pageIndex <= firstIndex) { // 代码略 } else if (pageIndex > firstIndex && pageIndex <= middleIndex) { sb.Append("SELECT TOP ").Append(pageSize).Append(" ") .Append(queryFields).Append(" FROM ").Append(tableName) .Append(" WHERE ").Append(primaryKey); if (ascending) sb.Append(" > (").Append(" SELECT MAX("); else sb.Append(" < (").Append(" SELECT MIN("); sb.Append(primaryKey).Append(") FROM ( SELECT TOP ") .Append(pageSize*pageIndex).Append(" ").Append(primaryKey) .Append(" FROM ").Append(tableName); if (condition != String.Empty) sb.Append(" WHERE ").Append(condition); sb.Append(" ORDER BY ").Append(primaryKey).Append(" ") .Append(GetSortType(ascending)).Append(" ) TableA )"); if (condition != String.Empty) sb.Append(" AND ").Append(condition); sb.Append(" ORDER BY ").Append(primaryKey).Append(" ") .Append(GetSortType(ascending)); } else if (pageIndex > middleIndex && pageIndex < lastIndex) { // 代码略 } else if (pageIndex >= lastIndex) { // 代码略 } return sb.ToString(); } |
除了Paging方法还有另外几个方法:
// 根据记录总数和分页大小计算分页数。 public static int GetPageCount(int recordCount, int pageSize) { return (int)Math.Ceiling((double)recordCount/pageSize); } // 计算中间页的页索引。 public static int GetMidPageIndex(int pageCount) { return (int)Math.Ceiling((double)pageCount/2) - 1; } // 获取排序的方式("ASC"表示升序,"DESC"表示降序) public static String GetSortType(bool ascending) { return (ascending ? "ASC" : "DESC"); } // 获取一个布尔值,该值指示排序的方式是否为升序。 public static bool IsAscending(String orderType) { return ((orderType.ToUpper() == "DESC") ? false : true); } |
让DataGrid工作起来
有了上面的类,实现分页的工作就简单多了。首先,我们要将DataGrid的AllowPaging属性和AllowCustomPaging属性为True,除此之外,为了体现出升序和降序的功能,还需要将AllowSorting属性也设置为True。然后在每次分页时,我们需要产生一个OleDbDataReader对象或DataView对象绑定到DataGrid,作为DataGrid的数据源。这里需要用FastPaging类的Paging方法根据条件产生一个SQL语句,并赋给OleDbCommand对象的CommandText属性:
cmd.CommandText = FastPaging.Paging( DataGrid1.PageSize, (int)ViewState["CurrentPageIndex"], DataGrid1.VirtualItemCount, "Items", "ItemId, ProductId, Price", "ItemId", FastPaging.IsAscending(OrderType), "" ); |
在上面的程序段中,ViewState["CurrentPageIndex"]的值在DataGrid的Page事件处理程序中被更新为e.NewPageIndex。为了方便处理ViewState的空值,最好把对ViewState["CurrentPageIndex"]的存取操作和空值判断封装在一个属性里。DataGrid1. VirtualItemCount应该设置为数据库表中的记录总数。DataGrid通过它和PageSize属性可以虚拟出DataGrid的分页数。VirtualItemCount的值是在Page的Load事件处理程序中被设置的,而该值的大小需要经过一次数据库访问才能得到。为了提高性能,可以只在第一次加载页面的时候设置该值。
总结
DataGrid基于Access的快速分页法到这里就介绍完了。当然,这种方法并不能“包治百病”,可能对于您的要实现的功能,还有其它更好的方法。这就需要大家在平时工作和学习中不断总结经验,在解决实际问题时尽可能找到最有效的方法。这也是本文的方法中所贯穿的思想。
相关文章:

urlrewrite使用小结
urlrewrite顾名思义,就是对URL进行重写,用户得到的全部都是经过处理后的URL地址,这样做我觉得好处有三:一:提高安全性,可以有效的避免一些参数名、ID等完全暴露在用户面前,如果用户随便乱输的话…
性能超越图神经网络,将标签传递和简单模型结合实现SOTA
译者 | 刘畅出品 | AI科技大本营头图 | CSDN付费下载自视觉中国图神经网络(GNNs)是图学习中一种主流的技术。然而,对于GNN为什么在实际使用中很成功以及它们是否是优异性能所必需的技术,了解相对较少。本文展示了许多标准的传导节…

模仿VIMD的模式的简化代码示例
按numpad0来切换模式,按t显示不同的结果; Numpad0:: tfmode:!tfmode aaa:(tfmode1?"AAAA":"BBBB") SplashImage Off SplashImage, "",X500 Y500 W200 B fs10 CT00FFFF CW000000,%aaa%, , 切换模式提示 WinSet, Tr…
DataGrid连接Access的快速分页法(1)——需求与现状
作者:黎波一、需求分析 DataGrid是一个功能强大的ASP.NET Web服务器端控件,它除了能够按各种方式格式化显示数据,还可以对数据进行动态的排序、编辑和分页。大大减轻了广大Web程序员的工作量。实现DataGrid的分页功能一直是很多入门者感到棘手…
CSDN公众号新功能上线,居然还能搜出小姐姐???
为了给各位打工人更好的搜索体验CSDN总是在学习新技能这次CSDN公众号又给大家带来了一项全新的搜索技能在CSDN旗下的公众号内回复消息就能自动回复想搜索的内容啦小编来给大家演示一下,在公众号内输入“mysql安装教程”,就能得到CSDN全站内关于mysql安装…
p2v、v2v 转换-windows篇
问题:如何把 xenserver的虚拟机转成Esxi的虚拟机 如何把物理机转成Esxi的虚拟机答案:↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓首先介绍一下实验环境。一台xenserver主机上两台虚拟机 win03和win08 转到Esxi5.0的一台主机上。Esxi5.0在某个…

WebViewJavascriptBridge原理解析
基本说明 我们的项目是一个OC与javascript重度交互的app,OC与javascript交互的那部分是在WebViewJavascriptBridge的github地址的基础上修改的,WebViewJavascriptBridge应该是当前最流行最成功的OC与Web交互实现了。最近看了一下他的实现原理,…

DataGrid连接Access的快速分页法(2)——SQL语句的选用(升序与降序)
作者:黎波 一、相关概念 在 ACCESS 数据库中,一个表的主键(PRIMARY KEY,又称主索引)上必然建立了唯一索引(UNIQUE INDEX),因此主键字段的值是不会重复的。并且索引页依据索引列的值…
从谷歌AutoML到百度EasyDL,AI大生产时代,调参师不再是刚需
出品 | AI科技大本营头图 | 付费下载于视觉中国2018 年,Google Cloud 宣布将 AutoML 作为机器学习产品的一部分。至此,AutoML 开始进入大众的视野。 实际上,2013 年AutoWEKA的发布可以算作AutoML的开端;2014 年,ICML开…

Python 语法小知识
为什么80%的码农都做不了架构师?>>> 序列解包 将含有多个值的序列解开,然后把值存放到变量中,当函数或者方法返回元组时这个特性很有用,可以把返回的序列值直接赋值给变量,在序列解包时等号两边的元素个数…
CSS布局之-水平垂直居中
对一个元素水平垂直居中,在我们的工作中是会经常遇到的,也是CSS布局中很重要的一部分,本文就来讲讲CSS水平垂直居中的一些方法。另外,文中的css都是用less书写的,如果看不懂less,可以把我给的demo链接打开&…
DataGrid连接Access的快速分页法——动态生成SQL语句
作者:黎波using System;using System.Text;namespace Paging{/// <summary>/// FastPaging 的摘要说明。/// </summary>public class FastPaging {private FastPaging() {}/// <summary>/// 获取根据指定字段排序并分页查询的 SELECT 语句。/// &…
一文读懂机器学习“数据中毒”
作者 | Ben Dickson翻译 | 火火酱~出品 | AI科技大本营头图 | 付费下载于视觉中国在人类的眼中,下面的三张图片分别展示了三样不同的东西:一只鸟、一只狗和一匹马。但对于机器学习算法来说,这三者或许表示同样的东西:一个有黑边的白色小方框。…
chartee
2019独角兽企业重金招聘Python工程师标准>>> 一个绘制图表的类库,支持绘制股票的K线图,还可以绘制曲线、柱状图等等。 Code4App编译测试,测试环境:Xcode 4.3, iOS 5.0。 转载:http://www.adobex.com/ios/source/detail…
C语言存储类关键字
1、static这个关键字有三种用法:(1)第一种是用来修饰局部变量,使之成为静态局部变量;静态局部变量存储在数据段/bss段中,作用域是代码块作用域,生命周期是程序生命周期,链接属性是无…
显示DataGrid序号的一个适用的方法
作者Blog:http://blog.csdn.net/wangj2001/如果数据量小的话没有问题,一旦数据量大,显示特别慢,还有个缺点就是拖动行高时行号不随行高的变化而变动,出现是几个序号在一个单元格中显示。我自己对他们的算法进行总结&am…
Integer的自动缓存
2019独角兽企业重金招聘Python工程师标准>>> Interger装箱有个自动缓存的概念 Integer a 100;Integer b 100;Integer c 200;Integer d 200;System.out.println(a b); //trueSystem.out.println(c d); //false Integer是对象,比较的是对象在内存中…
崩溃!双十一第 4 天,某互联网公司黄了?
01打折这么狠是不是要黄了??今年的双十一,开始地比以往早一些!不知道各位程序员小哥哥们的战绩如何,是不是已经被一轮又一轮的定金、尾款,折腾到数学细胞耗尽?付款了也不清楚自己有没有真正的「…
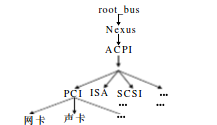
FreeBSD设备驱动管理介绍(BSP: Ti AM335x)
这段时间一直在忙FreeBSD驱动移植的项目,因此对FreeBSD做了一定的了解,鉴于网上对于FreeBSD的设备驱动资料较少,在这里给出本人对于FreeBSD驱动管理的理解心得(主要是USB驱动管理),希望能对开源开发者有所帮…

视障人士体验自动驾驶:携导盲犬登车,未来有望“自己开”
6月27日,滴滴出行首次面向公众开放自动驾驶服务。用户可通过滴滴APP线上报名,审核通过后,将能在上海自动驾驶测试路段,免费呼叫自动驾驶车辆进行试乘体验。现阶段,滴滴自动驾驶载人测试范围仅限于在上海开放测试道路上…
Listview获取选中行的值
一般情况请注意别先删除了选中行,又去使用。那就会导致找不到选中行。。。。。哥犯了这个错误。。。找了很长时间问题if (this.lstwlview.SelectedIndices.Count > 0) { if (MessageBox.Show("确认删除该条码?",…
asp.net中DataGrid性能测试
作者Blog:http://blog.csdn.net/yzdy/ 测试环境:数据库服务器:2.4G P4 CPU,2G 内存,Windows Advanced Server 2000,SQL Server 2000Web服务器:2.4G P4 CPU,1G 内存,Windows Advanced…
javassist学习笔记
2019独角兽企业重金招聘Python工程师标准>>> 介绍:www.javassist.org/ javassist、ASM 对比 1、javassist是基于源码级别的API比基于字节码的ASM简单。 2、基于javassist开发,不需要了解字节码的一些知识,而且其封装的一些工具类可…
金融领域首个开源中文BERT预训练模型,熵简科技推出FinBERT 1.0
出品 | AI科技大本营头图 | CSDN付费下载于东方IC为了促进自然语言处理技术在金融科技领域的应用和发展,熵简科技 AI Lab 近期开源了基于 BERT 架构的金融领域预训练语言模型 FinBERT 1.0。据悉,这是国内首个在金融领域大规模语料上训练的开源中文BERT预…
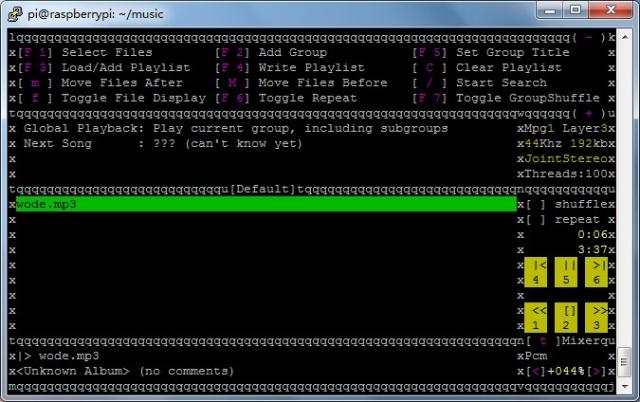
raspberry pi下使用mp3blaster播放mp3音乐
首先:sudo apt-get install mp3blaster mp3blaster wode.mp3会报错 但是加padsp mp3blaster wode.mp3 就可以正常播放了
把Excel文件中的数据读入到DataGrid中
作者Blog:http://blog.csdn.net/net_lover/使用Excel文件做为DataGrid的数据源是非常简单的,一旦数据被装载进来,就可以把数据再保存进SQL Server或XML中。我们只需要简单地使用OLE DB Provider 来访问Excel文件,然后返回DataSet即…
Vue 数组中更新属性值后,视图不更新,等待其他元素更新后会触发的解决办法...
因为 JavaScript 的限制,Vue.js 不能检测到下面数组变化: 直接用索引设置元素,如 vm.items[0] {}; 修改数据的长度,如 vm.items.length 0。 this.examineIntro.questionList[0].selList[1].url url;为了解决问题 (…
DeepMind 最新论文解读:首次提出离散概率树中的因果推理算法
翻译 | 高卫华出品 | AI科技大本营头图 | CSDN付费下载自视觉中国当前,一些前沿AI研究人员正在寻找用于表示上下文特定的因果依赖关系清晰的语义模型,这是因果归纳所必需的,在 DeepMind的算法中可看到这种概率树模型。概率树图用于表示概率空…
使用c#+(datagrid控件)编辑xml文件
作者Blog:http://blog.csdn.net/ouyang76cn/ 使用c#(datagrid控件)编辑xml文件 这个源码是我根据网上一个vb.net编辑xml文件的原理用c#重写的。除重用xml文件外.并未重用任何代码!. 这小段代码,可对xml文件的记录进行删除,修改&am…
HorizontalTable
2019独角兽企业重金招聘Python工程师标准>>> HorizontalTable 实现了可水平滚动的 TableView。 转载:http://www.adobex.com/ios/source/details/00000761.htm 转载于:https://my.oschina.net/u/868244/blog/106055